
Сообщение по информатике 8 класс на тему стандарт unicode
Обновлено: 17.05.2024
Юникод (Unicode), это многоязычный, основанный на ASCII стандарт кодирования символов, а также, связанное с ним, семейство многобайтных кодировок. Если некоторые слова из предыдущего предложения вам не понятны, давайте рассмотрим их подробнее.
Что такое кодировка
Современные компьютеры всё ещё достаточно глупые и, в большинстве своём, не умеют работать ни с чем, кроме чисел. Мы рассматриваем на своих мониторах фотографии, смотрим фильмы, играем в игры. Но для компьютеров всё это лишь безликий поток нулей и единичек. Так же и текст — для компьютера это просто набор байтов. Буквы и любые другие символы представляются в машинной памяти, как числа.
Подобный список всех используемых символов и соответствующих им чисел и называется кодировкой. Вы, скорее всего, уже слышали названия многих кодировок: Windows-1251, KOI-8, ну и, конечно, Unicode.
Крякозябры
Это всё из-за того, что в мире наплодилось слишком много разных кодировок. И текст в одной из них выглядит совершенно не так, как в другой. Дело в том, что компьютер не знает какую кодировку вы используете для текста. Для него это просто последовательность каких-то чисел.
Чтобы подобного не происходило, нужно каким-то образом указывать кодировку в которой набран текст. Например, в HTML это делается с помощью тега:
ASCII
В определённый момент времени распространение получила кодировка ASCII (American Standard Code for Information Interchange). В ней определены 128 символов с кодами от 0 до 127. Сюда включён латинский алфавит, цифры и основные знаки препинания (
Основан на ASCII и Юникод.
Однобайтные кодировки
Одна из причин, по которой появилось такое большое количество кодировок, это то, что вначале каждая компания придумывала свои стандарты, не обращая внимания на другие. Вторая причина заключается в том, что старые кодировки были однобайтными. То есть каждому символу в тексте соответствует один байт в памяти компьютера.
Однобайтные кодировки всем хороши: они компактны, с ними легко работать (нужно достать пятый символ — просто берём пятый байт от начала). Единственная проблема: в них помещается мало символов. Ровно столько, сколько значений может принимать один байт, то есть обычно, это 256. Например, в Windows-1251 мы отдали 128 символов под ASCII, добавили 66 букв русского алфавита (строчные и заглавные), несколько знаков препинания и вот у нас уже остаётся не так много свободных позиций. Даже на псевдографику не хватает.
То есть свести в одну кодировку все возможные символы даже европейских алфавитов достаточно сложно. А уж для китайцев с их тысячами иероглифов вообще всё тоскливо. А о всяких смайликах, эмоджи и иконках самолётиков и думать нечего. Поэтому для кириллицы приходилось изобретать свою кодировку, а для греческого языка другую.
Впрочем, такая ситуация сохранялась достаточно долго. Потому что проблемы англоязычных пользователей и программистов решила ASCII, а до китайских проблем им не было дела. С ростом же глобального интернета вдруг оказалось, что в мире говорят не только на английском языке, поэтому с кодировками нужно что-то менять.
Многобайтные кодировки
Самым простым решением было взять два байта вместо одного. Плюс такого решения: теперь можно в рамках одной кодировки использовать 65 тысяч символов. Минусы тоже есть:
- Для всех возможных символов, иероглифов и смайликов даже 65 тысяч символов мало.
- Текстовые файлы стали занимать вдвое больше места, даже тексты на английском. Слишком расточительно.
- Кодировки перестали быть ASCII-совместимыми и многие программы не могли с ними работать.
Стандарт Unicode
В конечном итоге всё вылилось в стандарт Юникода, который худо-бедно, но решает практически все стоявшие перед кодировками проблемы.
С одной стороны, Юникод позволяет кодировать практически неограниченное количество символов. В последнем стандарте определено более 100 000 различных символов всех современных и многих уже мёртвых языков, а также различные иконки и пиктограммы. С другой стороны, некоторые способы кодирования позволяют Юникоду оставаться ASCII-совместимыми. Что позволяет работать, как и раньше многим программам, а также американским и другим англоязычным пользователям, многие из которых появления Юникода даже не заметили. В Юникоде также собраны все символы из всех популярных стандартов кодирования, что позволяет преобразовать в него любой текст из старой кодировки.
Практически все современные программы, работающие с текстом, понимают Юникод. Более того, обычно они в нём и работают. Например, даже когда вы открываете сайт в старой доброй Windows-1251, браузер сначала внутри у себя перекодирует все тексты в Юникод, а потом отображает их. В общем, Юникод, это светлое будущее интернета и всей компьютерной индустрии.
Отличие набора символов от кодировки
В эпоху однобайтных кодировок, это различие было практически неуловимо. Число 65 — байт со значением 65 или последовательность битов 01000001 . Для многобайтных же уже возникают вопросы: сколько байтов использовать, в каком порядке, фиксированное число байтов или нет?
Кодировки и шрифты
За изображение символа отвечают шрифты. Поэтому один и тот же символ в разных шрифтах может выглядеть по разному, а то и вообще отсутствовать.
Мы используем 🍪cookie, чтобы сделать сайт максимально удобным для вас. Подробнее
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам
Климова Наталья Ивановна
Сам стандарт состоит из двух частей: универсальный набор символов и семейство кодировок. Универсальный набор символов (англ. UCS ) представляет из себя таблицу соответствия символов их кодовому значению. Сами символы делятся на группы по их принадлежности либо к какому-либо языку, либо к математическим символам, знакам пунктуации, специальным знакам. Сейчас таких групп 17 по 2 16 (65536) символа в каждом.
UTF -8 – это формат кодирует символы последовательностью из двоичных блоков от1 до 6 байт. Если последовательность состоит только из 8 бит, то такая кодировка совпадает с ACSII . В других случаях первый байт содержит количество бит символа, закодированного в двоичной системе счисления.

№ слайда 1
Кодирование символов: ASCII, KOI8, UNICODE

№ слайда 2

№ слайда 3
ASCII Для отображения всех этих символов была создана таблитца ASCII (англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией; произносится [э ски].

№ слайда 5

№ слайда 6
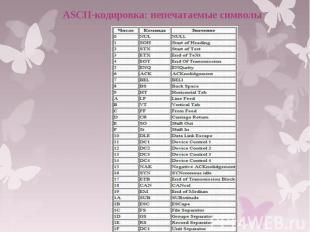
№ слайда 7
ASCII-кодировка: непечатаемые символы

№ слайда 8

№ слайда 9

Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
- прогноза погоды;
- вычислений экспериментальной и теоретической физики;
- расчета заработной платы сотрудников (например, компьютер LEO применялся для нужд компании, владеющей сетью чайных магазинов);
- прогнозирование результатов выборов президента США (1952 год, компьютер UNIVAC).
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
- Число из десятичной системы счисления переводится в двоичную, т.е. набор нулей и единиц. Например, 3 в двоичной системе счисления можно записать в виде 11, а 9 как 1001. Подробнее о системах счисления читайте в соответствующем гайде.
- Полученный набор нулей и единиц хранится в ячейках памяти компьютера. Например, наличие тока на элементе памяти означает единицу, его отсутствие — ноль.

В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).

Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
- Компьютеры должны стать универсальными. Это означало переход от производства узкоспециализированных компьютеров к машинам, которые могут решать разные задачи.
- Компьютеры должны стать совместимыми друг с другом, то есть должна быть возможность использовать данные с одного компьютера на другом.
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).

Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
- символ Ø можно было получить так: печатаем O, затем с помощью управляющего кода BS (BackSpace) передвигаем печатную головку на один символ назад и печатаем символ /,
- символ à получался как a BS `
- символ Ç получался как C BS ,
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.

Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.
Читайте также: