
Что произойдет если в упакованном методом rle сообщение пропустить один байт
Обновлено: 03.07.2024
1. Для метода упаковки подсчитайте коэффициент сжатия текста, содержащего только прописные английские буквы, пробелы и знаки препинания (точки, запятая, дефис).
2. Для метода упаковки подсчитайте коэффициент сжатия текста, содержащего прописные и строчные русские буквы, пробелы, цифры и знаки препинания (точки, запятая, дефис).
3. Приведите примеры алгоритмов сжатия с потерей и без потери информации.
5. Какова длина последовательности, после кодирования которой методом RLE получилось следующее:
11111111 11111111 11000000 00000001 00000010 11111111 00000000 ?
6. Как поступить при RLE-кодировании, если количество идущих в ряд одинаковых байтов больше 127 и не помещается в 7 разрядов?
Упаковка информации методом RLE-кодирования состоит в следующем. Упакованная последовательность содержит управляющие байты, за каждым управляющим байтом следует один или несколько байтов данных. Если старший бит управляющего байта равен 1, то следующий за управляющим байт данных при распаковке нужно повторить столько раз, сколько записано в оставшихся 7 битах управляющего байта. Если же старший бит управляющего байта равен 0, то надо взять несколько следующих байтов данных без изменения. Сколько именно – записано в оставшихся 7 битах управляющего байта. Например, управляющий байт 10000111 говорит о том, что следующий за ним байт надо повторить 7 раз, а управляющий байт 00000100 – о том, что следующие за ним 4 байта надо взять без изменений.
После кодирования методом RLE получилась следующая последовательность байтов (первый байт – управляющий):
10000011 10101010 00000010 10101111 11111111 10000101 10101010.
Сколько байт будет содержать данная последовательность после распаковки? Впишите только число.
Ответ: 10 байт
после расшифровки получится последовательность:
10101010
10101010
10101010
10101111
11111111
10101010
10101010
10101010
10101010
10101010
Решение:
10000011 - нужно взять следующий байт (10101010) 3 раза
00000010 - нужно взять 2 следующие байта (10101111 11111111) без изменений
10000101 - нужно взять следующий байт (10101010) 5 раз
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам

Описание презентации по отдельным слайдам:
Тема: Анализ алгоритма построения последовательности. Что нужно знать: - в некоторых задачах (на RLE-кодирование, см. далее) нужно знать, что такое бит и байт, что байт равен 8 бит, что такое старший бит, как переводить числа из двоичной системы в десятичную - в классических задачах (на символьные цепочки) каких-либо особых знаний из курса информатики, кроме умения логически мыслить, не требуется

Пример задания: Упаковка информации методом RLE-кодирования состоит в следующем. Упакованная последовательность содержит управляющие байты, за каждым управляющим байтом следует один или несколько байтов данных. Если старший бит управляющего байта равен 1, то следующий за управляющим байт данных при распаковке нужно повторить столько раз, сколько записано в оставшихся 7 битах управляющего байта. Если же старший бит управляющего байта равен 0, то надо взять несколько следующих байтов данных без изменения. Сколько именно – записано в оставшихся 7 битах управляющего байта. Например, управляющий байт 10000111 говорит о том, что следующий за ним байт надо повторить 7 раз, а управляющий байт 00000100 – о том, что следующие за ним 4 байта надо взять без изменений. После кодирования методом RLE получилась следующая последовательность байтов (первый байт – управляющий): 10000011 10101010 00000010 10101111 11111111 10000101 10101010. Сколько байт будет содержать данная последовательность после распаковки? Впишите в бланк только число.

Решение: обратите внимание, что в этой задаче НЕ нужно распаковывать последовательность, а нужно просто определить ее длину проанализируем первый управляющий байт, 10000011; он начинается с 1 – это команда на повторение следующего символа; количество повторений записано в семи младших битах: 112 = 3 раза; значит, раскодирование первых двух байт дает 3 символа следующий управляющий байт – третий, 00000010; его старший бит 0 говорит о том, что следующие 102 = 2 символа повторяются 1 раз; получаем еще 2 символа следующий управляющий байт – шестой, 10000101; он говорит о том, что следующий за ним символ нужно повторить 1012 =5 раз; получаем еще 5 символов полная длина распакованной последовательности равна 3 + 2 + 5 = 10 символов вот итог нашего анализа: Управляю-щий байты 1-3 Управляю-щий байт 4 байт 5 Управляю-щий байты 6-10 10000011 10101010 00000010 10101111 11111111 10000101 10101010

Упаковка информации методом RLE-кодирования состоит в следующем. Упакованная последовательность содержит управляющие байты, за каждым управляющим байтом следует один или несколько байтов данных. Если старший бит управляющего байта равен 1, то следующий за управляющим байт данных при распаковке нужно повторить столько раз, сколько записано в оставшихся 7 битах управляющего байта. Если же старший бит управляющего байта равен 0, то надо взять несколько следующих байтов данных без изменения. Сколько именно – записано в оставшихся 7 битах управляющего байта. Например, управляющий байт 10000111 говорит о том, что следующий за ним байт надо повторить 7 раз, а управляющий байт 00000100 – о том, что следующие за ним 4 байта надо взять без изменений. После кодирования методом RLE получилась следующая последовательность байтов (первый байт – управляющий): 00000011 10101010 00000010 10101111 10001111 11111111. Сколько байт будет содержать данная последовательность после распаковки? Впишите в бланк только число.

Методы сжатия цифровой информации

Все методы сжатия можно поделить на два больших класса: обратимые необратимые Обратимые алгоритмы только изменяют способ представления входных данных, приводя их к форме, которая более компактно кодируется. Для таких алгоритмов существуют обратные алгоритмы, которые могут точно восстановить исходные данные из сжатого массива.

Обратимые методы можно применять для сжатия любых типов данных. Характерными форматами файлов, хранящих сжатую без потерь информацию, являются: • GIF, TIF, PCX, PNG — для графических данных; • AVI — для чередующихся видео- и звуковых данных; • ZIP, ARJ, RAR, LZH, LH, CAB — для любых типов данных.

Алгоритмы обратимых методов Определение. Метод сжатия называется обратимым если из данных, полученных при сжатии, можно точно. Существует достаточно много обратимых методов сжатия данных, однако в их основе лежит сравнительно небольшое количество теоретических алгоритмов: Метод упаковки Алгоритм Хаффмана Алгоритм RLE Алгоритмы Лемпеля—Зива

Алгоритм RLE В основу алгоритмов RLE (англ. Run-Length Encoding — кодирование путем учета числа повторений) положен принцип выявления повторяющихся последовательностей данных и замены их простой структурой: повторяющимся фрагментом и коэффициентом повторения.

Упаковка информации методом RLE-кодирования состоит в следующем. Упакованная последовательность содержит управляющие байты, за каждым управляющим байтом следует один или несколько байтов данных. Если старший бит управляющего байта равен 1, то следующий за управляющим байт данных при распаковке нужно повторить столько раз, сколько записано в оставшихся 7 битах управляющего байта. Если же старший бит управляющего байта равен 0, то надо взять несколько следующих байтов данных без изменения. Сколько именно – записано в оставшихся 7 битах управляющего байта. Например, управляющий байт 10000111 говорит о том, что следующий за ним байт надо повторить 7 раз, а управляющий байт 00000100 – о том, что следующие за ним 4 байта надо взять без изменений. После кодирования методом RLE получилась следующая последовательность байтов (первый байт – управляющий): 10000011 1010 00000010 10101111 10000101 1010. Сколько байт будет содержать данная последовательность после распаковки? Впишите в бланк только число. Ответ: 10

Упаковка информации методом RLE-кодирования состоит в следующем. Упакованная последовательность содержит управляющие байты, за каждым управляющим байтом следует один или несколько байтов данных. Если старший бит управляющего байта равен 1, то следующий за управляющим байт данных при распаковке нужно повторить столько раз, сколько записано в оставшихся 7 битах управляющего байта. Если же старший бит управляющего байта равен 0, то надо взять несколько следующих байтов данных без изменения. Сколько именно – записано в оставшихся 7 битах управляющего байта. Например, управляющий байт 10000111 говорит о том, что следующий за ним байт надо повторить 7 раз, а управляющий байт 00000100 – о том, что следующие за ним 4 байта надо взять без изменений. После кодирования методом RLE получилась следующая последовательность байтов (первый байт – управляющий): 00000011 1010 00000010 10101111 10001111. Сколько байт будет содержать данная последовательность после распаковки? Впишите в бланк только число. Ответ: 18

Упакуйте методом RLE следующую последовательность байтов: 11111111 111100001111 11000011 10101010 Управляющий байт, начинающийся с 1, указывает, сколько раз нужно повторить следующий за ним байт: 10000101 1111 Управляющий байт, начинающийся с 0, указывает, сколько следующих за ним байт нужно взять без изменений: 00000011 111100001111 11000011 Затем опять: 10000100 1010 Итого: 10000101 1111 00000011 11110000 00001111 11000011 10000100 1010 Получили суммарный выигрыш в 4 байта.

Программные реализации алгоритмов RLE отличаются простотой и высокой скоростью работы, но обеспечивают в среднем невысокое сжатие. Наилучшие объекты для сжатия – графические изображения, в которых большие одноцветные участки. Различные реализации метода RLE используются в графических файлах форматов PCX, BMP, при факсимильной передаче информации. Для текстовых данных методы RLE, как правило, неэффективны.

1. Для метода упаковки подсчитайте коэффициент сжатия текста, содержащего только прописные английские буквы пробелы и знаки препинания (точка, запятая, дефис). Решение: Прописных латинских букв – 26, разделителей - 4. Всего 30 символов. Достаточно 5 бит на символ. Сжатие 8/5 от первоначального объема. 8/5=1, 6. Ответ: коэффициент сжатия 1, 6 2. Для метода упаковки подсчитайте коэффициент сжатия текста, содержащего прописные и строчные русские буквы пробелы, цифры и знаки препинания (точка, запятая, дефис). Решение: 33+33=66 +14 разделителей. Всего 80 символов Достаточно 7 бит на символ. Сжатие 8/7 от первоначального объема. 8/7=1, 14. Ответ: коэффициент сжатия 1, 14

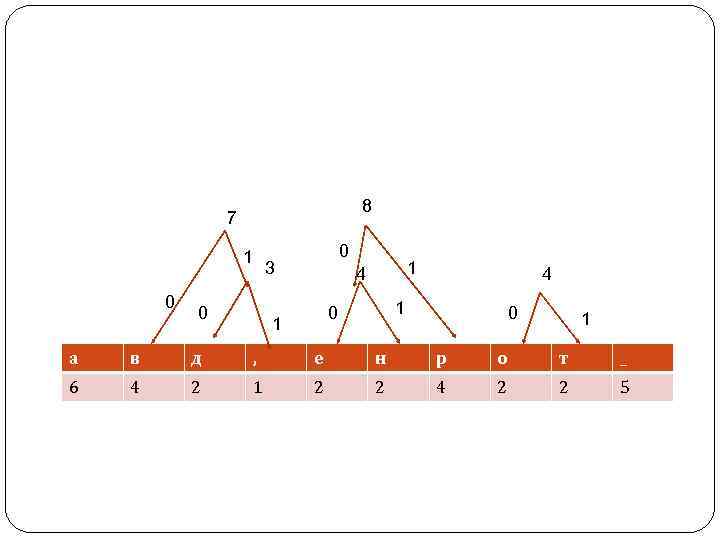
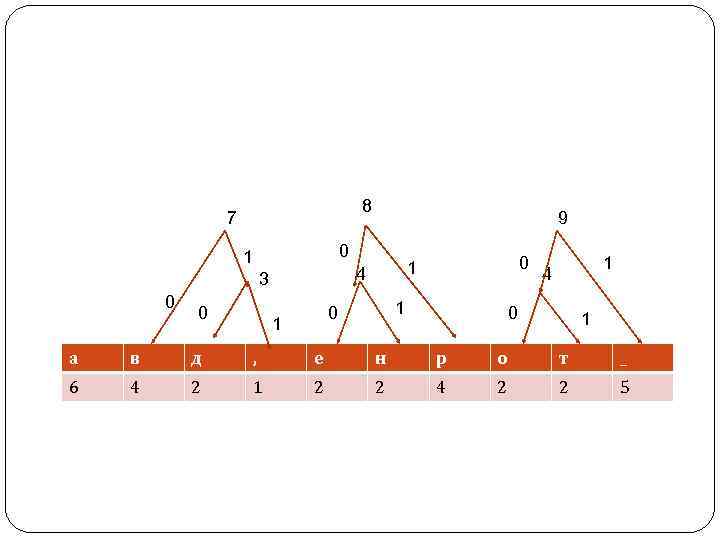
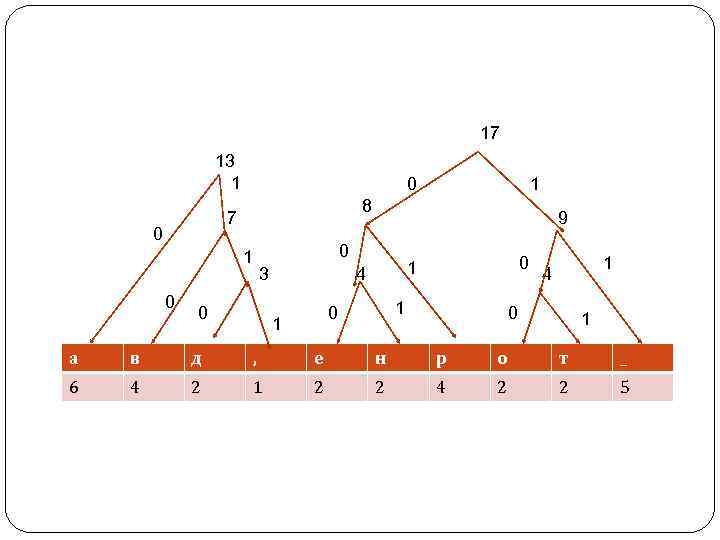
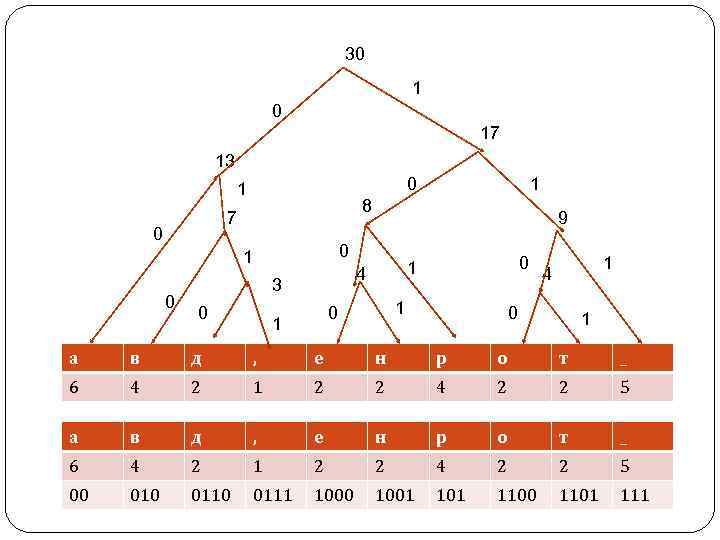
Алгоритм Хаффмана Улучшения степени сжатия можно достичь, кодируя часто встречающиеся символы короткими кодами, а редко встречающиеся — более длинными. Именно такова идея метода, опубликованного Д. Хаффманом (Huffman) в 1952 г. Алгоритм Хаффмана сжимает данные за два прохода: на первом проходе читаются все входные данные и подсчитываются частоты встречаемости всех символов. Затем по этим данным строится дерево кодирования Хаффмана, а по нему — коды символов. После этого, на втором проходе, входные данные читаются еще раз и при этом генерируется выходной массив данных.

После того как коды символов построены, остается сгенерировать сжатый массив данных, для чего надо снова прочесть входные данные и каждый символ заменить на соответствующий код. В нашем случае непосредственно код текста будет занимать 39 бит, или 5 байт. Коэффициент сжатия равен 18/5 = 3, 6. Для восстановления сжатых данных необходимо снова воспользоваться деревом Хаффмана, так код каждого символа представляет собой путь в дереве Хаффмана от вершины до конечного узла дерева, соответствующего данному символу. Код Хаффмана является префиксным. Это означает, что код каждого символа не является началом кода какого -либо другого символа.
8 7 1 0 3 4 1 4 0 1 0 1 1 а в д , е н р о т _ 6 4 2 1 2 4 2 2 5
8 7 9 1 0 1 3 4 0 1 0 1 а в д , е н р о т _ 6 4 2 1 2 4 2 5
17 13 1 0 1 8 7 9 0 1 0 1 3 4 0 1 0 1 1 а в д , е н р о т _ 6 4 2 1 2 4 2 5
30 1 0 17 13 1 0 1 8 7 9 0 1 0 1 4 3 0 1 0 1 1 а в д , е н р о т _ 6 4 2 1 2 4 2 5 00 010 0111 1000 1001 1100 1101 111

коэффициент сжатия при методе упаковки: 10 символов - 4 бита. Весь текст – 120 бит. По алгоритму Хаффмана: 2*6+3*4+4*2+4*1+4*2+3*4+4*2+3* 5=95 бит 120/95=1, 26 коэффициент сжатия по сравнению с кодом ASCII: 30*8=240 бит 240/95=2, 53

Демо 2012 Упражнения из ЕГЭ А 9 Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Использовали код: А-1, Б-000, В— 001, Г-011. Укажите, каким кодовым словом должна быть закодирована буква Д. Длина этого кодового слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования. 1) 00 2) 01 3) 11 4) 010 Ответ: 4) ЕГЭ 2011 А 5 А-01, Б-10, В— 000, Г-001. 1)110 2)11 3)111 4)00 Ответ: 2) ЕГЭ 2010 А 11 А-1, Б-01, В— 001 1)000 2)0001 3)11 4)101 Ответ: 1)

Алгоритмы Лемпеля—Зива LZ 77 и LZ 78 Кодируются не отдельные буквы, как в алгоритме Хаффмана, а слова. Общая схема алгоритма LZ 77 такова (это не точное описание алгоритма): • входные данные читаются последовательно, текущая позиция условно разбивает массив входных данных на прочитанную и непрочитанную части; • для цепочки первых байтов непрочитанной части ищется наиболее длинное совпадение в прочитанной части. Если совпадение найдено, то составляется комбинация , где смещение указывает, на сколько байтов надо сместиться назад от текущей позиции, чтобы найти совпадение, а длина — это длина совпадения; • если запись комбинации короче совпадения, то она записывается в выходной массив, а текущая позиция перемещается вперед (на длину совпадающей части); • если совпадение не обнаружено или оно короче записи комбинации , то в выходной массив копируется текущий байт, текущая позиция перемещается вперед на 1, и анализ повторяется.

Алгоритмы Лемпеля—Зива тем лучше сжимают текст, чем больше размер входного массива. Характерной особенностью обратных алгоритмов LZ 77 и LZ 78 является то, что, кроме самих сжатых данных, никакой дополнительной информации им не требуется. Для сравнения: в алгоритме Хаффмана вместе со сжатыми данными требуется сохранять дерево Хаффмана, иначе распаковка будет невозможна.

Методы сжатия с регулируемой потерей информации Как оказалось, для аудио- и видеоинформации абсолютно точное восстановление необязательно. Проведенные в конце XX века исследования психофизиологических характеристик зрения и слуха обнаружили ряд особенностей человеческого восприятия, использование которых позволяет существенно увеличивать степень сжатия звуковой, графической и видеоинформации.

Например, было установлено, что глаз человека наиболее чувствителен к зеленому цвету, чувствительность к красному ниже примерно в 4 раза, а к синему — почти в 10 раз! А это означает, что на хранение информации о красной и синей составляющих цвета можно было бы отводить меньше бит. Но в большинстве форматов графических файлов это не так — цветовые компоненты кодируются одинаковым количеством бит. Этот пример показывает, что традиционные способы представления видеоинформации обладают очень большой степенью избыточности, при условии, что речь идет о воспроизведении видеоинформации для человека.

Для разработки и стандартизации эффективных методов сжатия аудио- и видеоинформации на рубеже 1980 - 1990 -х годов были созданы Группа экспертов по фотографическим изображениям (Joint Photographic Experts Group, сокр. JPEG) и Группа экспертов по видеоизображениям (Motion Picture Experts Group, сокр. MPEG). К середине 1990 -х годов были разработаны специальные высокоэффективные методы сжатия аудио- и видеоинформации, учитывающие особенности человеческого слуха и зрения. Характерной чертой этих методов является возможность регулируемого удаления маловажной (для человеческого восприятия) информации. Поэтому такие алгоритмы сжатия обобщенно называют алгоритмами с регулируемой потерей информации.

Алгоритмы сжатия с регулируемой потерей информации выделяют во входных данных существенную информацию и ту часть, которой можно пренебречь. За счет удаления части информации удается добиться очень большой степени сжатия данных при субъективно незначительной потере качества аудио- и видеоданных. Алгоритмы с регулируемой потерей информации не универсальны, они не могут использоваться для сжатия любых данных, поскольку полное восстановление исходной информации невозможно. Наиболее известными методами сжатия с регулируемой потерей информации являются: • JPEG — метод сжатия графических данных; • MPEG — группа методов сжатия видеоданных; • МРЗ — метод сжатия звуковых данных.

Алгоритм JPEG используется для сжатия статических изображений. Помимо сжимаемого изображения, алгоритму передается также желаемый коэффициент сжатия — этот параметр регулирует долю информации, которая будет удалена при сжатии. Алгоритм JPEG способен упаковывать графические изображения в несколько десятков раз, при этом потери качества становятся заметными только при очень высоких коэффициентах сжатия.

Алгоритм МРЗ (точное название MPEG-1 Layer 3) является частью стандарта MPEG и описывает сжатие аудиоинформации. Помимо сжимаемого звукового фрагмента алгоритму передается также желаемый битрейт (англ. bitrate) — количество бит, используемых для кодирования одной секунды звука. Этот параметр регулирует долю информации, которая будет удалена при сжатии. Сжатие МРЗ также осуществляется в несколько этапов: звуковой фрагмент разбивается на небольшие участки — фреймы (англ. frames), а в каждом фрейме звук разлагается на составляющие звуковые колебания, которые в физике называют гармониками. С точки зрения математики, звук разлагается на группу синусоидальных колебаний с разными частотами и амплитудами. Затем начинается психоакустическая обработка — удаление маловажной для человеческого восприятия звуковой информации, при этом учитываются различные особенности слуха. Желаемый битрейт определяет, какие эффекты будут учитываться при сжатии, а также количество удаляемой информации. На последнем этапе оставшиеся данные сжимаются алгоритмом Хаффмана. Алгоритм МРЗ позволяет сжимать звуковые файлы в несколько раз. При этом даже самый большой битрейт 320 Кбит/с стандарта МРЗ обеспечивает четырехкратное сжатие аудиоинформации по сравнению с форматом Audio CD, при таком же субъективном качестве звука. Формат МРЗ стал стандартом де-факто для распространения музыкальных файлов через Интернет.

Еще один способ уменьшения кодируемой информации заключается в том, чтобы быстро сменяемые участки изображения кодировать с качеством, которое намного ниже качества статичных участков, — человеческий глаз не успевает рассмотреть их детально. Разновидности формата MPEG отличаются друг от друга по возможностям, качеству воспроизводимого изображения и максимальной степени сжатия: • MPEG-1 — использовался в первых Video CD (VCD-I); • MPEG-2 — используется в DVD и Super Video CD (SVCD, VCD-II); • MJPEG — формат сжатия видео, в котором каждый кадр сжимается по методу JPEG; • MPEG-4 — популярный эффективный формат сжатия видео; • Div. X, Xvi. D — улучшенные модификации формата MPEG-4.
Читайте также: