
Kafka получить сообщение из очереди
Обновлено: 05.07.2024
Компоненты системы обмена данными в Kafka
- топик;
- потребитель (consumer);
- издатель (producer).
Каждый из этих компонентов мы подробнее рассмотрим далее.
Топик
Издатель
Потребитель
Освоить Apache Kafka на профессиональном уровне в качестве администратора Big Data кластеров, разработчика распределенных приложений и прочих прикладных областях Data Science вы сможете на практических курсах по Kafka в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
Каждая группа потребителей поддерживает свое смещение по разделам топика. Группа потребителей состоит из consumer’ов, которые взаимодействуют, получая данные из некоторых топиков. Разделы всех топиков делятся между потребителями в группе. Когда прибывают новые члены группы, а старые уходят, разделы перебалансируются, чтобы каждый член группы получил пропорциональную долю разделов. Один из брокеров назначается координатором группы и отвечает за управление членами группы, а также за назначение их разделов.
Координатор каждой группы выбирается из лидеров топика внутренних смещений __consumer_offsets. Обычно идентификатор группы хешируется в один из разделов этого топика, а его лидер выбирается в качестве координатора. Таким образом, управление группами потребителей равномерно делится между всеми брокерами в кластере, позволяя масштабировать количество групп за счет увеличения количества брокеров.
Каждый вызов API фиксации приводит к отправке брокеру запроса фиксации смещения. Используя синхронный API, потребитель блокируется до успешного ответа на этот запрос. Это ожидание может снизить общую пропускную способность, т.к. ожидая возврата, потребитель простаивает вместо обработки записей [1]. Когда диспетчер смещения получает запрос на фиксацию смещения (OffsetCommitRequest), он добавляет запрос в специальный сжатый топик Kafka с названием __consumer_offsets. А менеджер смещения отправит потребителю ответ об успешной фиксации смещения только тогда, когда все реплики топика смещения получат информацию об этом смещении [2].
С конфигурацией retention.ms связаны log.retention.hours, log.retention.minutes, log.retention.ms, которые детализируют время хранения лог-файлов перед их удалением в часах, минутах и миллисекундах соответственно.

Статья подготовлена на основе открытого занятия из видеокурса по Apache Kafka. Авторы — Анатолий Солдатов, Lead Engineer в Авито, и Александр Миронов, Infrastructure Engineer в Stripe. Базовые темы курса доступны на Youtube.
Kafka и классические сервисы очередей
Для первого погружения в технологию сравним Kafka и классические сервисы очередей, такие как RabbitMQ и Amazon SQS.
Системы очередей обычно состоят из трёх базовых компонентов:
В веб-приложениях очереди часто используются для отложенной обработки событий или в качестве временного буфера между другими сервисами, тем самым защищая их от всплесков нагрузки.
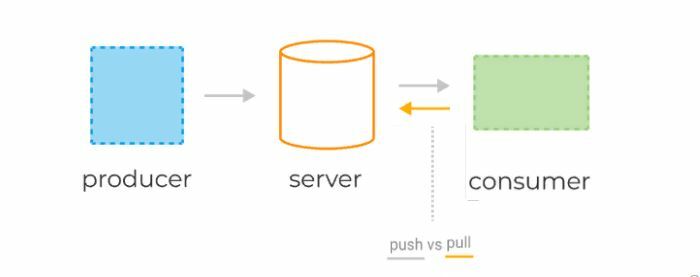
Консьюмеры получают данные с сервера, используя две разные модели запросов: pull или push.
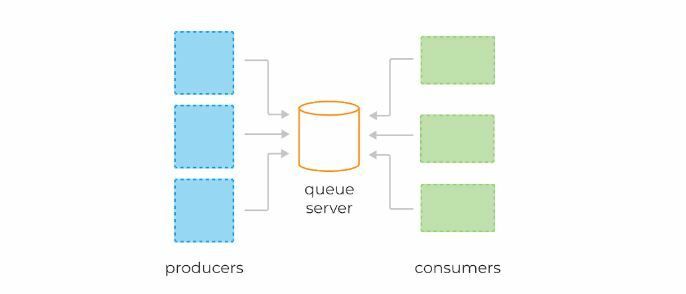
Как правило, приложение пишет и читает из очереди с помощью нескольких инстансов продюсеров и консьюмеров. Это позволяет эффективно распределить нагрузку.
С базовыми принципами работы очередей разобрались, теперь перейдём к Kafka. Рассмотрим её фундаментальные отличия.
Как и сервисы обработки очередей, Kafka условно состоит из трёх компонентов:
Базовые компоненты Kafka
Теперь давайте посмотрим, как Kafka и системы очередей решают одну и ту же задачу. Начнём с системы очередей.
Представим, что есть некий сайт, на котором происходит регистрация пользователя. Для каждой регистрации мы должны:
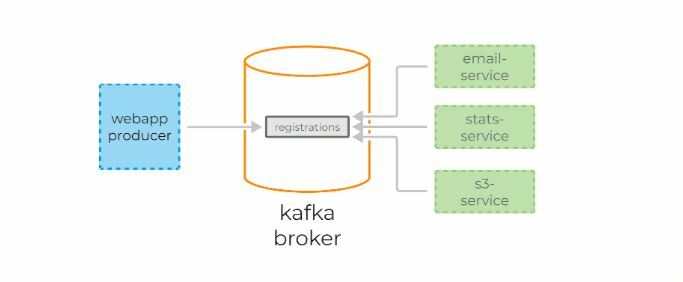
Kafka также позволяет тривиально подключать новые сервисы к стриму регистрации. Например, сервис архивирования всех регистраций в S3 для последующей обработки с помощью Spark или Redshift можно добавить без дополнительного конфигурирования сервера или создания дополнительных очередей.
Кроме того, раз Kafka не удаляет данные после обработки консьюмерами, эти данные могут обрабатываться заново, как бы отматывая время назад сколько угодно раз. Это оказывается невероятно полезно для восстановления после сбоев и, например, верификации кода новых консьюмеров. В случае с RabbitMQ пришлось бы записывать все данные заново, при этом, скорее всего, в отдельную очередь, чтобы не сломать уже имеющихся клиентов.
Структура данных

Consumer Groups
Теперь давайте перейдём к консьюмерам и рассмотрим их принципы работы в Kafka. Каждый консьюмер Kafka обычно является частью какой-нибудь консьюмер-группы.
Важно понять: внутри одной консьюмер-группы партиции назначаются консьюмерам уникально, чтобы избежать повторной обработки.
Если консьюмеры не справляются с текущим объёмом данных, то следует добавить новую партицию в топик. Только после этого консьюмер c4 начнёт свою работу.
Механизм партиционирования является нашим основным инструментом масштабирования Kafka. Группы являются инструментом отказоустойчивости.
Кстати, как вы думаете, что будет, если один из консьюмеров в группе упадёт? Совершенно верно: партиции автоматически распределятся между оставшимися консьюмерами в этой группе.
Добавлять партиции в Kafka можно на лету, без перезапуска клиентов или брокеров. Клиенты автоматически обнаружат новую партицию благодаря встроенному механизму обновления метаданных. Однако, нужно помнить две важные вещи:
Консьюмеры вольны коммитить совершенно любой офсет (валидный, который действительно существует в этой топик-партиции) и могут начинать читать данные с любого офсета, двигаясь вперёд и назад во времени, пропуская участки лога или обрабатывая их заново.
Ключевой для понимания факт: в момент времени может быть только один закоммиченный офсет для топик-партиции в консьюмер-группе. Иными словами, мы не можем закоммитить несколько офсетов для одной и той же топик-партиции, эмулируя каким-то образом выборочный acknowledgment (как это делалось в системах очередей).
Разумеется, консьюмеры, находящиеся в разных группах, могут иметь совершенно разные закоммиченные офсеты для одной и той же топик-партиции.
Apache ZooKeeper
В заключение нужно упомянуть об ещё одном важном компоненте кластера Kafka — Apache ZooKeeper.
ZooKeeper выполняет роль консистентного хранилища метаданных и распределённого сервиса логов. Именно он способен сказать, живы ли ваши брокеры, какой из брокеров является контроллером (то есть брокером, отвечающим за выбор лидеров партиций), и в каком состоянии находятся лидеры партиций и их реплики.
В случае падения брокера именно в ZooKeeper контроллером будет записана информация о новых лидерах партиций. Причём с версии 1.1.0 это будет сделано асинхронно, и это важно с точки зрения скорости восстановления кластера. Самый простой способ превратить данные в тыкву — потеря информации в ZooKeeper. Тогда понять, что и откуда нужно читать, будет очень сложно.
В настоящее время ведутся активные работы по избавлению Kafka от зависимости в виде ZooKeeper, но пока он всё ещё с нами (если интересно, посмотрите на Kafka improvement proposal 500, там подробно расписан план избавления от ZooKeeper).
Важно помнить, что ZooKeeper по факту является ещё одной распределённой системой хранения данных, за которой необходимо следить, поддерживать и обновлять по мере необходимости.
Традиционно ZooKeeper раскатывается отдельно от брокеров Kafka, чтобы разделить границы возможных отказов. Помните, что падение ZooKeeper — это практически падение всего кластера Kafka. К счастью, нагрузка на ZooKeeper при нормальной работе кластера минимальна. Клиенты Kafka никогда не коннектятся к ZooKeeper напрямую.
1. Обеспечьте высокую пропускную способность как для публикации, так и для подписки.
3. Распространено
4. Используйте режим pull для потребительских новостей.
5. Поддержка сетевых и автономных сценариев.
Он также поддерживает автономную обработку данных и обработку данных в реальном времени.
1. Broker
Один или несколько серверов в кластере Kafka вместе именуются брокером.
2. Topic
3. Partition
4. Producer
5. Consumer
6. Consumer Group
Пользователи Mac используют HomeBrew для установки, обновите brew перед установкой
Затем установите кафку
После завершения установки вы можете просмотреть файл конфигурации Kafka.
Расположение kafka, установленного HomeBrew на моем компьютере, - /usr/local/Cellar/kafka/0.11.0.1/bin, вы можете видеть, что версия kafka, установленная HomeBrew, уже 0.11.0.1 Об этом.
Kafka требуется zookeeper. HomeBrew установит zookeeper при установке kafka. Сначала запустите zookeeper:
Тогда запускай кафку
Создайте тему, установите количество разделов на 2 и назовите тему test-topic. В следующих примерах используется эта тема.
Посмотреть созданную тему
Удалить тему
Если delete.topic.enable = true не настроен в server.properties в файле конфигурации, загружаемом при запуске Kafka, то удаление в это время не является настоящим удалением, но тема помечена как: помечена для удаления
Просмотреть все темы
Физически удалить тему
1. Добавьте зависимости в pom-файл проекта maven.
4. Запустите zookeeper.
5. Запустите сервер kafka.
6. Запустите Consumer
7. Запустите "Продюсер"
Конфигурация кластера Kafka обычно бывает трех типов, а именно: брокер с одним узлом и несколькими узлами, брокер с несколькими узлами и несколькими узлами.
single node - single broker
1. Запустите zookeeper.
2. Запустите брокер Kafka.
3. Создайте тему Kafka.
4. Запустите продюсера для отправки информации
single node - multiple broker
1. Запустите zookeeper.
2. Запустите брокера.
Если вам нужно запустить несколько брокеров на одном узле (то есть на одном компьютере) (здесь в качестве примера для запуска трех брокеров), вам необходимо подготовить несколько файлов server.properties, поэтому вам нужно скопировать / usr / local / etc / kafka / server .properties файл. Поскольку вам необходимо указать отдельный файл конфигурации свойств для каждого брокера, три свойства broker.id, port и log.dir должны быть разными.
Создайте новый каталог kafka-example и три каталога для хранения журналов
Скопируйте три копии файла /usr/local/etc/kafka/server.properties
В файле конфигурации server-1.properties брокера 1 необходимо изменить соответствующие параметры:
В файле конфигурации broker2 server-2.properties необходимо изменить соответствующие параметры:
В файле конфигурации broker3 server-3.properties необходимо изменить соответствующие параметры:
Запустить каждого брокера
3. Создать тему
Создайте тему с именем topic-singlenode-multiplebroker.
4. Запустите продюсера для отправки информации
Если производителю необходимо подключиться к нескольким брокерам, вам необходимо передать параметры broker-list
multiple node - multiple broker
В многоузловом кластере с несколькими брокерами каждый узел должен установить Kafka, и все брокеры подключены к одному и тому же zookeeper. Здесь, конечно же, zookeeper можно настроить как кластер. Для конкретных шагов см. То, что я писал ранее.Настроить кластер zookeeper。
1. Конфигурация кластера Kafka
Так как это многоузловой и многоузловой брокер, файл конфигурации server.properties каждого брокера необходимо изменить, как описано выше.
2. Модификация конфигурации производителя.
3. Изменение конфигурации потребителя
Kafka обеспечивает высокую гибкость избыточности данных. Для сценариев, требующих высокой надежности данных, вы можете увеличить количество резервных копий избыточности данных (replication.factor), увеличить количество минимальных реплик записи (min.insync.replicas) и т. Д. Подождите, но это повлияет на производительность. И наоборот, производительность улучшается, а надежность снижается, и пользователям приходится делать выбор между собственными бизнес-характеристиками.
Чтобы обеспечить безопасность и высокую надежность данных, записываемых в Kafka, требуется следующая конфигурация:
1. Конфигурация темы
2. Файл с отображением памяти
Даже если он записывается на жесткий диск последовательно, скорость доступа жесткого диска не может догнать память. Следовательно, данные Kafka не записываются на жесткий диск в реальном времени. Он полностью использует память подкачки современной операционной системы, чтобы использовать память для повышения эффективности ввода-вывода. Файлы с отображением памяти (в дальнейшем именуемые mmap) также переводятся в файлы с отображением памяти, которые обычно могут представлять файлы данных размером 20 ГБ в 64-разрядной операционной системе. Принцип его работы заключается в прямом использовании страницы операционной системы для реализации прямого сопоставления файлов с физической памятью. . После завершения сопоставления операции с физической памятью будут синхронизированы с жестким диском (при необходимости, операционной системой). Через процесс mmap чтение и запись в память точно так же, как чтение и запись на жесткие диски. Не нужно заботиться о размере памяти. Для нас есть виртуальная память. Таким образом может быть получено большое улучшение ввода-вывода, потому что это экономит накладные расходы на копирование из пользовательского пространства в пространство ядра (вызов функции чтения файла сначала поместит данные в память пространства ядра, а затем скопирует их пользователю В памяти места) Но и у этого есть очевидный недостаток - ненадежность, данные, записанные в mmap, на самом деле не записываются на жесткий диск, операционная система будет активно вызывать программу Данные фактически записываются на жесткий диск при промывке. Таким образом, Kafka предоставляет параметр-производитель.type, чтобы контролировать, активен ли сброс. Если Kafka записывает в mmap, он немедленно сбрасывается, а затем возвращается к производителю, называемому синхронизацией (sync); если он возвращается сразу после записи в mmap, производитель не вызывает сброс , Это называется асинхронным (async).
При оптимизации скорости чтения Kafak в основном использует нулевое копирование.
Технология Zero Copy (Zero Copy):
В традиционном режиме мы читаем файл с жесткого диска следующим образом:
(1) Операционная система считывает данные с диска в буфер страницы в пространстве ядра.
(2) Приложение считывает данные из пространства ядра в кеш пользовательского пространства.
(3) Приложение записывает данные в кеш сокета в пространстве ядра.
(4) Операционная система записывает данные из кеша сокетов в кэш сетевой карты, чтобы отправлять данные по сети.
Это явно неэффективно: есть четыре копии и два системных вызова. В этом случае операционная система Unix предоставляет оптимизированный путь для передачи данных из буфера страницы в сокет. В Linux это делается с помощью системного вызова sendfile. Java предоставляет метод для доступа к этому системному вызову: FileChannel.transferTo API. Для этого метода требуется только одна копия: операционная система отправляет данные непосредственно из кэша страниц в сеть. В этом оптимизированном пути требуется только последний шаг для копирования данных в кэш сетевой карты.
Этот метод на самом деле очень распространен. Проблема C10K также имеет подробное описание. Nginx также использует этот метод. Вы можете найти много информации с помощью небольшого поиска.
Читайте также: