
Создание логической модели данных реферат
Обновлено: 02.07.2024
Логическими уровень - это абстрактный взгляд на данные, на нем данные представляются так, как выглядят в реальном мире, и могут называться так, как они называются в реальном мире.
Объекты модели, представляемые на логическом уровне, называются сущностями и атрибутами. Логическая модель данных может быть построена на основе другой логической модели, например на основе модели процессов. Логическая модель данных является универсальной и никак не связана с конкретной реализацией СУБД.
Различают три уровня логической модели, отличающихся по глубине представления информации о данных:
- диаграмм сущность-связь (Entity Relationship Diagram, ERD);
- модель данных, основанная на ключах (Key Based model, KB);
- полная атрибутная модель (Fully Attributed model, FA).
Диаграмма сущность-связь представляет собой модель данных верхнего уровня. Она включает сущности и взаимосвязи, отражающие основные бизнес-правила предметной области. Такая диаграмма не слишком детализирована, в нее включаются основные сущности и связи между ними, которые удовлетворяют основным требованиям, предъявляемым к ИС.
Диаграмма сущность-связь может включать связи многие-ко-многим и не включать описание ключей. Как правило, ERD используется для презентаций и обсуждения структуры данных с экспертами предметной области.
Модель данных, основанная на ключах, - более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области.
Полная атрибутивная модель - наиболее детальное представление структуры данных: представляет данные в третьей нормальной форме и включает все сущности, атрибуты и связи.
В данных методических указаниях будет рассмотрена модель данных, основанная на ключах.
Основные компоненты диаграммы ERwin – это сущности, атрибуты и связи.
Сущность на диаграмме изображается прямоугольником. В зависимости от режима представления диаграммы прямоугольник может содержать имя сущности, ее описание, список ее атрибутов и другие сведения (см. рис. 34).

Рис. 34. Сущность с заполненными атрибутами.
Экземпляры независимой сущности могут быть уникально идентифицированы без определения ее связей с другими сущностями; зависимая сущность, наоборот, не может быть уникально идентифицирована без определения ее связей с другими сущностями. Зависимая сущность отображается в ERwin прямоугольником с закругленными углами (см. рис. 35).

Рис. 35. Зависимая сущность с заполненными атрибутами.
Зависимая сущность может наследовать один и тот же внешний ключ от более чем одной родительской сущности, или от одной и той же родительской сущности через использование несколько связей. Если не введены различные роли для такого множественного наследования, ERwin считает, что в зависимой сущности атрибуты внешнего ключа появляются только один раз.
В зависимости от того, все ли возможные сущности-подтипы включены в модель, категорийная связь является полной или неполной. Например, если супертип может содержать данные об уволенных сотрудниках, то эта связь - неполной категоризации, так как для него не существует записи в сущностях - подтипах. В ERwin полная категория изображается окружностью с двумя подчеркиваниями, а неполная - окружностью с одним подчеркиванием.
Унификация - это объединение двух или более групп атрибутов внешних ключей в один внешний ключ (группу атрибутов), в предположении, что значения одноименных атрибутов в дочерней сущности всегда одинаковы. Рассмотрим пример: сущность "сотрудник" имеет первичный ключ "код сотрудника" и связан идентифицирующей связью с сущностями "супруга" и "дети". При этом происходит миграция первичного ключа в зависимые сущности. В свою очередь, сущность "супруга" связана не идентифицирующей связью с сущностью "дети". Имеются два пути миграции ключа, однако в сущности "дети" атрибут "код сотрудника" появляется один раз в качестве элемента первичного ключа. Существуют случаи, когда унификация атрибутов дает неверный с точки зрения предметной области результат. Для отмены унификации для атрибутов вводятся имена ролей.
Атрибут выражает свойство объекта, характеризующее его экземпляр (определенное свойство объекта. С точки зрения БД (физическая модель) сущности соответствует таблица, экземпляру сущности – строка в таблице, а атрибуту – колонка таблицы. Горизонтальная линия прямоугольника разделяет атрибуты сущности на два набора: атрибуты, составляющие первичный ключ (в верхней части) и прочие, не входящие в первичный ключ (в нижней части).
Первичный ключ - это атрибут или набор атрибутов, уникально идентифицирующий экземпляр сущности. Если несколько наборов атрибутов могут уникально идентифицировать сущность, то выбор одного из них осуществляется разработчиком на основании анализа предметной области. Для каждого первичного ключа ERwin создает при генерации структуры БД уникальный индекс.
Если между некоторыми сущностями существует связь, то факты из одной сущности ссылаются или некоторым образом связаны с фактами из другой сущности. Связь - это функциональная зависимость между сущностями. Поддержание непротиворечивости функциональных зависимостей между сущностями называется ссылочной целостностью. Поскольку связи содержатся "внутри" реляционной модели, реализация ссылочной целостности может выполняться как приложением, так и самой СУБД (с помощью механизмов декларативной ссылочной целостности, триггеров). Связь это понятие логического уровня, которому соответствует внешний ключ на физическом уровне. Связь называется идентифицирующей, если экземпляр дочерней сущности идентифицируется через ее связь с родительской сущностью. Атрибуты, составляющие первичный ключ родительской сущности, при этом входят в первичный ключ дочерней сущности. Дочерняя сущность при идентифицирующей связи всегда является зависимой. Связь называется не идентифицирующей, если экземпляр дочерней сущности идентифицируется иначе, чем через связь с родительской сущностью. Атрибуты, составляющие первичный ключ родительской сущности, при этом входят в состав не ключевых атрибутов дочерней сущности.

- при нажатии кнопки ввести название сущности;
- при нажатии кнопки New ввести название и тип добавляемого атрибута (список форматов возможных типов представлен в табл. 5), а при необходимости установить ему ключевой признак вводом флажка Primary Key.
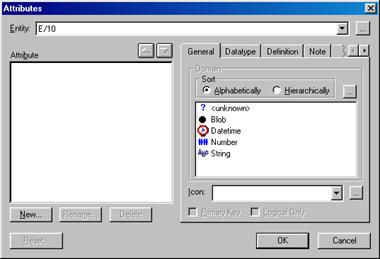
Рис. 36. Окно для заполнения атрибутов сущности.
Расшифровка назначения типов атрибутов
| Тип | Формат |
| Unknown | Не определен |
| Blob | Счетчик |
| Datetime | Дата или время |
| Number | Числовой |
| String | Текстовый |
Для каждого атрибута имеется возможность ввода дополнительных характеристик, расположенных на вкладках окна Attributes:
- General (основные характеристики атрибута);
- Datatype (выбранный формат атрибута);
- Definition (пояснения);
- Note (комментарий для данного атрибута);
- UDP (свойства атрибутов сущности, добавляемых пользователем);
- Key Group (отношение выбранного атрибута к ключевым признакам);
- History (история возникновения атрибута).
Пример логической модели данных представлен на рис. 37.
Для компактного расположения модели на листе бумаги при печати следует вызвать в меню File режим Print, а в открывшемся окне Print (см. рис. 38) нажать кнопку Fit model.
Для представления логического дизайна используют логическую модель объектов или данных. Однако проектная команда иногда создает обе модели, представляя логический проект с разных сторон. Это необходимо, когда одна из моделей представляет какую-либо часть проекта особо четко.
Логический дизайн — это промежуточный этап между концептуальным и физическим дизайном. Создавая модель данных, происходит преобразование концептуальных требований к данным (они определяются при концептуальном дизайне) в реальные объекты-сущности и отношения, отображающие реальное взаимодействие данных. Полученная информация помогает в дальнейшем моделировать физический дизайн.
При переходе к логической стадии дизайна данных одна из первоочередных задач заключается в формулировке сущностей на основании требований к данным и другой связанной информации. Сущностью (entity) обычно считают человека, место, элемент или понятие, которое определяет данные или о котором данные собираются и хранятся. Атрибут — это характеристика, представляющая собой дополнительное определение и описание свойств экземпляра сущности. У сущности обычно несколько атрибутов.
После определения сущностей следует определить необходимые атрибуты — они описывают сущности решения.
При реализации физического дизайна атрибуты обычно превращаются в столбцы таблиц базы данных.
Логическая модель данных представляется в виде диаграмм “сущность-связь” (ERD), предназначены для разработки моделей данных и обеспечивают стандартный способ определения данных и отношений между ними. Фактически с помощью ERD осуществляется детализация хранилищ данных проектируемой системы, а также документируются сущности системы и способы их взаимодействия, включая идентификацию объектов, важных для предметной области (сущностей), свойств этих объектов (атрибутов) и их отношений с другими объектами (связей).
Данная нотация была введена Ченом (Chen) и получила дальнейшее развитие в работах Баркера (Barker). Нотация Чена предоставляет богатый набор средств моделирования данных, включая собственно ERD, а также диаграммы атрибутов и диаграммы декомпозиции. Эти диаграммные техники используются прежде всего для проектирования реляционных баз данных (хотя также могут с успехом применяться и для моделирования как иерархических, так и сетевых баз данных).
Сущность представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, состояний, идей, предметов и т.п.), обладающих общими атрибутами или характеристиками. Любой объект системы может быть представлен только одной сущностью, которая должна быть уникально идентифицирована. При этом имя сущности должно отражать тип или класс объекта, а не его конкретный экземпляр.
Отношение в самом общем виде представляет собой связь между двумя и более сущностями. Именование отношения осуществляется с помощью грамматического оборота глагола (имеет, определяет, может владеть и т.п.).
Другими словами, сущности представляют собой базовые типы информации, хранимой в базе данных, а отношения показывают, как эти типы данных взаимоувязаны друг с другом. Введение подобных отношений преследует две основополагающие цели:
· обеспечение хранения информации в единственном месте (даже если она используется в различных комбинациях);
· использование этой информации различными приложениями.
Для идентификации требований, в соответствии с которыми сущности вовлекаются в отношения, используются связи. Каждая связь соединяет сущность и отношение и может быть направлена только от отношения к сущности.
Пара значений связей, принадлежащих одному и тому же отношению, определяет тип этого отношения. Практика показала, что для большинства приложений достаточно использовать следующие типы отношений:
1. 1*1 (один-к-одному). Отношения данного типа используются, как правило, на верхних уровнях иерархии модели данных, а на нижних уровнях встречаются сравнительно редко.
2. 1*n (один-к-многим). Отношения данного типа являются наиболее часто используемыми.
3. n*m (многие-к-многим). Отношения данного типа обычно используются на ранних этапах проектирования с целью прояснения ситуации. В дальнейшем каждое из таких отношений должно быть преобразовано в комбинацию отношений типов 1 и 2 (возможно, с добавлением вспомогательных сущностей и с введением новых отношений).
В результате исследования use case были выделены следующие сущности:
Итак, получаем следующие отношения сущностей:
Логическая модель данных представлена на рисунке

Рис. 3.9 Диаграмма сущность-связь
Раздел: Информатика, программирование
Количество знаков с пробелами: 97537
Количество таблиц: 15
Количество изображений: 21
Похожие работы





. предприятия. Для дальнейшего развития Системы необходимо рассчитать экономическую эффективность проекта. Для этого необходимо выбрать направление распространения Системы. Заказчиком системы выступало закрытое акционерное общество "Белгородский бройлер". Произведем расчет экономической эффективности проекта с точки зрения заказного проекта. Структура экономической части при создании программного .





. посильный вклад в изучение организации маркетинга в сфере образовательных услуг на примере Белгородского филиала Современного Гуманитарного Института. 1. Маркетинг образовательных услуг 1.1. Теория и практика маркетинга в сфере образовательных услуг Маркетинг образовательных услуг имеет свои особенности только в сфере практического применения, а все основные теоретические выкладки в нем .

проблема структуризации данных, на ней мы сосредоточим основное внимание.
При проектировании структур д анн ых для автоматизированных систем
1. Сбор информации об объектах решаемой задачи в рамках одной таблицы
(одного отношения) и последующая декомпозиция ее на несколько
взаимосвязанных таблиц на основе процедуры нормализации отношений.
2. Формулирование знаний о системе (определение типов исходных данных и
их взаимосвязей) и требований к обработке данных, получение с помощью CASE-
систе-мы (системы автоматизации проектирования и разработки баз данных)
готовой схемы БД или даже готовой прикладной информационной системы.
3. Ст руктурирование информации для использования в информационной
системе в процессе проведения систем ного анализа на основе совокупности
Базы данных— это компьютеризированная система хранения записей, т.е.
компьютеризированная система, основное назначение которой — хранить
информацию, предоставляя пользователям средства ее извлечения и модифика -
ции. К информ ации может относиться все, что заслуживает внимания отдельного
пользователя или организации, использующей систему, иначе г оворя, все
необходимое для текущей работы данного пользователя или предприятия.
На рис. 1 показана весьма упрошенная схема системы баз данных. Здесь
отражено четыре главных компонента системы, а именно: данные, аппаратное
обеспечение, программное обеспечение и пользователи. Каждый из этих

Системы с базами данных существуют как на самых малых компьютерах, так
и на крупнейших мэйнфреймах. Нет необходимости говорить, что
предоставляемые каж дой конкретной системой средства в некоторой мере зависят
от мощности и возможностей базовой машины. В частности, системы на больших
машинах ("большие системы"), в основном, многопользовательские, тогда как
системы на малых машинах ("малые сис темы"), как правило,
однопользовательские. Однопользоват ельская система ( single-user system) — это
система, в которой одновременно к базе данных может по лучить доступ не более
одного пользователя, а многопользовательская систем а ( multi-user system) — это
такая система, в которой к базе данных могут получить доступ сразу не сколько
пользователей. Как и в схем е на рис. 1, исходя из соображений общности, мы
обычно будем подразумевать именно второй вид систем, хотя, с точки зрения
пользователей, между этими системами фактически не существует большого
различия. Основная задача большинства многопользовательских систем—
позволить каж дому отдельному пользователю работать с ней так, как он мог бы
работать с однопользовательской системой. Различия между этими двумя видами
систем проявляются в их внутренней структуре, и потому практически не видны
К аппаратному обеспечению системы относится следующее.
• Тома вторичной (внешней) памяти (обычно это магнитные диски),
используемые для хранения информации, а также соответствующие устройства
ввода-вывода (дисководы и т.п.), контроллеры устройств, каналы ввода-вывода и

• Аппаратный процессор (или процессоры) вместе с основной (первичной)
памятью, предназначенные для поддержки работы программного обеспечения
Между собственно физической базой данных (т.е. данными, которые реально
хранятся) и пользователями сист емы располагает ся уровень программного
обеспечения, который можно называть по-разному: менеджер базы данных
(database manager), сервер базы данных (database server) или, что более
привычно, система управления базами данных, СУБД (database management
system — DBM S). Все запросы пользо вателей на доступ к базе данных
обрабатываются СУБД. Все имеющиеся средства до бавления файлов (или
таблиц), выборки и обновления данных в этих файлах или таб лицах также
предоставляет СУБД. Основная задача СУБД — предоставить пользова телю базы
данных возможность работать с ней, не вникая в детали на уровне аппа ратного
обеспечения. ( Пользователь СУБД более отстранен от этих деталей, чем при -
кладной программист, применяющий языковую среду программирования.)
Иными словами, СУБД позволяет конечному пользователю рассматривать базу
данных как объект более высокого уровня по сравнению с аппаратным
обеспечением, а также предоставляет в его распоряжение набор операций,
выражаемых в терминах языка вы сокого уровня (например, набор операций,
Пользователей можно разделить на три большие и отчасти перекрывающиеся
• Первая группа — прикладные программисты , которые отвечают за
написание прикладных программ, использующих базу данных. Для этих целей
применимы такие языки, как COBOL, PL/I, C++, Java или какой-нибудь
высокоуровневый язык четвертого поколения. Прикладные программы получают
доступ к базе данных посредством выдачи соответствующего запроса к СУБД
• Вторая группа — конечные п ользо ватели , которые работают с системой
баз данных непосредственно через рабочую станцию или терминал. Конечный
пользователь может получать доступ к базе данных, применяя одно из
интерактивных приложений, упомянутых выше, или же интерфейс,
интегрированный в про граммное обеспечение самой СУБД. Безусловно,
подобный интерфейс также под держивается интерактивными приложениями,
однако эти приложения не создаются пользователями-программистами, а
являются встроенным и в СУБД. Большин ство СУБД включает по крайней мере
одно такое встроенное приложение, а именно — процессор языка запросов,
позволяющий пользов ателю в диалоговом режиме вводить запросы к базе данных
(их часто иначе называют операторами (statement) или командами ( commands)),
например S ELECT или INSERT. Язык SQL — типичный пример языка запросов

Структурой системы называется её расчленение на группы элементов с
указанием связей между ними, неизменное на всё время рассмотрения и дающее
представление о системе в целом. Иначе можно сказать, что структура это
множество элементов и связей м ежду ними, принадлежащее определённому
уровню декомпозиции. Важнейшим стимулом и сутью декомпозиции является
упрощение системы, слишком сложной для рассмотрения целиком.
Архитектура ANSI/SPARC включает три уровня: внутренний, внешний и
концептуальный (рис. 2). В общих чертах они представляют собой следующее.
• Внутренний уро вень (также называемый физическим) наиболее близок к
физическому хранилищу информации, т.е. связан со способ ами сохранения
• Внешний уро вень (также называемый пользовательским логическим)
наиболее близок к пользователя м, т.е. связан со способами представления данных
• Концептуальный уровень (также называемый общим логическим или
просто логическим) является "промежуточным" уровнем между двумя первыми.
Если внешний уровень связан с индивидуальными представлениями
пользователей, тс концептуальный уровень связан с обобщенным представлением
пользователей. Иначе говоря , может существовать несколько внешних
представлений, каждое из которых со стоит из более или менее абстрактного
представления определенной части базы данных и только одно концептуальное
представление, состоящее из абстрактного представления базы данных в целом.
(Вспомните, что большинство пользователей интересует не вся база данных, а
лишь ее некоторая ограниченная часть.) Также существует единственное
внутреннее представление, отражающее способ физического хранения всей базы
Для лучшего понимания этих идей рассмотрим пример, представленный на
рис. 3. Здесь отображено концептуальное представление простой базы данных о
персонале, а также соответствующие ему внутреннее и два внешних
представления (одно — для поль зователя, прим еняющего язык PL/I, а другое —
для пользователя, применяющего язык COBOL). Конечно, этот пример полностью

гипотетичен и мало похож на реальные сис темы, поскольку в нем умышленно
Рис. 3 Пример трех уровней представления базы данных
Рассматриваемый здесь пример нуждается в пояснениях.
На концептуальном уровне база данных содержит информацию о типе
сущности с именем EMPLOYEE (служащий). Каждый экземпляр
сущности EMPLOYEE включает атрибуты номера служащего
EMPLOYEE_NUMBER (длиной шесть символов), номера отдела
DEPARTMENT_NUMBER (длиной четыре символа) и зарплаты
На внутреннем уровне служащие представлены типом хранимой
записи STORED_EMP, длина которой составляет 20 байт. Запись
STORED_EMP содержит че тыре хранимых поля: шестибайтовый префикс
(возможно, содержащий управляющую информацию, такую как флаги или
указатели) и три поля данных, соот ветствующие трем свойствам
сущности, которая представляет служащего. Кроме того, записи STORED
Пользователь, применяющий язык PL /I, имеет дело с соответствующим
внешним представлением базы данных. В нем каждый сотрудник
представлен записью на языке PL/I, содержащей два поля (номера отделов
не представляют интереса для данного пользователя, поэтому в
представлении они опущены ). Тип записи определен с помощью обычной
Аналогично пользователь, прим еняющий язык COBOL, имеет дело с
собственным внешним представлением базы данных, в котором каждый
сотрудник представлен записью на языке COBOL, содержащей, опять ж е,
два поля (в данном случае опущен размер оклада). Тип записи определен с
помощью обычного описания на языке COBOL в соответствии с

Нужно обратить внимание, что в каждом случае соответствующие элементы
данных могут меть различные им ена. Например, к номеру сотрудника
обращаются, как к полю EMPt в представлении для языка PL/I и как к полю
EMPNO в представлении для языка COBOL. Этот же атрибут в концептуальном
представлении имеет имя E MP LOYEE_NUMBER, а во внутреннем представлении
Например, она должна знать, что поле EMPNO в представлении для языка
COBOL образовано из концептуального поля EMPLOYEE NUMBER, которое, в
Такие соответствия, или отображения, явно не показаны на рис. 3.
В данном случае не имеет особого значения, является ли рассматриваемая
Внешний уровень — это индивидуальный уровень пользователя. Как было
сказано главе 1, пользователь может быть прикладным программистом или
конечным пользователем с любым уровнем профессиональной подготовки.
(Особое место среди пользователей занимает адм инистратор базы данных (АБД).
В отличие от остальных пользователей, АБД интересует также концептуальный и
внутренний уровни. Об этом еще будет говориться в следующих двух разделах.)
Для прикладного программиста это либо один из распространенных
языков программирования (например, PL/I, C++ или Java), либо
специальный язык рассматриваемой системы. Такие оригинальные языки
называют языками четвертого поколения на том (не вполне
определенном!) основании, что машинный код, язык ассемблера и такие
языки, как PL /I, можно считать языками трех первых "поколений", а
оригинальные языки модернизированы по сравнению с языкам третьего
поколения так же, как языки третьего поколения улучшены по сравнению
Для конечного пользователя это или специальный язык запросов, или язык
специального назначения, который может быть основан на использовании
форм и меню, разработан специально с учетом требований пол ьзователя и
интерактивно поддерживаться некоторым оперативным приложением.
Для нашего обсуждения важно, что все эти языки включают подъязык
данных, т.е. подмножество операторов всего языка, связанное только с
объектами баз дан ных и операциям и с ними. Иначе говоря, подъязык данных
встроен в базовый язык, который дополнительно обеспечивает различные не
связанные с базами дан ных возможности (такие, как локальные (временные)
переменные, вычислительные операции, логические операции и т.д.). Система
может поддерживать любое количе ство базовых языков и любое количество
подъязыков данных. Однако существует один язык, который поддерживается
практически всеми сегодняшними систем ами. Это язык SQL. Большинство систем
позволяет использовать язык SQL и интерактивно, как самостоятельный язык
запросов, и посредством внедрения его операторов в другие языки

Хотя с точки зрения архитектуры удобно различать подъязык данных и
включающий его базовый язык, на практике они могут быть неразличимы
настолько, насколько это имеет отношение к пользователю. Безусловно, с точки
зрения пользователя пред почтительнее, чтобы они были неразличимы. Е сли они
неразличимы или трудноразли чимы, их называют сильно связанными. Если они
ясно и легко различаются, говорят, что эти языки сл або связ аны. В то время как
некоторые коммерческие. системы (особенно объектные системы) поддерживают
сильную связь, большин ство систем, в частности системы SQL, обычно
поддерживают лишь слабую свя зь. Системы с сильной связью м огли б ы
предоставить пользователю более унифициро ванный набор возможностей, но,
очевидно, они требуют боль ше усилий со стороны системных проектировщиков и
разработчиков, которые, вероятно, рассчитывают на сохранение статус-кво.
В принципе, любой подъязык данных является на самом деле ком бинацией
по крайней мере двух подчиненных языков — языка определения данных (data
definition language — DDL), который поддерживает определения или объявления
объектов базы данных, и языка обработки да нных (data manipulation language —
DML), который поддерживает операции с такими объектами или их обработку.
Например, рассмотрим пользователя языка PL/I (см. рис. 3). Подъязык данных
этого пользователя включает определенные средства языка PL/I, применяемые
Язык определения данных включает некоторые описательные структуры
языка PL/I, необходимые для объявления объектов базы данных. Это сам
оператор DECLARE (DCL), определенные типы данных языка PL/I, а также
возможные специальные дополнения для языка PL/I , предназначенные для
поддержки новых объектов, которые не поддерживаются существующей
Язык обработки данных состоит из тех выполняемых операторов языка PL/
I, которые передают информацию в базу данных и из нее; опять же,
Отдельного пользователя интересу ет лишь некоторая часть всей базы
данных. Кроме того, представление пользователя об этой части будет, безусловно,
чем-то абстрактным по сравнению с выбранным способом физического хранения
данных. В соответствии с терминологией ANSI/SPARC представление отдельного
пользователя называется внешним представлением. Таким образом, внешнее
представление— это содержимое базы данных, каким его видит определенный
пользователь (т.е. для каждого пользователя знешнее представление и есть та
база данных, с которой он работает). Например, пользователь из отдела кадров
может рассматривать базу данных как набор записей с информацией об отделах
плюс набор записей с информацией о служащих и ничего не знать о записях с
информацией о материалах и их поставщиках, с которыми рабо тают пользователи
В общем случае внешнее представление состоит из некоторого множества
экземпляров каждого из м ногих типов внешних записей (которые вовсе не
обязательно должны совпадать с хранимыми записями). Предоставляемый в
распоряжение пользователя подъязык данных всегда определяется в терминах

внешних записей. Напри мер, операция выборки языка обработки данных
осуществляет выборку экземпляров внешних, а не хранимых записей.
Каждое внешнее представление определяется посредством внешн е й схемы,
которая, в основном, состоит из определений записей каждого из типов, присутст -
вующих в этом внешнем представлении (см. рис. 3). Внешняя схема записывает ся
с помощью языка определения данных, являющегося подмножеством подъязы ка
данных пользователя. (Поэтому язык определения данных иногда называют
внешним языком определения данных.) Например, тип внешней записи о работни -
ке можно определить как шестисим вольное поле с номером работника, плюс поле
из пяти десятичных цифр, предназначенное для его зарплаты, и т.д. Кроме того,
может потребоваться определить отображен ие между внешней и исходной
Рис. 4 Детальная схема архитектуры системы баз данных
Концептуальное представление — это представление всей информации
базы данных в несколько более абстрактной форме (как и в случае внешнего
представления по сравнению с физическим способом хранения данных. Однако
концептуальное представление существенно отличается от представления данных
каким-либо отдельным пользователем. Вообще говоря, концептуальное
представление — это представление данных такими, какими они являются на
самом деле, а не такими, какими их вынужден видеть пользователь в рамках,
например, определенного языка или используемого ап паратного обеспечения.
Концептуальное представление состоит из некоторого множества
экземпляров каждого из существующих типов концептуальных зап исей.
Например, оно может состоять из набора экземпляров записей, содержащих
информацию об отделах, набора экземпляров записей, содержащих инф ор мацию
Содержание
1Проектирование базы данных 6
1.1Логическая модель 6
2Создание БД на MSSQL 8
3Разработка структур программы 9
4Разработка алгоритмов решения задачи 10
5Текст программы 11
6Тестирование и отладка программы 12
7Программная документация 13
7.1Руководство пользователя 13
7.1.1Назначение программы 13
7.1.2Условия выполнения программы 13
7.1.3Выполнение программы 13
7.2Руководство системного администратора 13
7.2.1Общие сведения о программе 13
7.2.2Проверка программы 14
Список использованных источников 16
Приложение А 17
Код программы 17
Введение
Данная курсовая работа посвящена разработке программы, предназначенной для работы с БД с СУБД MSSQL. Проектирование приложение выполнялось в соответствии с основными принципами технологии программирования.
Первая часть посвящена проектированию базы данных.
Вторая часть рассматривает последовательность действий при создании БД.
Третья часть описывает структуру приложения.
В четвертой части разрабатывается алгоритм программы и представлено описание пользовательского интерфейса.
Пятая часть посвящена написанию кода программы.
В шестой части производится тестирование и отладка приложения.
Седьмая часть содержит программную документацию к разработанному приложению.
Проектирование базы данных
Для начала определим логическую структуру БД. В результате проектирования должен быть определен состав реляционных таблиц, для каждой таблицы - состав ее атрибутов (столбцов) и логические связи между таблицами. Для каждого атрибута должны быть заданы тип данного, его размер и ограничения целостности.
Логическая модель

Рис.1 – Логическая модель БД
Все внешние ключи (FK) созданы с правилом каскадного удаления и обновления. При этом обновление дочерней таблицы вызовет автоматическое обновление родительской таблицы.
Читайте также: