
5 последовательность символов образующих сообщение
Обновлено: 04.07.2024
Кодирование – это перевод информации, представленной символами первичного алфавита, в последовательность кодов.
Декодирование (операция, обратная кодированию) – перевод кодов в набор символов первичного алфавита.
Кодирование может быть равномерное и неравномерное. При равномерном кодировании каждый символ исходного алфавита заменяется кодом одинаковой длины. При неравномерном кодировании разные символы исходного алфавита могут заменяться кодами разной длины.
Равномерное кодирование всегда однозначно декодируемо.
Для неравномерных кодов существует следующее достаточное (но не необходимое) условие однозначного декодирования:
Кодирование в различных системах счисления
Для кодирования букв О, В, Д, П, А решили использовать двоичное представление
чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления). Если закодировать последовательность букв ВОДОПАД таким способом и результат записать восьмеричным кодом, то получится
Представим коды указанных букв в двоичном коде, добавив незначащий нуль для одноразрядных чисел:
Закодируем последовательность букв: ВОДОПАД — 010010001110010.
Разобьём это представление на тройки справа налево и переведём каждую тройку в восьмеричное число.
010 010 001 110 010 — 22162.
Правильный ответ указан под номером 1.
Для передачи по каналу связи сообщения, состоящего только из символов А, Б, В и Г, используется посимвольное кодирование: А-10, Б-11, В-110, Г-0. Через канал связи передаётся сообщение: ВАГБААГВ. Закодируйте сообщение данным кодом. Полученное двоичное число переведите в шестнадцатеричный вид.
Закодируем последовательность букв: ВАГБААГВ — 1101001110100110. Разобьем это представление на четвёрки справа налево и переведём каждую четверку в шестнадцатеричное число:
1101 0011 1010 01102 = D3A616
Правильный ответ указан под номером 1.
Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв – из двух бит, для некоторых – из трех). Эти коды представлены в таблице:
Определите, какой набор букв закодирован двоичной строкой 1000110110110, если известно, что все буквы в последовательности – разные:
Мы видим, что условия Фано и обратное условие Фано не выполняются, значит код можно раскодировать неоднозначно.
Значит, будем перебирать варианты, пока не получим подходящее слово :
1) 100 011 01 10 110
Первая буква определяется однозначно, её код 100: a.
Пусть вторая буква — с, тогда следующая буква — d, потом — e и b.
Такой вариант удовлетворяет условию, значит, окончательно получили ответ: acdeb.
Для передачи данных по каналу связи используется 5-битовый код. Сообщение содержит только буквы А, Б и В, которые кодируются следующими кодовыми словами: А — 11010, Б — 10111, В — 01101.
Получено сообщение 11000 11101 10001 11111. Декодируйте это сообщение — выберите правильный вариант.
Декодируем каждое слово сообщения. Первое слово: 11000 отличается от буквы А только одной позицией. Второе слово: 11101 отличается от буквы В только одной позицией. Третье слово: 10001 отличается от любой буквы более чем одной позицией. Четвёртое слово: 11111 отличается от буквы Б только одной позицией.
Таким образом, ответ: АВхБ.
Однозначное кодирование
Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=1, Б=01, В=001. Как нужно закодировать букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Видим, что ближайший от корня дерева свободный лист (т.е. код с минимальной длиной) имеет код 000.
Для кодирования некоторой последовательности, состоящей из букв У, Ч, Е, Н, И и К, используется неравномерный двоичный префиксный код. Вот этот код: У — 000, Ч — 001, Е — 010, Н — 100, И — 011, К — 11. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему остался префиксным? Коды остальных букв меняться не должны.
Выберите правильный вариант ответа.
Примечание. Префиксный код — это код, в котором ни одно кодовое слово не является началом другого; такие коды позволяют однозначно декодировать полученную двоичную последовательность.
1) кодовое слово для буквы Е можно сократить до 01
2) кодовое слово для буквы К можно сократить до 1
3) кодовое слово для буквы Н можно сократить до 10
4) это невозможно
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Легко заметить, что если букву Н перенести в вершину 10, она останется листом. Т.е. кодовое слово для буквы Н можно сократить до 10.
Выяснить, есть ли среди символов заданной последовательности символы, образующие слово char
1.6. Пусть во входном потоке находится последовательность литер, заканчивающаяся точкой (кодировка.
определить есть ли среди символов буквы, входящие в слово "ШИНА", и сколько среди них символов пробелов
Ввести произвольную последовательность из 30 символов и определить есть ли среди них буквы входящие.

Функция: определить, есть ли в строке слово (набор символов), в котором все символы различны
Описать функцию, в которую передается строка( тип string) и которая определяет есть ли в ней.
Черный экран не запускается. значит у меня не так с кодом программы, но какая ошибка, не знаю. Может я неправильно поняла условие задачи. Подскажите.
С уважением и благодарность, Кэйт.
Во-первых, не strlen(argc[i]), а strlen(argv[i]). Аналогично в ифах.
Во-вторых, после if не нужен then.
В-третьих, тут я давал готовую программу, зачем вы пишете свою программу - непонятно.
Решение
printf("\"%s\" has \"%s\"? %d\n\"%s\" has all symbols of \"%s\"? %d\n\n", argv[i], word, strHasWord(argv[i], word), argv[i], word, strHasSymbolsOfWord(argv[i], word));\\выводят все символы на экран, я правильно поняла?
Решение
printf("\"%s\" has \"%s\"? %d\n\"%s\" has all symbols of \"%s\"? %d\n\n", argv[i], word, strHasWord(argv[i], word), argv[i], word, strHasSymbolsOfWord(argv[i], word));\\выводят все символы на экран, я правильно поняла?
Go,во время выполнения программы передавать аргументы через параметры argc и argv функции main Написать программу для определения, есть ли среди символов этой последовательности символы, образующие слово char. Собственно определение оформить как функцию( это точное условие задачи)
Могу привести пример.
Напишу другое условие задачи, но тоже самое в этой теме про аргументы функции main.
Написать программу сортировки в алфавитном порядке символов переданной строки. Собственно сортировку оформить как функцию.
Тема 5. Защита от ошибок в системах связи
Помехи, действующие в канале, как известно, приводят к возникновению ошибок. Исходная вероятность ошибки в каналах связи обычно не позволяет достичь высокой степени достоверности без применения дополнительных мероприятий. К таким мероприятиям, обеспечивающим защиту от ошибок, относят применения корректирующих кодов.
В общей структурной схеме СПДС задачу защиты от ошибок выполняет кодер и декодер канала, который иногда называют УЗО.
5.1 Понятие о корректирующих кодах
Полученный таким образом код называется простым, он не способен обнаруживать и исправлять ошибки.
Для того, что бы код мог обнаруживать и исправлять ошибки необходимо выполнение условия , при этом неиспользуемые для передачи комбинации (N0-K) называют запрещенными.
Появление ошибки в кодовой комбинации будет обнаружено, если передаваемая разрешенная комбинация перейдет в одну из запрещенных.
Расстояние Хемминга – характеризует степень различия кодовых комбинаций и определяется числом несовпадающих в них разрядов.
Перебрав все возможные пары разрешенных комбинаций рассматриваемого кода можно найти минимальное расстояние Хемминга d0.
Минимальное расстояние d0 - называется кодовым расстоянием
Кодовое расстояние определяет способность кода обнаруживать и исправлять ошибки.
У простого кода d0=1 – он не обнаруживает и не исправляет ошибки. Так как любая ошибка переводит одну разрешенную комбинацию в другую.
В общем случае справедливы следующие соотношения
– для обнаруживающей способности
– для исправляющей способности
Линейные коды.
Двоичный блочный код является линейным если сумма по модулю 2 двух кодовых слов является также кодовым словом.
Линейные коды также называют групповыми.
Введем понятия группы.
Множество элементов с определенной на нем групповой операцией называется группой, если выполняется следующие условия:
1. Замкнутость gig j= gk G в результате операции с двумя элементами группы получается третий, так же принадлежащий этой группе.
2. Ассоциативность (сочетательность) (gigj) gk = gi (gj gk)
3. Наличие нейтрального элемента gj e = gj
4. Наличие обратного элемента. gi (gi) -1 = e
Если выполняется условие gi gj = gj gi, то группа называется коммутативной.
Множество кодовых комбинаций n-элементного кода является замкнутой группой с заданной групповой операцией сложение по модулю 2.
Поэтому используя свойство замкнутости относительно операции 2, множество всех элементов можно задать не перечислением всех элементов, а производящей матрицей.
Все остальные элементы, кроме 0, могут быть получены путем сложения по модулю 2 строк производящей матрицы в различных сочетаниях.
В общем случае строки производящей матрицы могут быть любыми линейно независимыми, но проще и удобнее брать в качестве производящей матрицы – единичную.
5.2 ЦИКЛИЧЕСКИЕ КОДЫ
Широкое распространение на практике получил класс линейных кодов, которые называются циклическими. Данное название происходит от основного свойства этих кодов:
если некоторая кодовая комбинация принадлежит циклическому коду, то комбинация полученная циклической перестановкой исходной комбинации (циклическим сдвигом), также принадлежит данному коду.
Вторым свойством всех разрешенных комбинаций циклических кодов является их делимость без остатка на некоторый выбранный полином, называемый производящим.
Синдромом ошибки в этих кодах является наличие остатка от деления принятой кодовой комбинации на производящий полином.
Эти свойства используются при построении кодов, кодирующих и декодирующих устройств, а также при обнаружении и исправлении ошибок.
Представление кодовой комбинации в виде многочлена.
Описание циклических кодов и их построение удобно проводить с помощью многочленов (или полиномов).
В теории циклических кодов кодовые комбинации обычно представляются в виде полинома. Так, n-элементную кодовую комбинацию можно описать полиномом (n-1) степени, в виде
где =, причем = 0 соответствуют нулевым элементам комбинации, а = 1 - ненулевым.
Запишем полиномы для конкретных 4-элементных комбинаций
Действия над многочленами.
При формировании комбинаций циклического кода часто используют операции сложения многочленов и деления одного многочлена на другой. Так,
Следует отметить, что действия над коэффициентами полинома (сложение и умножение) производятся по модулю 2.
Рассмотрим операцию деления на следующем примере:
Деление выполняется, как обычно, только вычитание заменяется суммированием по модулю два.
Отметим, что запись кодовой комбинации в виде многочлена, не всегда определяет длину кодовой комбинации. Например, при n = 5, многочлену соответствует кодовая комбинация 00011.
Алгоритм получения разрешенной кодовой комбинации циклического кода из комбинации простого кода
Пусть задан полином , определяющий корректирующую способность кода и число проверочных разрядов r, а также исходная комбинация простого k-элементного кода в виде многочлена .
Требуется определить разрешенную кодовую комбинацию циклического кода (n, k).
Формирование базиса (производящей матрицы) циклического кода
Формирование базиса циклического кода возможно как минимум двумя путями.
Вариант первый.
- Составить единичную матрицу для простого исходного кода.
- Определить для каждой кодовой комбинации исходного кода группу проверочных элементов и дописать их в соответствующие строки матрицы.
Полученная матрица и будет базисом циклического кода. Причем, в данном случае, разрешенные комбинации заведомо разделимы (т.е. информационные и проверочные элементы однозначно определены).
Вариант второй.
В данном случае код будет неразделимым.
Получив базис ЦК, можно получить все разрешенные комбинации, проводя сложение по модулю 2 кодовых комбинаций базиса в различных сочетаниях и плюс НУЛЕВАЯ.
Циклические коды достаточно просты в реализации, обладают высокой корректирующей способностью (способностью исправлять и обнаруживать ошибки) и поэтому рекомендованы МСЭ-Т для применения в аппаратуре ПД. Согласно рекомендации V.41 в системах ПД с ОС рекомендуется применять код с производящим полиномом
Построение кодера циклического кода
Рассмотрим код (9,5) образованный полиномом
Разрешенная комбинация циклического кода образуется из комбинации простого (исходного) кода путем умножения ее на и прибавления остатка R(x) от деления на образующий полином.
Для реализации операции добавления нулей используется r-разрядный регистр задержки.
Как видим из примера, процедура деления одного двоичного числа на другое сводится к последовательному сложению по mod2 делителя [10011] с соответствующими членами делимого [10101], затем с двоичным числом, полученным в результате первого сложения, далее с результатом второго сложения и т.д., пока число членов результирующего двоичного числа не станет меньше числа членов делителя.
Это двоичное число и будет остатком .
Построение формирователя остатка циклического кода
Структура устройства осуществляющего деление на полином полностью определяется видом этого полинома. Существуют правила позволяющие провести построение однозначно.
Сформулируем правила построения ФПГ.
- Число ячеек памяти равно степени образующего полинома r.
- Число сумматоров на единицу меньше веса кодирующей комбинации образующего полинома.
- Место установки сумматоров определяется видом образующего полинома.
Сумматоры ставят после каждой ячейки памяти, (начиная с нулевой) для которой существует НЕнулевой член полинома. Не ставят после ячейки для которой в полиноме нет соответствующего члена и после ячейки старшего разряда.
4. В цепь обратной связи необходимо поставить ключ, обеспечивающий правильный ввод исходных элементов и вывод результатов деления.
Структурная схема кодера циклического кода (9,5)
Полная структурная схема кодера приведена на следующем рисунке. Она содержит регистр задержки и рассмотренный выше формирователь проверочной группы.
Рассмотрим работу этой схемы
1. На первом этапе К1– замкнут К2 – разомкнут. Идет одновременное заполнение регистров задержки и сдвига информ. элементами (старший вперед!) и через 4 такта старший разряд в ячейке №4
2. Во время пятого такта К2 – замыкается а К1 – размыкается с этого момента в ФПГ формируется остаток. Одновременно из РЗ на выход выталкивается задержание информационные разряды.
За 5 тактов (с 5 по 9 включительно) в линию уйдут все 5-информационных элемента. К этому времени в ФПГ сформируется остаток
3. К2 – размыкается, К1 – замыкается и в след за информационными в линию уйдут элементы проверочной группы.
4. Одновременно идет заполнение регистров новой комбинацией.
Второй вариант построения кодера ЦК.
Рассмотренный выше кодер очень наглядно отражает процесс деления двоичных чисел. Однако можно построить кодер содержащий меньшее число элементов т.е. более экономичный.
Устройство деления на производящий полином можно реализовать в следующем виде:
За пять тактов в ячейках будет сформирован такой же остаток от деления, что и в рассмотренном выше Формирователе проверочной группы. (ФПГ).
За эти же 5 тактов информационные разряды, выданные сразу на модулятор.
Далее в след за информационными уходят проверочные из ячеек устройств деления.
Но важно отключить обратную связь на момент вывода проверенных элементов, иначе они исказятся.
Окончательно структурная схема экономичного кодера выглядит так.
- На первом такте Кл.1 и Кл.3 замкнуты, информационные элементы проходят на выход кодера и одновременно формируются проверочные элементы.
- После того, как в линию уйдет пятый информационный элемент, в устройстве деления сформируются проверочные;
- на шестом такте ключи 1 и 3 размыкаются (разрываются обратная связь), а ключ 2 замыкается и в линию уходят проверочные разряды.
Ячейки при этом заполняются нулями и схема возвращается в исходное состояние.
Определение ошибочного разряда в ЦК.
Пусть А(х)-многочлен соответствующий переданной кодовой комбинации.
Н(х)- многочлен соответствующей принятой кодовой комбинацией.
Тогда сложение данных многочленов по модулю два даст многочлен ошибки.
E(x)=A(x) H(x)
При однократной ошибке Е(х) будет содержать только один единственный член соответствующий ошибочному разряду.
Остаток – полученный от деления принятого многочлена H(x) на производящей Pr(x) равен остатку полученному при делении соответствующего многочлена ошибок E(x) на Pr(x)
При этом ошибке в каждом разряде будет соответствовать свой остаток R(x) (он же синдром), а значит, получив синдром можно однозначно определить место ошибочного разряда.
Алгоритм определения ошибки.
Пусть имеем n-элементные комбинации (n = k + r) тогда:
1. Получаем остаток от деления Е(х) соответствующего ошибке в старшем разряде [1000000000], на образующей поленом Pr(x)
2. Делим полученный полином Н(х) на Pr(x) и получаем текущий остаток R(x).
3. Сравниваем R0(x) и R(x).
- Если они равны, то ошибка произошла в старшем разряде.
- Если "нет", то увеличиваем степень принятого полинома на Х и снова проводим деления
в) Опять сравниваем полученный остаток с R0(x)
- Если они равны, то ошибки во втором разряде.
- Если нет, то умножаем Н(х)х 2 и повторяем эти операции до тех пор, пока R(X) не будет равен R0(x).
Ошибка будет в разряде соответствующем числу на которое повышена степень Н(х) плюс один.
Например: то номер ошибочного разряда 3+1=4
Пример декодирования комбинации ЦК.
Положим, получена комбинация H(х)=111011010
Проанализируем её в соответствии с вышеприведенным алгоритмом.
Реализуя алгоритм определения ошибок, определим остаток от деления вектора соответствующего ошибке в старшем разряде Х 8 на производяший полином P(x)=X 4 +X+1
X 8 +X 5 +X 4 x 4 +x+1
Разделим принятую комбинацию на образующий полином
Полученный на 9-м такте остаток, как видим, не равен R0(X). Значит необходимо умножить принятую комбинацию на Х и повторить деление. Однако результаты деления с 5 по 9 такты включительно будут такими же, значит необходимо продолжить деление после девятого такта до тех пор, пока в остатке не будет R0(Х). В нашем случае это произойдет на 10 такте, при повышении степени на 1. Значит ошибки во втором разряде.
Декодер циклического кода с исправлением ошибки
Если ошибка в первом разряде, то остаток R0(X)=10101 появления после девятого такта в ячейках ФПГ.
Если во втором по старшинству то после 10 го ;
в третьем по старшинству то после 11 го ;
в четвертом по старшинству то после 12 го
в пятом по старшинству то после 13 го
в шестом по старшинству то после 14 го
в седьмом по старшинству то после 15 го
в восьмом по старшинству то после 16 го
в девятом по старшинству то после 17 го .
На 10 такте старший разряд покидает регистр задержки и проходит через сумматор по модулю 2.
Если и этому моменту остаток в ФПГ=R0(X), то логическая 1 с выхода дешифратора поступит на второй вход сумматора и старший разряд инвертируется.
В нашем случае инвертируется второй разряд на 11 такте.
5.3 Выбор образующего полинома
Рассмотрим вопрос выбора образующего полинома, который определяет корректирующие свойства циклического кода. В теории циклических кодов показано, что образующий полином представляет собой произведение так называемых минимальных многочленов mi(x), являющихся простыми сомножителями (то есть делящимся без остатка лишь на себя и на 1) бинома x n + 1:
где j = d0 – 2 =( 2tu.ош+1) – 2 = 2 tи.ош – 1.
Существуют специальные таблицы минимальных многочленов, одна из которых приведена ниже. Кроме образующего полинома необходимо найти и количество проверочных разрядов r. Оно определяется из следующего свойства циклических кодов:
для любых значений l и tи.ош существует циклический код длины n =2 l – 1, исправляющий все ошибки кратности tи.ош и менее, и содержащий не более проверочных элементов.
Так как , то откуда . (**)
Очевидно, что для уменьшения времени передачи кодовых комбинаций, r следует выбирать как можно меньше. Пусть, например, длина кодовых комбинаций n = 7, кратность исправляемых ошибок tи.ош =1. Из (**) получим r = 1 . log2 ( 7+1 )=3.
После определения количества проверочных разрядов r, вычисления образующего полинома удобно осуществить, пользуясь таблицей минимальных многочленов, представленной в следующем виде:
С позиций теории вероятностей вероятностный источник представляет собой дискретное распределение .
 | ( 6.1) |
Различные задачи кодирования можно формализовать следующим образом. Пусть и алфавиты, некоторое множество слов в алфавите . Тогда функция

Побуквенное (алфавитное) кодирование. Обычно, кодирование множества слов производится с помощью функции кодирующей отдельные буквы алфавита . Для этого случая определение кода будет следующим.
Кодом называется отображение
 | ( 6.2) |
сопоставляющее каждому знаку из алфавита некоторое слово, которое составлено из знаков, входящих в . Слова, входящие в , называются кодовыми словами. Отображение (6.2) может задаваться любым из известных в математике способов. Для конечного множества чаще всего используется табличный способ, задающий код (6.2) таблицей.
Такая таблица называется кодовой таблицей. В качестве примера можно привести таблицу кодирования алфавита " />
из цифр восьмеричной системы счисления словами из упоминавшегося ранее бинарного алфавита " />
. В данном случае отображение (6.2) имеет вид \to B^3" />
.
Еще одним примером является так называемый код ASCII , фрагмент которого показан в следующей таблице.
Кодирование слов. Отображение (6.2) позволяет перейти от кодирования отдельных знаков (букв конечного алфавита) к кодированию слов. Если - слово, состоящее из знаков (полученное конкатенацией знаков) , то кодом слова (по определению) является конкатенация кодов знаков , образующих слово, т. е. . Например, с применением таблицы ASCII кода (см. последнюю таблицу) слово head будет закодировано последовательностью 10410197100 при использовании десятичной системы счисления или последовательностью 68656164 - в шестнадцатеричной.
Условие (необходимое) однозначной декодируемости заключается в инъективности отображения (6.2). Инъективность обеспечивает однозначную декодируемость отдельных знаков из алфавита . Однако однозначной декодируемости слов из это условие не обеспечивает, если коды отдельных знаков, входящих в слово, следуют один за другим и не разделяются специальным символом. Подробнее проблема однозначной декодируемости будет рассмотрена позже.
В частном случае, когда знаки из кодируются однобуквенными словами, отображение (6.2) имеет вид и представляет собой простую замену (подстановку) знаков. Однако чаще всего, в основном из-за использования в большинстве технических устройств обработки информации двоичного алфавита " />
, каждый знак из кодируется последовательностью знаков (словом) из B.
Недостаточность количества знаков в алфавите является препятствием применения простой замены для кодирования (не обеспечивается инъективность и, следовательно, однозначность декодируемости при ). Для устранения этой проблемы используются множества новых, "составных" объектов из степеней алфавита . Множество состоит из упорядоченных последовательностей элементов из (векторов) длины . Число элементов множества равно . Например, для двоичного алфавита " />
имеем . Таким образом, взяв достаточно большую степень , можно получить нужное количество элементов вторичного алфавита.
Процедуру кодирования слова a_ \dots a_" />
в алфавите можно представить следующим образом. Имеется кодовая таблица, в левом столбце которой находятся кодируемые буквы алфавита , а в правом столбце - соответствующие кодовые слова (кодовые слова могут иметь различную длину).
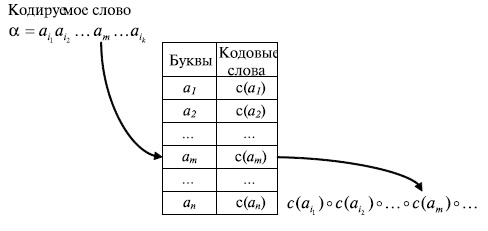
Для каждого знака слова a_ \dots a_" />
, начиная с первого знака, в кодовой таблице находится строка, в которой в левом поле располагается кодируемый знак (буква), и из правого поля этой строки берется соответствующее кодовое слово в алфавите . Найденное кодовое слово приписывается слева (конкатенируется) к уже сформированной части кода слова . Кодовое слово первой буквы слова приписывается к пустому слову е. Эта процедура схематически показана на рис.6.4.
Читайте также: