
Сообщение на тему документ ориентированные базы данных
Обновлено: 24.06.2024
Документальные БД. Теоретико-множественная модель индексирования и поиска. Структура процессов в абстрактной АИПС. Примеры структур документоориентированных баз данных
5.1. Документальные информационные системы, основанные на концепции БД
Элементом информационного массива АИС является документ. Документом при этом можно считать как всю совокупность записей (обычно текстов), хранящихся в БД, так и отдельные фрагменты текста - заголовки разделов, абзацы и т. д. при этом большую проблему представляет учет контекста употребления слова, зависящий больше не от синтаксических, а от семантических критериев. При поиске может использоваться сходство внутренней структуры отдельных документов, представленной, например, средствами формального языка типа SGML (Standard Generalized Markup Language). Помимо текста, для поиска могут использоваться содержащиеся в статьях уравнения, таблицы и графики, хотя пока такие средства поиска разрабатываются только для узких специализированных применений (поиск по структурным химическим формулам, элементам электронных схем и т. д.). В более широком смысле, объектами текста могут являться заголовки или абзацы, примечания, ссылки, названия таблиц и т. п. В некоторых системах применяются свернутые (сигнатурные) образы документов.
Организация данных в БД документальной информации построены на тех же принципах, что и БД фактографических систем. Однако есть и существенные различия, которые обусловлены в первую очередь информационной природой элементов данных:
2. Семантическая природа текстовых полей, представляющих смысл в основном на естественном языке, определяет необходимость учитывать важнейшие свойства используемых терминов: синонимию, полисемию, омонимию, контекстную обусловленность смысла отдельного слова и возможность выразить один смысл многими способами. Вследствие этого поисковые индексы могут быть отличны от соответствующих словоформ поля ( слайд 2 ).
Для рассмотрения особенностей реализации поиска информации важно понимать тот простой факт, что поиск – это процесс, сводящийся к отбору через соотнесение отыскиваемого с объектами, хранящимися в массиве. Причем определяющими для понимания методологической основы автоматизации информационного поиска являются два следующих фактора:
2) сам процесс является сложным (составным, не одноактным) и обычно реализуется последовательностью разнотипных операций.
Первый фактор имеет коммуникативную природу, что предполагает решение на уровне лингвистических средств. Второй – технологическую, предполагающую, что задача реализации процесса поиска сводится к задаче построения структур данных и алгоритмов обработки.
Для задач содержательного (семантического) поиска, реализуемого в дискретной вычислительной среде, такой образец обычно представляется набором атрибутов, отражающих свойства объекта в форме, скорее фактографической, чем аналитической.
Атрибут, как поисковый признак, задается парой и может быть представлен в позиционной или ключевой форме.
Первая аналогична табличному способу представления данных о свойствах некоторого множества объектов: отдельному i -ому атрибуту соответствует i -я колонка, каждая ячейка которой содержит значение этого атрибута, свойственное отдельному объекту. Характерными чертами такого способа являются: 1) атомарность, т. е. отдельный атрибут отдельного объекта имеет строго одно значение; 2) предопределенность набора атрибутов – все существенные атрибуты объектов, информация о которых должна быть внесена в такую форму, должны быть определены на шаге, предшествующем построению таблицы и внесению в неё значений атрибутов.
5.2. Теоретико-множественная модель индексирования и поиска (слайд 4)
С теоретико-множественных позиций описываем и документы или элементы массива. Каждый документ есть множество лексических единиц - слов, дескрипторов (односложных или составных), терминов индексирования, классификационных рубрик (УДК, МПК, ББК и т.д.). Целесообразно ввести понятие универсального словаря D, подмножествами которого являются любые документы.

, для всех k

Далее, является элементом некоторого массива L:

L

L 0
, для всех k, причем
Прообразом Lo могут являться: поисковый массив АИС, отраслевой справочно-информационный фонд, массив библиотеки и т.д.
Представления документа как множества приводит к тому, что с точки зрения потребителя информации каждый документ, загруженный в базу данных, является или множеством терминов или же совокупностью множеств терминов, где могут быть выделены, например:
- множество терминов заголовка;
- множество терминов реферата первоисточника;
- множество дескрипторов индексирования документа.
5.3. Линейное описание информационных массивов (слайд 5)
Линейное представление теоретико-множественного образа документа является дополнительным к теоретико-множественному:


, если i -й термин входит в k -й документ
, в противном случае
Универсальный массив в линейном представлении есть матрица размерности ( - мощность множества ):

L0
Подобные матрицы известны под названием "матрицы термин-документ".
Автоматизированная информационно-поисковая система (АИПС) представляет собой объект, реализующий два типа формализованных процедур:
Модели упомянутых групп процессов представляют собой основной объект нашего дальнейшего изложения; в различных интерпретациях или сочетаниях они позволяют получить комплексное описание многих аспектов информационной деятельности.
5.4. Структурная схема АИПС .
В структурной схеме (Слайд 6) может быть выделен контур документов и контур запросов.
Контур документов включает процессы получения множества документов и преобразования каждого документа в поисковый образ (ПОД).
Контур запросов включает множества запросов. Каждый запрос преобразуется в поисковый образ (ПОЗ) с созданием массива поисковых образов запросов.
Тезаурус есть средство, используемое для индексирования, реализующее отображение D ® D , причем в общем случае тезаурус, применяемый для документов, не совпадает с тезаурусом запросов.
5.5. Критерий смыслового соответствия (КСС)
КСС есть пара (слайд 7):
КСС = b * , k c >
где b * есть мера формальной релевантности, или мера близости (способ исчисления близости) поисковых образов документа и запроса,
k c - пороговое значение меры близости, при превышении которого документ признается формально релевантным соответствующему запросу.
В задачах информационного поиска различают формальную и истинную релевантность.
Формальная релевантность – соответствие документа запросу с точки зрения АИПС.
Истинная релевантность – соответствие документа запросу с точки зрения пользователя.
Данное определение КСС, хотя и не отвечает полностью применяемым в АИПС критериям, тем не менее, позволяет описать такие возможности, как сужение или расширение поискового запроса. Это достигается, соответственно, увеличением или уменьшением порога релевантности k c .
Известны, например, следующие меры формальной релевантности (слайд 8):
- скалярное произведение векторов ПОЗ и ПОД:

- мера Танимото (нормированное скалярное произведение):

- мера косинуса угла векторов ПОЗ и ПОД:


Поиск документов состоит в построении матрицы поискового пространства, где определяется по одному из выражений меры формальной релевантности.

Множество формально релевантных запросу документов составляют такие документы, для которых .
5.6. Логическая структура документальной АИПС.
База данных документальной ИПС IRBIS - это именованная совокупность массива документов и структурированных справочников, обеспечивающих эффективность поиска. Логическая структура БД документальной ИПС IRBIS представлена на слайде 9 .
Документ базы данных как структурированная форма представления информации в общем случае определяется своим уникальным (в массиве документов БД) идентификатором и составом полей.
Поле как часть документа представляет собой однозначно идентифицируемый в информационном массиве фрагмент, для которого определены тип, имя и характер обработки.
Слово как фрагмент поля, выделяемый по некоторым формальным (заданным в схеме представления документа) правилам, является единицей информации в операциях поиска.
Схема базы данных (документа) определяет логическую связь именования, физического размещения и наполнения полей, образующих документ, а также стратегию поиска. Особенностью этой реализации является логическая независимость схемы. Для одной базы данных может быть определено несколько разных схем, причем они в принципе равноправны, и в то же время одна и та же схема может быть использована для определения документов в нескольких БД.
В схеме документ определяется совокупностью описаний отдельных полей, для каждого из которых задается:
- идентификация материала в базе данных, обеспечивающая пользователю доступ средствами документального поиска;
- представление материала при вводе и выводе (формат и длина поля, размещение и оформление материала при отображении и т. д.);
- спецификация стратегии документального поиска (прямое сканирование записей или использование инвертированных поисковых справочников). Для полей, специфицированных как ключевые, т. е. имеющих поисковые справочники, дополнительно определяются правила формирования дескрипторов (заданием списков символов-разделителей слов и списков стоп-слов).
Таким образом, можно сказать, что документальная БД имеет постреляционную модель данных.
5.7. Документо-ориентированная база данных Lotus Domino/Notes
Основой единицей хранения информации в базе данных Lotus Domino/Notes является отдельный документ.
Структура документа Notes, представленная на слайде 10, определяется формой, содержащей в себе набор полей различных типов. Поля данных подразделяются на поля данных документа и поля данных Notes.
Среда Notes изначально проектировалась для работы со слабо структурированной информацией. Это и предопределило структуру базы данных Notes. Отдельный документ не обязательно имеет все те же поля, что и остальные документы, под поле выделяется столько памяти, сколько это необходимо для хранения конкретных данных, поля в документы могут добавляться динамически по мере возникновения в них необходимости или изменений представления разработчиков и пользователей.
База данных Notes может хранить любые типы данных, начиная от простого текста, чисел, времени и даты, до форматированного текста, графических образов, звука, видео и произвольных данных, которые могут храниться в виде присоединенных объектов в своем родном формате.
Полнотекстовый поиск. Lotus Notes поддерживает функцию полнотекстового поиска, которая позволяет пользователям индексировать документы Notes и проводить их поиск по запросам. Notes показывает документы, удовлетворяющие критериям поиска, либо в порядке степени их соответствия критерию, либо в заданном пользователем порядке.
Управление версиями. Lotus Notes содержит функцию управления версиями документа, которая отслеживает многочисленные изменения, вносимые в документ различными пользователями. Автоматическое управление версиями реализовано таким образом, что при каждом сеансе редактирования документ помечается либо как основной, либо как производный от оригинала (ответ). При этом изменения, внесенные в документ Notes одним пользователем, не затираются, когда другой пользователь сохраняет свои изменения в документе. Характер изменений иллюстрируется схемами, представленными на слайдах 12 и 13..
Функция управления версиями Notes является достаточно гибкой, ее можно модифицировать в соответствии с потребностями любой рабочей группы. Кроме того, пользователи имеют возможность добавлять дополнительные комментарии к оригиналу документа, работая с ним как с производным, т. е. не сохраняя оригинал повторно.
5.8. Модель полнотекстовых документов
1. Разнородность может проявляться как на уровне семантики (способов интерпретации величин), так и на структурно-форматном уровне (различных наборов и типов полей, образующих документ).
3. Для реализации разнородных БД может использоваться декларативный или процедурный способ определения структуры документа.
- элемент данных – величина, представляющая в машинной форме логическую (семантически значимую) единицу информации. Обычно представлена в вычислительной среде целостным физическим объектом и идентифицируется именем;
- поле данных – группа (последовательность) элементов данных, объединенных по какому-либо функциональному или семантическому признаку. Обычно представляет логически целостный объект, обеспечивающий полноту передачи контекстно-однородной информации;
- документ – структура, связывающая разнородные поля данных в соответствии с контекстом (или технологией) использования информации. Обеспечивает возможность адекватного восприятия содержания в целом: точность интерпретации значений полей, эффективность восприятия и понимания которых вне системы (обычно, человеком) обусловлена специфицируемой структурой документа - упорядоченной последовательностью соответствующим образом оформленного материала полей (версткой документа).
Такой подход, отражающий в первую очередь семантику использования информации в сфере основной деятельности пользователя, имеет в своей основе логику, подобную логике управления данными: документ является упорядоченной совокупностью элементов данных, которая формируется в соответствии со схемой - определением структуры, задаваемой статически или динамически. Причем, в том случае, когда документальная система реализуется в среде универсальной СУБД (например, реляционной), наибольшая гибкость представления данных достигается при двухуровневой схеме определения структуры документа: поля определяются как композиция элементов данных средствами языка СУБД, а документ - как композиция полей средствами, внешними по отношению к СУБД (это могут быть средства языка программирования прикладной программы или генератора отчетов).
Однако в практике создания документальных БД оптимальность такого подхода далеко не очевидна. Можно выделить несколько критериев оптимизации, практически не связанных друг с другом, например, количество элементов во внутрисистемной и внешних структурах документа, время или иные ресурсы, затраченные на преобразование документа из внешнего во внутрисистемное представление и обратно.
В случае, когда для хранения полнотекстовой информации используются БД, структура документов может быть определена двумя путями [2] :
1) так же, как и для фактографических БД, заданием схемы – последовательности именованных типизированных полей данных;
2) контекстным определением – использованием специализированных языков разметки (например, HTML или XML ), задающим индивидуальные особенности представления материала каждого документа.
[2] Для реляционной СУБД MS SQL Server 2000 реализован импорт/экспорт документов, представленных в XML -формате, в том числе с использованием схем сопоставления, определяющих соотношение элементов XDR -схем таблицам, а атрибутов – столбцам.
В этой статье мы познакомимся с разными типами NoSQL СУБД.
Всего есть 4 основных типа:
Такие базы данных как правило используют хеш-таблицу, в которой находится уникальный ключ и указатель на конкретный объект данных. Существует понятие блока (bucket) — логической группы ключей, которые не группируют данные физически. В разных блоках могут быть идентичные ключи.
Производительность сильно вырастает за счёт кеширующих механизмов, которые работают на основе маппингов. Чтобы прочитать значение, вам нужно знать как ключ, так и блок, поскольку на самом деле ключ является хешем (блок + ключ).
Если поразмыслить о теореме CAP, то становится довольно очевидно, что такие хранилища хороши в плане доступности (Availability) и устойчивости к разделению (Partition tolerance), но явно проигрывают в согласованности данных (Consistency).
Пример: посмотрим на набор данных, представленных таблицей ниже. Здесь ключ — это название страны, а значение — список адресов в этой стране:

База данных такого типа позволяет читать и записывать значения с помощью ключа следующим образом:
- Get(key) возвращает значение, связанное с переданным ключом;
- Put(key, value) связывает значение с ключом;
- Multi-get(key1, key2, . keyN) возвращает список значений, связанных с переданным ключами;
- Delete(key) удаляет запись для ключа из хранилища.
Второй недостаток в том, что при увеличении объёмов данных, поддержание уникальных ключей может стать проблемой. Для её решения необходимо как-то усложнять процесс генерации строк, чтобы они оставались уникальными среди очень большого набора ключей.
Riak и Dynamo от Amazon — самые популярные СУБД данных такого типа.
Документоориентированная база данных
Тот факт, что такие базы данных работают без схемы, делает простой задачей добавление полей в JSON-документы без необходимости сначала заявлять об изменениях.
Couchbase и MongoDB — самые популярные документоориентированные СУБД.
Колоночная база данных
В колоночных NoSQL базах данных данные хранятся в ячейках, сгруппированных в колонки, а не в строки данных. Колонки логически группируются в колоночные семейства. Колоночные семейства могут состоять из практически неограниченного количества колонок, которые могут создаваться во время работы программы или во время определения схемы. Чтение и запись происходит с использованием колонок, а не строк.
В сравнении с хранением данных в строках, как в большинстве реляционных баз данных, преимущества хранения в колонках заключаются в быстром поиске/доступе и агрегации данных. Реляционные базы данных хранят каждую строку как непрерывную запись на диске. Разные строки хранятся в разных местах на диске, в то время как колоночные базы данных хранят все ячейки, относящиеся к колонке, как непрерывную запись, что делает операции поиска/доступа быстрее.
Пример: получение списка заголовков нескольких миллионов статей будет трудоёмкой задачей при использовании реляционных баз данных, так как для извлечения заголовков придётся проходить по каждой записи. А можно получить все заголовки с помощью только одной операции доступа к диску.
- Колоночное семейство — структура, которая может легко группировать колонки и суперколонки;
- Ключ — постоянное имя записи. У ключей может быть разное количество колонок, поэтому база данных может расширяться неравномерно;
- Пространство ключей — определяет самый внешний уровень организации, как правило, имя приложения/базы данных.
- Колонка — имеет упорядоченный список элементов — кортежей с именами и значениями.
Самыми известными примерами являются Google BigTable и HBase с Cassandra, вдохновлённые BigTable.
BigTable представляет собой высокопроизводительное, сжатое и проприетарное хранилище данных от Google. У него есть следующие атрибуты:
- Разреженность — некоторые ячейки могут быть пустыми;
- Распределённость — данные разделены между многими узлами;
- Постоянство — хранится на диске;
- Многомерность — более 1 измерения;
- Сопоставление — ключ и значение;
- Отсортированность — сопоставления обычно не сортируются, но этот случай — исключение.
Двумерная таблица, состоящая из строк и колонок, является частью реляционной системы баз данных.

Эту таблицу можно представить в виде BigTable-сопоставления следующим образом:
На колонки можно ссылаться с помощью колоночного семейства.
Графовая база данных
В графовой базе данных вы не найдёте строгого формата SQL или представления таблиц и колонок, вместо этого используется гибкое графическое представление, которое идеально подходит для решения проблем масштабируемости. Графовые структуры используются вместе с рёбрами, узлами и свойствами, что обеспечивает безиндексную смежность. При использовании графового хранилища данные могут быть легко преобразованы из одной модели в другую.
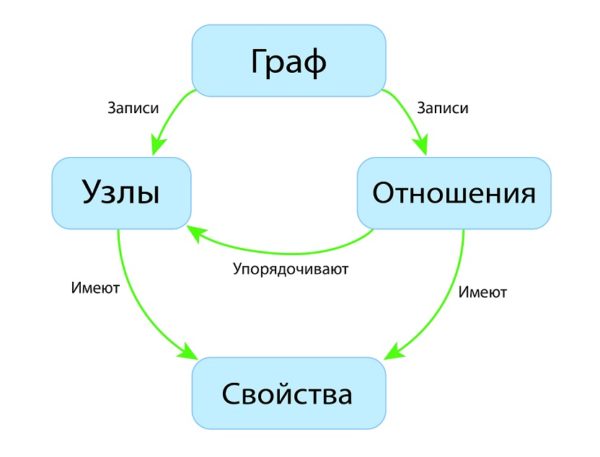
- Такие базы данных используют рёбра и узлы для представления данных.
- Узлы связаны между собой определённым отношениями, представленными рёбрами между ними.
- У узлов и отношений есть некоторые свойства.

Контейнерная иерархия документоориентированной базы данных содержит данные без схемы, которые можно представить в виде дерева, которое является графом. Если обращаться к документам или их элементам в этом дереве, можно получить более выразительное представление данных, в котором можно легко ориентироваться с помощью Neo4j.
Далее описаны некоторые особенности графовой базы данных на основе примера ниже:
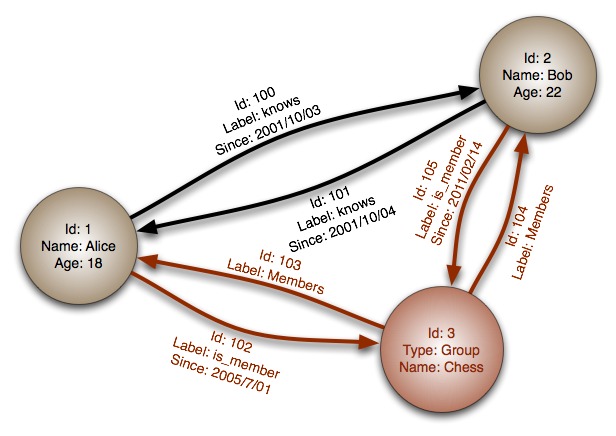
Хотя реляционные базы данных могут скопировать поведение графовых, рёбрам потребуется соединение (JOIN), что дорого обойдётся.
Пример использования
InfoGrid и Infinite Graph — самые популярные графовые базы данных. InfoGrid позволяет соединять множество рёбер (Relationships) и узлов (MeshObjects), что упрощает представление набора информации со сложными взаимными ссылками.
Область применения: достаточно статические структурированные массивы данных, построенные (хотя не обязательно) на основе справочников.
Вид инструмента: система управления данными (CMS) для web приложений.
Реализация: PHP, MySQL.
С точки зрения конечного пользователя, все возможные варианты технической реализации представляется сложным или простым GUI, в котором он может внести тот или иной набор данных. Какой бы GUI не был бы, он ограничен применяемыми элементами ввода данных (контролами): input, select, file, text etc. Этот набор данных описывает документ (запись) и является набором его свойств. Исходя из допустимых вариантов контролов, свойства могут или иметь числовое значение id другого элемента (справочник), или могут описываться текстом.
Поскольку рассмотрение реализации документно-ориентированной БД ведется с точки зрения CMS, то есть еще несколько дополнительных требований: к части данных должен быть быстрый и простой доступ для выполнения быстрого и простого поиска и выполнения наиболее частых сортировок, кроме того должен быть механизм простого управления свойствами документа и ввода данных.
С теоретизированием покончено, поехали.
Таблица первая и главная — хранение самих объектов (документов, записей).
Хранение документов в БД самое простое — каждому новому документу присваивается id, id родительского элемента, текстовое поле для хранения свойств и некоторое количество доп полей о которых позже.
id Название свойства родитель доп_поля
1 Запись_1 xml_свойтва 0 доп_поля
2 Запись_2 xml_свойтва 0 доп_поля
3 Запись_3 xml_свойтва 2 доп_поля
4 Запись_4 xml_свойтва 2 доп_поля
Хранить свойства можно любым способом: от банальных разделителей; и | до json и xml.
Мной был выбран xml по причине простых механизмов работы с ним на PHP и реализации xPath в MySQL
Будем считать, что каждый документ описывается набором свойств заданным в некотором шаблоне — Контент Шаблоне (КШ).
Следующая таблица — таблица описывающая наборы свойств для документов (КШ). В таблице есть текстовое описание шаблона, и подчиненное ему произвольное количество табов, которым в свою очередь может быть подчинено произвольное количество полей.
Название_КШ
Таб_1
поле_1 Текстовое
поле_2 Список
поле_3 Дата
К каждой записи в главной таблице привязывается какой именно КШ с данными к ней относится.
Естественно, что кроме данных необходимо некоторое представление этих данных для пользователя на сайте (не забываем, что мы стоим CMS).
Следующая таблица — таблица описывающая Дизайн Шаблон (ДШ) представления данных из Контент Шаблона. ДШ может быть построен на основе любого шаблонизатора. Мы используем примитивную смесь PHP и HTML.
Теперь давайте вспомним об ограничениях, которые мы наложили и вернемся к дополнительным полям.
Ну, во-первых, в дополнительные поля попадают id относящихся к записи КШ и ДШ. Кроме того, в КШ можно задавать часть полей для хранения не в xml, а непосредственно в таблице БД (типа link1, link2, link3). Этих полей по несколько штук на допустимые в MySQL типы данных — текст, числа, даты.
В дополнительные поля попадают ключевые слова и описания документов, а также информация о правах доступа различных пользователей.
Какие достоинства такого подхода:
простой и гибкий механизм настройки шаблонов вводя данных для неквалифицированного оператора.
получив запись по id одним запросом из БД достается максимальное количество её свойств.
возможность использовать механизм xPath для работы c XML в MySQL.
Какие есть недостатки:
невозможность нативной сортировки по данным, лежащим в XML при хранении в MySQL
медленная выборка по конструкции LIKE ‘%’
Описан принцип, хотя есть полностью реализованная CMS на которой работает рад достаточно крупных проектов.,
Любые данные где-то хранятся. Будь это интернет вещей или пароли в *nix. Показываем схемы основных типов баз данных, чтобы наглядно представить различия между ними.

Типы баз данных, называемых также моделями БД или семействами БД, представляют собой шаблоны и структуры, используемые для организации данных в системе управления базами данных (СУБД). Выбор типа повлияет на то, какие операции сможет выполнять приложение, как будут представлены данные, на функции СУБД для разработки и рантайма.
Начнём с трёх типов БД, которые всё ещё могут встречаться в специализированных средах, но в основном заменены надежными и производительными альтернативами.
1. Простые структуры данных
Первый и простейший способ хранения данных – текстовые файлы. Метод применяется и сегодня для работы с небольшими объёмами информации. Для разделения полей используется специальный символ: запятая или точка с запятой в csv-файлах датасетов, двоеточие или пробел в *nix-подобных системах:
/etc/passwd в *nix системе
- ограничен тип и уровень сложности хранимой информации;
- трудно установить связи между компонентами данных;
- отсутствие функций параллелизма;
- практичны только для систем с небольшими требованиями к чтению и записи;
- используются для хранения конфигурационных данных;
- нет необходимости в стороннем программном обеспечении.
- /etc/passwd и /etc/fstab в *nix-системах
- csv-файлы
2. Иерархические базы данных

Пример построения иерархических связей
3. Сетевые базы данных
Сетевые базы данных расширяют функциональность иерархических: записи могут иметь более одного родителя. А значит, можно моделировать сложные отношения.

Пример связей в сетевой базе данных
- сетевые базы данных представляются не деревом, а общим графом
- ограничены теми же шаблонами доступа, что иерархические БД
4. SQL базы данных
Реляционные базы данных – старейший тип до сих пор широко используемых БД общего назначения. Данные и связи между данными организованы с помощью таблиц. Каждый столбец в таблице имеет имя и тип. Каждая строка представляет отдельную запись или элемент данных в таблице, который содержит значения для каждого из столбцов.

- поле в таблице, называемое внешним ключом, может содержать ссылки на столбцы в других таблицах, что позволяет их соединять;
- высокоорганизованная структура и гибкость делает реляционные БД мощными и адаптируемыми ко различным типам данных;
- для доступа к данным используется язык структурированных запросов (SQL);
- надёжный выбор для многих приложений.

- хранилища обеспечивают быстрый и малозатратный доступ;
- часто хранят данные конфигураций и информацию о состоянии данных, представленных словарями или хэшем;
- нет жёсткой схемы отношения между данными, поэтому в таких БД часто хранят одновременно различные типы данных;
- разработчик отвечает за определение схемы именования ключей и за то, чтобы значение имело соответствующий тип/формат.
6. Документная база данных

- база данных не предписывает опредёленный формат или схему;
- каждый документ может иметь свою внутреннюю структуру;
- документные БД являются хорошим выбором для быстрой разработки;
- в любой момент можно менять свойства данных, не изменяя структуру или сами данные.
7. Графовая база данных
Вместо сопоставления связей с таблицами и внешними ключами, графовые базы данных устанавливают связи, используя узлы, рёбра и свойства.

Графовые базы представляют данные в виде отдельных узлов, которые могут иметь любое количество связанных с ними свойств.
- выглядят аналогично сетевым;
- фокусируются на связях между элементами;
- явно отображает связи между типами данных;
- не требуют пошагового обхода для перемещения между элементами;
- нет ограничений в типах представляемых связей.
8. Колоночные базы данных
Колоночные базы данных (также нереляционные колоночные хранилища или базы данных с широкими столбцами) принадлежат к семейству NoSQL БД, но внешне похож на реляционные БД. Как и реляционные, колоночные БД хранят данные, используя строки и столбцы, но с иной связью между элементами.

- БД удобны при работе с приложениями, требующими высокой производительности;
- данные и метаданные записи доступны по одному идентификатору;
- гарантировано размещение всех данных из строки в одном кластере, что упрощает сегментацию и масштабирование данных.
9. Базы данных временных рядов
Базы данных временны́х рядов созданы для сбора и управления элементами, меняющимися с течением времени. Большинство таких БД организованы в структуры, которые записывают значения для одного элемента. Например, можно создать таблицу для отслеживания температуры процессора. Внутри каждое значение будет состоять из временной метки и показателя температуры. В таблице может быть несколько метрик.

- ориентированы на запись;
- предназначены для обработки постоянного потока входных данных;
- производительность зависит от количества отслеживаемых элементов, интервала опроса между записью новых значений и фактической полезной нагрузки данных.
NewSQL и многомодельные БД являются разными типами баз данных, но решают одну группу проблем, вызванных полярными подходами SQL или NoSQL-стратегии. Почему бы не объединить преимущества обеих групп?
10. NewSQL базы данных
NewSQL базы данных наследуют реляционную структуру и семантику, но построены с использованием более современных, масштабируемых конструкций. Цель – обеспечить большую масштабируемость, нежели реляционные БД, и более высокие гарантии согласованности, чем в NoSQL. Компромисс между согласованностью и доступностью является фундаментальной проблемой распределённых баз данных, описываемой теоремой CAP.
- возможность горизонтального масштабирования;
- высокая доступность;
- большая производительность и репликация;
- небольшой функционал и гибкость;
- немалое потребление ресурсов и необходимость специализированных знаний для работы с базой данных.
11. Многомодельные базы данных
Многомодельные базы данных – базы, объединяющие функциональные возможности нескольких видов БД. Преимущества такого подхода очевидны – одна и та же система может использовать различные представления для разных типов данных.
Совместное размещение данных из нескольких типов БД в одной системе позволяет выполнять новые операции, которые в противном случае были бы затруднены или невозможны. Например, многомодельные базы могут позволить юзерам получить доступ к данным, хранящимся в разных типах БД, и управлять ими в рамках одного запроса, а также поддерживают согласованность данных при выполнении операций, изменяющих информацию сразу в нескольких системах.
- помогают уменьшить нагрузку на СУБД;
- позволяют расширяться до новых моделей по мере изменения потребностей без внесения изменений в базовую инфраструктуру;
- обеспечивают непрерывный доступ и простое распределение данных;
- имеют линейную масштабируемость и просты для разработки.
Заключение
Изменение типов хранимых данных, требования к скорости и производительности привели и к продолжающемуся расширению типов баз данных. При этом каждый из них продолжает быть нужным в своей нише, где взаимосвязи между данными ассоциируются с определенной схемой строения базы данных.
Читайте также: