
Способы сжатия графической информации реферат
Обновлено: 02.07.2024
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.

В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.
Алгоритм Хаффмана
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.
Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.
Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).
Перевод в цветовое пространство YCbCr
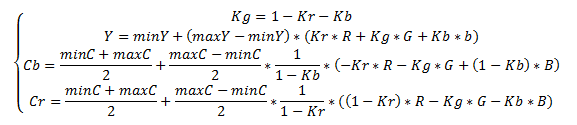
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.
Субдискретизация компонент цветности
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.
Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).
Зигзаг-обход матриц

Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.
RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).
Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.
Степень исключения этой информации как раз и определяется установкой требуемого качества. Далее информация о яркости и цвете кодируется так, что остаются только различия между соседними блоками. В результате процессе обработки остаются только последовательности простых чисел, которые далее легко сжимаютсялюбым алгоритмом сжатия без потерь (например, алгоритмом Хаффмана).Достоинства алгоритма… Читать ещё >
Методы сжатия графической информации ( реферат , курсовая , диплом , контрольная )
Содержание
- Введение
- 1. Виды графической информации по способу кодировки
- 2. Алгоритмы сжатия данных
- 2. 1. Групповое кодирование (RLE)
- 2. 2. Алгоритм Хаффмана
- 2. 3. Алгоритм Хаффмана с фиксированной таблицей CCITTGroup
- 2. 4. LZW-сжатие
- 2. 4. JPEG (Joint Photographic Experts Group)
Далее, этот ряд уже, в свою очередь, сжимается по Хаффману с фиксированной таблицей. Каждая строка изображения сжимается независимо. Считается, что в изображении существенно преобладает белый цвет, и все строки изображения начинаются с белой точки. Для строки, начинающейся с черной точки, считают, что строка начинается белой серией длины 0. На практике в тех случаях, когда в изображении преобладает черный цвет, перед компрессией изображение инвертируется, что записывается в заголовок файла. Достоинства алгоритма в том, что он чрезвычайно прост в реализации, быстр и может быть легко реализован аппаратно. Алгоритм CCITTGroup 3 реализован в формате TIFF.
Схема сжатия Лемпела — Зива — Велча (LZW) (по первым буквам фамилий его разработчиков) — одиниз наиболее распространенных в компьютерной графике. Существует довольно большое семейство LZ-подобных алгоритмов, различающихся, например, методом поиска повторяющихся цепочек. Алгоритм LZW позволяет работать с любым типом данных. Он относится к алгоритмам подстановок, основанными на словарях. Этот алгоритм из данных входного потока строит словарь данных (также называемый переводной таблицей или таблицей строк). В таблице инициализируются все 1-символьные строки. Алгоритм сверяет каждый символ данных, и каждую уникальную2х-символьную строку сохраняет в таблице в виде кода, ссылающегося на соответствующий первый символ. При просматривании очередного символа, для него из таблицы находится уже встречавшаяся строка максимальной длины, затем в таблице сохраняется код для этой строки со следующим символом на входе; на выход выдаётся код этой строки, а следующий символ используется в качестве начала следующей строки. При раскодировании требуется только закодированные данные, а по нему воссоздается соответствующая таблица строк непосредственно по закодированным данным. Декодирование LZW-данных осуществляется в порядке, обратном кодированию. Достоинства алгоритма LZW: — нетнеобходимости вычислять вероятности встречаемости символов;
— таблицу строкможно восстановить, пользуясь только потоком кодов, поэтому нет необходимости сохранять её вместе со сжатыми;
— в исходный графический файл не вносятся искажения, поэтому алгоритм подходит для сжатия растровых данных любого типа. Недостатки:
алгоритм не проводит анализ входных данных поэтому не оптимален. Применяется в форматах GIFи TIFF, включен в стандарт сжатия для модемов V.42bisи PostScriptLevel 2.
2.4 JPEG (Joint Photographic Experts Group) Наиболее известным методом компрессии с потерями является JPEG-компрессия. В основе метода лежит особенность человеческого восприятия: глаз может достаточно четко различать яркость объекта и цветовые контрасты, а плавные изменения в светах и тенях различает значительно меньше. Поэтому при записи часть цветовых данных можно опустить, как предполагается, без заметного ущерба для восприятия. Рисунок2 — Компромисс между качеством и уровнем компрессии
Алгоритм разрабатывалсяспециально для сжатия 24-битных изображений группой экспертов в области фотографииJPEG — JointPhotographicExpertGroup — подразделение в рамках ISO — Международной организации по стандартизации. В JPEGизображение обрабатывается в несколько этапов. Сначала оно конвертируется в особое цветовое пространство, похожее на цветовую модель CIE Lab, где один канал определяет яркость, а в остальных двух каналах уменьшается разрешение (по методу мозаики).Далее изображение разбивается на области квадратной формы размером 8×8 пикселей. В каждойобластиосуществляются достаточно сложные математические преобразования. Происходит запись двух типов информации — усредненной информации о блоке и информации о его деталях. Дальше, в зависимости от необходимой степени сжатия, удаляется то или иное количество дополнительной информации. Соответственно, у файла меньшего размера, качество будет хуже. Одновременно каждаяобластьподвергается разложению на составляющие цвета и происходит подсчет частоты встречаемости каждого цвета. Это позволяет исключить небольшую часть яркостной характеристики, и довольно значительную часть цветовой.
Степень исключения этой информации как раз и определяется установкой требуемого качества. Далее информация о яркости и цвете кодируется так, что остаются только различия между соседними блоками. В результате процессе обработки остаются только последовательности простых чисел, которые далее легко сжимаютсялюбым алгоритмом сжатия без потерь (например, алгоритмом Хаффмана).Достоинства алгоритма LPEG: — можно задать степень сжатия, соответственно подобрать необходимый размер и качество изображения;
при высокой степени сжатия происходит распад изображения на отдельные квадраты (8×8), за счет больших потерь в низких частотах при квантовании и что делает невозможным восстановление исходных данных;
— по границам резких переходов цветов проявляется заметные ореолы — эффект Гиббса. Алгоритмы сжатия с потерями, в частности алгоритм JPEG, не позволяют полностью восстановить изображение до его исходного состояния, а, следовательно, не рекомендуется сжимать изображения несколько раз. Заключение
Представление данных на мониторе компьютера в графическом виде впервые было реализовано в середине 50-х годов для больших ЭВМ, применявшихся в научных и военных исследованиях. С тех пор графический способ отображения данных стал неотъемлемой принадлежностью подавляющего числа компьютерных систем, в особенности персональных. Графический интерфейс пользователя сегодня является стандартом “де-факто” для программного обеспечения разных классов, начиная с операционных систем.
В настоящее время в связи с широким внедрением персональных компьютеров во все сферы жизни, резкой интенсификацией процесса научных исследований, революционным совершенствованием его технологии, значительным повышением возможностей аппаратуры все больший интерес вызывают идеи, алгоритмы и средства компьютерной графики ……………………………………………………………………………………………………………………………………………………
Надежность хранения информации и легкий доступ для тех, кто в ней нуждается, является залогом успешной совместной работы.Системы электронного документооборота (Electronic Document Management System) представляют собой взаимосвязанную систему организационного, технического и программного обеспечения для управления различными видами документов и информацией.
Удивительно, что даже простейшие методы анализа данных позволяют существенно прояснить сложную ситуацию, первоначально поражающую нагромождением цифр. По результатам анализа вы получаете статистические таблицы, графические иллюстрации и аналитический отчет.
Составить математическую модель задачи и решить ее двумя способами: симплекс методом и графически.
1. Понятие компьютерной графики
2. Растровая и векторная графика
3. Цветовой охват 104. Цвет в КГ. Аддитивные и субтрактивные цвета. Системы RGB, CMYK, HSB, HSL
Литература
1. Шикин Е.В., Боресков А.В. Компьютерная графика. — М.: Диалог — МИФИ, 1995. – 464 с.
3. Джеймс Д. Мюррей, Уильям ванРайперЭнциклопедия форматов графических файлов — К.: BHV, 1997.
4. Том Сван Форматы файлов Windows — М.: Binom, 1995.
5. Борзенко А., Федоров А. Мультимедиа для всех. — М.:Компьютер-пресс, 1995.
6. Корриган Д. Компьютерная графика. Секреты и решения — М.:Энтроп, 1995.
Графические данные, особенно данные растровых файлов, занимают колоссальное количество дискового пространства. Например, растровое изображение формата А4 в цветовой модели CMYK при разрешении 300 точек на дюйм занимает порядка 30 мегабайт дискового пространства. Хорошо, если файл один, и ваша публикация не использует других изображений (что крайне маловероятно). Ситуация в корне изменяется тогда, когда вы создаете некий шедевр, например, галерею репродукций картин А2 формата, при этом она с трудом умещается на 100 листах, запечатанных с двух сторон. При самых скромных подсчетах (120 мегабайт х 100 листов х 2 стороны у каждого листа), растровые изображения в этом формате при таком количестве листов будут занимать порядка 24 гигабайт дискового пространства. На чем вы собираетесь хранить такую публикацию ? А теперь представьте, что у вас несколько заказчиков, и работы каждого из них хранятся в нескольких вариантах оформления, кроме того, для большинства заказов вы сохранили выполненный проект на разных стадиях его готовности, чтобы в случае желания заказчика все в корне и кардинально изменить, вы могли быстро это выполнить. Естественно, все эти данные сохранить будет очень и очень сложно. Именно поэтому, а также потому, что дисковое пространство обычно достаточно дорого обходится (не смотря на то, что устройства для хранения цифровой информации постоянно дешевеют, их все время требуется больше и больше, что требует немалых капиталовложений), были изобретены множество методов сжатия данных самого различного типа, в том числе и графических. О наиболее распространенных и широко использующихся мы сейчас поговорим.
В самом начале разделим существующие методы сжатия изображений на две условные категории - на архивацию (сжатие), и на компрессию (конвертирование). Разница между этими способами в том, что второй не подразумевает полного восстановления исходного сохраненного изображения в полном качестве. Но каким бы не был алгоритм компрессии данных, для работы с ним файл нужно проанализировать и распаковать, т. е. вернуть данные в исходный незапакованный вид для их быстрой обработки (обычно это происходит прозрачно для пользователя). Ниже мы рассмотрим способы сжатия подробнее.
Архивация, или сжатие графических данных, возможно как для растровой, так и для векторной графики. При этом способе уменьшения данных, программа анализирует наличие в сжимаемых данных некоторых одинаковых последовательностей данных, и исключает их, записывая вместо повторяющегося фрагмента ссылку на предыдущий такой же (для последующего восстановления). Такими одинаковыми последовательностями могут быть пикселы одного цвета, повторяющиеся текстовые данные, или некая избыточная информация, которая в рамках данного массива данных повторяется несколько раз. Например, растровый файл, состоящий из подложки строго одного цвета (например, серого), имеет в своей структуре очень много повторяющихся фрагментов.
Компрессия (конвертирование) данных - это способ сохранения данных таким образом, при использовании которого не гарантируется (хотя иногда возможно) полное восстановление исходных графических данных. При таком способе хранения данных обычно графическая информация немного "портится" по сравнению с оригинальной, но этими искажениями можно управлять, и при их небольшом значении ими вполне можно пренебречь. Обычно файлы, сохраненные с использованием этого способа хранения, занимают значительно меньше дискового пространства, чем файлы, сохраненные с использованием простой аривации (сжатия). Сильная степень компрессии при использовании второго способа сжатия и дает этому способу хранения данных право на существование (в противном случае, все поголовно использовали бы сжатие без потерь). Как правило, при сохранении данных с использованием компрессии, имеется возможность компромисса между размером выходного файла и его качеством. Понятно, что возможна оптимизация только по одному параметру (чем меньше качество, тем меньше объем выходного файла, и наоборот).
Ниже будут рассмотрены некоторые алгоритмы сжатия данных, их достоинства и недостатки, а также оптимальная их сфера применения (т. е. те типы изображений, к которым данный метод сжатия лучше применять).
Вначале рассмотрим несколько алгоритмов сжатия данных, которые не вносят изменения в исходные файлы и гарантируют полное восстановление данных.
RLE (Run - length encoding) - метод сжатия данных, при котором одинаковые последовательности одних и тех же байт заменяются однократным упоминанием повторяющегося байта (или целой цепочки байтов), и числа его повторений в исходных данных. Например, строка типа 0100 0100 0100 0100 0100 0100 0100 0100, описывающая некую группу пикселов будет заменена на запись типа 0100 х 8, и т.д. Применяется этот тип сжатия в тех случаях, когда изображение имеет большие участки одинакового цвета, цифровое представление которых идентично. В основном, этот тип сжатия применим для монохромных изображний, сохраненных в цветовой модели Bitmap, где при сжатии данных с его использованием можно добиться наилучших результатов. Для сжатия других типов данных (в том числе, и не графических) алгоритм применим, но малоэффективен, так как сжимаемые данные должны иметь простую повторяющуюся структуру). Этот алгоритм имеет еще одно важное преимущество, заключающееся в его относительной простоте, что позволяет быстро производить распаковку из этого формата и упаковку в этот формат (как вы помните, все графические данные для их обработки должны быть предварительно распакованы, а любая компрессия или архивация применяется, в основном, для временного или постоянного хранения файла). В принципе, на основе этого несложного алгоритма, работают более совершенные и более сложные (а также менее быстрые) методы сжатия графических данных, которые мы рассмотрим ниже. Этот метод сжатия графических фанных испольуется для файлов формата PSD, BMP и других.
CCITT Group 3, CCITT Group 4 - Два похожих метода сжатия графических данных, работающие с однобитными изображениями, сохраненными в цветовой модели Bitmap. Основаны на поиске и исключении из исходного изображения дублирующихся последовательностей данных (как в предыдущем типе сжатия, RLE). Различием является лишь то, что эти алгоритмы ориентированы на упаковку именно растровой графической информации, так как работают с отдельными рядами пикселов в изображении. Изначально алгоритм был разработан для сжатия данных, передаваемых через факсимильные системы связи (CCITT Group 3), а более совершенная разновидность этого метода архивации данных (CCITT Group 4) подходит для записи монохромных изображений с более высокой степенью сжатия. Как и предыдущий алгоритм, он, в основном, подходит для сжатия изображений с большими одноцветными областями. Его достоинством является скорость выполнения, а недостатком - ограниченность применения для компрессии графических данных (не все данные удается таким образом эффективно сжать). Этот метод сжатия графических фанных испольуется в файлах формата PDF, PostScript (в инкапсулированных объектах) и других.
LZW (Lemple-Zif-Welch) - алгоритм сжатия данных, основанный на поиске и замене в исходном файле одинаковых последовательностей данных, для их исключения, и уменьшения размера "архива". В отличие от предыдущих рассмотреных методов сжатия, в данном случае производится более "интеллектуальный" просмотр сжимаемого cодержимого, для достижения большей степени сжатия данных. Данный тип сжатия не вносит искажений в исходный графический файл, и подходит для обработки растровых данных любого типа - монохромных, черно - белых, или полноцветных. Наилучшие результаты получаются при компрессии изображений с большими областями одинакового цвета или изображений с повторяющимися одинаковыми структурами. Этот метод позволяет достичь одну из самых наилучших степеней сжатия среди других существующих методов сжатия графических данных, при одновременном полном отсутствии потерь или искажений в исходных файлах. Этот метод сжатия графических фанных испольуется в файлах формата TIFF, PDF, GIF, PostScript (в инкапсулированных объектах) и других.
ZIP - метод сжатия данных, аналогичный методу, использованному в популярном алгоритме архивации PKZip. В основу метода сжатия положен метод, аналогичный LZW. Как и предыдущий метод сжатия данных, этот способ не вносит искажений в исходный файл, и лучше всего подходит для обработки графических данных с одинаковыми одноцветными или повторяющимися областями. Этот метод сжатия графических фанных испольуется в файлах формата PDF, TIFF и некоторых других.
А теперь рассмотрим алгоритмы и методы конвертирования данных, которые вносят изменения в исходные файлы, показывая при этом более высокую степень упаковки графических изображений.
JPEG (Joint Photographic Experts Group) - метод, используемый для хранения полутоновых и полноцветных изображений, позволяющий добиться наивысшей степени сжатия и минимальный размер выходного файла. Основан алгоритм на особенностях восприятия человеческим глазом различных цветов, и достаточно громоздок с вычислительной точки зрения, так как занимает много процессорного времени. Происходит кодирование файла в несколько этапов. Во-первых, изображение условно разбивается на несколько цветовых каналов, для дальнейшего анализа. Затем, изображение разбивается на группы, по 64 пиксела в каждой группе, которые представляют из себя квадратные участки изображения размером 8х8 пикселов, для последующей обработки. Затем, цвет пикселов специальным образом кодируется, исключается дублирующая и избыточная информация, причем при описании цвета большее внимание уделяется скорее яркостной, чем цветовой составляющей, так как человеческий глаз воспринимает больше изменения яркости, чем конкретного цветового тона. Полученные данные сжимаются по RLE или LZW - алгоритму, для получения еще большей компрессии. В результате, на выходе мы получаем файл, иногда в десятки раз меньший, чем его неконвертированный аналог. Однако, чем меньше размер выходного файла, тем меньше степень "аккуратности" при работе программы - конвертора, и, соответственно, ниже качество выходного изображения. Обычно, в программах, позволяющих сохранять растровые данные, возможно задание некоего компромисса между объемом выходного файла и качеством изображения. При наивысшем качестве, обхем выходного файла в 3-5 раз меньше исходного незапакованного. При наименьшем - меньше исходника в десятки раз, но, как правило, при этом качество изображения не позволяет его где-либо использовать. Как правило, для сохранения достойного уровня качества, используют наивысшую из доступных степень качества. Данный формат предназначен для хранения, в основном, фотографических изображений с большим количеством оттенков и цветовых переходов, и практически не подходит для хранения однотонных изображений типа кадров из мультфильмов, скриншотов и пр.(сжатие будет слишком низким, или качество картинки окажется просто недопустимым). Этот метод сжатия графических фанных испольуется в файлах формата PDF, PostScript (в инкапсулированных объектах), собственно, в JPEG и других.
Главным недостатком компрессии с частичной потерей качества, является то, что эти потери, выражающиеся в искажении цветового тона или появлении характерной кубической структуры в контрастных участках изображения (проявляются так называемые артефакты), возникают каждый раз при сохранении изображения, и "накладываются" друг на друга при многократном сохранении файла в этом формате. Поэтому специалисты рекомендуют использовать форматы с частичной потерей качества только для хранения окончательных результатов работы, а не промежуточных рабочих файлов.
Кроме того, в качестве вспомогательных средств, которые могут использоваться для понижения объемов файлов можно рассмотреть изменение цветовой модели графического файла, изменение разрешения растрового файла и ресемплирование (изменение глубины цвета пикселов).
Изменение цветовой модели файла. Например, файлы в цветовом пространстве CMYK больше аналогичных файлов в пространстве RGB на 33% (так как в CMYK имеется дополнительный четвертый черный канал). Если вы не планируете печать ваших файлов, или уверенны в том, что вы сможете корректно провести цветоделение (переход в субтрактивную модель CMYK) позже, вы можете хранить рабочие файлы в RGB.
Изменение разрешения растрового файла. Файл с разрешением 600 точек на дюйм больше своего аналога разрешением в 300 точек в четыре раза, а качество печати при повышенном разрешении не всегда будет выше, нем при номинальном его значении. Так что если разрешение избыточно, можете его понизить. Понижение разрешения файла - необратимый процесс, и никакя последующая интерполяция потом потерянные пикселы не восстановит. Так что при задании необходимого разрешения также будьте внимательны и рациональны. Следует учесть, что параметр разрешения контуров применительно к векторной графике не имеет отношения к объему выходного файла (это уже несколько другое разрешение и несколько другое понятие), а влияет на аккуратность "прорисовки" вектора при его растеризации в устройстве, где производится печать. Так что уменьшение этого параметра для векторной графики не уменьшит объем ваших файлов, а только ухудшит качество печати.
Ресемплирование (изменение глубины цвета растрового изображения) - это изменение начальной глубины цвета файла. Некоторые оцифровывающие устройства выдают растровую информацию с глубиной цвета, превышающую достаточное для печати значение 8 бит на канал. Это иногда оправдано, так как большее значение бит на канал позволяет задавать большее число градаций цвета, что требуется, например, при сильной, "кардинальной" цветокоррекции - сильном осветлении или затенении отдельных участков. Однако, в большинстве случаев для хранения растровых данных в различных цветовых моделях с лихвой достаточно глубины цвета 8 бит на канал. Кроме того, один из стандартов сжатия для RGB изображений подразумевает использование разного количества бит для разных цветовых составляющих (обычно наибольшее количество бит используется для зеленого канала). Также, большинство фильтров Adobe Photoshop рассчитано на работу с изображениями с глубиной цвета в 8 бит (с изображением, использующим нестандартную глубину цвета, становится практически невозможно работать, так как большинство фильтров рассчитаны на значение глубины цвета в 8 бит).
Хорошим примером настройки опций сжатия графики является диалоговое окно Job Options - Compression из программы Adobe Acrobat Distiller, опции которого рассмотрены ниже.
Рис. 1. Диалоговое окно Adobe Acrobat Distiller
Для различных типов изображений, которые могут быть составляющими файла PostScript (про такие объекты говорят, что они инкапсулированы) - для - полноцветных (color bitmap), полутоновых черно-белых (grayscale) и для штриховых объектов (bitmap, 1 bit per pixel) указаны различные установки параметров сжатия, являющиеся оптимальными для создания PDF - документа, оптимизированного для печати и сжатого с минимальными потерями качества. В качестве параметра сжатия изображения выбрана альтернатива JPEG с максимально возможным качеством. Выходное разрешение растровых полноцветных изображений выбрано не более 300 точек на дюйм, и в случае превышения указанного предельного разрешения к изображению будет применен алгоритм бикубической интерполяции с понижением разрешения (bicubic downsampling) - это наиболее медленный, но и наиболее качественный алгоритм интерполяции. Кроме этого алгоритма, допустимо также указать алгоритмы Average downsampling (усреднение значения цвета пикселов) и Subsampling (полное отсутствие интерполяции, берется один из пикселов, и его цвет устанавливается как цвет всего участка изображения). Естественно, последний вариант работает быстрее всех, но и с наименьшим качеством выходного изображения. Для черно - белых полутоновых изображений (grayscale) установки интерполояции, предельного разрешения и метода сжатия аналогичны прерыдущему примеру. Для монохромных изображений, заданных в цветовой модеди Bitmap с глубиной цвета 1 бит на пиксел параметры несколько другие. Во-первых, значение предельного разрешения установлено на уровне 1200 точек на дюйм, что является корректным для изображений в этой цветовой модели (напомню, что спектр разрешений для изображений в этой цветовой модели обычно задается в пределах от 800 до 2540 точек на дюйм). Метод интерполяции в случае превышения разрешения также бикубический, как и в предыдущих примерах, а вот метод сжатия выбран именно ZIP (возможен также выбор CCITT Group 3, CCITT Group 4, или RLE). При этом не происходит никаких потерь качества в выходном изображении. Кроме того, с учетом специфики цветовой модели, невозможно задание алгоритмов сжатия типа JPEG.
Последняя опция - Compress text and line art - подразумевает сжатие текстовых и векторных данных по одному из алгоритмов, подобных ZIP или LZW. Естественно, подразумевается полное восстановление данных при распаковке файла.
Читайте также: