
Методы ближайшего соседа и k ближайших соседей реферат
Обновлено: 02.07.2024
Одно из самых популярных приложений машинного обучения — решение задач классификации. Задачи классификации — это ситуации, когда у вас есть набор данных, и вы хотите классифицировать наблюдения из этого набора в определенную категорию.
Известный пример — спам-фильтр для электронной почты. Gmail использует методы машинного обучения с учителем, чтобы автоматически помещать электронные письма в папку для спама в зависимости от их содержания, темы и других характеристик.
Две модели машинного обучения выполняют большую часть работы, когда дело доходит до задач классификации:
- Метод K-ближайших соседей
- Метод К-средних
Из этого руководства вы узнаете, как применять алгоритмы K-ближайших соседей и K-средних в коде на Python.
Модели K-ближайших соседей
Алгоритм K-ближайших соседей является одним из самых популярных среди ML-моделей для решения задач классификации.
Обычным упражнением для студентов, изучающих машинное обучение, является применение алгоритма K-ближайших соседей к датасету, категории которого неизвестны. Реальным примером такой ситуации может быть случай, когда вам нужно делать предсказания, используя ML-модели, обученные на секретных правительственных данных.
В этом руководстве вы изучите алгоритм машинного обучения K-ближайших соседей и напишите его реализацию на Python. Мы будем работать с анонимным набором данных, как в описанной выше ситуации.
Используемый датасет
Первое, что вам нужно сделать, это скачать набор данных, который мы будем использовать в этом руководстве. Вы можете скачать его на Gitlab.
Далее вам нужно переместить загруженный файл с датасетом в рабочий каталог. После этого откройте Jupyter Notebook — теперь мы можем приступить к написанию кода на Python!
Необходимые библиотеки
Чтобы написать алгоритм K-ближайших соседей, мы воспользуемся преимуществами многих Python-библиотек с открытым исходным кодом, включая NumPy, pandas и scikit-learn.
Начните работу, добавив следующие инструкции импорта:
Импорт датасета
Следующий шаг — добавление файла classified_data.csv в наш код на Python. Библиотека pandas позволяет довольно просто импортировать данные в DataFrame.
Поскольку датасет хранится в файле csv, мы будем использовать метод read_csv :
Отобразив полученный DataFrame в Jupyter Notebook, вы увидите, что представляют собой наши данные:

Затем давайте посмотрим на показатели (признаки), содержащиеся в этом датасете. Вы можете вывести список имен столбцов с помощью следующей инструкции:
Поскольку этот набор содержит секретные данные, мы понятия не имеем, что означает любой из этих столбцов. На данный момент достаточно признать, что каждый столбец является числовым по своей природе и поэтому хорошо подходит для моделирования с помощью методов машинного обучения.
Стандартизация датасета
Поскольку алгоритм K-ближайших соседей делает прогнозы относительно точки данных (семпла), используя наиболее близкие к ней наблюдения, существующий масштаб показателей в датасете имеет большое значение.
Из-за этого специалисты по машинному обучению обычно стандартизируют набор данных, что означает корректировку каждого значения x так, чтобы они находились примерно в одном диапазоне.
К счастью, библиотека scikit-learn позволяет сделать это без особых проблем.
Для начала нам нужно будет импортировать класс StandardScaler из scikit-learn. Для этого добавьте в свой скрипт Python следующую команду:
Этот класс во многом похож на классы LinearRegression и LogisticRegression , которые мы использовали ранее в этом курсе. Нам нужно создать экземпляр StandardScaler , а затем использовать этот объект для преобразования наших данных.
Во-первых, давайте создадим экземпляр класса StandardScaler с именем scaler следующей инструкцией:
Теперь мы можем обучить scaler на нашем датасете, используя метод fit:
Теперь мы можем применить метод transform для стандартизации всех признаков, чтобы они имели примерно одинаковый масштаб. Мы сохраним преобразованные семплы в переменной scaled_features :
В качестве результата мы получили массив NumPy со всеми точками данных из датасета, но нам желательно преобразовать его в формат DataFrame библиотеки pandas.
К счастью, сделать это довольно легко. Мы просто обернем переменную scaled_features в метод pd.DataFrame и назначим этот DataFrame новой переменной scaled_data с соответствующим аргументом для указания имен столбцов:
Теперь, когда мы импортировали наш датасет и стандартизировали его показатели, мы готовы разделить этот набор данных на обучающую и тестовую выборки.
Разделение датасета на обучающие и тестовые данные
Мы будем использовать функцию train_test_split библиотеки scikit-learn в сочетании с распаковкой списка для создания обучающих и тестовых датасетов из нашего набора секретных данных.
Во-первых, вам нужно импортировать train_test_split из модуля model_validation библиотеки scikit-learn:
Затем нам необходимо указать значения x и y , которые будут переданы в функцию train_test_split .
Значения x представляют собой DataFrame scaled_data , который мы создали ранее. Значения y хранятся в столбце "TARGET CLASS" нашей исходной таблицы raw_data .
Вы можете создать эти переменные следующим образом:
Затем вам нужно запустить функцию train_test_split , используя эти два аргумента и разумный test_size . Мы будем использовать test_size 30%, что дает следующие параметры функции:
Теперь, когда наш датасет разделен на данные для обучения и данные для тестирования, мы готовы приступить к обучению нашей модели!
Обучение модели K-ближайших соседей
Начнем с импорта KNeighborsClassifier из scikit-learn:
Затем давайте создадим экземпляр класса KNeighborsClassifier и назначим его переменной model .
Для этого требуется передать параметр n_neighbors , который равен выбранному вами значению K алгоритма K-ближайших соседей. Для начала укажем n_neighbors = 1 :
Теперь мы можем обучить нашу модель, используя метод fit и переменные x_training_data и y_training_data :
Теперь давайте сделаем несколько прогнозов с помощью полученной модели!
Делаем предсказания с помощью алгоритма K-ближайших соседей
Способ получения прогнозов на основе алгоритма K-ближайших соседей такой же, как и у моделей линейной и логистической регрессий, построенных нами ранее в этом курсе: для предсказания достаточно вызвать метод predict , передав в него переменную x_test_data .
В частности, вот так вы можете делать предсказания и присваивать их переменной predictions :
Давайте посмотрим, насколько точны наши прогнозы, в следующем разделе этого руководства.
Оценка точности нашей модели
В руководстве по логистической регрессии мы видели, что scikit-learn поставляется со встроенными функциями, которые упрощают измерение эффективности классификационных моделей машинного обучения.
Для начала импортируем в наш отчет две функции classification_report и confusion_matrix :
Теперь давайте поработаем с каждой из них по очереди, начиная с classification_report . С ее помощью вы можете создать отчет следующим образом:
Точно так же вы можете сгенерировать матрицу ошибок:
Глядя на такие метрики производительности, похоже, что наша модель уже достаточно эффективна. Но ее еще можно улучшить.
В следующем разделе будет показано, как мы можем повлиять на работу модели K-ближайших соседей, выбрав более подходящее значение для K .
Метод локтя включает в себя итерацию по различным значениям K и выбор значения с наименьшей частотой ошибок при применении к нашим тестовым данным.
Для начала создадим пустой список error_rates . Мы пройдемся по различным значениям K и добавим их частоту ошибок в этот список.
Затем нам нужно создать цикл Python, который перебирает различные значения K , которые мы хотим протестировать, и на каждой итерации выполняет следующее:
- Создает новый экземпляр класса KNeighborsClassifier из scikit-learn.
- Тренирует эту модель, используя наши обучающие данные.
- Делает прогнозы на основе наших тестовых данных.
- Вычисляет долю неверных предсказаний (чем она ниже, тем точнее наша модель).
Реализация описанного цикла для значений K от 1 до 100:
Давайте визуализируем, как изменяется частота ошибок при различных K , используя matplotlib — plt.plot(error_rates) :

Как видно из графика, мы достигаем минимальной частоты ошибок при значении K, равном приблизительно 35. Это означает, что 35 является подходящим выбором для K , который сочетает в себе простоту и точность предсказаний.
Модели кластеризации методом K-средних
Алгоритм кластеризации K-средних обычно является первой моделью машинного обучения без учителя, которую изучают студенты.
Он позволяет специалистам по машинному обучению создавать группы точек данных со схожими количественными характеристиками в датасете. Это полезно для решения таких задач, как формирование клиентских сегментов или определение городских районов с высоким уровнем преступности.
В этом разделе вы узнаете, как создать свой первый алгоритм кластеризации K-средних на Python.
Используемый датасет
В этом руководстве мы будем использовать набор данных, созданный с помощью scikit-learn.
Давайте импортируем функцию make_blobs из scikit-learn, чтобы сгенерировать необходимые данные. Откройте Jupyter Notebook и запустите свой скрипт Python со следующей инструкцией:
Теперь давайте воспользуемся функцией make_blobs , чтобы получить фиктивные данные!
В частности, вот как вы можете создать набор данных из 200 семплов, который имеет 2 показателя и 4 кластерных центров. Стандартное отклонение для каждого кластера будет равно 1.8.
Если вы выведите объект raw_data , то заметите, что на самом деле он представляет собой кортеж Python. Первым его элементом является массив NumPy с 200 наблюдениями. Каждое наблюдение содержит 2 признака (как мы и указали в нашей функции make_blobs ).
Теперь, когда наши данные созданы, мы можем перейти к импорту других необходимых библиотек с открытым исходным кодом в наш скрипт Python.
Импортируемые библиотеки
В этом руководстве будет использоваться ряд популярных библиотек Python с открытым исходным кодом, включая pandas, NumPy и matplotlib. Продолжим написание скрипта, добавив следующие импорты:
Первая группа библиотек в этом блоке кода предназначена для работы с большими наборами данных. Вторая группа предназначена для визуализации результатов.
Теперь перейдем к созданию визуального представления нашего датасета.
Визуализация датасета
В функции make_blobs мы указали, что в нашем наборе данных должно быть 4 кластерных центра. Лучший способ убедиться, что все действительно так, — это создать несколько простых точечных диаграмм.
Для этого мы воспользуемся функцией plt.scatter , передав в нее все значения из первого столбца нашего набора данных в качестве X и соответствующие значения из второго столбца в качестве Y :

Примечание: ваш датасет будет отличаться от моего, поскольку его данные сгенерированы случайным образом.
Представленное изображение, похоже, указывает на то, что в нашем датасете всего три кластера. Нам так кажется потому, что два кластера расположены очень близко друг к другу.
Если при построении мы будем использовать уникальный цвет для каждого кластера, то мы легко различим 4 группы наблюдений. Вот код для этого:

Теперь мы видим, что в нашем наборе данных есть четыре уникальных кластера. Давайте перейдем к построению нашей модели на основе метода K-средних на Python!
Создание и обучение модели кластеризации K-средних
Для того, чтобы начать использовать метод K-средних, импортируем соответствующий класс из scikit-learn. Для этого добавьте в свой скрипт следующую команду:
Затем давайте создадим экземпляр класса KMeans с параметром n_clusters=4 и присвоим его переменной model :
Теперь обучим нашу модель, вызвав на ней метод fit и передав первый элемент нашего кортежа raw_data :
В следующем разделе мы рассмотрим, как делать прогнозы с помощью модели кластеризации K-средних.
Прежде чем двигаться дальше, я хотел бы указать на одно различие, которое вы, возможно заметили, между процессом построения модели, используя метод K-средних (он является алгоритмом кластеризации без учителя), и алгоритмами машинного обучения с учителем, с которыми мы работали ранее в данном курсе.
Оно заключается в том, что нам не нужно разбивать набор данных на обучающую и тестовую выборки. Это важное различие, так как вам никогда не нужно разделять таким образом датасет при построении моделей машинного обучения без учителя!
Применяем нашу модель кластеризации K-средних для получения предсказаний
Специалисты по машинному обучению обычно используют алгоритмы кластеризации, чтобы делать два типа прогнозов:
- К какому кластеру принадлежит каждая точка данных.
- Где находится центр каждого кластера.
Теперь, когда наша модель обучена, мы можем легко сгенерировать такие предсказания.
Во-первых, давайте предскажем, к какому кластеру принадлежит каждая точка данных. Для этого обратимся к атрибуту labels_ из объекта model с помощью оператора точки:
Таким образом мы получаем массив NumPy с прогнозами для каждого семпла:
Чтобы узнать, где находится центр каждого кластера, аналогичным способом обратитесь к атрибуту cluster_centers_ :
Получаем двумерный массив NumPy, содержащий координаты центра каждого кластера. Он будет выглядеть так:
Визуализация точности предсказаний модели
Последнее, что мы сделаем в этом руководстве, — это визуализируем точность нашей модели. Для этого можно использовать следующий код:
Он генерирует две точечные диаграммы. Первая показывает кластеры, используя фактические метки из нашего датасета, а вторая основана на предсказаниях, сделанных нашей моделью. Вот как выглядит результат:

Хотя окраска двух графиков разная, вы можете видеть, что созданная модель довольно хорошо справилась с предсказанием кластеров в нашем наборе данных. Вы также можете заметить, что модель не идеальна: точки данных, расположенные на краях кластеров, в некоторых случаях классифицируются неверно.
И последнее, о чем следует упомянуть, говоря об оценке точности нашей модели. В этом примере мы знали, к какому кластеру принадлежит каждое наблюдение, потому что мы сами создали этот набор данных.
Такая ситуация встречается крайне редко. Метод К-средних обычно применяется, когда не известны ни количество кластеров, ни присущие им качества. Таким образом, специалисты по машинному обучению используют данный алгоритм, чтобы обнаружить закономерности в датасете, о которых они еще ничего не знают.
Заключительные мысли
В этом руководстве вы научились создавать модели машинного обучения на Python, используя методы K-ближайших соседей и K-средних.
Вот краткое изложение того, что вы узнали о моделях K-ближайших соседей в Python:
- Как засекреченные данные являются распространенным инструментом для обучения студентов решению задач K-ближайших соседей.
- Почему важно стандартизировать набор данных при построении моделей K-ближайших соседей.
- Как разделить датасет на обучающую и тестирующую выборки с помощью функции train_test_split .
- Способ обучить вашу первую модель K-ближайших соседей и как получить сделанные ее прогнозы.
- Как оценить эффективность модели K-ближайших соседей.
- Метод локтя для выбора оптимального значения K в модели K-ближайших соседей.
А вот краткое изложение того, что вы узнали о моделях кластеризации K-средних в Python:
Цель данной работы: на основе общей математической теории распознавания подробно изучить один из методов этой теории: метод ближайших соседей, и использовать его для задач: первая – классификации видов преступления и вторая – по экономическим данным определения географического региона в зависимости от ряда факторов.
В работе решаются следующие задачи: выявление особенности изучаемого метода в зависимости от выбора признаков обучающей выборки (дискретные и непрерывные); сбор данных для создания информационной базы данных (информация о преступлениях против личности и против порядка управления, данные по трудовой деятельности граждан, осуществляющих деятельность в Центральной и Восточной части России).
Содержание
Введение.
Глава 1. Общая теория распознавания образов.
Глава 2. Алгоритм ближайшего соседа.
Глава3. Практическая реализация алгоритма ближайшего соседа.
Заключение.
Список литературы.
Приложения.
Прикрепленные файлы: 1 файл
диплом.docx
МЕТОД БЛИЖАЙШИХ СОСЕДЕЙ В ЗАДАЧЕ
Выпускная квалификационная работа
Введение.
Человек, сталкиваясь с новой задачей, использует свой жизненный опыт, вспоминает аналогичные ситуации, которые когда-то с ним происходили. О свойствах нового объекта мы судим, полагаясь на похожие знакомые наблюдения.
Распознавание – это отнесение конкретного объекта (реализации), представленного значениями его свойств (признаков), к одному из фиксированного перечня образов (классов) по определённому решающему правилу в соответствии с поставленной целью.
В последние годы распознавание образов находит все большее применение. Распознавание речи, печатного и рукописного текста, различных изображений, отнесения произвольного объекта к конкретному классу, без дополнительных вычислений и наблюдений значительно упрощает взаимодействие человека с компьютером, создает предпосылки для применения различных систем искусственного интеллекта.
Способность восприятия внешнего мира в форме образов позволяет с определенной достоверностью узнавать бесконечное число объектов на основании ознакомления с конечным их числом, а объективный характер основного, уже известного свойства образов позволяет моделировать процесс их распознавания.
Цель данной работы: на основе общей математической теории распознавания подробно изучить один из методов этой теории: метод ближайших соседей, и использовать его для задач: первая – классификации видов преступления и вторая – по экономическим данным определения географического региона в зависимости от ряда факторов.
В работе решаются следующие задачи:
- выявление особенности изучаемого метода в зависимости от выбора признаков обучающей выборки (дискретные и непрерывные);
- сбор данных для создания информационной базы данных (информация о преступлениях против личности и против порядка управления, данные по трудовой деятельности граждан, осуществляющих деятельность в Центральной и Восточной части России);
- изучение языка программирования Java, его особенностей, основных библиотек и классов;
- разработка работоспособного программного продукта, который реализует метод ближайших соседей;
- внедрение созданного программного продукта на предприятии.
- Оптическое распознавание символов;
- Распознавание штрих-кодов;
- Распознавание автомобильных номеров;
- Распознавание лиц;
- Распознавание речи;
- Распознавание изображений;
- Распознавание локальных участков земной коры, в которых находятся месторождения полезных ископаемых;
- Классификация документов.
- В случае использования метода для классификации объект присваивается тому классу, который является наиболее распространённым среди k соседей данного элемента, классы которых уже известны.
- В случае использования метода для регрессии, объекту присваивается среднее значение по k ближайшим к нему объектам, значения которых уже известны.
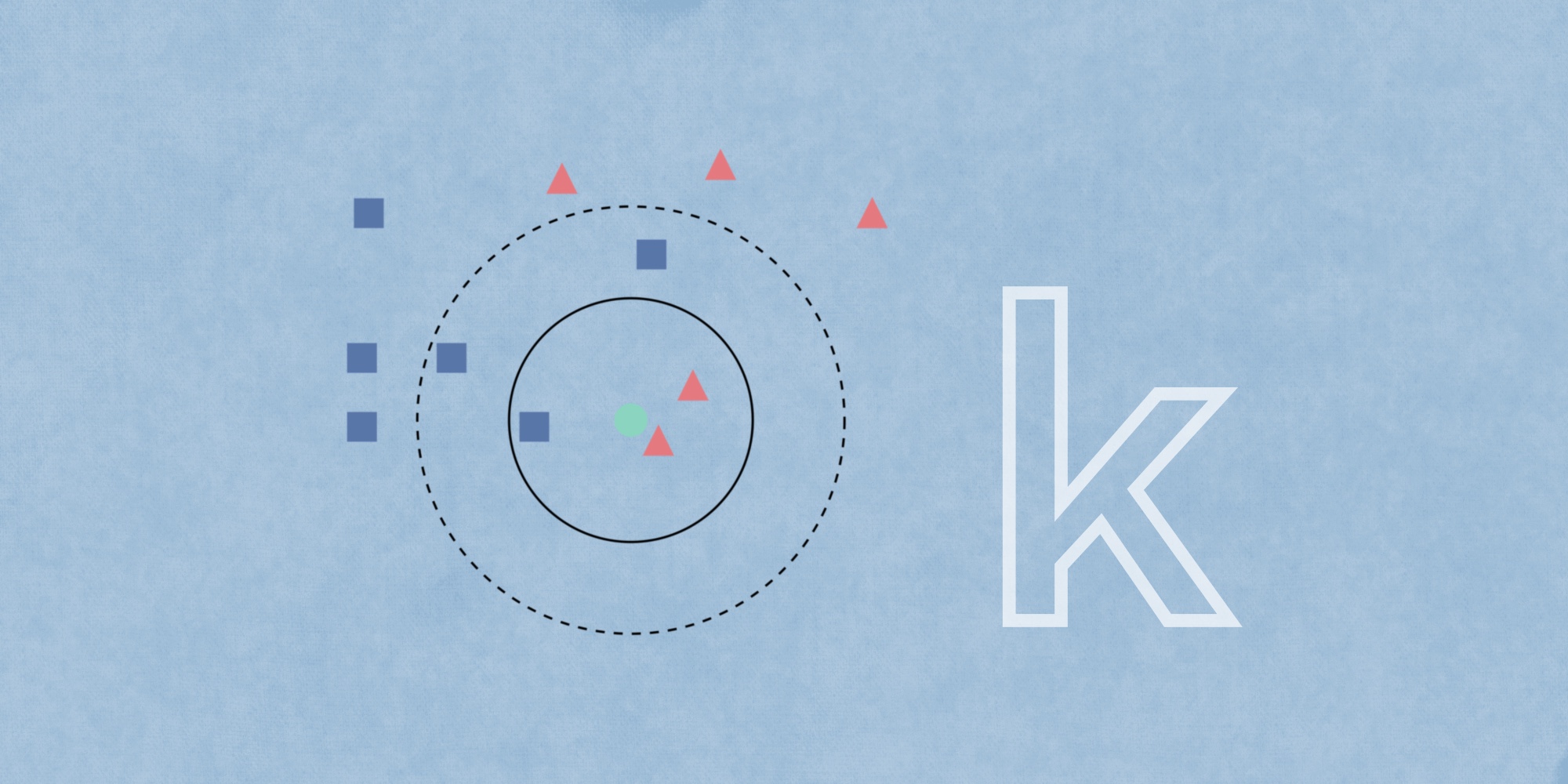
- У нас есть тестовый образец в виде зеленого круга. Синие квадраты мы обозначим как класс 1, красные треугольники – класс 2.
- Зеленый круг должен быть классифицирован как класс 1 или класс 2. Если рассматриваемая нами область является малым кругом, то объект классифицируется как 2-й класс, потому что внутри данного круга 2 треугольника и только 1 квадрат.
- Если мы рассматриваем большой круг (с пунктиром), то круг будет классифицирован как 1-й класс, так как внутри круга 3 квадрата в противовес 2 треугольникам.
- Евклидова метрика (евклидово расстояние, или же Euclidean distance) – метрика в евклидовом пространстве, расстояние между двумя точками евклидова пространства, вычисляемое по теореме Пифагора. Проще говоря, это наименьшее возможное расстояние между точками A и B. Хотя евклидово расстояние полезно для малых измерений, оно не работает для больших измерений и для категориальных переменных. Недостатком евклидова расстояния является то, что оно игнорирует сходство между атрибутами. Каждый из них рассматривается как полностью отличный от всех остальных.
- Другой важной составляющей метода является нормализация. Разные атрибуты обычно обладают разным диапазоном представленных значений в выборке. К примеру, атрибут А представлен в диапазоне от 0.01 до 0.05, а атрибут Б представлен в диапазоне от 500 до 1000). В таком случае значения дистанции могут сильно зависеть от атрибутов с бо́льшими диапазонами. Поэтому данные в большинстве случаев проходят через нормализацию. При кластерном анализе есть два основных способа нормализации данных: MinMax-нормализация и Z-нормализация.
- Загрузите ваши данные.
- Инициализируйте k путем выбора оптимального числа соседей.
- Для каждого образца в данных:
- Вычислите расстояние между примером запроса и текущим примером из данных.
- Добавьте индекс образца в упорядоченную коллекцию, как и его расстояние.
- Отсортируйте упорядоченную коллекцию расстояний и индексов от наименьшего до наибольшего, в порядке возрастания.
- Выберите первые k записей из отсортированной коллекции.
- Возьмите метки выбранных k записей.
- Если у вас задача регрессии, верните среднее значение выбранных ранее k меток.
- Если у вас задача классификации, верните наиболее часто встречающееся значение выбранных ранее меток k.
- Низкое значение k, например, 1 или 2, может привести к эффекту недообучения модели.
- Высокое значение k на первый взгляд выглядит приемлемо, однако возможны трудности с производительностью модели, а также повышается риск переобучения.
- Алгоритм прост и легко реализуем.
- Не чувствителен к выбросам.
- Нет необходимости строить модель, настраивать несколько параметров или делать дополнительные допущения.
- Алгоритм универсален. Его можно использовать для обоих типов задач: классификации и регрессии.
- Алгоритм работает значительно медленнее при увеличении объема выборки, предикторов или независимых переменных.
- Из аргумента выше следуют большие вычислительные затраты во время выполнения.
- Всегда нужно определять оптимальное значение k.
- — простейший метод ближайшего соседа;
- — метод ближайших соседей;
- — метод экспоненциально взвешенных ближайших соседей, где предполагается ;
- — метод парзеновского окна фиксированной ширины ;
- — метод парзеновского окна переменной ширины;
- — метод потенциальных функций, в котором ширина окна зависит не от классифицируемого объекта, а от обучающего объекта .
- выборка прореживается путём выбрасывания неинформативных объектов (см. выше);
- применяются специальные индексы и эффективные структуры данных для быстрого поиска ближайших соседей (например, -деревья).
Глава 1. Общая теория распознавания образов.
Основные понятия теории распознавания образов.
Теория распознавания образов - научное направление, связанное с разработкой принципов и построением систем, предназначенных для определения принадлежности данного объекта к одному из заранее выделенных классов объектов. Под объектами в распознавании образов понимают различные предметы, явления, процессы, ситуации, сигналы. Каждый объект описывается совокупностью основных характеристик (признаков, свойств) где -я координата вектора определяет значения -й характеристики, и дополнительной характеристикой , которая указывает на принадлежность объекта к некоторому классу (образу). Набор заранее расклассифицированных объектов, т. е. таких, у которых известны характеристики и , используется для обнаружения закономерных связей между значениями этих характеристик и поэтому называются обучающей выборкой. Те объекты, у которых характеристика неизвестна, образуют контрольную выборку. Отдельные объекты обучающей и контрольной выборок называются реализациями [1].
Одна из основных задач распознавания образов – выбор правила (решающей функции) , в соответствии с которым по значению контрольной реализации устанавливается её принадлежность к одному из образов, т. е. указываются "наиболее правдоподобные" значения характеристики для данного . Выбор решающей функции требуется произвести так, чтобы стоимость самого распознающего устройства, его эксплуатации и потерь, связанных с ошибками распознавания, была минимальной. Примером задачи распознавания образов этого типа может служить задача различения нефтеносных и водоносных пластов по косвенным геофизическим данным. По этим характеристикам сравнительно легко обнаружить пласты, насыщенные жидкостью. Значительно сложнее определить, наполнены они нефтью или водой. Требуется найти правило использования информации, содержащейся в геофизических характеристиках, для отнесения каждого насыщенного жидкостью пласта к одному из двух классов - водоносному или нефтеносному. При решении этой задачи в обучающую выборку включают геофизические данные вскрытых пластов.
Успех в решении задачи распознавания образов зависит в значительной мере от того, насколько удачно выбраны признаки . Исходный набор характеристик часто бывает очень большим. В то же время приемлемое правило должно быть основано на использовании небольшого числа признаков, наиболее важных для различения одного образа от другого. Так, в задачах медицинской диагностики важно определить, какие симптомы и их сочетания (синдромы) следует использовать при постановке диагноза данного заболевания. Поэтому проблема выбора информативных признаков - важная составная часть проблемы распознавания образов [2].
Проблема распознавания образов тесно связана с задачей предварительной классификации, или таксономией.
В основной задаче распознавания образов о построении решающих функций используются закономерные связи между характеристиками и обнаруживаемые на обучающей выборке, и некоторые дополнительные априорные предположения, например следующие гипотезы: характеристики для реализаций образов представляют собой случайные выборки из генеральных совокупностей с нормальным распределением, реализации одного образа расположены "компактно" (в некотором смысле), признаки в наборе независимы и т.д.
Формальная постановка задачи.
Распознавание образов — это отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные, из общей массы несущественных данных.
Классическая постановка задачи распознавания образов:
Дано множество объектов. Относительно них необходимо провести классификацию. Множество представлено подмножествами, которые называются классами. Заданы: информация о классах, описание всего множества и описание информации об объекте, принадлежность которого к определенному классу неизвестна. Требуется установить – к какому классу относится этот объект [1].
Основная типология методов распознавания образов:
Примеры задач распознания образов:
Байесовская теория.
Байесовская теория принятия решений составляет основу статического подхода к задаче распознавания образов. Этот подход основан на предположении, что задача выбора решения сформулирована в терминах теории вероятностей и известны все представляющие интерес вероятностные величины.
Правило Байеса показывает, как наличие измеренной величины х позволяет из априорной вероятности получить апостериорную вероятность Если при наблюдении получено значение , для которого больше, чем , то естественно склониться к решению, что истинное состояние природы есть . Аналогично, если больше, чем , то естественно склониться к выбору . Для того, чтобы обосновать это, вычислим вероятность ошибки при принятии решения, когда наблюдалось определенное значение х:
Средняя вероятность ошибки определяется выражением
и если для каждого х вероятность достигает наименьшего значения, то и интеграл должен быть минимальным. Этим мы обосновали следующее байесовское решающее правило, обеспечивающее наименьшую вероятность ошибки:
Самим видом решающего правила подчеркивается роль апостериорных вероятностей. Используя уравнение (1), можно выразить это правило через условные и априорные вероятности. Заметим, что в уравнении (1) с точки зрения принятия решения роли не играет, являясь всего-навсего масштабным множителем, обеспечивающим равенство . Исключив его, получим следующее решающее правило, полностью эквивалентное прежнему:
Чтобы пояснить существо вопроса, рассмотрим крайние случаи. Пусть для некоторого получено, что , так что конкретное наблюдение не дает информации о состоянии объекта. В этом случае решение, которое мы примем, целиком зависит от априорных вероятностей. С другой стороны, если , то состояния объекта априорно равновозможны, и вопрос о принятии решения опирается исключительно на – правдоподобие при данном . В общем случае при выборе решения важны обе указанные величины, что и учитывается правилом Байеса, обеспечивающим наименьшую вероятность ошибки [3].
Глава 2. Алгоритм ближайшего соседа.
Описание алгоритма.
Метод k ближайших соседей для решения задач дискриминантного анализа был впервые предложен еще в 1952 году. Он заключается в следующем.
При классификации неизвестного объекта находится заданное число (k) геометрически ближайших к нему в пространстве признаков других объектов (ближайших соседей) с уже известной принадлежностью к распознаваемым классам. Решение об отнесении неизвестного объекта к тому или иному диагностическому классу принимается путем анализа информации об этой известной принадлежности его ближайших соседей, например, с помощью простого подсчета голосов.
Первоначально метод k ближайших соседей рассматривался как непараметрический метод оценивания отношения правдоподобия. Для этого метода получены теоретические оценки его эффективности в сравнении с оптимальным байесовским классификатором.
При использовании метода k ближайших соседей для распознавания образов исследователю приходится решать сложную проблему выбора метрики для определения близости диагностируемых объектов. Эта проблема в условиях высокой размерности пространства признаков чрезвычайно обостряется вследствие достаточной трудоемкости данного метода, которая становится значимой даже для высокопроизводительных компьютеров. Поэтому здесь необходимо решать творческую задачу анализа многомерной структуры экспериментальных данных для минимизации числа объектов, представляющих диагностические классы.
Сходство объектов лежит в основе алгоритма k-ближайших соседей (k-nearest neighbor algorithm, KNN). Алгоритм способен выделить среди всех наблюдений k известных объектов (k-ближайших соседей), похожих на новый неизвестный ранее объект. На основе классов ближайших соседей выносится решение относительно нового объекта. Важной задачей данного алгоритма является подбор коэффициента – количество записей, которые будут считаться похожими [4].
Метод ближайшего соседа является, пожалуй, самым простым алгоритмом классификации. Классифицируемый объект относится к тому классу , которому принадлежит ближайший объект обучающей выборки .
Пусть имеется n наблюдений, каждому из которых соответствует запись в таблице. Все записи принадлежат какому-либо классу. Необходимо определить класс для новой записи.
На первом шаге алгоритма следует задать число – количество ближайших соседей. Если принять , то алгоритм потеряет обобщающую способность (то есть способность выдавать правильный результат для данных, не встречавшихся ранее в алгоритме) так как новой записи будет присвоен класс самой близкой к ней. Если установить слишком большое значение, то многие локальные особенности не будут выявлены.
На втором шаге находятся записей с минимальным расстоянием до вектора признаков нового объекта (поиск соседей).
Для упорядоченных значений признаков находится Евклидово расстояние:
где – количество признаков.
Вначале, найдя число , мы узнали, сколько записей будет иметь право голоса при определении класса. Затем мы выявили эти записи, расстояние от которых до новой оказалось минимальным. Теперь можно приступить к ***стому невзвешенному голосованию.
Расстояние от каждой записи при голосовании здесь больше не играет роли. Все имеют равные права в определении класса. Запись отдает предпочтение тому классу, к которому она принадлежит, а тот, который наберет наибольшее количество голосов, присваивается новой записи.
Метод k-ближайших соседей (k Nearest Neighbors, или kNN) – популярный алгоритм классификации, который используется в разных типах задач машинного обучения. Наравне с деревом решений это один из самых понятных подходов к классификации.
На интуитивном уровне суть метода проста: посмотри на соседей вокруг, какие из них преобладают, таковым ты и являешься. Формально основой метода является гипотеза компактности: если метрика расстояния между примерами введена удачно, то схожие примеры гораздо чаще лежат в одном классе, чем в разных.
Пример классификации k-ближайших соседей.
Теоретическая составляющая алгоритма k-NN
Помимо простого объяснения, необходимо понимание основных математических составляющих алгоритма k-ближайших соседей.
Формула вычисления Евклидова расстояния:
MinMax-нормализация осуществляется следующим образом:
в данном случае все значения будут находиться в диапазоне от 0 до 1; дискретные бинарные значения определяются как 0 и 1.
Z-нормализация:
где σ – среднеквадратичное отклонение. В данном случае большинство значений попадает в диапазон.
Каков порядок действий?
Реализация на языке Python
Набор данных состоит из 15 столбцов, таких как sex (пол), fare (плата за проезд), p_class (класс каюты), family_size (размер семьи), и т. д. Главным признаком, который мы и должны предсказать в соревновании, является survived (выжил пассажир или нет).
Дополнительный анализ показал, что находящиеся в браке люди имеют больший шанс на то, чтобы быть спасенными с корабля. Поэтому были добавлены еще 4 столбца, переименованные из Name (Имя), которые обозначают мужчин и женщин в зависимости от того, были они женаты или нет (Mr, Mrs, Mister, Miss).
Чтобы наглядно продемонстрировать функциональность k-NN для предсказания выживания пассажира, мы рассматриваем только два признака: age (возраст), fare (плата за проезд).
Здесь вероятность выживания составляет 0.3 – 30%.
Далее мы настраиваем алгоритм k-NN на поиск и использование 20 ближайших соседей, чтобы оценить состояние пассажира. Для наглядности выводим 20 первых соседей новой записи с помощью импортированного метода kneighbors . Реализация выглядит следующим образом:
Результат работы кода:

Как видите, на графике показаны 20 ближайших соседей, 14 из которых связаны с теми, кто не выжил (вероятность 0,7 – 70%), а 6 связаны с выжившими (вероятность 0,3 – 30%).
Мы можем просмотреть первые 20 ближайших соседей для заданных параметров при помощью следующего кода:
Результатом будет таким:

Выбор Оптимального значения для k-NN
Не существует конкретного способа определить наилучшее значение для k, поэтому нам нужно попробовать несколько значений, чтобы найти лучшее из них. Но чаще всего наиболее предпочтительным значением для k является 5:
Преимущества и Недостатки
Преимущества:
В заключение
Метод k-ближайших соседей (k-nearest neighbors) – это простой алгоритм машинного обучения с учителем, который можно использовать для решения задач классификации и регрессии. Он прост в реализации и понимании, но имеет существенный недостаток – значительное замедление работы, когда объем данных растет.
Алгоритм находит расстояния между запросом и всеми примерами в данных, выбирая определенное количество примеров (k), наиболее близких к запросу, затем голосует за наиболее часто встречающуюся метку (в случае задачи классификации) или усредняет метки (в случае задачи регрессии).
KNN (алгоритм ближайшего соседа K) подробное введение
Наиболее подробное введение в KNN (алгоритм ближайшего соседа)
Алгоритмы KNN в основном делятся на две категории: одна - KNeighborsClassifier, а другая - KNeighborsRegressor. Выполните операции классификации и регрессии отдельно.
Основную идею алгоритма KNN можно резюмировать в несколько шагов, включая:
1. Рассчитайте расстояние между целевой точкой (или точкой классификации) и каждой точкой выборки и отсортируйте вычисленные значения этих расстояний от малых до больших. Выберите k образцов, ближайших к целевой точке.
2. Если это проблема классификации, подсчитайте, какая категория является самой многочисленной среди k точек выборки, а затем классифицируйте целевую точку в эту категорию. А затем завершите работу по классификации.


Во-первых, на входе любого алгоритма должна быть количественная информация, которую мы называем характеристиками, а объекты в реальной жизни должны описываться цифровыми характеристиками (вектор / матрица / тензор).
Во-вторых, поскольку KNN является алгоритмом обучения с учителем, образцы должны быть помечены заранее (метка или значение атрибута каждого образца должны быть определены и помечены).
В-третьих, нам нужно найти способ вычислить расстояние или сходство между двумя выборками, а затем мы можем выбрать ближайшую выборку (расстояние или сходство, используемое здесь, обычно использует евклидову Расстояние, другие расстояния могут использоваться в особых случаях, например, расстояние Хэмминга).
В-четвертых, вам необходимо знать, как выбрать наиболее подходящее значение K. Чтобы понять это, вы должны сначала понять влияние K на саму модель (обучающий набор необходимо разделить на обучающий набор и набор проверки, Выполните K-кратную перекрестную проверку, см. Код ниже).
Не применимо к sklearn для реализации алгоритма KNN, код выглядит следующим образом:
Из вышесказанного мы уже знаем, что важный параметр K в модели KNN нуждается в корректировке, потому что при другом значении K результаты классификации модели или регрессии могут быть совершенно разными. В процессе настройки параметра k необходимо задействовать следующие технологии:
1. Что такое граница решения и как найти границу решения модели?
2. Перекрестная проверка, принцип и реализация k-кратной перекрестной проверки
3. Масштабирование элементов, чтобы сделать модель эффективной, как проектировать или масштабировать элементы.
1. Что такое граница принятия решения и как найти границу принятия решения KNN?
(1) Линейная модель и нелинейная модель
Мы делаем разные вещи каждый деньпринятие решенияНапример, я решил купить его, когда цена Huawei Mate упала до 2000 юаней. На этот вопрос мойГраница решенияЭто 2 000 юаней, то есть я не буду покупать, когда цена больше 2 000 юаней, но я выберу покупку, когда она будет меньше 2 000 юаней. Есть много подобных примеров из жизни.
(2) Как найти решающую границу KNN

Сначала мы берем k = 1 в качестве примера, классифицируем каждую тестовую целевую точку (здесь предполагается две классификации) и рисуем два соответствующих цвета, разделяем их по границе и представляем границу решения.
По мере увеличения значения K граница принятия решения действительно становится более плавной. Гладкость границы решения также означает устойчивость модели. На самом деле это очень легко понять: в повседневной работе несколько человек, принимающих совместные решения, с большей вероятностью сделают меньше ошибок, чем один человек, принимающий решения. Но стабильность не означает, что эта модель будет более точной.
** Приведенный выше код описывает явление, что по мере увеличения значения k граница принятия решения становится все более гладкой. ** Результаты бега следующие:
2. Перекрестная проверка - определение значения K
Хотя гладкая граница решения делает модель более устойчивой, устойчивость не означает, что точность модели выше. Это похоже на наши инвестиции в акции: если мы стремимся к особой стабильности, это означает, что конечная прибыль будет очень небольшой, но, по крайней мере, способность противостоять рискам будет высокой. Таким образом, риски и преимущества обычно сбалансированы, чтобы выбрать наиболее подходящую точку баланса. Как выбрать этот баланс? Ответ - перекрестная проверка
(1) Оставьте проверочный набор.
Первым шагом перекрестной проверки является дальнейшее разделение обучающих данных на обучающий набор и набор проверки. Потому что нам нужен механизм оценки, чтобы выбрать лучшее значение K. Какие данные используются для оценки? Это набор для проверки. Данные теста используются для разового тестирования. Например, чтобы проверить, выполняются ли онлайн-условия перед подключением к сети, но тестовые данные не могут использоваться для обучения модели.
Обычно используемый метод перекрестной проверки называется перекрестной проверкой в K-кратном порядке. Сначала мы разделяем обучающие данные на обучающий набор и проверочный набор, затем используем обучающий набор для обучения модели, а затем оцениваем точность модели на проверочном наборе. Например, например, в модели есть параметр с именем α. Мы не знали, выбрать ли вначале 0,1 или 1, поэтому в этот раз мы провели перекрестную проверку: разделим все обучающие наборы на K блоков и по очереди оценили каждое значение α. Точность. Следующая анимация описывает, как использовать K-кратную перекрестную проверку для выбора наиболее подходящего значения параметра.
Таким образом, для разных значений K попробуйте один за другим выбрать лучшее. И этот тип параметра называется гиперпараметром (Hyperparameter).Короче говоря, гиперпараметры относятся к искусственно заданным экзогенным значениям параметров.
(2) Связь между значением k и количеством данных.
K-кратная перекрестная проверка часто используется при перекрестной проверке, которая заключается в повторении нескольких проверок существующих данных, чтобы сделать результаты оценки более стабильными.
В общем, когда объем данных невелик, значение K, которое мы принимаем, будет больше. Почему? Потому что, когда объем данных невелик, если вы каждый раз оставляете больше проверочных данных, это будет более невыгодно для самой модели обучения. Поэтому сейчас мы стараемся использовать как можно больше данных для обучения модели. Поскольку количество данных проверки, выбираемых каждый раз, невелико, значение K компромисса K также будет увеличиваться в это время, но, в конце концов, можно обнаружить, что независимо от того, как выбирается значение K, количество образцов, используемых для проверки, равно общему Количество образцов. В самом крайнем случае мы можем использовать перекрестную проверку leave_one_out (метод исключения одного), то есть только одна выборка используется в качестве данных проверки за раз, а остальные данные используются в качестве обучающей выборки.
(3) K-кратная перекрестная проверка не основана на sklearn

Результат вывода:
(4) K-кратная перекрестная проверка на основе sklearn
Мы не должны использовать тестовые данные в процессе перекрестной проверки.Роль тестовых данных всегда заключается в том, чтобы выполнить последний шаг тестирования, чтобы увидеть, соответствует ли модель онлайн-стандартам, но они не должны участвовать в обучении модели. Об этом нужно помнить, это очень важно!
3. Масштабирование признаков - общие методы проектирования признаков.

Вообще говоря, существует два общих метода стандартизации функций. Это линейная нормализация и нормализация стандартного отклонения. Среди них линейная нормализация относится к отображению диапазона собственных значений в интервал [0,1], а метод стандартизации стандартного отклонения позволяет отображать собственные значения в нормальное распределение со средним значением 0 и стандартным отклонением 1. Далее я подробно объясню эти два метода.
Метод ближайших соседей — простейший метрический классификатор, основанный на оценивании сходства объектов. Классифицируемый объект относится к тому классу, которому принадлежат ближайшие к нему объекты обучающей выборки.
Содержание
? Что означает оператор квадратных скобок в данном контексте:
Введение
Метод ближайшего соседа является, пожалуй, самым простым алгоритмом классификации. Классифицируемый объект относится к тому классу , которому принадлежит ближайший объект обучающей выборки .
Метод ближайших соседей. Для повышения надёжности классификации объект относится к тому классу, которому принадлежит большинство из его соседей — ближайших к нему объектов обучающей выборки . В задачах с двумя классами число соседей берут нечётным, чтобы не возникало ситуаций неоднозначности, когда одинаковое число соседей принадлежат разным классам.
Метод взвешенных ближайших соседей. В задачах с числом классов 3 и более нечётность уже не помогает, и ситуации неоднозначности всё равно могут возникать. Тогда -му соседу приписывается вес , как правило, убывающий с ростом ранга соседа . Объект относится к тому классу, который набирает больший суммарный вес среди ближайших соседей.
Гипотеза компактности
Основная формула
Пусть на множестве объектов задана функция расстояния . Эта функция должна быть достаточно адекватной моделью сходства объектов. Чем больше значение этой функции, тем менее схожими являются два объекта .
Для произвольного объекта расположим объекты обучающей выборки в порядке возрастания расстояний до :
где через обозначается тот объект обучающей выборки, который является -м соседом объекта . Аналогичное обозначение введём и для ответа на -м соседе: . Таким образом, произвольный объект порождает свою перенумерацию выборки. В наиболее общем виде алгоритм ближайших соседей есть
где — заданная весовая функция, которая оценивает степень важности -го соседа для классификации объекта . Естественно полагать, что эта функция неотрицательна и не возрастает по .
По-разному задавая весовую функцию, можно получать различные варианты метода ближайших соседей.
Здесь — заданная неотрицательная монотонно невозрастающая функция на , ядро сглаживания.
Основные проблемы и способы их решения
Выбор числа соседей k
При алгоритм ближайшего соседа неустойчив к шумовым выбросам: он даёт ошибочные классификации не только на самих объектах-выбросах, но и на ближайших к ним объектах других классов. При , наоборот, алгоритм чрезмерно устойчив и вырождается в константу. Таким образом, крайние значения нежелательны. На практике оптимальное значение параметра определяют по критерию скользящего контроля, чаще всего — методом исключения объектов по одному (leave-one-out cross-validation).
Отсев шума (выбросов)
Исключение из выборки шумовых и неинформативных объектов даёт несколько преимуществ одновременно: повышается качество классификации, сокращается объём хранимых данных и уменьшается время классификации, затрачиваемое на поиск ближайших эталонов.
Идея отбора эталонов реализована в алгоритме STOLP, описанном в книге Н. Г. Загоруйко .
Сверхбольшие выборки
Метод ближайших соседей основан на явном хранении всех обучающих объектов. Сверхбольшие выборки () создают несколько чисто технических проблем: необходимо не только хранить большой объём данных, но и уметь быстро находить среди них ближайших соседей произвольного объекта .
Проблема решается двумя способами:
Проблема выбора метрики
Если признаков слишком много, а расстояние вычисляется как сумма отклонений по отдельным признакам, то возникает проблема проклятия размерности. Суммы большого числа отклонений с большой вероятностью имеют очень близкие значения (согласно закону больших чисел). Получается, что в пространстве высокой размерности все объекты примерно одинаково далеки друг от друга; выбор ближайших соседей становится практически произвольным.
Проблема решается путём отбора относительно небольшого числа информативных признаков (features selection). В алгоритмах вычисления оценок строится множество различных наборов признаков (т.н. опорных множеств), для каждого строится своя функция близости, затем по всем функциям близости производится голосование.
Рассуждения на основе прецедентов
Для CBR крайне важно, чтобы число было поменьше, а среди обучающих объектов не было выбросов; иначе классификации теряют свойство интерпретируемости. Поэтому в CBR приходится применять и методы отбора эталонов, и оптимизацию метрик.
Читайте также: