
По некоторому каналу связи передается сообщение состоящее из 0 и 1
Обновлено: 04.07.2024
1) Для кодирования букв А, Б, В, Г решили использовать двухразрядные последовательные двоичные числа (от 00 до 11 соответственно). Если таким способом закодировать последовательность символов ГБАВ и записать результат в шестнадцатеричной системе счисления, то получится:
1) 132 16 2) D2 16 3) 3102 16 4) 2D 16
Решение и ответ:
Из условия соответственно:
А - 00
Б - 01
В - 10
Г - 11
ГБАВ = 11010010 - переведем данную двоичную запись в шестнадцатеричную систему и получим D2
Ответ: 2
2) Для кодирования букв А, Б, В, Г решили использовать двухразрядные последовательные двоичные числа (от 00 до 11 соответственно). Если таким способом закодировать последовательность символов ГБВА и записать результат шестнадцатеричным кодом, то получится:
1) 138 16 2) DBCA 16 3) D8 16 4) 3120 16
Решение и ответ:
По условию:
А = 00
Б = 01
В = 10
Г = 11
Значит:
ГБВА = 11011000 в двоичной системе. Переведем в шестнадцатеричную и получим D8
Ответ: 3
3) Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв - из двух бит, для некоторых - из трех). Эти коды представлены в таблице:
a b c d e
000 110 01 001 10
Определите, какой набор букв закодирован двоичной строкой 1100000100110
1) baade 2) badde 3) bacde 4) bacdb
Решение и ответ:
Первая буква - b, так как стоит двоичный код 110
Вторая буква - a, так как стоит двоичный код 000
Третья буква - с, так как стоит двоичный код 01
Четвертая буква - d, так как стоит двоичный код 001
Пятая буква - e, так как стоит двоичный код 10
Итог: bacde, что соответствует варианту под номером 3.
Ответ: 3
4) Для кодирования букв А, Б, В, Г используются четырехразрядные последовательные двоичные числа от 1000 до 1011 соответственно. Если таким способом закодировать последовательность символов БГАВ и записать результат в восьмеричном коде, то получится:
1) 175423 2) 115612 3) 62577 4) 12376
Решение и ответ:
По условию:
А = 1000
Б = 1001
В = 1010
Г = 1011
БГАВ = 1001101110001010, теперь слудует перевести данное число из двоичной в восьмеричную, и получить ответ.
10011011100010102 = 1156128
Ответ: 2
5)
Для кодирования букв А, В, С, D используются трехразрядные последовательные двоичные числа, начинающиеся с 1 (от 100 до 111 соответственно). Если таким способом закодировать последовательность символов CDAB и записать результат в шестнадцатеричном коде, то получится:
1) А5216 2) 4С816 3) 15D16 4) DE516
Решение и ответ:
По условию: Соответственно
A = 100
B = 101
C = 110
D = 111
СDAB = 110111100101, переведем двоичное число в шестнадцатеричную:
1101111001012 = DE516
Ответ: 4
6) Для кодирования букв К, L, М, N используются четырехразрядные последовательные двоичные числа от 1000 до 1011 соответственно. Если таким способом закодировать последовательность символов KMLN и записать результат в восьмеричном коде, то получится:
1) 846138 2) 1052338 3) 123458 4) 7763258
Решение и ответ:
По условию: соответственно
K = 1000
L = 1001
M = 1010
N = 1011
KMLN = 1000101010011011, переведем в восьмеричное число:
Ответ: 2
7) Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв – из двух бит, для некоторых – из трех). Эти коды представлены в таблице:
а b с d е
100 110 011 01 10
Определите, какой набор букв закодирован двоичной строкой 1000110110110, если известно, что все буквы в последовательности – разные:
1) cbade 2) acdeb 3) acbed 4) bacde
Решение и ответ:
Запишем двоичный код в виде битов: Методом перебора возможных вариантов, чтобы не повторялись буквы.
Получается: 100 011 01 10 110
Следовательно: acdeb
Ответ: 2
8) Для 6 букв латинского алфавита заданы их двоичные коды (для некоторых букв из двух бит, для некоторых – из трех). Эти коды представлены в таблице:
А В С D Е F
00 100 10 011 11 101
Определите, какая последовательность из 6 букв закодирована двоичной строкой 011111000101100.
1) DEFBAC 2) ABDEFC 3) DECAFB 4) EFCABD
Решение и ответ:
Решим методом перебора, так как буквы в ответах не повторяются, значит и коды не должны повторяться:
Получаем:
011 11 10 00 101 100
Соответственно: DECAFB
Ответ: 3
9) Для кодирования букв А, В, С, D используются четырехразрядные последовательные двоичные числа, начинающиеся с 1 (от 1001 до 1100 соответственно). Если таким способом закодировать последовательность символов CADB и записать результат в шестнадцатеричном коде, то получится:
1) AF5216 2) 4CB816 3) F15D16 4) В9СА16
Решение и ответ: соответственно..
A - 1001
B - 1010
C - 1011
D - 1100
Значит: CADB = 1011100111001010, переведем 1011100111001010 из двоичной в шестнадцатеричную:
1011 1001 1100 10102= B9CA 16, что соответствует четвертому варианту.
Ответ: 4
Решение и ответ:
ВГАГБВ = 0100110001111010, переведем в шестнадцатеричную:
0100 1100 0111 10102 = 4C7A16
Ответ: 4
Решение и ответ:
ГАВБВГ = 01100010110100112 - Переведем в шестнадцатеричную систему:
0110 0010 1101 00112 = 62D316
Ответ: 1
двоичный код:
А Б В Г
00 11 010 011
Если таким способом закодировать последовательность символов ГБВАВГ и записать результат в шестнадцатеричном
коде, то получится:
1) 7101316 2) DBCACD16 3) 31A716 4) 7A1316
Решение и ответ:
ГБВАВГ = 01111010000100112 - переведем в шестнадцатеричную.
0111 1010 0001 00112 = 7A1316
Ответ: 4
ГАВБГВ = 01100010110110102, переведем в шестнадцатеричную:
0110 0010 1101 10102 = 62DA16
Ответ: 4
Решение и ответ:
Возьмем первый код:
11 000 001 001 11 10 = BADDBE
Второй код:
11 000 001 10 11 110 = с ошибкой в конце.
Третий код:
11 000 10 01 001 110 = с ошибкой в конце.
Четвертый код:
11 000 000 10 11 110 = с ошибкой в конце.
Ответ: 1
данным кодом. Полученную двоичную последовательность переведите в шестнадцатеричный вид.
1) AD34 2) 43DA 3) 101334 4) CADBCD
Решение и ответ:
ВАГБГВ = 01000011110110102, переведем в шестнадцатеричную систему:
0100 0011 1101 10102 = 43DA16
Ответ: 2
1, 3 и 4 варианты не подходят, являются началом других кодов.
2 вариант - не является началом других кодов.
Ответ: 2
1) 1 2) 11 3) 01 4) 010
Аналогично заданию номер 16.
Ответ: 2
18) Черно-белое растровое изображение кодируется построчно, начиная с левого верхнего угла и заканчивая в правом нижнем углу. При кодировании 1 обозначает черный цвет, а 0 – белый.

Для компактности результат записали в восьмеричной системе счисления. Выберите правильную запись кода.
1) 57414 2) 53414 3) 53412 4) 53012
Решение и ответ:
После кодирования мы получаем данный код:
1010111000010102, переведем данный код в восьмеричную:
101 011 100 001 0102 = 534128
Ответ: 3
данным кодом. Полученную двоичную последовательность переведите в восьмеричный код.
1) DBACACD 2) 75043 3) 7A23 4) 3304043
Решение и ответ: Соответственно:
ГБАВАВГ = 01111010001000112, переведем в восьмеричную систему.
0 111 101 000 100 0112 = 750438, первый нолик не значащий.
Ответ: 2
буквы А, Б и В, которые кодируются следующими кодовыми словами:
A — 11010, Б — 00110, В — 10101.
1) БААx
2) БААВ
3) xxxx
4) xAAx
Решение:
1) 00111 = Б, так как 1 ошибка в последней цифре.
2) 11110 = A, так как 1 ошибка в третьей цифре.
3) 11000 = А, так как 1 ошибка в четвертой цифре.
4) 10111 = В, так как 1 ошибка в четвертой цифре
00111 11110 11000 10111 = БААВ.
Ответ: 2
нули и единицы должны быть как обычные символы или как реально двоичная информация? т. е. char a = 1; или char a = "1"; ?
string str;
string sh;
Предложенный способ по-моему не рационален, поскольку проверочной информации в три раза больше, чем полезной. (хотя может везде так)
Автор, погляди код Хемминга. Имеет недостатки в определении ошибок - определяет ошибки, если их нечетное количество в одном блоке (на сколько я помню).
Идея такая: суммируем три принятых символа. Если результат больше единицы, значит принята единица, иначе ноль. Это при расшифровке. А при шифровании просто трижды повторяем символ, прежде чем перейти к следующему.
Кодирование – это перевод информации, представленной символами первичного алфавита, в последовательность кодов.
Декодирование (операция, обратная кодированию) – перевод кодов в набор символов первичного алфавита.
Кодирование может быть равномерное и неравномерное. При равномерном кодировании каждый символ исходного алфавита заменяется кодом одинаковой длины. При неравномерном кодировании разные символы исходного алфавита могут заменяться кодами разной длины.
Равномерное кодирование всегда однозначно декодируемо.
Для неравномерных кодов существует следующее достаточное (но не необходимое) условие однозначного декодирования:
Кодирование в различных системах счисления
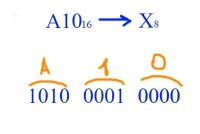
Для кодирования букв О, В, Д, П, А решили использовать двоичное представление
чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления). Если закодировать последовательность букв ВОДОПАД таким способом и результат записать восьмеричным кодом, то получится
Представим коды указанных букв в двоичном коде, добавив незначащий нуль для одноразрядных чисел:
Закодируем последовательность букв: ВОДОПАД — 010010001110010.
Разобьём это представление на тройки справа налево и переведём каждую тройку в восьмеричное число.
010 010 001 110 010 — 22162.
Правильный ответ указан под номером 1.
Для передачи по каналу связи сообщения, состоящего только из символов А, Б, В и Г, используется посимвольное кодирование: А-10, Б-11, В-110, Г-0. Через канал связи передаётся сообщение: ВАГБААГВ. Закодируйте сообщение данным кодом. Полученное двоичное число переведите в шестнадцатеричный вид.
Закодируем последовательность букв: ВАГБААГВ — 1101001110100110. Разобьем это представление на четвёрки справа налево и переведём каждую четверку в шестнадцатеричное число:
1101 0011 1010 01102 = D3A616
Правильный ответ указан под номером 1.
Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв – из двух бит, для некоторых – из трех). Эти коды представлены в таблице:
Определите, какой набор букв закодирован двоичной строкой 1000110110110, если известно, что все буквы в последовательности – разные:
Мы видим, что условия Фано и обратное условие Фано не выполняются, значит код можно раскодировать неоднозначно.
Значит, будем перебирать варианты, пока не получим подходящее слово :
1) 100 011 01 10 110
Первая буква определяется однозначно, её код 100: a.
Пусть вторая буква — с, тогда следующая буква — d, потом — e и b.
Такой вариант удовлетворяет условию, значит, окончательно получили ответ: acdeb.
Для передачи данных по каналу связи используется 5-битовый код. Сообщение содержит только буквы А, Б и В, которые кодируются следующими кодовыми словами: А — 11010, Б — 10111, В — 01101.
Получено сообщение 11000 11101 10001 11111. Декодируйте это сообщение — выберите правильный вариант.
Декодируем каждое слово сообщения. Первое слово: 11000 отличается от буквы А только одной позицией. Второе слово: 11101 отличается от буквы В только одной позицией. Третье слово: 10001 отличается от любой буквы более чем одной позицией. Четвёртое слово: 11111 отличается от буквы Б только одной позицией.
Таким образом, ответ: АВхБ.
Однозначное кодирование
Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=1, Б=01, В=001. Как нужно закодировать букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Видим, что ближайший от корня дерева свободный лист (т.е. код с минимальной длиной) имеет код 000.
Для кодирования некоторой последовательности, состоящей из букв У, Ч, Е, Н, И и К, используется неравномерный двоичный префиксный код. Вот этот код: У — 000, Ч — 001, Е — 010, Н — 100, И — 011, К — 11. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему остался префиксным? Коды остальных букв меняться не должны.
Выберите правильный вариант ответа.
Примечание. Префиксный код — это код, в котором ни одно кодовое слово не является началом другого; такие коды позволяют однозначно декодировать полученную двоичную последовательность.
1) кодовое слово для буквы Е можно сократить до 01
2) кодовое слово для буквы К можно сократить до 1
3) кодовое слово для буквы Н можно сократить до 10
4) это невозможно
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Легко заметить, что если букву Н перенести в вершину 10, она останется листом. Т.е. кодовое слово для буквы Н можно сократить до 10.

Привет! Сегодня узнаем, как решать 4 задание из ЕГЭ по информатике нового формата 2021.
Четвёртое задание из ЕГЭ по информатике раскрывает тему кодирование информации. Одним из центральных приёмов при решении задач подобного типа является построение дерева Фано. Рассмотрим на примерах этот метод.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование
Т.к. код букв должен удовлетворять условию Фано (т.е. однозначно декодироваться), то расположим буквы, которые уже имеют код (A, B, C), на Дереве Фано.
Дерево Фано для двоичного кодирования начинается с двух направлений, которые означают 0(ноль) и 1(единицу) (цифры двоичного кодирования).
От каждого направления можно также рисовать только два направления: 0(ноль) и 1(единицу) и т.д. Для удобства будем рисовать 1(единицу) только вправо, а 0(ноль) только влево.
Получается структура похожая на дерево!
В конце каждой ветки можно располагать букву, которую мы хотим закодировать, но если мы расположили букву, от этой ветки больше нельзя делать новых ответвлений.
.jpg)
Буква C заблокировала левую ветку, поэтому будем работать с правой частью нашего дерева.
Если мы расположим какую-нибудь букву на оставшуюся ветку (100), то эта ветка заблокируется, и нам некуда будет писать остальные 2 буквы. Поэтому продолжаем ветку (100) дальше.
.jpg)
Теперь свободно уже две ветки, а нам нужно закодировать ещё три буквы. Поэтому должны ещё раз продолжить дерево от какой-нибудь ветки.
Но уже видно, что букве F будет правильно присвоить код 1000, т.к. нам в условии сказано, что код буквы F должен соответствовать наименьшему возможному двоичному числу. Как расположить буквы D и E в данной задаче не принципиально.
.jpg)
Ответ: 1000.
Ещё один важный тип задания 4 из ЕГЭ по информатике нового формата 2021.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Коды букв должны удовлетворять условию Фано. Некоторые буквы уже имеют заданные коды (Б, К, Л). Нам нужно, чтобы слово АБСЦИССА имело как можно меньше двоичных знаков. Заметим, что буква C встречается три раза, а буква A два раза, значит, этим буквам стараемся присвоить как можно меньшую длину!
Отметим на дереве Фано уже известные буквы (Б, К, Л).
.jpg)
У нас осталось 4 (четыре) буквы, а свободных веток 3(три), поэтому мы должны продолжить дерево. но какую ветку продолжить ?
Если продолжить линию 1-0, то получится такая картина :
.jpg)
Теперь получились 4(четыре) свободные ветки равной длины (3(трём) двоичным символам). Т.к. ветки равной длины, то не важно на какую ветку какую букву расположим.
Посчитаем общую длину слова АБСЦИССА.
.jpg)
3 + 2 + 3 + 3 + 3 + 3 + 3 + 3 = 23.
Продлим линию 1-1-0 (можно и 0-1-1, не принципиально, т.к. эти ветки имеют одинаковую длину.), то получится:
.jpg)
Из этих же соображений букве А присваиваем код из трёх двоичных символов 0-1-1.
.jpg)
3 + 2 + 2 + 4 + 4 + 2 + 2 + 3 = 22
Длина получилась меньше, чем в первом варианте. Других вариантов нет, поэтому ответ будет 22.
В этой задаче ничего не сказано про условие Фано. Здесь уже все буквы закодированы, осталось написать сам код.
Задача сводится к переводу из двоичной системы в восьмеричную систему. На эту тему был урок на моём сайте.
Ответ: 151646.
На этом всё! Увидимся на следующих занятиях по подготовке к ЕГЭ по информатике.
Системы счисления (Теория)
Стас костюшкин 15-10-2020 в 18:48:52
Этого не знаю. Это просто примерные задачи, которые наиболее часто попадаются в книжках и на сайтах по подготовке к ЕГЭ по информатике.
Калужский Александр 15-10-2020 в 18:57:40
Глеб Цыбрий 15-11-2020 в 10:30:33
Ольга Владимировна Сорокина 05-03-2021 в 12:09:08
Ольга Владимировна Сорокина 05-03-2021 в 12:09:14

Задание 4 № 27263
Буква К повторяется в слове КОКОС 2 раза. Закодируем её кодовым словом 101. Буква О повторяется в слове КОКОС 2 раза. Закодируем её кодовым словом 1100. Букву С закодировать кодовым словом длины 4 нельзя, поскольку не останется кодовых слов для других букв. Значит, букву С закодируем кодовым словом 00110. Тогда ответ — 3 · 2 + 4 · 2 + 5 = 19.
Заметим, что при кодировании буквы К последовательностью 101 и буквы О последовательностью 1100 букву С нельзя закодировать кодовым словом 0011, поскольку при этом не останется ни одной четырехсимвольной последовательности, с которой могли бы начинаться коды для других букв, передаваемых по каналу связи (по условию задачи могут передаваться все заглавные русские буквы).
Задание 4 № 15790
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Следующая буква должна кодироваться как 11, поскольку 10 мы взять не можем. 100 взять не можем из-за Г, значит, следующая буква должна быть закодирована кодом 101. Следующая буква должна кодироваться как 000, поскольку 00 взять не можем, иначе не останется кодовых слов для оставшейся буквы, которые удовлетворяют условию Фано. Значит, последняя буква будет кодироваться как 001. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова МАГИЯ равно 2 + 3 + 3 + 3 + 3 = 14.
Заметим, что после кодирования всех букв, входящих в слово МАГИЯ, должен остаться хотя бы один свободный код для кодирования буквы Р, которая не входит в данное слово, но может передаваться по каналу связи. Проверить наличие свободного кода можно, построив дерево кодов, как показано в задаче 18553.
Если использовать для А - 010, Б - 011, Г -100, И - 00, М - 11, Я - 101, то условие Фано выполняется, а слово МАГИЯ будет выглядеть как 11 010 100 00 101 и тогда количество двоичных знаков будет равно 13, а не 14, как написано в решении.
Задание 4 № 15817
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Следующая буква должна кодироваться как 011, поскольку 01 мы взять не можем, иначе код для буквы А не будет удовлетворять условию Фано. 10 из-за Г взять не можем, тогда следующая буква будет кодироваться как 100. Следующая буква должна кодироваться как 110, поскольку 11 взять не можем, иначе не останется кодовых слов для оставшейся буквы, которые удовлетворяют условию Фано. Значит, последняя буква будет кодироваться как 111. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова МАГИЯ равно
Заметим, что после кодирования всех букв, входящих в слово МАГИЯ, должен остаться хотя бы один свободный код для кодирования буквы Р, которая не входит в данное слово, но может передаваться по каналу связи. Проверить наличие свободного кода можно, построив дерево кодов, как показано в задаче 18553.
Задание 4 № 15915
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Для трёх букв кодовые слова уже известны, осталось подобрать для оставшихся четырёх букв такие кодовые слова, которые обеспечат наименьшее количество двоичных знаков для кодирования слова ГРАММ.
Закодируем букву М кодовым словом 00, поскольку буква М повторяется в слове ГРАММ два раза. Для буквы Г возьмём кодовое слово 110. Кодовое слово 111 взять не можем, поскольку для остальных букв не останется кодовых слов, удовлетворяющих условию Фано. Оставшиеся две буквы закодируем кодовыми словами длины 4.
Таким образом, наименьшее количество двоичных знаков, которые потребуются для кодирования слова ГРАММ, равно 3 + 4 + 3 + 2 + 2 = 14.
Заметим, что после кодирования всех букв, входящих в слово ГРАММ, должен остаться хотя бы один свободный код для кодирования буквы Я, которая не входит в данное слово, но может передаваться по каналу связи. Проверить наличие свободного кода можно, построив дерево кодов, как показано в задаче 18553.
Задание 4 № 17323
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Букву А закодируем кодовым словом 11, поскольку буква А повторяется в слове БАЛАЛАЙКА 4 раза. Букву Л закодируем кодовым словом 011, поскольку буква Л повторяется в слове БАЛАЛАЙКА 2 раза. Буквы Й и В закодируем кодовыми словами 1000 и 1001 соответственно (заметим, что хотя буквы В нет в слове БАЛАЛАЙКА, но эта буква может передаваться по каналу связи, следовательно, для нее должен быть определен код). Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова БАЛАЛАЙКА равно 2 + 2 + 3 + 2 + 3 + 2 + 4 + 3 + 2 = 23.
Задание 4 № 17369
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Букву О закодируем кодовым словом 11, поскольку буква О повторяется в слове ВОДОВОРОТ 4 раза. Букву В закодируем кодовым словом 101, поскольку буква В повторяется в слове ВОДОВОРОТ 2 раза. Букву Т нельзя закодировать словом 000, так как в этом случае невозможно будет закодировать букву А, поэтому букву Т закодируем словом 0000. Тогда наименьшее количество двоичных знаков, которые потребуются для кодирования слова ВОДОВОРОТ равно 3 + 2 + 3 + 2 + 3 + 2 + 3 + 2 + 4 = 24.
Заметим, что после кодирования всех букв, входящих в слово ВОДОВОРОТ, должен остаться хотя бы один свободный код для кодирования буквы А, которая не входит в данное слово, но может передаваться по каналу связи. Проверить наличие свободного кода можно, построив дерево кодов, как показано в задаче 18553.
Задание 4 № 18553
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Буква Е повторяется в слове НЕВЕЗЕНИЕ чаще всего, поэтому закодируем её кодовым словом 11. Буква Н повторяется в слове НЕВЕЗЕНИЕ 2 раза, поэтому закодируем её кодовым словом 100. Букву З закодировать кодовым словом длины 3 нельзя, поскольку не останется кодовых слов для оставшихся букв, которые удовлетворяли бы условию Фано. Поэтому букву З закодируем кодовым словом 0110. Тогда количество двоичных знаков, которые потребуются для кодирования слова НЕВЕЗЕНИЕ равно 4 · 1 + 2 · 5 + 3 · 3 = 23.
Ответ в данной задаче — 23. Тем, у кого получается другой ответ, рекомендуем сделать следующее:
1. Построить дерево возможных кодовых слов (в дальнейшем — кодов), длина которых не превышает 4.
2. Отметить на данном дереве заданные коды для букв А, В, И.
3. Вычеркнуть запрещенные коды, то есть коды, расположенные на ветках дерева, исходящих из отмеченных кодов, а также на ветках, соединяющих отмеченные коды с вершиной дерева.
4. Последовательно отмечать на дереве выбранный код для очередной буквы и вычеркивать коды, которые оказываются запрещенными после выбора данного кода.
После кодирования всех букв, входящих в слово НЕВЕЗЕНИЕ, в дереве кодов должен остаться хотя бы один свободный (не отмеченный и не запрещенный) код. Он необходим, чтобы на его основе построить коды для букв О и Р, которые хотя и не входят в слово НЕВЕЗЕНИЕ, но тоже могут передаваться по каналу связи и, следовательно, должны иметь свои коды. Если такого свободного кода не осталось, то решение является неверным, и необходимо выбрать другой код для последней кодируемой буквы.
Покажем, как могло бы выглядеть решение в этом случае.
Строим дерево кодовых слов, отмечаем коды заданных букв (выделено красным) и вычеркиваем запрещенные коды (выделено серым).
Выбираем для буквы, чаще всего встречающейся в слове (это буква Е, встречается 4 раза) свободный код с наименьшей длиной, отмечаем его (выделено синим) и вычеркиваем запрещенные коды (выделено серым).
Выбираем для следующей буквы, чаще встречающейся в заданном слове (это буква Н, встречается 2 раза) свободный код с наименьшей длиной (выделено синим) и вычеркиваем запрещенные коды (выделено серым).
Пытаемся выбрать код для следующей буквы (это буква З), отмечаем его и вычеркиваем запрещенные коды. В получившемся дереве не осталось ни одного свободного кода, следовательно, наш выбор неправильный.
Тогда для буквы З придется использовать код большей длины.
Если сосчитать суммарную длины кодовых слов все букв, входящих в слово НЕВЕЗЕНИЕ, то получим 23.
Читайте также: