
Сообщение на тему оптимизация производительности бд
Обновлено: 18.05.2024
Что касается оптимизации базы данных, в Интернете много информации и методов, но многие из них имеют неравномерное качество, а некоторые из них недостаточно обобщены, а содержание является избыточным.
Время от времени находя эту статью, ее резюме очень классические, и поток статей также очень большой, поэтому получите мою собственную коллекцию сводок, накапливайте высококачественные статьи, улучшайте личные способности, надейтесь на развитие для всех в будущем Также помогает
1. Выберите наиболее применимые атрибуты полей
MySQL может поддерживать большие объемы доступа к данным, но, как правило, чем меньше таблица в базе данных, тем быстрее выполняется запрос к ней. Поэтому при создании таблицы, чтобы получить лучшую производительность, мы можем установить ширину полей в таблице как можно меньше.
Например, при определении поля почтового индекса, если вы установите его в CHAR (255), оно, очевидно, добавляет ненужное пространство в базу данных, и даже использование типа VARCHAR является избыточным, потому что CHAR (6) может быть очень хорошим Выполнено задание. Точно так же, если возможно, мы должны использовать MEDIUMINT вместо BIGIN для определения целочисленных полей.
Еще один способ повысить эффективность - по возможности установить поле NOT NULL., Так что когда запрос будет выполнен в будущем, базе данных не нужно сравнивать значения NULL.
2. Используйте JOIN вместо подзапросов
MySQL поддерживает подзапросы SQL с 4.1. Этот метод может использовать инструкцию SELECT для создания результата запроса в один столбец, а затем использовать этот результат в качестве условия фильтра в другом запросе. Например, если мы хотим удалить клиента, у которого нет заказа в таблице базовой информации о клиентах, мы можем использовать подзапрос, чтобы сначала извлечь все идентификаторы клиентов из таблицы с информацией о продажах, а затем передать результаты в основной запрос, как показано ниже. :
WHERE CustomerID NOT in (SELECT customerid FROM salesinfo)
Использование подзапросов может завершить множество операций SQL, для которых требуется логическое завершение нескольких шагов одновременно, а также избежать транзакций или блокировок таблиц, и их легко написать. Однако в некоторых случаях подзапросы могут быть заменены более эффективными объединениями (JOIN). Например, предположим, что мы хотим убрать всех пользователей, у которых нет записей заказов, мы можем использовать следующий запрос для завершения:
WHERE customerid NOT IN (SELECT customerid FROM salesinfo)
Если вы используете JOIN для выполнения этого запроса, скорость будет намного выше.Особенно, если CustomerID проиндексирован в таблице salesinfo, производительность будет выше. Запрос выглядит следующим образом:
LEFT JOIN salesinfo ON customerinfo.customerid =salesinfo.customerid
WHERE salesinfo.customerid IS NULL
JOIN .. Причина, по которой он более эффективен, заключается в том, что MySQL не нужно создавать временные таблицы в памяти для выполнения этого логического двухэтапного запроса.
3. Используйте UNION для замены созданных вручную временных таблиц.
Начиная с версии 4.0 MySQL поддерживает запросы на объединение и может объединять два или более запроса на выборку, для которых требуются временные таблицы, в один запрос. В конце сеанса запросов клиента временная таблица будет автоматически удалена, чтобы обеспечить аккуратность и эффективность базы данных. При использовании объединения для создания запроса нам нужно использовать только UNION в качестве ключевого слова для соединения нескольких операторов выбора, следует отметить, что количество полей во всех операторах выбора должно быть одинаковым. В следующем примере демонстрируется запрос с использованием UNION.
SELECT name,birthdate FROM author UNION
SELECT name,supplier FROM product
4. Дела
Хотя мы можем использовать подзапросы, JOIN и UNION для создания разнообразных запросов, не все операции с базой данных могут быть выполнены с помощью одного или нескольких операторов SQL. а. Чаще всего необходимо использовать серию утверждений для выполнения определенного вида работы. Однако в этом случае, когда оператор в этом блоке операторов выполняется неправильно, работа всего блока операторов становится неопределенной. Представьте себе, что если вы хотите вставить определенные данные в две связанные таблицы одновременно, может возникнуть такая ситуация: после успешного обновления первой таблицы база данных внезапно обнаружит непредвиденное состояние, в результате чего операция во второй таблице не будет завершена. Таким образом, это приведет к неполным данным и даже уничтожит данные в базе данных. Чтобы избежать этой ситуации, вы должны использовать транзакции, и их роль такова: либо каждый оператор в блоке операторов выполняется, либо завершается неудачей. Другими словами, можно поддерживать согласованность и целостность данных в базе данных. Все начинается с ключевого слова BEGIN, а ключевое слово COMMIT заканчивается. Если в промежутке между операциями SQL происходит сбой, команда ROLLBACK может восстановить состояние базы данных до начала BEGIN.
Другая важная роль транзакций заключается в том, что когда несколько пользователей используют один и тот же источник данных в одно и то же время, он может использовать метод блокировки базы данных, чтобы предоставить пользователям безопасный метод доступа, который может гарантировать, что операции пользователя не будут мешать другим пользователям. ,
5. Зафиксируйте стол
Хотя транзакции являются очень хорошим способом поддержания целостности базы данных, но из-за ее исключительности это иногда влияет на производительность базы данных, особенно в больших прикладных системах. Поскольку база данных будет заблокирована во время выполнения транзакции, другие пользовательские запросы могут только временно ждать окончания транзакции. Если система баз данных используется только несколькими пользователями, влияние транзакций не станет большой проблемой, но, если учесть, что тысячи пользователей одновременно получают доступ к системе баз данных, например, к веб-сайту электронной коммерции, Более серьезная задержка ответа.
Фактически, в некоторых случаях мы можем добиться лучшей производительности, блокируя таблицу. В следующем примере используется метод таблицы блокировки для завершения функции транзакции в предыдущем примере.
UPDATE inventory SET Quantity=11 WHERE Item= ‘book’ ;UNLOCKTABLES
Здесь мы используем оператор select для извлечения исходных данных, а после некоторых вычислений мы используем оператор update для обновления нового значения в таблице. Оператор LOCKTABLE, содержащий ключевое слово WRITE, может гарантировать отсутствие другого доступа для вставки, обновления или удаления инвентаризации до выполнения команды UNLOCKTABLES.
6. Используйте внешние ключи
Метод блокировки таблицы может поддерживать целостность данных, но не может гарантировать актуальность данных. В это время мы можем использовать внешние ключи.
Например, внешние ключи могут гарантировать, что каждая запись о продажах указывает на определенного существующего клиента. В данном случае внешний ключ может отображать параметр customerid в таблице customerinfo в значение customerid в таблице salesinfo, и любая запись без действительного customerid не будет обновляться или вставляться в salesinfo.
CREATE TABLE salesinfo ( salesid int not null ,customerid int not null , primary key(customerid,salesid) ,foreign key (customerid) references customerinfo (customerid) on delete cascade)engine = innodb;
7. Используйте индекс
индексЭто распространенный метод повышения производительности базы данных, который позволяет серверу баз данных извлекать определенные строки с гораздо более высокой скоростью, чем без индекса, особенно когда оператор запроса содержит команды MAX (), MIN () и ORDERBY. Улучшение более очевидно.
Какие поля должны быть проиндексированы?
Вообще говоря, индекс должен строиться на полях, которые будут использоваться для оценки JOIN, WHERE и сортировки ORDERBY. Старайтесь не индексировать поле в базе данных, которое содержит много повторяющихся значений. Для поля типа ENUM очень вероятно, что большое количество повторяющихся значений
8. Оптимизированный оператор запроса
В большинстве случаев использование индекса может повысить скорость запроса, но если оператор SQL не используется должным образом, индекс не сможет играть свою роль.
Ниже приведены некоторые аспекты, которые следует отметить.
a、 Прежде всего, лучше сравнивать операции между полями одного типа.
До версии MySQL 3.23 это было даже необходимым условием. Например, индексированное поле INT и поле BIGINT нельзя сравнивать, но в особом случае, когда размер поля поля типа CHAR и поля типа VARCHAR одинаков, их можно сравнивать.
b、 Во-вторых, старайтесь не использовать функции для работы с индексированными полями
Например, при использовании функции YEAE () в поле типа DATE индекс не будет играть свою роль. Поэтому, хотя следующие два запроса возвращают один и тот же результат, последний намного быстрее, чем первый.
c、В-третьих, при поиске символьных полей мы иногда используем LIKE ключевые слова и подстановочные знаки, хотя этот метод прост, но он также снижает производительность системы.
Например, следующий запрос будет сравнивать каждую запись в таблице.
Но если вы переключитесь на следующий запрос, возвращаемые результаты будут такими же, но скорость будет намного выше:
Наконец, следует позаботиться о том, чтобы MySQL не выполнял автоматические преобразования типов во время запросов, поскольку процесс преобразования также делает индексы неэффективными.
1. LIMIT 1 Когда нужно извлечь из таблицы уникальную строку
Иногда, формируя запрос, вы уже знаете, вам нужна только одна уникальная строка в таблице. Вы можете сформировать выборку по уникальной записи. Или вы можете просто запустить проверку на существование любого количества записей, которые удовлетворяют вашему условию.
В таких случаях, использование метода LIMIT 1 может существенно увеличить производительность:
2. Оптимизация работы с базой с помощью обработки кэша запросов
Большинство серверов MySQL поддерживают функцию кэширования запросов. Это один из наиболее эффективных методов повышения производительности, с которым движок базы данных справляется без проблем.
Когда один и тот же запрос выполняется несколько раз, то, результат будет получен из кэша. Без необходимости обрабатывать снова все таблицы. Это значительно ускоряет процесс.
3. Индексация полей поиска
Индексы предназначены не только для присвоения первичному или уникальному ключам. Если в таблице есть столбцы, по которым вы производите поиск, их практически в обязательном порядке следует индексировать.
4. Индексирование и использование столбцов одинакового типа при объединении
Если ваше приложение содержит много запросов на объединение, необходимо убедиться, что столбцы в обеих таблицах, которые вы объединяете, проиндексированы. Это влияет на оптимизацию внутренних операций MySQL по объединению.
Кроме того, столбцы, которые объединяются, должны быть одинакового типа. Например, если вы объединяете столбец типа DECIMAL из одной таблицы и столбец типа INT из другой, MySQL не сможет использовать по крайней мере один из индексов.
Даже кодировка символов должна быть того же типа для соответствующих строк объединяемых столбцов.
5. По возможности не используйте запросы типа SELECT *
Чем больше данных в таблице обрабатывается при запросе, тем медленнее выполняется сам запрос. Время уходит на дисковые операции. Кроме того, когда сервер базы данных разделен с веб-сервером, возникают задержки при передаче данных между серверами.
6. Пожалуйста, не используйте метод сортировки ORDER BY RAND()
Это один из тех приемов, которые на первых порах кажутся неплохими, и многие программисты-новички попадаются на эту удочку. Вы даже не представляете, какую ловушку расставляете сами себе же, как только начинаете использовать в запросах этот фильтр.
Если вам действительно нужно отсортировать некоторые строки в результатах поиска, то есть гораздо более эффективные способы сделать это. Допустим, что вам нужно добавить дополнительный код к запросу, но из-за данной ловушки вы не сможете этого сделать, что приведет к уменьшению эффективности обработки данных, по мере того, как база будет разрастаться в размерах.
Проблема в том, что MySQL будет выполнять операцию RAND () (которая использует вычислительные ресурсы сервера) перед сортировкой для каждой строки в таблице. При этом выбираться будет всего одна строка.
Таким образом, вы выберете меньшее количество результатов поиска, после чего сможете применить метод LIMIT, описанный в пункте 1.
7. Используйте столбцы типа ENUM вместо VARCHAR
Столбцы типа ENUM очень компактны, а, следовательно, быстры в обработке. Внутри базы их содержание хранится в формате TINYINT , но они могут содержать и выводить любые значения. Поэтому в них очень удобно задавать определенные поля.
Используйте для хранения IP-адресов поля типа UNSIGNED INT
Многие разработчики создают для этих целей поля типа VARCHAR (15) , в то время как IP-адреса можно было бы хранить в базе в виде десятичных чисел. Поля типа INT предоставляют возможность хранить до 4 байта информации, и при этом для них можно задать фиксированный размер поля.
Вы должны удостовериться, что ваши колонки имеют формат UNSIGNED INT , поскольку IP-адрес задается 32-мя битами.
В запросах можно использовать параметр INET_ATON () для преобразования IP-адресов в десятичные числа, и INET_NTOA () — наоборот. PHP имеет и другие аналогичные функции long2ip () и ip2long () .
8. Вертикальное секционирование (разделение)
Вертикальное секционирование представляет собою процесс, когда структура таблицы разделяется по вертикали из соображений оптимизации работы с базой данных.
Пример 1: Допустим, у вас есть таблица пользователей, в которой в числе прочего содержатся их домашние адреса. Данная информация используется очень редко. Вы можете разделить вашу таблицу и хранить данные по адресам в другой таблице.
Таким образом, ваша основная таблица пользователей заметно уменьшится в размерах. А как вы знаете, меньшие таблицы, обрабатываются быстрее.
Однако вы должны быть уверены в том, что обе таблицы, которые получились после секционирования, не будут в дальнейшем использоваться одинаково часто. В противном случае это существенно снизит производительность.
9. Меньшие столбцы – быстрее
Для движков баз данных дисковое пространство, пожалуй, самое узкое место. Поэтому хранить информацию более компактно, как правило, полезно с точки зрения производительности. Это уменьшает количество обращений к диску.
В MySQL Docs прописан ряд требований к хранению разных типов данных. Если ожидается, что таблица не будет содержать слишком большое количество записей, то нет причин хранить первичный ключ в полях типа INT, MEDIUMINT, SMALLINT , а в отдельных случаях даже TINYINT . Если в формате даты вам не нужны составляющие времени (часы : минуты), то используйте поля типа DATE вместо DATETIME.
Однако все же убедитесь, что на перспективу вы оставили себе достаточно пространства для развития. Иначе в какой-то момент может произойти что-то типа обвала.
10. Правильно выбирайте движок
Даже если вы обновляете всего одно поле одной из строк, вся таблица может быть заблокирована, и никакой другой процесс не сможет получить к ней доступ, пока не завершится этот запрос. В то же время MyISAM очень быстр в обработке запросов типа SELECT COUNT (*) .
InnoDB – это более сложный механизм и может медленнее, чем MyISAM работать с большинством приложений. Но он поддерживает функции, которые позволяют более эффективно работать с базами больших размеров.
Данная статья написана по материалам доклада, прочитанного на Конференции Инфостарта IE 2014 29-31 октября 2014 года. Меня зовут Сергей, являюсь руководителем отдела оптимизации и производительности систем в компании "Деловые линии". Цель этого доклада – поделиться информацией о нашем опыте работы с большой базой на платформе 1С, с чем пришлось столкнуться, как удалось обеспечить работоспособность.
Текущее состояние автоматизируемой системы
Для начала - несколько слов о системе и нагрузке на нее (*по состоянию на сентябрь 2014):
- Суммарно за сутки записывается порядка миллиона объектов ссылочного типа. Из них:
- 700 тысяч – это документы (перепроведение существующих и запись новых).
- 300 тысяч – это справочники (также модификация существующих и запись новых).
- Количество формирований отчетов в сутки составляет порядка 250 тысяч. Это многочисленные оперативные и аналитические отчеты.
- Суммарная длительность запросов, выполняемых пользователями в базе за сутки, превышает 330 тысяч секунд (92 часа) – достаточно интенсивная нагрузка.
При этом компания продолжает развиваться, открываются новые подразделения, привлекаются новые сотрудники, новые клиенты.
Есть постоянная потребность по разработке и внедрению новых подсистем, по автоматизации бизнес процессов, по решению различных интеграционных вопросов.
Поэтому у нас и большой отдел разработки - более 40 человек программистов, а также аналитики, тестировщики, архитекторы, эксперты. В общей сложности более 100 человек.
Процесс оптимизации. Начало
Вопрос необходимости оптимизации возник несколько лет назад, когда в процессе бурного роста нашей компании постоянно увеличивалось количество пользователей информационной базы и, соответственно, значительно возрос объем обрабатываемых ими данных. При этом архитектура базы не была готова к такой интенсивной работе, поскольку она рождалась достаточно давно (еще на 7.7) и не была на это рассчитана, а вопросами SQL-сервера занимался программист 1С.
Начальные условия:
- Платформа 8.1
- Число пользователей в базе: 1000
- Режим блокировок: атоматические
- APDEX - отсутствует
- Нагрузка ЦПУ сервера СУБД достигает 98%
- Постоянные жалобы пользователей на "подвисания"
- Количество разработчиков: 10
- Обновления конфигурации БД: еженедельно
Что сделали на первом этапе:
- Разработали план регламентных работ по перестроению и дефрагментации индексов.
- Установили ЦУП и принялись за оптимизацию запросов.
- Перешли на управляемые блокировки.
- Внедрили APDEX (на мой взгляд – это обязательная штука, если, конечно, вы хотите знать что происходит с вашей базой).
Конечно запросы из форм списков были не единственными, мы переписали досточно много запросов, а где то и архитектуру. Эта работа дала результат. Раньше, например, нагрузка на систему в понедельник и пятницу могла быть настолько высока, что приходилось отпускать домой некоторые отделы (менеджеров, колл-центр). А в результате проведенной оптимизации получилось снизить нагрузку в пятницу – проблем больше не было. Да и в понедельник мы тоже, со скрипом, но работали.
Второй этап оптимизации. "Разделяй и властвуй"
Тем не менее, мы прекрасно понимали, что расслабляться нельзя, надо действовать дальше, потому что количество пользователей к тому моменту опять выросло: их стало почти 2000. Штат разработчиков вырос до 20 человек, функционал наращивался очень быстро. И здесь нам помог случай и неудачный переход на 8.2 (8.2.13). Про переход на 8.2 можно многое рассказать, но так как тот опыт удачным не был, отмечу основную ошибку - не был проведен полноценный нагрузочный тест на 2000 рабочих мест.
Итак, не впадая в историзмы, у нас развивался свой сайт и от него поступал достаточно большой трафик запросов, которые "стучались" в боевую базу. Но эти запросы не требовали он-лайн данных и могли бы, например, подключаться к копии с актуальностью минус сутки. И у нас была подсистема репликации на планах обмена, которая разрабатывалась специально для перехода на 8.2 (на случай отката с 8.2 обратно на 8.1). Эта подсистема, используя план обмена, позволяет поддерживать в актуальном состоянии копию рабочей базы. Вот в эту копию мы и перенаправили часть соединений вэб сервисов. И заметили снижение нагрузки. Да, было понятно, что нагрузка должна несколько снизиться, но мы не рассчитывали, что ее падение будет настолько существенным. Сами запросы от сайта были достаточно маленькие, просто их поток был очень большим.
Возник вопрос: нельзя ли то же самое сделать с отчетами? Первое, что приходит в голову – это запустить для пользователя две базы: первую использовать только для ввода данных, а вывод отчетов там запретить, а во второй разрешить формировать отчеты, но запретить ввод данных. С точки зрения юзабилити это негативный сценарий, пользователь должен работать в одной базе, но при этом запрос надо выполнять в копии. Поэтому пошли другим путем:
- Провели пару экспериментов, убедились, что и результат запроса и табличный документы отлично сериализуются. В табличном документе, переданном по COM посредством сериализации/десериализации, работают даже расшифровки.
- Разработали шаблон отчета, который позволяет передавать настройки отчета и получать его результат по СОМ соединению.
- Улучшили подсистему репликации и добились актуальности данных в 2 – 3 минуты, что значительно расширило список перенаправляемых отчетов. Доработки в основном были нужны потому, что стандартный метод "ВыбратьИзменения" планов обмена создает большое колличество блокировок.
- Переписали кучу отчетов, приведя их к единому стандарту.
- OLTP – это рабочая база, где вносят первичку.
- OLAP –это база, где формируются отчеты и куда перенаправляются запросы веб-сервисов. Или, например, в эту базу можно зайти разработчику, чтобы протестировать какой-то отчет, как он будет себя вести в боевой системе.
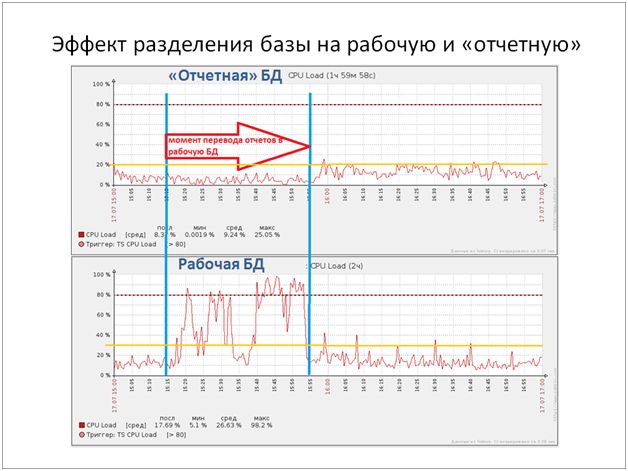
Нагрузка на CPU в этот период достигала 98%. Так же обращаю внимание на не линейный рост нагрузки, грубо говоря, 20%+30%=100%.
Очередное развитие отчетная база получила, когда вышел SQL Server 2012 и появилась технология AlwaysOn, которая позволяет средствами самой СУБД создавать и поддерживать несколько копий БД в актуальном состоянии (теперь у нас задержки всего лишь несколько миллисекунд). Сама по себе технология позволяет отказаться от репликации средствами 1С, но переписывать отчеты все равно придется.
Разделение базы стало для нас очень большим прорывом, потому что у нашей системы появился запас прочности (а у нас появились выходные).
Этот запас прочности помог нам начать большой проект по переходу на 8.2 с поддержкой ЦКТП от 1С. В прошлом году (*декабрь 2013) этот проект был удачно завершен, и этой весной (*весна 2014) мы перешли на релиз 8.2.19.
О ЦКТП осталось положительное впечатление. Советую всем, у кого "большая база": если вы планируете перейти на другую платформу либо хотите понять что будет, например, при двух кратном увеличении числа пользователей – обращайтесь в 1С, в рамках проектов ЦКТП достаточно оперативно устраняются и ошибки платформы и выявляются "узкие" места БД.
Инструменты для мониторинга и обнаружения проблем производительности
- ЦУП;
- PerfExpert от SoftPoint;
- zabbix;
- Статистика SQLServer.
Статистика SQL сервера
- dm_exec_query_stats - статистика производительности для кэшированных планов запросов.
db.name,
SUBSTRING(text,(statement_start_offset/2)+1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(text)
ELSE statement_end_offset
END - statement_start_offset)/2)+ 1) AS [Текст запроса],
execution_count [Количество выполнений],
total_elapsed_time/1000000 [Длительность, сек],
total_worker_time/1000000 [Процессорное время, сек],
total_logical_reads [Логических чтений],
total_physical_reads [Физических чтений],
qp.query_plan [XML план запроса]
FROM sys.dm_exec_query_stats
OUTER APPLY sys.dm_exec_sql_text(sql_handle) dm_text
left join sys.databasesdb on dm_text.dbid = db.database_id
OUTER APPLY sys.dm_exec_query_plan(plan_handle) AS qp
WHERE
last_execution_time>=DATEADD(minute,-180,getdate())
ORDER BY
total_worker_time DESC--сортировка по нагрузке на процессор
--total_logical_reads DESC --сортировка по логическим чтениям
--execution_count desc --сортировка по количеству выполнений
- dm_exec_requests это второе часто используемое динамическое представление - сведения о выполняемых в текущий момент запросах.
db.name,
a.session_id,
a.blocking_session_id,
a.transaction_id,
a.cpu_time,
a.reads,
a.writes,
a.logical_reads,
a.start_time,
a.[status],
case a.transaction_isolation_level
when 1 then'ReadUncomitted'
when 2 then'ReadCommitted'
when 3 then'Repeatable'
when 4 then'Serializable'
when 5 then'Snapshot'
end УровеньИзоляции,
a.wait_time,
a.wait_type,
a.last_wait_type,
a.wait_resource,
a.total_elapsed_time,
st.text,
qp.query_plan,
p.loginame [loginame сессии вызвавшей блокировку],
p.program_name [Приложение сессии вызвавшей блокировку],
p.login_time [Время входа сессии вызвавшей блокировку],
p.last_batch [Время последнего запроса сессии вызвавшей блокировку],
p.hostname [Host Name сессии вызвавшей блокировку],
stblock.text [Текущий(!) запрос сессии вызвавшей блокировку]
FROM sys.dm_exec_requests a
OUTER APPLY sys.dm_exec_sql_text(a.sql_handle) AS st
OUTER APPLY sys.dm_exec_query_plan(a.plan_handle) AS qp
LEFT JOIN sys.sysprocesses p
OUTER APPLY sys.dm_exec_sql_text(p.sql_handle) AS stblock
on a.blocking_session_id > 0 and a.blocking_session_id = p.spid
LEFT JOIN sys.databases db
ON a.database_id = db.database_id
WHERE not a.status in('background','sleeping')
ORDER BY a.cpu_time DESC
Сейчас, для определения причин высокой нагрузки на процессор, нам в 90% случаев хватает именно этих двух запросов к динамическим представлениям.
На слайде - недавний случай:
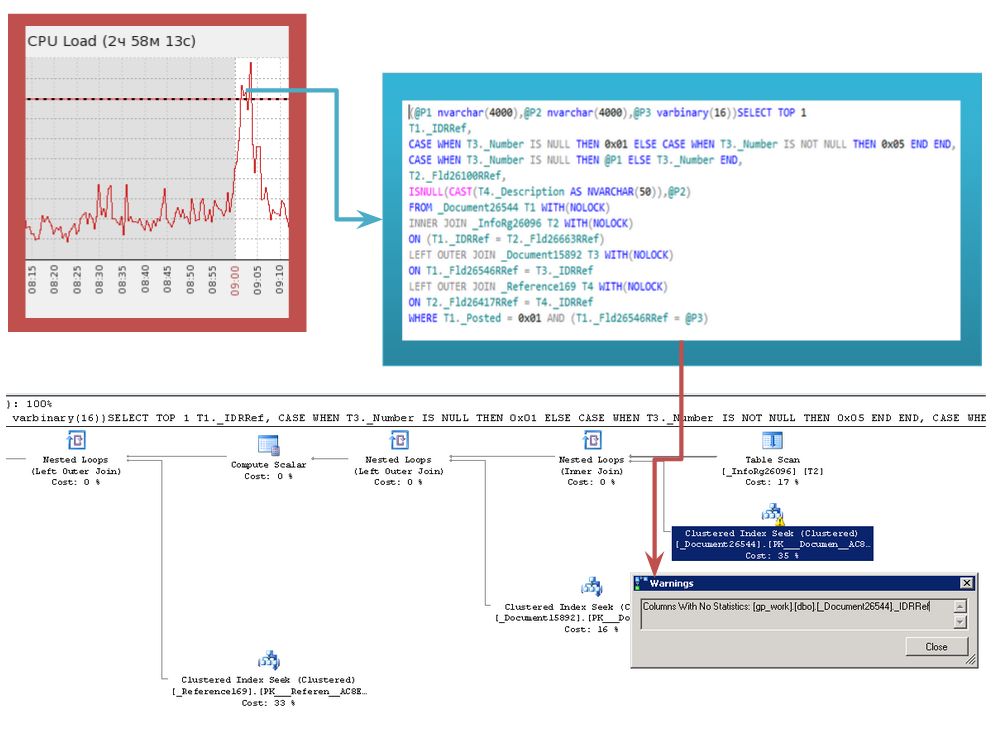
Резкое повышение нагрузки в 9 утра – народ пришел на работу. Посмотрев статистику кэшированных запросов обратили внимание на лидера по количеству логических чтений и план этого запроса. Причина была в отсутствии статистик для индексов документа. Выполнив обновление статистик этого документа проблему достаточно оперативно устранили.
По динамическим представлениям есть один нюанс, связанный с не повторяемостью текстов запросов использующих временные таблицы. Например, три одинаковых запроса, отличающихся только именем временной таблицы:

Проблема не так мала, как может показаться.
Во-первых, это накладные расходы на сервер т.к. СУБД воспринимает их как разные запросы и для каждого будет заново строить план запроса.
Во-вторых, сложнее пользоваться статистикой самого СУБД. Динамические представления, о которых шла речь выше, не группируют эти запросы и увидеть их суммарное влияние становится проблематично.
По заявлениям 1С данная проблема решена в 8.3, хотя по нашим тестам, получить подобный набор запросов достаточно просто. Проблему можно легко решить - дать возможность программисту самому назначить имя временной таблицы, но разработчики платформы нам с вами не доверяют принимать столь ответственное решение.
- dm_db_index_usage_stats, dm_db_missing_index_groups, dm_db_missing_index_group_stats - сведения об отсутствующих индексах и частоте использования существующих индексов.
(!)Обращаю внимание, что эта информация носит рекомендательный характер и бездумное ее применение может навредить системе. Например, если вы удумаете создать индекс напрямую в СУБД и той структуры, которую выводит статистика, то помимо нарушения лицензионного согласения с 1С вы можете столкнуться с блокировками. Второй момент, который надо обязательно знать, на одну и ту же конструкцию запроса SQL может "захотеть" несколько вариантов индекса и слепо следуя совету вы насоздаете много лишнего.
Запрос, отображающий статистику по существующим индексам:
С помощью него можно определить какие индексы не используются, какие используются редко и имеют высокие издержки содержания.
Для наглядности покажу на примере обработки, в которую сведена информация из обоих запросов:
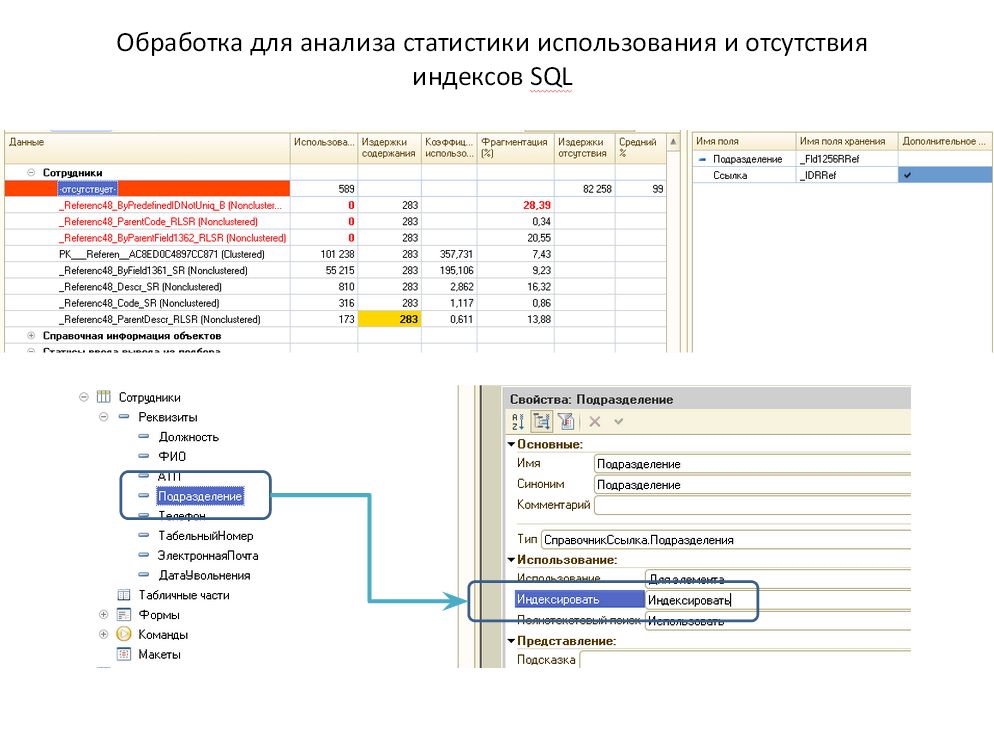
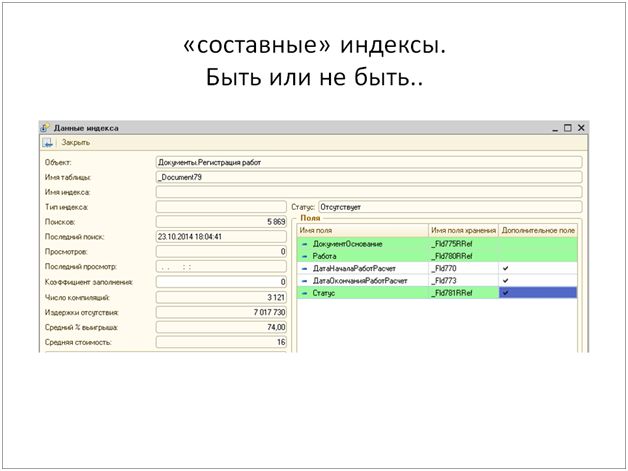
Позиция 1С достаточно проста – если вам нужен составной индекс, значит надо переписать или доработать архитектуру.
ЦУП
Центр управления производительностью из Корпоративного Инструментального Пакета от 1С. Его многие знают или, как минимум, слышали про него.
Назначение - сбор данных о ресурсоемких запросах, блокировках и deadlock.
Источник данных - технологический журнал, для анализа дэдлоков ЦУП - трассировки СУБД.
С ЦУПа мы начали, используем его и сейчас. Правда его пришлось самого оптимизировать и выделить для него мощный сервер.
- ресурсоемкость запроса определяется только на основании времени его выполнения;
- требует доработок;
PerfExpert
Назначение - сбор данных о ресурсоемких запросах, блокировках и дедлоках; накопление и отображение данных о состоянии системы.
Источник данных - трассировки СУБД, Perfomance Monitor.
Основное отличие – статистика по запросам накапливается из трассировок к СУБД и делится на 2 категории – запросы с длительностью более 5 секунд и запросы с количеством чтений больше 50000. При этом тексты запросов группируются корректно и разные имена временных таблиц не мешают этому. Консолидирует и отображает информацию по большому количеству счетчиков Perfomance Monitor, так же есть возможность подключать в качестве счетчика прямой запрос к СУБД, что позволяет, например, выводить график APDEX.
- нет полного контекста выполнения;
- нельзя купить лицензию на бессрочное использование.
- наглядное отображение текущего состояния системы;
- подробная информация о нагрузке на СУБД.
Zabbix
Назначение - накопление и отображение данных о состоянии системы; уведомление о превышении показателя пороговых значений.
Используется как универсальное средство для различного рода уведомлений и сигнализаций. Например о высокой нагрузке на CPU, о снижении АПДЕКСа. О состоянии важных бизнес процессов, например уведомление о превышении порогового количества электронных писем в очереди на отправку.
В отличии от перечисленных выше инструментов не является помощником в оптимизации и востребован, в основном, отделом технической поддержки пользователей.
Этот материал я дополнил той информацией, которую планировал рассказать на конференции, но не успел.
Спасибо за внимание!
*Доклад не корректировался с учетом "временного сдвига", в частности информация о числе пользователей, количестве записываемых объектов и т.п. уже изменилась (в большую сторону).
Открыт набор на уникальный курс повышения квалификации по управленческому учету, в котором своим опытом делятся не один, а три преподавателя-практика.
MySQL - это одна из самых популярных реляционных систем управления базами данных, которая используется для обеспечения большинства веб-сайтов в интернете. От скорости записи и получения данных из таблиц зависит скорость работы сайта, в целом, так как, если на один запрос будет уходить больше секунды, то это будет тормозить работу php, а в следствии скоро накопиться столько запросов, что сервер не сможет их обработать.
В сегодняшней статье мы поговорим о том, как выполняется оптимизация производительности mysql. Какие программы для этого лучше использовать и как это работает.
Скорость работы MySQL
Оптимизация без аналитики бессмысленна. Перед тем как переходить к оптимизации давайте посмотрим как работает база данных сейчас, есть ли запросы, которые выполняются очень медленно. Все настройки вашего сервиса mysql находятся в файле /etc/my.cnf. Чтобы включить отображение медленных запросов добавьте такие строки в my.cnf, в секцию [mysqld]:
Здесь первая строка включает запись лога медленных запросов, вторая указывает, что минимальное время запроса для внесения его в этот лог - две секунды. Еще можно включить в лог запросы, которые не используют индексы:
Но это уже необязательно для проверки скорости и используется больше для отладки кода и правильности создания таблиц. Дальше перезапустите сервер баз данных и посмотрите лог:
systemctl restart mariadb
tail -f /var/log/mariadb/slow-queries.log

Мы можем видеть, что есть запросы, которые выполняются больше, чем 10 секунд. Это, например, запрос
SELECT option_name, option_value FROM wp_options WHERE autoload = 'yes';
Можно его выполнить отдельно, в консоли mysql:

Здесь тоже измеряется время, и мы видим результат - три секунды. Это очень много. И еще ничего, если такие запросы приходят редко, если ваш сайт постоянно под нагрузкой, то тремя секундами вы не отделаетесь, количество необработанных запросов будет расти, а скорость ответа увеличиваться до нескольких минут. Можно пойти двумя путями - оптимизировать код, убрать сложные запросы, или же нужна оптимизация mysql на сервере.
Оптимизация MySQL
Конфигурация MySQL достаточно сложная, но, к счастью, вам не нужно в нее сильно углубляться. Есть специальный скрипт под названием MySQLTunner, который анализирует работу MySQL и дает советы какие параметры нужно изменить и какие значения для них установить. Скрипт поддерживает большинство версий MariaDB, MySQL и Percona XtraDB. Нам понадобится загрузить три файла с помощью wget:

Первый из них - это сам скрипт, написанный на Perl, второй и третий - база данных простых паролей и уязвимостей. Они позволяют обнаружить проблемы с безопасностью. Дальше можно переходить к тестированию. Я использую сервер с настройками mysql по умолчанию, установленными панелью управления VestaCP.

Буквально за несколько минут скрипт выдаст полную статистику по работе MySQL. Количеству запросов, занимаемому объему памяти и эффективности работы буферов. Вы можете ознакомиться со всем этим, чтобы лучше понять в чем причина проблем. Проблемные места обозначены красными восклицательными знаками. Например, здесь мы видим, что размер буфера движка таблиц InnoDB (InnoDB buffer pool) намного меньше, чем должен быть для оптимальной работы:


Все параметры нужно добавлять в /etc/my.cnf. Еще раз замечу, что вы не копируете статью, а смотрите что вам выдала утилита. Начнем с query-cache.
query_cache_size=0
query_cache_type=0
query_cache_limit=1M
Скрипт рекомендует отключить кэш запросов. Query Cache - это кэш вызовов SELECT. Когда базе данных отправляется запрос, она выполняет его и сохраняет сам запрос и результат в этом кэше. И все бы ничего, но при использовании его вместе с InnoDB при любом изменении совпадающих данных кэш будет перестраиваться, что влечет за собой потерю производительности. И чем больше объем кэша, тем больше потери. Кроме того при обновлении кэша могут возникать блокировки запросов. Таким образом, если данные часто пишутся в базу данных - его надежнее отключить.
Оба параметра устанавливают размер памяти, которая используется для внутренних временных таблиц MySQL. Утилита рекомендует использовать объем больше 16 мегабайт, просто установите это ваше значение для обоих переменных, если у вас достаточно памяти, то можно выделить 32 или даже 64. Но важно чтобы оба значения совпадали, иначе будет использоваться минимальное.
Этот параметр отвечает за количество потоков, которые будут закэшированны. После того, как работа с подключением будет завершена, база данных не разорвет его, а закэширует, если количество кэшированных потоков не превышает ограничение. Утилита рекомендует больше четырех, например, 16.
Указывает, что не нужно пытаться определить доменное имя для подключений извне. Ускоряет работу, так как не тратится время на DNS запросы.
Этот параметр определяет размер буфера InnoDB в оперативной памяти, от этого размера очень сильно зависит скорость выполнения запросов. Значение зависит от размера ваших таблиц и количества данных в них. Если памяти недостаточно, запросы будут обрабатываться дольше. У меня используется стандартный объем 128, а нужно больше 652.

Размер файла лога innodb должен составлять 25% от размера буфера. В случае 800 мегабайт это будет 200М. Но тут есть одна проблема. Чтобы изменить размер лога нужно выполнить несколько действий. Поскольку мы изменили все нужные параметры перейдем к перезагрузке сервера. Для нашего лога нужно остановить сервис:
systemctl stop mariadb
Затем переместите файлы лога в /tmp:
mv /var/lib/mysql/ib_logfile[01] /tmp

И запустите сервис:
systemctl start mariadb
systemctl status mariadb

Тестирование результата
Готово оптимизация базы данных mysql завершена, теперь тестируем тот же запрос через клиент mysql:
> USE база_данных;
> SELECT option_name, option_value FROM wpfc_options WHERE autoload = 'yes';

Первый раз он выполняется долго, может даже дольше чем обычно, но все последующие разы буквально мгновенно. Результат с более 3 секунд до 0,15. А если брать статистику из slow-log, то от более 12. Если в выводе утилиты для вас были предложены и другие оптимизации, то их тоже стоит применить.
Выводы
Как видите, оптимизация mysql это достаточно просто благодаря такому скрипту, но, в то же время, такая операция может очень сильно помочь, особенно высоконагруженным проектам. Еще лучше ускорить работу может только оптимизация запросов mysql. Не забывайте время от времени проверять параметры, чтобы быть уверенным что все в порядке. Если у вас остались вопросы, спрашивайте в комментариях!
На завершение лекция про производительность MySQL от Percona:
Читайте также: