
Распознавание лиц нейронные сети реферат
Обновлено: 05.07.2024
Технологии распознавания лиц в том или ином виде развиваются уже достаточно давно, однако за последний примерно десяток лет или около того произошел существенный скачок в области разработки и обучения нейронных сетей. Это направление уже является одним из наиболее актуальных и перспективных, наряду с развитием технологий передачи информации, разного рода облачных сервисов и осмысленного анализа больших объемов данных. Сегодня можно уже с уверенностью сказать, что в некоторых прикладных кейсах системы на основе нейронных сетей и распознавания эффективны. Но, далеко не во всех.
Попробуем разобраться, что системы face recognition умеют уже сегодня с точки зрения анализа видео и изображений и где наступает предел.
Развитие технологии
И архитектура, и методики обучения нейросетей продолжают активно развиваться и открывать новые применения на практике. Например, сегодня уже используются так называемые рекуррентные нейронные сети, что позволило существенно повысить качество работы систем face recognition на их основе.
Попробуем объяснить, что стоит за этим понятием. Долгое время логика работы нейронных сетей предусматривала работу с каждым кадром по-отдельности и, соответственно, их отдельный анализ. В результате система достаточно часто принимала ошибочные решения. Логика работы рекуррентных сетей в полной мере позволяет учитывать контекст, когда последовательность кадров рассматривается, как общая совокупность и результат обработки предыдущих кадров влияет на обработку последующих кадров. Таким образом достигается очень высокое качество распознавания. А это, свою очередь, расширяет возможности практического применения.

Фото программного кода
Развивается и подход к использованию вычислительных ресурсов с целью максимально эффективной их утилизации. В системах распознавания лиц задействованы мощности и CPU, и GPU. Перераспределяя различные типы вычислительных задач между ними, а также оптимизируя общий work flow процесса распознавания, можно добиться хороших результатов, когда один условный сервер может “переварить” существенно больше видеопотоков.
Как работает распознавание лиц
Верхнеуровнево принцип работы систем распознавания лиц можно описать так. Под системой мы будем понимать не только саму нейронную сеть, а весь набор компонентов до и после нее, которые задействованы в процессе. На вход системы поступает закодированный видеопоток с камеры, представляющий из себя последовательность кадров, на которых могут быть лица. Данные поступают в так называемый декодер, который декодирует видеопоток в отдельные кадры для их дальнейшей обработки детектором. Далее детектор на каждом кадре определяет наличие в принципе каких-либо объектов в кадре, похожих на лицо.
После этого происходит скоринг детектированных объектов, определяются ключевые точки, позволяющие определить угол поворота лица и его качество. На основе этого лицам проставляются оценки. Объекты, оцененные, как не лица, выкидываются полностью. На дететктированных лицах с набора последовательных кадров строится треклет одного лица (например, когда один и тот же человек прошел в кадре из одного конца помещения в другой и попал в систему сразу на 100 кадрах), исключается дублирование и определяется несколько наилучших из треклета лиц (наивысшая оценка), которые будут участвовать в распознавании. Объекты, отнесенные к лицам, но плохо подходящие для распознавания (например, система понимает, что в кадре лицо, но оно сильно повернуто и для качественного распознавания видимой части лица не хватит) получают низкую оценку.

Фото детектирования объектов
Отобранные лица из треклета обрабатываются нейронной сетью, с них определяется так называемый вектор фич — извлеченный нейросетью уникальный набор признаков, характерный только этой персоне, по сути формирующий уникальный код лица. Произошло распознавание лица.
Далее распознанные лица через тот самый уникальный код лица, сравниваются с базой данных персон в системе. И, если разница не превышает заданного порогового значения, система связывает распознанное в кадре лицо с персоной из базы данных. Если превышает — формируется новая отдельная персона. Произошла персонификация лица.
Таким образом, нейронная сеть является только частью системы распознавания лиц. Чаще всего сетей в системе бывает несколько и каждая важна для достижения качественного результата. Скажем, хорошая сеть извлечения вектора фич и плохая сеть детектора не дадут хороший результат. А все качественно обученные сети в совокупности и позволяют получить высокий уровень распознавания лиц.
Можно ли обмануть систему
И да, и нет. Ответ на этот вопрос сильно зависит от контекста задачи. Есть два крайних случая. Если лицо закрыто полностью или почти полностью, то система его не распознает (даже не детектирует), что логично. Если лицо полностью открыто (и еще имеет высокую оценку), то система точно распознает его корректно. Между ними есть множество разных состояний лица в кадре.

Нанесенный рисунок для обмана камеры наблюдения
Нейросеть, как уже отмечалось выше, извлекает целый набор значений, формирующих вектор фич одного лица. Их может быть несколько десятков или даже сотен. Если часть лица не видна хорошо (например, чем-то закрыта или на лицо нанесен необычный рисунок, призванный спутать сеть), то анализ все равно будет произведен по оставшимся частям. Хотя, вероятность ошибки возрастает, но чаще всего некритично.
Например, если взять какую-то готовую систему распознавания лиц, с конкретным набором сетей (каждая из которых выполняет свою функцию) и логикой работы, то изображение лица с нанесенными на него артефактами может привести к некорректному определению ключевых точек. Система на выходе даст плохой результат, потому что на одном из этапов был сбой (выше мы писали, как важно, чтобы каждый из этапов работал корректно). Однако, если в той же самой системе распознавания “отключить” проблемный этап, то скорее всего она корректно распознает то же самое лицо с артефактами. И таких примеров много. Поэтому, универсального способа обманывать системы face recognition скорее всего нет. Тот, который обманет одну систему, не обманет другую, и наоборот. Чтобы обмануть конкретную систему нужно очень детально понимать именно ее логику работы, а это сильно усложняет задачу.
Чем технология полезна бизнесу
Системы распознавания лиц могут помочь бизнесу автоматизировать некоторые процессы в компаниях, которые сейчас выполняются живыми людьми. Тем самым, сократив участие людей в них или (в будущем) вообще заменив людей на таких участках. Например, такие системы могут быть вспомогательными в вопросах безопасности магазинов, проводя автоматический анализ входящих посетителей и сравнивая их с “черным списком” для более оперативной реакции персонала. Или в вопросах маркетинга, когда алгоритм позволяет распознавать эмоции клиента, анализируя жесты, мимику, глаза и т.д. Это позволит персоналу лучше реагировать на целевые ситуации, делать точечные предложения. Или проводить ретроспективный анализ количества уникальных и лояльных посетителей ресторанов или кафе, также учет рабочего времени своих сотрудников.
Практические реализации в отраслях

Использование видеораспознавания в банкоматах
Области применения решений на основе распознавания лиц неуклонно расширяются. Сегодня среди них и банковская сфера с транспортом, и ритейл с промышленностью, и даже медицина.
Например, установив такое решение, скажем, на банкомате, можно с одном стороны упростить взаимодействие с клиентом, а с другой стороны даже повысить его эффективность. Клиента банка можно идентифицировать как только он подошел к банкомату. Причем, к этому моменту банк уже много знает про клиента: о его остатках, предпочтениях, подключенных услугах и т.п. Все это в совокупности со вторичным факторами, такими как место, время или день месяца, можно предложить клиенту что-то существенно более подходящее. Такие решения еще не нашли массового применения, но уже проходят пилотные тестирования.
Камеры видеонаблюдения с функцией распознавания лиц уже установлены и на турникетах метро в Москве. Конечно, изначально основной задачей было обеспечение безопасности на транспорте и помощь в поиске правонарушителей (когда система сравнивает лица пассажиров с базой данных). Однако сейчас проводятся пилотные тестирования по оплате проезда с применением данной технологии. Надо сказать, что камеры на турникетах метро работают в условиях, близких к идеальным для распознавания. Однако, и в таких условиях вероятность ошибок все еще достаточно большая (например, у сегодняшних систем есть ощутимые ограничения по качественному распознаванию лиц в большой толпе — это отдельное усложняющее условие), а цена такой ошибки в случаях с оплатой высока. Поэтому, такие сервисы появятся, но несколько позже.
Или взять те же домофоны. Уже никого не удивить современными домофонами, которые управляются через приложение на смартфоне из любой точки мира (нужен только доступ в Интернет). А самые продвинутые компании уже тестируют домофонные решения с функцией распознавания лиц, позволяющие открывать дверь по лицу, как только человек подходит к ней. Такие модели еще не готовы для массового применения (в частности, помимо самой технологии нужно подобрать и оптимальный сценарий для пользователя — достаточно ли просто подойти к двери или удобнее будет нажать на любую кнопку без ключа), но пилотные зоны уже есть.
Выводы
За последние годы технологии в области распознавания лиц продвинулись сильно вперед как с точки зрения качества, так и с точки зрения используемых ресурсов (а это означает, что они становятся дешевле). Тем не менее, до уровня живого человека им еще достаточно далеко, поэтому на сегодняшний день такие решения целесообразны в бизнесе лишь для решения каких-то узких точечных задач, но они есть уже сегодня. Однако, общий тренд все же говорит о том, что со временем решения на базе таких технологий все больше будут становиться помощником людей в самых разных задачах. В первую очередь это будет касаться простых и рутинных задач, чтобы люди могли сфокусировать свои усилия на более сложных или творческих.
Друзья, продолжаем рассказ о нейронных сетях, который мы начали в прошлый раз, и о том, как работает технология распознавания лиц.
Что собой представляет нейронная сеть
Нейронная сеть в простейшем случае — математическая модель, состоящая их нескольких слоёв элементов, выполняющих параллельные вычисления. Изначально такая архитектура была создана по аналогии с мельчайшими вычислительными элементами человеческого мозга — нейронами. Минимальные вычислительные элементы искусственной нейронной сети тоже называются нейронами. Нейронные сети обычно состоят из трёх или более слоёв: входного слоя, скрытого слоя (или слоёв) и выходного слоя (рис. 1), в некоторых случаях входной и выходной слои не учитываются, и тогда количество слоёв в сети считается по количеству скрытых слоёв. Такой тип нейронной сети называется перцептрон.

Рис. 1. Простейший перцептрон

Рис. 2. Обучение нейронной сети
Что такое глубокие нейронные сети
Глубокие, или глубинные, нейронные сети — это нейронные сети, состоящие из нескольких скрытых слоёв (Рис.3). Данный рисунок представляет собой изображение глубинной нейронной сети, дающее читателю общее представление о том, как выглядит нейронная сеть. Тем не менее, реальная архитектура глубинных нейронных сетей гораздо сложнее.

Рис. 3. Нейронная сеть с множеством скрытых слоёв
Создатели свёрточных нейронных сетей, конечно, сначала вдохновились биологическими структурами зрительной системы. Первые вычислительные модели, основанные на концепции иерархической организации визуального потока примата, известны как Неокогнитрон [1] Фукушимы (Рис.4). Современное понимание физиологии зрительной системы схоже с типом обработки информации в свёрточных сетях, по крайней мере, для быстрого распознавания объектов.

Рис. 4. Диаграмма, показывающая связи между слоями в модели Неокогнитрон [1].
Позже эта концепция была реализована канадским исследователем Яном ЛеКуном в его свёрточной нейронной сети, созданной им для распознавания рукописных символов [2]. Данная нейронная сеть состояла из слоёв двух типов: свёрточных слоев и субдискретизирующих (subsampling) слоёв (или слоёв подвыборки-pooling). В ней каждый слой имеет топографическую структуру, то есть каждый нейрон связан с фиксированной точкой исходного изображения, а также с рецептивным полем (областью входного изображения, которая обрабатывается данным нейроном). В каждом месте каждого слоя существует целый ряд различных нейронов, каждый со своим набором входных весов, связанных с нейронами в прямоугольном фрагменте предыдущего слоя. Разные входные прямоугольные фрагменты с одинаковым набором весов связаны с нейронами из разных локаций.

Рис. 5. Диаграмма свёрточной нейронной сети
Как правило, глубинные нейронные сети изображены в упрощённом виде: как стадии обработки, которые иногда называют фильтрами. Каждая стадия отличается от другой рядом характеристик, таких как размер рецептивного поля, тип признаков, который сеть учится распознавать в данном слое, и тип вычислений, выполняемых на каждой стадии.
Сферы применения глубинных нейронных сетей, в том числе свёрточных сетей, не ограничиваются распознаванием лиц. Они широко используются для распознавания речи и аудио-сигналов, обработки показаний с разного типа сенсоров или для сегментации сложных многослойных изображений (таких как спутниковые карты [3]) или медицинских изображений (рентгеновские снимки, снимки фМРТ- см. здесь).
Нейронные сети в биометрии и распознавании лиц
Для достижения высокой точности распознавания нейронная сеть предобучается на большом массиве изображений, например, таком, как в базе данных MegaFace .Это основной метод обучения для распознавания лиц.

Рис. 6. База данных MegaFace содержит 1 млн. изображений более 690 тыс. людей

Рис. 7. Процесс распознавания лица
Определение качества алгоритма
Точность
Когда мы выбираем, какой алгоритм применить к задаче распознавания объекта или лица, мы должны иметь средство сравнения эффективности различных алгоритмов. В этой части мы опишем инструменты, с помощью которых это делается [5].
Оценка качества работы системы распознавания лиц проводится с помощью набора метрик, которые соответствуют типичным сценариям использования системы для аутентификации с помощью биометрии.
Как правило, работа любой нейронной сети может быть измерена с точки зрения точности: после настройки параметров и завершения процесса обучения сеть проверяется на тестовом множестве, для которого мы имеем отклик учителя, но который отделён от обучающего набора. Как правило, этот параметр является количественной мерой: число (часто в процентах), которое показывает, насколько хорошо система способна распознавать новые объекты. Еще одна типичная мера — это ошибка (может быть выражена как в процентах, так и в числовом эквиваленте). Тем не менее, для биометрии существуют более точные меры.
В биометрии вообще и биометрии для распознавания лиц, в частности, существует два типа приложений: верификация и идентификация. Верификация представляет собой процесс подтверждения определённой личности путём сравнения изображения индивида (вектора признаков лица или другого вектора признаков, например, сетчатки или отпечатков пальцев) с одним или несколькими ранее сохранёнными шаблонами. Идентификация — это процесс определения личности индивида. Биометрические образцы собирают и сравнивают со всеми шаблонами в базе данных. Существует идентификация в замкнутом множестве признаков, если предполагается, что человек существует в базе данных. Таким образом, распознавание объединяет один или оба термина — верификацию и идентификацию.
Существует ряд методов для оценки качества работы системы (как для задачи верификации, так и идентификации). О них мы расскажем в следующий раз. А вы оставайтесь с нами и не стесняйтесь оставлять комментарии и задавать вопросы.

С целью повышения уровня общественной безопасности, ежегодно устанавливаются дополнительные камеры общественного видеонаблюдения. Благодаря интеграции систем распознавания лиц, задержание преступников и поиск видеодоказательств совершенного преступления стал в разы эффективнее. Однако на практике встречаются ситуации, при которых возможна идентификация личности лишь на небольшом участке области обзора камеры, вследствие чего информация о передвижении человека при исчезновении его лица из кадра теряется и дальнейшее идентифицирование его личности возможно только с использованием человеческих ресурсов. В данной статье представлено теоретическое описание системы распознавания и отслеживания лиц. С помощью эталонных фотографий выбранных личностей, система запоминает их лица. В случае появления во входном видеопотоке знакомых лиц, система распознает соответствующих людей и продолжает отслеживание даже в случае исчезновения лица из кадра. Для реализации описанной системы были рассмотрены такие задачи, как детекция объектов, идентификация личности, отслеживание перемещений и современные подходы в их решении.
Ключевые слова: обнаружение, распознавание, отслеживание.
Введение
В наши дни алгоритмы искусственного интеллекта в сфере компьютерного зрения занимают ключевое место в сфере безопасности и применяются не только частными компаниями, но и государственными организациями. В технически развитых городах-миллионниках благодаря камерам общественного видеонаблюдения, эффективность выполнения задач общественной безопасности возросла на порядок. Так, например, с внедрением системы распознавания лиц в Московском метро, ежемесячно задерживаются от пяти до десяти разыскиваемых преступников.
В данной работе представлено теоретическое описание и процесс разработки системы распознавания и отслеживания лиц, которая актуальна для следующих задач:
– Идентификация и отслеживание преступников.
– Поддержка и ускорение расследований
– Поиск пропавших детей и дезориентированных взрослых.
Для достижения данной цели были поставлены следующие задачи:
– Изучение современных технологий, лежащих в основе решения.
– Извлечение кадра из входного видеопотока.
– Детектирование областей, в которых находятся люди.
– Идентификация личностей обнаруженных людей по биометрическим данным.
– Соотношение идентификационной информации с областью, содержащей человека.
– Отслеживание передвижения людей от кадра к кадру.
В открытом доступе находятся множество подходов к решению поставленных задач по отдельности, но не было найдено ни одного открытого решения, которое бы реализовало описанную цель.
Задача детекции
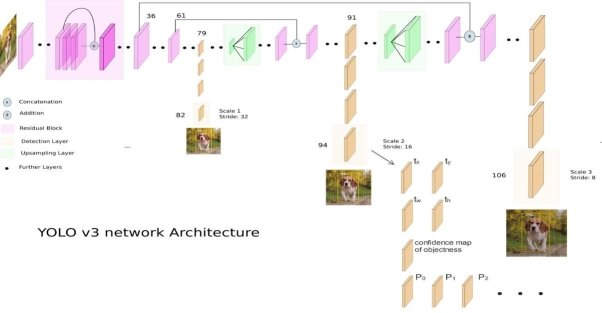
Детектирование людей на изображениях, как и детектирование лиц являются частными задачами более общей — детектирования объектов. В этой статье для детекции людей на изображении используется самая известная модель детекции объектов — YOLOv3 [4]. С концепцией архитектуры энкодера-декодера и одностадийным подходом, данная сеть работает в три раза быстрее, чем SSD [8], и показывает точность, сравнимую с Faster-RCNN [7].
YOLOv3 (You Only Look Once) [4] — многоклассовый детектор объектов. Данная модель использует в качестве основы (backbone) сеть Darknet-53, состоящую из 53 сверточных слоев для извлечения признаков из изображения и применяет в своей архитектуре такие известные практики, как:
− Residual blocks with shortcut-connections. Как и в сетях семейства ResNet [5], такие блоки предотвращают затухание градиентов при обучении нейронных сетей, что позволяет использовать более глубокие архитектуры без потери качества их выразительности.
− Upsampling with concatenations of feature maps. Данный метод позволяет получить более значимую семантическую информацию из апсемплированных признаков и более точную информацию из ранних карт признаков.
RetinaFace
Для распознавания лиц на изображениях используется нейронная сеть RetinaFace. Несмотря на то, что обнаружение лиц является частным случаем задачи детекции объектов, было разработано множество решений, одним из которых является модель RetinaFace [3]. Данная нейронная сеть является устойчивым одностадийным детектором, предоставляющим попиксельную локализацию для лиц разного масштаба и показывающим наилучшую точность среди всех современных моделей на момент публикации в 2019 году. Принимая на вход изображение, данная модель выводит позитивные шаблоны, состоящие из векторов, содержащих вероятность принадлежности области к области лица, границы области лица, пять лицевых ориентиров и плотные 3D грани лица, спроецированные на плоскость изображения.
Идентификация личностей
Идентификация личности по биометрическим данным — самая обсуждаемая область компьютерного зрения последних нескольких лет. В рамках данной работы, в качестве биометрических данных будем рассматривать человеческие лица и подход, основанный на вычислении эмбеддингов.
В задаче идентификации личности одним из ключевых шагов является очистка изображения от лишней информации. Выделяя области, содержащие человеческие лица, мы оставляем все необходимое данные для вычисления признаков средствами сверточных нейронных сетей, которые и будут составлять наши эмбеддинги. Одной из моделей идентификации личности является FaceNet [2] — модель компании Google, представленная в 2015 году. Данная нейронная сеть обучена отображать область изображения, содержащую человеческое лицо в точку многомерного пространства, где расстояние между этими точками напрямую соответствует мере сходства лица. В статье [2] представлены особенности обучения данной сети, сравнение нескольких глубоких архитектур, их результаты и тестирование размерностей выходных векторов.
Отслеживание объектов
Задача отслеживания объектов в видеопотоке заключается в:
– Обнаружении заданных объектов на входном видеопотоке.
– Присвоении уникальных меток каждой области с объектом.
– Сопоставлении одних и тех же областей от кадра к кадру.
Одним из самых популярных и точных подходов к задаче отслеживания является алгоритм DeepSort [6]. Данный алгоритм представлен в 2017 году и является улучшением алгоритма SORT [1]. Используя сверточную нейронную сеть для интегрирования информации о внешнем виде, DeepSort показывает снижение в переключении идентификаторов на 45 % по сравнению со своим предшественником.
Общая структура
При реализации системы распознавания и отслеживания лиц, были выделены следующие этапы:
- Детектирование людей.
- Присвоение уникальных меток обнаруженным людям в соответствии с детекциями и уникальными метками на прошлом кадре (этап отслеживания).
- Детекция лиц.
- Идентификация личности.
- Соотношение лиц и людей на видеокадре.
- Соотношение идентификационной информации с уникальными метками.
Считывая новый кадр из видеопотока, первым делом YOLOv3 [4] определяет ограничивающие прямоугольники, в которых содержатся люди (1), после чего, DeepSort [6] присваивает этим областям уникальные метки
Определение областей (1) и (3) происходит отдельно по всему кадру в силу архитектур используемых моделей. Такой подход предполагает более высокую скорость работы, в отличии от подачи на вход сети RetinaFace отдельных областей (1) изображения.
Для того, чтобы идентифицировать человека по его лицу с помощью эмбеддингов, нам нужны эталонные значения. Подготовив несколько изображений каждого человека, которого надо идентифицировать, мы считаем такие же векторы по каждой области лица, усредняем их и принимаем в качестве эталонных. Данный этап подготовки происходит до извлечения первого кадра из видеоряда.
После получения векторов по каждой области лица на текущем кадре, мы считаем l2-расстояние между эталонными и новыми, на основании чего делаем вывод, известен ли системе этот человек или нет, и если известен, то кто это, сохраняя полученные идентификационные метки (4), вместе с расстоянием в качестве значения уверенности.
Сохранив соотношения (1) с (2) и (3) с (4), мы соотносим (1) с (3) и с (4) следующим образом. Находим координаты середины ограничивающего лицо прямоугольника и смотрим, находится ли он в рассматриваемой области человека. Если находится, то запоминаем данное соотношение и переходим к следующему лицу.
После получения такого соотношения, мы сравниваем значение уверенности идентификационной информации (4) с соотношением, полученным на предыдущем кадре. Если расстояние между эмбеддингами меньше, то мы обновляем идентификационную информацию рассматриваемой области, в противном случае используем соотношение, вычисленное ранее.
Выводы
В работе исследованы и применены на практике современные нейросетевые подходы к решению поставленной задачи, в результате чего была разработана система определения и отслеживания людей. В ходе ее разработки были решены следующие практические задачи:
– Извлечение кадра из видеопотока.
– Детектирование областей, в которых находятся люди.
– Идентификация личности по биометрическим данным.
– Соотношение идентификационной информации с областью, содержащей человека.
– Отслеживание передвижения людей от кадра к кадру.
Основные термины (генерируются автоматически): идентификационная информация, Идентификация личности, кадр, нейронная сеть, задача, лицо, область, область лица, отслеживание лиц, Соотношение.
ИНС (искусственные нейросети) – это математическая модель функционирования традиционных для живых организмов нейросетей, которые представляют собой сети нервных клеток. Как и в биологическом аналоге, в искусственных сетях основным элементом выступают нейроны, соединенные между собой и образующие слои, число которых может быть разным в зависимости от сложности нейросети и ее назначения (решаемых задач).
Пожалуй, самая популярная задача нейросетей – распознавание визуальных образов. Сегодня создаются сети, в которых машины способны успешно распознавать символы на бумаге и банковских картах, подписи на официальных документах, детектировать объекты и т.д. Эти функции позволяют существенно облегчить труд человека, а также повысить надежность и точность различных рабочих процессов за счет отсутствия возможности допущения ошибки из-за человеческого фактора.
Нейросеть – это математическая модель в виде программного и аппаратного воплощения, строящаяся на принципах функционирования биологических нейросетей. Сегодня такие сети активно используют в практических целях за счет возможности не только разработки, но и обучения. Их применяют для прогнозирования, распознавания образов, машинного перевода, распознавания аудио и т.д.
Применение нейронной сети в распознавании изображений
Работа с изображениями — важная сфера применения технологий Deep Learning. Глобально все изображения со всех камер мира составляют библиотеку неструктурированных данных. Задействовав нейросети, машинное обучение и искусственный интеллект, эти данные структурируют и используют для выполнения различных задач: бытовых, социальных, профессиональных и государственных, в частности, обеспечения безопасности.
Основой всех архитектур для видеонаблюдения является анализ, первой фазой которого будет распознавание изображения (объекта). Затем искусственный интеллект с помощью машинного обучения распознает действия и классифицирует их.
Для того чтобы распознать изображение, нейронная сеть должна быть прежде обучена на данных. Это очень похоже на нейронные связи в человеческом мозге — мы обладаем определенными знаниями, видим объект, анализируем его и идентифицируем.
Нейросети требовательны к размеру и качеству датасета, на котором она будет обучаться. Датасет можно загрузить из открытых источников или собрать самостоятельно
На практике означает, что до определённого предела чем больше скрытых слоев в нейронной сети, тем точнее будет распознано изображение. Как это реализуется?
Картинка разбивается на маленькие участки, вплоть до нескольких пикселей, каждый из которых будет входным нейроном. С помощью синапсов сигналы передаются от одного слоя к другому. Во время этого процесса сотни тысяч нейронов с миллионами параметров сравнивают полученные сигналы с уже обработанными данными.
Проще говоря, если мы просим машину распознать фотографию кошки, мы разобьем фото на маленькие кусочки и будем сравнивать эти слои с миллионами уже имеющихся изображений кошек, значения признаков которых сеть выучила.
В какой-то момент увеличение числа слоёв приводит к просто запоминанию выборки, а не обучению. Далее - за счёт хитрых архитектур.
Как нейросеть решает задачи по распознаванию образов
Нейронная сеть для распознавания изображений – это, пожалуй, наиболее популярный способ применения НС. При этом вне зависимости от особенностей решаемых задач, она работает по этапам, наиболее важные среди которых рассмотрим ниже.

В качестве распознаваемых образов могут выступать самые разные объекты, включая изображения, рукописный или печатный текст, звуки и многое другое. При обучении сети ей предлагаются различные образцы с меткой того, к какому именно типу их можно отнести. В качестве образца применяется вектор значений признаков, а совокупность признаков в этих условиях должна позволить однозначно определить, с каким классом образов имеет дело НС.
Важно учитывать, что исходные данные для нейросети должны быть однозначны и непротиворечивы, чтобы не возникали ситуации, когда НС будет выдавать высокие вероятности принадлежности одного объекта к нескольким классам.
В целом создание нейронной сети для распознавания изображений включает в себя:
Читайте также: