
Раскодировать сообщение код хемминга
Обновлено: 30.06.2024
Механика Хэмминга (7,4)
В качестве примера кодов Хэмминга мы рассмотрим код Хемминга (7,4). В дополнение к 4 битам данных d1, d2, d3, d4 используются 3 бита четности p1, p2, p3 , которые рассчитываются с использованием следующих уравнений:
Результирующее кодовое слово (данные + биты четности) имеет вид p1 p2 d1 p3 d2 d3 d4 .
Обнаружение ошибки работает следующим образом. Вы пересчитываете биты четности и проверяете, соответствуют ли они принятым битам четности. В следующей таблице вы можете видеть, что каждое разнообразие однобитовой ошибки приводит к различному соответствию битов четности. Следовательно, каждая однобитовая ошибка может быть локализована и исправлена.
пример
Пусть ваши данные будут 1011 . Биты четности есть p1 = 1 + 0 + 1 = 0 , p2 = 1 + 1 + 1 = 1 и p3 = 0 + 1 + 1 = 0 . Объедините данные и биты четности, и вы получите кодовое слово 0110011 .
Скажем, во время передачи или вычисления 6-й бит (= 3-й бит данных) переворачивается. Вы получаете слово 0110001 . Предполагаемые полученные данные есть 1001 . Вы снова вычислить биты четности p1 = 1 + 0 + 1 = 0 , p2 = 1 + 0 + 1 = 0 , p3 = 0 + 0 + 1 = 1 . Соответствует только p1 битам четности кодового слова 0110001 . Поэтому произошла ошибка. Глядя на таблицу выше, говорит нам, что произошла ошибка, d3 и вы можете восстановить исходные данные 1011 .
Вызов:
Напишите функцию или программу, которая получает слово (7 бит), один из битов может быть неправильным, и восстановите исходные данные. Формат ввода (через STDIN, аргумент командной строки, приглашение или аргумент функции) может быть строкой "0110001" , списком или массивом [0, 1, 1, 0, 0, 0, 1] или целым числом в MSB 0b0110001 = 49 . Как описано выше, порядок ввода такой p1 p2 d1 p3 d2 d3 d4 . Вывод (через возвращаемое значение или STDOUT) должен быть в том же формате, но в порядке d1 d2 d3 d4 . Вернуть / вывести только 4 бита данных.
1 Что такое код Хэмминга
Общий вид формулы, по которой определяются виды кодов Хэмминга по соотношению числа информационных символов к проверочным: (2 x − 1, 2 x − x − 1), где x – натуральное число.
Из-за своей простоты, кодирование кодом Хемминга получило широкое распространение. Оно применяется, например, в беспроводной технологии WiFi, в системах хранения данных (RAID-массивах), в некоторых типах микросхем памяти, в схемотехнике и т.д.
Хорошая статья, описывающая принцип работы кода Хэмминга, есть, например, на Хабре.
Напишем кодировщик, который будет получать на вход 11 бит данных, кодировать их и возвращать 15 бит выходной информации. Если на вход пришло больше 11-ти бит данных, генерируется исключение. Если данных меньше 11-ти бит (например, 1 байт – 8 бит), то число дополняется нулями в старших разрядах до 11-ти бит и далее кодируется обычным образом. Возвращает кодер 16 бит (кодовое слово).
Данный кодер легко переписать таким образом, чтобы он работал не с битовыми массивами типа BitArray(), а с байтами: на вход получал 11-разрядное число (от 0 до 0x7FF) и выдавал 2 закодированных байта:
Теперь пора поговорить о декодере. Декодер получает на вход 2 байта закодированных данных и возвращает 11 бит декодированных данных, которые распределены по двум байтам. Если в кодер были переданы 8 бит данных, то нас будет интересовать только первый байт, полученный с декодера.
4 Консольная программа, кодирующая и декодирующая код Хемминга (15, 11)
Для быстрой проверки кодировщика и декодировщика кода Хэмминга (15, 11), используя вышеописанные классы, я написал две программы. Первая – кодер Хэмминга . Вводите 11-разрядное число (от 0 до 0x7FF или 2047), и на выходе получаем 16-разрядное число, представленное в виде двух байтов.

Внешний вид программы кодера кода Хэмминга (15, 11)
Вторая программа – декодер кода Хмминга (15, 11) .

Внешний вид программы декодера кода Хэмминга (15, 11)
Легко убедиться, что если мы внесём битовую ошибку при декодировании, то декодер восстановит исходное закодированное число.
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.
p, blockquote 1,0,0,0,0 -->

p, blockquote 2,0,0,0,0 -->
Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т.к. в любой системе передачи и хранении информации неизбежно возникают ошибки.
p, blockquote 3,0,0,0,0 -->
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.
p, blockquote 4,0,0,0,0 -->

p, blockquote 5,0,0,0,0 -->
Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
p, blockquote 6,0,0,0,0 -->
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
- запрос повторной передачи (Automatic Repeat reQuest, ARQ): с помощью помехоустойчивого кода выполняется только обнаружение ошибок, при их наличии производится запрос на повторную передачу пакета данных;
- прямое исправление ошибок (Forward Error Correction, FEC): производится декодирование помехоустойчивого кода, т. е. исправление ошибок с его помощью.
p, blockquote 8,0,0,0,0 -->
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
p, blockquote 9,0,0,0,0 -->
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
p, blockquote 10,0,0,0,0 -->
Допустим есть 4 символа информации, А, B, С,D, и эту информацию повторяем несколько раз. В процессе передачи информации по каналу связи, где-то возникла ошибка. Есть три пакета (A1B1C1D1|A2B2C2D2|A3B3C3D3), которые должны нести одну и ту же информацию.
p, blockquote 11,0,0,0,0 -->

p, blockquote 12,0,0,0,0 -->
Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
p, blockquote 13,0,0,0,0 -->
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
p, blockquote 14,0,0,0,0 -->
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.д.
p, blockquote 17,0,0,0,0 -->
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
p, blockquote 18,0,0,0,0 -->
p, blockquote 19,0,0,0,0 -->
Контроль чётности
p, blockquote 20,0,0,0,0 -->
Если нечетное количество единиц, добавляем 0.
p, blockquote 21,0,0,0,0 -->
1 0 1 0 0 1 0 0 | 0
p, blockquote 22,0,0,0,0 -->
Если четное количество единиц, добавляем 1.
p, blockquote 23,0,0,0,0 -->
1 1 0 1 0 1 0 0 | 1
p, blockquote 24,0,0,0,0 -->
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
p, blockquote 25,0,0,0,0 -->
1 1 0 0 0 1 0 0 | 1
p, blockquote 26,0,0,0,0 -->
p, blockquote 27,0,0,0,0 -->
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
p, blockquote 28,0,0,0,0 -->
p, blockquote 29,0,0,0,0 -->

p, blockquote 30,0,0,0,0 -->
p, blockquote 31,0,0,0,0 -->
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
p, blockquote 32,0,0,0,0 -->
Рассчитаем скорость кода для:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
p, blockquote 35,0,0,0,0 -->
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
p, blockquote 36,0,0,0,0 -->
Классификация помехоустойчивых кодов
- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
По используемому алфавиту:
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
Блочные коды делятся на
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.
p, blockquote 39,0,0,0,0 -->

p, blockquote 40,0,0,0,0 -->
Смотря на картинку выше, код 1 1 0 0 0 1 0 0 | 1 является систематическим, на вход поступило 8 бит, а на выходе кодера 9 бит, которые в явном виде содержат в себе 8 бит информационных и один проверочный.
p, blockquote 41,0,0,0,0 -->

p, blockquote 42,0,0,0,0 -->
Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.
p, blockquote 43,0,0,0,0 -->

p, blockquote 44,0,0,0,0 -->
Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
p, blockquote 45,0,0,0,0 -->
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:
p, blockquote 46,0,0,0,0 -->

p, blockquote 47,0,0,0,0 -->
Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:
p, blockquote 48,0,0,0,0 -->

p, blockquote 49,0,0,0,0 -->
Расстояние Хэмминга
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух кодовых слов одинаковой длины различны. Если рассматривать два кодовых слова, (пример на картинке ниже, 1 0 1 1 0 0 1 и 1 0 0 1 1 0 1) видно что они отличаются друг от друга на два символа, соответственно расстояние Хэмминга равно 2.
p, blockquote 50,0,0,1,0 -->

p, blockquote 51,0,0,0,0 -->
Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
p, blockquote 52,0,0,0,0 -->
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)
p, blockquote 53,0,0,0,0 -->

p, blockquote 54,0,0,0,0 -->
Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
p, blockquote 56,0,0,0,0 -->
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.
p, blockquote 57,0,0,0,0 -->

p, blockquote 58,0,0,0,0 -->
Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
p, blockquote 59,0,0,0,0 -->
Компромиссы при использовании помехоустойчивых кодов
p, blockquote 60,0,0,0,0 -->

p, blockquote 61,0,0,0,0 -->
- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
p, blockquote 63,0,0,0,0 -->
p, blockquote 64,0,0,0,0 -->
Пример блочного перемежения:
p, blockquote 65,0,0,0,0 -->

p, blockquote 66,0,0,0,0 --> p, blockquote 67,0,0,0,1 -->
На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.
Данный исходный код написан на С++, но переписать его на другой язык могу быстро.
Актуальность алгоритма кода Хемминга
В настоящее время актуальность подобных алгоритмов только увеличивается.
Пусть давно нет перфокарт, но зато передача данных сейчас происходит по многим каналам различной надежности, и, следовательно, вероятность ошибок при передаче также возрастает.
Из теории известно, что коды Хемминга позволяют исправлять одинарные ошибки и фиксировать двойные Таким образом, проведя статистические исследования (задавшись надежностью, как параметром) для определенного канала передачи данных, всегда можно определить оптимальную длину пакета (или слова) кодограммы.
Смысл алгоритма кодирования по Хеммингу
Смысл алгоритма кодирования и декодирования по Хеммингу представляется так:
Исходный текст, который необходимо передать по ненадежному каналу, рубится на куски определенной одинаковой длины (пакеты) и в конец каждого такого пакета помещается избыточная информация (контрольные биты).
Принятую кодограмму, алгоритм декодирования, также анализирует по пакетам Проверяется четность пакета в целом и четность каждой из групп
В этом случае, группой называется комбинация информационных бит (различной длины), причем, обязательно дополненная одним контрольным битом, который как раз и должен обеспечивать четность всей группы.
- Пакеты без ошибок
- Пакеты с одинарной ошибкой (которую автоматически исправит)
- Пакеты с двойной ошибкой (не исправит, но сообщит, что пакет с двойной ошибкой)
Программа, демонстрирующая самокорректирующие возможности
Внимание. При возникновении тройной и более ошибки в пакете, результат декодирования бывает непредсказуемым Поэтому для исключения такого исхода, укорачивая пакет (т.е. выбирая его длину) всегда можно достичь необходимой надежности даже для не очень надежных каналов передачи данных.
В настоящей программе, демонстрирующей кодирование и декодирование любого файла (или любого текста введенного в верхнее окно) пользователь может:
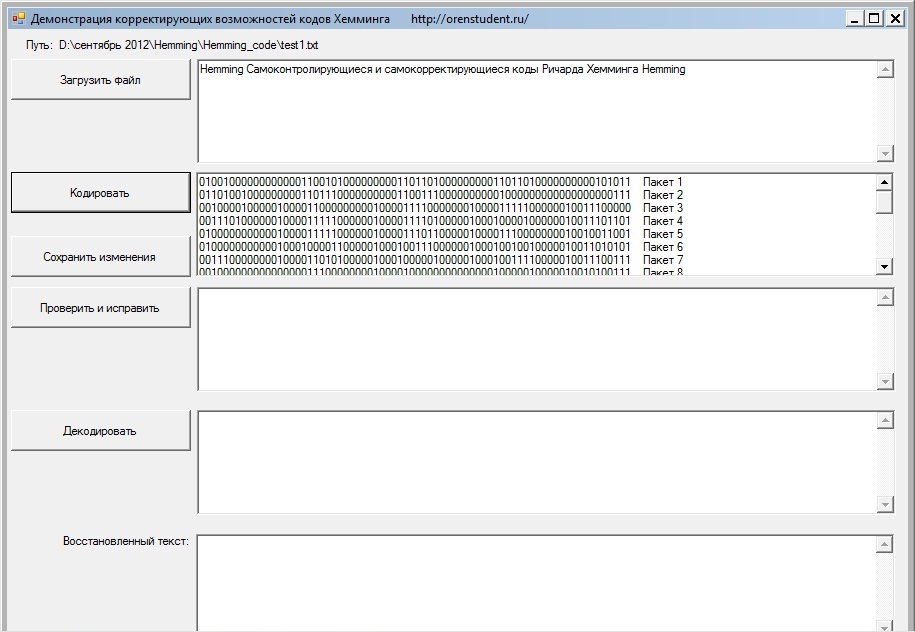
Рис.1 Программа, демонстрирующая самокорректирующие возможности
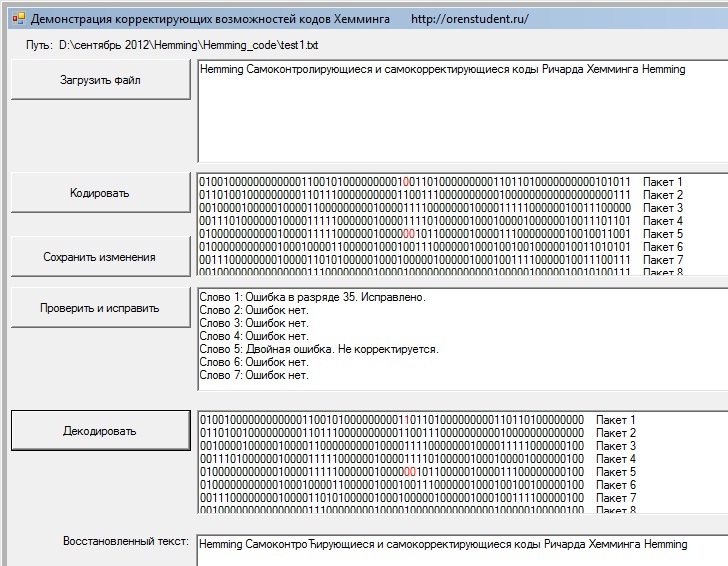
Рис.2 Результат исправления умышленно внесенных ошибок
Матрица для схемы (64, 7)
Весь код достаточно длинен и сложен, поэтому здесь приведу только основные константы и матрицу:
const char m=64; //бит в исходном пакете
const char k=7; //контрольных бит
const char n=m+k+1; //бит в закодированном пакете (72)
unsigned char lenc; //9 байт в закодированном пакете переменная модуля
unsigned char matr[n * (k+1)]=<
//количество единиц в строке матрицы - нечетное
// (т.к. одна в разряде)
0,0,0,0,0,1,1, 1, // 7 - 1
0,0,0,0,1,0,1, 1, // 11 - 2
0,0,0,0,1,1,0, 1, // 13 - 3
0,0,0,0,1,1,1, 0, // 14 - 4
0,0,0,1,0,0,1, 1, // 19 - 5
0,0,0,1,0,1,0, 1, // 21 - 6
0,0,0,1,0,1,1, 0, // 22 - 7
0,0,0,1,1,0,0, 1, // 25 - 8
0,0,0,1,1,0,1, 0, // 26 - 9
0,0,0,1,1,1,0, 0, // 28 - 10
0,0,0,1,1,1,1, 1, // 31 - 11
0,0,1,0,0,0,1, 1, // 35 - 12
0,0,1,0,0,1,0, 1, // 37 - 13
0,0,1,0,0,1,1, 0, // 38 - 14
0,0,1,0,1,0,0, 1, // 41 - 15
0,0,1,0,1,0,1, 0, // 42 - 16
0,0,1,0,1,1,0, 0, // 44 - 17
0,0,1,0,1,1,1, 1, // 47 - 18
0,0,1,1,0,0,0, 1, // 49 - 19
0,0,1,1,0,0,1, 0, // 50 - 20
0,0,1,1,0,1,0, 0, // 52 - 21
0,0,1,1,0,1,1, 1, // 55 - 22
0,0,1,1,1,0,0, 0, // 56 - 23
0,0,1,1,1,0,1, 1, // 59 - 24
0,0,1,1,1,1,0, 1, // 61 - 25
0,0,1,1,1,1,1, 0, // 62 - 26
0,1,0,0,0,0,1, 1, // 67 - 27
0,1,0,0,0,1,0, 1, // 69 - 28
0,1,0,0,0,1,1, 0, // 70 - 29
0,1,0,0,1,0,0, 1, // 73 - 30
0,1,0,0,1,0,1, 0, // 74 - 31
0,1,0,0,1,1,0, 0, // 76 - 32
0,1,0,0,1,1,1, 1, // 79 - 33
0,1,0,1,0,0,0, 1, // 81 - 34
0,1,0,1,0,0,1, 0, // 82 - 35
0,1,0,1,0,1,0, 0, // 84 - 36
0,1,0,1,0,1,1, 1, // 87 - 37
0,1,0,1,1,0,0, 0, // 88 - 38
0,1,0,1,1,0,1, 1, // 91 - 39
0,1,0,1,1,1,0, 1, // 93 - 40
0,1,0,1,1,1,1, 0, // 94 - 41
0,1,1,0,0,0,0, 1, // 97 - 42
0,1,1,0,0,0,1, 0, // 98 - 43
0,1,1,0,0,1,0, 0, // 100 - 44
0,1,1,0,0,1,1, 1, // 103 - 45
0,1,1,0,1,0,0, 0, // 104 - 46
0,1,1,0,1,0,1, 1, // 107 - 47
0,1,1,0,1,1,0, 1, // 109 - 48
0,1,1,0,1,1,1, 0, // 110 - 49
0,1,1,1,0,0,0, 0, // 112 - 50
0,1,1,1,0,0,1, 1, // 115 - 51
0,1,1,1,0,1,0, 1, // 117 - 52
0,1,1,1,0,1,1, 0, // 118 - 53
0,1,1,1,1,0,0, 1, // 121 - 54
0,1,1,1,1,0,1, 0, // 122 - 55
0,1,1,1,1,1,0, 0, // 124 - 56
0,1,1,1,1,1,1, 1, // 127 - 57
1,0,0,0,0,0,1, 1, // 131 - 58
1,0,0,0,0,1,0, 1, // 133 - 59
1,0,0,0,0,1,1, 0, // 134 - 60
1,0,0,0,1,0,0, 1, // 137 - 61
1,0,0,0,1,0,1, 0, // 138 - 62
1,0,0,0,1,1,0, 0, // 140 - 63
1,0,0,0,1,1,1, 1, // 143 - 64
Каждая строка этой матрицы соответствует порядковому номеру бита в пакете Поэтому для кодирования достаточно перемножить вектор-строку исходных бит (длиною 64) на 64 строки данной матрицы На выходе получится вектор-строка из 8 бит (это и есть контрольный байт), который следует прибавить в конец т.е. девятым байтом и длина закодированного пакета станет 72 бита Конечно, есть некоторые тонкости, которые прописаны в коде и благодаря которым, алгоритм работает достаточно стабильно.
При декодировании 72-битная строка перемножается на ту же матрицу и результатом будет являться байт синдромов, анализ битов которого и дает однозначный ответ о наличии ошибок и возможности коррекции
Удачного Вам тестирования!
Работа с файлами
Кнопка "Сохранить файл-код" создаст Вам правильный файл, усиленный избыточной информацией. Кодировка ASCII. Можете ломать…
Только помните, что если Вы внесете изменения более чем в 2 бита на пакет, (а для этого достаточно грубо изменить один символ) то, получите непредсказуемый "результат".
Для наглядности, я (аккуратно) внес единичную ошибку в копию файла testEnglish.cdh и назвал эту поврежденную копию testEnglish_err1.cdh; (символ t заменил на символ u). Файл с двойной ошибкой testEnglish_err2.cdh тоже присутствует в прикрепленном наборе (символ Y заменил на символ X). Программа Lister позволяет эти повреждения видеть…
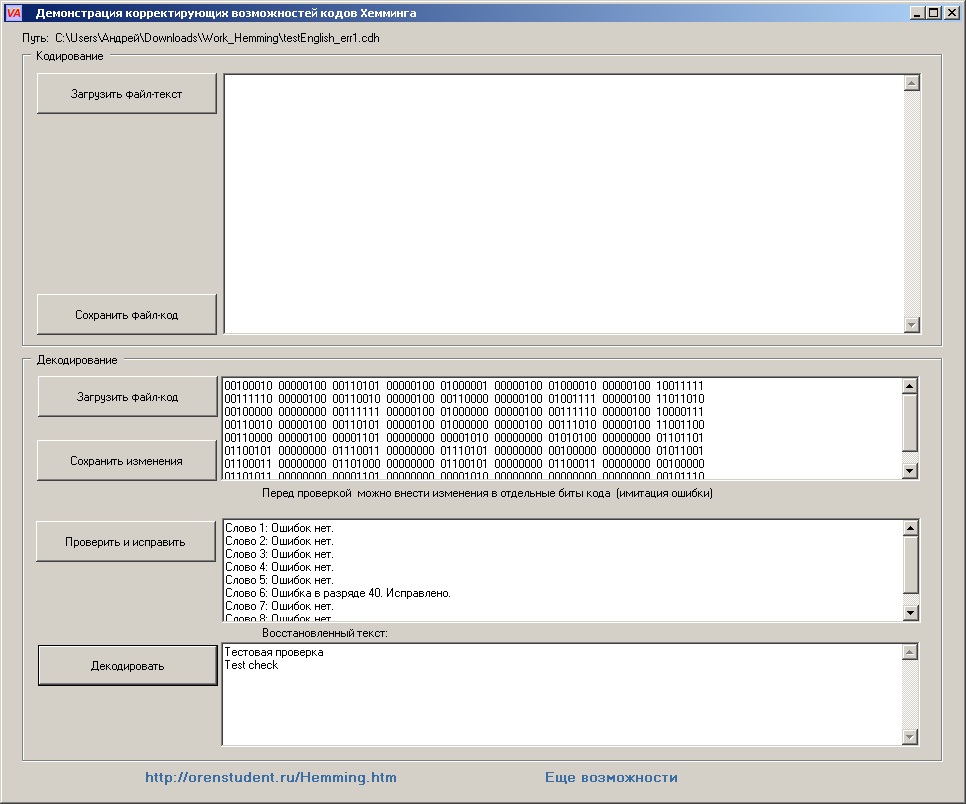
Рис.3 Работа с файлами
Если у Вас остались вопросы, то задать их Вы можете, нажав на эту кнопочку .
Читайте также: