
Частотный анализ текста сообщение кратко
Обновлено: 04.07.2024
Частотный анализ – это один из методов криптоанализа, основывающийся на предположении о существовании нетривиального статистического распределения отдельных символов и их последовательностей как в открытом тексте, так и шифрованном тексте, которое с точностью до замены символов будет сохраняться в процессе шифрования и дешифрования.
Кратко говоря, частотный анализ предполагает, что частота появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка. При этом в случае моно алфавитного шифрования, если в шифрованном тексте будет символ с аналогичной вероятностью появления, то можно предположить, что он и является указанной зашифрованной буквой. Аналогичные рассуждения применяются к биграммам (двухбуквенным последовательностям), триграммам в случае поли алфавитных шифров.
Метод частотного анализа известен с еще IX-го века и связан и именем Ал-Кинди. Но наиболее известным случаем применения такого анализа является дешифровка египетских иероглифов Ж.-Ф. Шампольоном в 1822 году.
Данный вид анализа основывается на том, что текст состоит из слов, а слова из букв. Количество различных букв в каждом языке ограничено и буквы могут быть просто перечислены. Важными характеристиками текста являются повторяемость букв, пар букв (биграмм) и вообще m-ок (m-грамм), сочетаемость букв друг с другом, чередование гласных и согласных и некоторые другие.
Идея состоит в подсчете чисел вхождений каждой nm возможных m-грамм в достаточно длинных открытых текстах T=t1t2…tl, составленных из букв алфавита . При этом просматриваются подряд идущие m-граммы текста:
t1t2. tm, t2t3. tm+1, . ti-m+1tl-m+2. tl.
Если – число появлений m-граммы ai1ai2. aim в тексте T, а L – общее число подсчитанных m-грамм, то опыт показывает, что при достаточно больших L частоты
для данной m-граммы мало отличаются друг от друга.
В силу этого, относительную частоту считают приближением вероятности P (ai1ai2. aim) появления данной m-граммы в случайно выбранном месте текста (такой подход принят при статистическом определении вероятности).
В представленной ниже таблице приводятся частоты встречаемости букв в русском языке (в процентах):
| Буква алфавита | Показатель частоты встречаемости | Буква алфавита | Показатель частоты встречаемости |
|---|---|---|---|
| А | 0,062 | Р | 0,04 |
| В | 0,038 | Т | 0,053 |
| Д | 0,025 | Ф | 0,002 |
| Ж | 0,007 | Ц | 0,004 |
| И | 0,062 | Ш | 0,006 |
| К | 0,028 | Ъ, Ь | 0,014 |
| М | 0,026 | Э | 0,003 |
| О | 0,09 | Я | 0,018 |
Имеется мнемоническое правило запоминания десяти наиболее частых букв русского алфавита. Эти буквы составляют слово СЕНОВАЛИТР.
Устойчивыми являются также частотные характеристики биграмм, триграмм и четырехграмм осмысленных текстов. Существуют специальные таблицы с указанием частоты биграмм некоторых алфавитов. По результатам исследований с помощью таких таблиц ученые определили наиболее часто встречаемые биграммы и триграммы для русского алфавита:
СТ, НО, ЕН, ТО, НА, ОВ, НИ, РА, ВО, КО, СТО, ЕНО, НОВ, ТОВ, ОВО, ОВА.
Из таблиц биграмм можно также легко извлечь информацию о сочетаемости букв, т.е. о предпочтительных связях букв друг с другом.
| Г | С | Слева | Справа | Г | С | |
|---|---|---|---|---|---|---|
| 3 | 97 | л, д, к, т, в, р, н | А | л, н, с, т, р, в, к, м | 12 | 88 |
| 80 | 20 | я, е, у, и, а, о | Б | о, ы, е, а, р, у | 81 | 19 |
| 68 | 32 | я, т, а, е, и, о | В | о, а, и, ы, с, н, л, р | 60 | 40 |
| 78 | 22 | р, у, а, и, е, о | Г | о, а, р, л, и, в | 69 | 31 |
| 72 | 28 | р, я, у, а, и, е, о | Д | е, а, и, о, н, у, р, в | 68 | 32 |
| 19 | 81 | м, и, л, д, т, р, н | Е | н, т, р, с, л, в, м, и | 12 | 88 |
| 83 | 17 | р, е, и, а, у, о | Ж | е, и, д, а, н | 71 | 29 |
| 89 | 11 | о, е, а, и | З | а, н, в, о, м, д | 51 | 49 |
| 27 | 73 | р, т, м, и, о, л, н | И | с, н, в, и, е, м, к, з | 25 | 75 |
| 55 | 45 | ь, в, е, о, а, и, с | К | о, а, и, р, у, т, л, е | 73 | 27 |
| 77 | 23 | г, в, ы, и, е, о, а | Л | и, е, о, а, ь, я, ю, у | 75 | 25 |
| 80 | 20 | я, ы, а, и, е, о | М | и, е, о, у, а, н, п, ы | 73 | 27 |
| 55 | 45 | д, ь, н, о | Н | о, а, и, е, ы, н, у | 80 | 20 |
| 11 | 89 | р, п, к, в, т, н | О | в, с, т, р, и, д, н, м | 15 | 85 |
| 65 | 35 | в, с, у, а, и, е, о | П | о, р, е, а, у, и, л | 68 | 32 |
| 55 | 45 | и, к, т, а, п, о, е | Р | а, е, о, и, у, я, ы, н | 80 | 20 |
| 69 | 31 | с, т, в, а, е, и, о | С | т, к, о, я, е, ь, с, н | 32 | 68 |
| 57 | 43 | ч, у, и, а, е, о, с | Т | о, а, е, и, ь, в, р, с | 63 | 37 |
| 15 | 85 | п, т, к, д, н, м, р | У | т, п, с, д, н, ю, ж | 16 | 84 |
| 70 | 30 | н, а, е, о, и | Ф | и, е, о, а, е, о, а | 81 | 19 |
| 90 | 10 | у, е, о, а, ы, и | Х | о, и, с, н, в, п, р | 43 | 57 |
| 69 | 31 | е, ю, н, а, и | Ц | и, е, а, ы | 93 | 7 |
| 82 | 18 | е, а, у, и, о | Ч | е, и, т, н | 66 | 34 |
| 67 | 33 | ь, у, ы, е, о, а, и, в | Ш | е, и, н, а, о, л | 68 | 32 |
| 84 | 16 | е, б, а, я, ю | Щ | е, и, а | 97 | 3 |
| 0 | 100 | м, р, т, с, б, в, н | Ы | л, х, е, м, и, в, с, н | 56 | 44 |
| 0 | 100 | н, с, т, л | Ь | н, к, в, п, с, е, о, и | 24 | 76 |
| 14 | 86 | с, ы, м, л, д, т,, р, н | Э | н, т, р, с, к | 0 | 100 |
| 58 | 42 | ь, о, а, и, л, у | Ю | д, т, щ, ц, н, п | 11 | 89 |
| 43 | 57 | о, н, р, л, а, и, с | Я | в, с, т, п, д, к, м, л | 16 | 84 |
Пример: Проведем анализ текста следующего содержания
Привет, Хабр! В этой статье я покажу как сделать частотный анализ современного русского интернет-языка и воспользуюсь им для расшифровки текста. Кому интересно, добро пожаловать под кат!

Частотный анализ русского интернет-языка
В качестве источника, откуда можно взять много текста с современным интернет-языком, была взята социальная сеть Вконтакте, а если быть точнее, то это комментарии к публикациям в различных сообществах данной сети. В качестве сообщества я выбрал реальный футбол. Для парсинга комментариев я воспользовался API Вконтакте:
В результате было получено около 200MB текста. Теперь считаем, какой символ сколько раз встречается:
Полученные результаты можно сравнить с результатами из Википедии и отобразить в виде:
1) сравнительной диаграммы

2) таблицы(слева — данные википедии, справа — мои данные)

Шифрование и дешифрование текста
Далее я выбрал из того же сообщества более развёрнутый комментарий, который найти было не так уж и легко, так как в основном комментарии состоят из 2-4 слов:

дружа слово почти не считается, вар извинилась за неправильное решение, и этого достаточно чтобы сделать вывод и усомниться во многих их решениях, вар вместо того чтобы исключать ошибки делает их, это абсолютно не нормально, народ не такой уже и тупой, не по радио же слушаем транслы а в живую смотрим, по этому я больше чем уверен если бы не было столько пенок для мю они бы подавно в топ не попали, аналогично касается ман с, хотя играют местами захватывающе и красиво
После этого необходимо зашифровать полученный текст с помощью какого-нибудь симметричного алгоритма шифрования. Первое, что приходит на ум — это шифр цезаря, сущность которого заключается в том, чтобы изменить символ на другой с определенным шагом:
жуцйг фосес тсъхл рз фълхгзхфв егу лкелрлогфя кг рзтугелоярсз узызрлз л ахсёс жсфхгхсърс ъхсдю фжзогхя еюесж л цфспрлхяфв ес прсёлш лш узызрлвш егу епзфхс хсёс ъхсдю лфнобъгхя сылднл жзогзх лш ахс гдфсобхрс рз рсупгоярс ргусж рз хгнсм цйз л хцтсм рз тс угжлс йз фоцыгзп хугрфою г е йлецб фпсхулп тс ахспц в дсояыз ъзп цезузр зфол дю рз дюос фхсоянс тзрсн жов пб срл дю тсжгерс е хст рз тстгол гргосёлърс нгфгзхфв пгр ф шсхв лёугбх пзфхгпл кгшегхюегбьз л нугфлес
Затем осталось расшифровать текст с помощью частотного анализа:
двужа лросо мопти не лпитаетлб сав ишсиниралг ша немвасиргное вейение и ютохо долтатопно птоыч лдератг счсод и улокнитглб со кнохиз из вейенибз сав скелто тохо птоыч ильряпатг ойиыьи дерает из юто аылорятно не новкаргно навод не таьоф уже и тумоф не мо вадио же лруйаек тванлрч а с жисуя лкотвик мо ютоку б ыоргйе пек усевен елри ыч не ычро лторгьо меноь дрб кя они ыч модасно с том не момари анарохипно ьалаетлб кан л зотб ихваят келтаки шазсатчсаяэе и ьвалисо
Заключение
Если посмотреть на расшифрованный текст, то можно догадаться, где наш алгоритм ошибся: дерает → делает, вадио → радио, тохо → того, навод → народ. Таким образом, можно расшифровать весь текст, по крайне мере, уловить смысл текста. Также хочу отметить, что данный метод будет эффективный в расшифровке только длинных текстов, которые были зашифрованы симметричными методами шифрования. Полный код доступен на Github .
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам
Тема: Частотный анализ текста.
На начальном этапе (до начала XVI в.) для защиты информации использовались методы кодирования и стеганографии. Большинство из используемых шифров сводились к перестановке или моноалфавитной подстановке.
Этап формальной криптографии (конец XV – начало XX вв.) связан с появлением формализованных и относительно стойких к ручному криптоанализу шифров. Важная роль на этом этапе принадлежит Леону Батисте Альберти, итальянскому архитектору, который одним из первых предложил многоалфавитную подстановку. Данный шифр, состоял в последовательном "сложении" букв исходного текста с ключом (процедуру можно облегчить с помощью специальной таблицы). Его работа "Трактат о шифре" (1466 г.) считается первой научной работой по криптологии.
Научная криптография (1930 – 60-е гг.) обусловлена появлением криптосистем со строгим математическим обоснованием криптостойкости. К началу 30-х гг. окончательно сформировались разделы математики, являющиеся научной основой криптологии: теория вероятностей и математическая статистика, общая алгебра, теория чисел, начали активно развиваться теория алгоритмов, теория информации, кибернетика. Своеобразным водоразделом стала работа Клода Шеннона "Теория связи в секретных системах" (1949), которая подвела научную базу под криптографию и криптоанализ.
Компьютерная криптография (с 1970-х гг.) обязана своим появлением вычислительным средствам с производительностью, достаточной для реализации криптосистем, обеспечивающих при большой скорости шифрования на несколько порядков более высокую криптостойкость, чем "ручные" и "механические" шифры. Первым классом криптосистем стали блочные шифры. В 70-е гг. был разработан американский стандарт шифрования DES (принят в 1978 г.). Один из его авторов, Хорст Фейстель (сотрудник IBM), описал модель блочных шифро. В середине 70-х гг. ХХ столетия появились асимметричные криптосистемы, которые не требовали передачи секретного ключа между сторонами. Асимметричная криптография открыла сразу несколько новых прикладных направлений, в частности системы электронной цифровой подписи (ЭЦП) и электронных денег.
Актуальность работы заключается в том, что каждый метод криптоанализа добавляет новые требования к алгоритмам шифрования. Частотный метод, в котором по распределению символов в шифртексте выдвигаются гипотезы о ключе шифрования, породил требование равномерного распределения символов в шифртексте. Кроме того, принципы частотного анализа сегодня широко применяются в программах по поиску паролей, фильтрации текстов в поисковых системах, в алгоритмах сжатия информации Целью данной работы является вскрытие текста, зашифрованного шифром моноалфавитной подстановки, без знания ключа.
Для достижения цели необходимо решить следующие задачи:
• Сбор и анализ научной информации о применении частотного анализа для вскрытия шифров моноалфавитной подстановки.
• Определение частотных характеристик криптограмм.
• Применение полученных данных для вскрытия криптограмм.
• Сделать вывод о возможностях применения частотного анализа при дешифровке текстов моноалфавитной подстановки и рассмотреть область применения данного метода в других областях.
При написании работы использовались следующие методы:
• Эмпирический – наблюдение, сравнение.
• Теоретический – обобщение результатов, их анализ и выводы.
Частотный анализ, частотный криптоанализ — один из методов криптоанализа, основывающийся на предположении о существовании нетривиального статистического распределения отдельных символов и их последовательностей как в открытом тексте, так и в шифротексте, которое, с точностью до замены символов, будет сохраняться в процессе шифрования и дешифрования.
Упрощённо, частотный анализ предполагает, что частота появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка. При этом в случае моноалфавитного шифрования если в шифротексте будет символ с аналогичной вероятностью появления, то можно предположить, что он и является указанной зашифрованной буквой. Аналогичные рассуждения применяются к биграммам (двубуквенным последовательностям), триграммам и т.д. в случае полиалфавитных шифров.
Начиная с середины XX века большинство используемых алгоритмов шифрования разрабатываются устойчивыми к частотному криптоанализу.
Описание частотного криптоанализа
Как упоминалось выше, важными характеристиками текста являются повторяемость букв (количество различных букв в каждом языке ограничено), пар букв, то есть m (m-грамм), сочетаемость букв друг с другом, чередование гласных и согласных и некоторые другие особенности. Примечательно, что эти характеристики являются достаточно устойчивыми.
Идея состоит в подсчете чисел вхождений каждой nm возможных m-грамм в достаточно длинных открытых текстах T=t1t2…tl, составленных из букв алфавита . При этом просматриваются подряд идущие m-граммы текста:
t1t2…tm, t2t3… tm+1, …, ti-m+1tl-m+2…tl.
Если L (ai1ai2 … aim) — число появлений m-граммы ai1ai2…aim в тексте T, а L — общее число подсчитанных m-грамм, то при достаточно больших L частоты L (ai1ai2… aim)/ L, для данной m-граммы мало отличаются друг от друга.
В силу этого, относительную частоту считают приближением вероятности P (ai1ai2…aim) появления данной m-граммы в случайно выбранном месте текста (такой подход принят при статистическом определении вероятности).
В общем смысле частоту букв в процентном выражении можно определить следующим образом: подсчитывается сколько раз она встречается в шифро-тексте, затем полученное число делится на общее число символов шифро-текста; для выражения в процентном выражении, еще умножается на 100.
Но существует некоторая разница значений частот, которая объясняется тем, что частоты существенно зависят не только от длины текста, но и от характера текста. Например, текст может быть технического содержания, где редкая буква Ф может стать довольно частой. Поэтому для надежного определения средней частоты букв желательно иметь набор различных текстов.
В таблице 1 приведены относительные частоты появления русских букв. [1]

· перебор, оптимизированный по словарям вероятных паролей;
· перебор, оптимизированный на основе встречаемости символов и биграмм;
· перебор, ориентированный на информацию о подсистеме аутентификации ОС. Если ключевая система ОС допускает существование эквивалентных паролей, при переборе из каждого класса эквивалентности опробуется всего один пароль;
· перебор с использованием знаний о пользователе. Как правило, опробуются пароли, использование которых представляется наиболее вероятным.
Если программа перебора вначале подбирает наиболее вероятные пароли, а менее вероятные оставляет на потом, то перебор сокращается в десятки и сотни раз. В таблице 2 приводится ряд результатов, полученных при подборе пароля. [3] Числа, указанные в первой колонке таблицы 2, соответствуют сложности полного перебора. Однако применялся оптимизированные перебор, а в первом случае пароль представлял собой два английских слова, записанных без пробела. Таким образом, время перебора сократилось во много раз. Во втором же случае пароль состоял из трех строчных английских букв, двух заглавных английских букв и одной цифры и был абсолютно бессмысленным.
В данной статье мы начнем обсуждение чрезвычайно интересной темы - применение статистики для анализа текстовой информации. Заметим, что применение статистики для анализа текстов – традиционная задача.
Вначале мы приведем некоторые интересные факты относительно частоты встречаемости букв и их сочетаний в разных языках (подробнее см. например, недавно вышедшую интересную книгу [1]). В последующих статьях покажем, как применять более сложные методы анализа и графического представления.
Итак, текст состоит из слов, слова из букв. Количество различных букв в каждом языке ограничено и буквы могут быть просто перечислены. Важными характеристиками текста являются повторяемость букв, пар букв (биграмм) и вообще m-ок (m-грамм), сочетаемость букв друг с другом, чередование гласных и согласных и некоторые другие. Замечательно, что эти характеристики являются достаточно устойчивыми. Вопрос "почему" мы оставляем за кадром.
Используя систему STATISTICA Вы можете проверить эти закономерности, например, в текстах Интернет.
Идея состоит в подсчете чисел вхождений каждой n m возможных m-грамм в достаточно длинных открытых текстах T=t1t2…tl, составленных из букв алфавита a1, a2, . an>. При этом просматриваются подряд идущие m-граммы текста:
Если – число появлений m-граммы ai1ai2. aim в тексте T, а L – общее число подсчитанных m-грамм, то опыт показывает, что при достаточно больших L частоты
для данной m-граммы мало отличаются друг от друга.
В силу этого, относительную частоту (1) считают приближением вероятности P (ai1ai2. aim) появления данной m-граммы в случайно выбранном месте текста (такой подход принят при статистическом определении вероятности).
Ниже приводится таблицы частот букв (в процентах) ряда европейских языков. Данные заимствованы из книги [Bau39].
| Буква алфавита | Французский язык | Немецкий язык | Английский язык | Испанский язык | Итальянский язык |
| A | 7.68 | 5.52 | 7.96 | 12.90 | 11.12 |
| B | 0.80 | 1.56 | 1.60 | 1.03 | 1.07 |
| C | 3.32 | 2.94 | 2.84 | 4.42 | 4.11 |
| D | 3.60 | 4.91 | 4.01 | 4.67 | 3.54 |
| E | 17.76 | 19.18 | 12.86 | 14.15 | 11.63 |
| F | 1.06 | 1.96 | 2.62 | 0.70 | 1.15 |
| G | 1.10 | 3.60 | 1.99 | 1.00 | 1.73 |
| H | 0.64 | 5.02 | 5.39 | 0.91 | 0.83 |
| I | 7.23 | 8.21 | 7.77 | 7.01 | 12.04 |
| J | 0.19 | 0.16 | 0.16 | 0.24 | - |
| K | - | 1.33 | 0.41 | - | - |
| L | 5.89 | 3.48 | 3.51 | 5.52 | 5.95 |
| M | 2.72 | 1.69 | 2.43 | 2.55 | 2.65 |
| N | 7.61 | 10.20 | 7.51 | 6.20 | 7.68 |
| O | 5.34 | 2.14 | 6.62 | 8.84 | 8.92 |
| P | 3.24 | 0.54 | 1.81 | 3.26 | 2.66 |
| Q | 1.34 | 0.01 | 0.17 | 1.55 | 0.48 |
| R | 6.81 | 7.01 | 6.83 | 6.95 | 6.56 |
| S | 8.23 | 7.07 | 6.62 | 7.64 | 4.81 |
| T | 7.30 | 5.86 | 9.72 | 4.36 | 7.07 |
| U | 6.05 | 4.22 | 2.48 | 4.00 | 3.09 |
| V | 1.27 | 0.84 | 1.15 | 0.67 | 1.67 |
| W | - | 1.38 | 1.80 | - | - |
| X | 0.54 | - | 0.17 | 0.07 | - |
| Y | 0.21 | - | 1.52 | 1.05 | - |
| Z | 0.07 | 1.17 | 0.05 | 0.31 | 1.24 |
Некоторая разница значений частот в приводимых в различных источниках таблицах объясняется тем, что частоты существенно зависят не только от длины текста, но и от его характера. Например, в технических текстах редкая буква Ф может стать довольно частой в связи с частым использованием таких слов, как функция, дифференциал, диффузия, коэффициент и т.п.
Еще большие отклонения от нормы в частоте употребления отдельных букв наблюдаются в некоторых художественных произведениях, особенно в стихах. Поэтому для надежного определения средней частоты букв желательно иметь набор различных текстов, заимствованных из различных источников. Вместе с тем, как правило, подобные отклонения незначительны, и в первом приближении ими можно пренебречь.
Наглядное представление о частотах букв дает диаграмма встречаемости. Так, для ангийского языка, в соответствии с таблицей, такая диаграмма изображена на рис.1. Для ее построения мы импользовали систему STATISTICA.
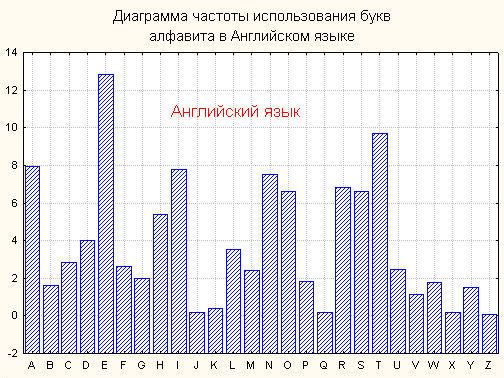
Для русского языка частоты (в порядке убывания) знаков алфавита, в котором отождествлены E c Ё, Ь с Ъ, а также имеется знак пробела (-) между словами, приведены в следующей таблице (см. [Ягл.73]).
| - 0.175 | О 0.090 | Е, Ё 0.072 | А 0.062 |
| И 0.062 | Т 0.053 | Н 0.053 | С 0.045 |
| Р 0.040 | В 0.038 | Л 0.035 | К 0.028 |
| М 0.026 | Д 0.025 | П 0.023 | У 0.021 |
| Я 0.018 | Ы 0.016 | З 0.016 | Ь, Ъ 0.014 |
| Б 0.014 | Г 0.013 | Ч 0.012 | Й 0.010 |
| Х 0.009 | Ж 0.007 | Ю 0.006 | Ш 0.006 |
| Ц 0.004 | Щ 0.003 | Э 0.003 | Ф 0.002 |
На основании таблицы получаем следующую диаграмму частот (рис.2).
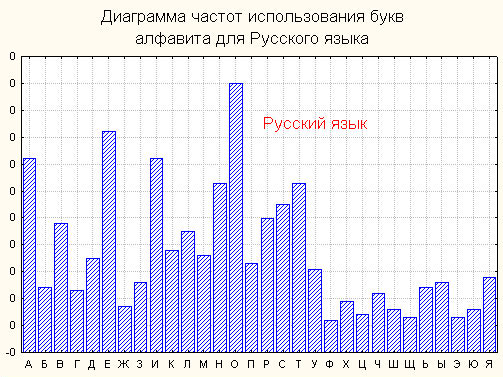
Имеется мнемоническое правило запоминания десяти наиболее частых букв русского алфавита. Эти буквы составляют нелепое слово СЕНОВАЛИТР. Можно также предложить аналогичный способ запоминания частых букв английского языка, например с помощью слова TETRIS-HONDA (см. таблицу).
| Французский язык | E, S, A, N, T, I, R, U, L, O | 79.9% |
| Немецкий язык | E, N, I, S, T, A, H, D, U | 77.2% |
| Английский язык | E, T, A, I, N, R, O, S, H, D | 75.3% |
| Испанский язык | E, A, O, S, I, R, N, L, D, C | 78.3% |
| Итальянский язык | I, E, A, O, N, T, R, L, S, T | 79.9% |
Устойчивыми являются также частотные характеристики биграмм, триграмм и четырехграмм осмысленных текстов.
Приведем таблицы частот биграмм для русского и английского языков (таблицы заимствованы из книги [Fri85]). Для удобства они разбиты на четыре части по следующей схеме:
| Часть1 | Часть2 |
| Часть3 | Часть4 |
| Часть1 | |||||||||||||||
| А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| А | |||||||||||||||
| Б | |||||||||||||||
| В | |||||||||||||||
| Г | |||||||||||||||
| Д | |||||||||||||||
| Е | |||||||||||||||
| Ж | |||||||||||||||
| З | |||||||||||||||
| И | |||||||||||||||
| Й | |||||||||||||||
| К | |||||||||||||||
| Л | |||||||||||||||
| М | |||||||||||||||
| Н | |||||||||||||||
| О | |||||||||||||||
| П |
| Часть2 | ||||||||||||||
| Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ы | Ь | Э | Ю | Я |
| А | ||||||||||||||
| Б | ||||||||||||||
| В | ||||||||||||||
| Г | ||||||||||||||
| Д | ||||||||||||||
| Е | ||||||||||||||
| Ж | ||||||||||||||
| З | ||||||||||||||
| И | ||||||||||||||
| Й | ||||||||||||||
| К | ||||||||||||||
| Л | ||||||||||||||
| М | ||||||||||||||
| Н | ||||||||||||||
| О | ||||||||||||||
| П |
| Часть3 | |||||||||||||||
| А | Б | В | Г | Д | Е | Ж | З | И | Й | К | Л | М | Н | О | П |
| Р | |||||||||||||||
| С | |||||||||||||||
| Т | |||||||||||||||
| У | |||||||||||||||
| Ф | |||||||||||||||
| Х | |||||||||||||||
| Ц | |||||||||||||||
| Ч | |||||||||||||||
| Ш | |||||||||||||||
| Щ | |||||||||||||||
| Ы | |||||||||||||||
| Ь | |||||||||||||||
| Э | |||||||||||||||
| Ю | |||||||||||||||
| Я |
| Часть4 | ||||||||||||||
| Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ы | Ь | Э | Ю | Я |
| Р | ||||||||||||||
| С | ||||||||||||||
| Т | ||||||||||||||
| У | ||||||||||||||
| Ф | ||||||||||||||
| Х | ||||||||||||||
| Ц | ||||||||||||||
| Ч | ||||||||||||||
| Ш | ||||||||||||||
| Щ | ||||||||||||||
| Ы | ||||||||||||||
| Ь | ||||||||||||||
| Э | ||||||||||||||
| Ю | ||||||||||||||
| Я |
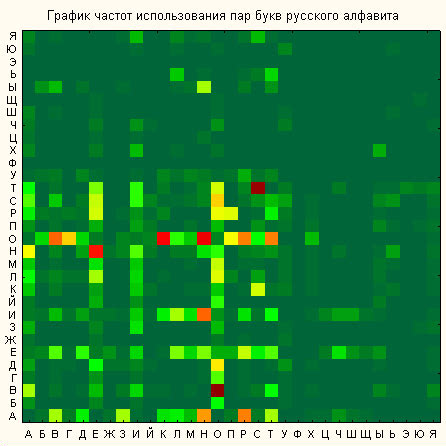
Хорошие таблицы k-грамм легко получить, используя тексты электронных версий многих книг, содержащихся на CD-дисках.
Для получения более точных сведений об открытых текстах можно строить и анализировать таблицы k-грамм при k>2, однако для учебных целей вполне достаточно ограничиться биграммами. Неравномерность k-грамм (и даже слов) тесно связана с характерной особенностью открытого текста – наличием в нем большого числа повторений отдельных фрагментов текста: корней, окончаний, суффиксов, слов и фраз. Так, для русского языка такими привычными фрагментами являются наиболее частые биграммы и триграммы:
СТ, НО, ЕН, ТО, НА, ОВ, НИ, РА, ВО, КО
СТО, ЕНО, НОВ, ТОВ, ОВО, ОВА
Полезной является информация о сочетаемости букв, то есть о предпочтительных связях букв друг с другом, которую легко извлечь из таблиц частот биграмм.
Имеется в виду таблица, в которой слева и справа от каждой буквы расположены наиболее предпочтительные "соседи" (в порядке убывания частоты соответствующих биграмм). В таких таблицах обычно указывается также доля гласных и согласных букв (в процентах), предшествующих (или следующих за) данной букве.
Сочетаемость букв русского языка:
| Г | С | Слева | Справа | Г | С |
| л, д, к, т, в, р, н | A | л, н, с, т, р, в, к, м | |||
| я, е, у, и, а, о | Б | о, ы, е, а, р, у | |||
| я, т, а, е, и, о | В | о, а, и, ы, с, н, л, р | |||
| р, у, а, и, е, о | Г | о, а, р, л, и, в | |||
| р, я, у, а, и, е, о | Д | е, а, и, о, н, у, р, в | |||
| м, и, л, д, т, р, н | Е | н, т, р, с, л, в, м, и | |||
| р, е, и, а, у, о | Ж | е, и, д, а, н | |||
| о, е, а, и | З | а, н, в, о, м, д | |||
| р, т, м, и, о, л, н | И | с, н, в, и, е, м, к, з | |||
| ь, в, е, о, а, и, с | К | о, а, и, р, у, т, л, е | |||
| г, в, ы, и, е, о, а | Л | и, е, о, а, ь, я, ю, у | |||
| я, ы, а, и, е, о | М | и, е, о, у, а, н, п, ы | |||
| д, ь, н, о | Н | о, а, и, е, ы, н, у | |||
| р, п, к, в, т, н | О | в, с, т, р, и, д, н, м | |||
| в, с, у, а, и, е, о | П | о, р, е, а, у, и, л | |||
| и, к, т, а, п, о, е | Р | а, е, о, и, у, я, ы, н | |||
| с, т, в, а, е, и, о | С | т, к, о, я, е, ь, с, н | |||
| ч, у, и, а, е, о, с | Т | о, а, е, и, ь, в, р, с | |||
| п, т, к, д, н, м, р | У | т, п, с, д, н, ю, ж | |||
| н, а, е, о, и | Ф | и, е, о, а, е, о, а | |||
| у, е, о, а, ы, и | Х | о, и, с, н, в, п, р | |||
| е, ю, н, а, и | Ц | и, е, а, ы | |||
| е, а, у, и, о | Ч | е, и, т, н | |||
| ь, у, ы, е, о, а, и, в | Ш | е, и, н, а, о, л | |||
| е, б, а, я, ю | Щ | е, и, а | |||
| м, р, т, с, б, в, н | Ы | л, х, е, м, и, в, с, н | |||
| н, с, т, л | Ь | н, к, в, п, с, е, о, и | |||
| с, ы, м, л, д, т,, р, н | Э | н, т, р, с, к | |||
| ь, о, а, и, л, у | Ю | д, т, щ, ц, н, п | |||
| о, н, р, л, а, и, с | Я | в, с, т, п, д, к, м, л |
При анализе сочетаемости букв друг с другом следует иметь в виду зависимость появления букв в открытом тексте от значительного числа предшествующих букв. Для анализа этих закономерностей используют понятие условной вероятности.
Наблюдения над открытыми текстами показывают, что для условных вероятностей выполняются неравенства p(ai1)≠p(ai1/ai2), p(ai1/ai2)≠p(ai1/ai2ai3).
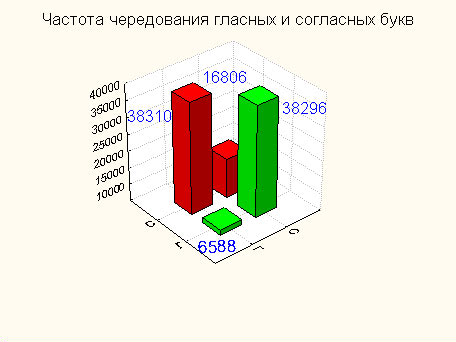
Систематически вопрос о зависимости букв алфавита в открытом тексте от предыдущих букв исследовался известным русским математиком А. А. Марковым (1856 – 1922). Он доказал, что появления букв в открытом тексте нельзя считать независимыми друг от друга. В связи с этим А. А. Марковым отмечена еще одна устойчивая закономерность открытых текстов, связанная с чередованием гласных и согласных букв. Им были подсчитаны частоты встречаемости биграмм вида гласная-гласная (г, г), гласная-согласная (г, с), согласная-гласная (с, г), согласная-согласная (с, с) в русском тексте длиной в 10 5 знаков. Результаты подсчета отражены в следующей таблице:
| Г | С | Всего |
| Г | ||
| С |
Из этой таблицы видно, что для русского языка характерно чередование гласных и согласных, причем относительные частоты могут служить приближениями соответствующих условных и безусловных вероятностей:
p(г/с)≈0.663, p(с/г)≈0.872,
p(г)≈0.432, p(с)≈0.568.
После А. А. Маркова зависимость появления букв текста вслед за несколькими предыдущими исследовал методами теории информации К. Шеннон. Фактически им было показано, в частности, что такая зависимость ощутима на глубину приблизительно в 30 знаков, после чего она практически отсутствует.
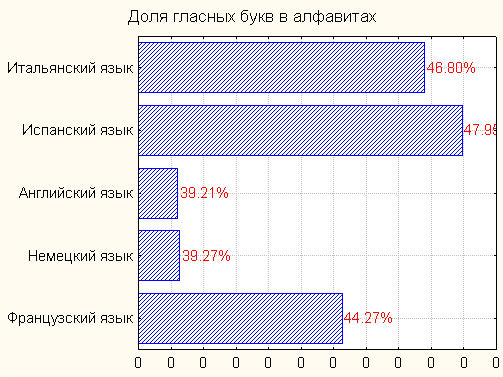
Доля гласных букв в литературном тексте:
| Французский язык | 44.27% |
| Немецкий язык | 39.27% |
| Английский язык | 39.21% |
| Испанский язык | 47.95% |
| Итальянский язык | 46.80% |
В качестве примера приведем частотные характеристики букв английского алфавита, входящих в состав кода ASCII.
[1] - А.П.Алферов и др., "Криптография"
[Ягл73] – Яглом А. М., Яглом И. М., Вероятость и информация, М.: Наука, 1973.
[Bau39] – Baudouin C., Elements de cryptographie / Ed. Pedone A. – Paris, 1939.
[Fri85] – Friedman W. F., Callimahos D., Military cryptanalysis, Part i, Vol 2, Aegean Park Press, Laguna Hills CA, 1920.
Читайте также: