
Концептуальные логические и физические модели данных реферат
Обновлено: 30.06.2024
Тема : Концептуальная, логическая и физическая модели данных. Обеспечение непротиворечивости и целостности данных. Проектирование логической и физической БД.
КОНЦЕПТУАЛЬНАЯ, ЛОГИЧЕСКАЯ И ФИЗИЧЕСКАЯ МОДЕЛИ
Процесс создания информационной модели начинается с определения концептуальных требований будущих пользователей БД.
Концептуальная модель отображает предметную область в виде взаимосвязанных объектов без указания способов их физического хранения. Концептуальная модель представляет интегрированные концептуальные требования всех пользователей к базе данных данной предметной области.
При этом усилия разработчика должны быть направлены в основном на структуризацию данных, принадлежащих будущим пользователям БД, и выявление взаимосвязей между ними. Возможно, что отраженные в концептуальной модели взаимосвязи между объектами окажутся впоследствии нереализуемыми средствами выбранной СУБД. Это потребует изменения концептуальной модели. Версия концептуальной модели, которая может быть реализована конкретной СУБД, называется логической моделью.
Логическая модель отражает логические связи между атрибутами объектов вне зависимости от их содержания и среды хранения и может быть реляционной, иерархической или сетевой. Таким образом, логическая модель отображает логические связи между информационными данными в данной концептуальной модели.
Различным пользователям в информационной модели соответствуют различные подмножества ее логической модели, которые называются внешними моделями пользователей. Таким образом, внешняя модель пользователя представляет собой отображение концептуальных требований этого пользователя в логической модели и соответствует тем представлениям, которые пользователь получает о предметной области на основе логической модели. Следовательно, насколько хорошо спроектирована внешняя модель, настолько полно и точно информационная модель отображает предметную область и настолько полно и точно работает автоматизированная система управления этой предметной областью.
Логическая модель отображается в физическую память, которая может быть построена на электронных, магнитных, оптических, биологических или других принципах.
Внутренняя модель предметной области определяет размещение данных, методы доступа и технику индексирования в данной логической модели и иначе называется физической моделью.
Информационные данные любого пользователя в БД должны быть независимы от всех других пользователей, т. е. не должны оказывать влияния на существующие внешние модели. Это первый уровень независимости данных. С другой стороны, внешние модели пользователей никак не связаны с типом физической памяти, в которой будут храниться данные, и с физическими методами доступа к этим данным. Это положение отражает второй уровень независимости данных.
Обеспечение непротиворечивости и целостности данных в базе
Для пользователей АИС важно, чтобы база данных отображала предметную область однозначно и непротиворечиво, т. е. чтобы она удовлетворяла условию целостности.
Выделяют два основных типа ограничений по условию целостности:
1. Каждая строка таблицы должна отличаться от остальных ее строк значением хотя бы одного столбца.
Пример 2.
2. Внешний ключ не может быть указателем на несуществующую строку той таблицы, на которую он ссылается. Это ограничение называется ограничением целостности по ссылкам.
Пример 3.
В реальных базах данных названия не делают ключевыми из-за их длины (замедление процесса поиска), а также из-за того, что они могут изменяться (сложности с сопровождением системы).
Методология логического моделирования данных
Теперь у нас есть завершенная логическая модель данных. Вспомним, какие шаги нужно осуществить, чтобы получить ее:
1. Выявить и смоделировать сущности.
2. Выявить и смоделировать связи между сущностями.
3. Выявить и смоделировать атрибуты.
4. Указать уникальный идентификатор для каждой сущности.
5. Провести нормализацию.
На практике процесс редко происходит в такой последовательности. Как показывает наш пример, часто возникают желание и необходимость перескакивать между сущностями, связями, атрибутами и идентификаторами. Важно не столько строго следовать последовательности шагов, сколько выявить и зафиксировать все данные, необходимые для правильного моделирования системы.
Модель данных, которую мы создали в этой главе, очень проста. Мы рассказали, как создать модель, соответствующую по типу и сложности тем базам данных, с которыми вы, скорее всего, столкнетесь, разрабатывая базы данных для MySQL или mSQL. Мы не коснулись целой массы приемов проектирования и понятий, которые не имеют большого значения при проектировании маленьких баз данных и могут быть найдены в любом учебнике, посвященном проектированию баз данных.
Проектирование баз данных — процесс создания схемы базы данных и определения необходимых ограничений целостности.

Невозможно создать БД без подробного ее описания, также как и невозможно сделать какое-либо сложное изделие без чертежа и подробного описания технологий его изготовления. Другими словами, нужен проект. Проектом принято считать эскиз некоторого устройства, который в дальнейшем будет воплощен в реальность. Процесс проектирования БД представляет собой процесс переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. Конечной целью проектирования является построение конкретной БД. Очевидно, что процесс проектирования сложен и поэтому имеет смысл разделить его на логически завершенные части – этапы.
При проектировании таблиц рекомендуется руководствоваться следующими основными принципами:
- Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Когда определенная информация хранится только в одной таблице, то и изменять ее придется только в одном месте. Это делает работу более эффективной, а также исключает возможность несовпадения информации в разных таблицах. Например, в одной таблице должны содержаться адреса и телефоны клиентов.
- Каждая таблица должна содержать информацию только на одну тему. Сведения на каждую тему обрабатываются намного легче, если они содержатся в независимых друг от друга таблицах. Например, адреса и заказы клиентов лучше хранить в разных таблицах с тем, чтобы при удалении заказа информация о клиенте осталась в базе данных.
- Каждая таблица должна содержать необходимые поля. Каждое поле в таблице должно содержать отдельные сведения по теме таблицы. Например, в таблице с данными о клиенте могут содержаться поля с названием компании, адресом, городом, страной и номером телефона. При разработке полей для каждой таблицы необходимо помнить, что каждое поле должно быть связано с темой таблицы. Не рекомендуется включать в таблицу данные, которые являются результатом выражения. В таблице должна присутствовать вся необходимая информация. Информацию следует разбивать на наименьшие логические единицы (Например, поля "Имя" и "Фамилия", а не общее поле "Имя").

- База данных должна иметь первичный ключ. Это необходимо для того, чтобы СУБД могла связать данные из разных таблиц, например, данные о клиенте и его заказы.
Основные задачи проектирования баз данных:
- Обеспечение хранения в БД всей необходимой информации.
- Обеспечение возможности получения данных по всем необходимым запросам.
- Сокращение избыточности и дублирования данных.
- Обеспечение целостности базы данных.
Основные этапы проектирования баз данных:
Концептуальное (инфологическое) проектирование.
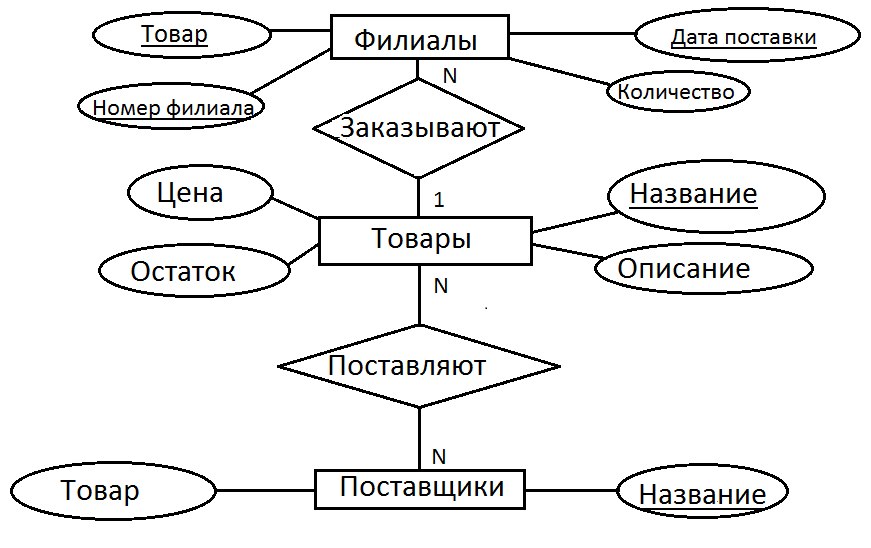
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам.
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений. При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
Логическое (даталогическое) проектирование.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Логическая структура БД должна соответствовать логической модели предметной области и учитывать связь модели данных с поддерживаемой СУБД. Поэтому этап начинается с выбора модели данных, где важно учесть её простоту и наглядность.
Предпочтительнее, когда естественная структура данных совпадает с представляющей её моделью. Так, например, если в данные представлены в виде иерархической структуры, то и модель лучше выбирать иерархическую. Однако на практике такой выбор чаще определяется системой управления БД, а не моделью данных. Поэтому концептуальная модель фактически транслируется в такую модель данных, которая совместима с выбранной системой управления БД.
Здесь тоже находит отражение природа проектирования, которая допускает возможность (или необходимость) вернуться к концептуальной модели для её изменения в случае, если отражённые там взаимосвязи между объектами (или атрибуты объектов) не удастся реализовать средствами выбранной СУБД.
По завершению этапа должны быть сформированы схемы баз данных обоих уровней архитектуры (концептуального и внешнего), созданные на языке определения данных, поддерживаемых выбранной СУБД.
Схемы базы данных формируются с помощью одного из двух разнонаправленных подходов:
- либо с помощью восходящего подхода, когда работа идёт с нижних уровней определения атрибутов, сгруппированных в отношения, представляющие объекты, на основе существующих между атрибутами связей;
- либо с помощью обратного, нисходящего, подхода, применяемого при значительном (до сотен и тысяч) увеличении числа атрибутов.
Физическое проектирование.
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.

На следующем этапе физического проектирования БД логическая структура отображается в виде структуры хранения БД, то есть увязывается с такой физической средой хранения, где данные будут размещены максимально эффективно. Здесь детально расписывается схема данных с указанием всех типов, полей, размеров и ограничений. Помимо разработки индексов и таблиц, производится определение основных запросов.
Построение физической модели сопряжено с решением во многом противоречивых задач:
- задачи минимизации места хранения данных,
- задачи достижения целостности, безопасности и максимальной производительности.
Вторая задача вступает в конфликт с первой, поскольку, например:
- для эффективного функционирования транзакций нужно резервировать дисковое место под временные объекты,
- для увеличения скорости поиска нужно создавать индексы, число которых определяется числом всех возможных комбинаций участвующих в поиске полей,
- для восстановления данных будут создаваться резервные копии базы данных и вестись журнал всех изменений.
Всё это увеличивает размер базы данных, поэтому проектировщик ищет разумный баланс, при котором задачи решаются оптимально путём грамотного размещения данных в пространстве памяти, но не за счёт средств защиты базы дынных, куда входит как защита от несанкционированного доступа, так и защита от сбоев.
Для завершения создания физической модели проводят оценку её эксплуатационных характеристик (скорость поиска, эффективность выполнения запросов и расхода ресурсов, правильность операций). Иногда этот этап, как и этапы реализации базы данных, тестирования и оптимизации, а также сопровождения и эксплуатации, выносят за пределы непосредственного проектирования БД.
Выбор системы управления и программных средств БД.
От выбора системы управления БД зависит практическая реализация информационной системы. Наиболее значимыми критериями в процессе выбора становятся параметры:
- типа модели данных и её соответствие потребностям предметной области,
- запас возможностей в случае расширения информационной системы,
- характеристики производительности выбранной системы,
- эксплуатационная надёжность и удобство СУБД,
- инструментальная оснащённость, ориентированная на персонал администрирования данных,
- стоимость самой СУБД и дополнительного софта.
Ошибки в выборе СУБД практически наверняка впоследствии спровоцируют необходимость корректировать концептуальную и логическую модели.
Исследование разработки программного продукта в области торговли. Обоснование выбора концепции управления базами данных, языка программирования и операционной системы. Основная характеристика проектирования концептуальной, логической и физической модели.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 11.10.2015 |
| Размер файла | 337,8 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Подобные документы
Автоматизация учёта поступления и обучения детей в "Доме детского творчества". Проектирование программного продукта ИС; выбор системы управления базы данных, языка программирования. Разработка концептуальной, логической и физической моделей данных.
дипломная работа [1,5 M], добавлен 10.10.2015
Порядок автоматизации расчетов себестоимости и длительности программного обеспечения производственного предприятия. Выбор языка программирования и системы управления базами данных. Разработка алгоритмов расчета себестоимости программного обеспечения.
дипломная работа [1,7 M], добавлен 13.06.2017
Анализ предметной области, этапы проектирования автоматизированных информационных систем. Инструментальные системы разработки программного обеспечения. Роль CASE-средств в проектировании информационной модели. Логическая модель проектируемой базы данных.
курсовая работа [410,6 K], добавлен 21.03.2011
Основы методологии проектирования информационной системы. Общая характеристика и классификация CASE-средств. Рассмотрение логической, функциональной и физической модели данных системы "Студент". Расчет трудоемкости разработки программного изделия.
дипломная работа [1,9 M], добавлен 16.03.2012
Обоснование выбора языка программирования. Анализ входных и выходных документов. Логическая структура базы данных. Разработка алгоритма работы программы. Написание программного кода. Тестирование программного продукта. Стоимость программного продукта.
Мне как фриланс-архитектору часто приходится сталкиваться с людьми из бизнеса, которые не понимают что такое ИТ, как там все происходит и зачем все эти страшные слова.
А когда люди не понимают о чем говорят они закрываются и боятся принять какое-либо решение. А так как мне нужно рассказать о своих способностях и том, чем я могу быть полезен, т.е. по сути продать свои услуги, мне часто приходится искать общие понятия, так сказать common ground. Когда люди начинают строить аналогии с тем, что им понятно, происходит уже более предметное обсуждение.
Часто встречаясь с одними и теми же проблемами, в конце концов, я решил поделиться своим опытом, возможно, это кому-то будет полезно в чистом виде, а кто-то поймёт принцип и придумает примеры и объяснения получше.
В этой статье я хочу рассказать об уровнях данных – Физическом, Логическом, Концептуальном.
Физический уровень
Физический уровень - это уровень базы данных. Я не буду рассказывать историю эволюции баз данных и про их типы. Для начала нужны базовые знания, на которые впоследствии можно наложить новые.
Итак, представьте себе, что у вас есть коробка для хранения и целый набор различных крепёжных элементов – болты, гайки, саморезы, гвозди, эксцентрики и прочее (рис.1)

Рис.1 База данных и её элементы в реальной жизни
Коробка - это и есть база данных, а крепёжные элементы — это данные.
Свалив все в коробку вы уже получили базу, содержащую данные. Теперь каждый раз, когда вам нужно что-то достать, вы будете открывать коробку и доставать из неё нужный элемент крепежа. При этом вам каждый раз придётся копаться во всей коробке.
Это называется неструктурированная и ненормированная база данных. Её преимущества в простоте и дешевизне.
Неудобства очевидны - это необходимость копаться во всей коробке в поисках конкретного элемента и тратить на это кучу времени. Конечно, через какое-то время вы запомните какие примерно элементы есть в коробке и если дюбелей в ней нет, то искать вы их не будете. И, конечно, постепенно вы выработаете какие-то свои правила поиска нужных элементов в куче.
Однако, то, что очевидно для вас, совсем не очевидно для другого человека. Для человека незнакомого с вашей коробкой и её содержим, поиск будет настоящим мучением.
Точно та же проблема будет стоять и перед любым ИТ-специалистом.
Со временем вы захотите навести больше порядка в своей коробке – т.е. её структурировать. Выделить каждому типу элементов свой контейнер, чтобы как можно быстрее находить нужное.
Для этого вы купите дополнительные контейнеры поменьше и раскидаете в них соответствующие элементы. Болты в один контейнер, гвозди в другой, гайки в третий и так далее.
При этом вы наверняка начнёте размещать наиболее часто используемые коробочки наверх, наиболее редко используемые вниз. Элементы, которые часто используете вместе, размещать рядом и так далее.
На языке ИТ это называется нормализация. А крепёжные элементы — это объекты.

Рис.2 – Структурированная база данных
После выполнения нормализации, в каждой коробочке будет находится свой тип объекта – гайки, болты или гвозди.
Нормализацию вы можете продолжать и дальше. Например, вы можете купить коробочки поменьше и разложить саморезы по металлу, дереву и бетону в разные.
Можете дополнительно разделить их по длине, цвету или скажем ходу резьбы.
Как и в случае с коробками, фанатичная нормализация базы данных создаёт те же проблемы – большой уровень вложенности и замедление поиска нужного элемента, которого просто может не оказаться в коробке.
Потому ИТ-специалисты всегда стараются соблюдать баланс между чёткой структурой и удобством её использования.
Поэтому иногда специально прибегают к денормализации.
Например, болт и гайка почти всегда используются вместе. Если следовать прямой логике структуризации – болты нужно положить в одну коробочку, а гайки в другую.
Но с точки зрения удобства, это хуже, т.к. приходится заглядывать в две коробочки и тратить на это время. Потому, вы можете пойти на осознанную денормализацию и положить болты и гайки в одну коробочку.
Если коробочек много или скажем они не прозрачны или ещё по каким-либо причинам удобства, вы можете наклеить на каждую коробочку метку – индекс.
С помощью таких индексов скорость поиска существенно повышается, т.к. вы точно знаете где что хранится и возможно что хранится в соседних коробочках.
Таким образом, организуя хранилище крепёжных элементов, вы можно сказать, что вы управляете базой данных.
Вы можете выполнять две основные операции над коробкой – извлекать элементы и класть элементы.
Конечно, вы можете осуществлять поиск, выбирать конкретные элементы или считать их количество. Т.е. то же самое, что и с базой данных.
При этом самой коробочке все равно какие типы элементов в ней хранятся, как они будут использоваться и как удобно вам с ним обращаться. Её задача хранить элементы.
Что делать с элементами или какой в них бизнес-смысл — это задача логического уровня.
Логический уровень
Однажды в моей жизни произошла забавная ситуация, когда я работал в крупной компании с процедурами, регламентами, базами заявок и прочее.
Мне нужно было чтобы от одного стола открутили перегородку, а к другому столу ее прикрутили. Конечной целью являлась прикрученная перегородка ко второму столу, а то, что её нужно было открутить от второго стола, воспринималось все равно что взять её у стены.
Потому и заявку я оставил на прикручивание перегородки к столу. Монтажник пришёл с шуруповёртом и был очень недоволен, что заявка на прикручивание перегородки, а нужно ещё открутить. Мы тогда посмеялись и спросили, помочь ли ему переключить шуруповёрт в режим реверса. Ведь с житейской точки зрения, это глупость чистой воды, возьми открути перегородку, потрать лишние 30 секунд.
Если посмотреть на ситуацию более системно, то все дело в том, что шуруповёрт давно был продуман и подготовлен к такой ситуации. Производитель давно подумал о функции реверса и потому отказ монтажника от того, чтобы открутить перегородку кажется абсурдным.
Но ведь ситуация могла быть и совсем другой, например, если бы он пришёл с шуруповертом, у которого нет функции реверса, и он физически мог бы только закрутить болт, но не мог бы его открутить.
На рисунке 3 представлена упрощённая логическая модель из примера с заявкой.

Рис.3 Логическая модель данных
В ИТ-мире это особенно важно, ведь если перед программистом не стояло задачи реализовать реверс, то монтажник сделать ничего не сможет.
Обратите внимание, что мы говорим о тех самых объектах с физического уровня – болтах. Но операции, которые мы теперь выполняем над ними уже не достать или положить, а прикрутить или открутить. При том, что сами операции открутить или прикрутить, определяются направлением вращения отвёртки, а отнюдь не самим болтом.
Конечно, у болта есть свойство это направление резьбы, которая определяет в какую сторону нужно поворачивать отвёртку.
В ИТ-мире вы часто можете услышать слово атрибут объекта, вместо свойства.
При этом заметьте, что, если мы изменим направление резьбы, сами операции закрутить и открутить останутся, но нужно будет изменить направление вращения отвёртки.
Таким образом, когда мы говорим о логическом уровне работы с данными, мы говорим о каких-то осмысленных операциях над данными, позволяющими решать какие-то задачи.
Помимо списка операций, мы всегда думаем о ценности наличия тех или иных объектов, т. е. об их предназначении. Зачем нам эти объекты и что мы будем с ними делать?
Часто в ИТ-мире это называется бизнес-логикой или бизнес-смыслом.
Подводя итог нужно сказать, что на логическом уровне мы определяем - свойства объектов (атрибуты), операции, предназначение (бизнес-логика).
Концептуальный уровень
Уровень концепции — это уровень верхнеуровневых рассуждений без деталей.
Мы часто используем этот уровень, даже не подозревая об этом.
Например, чтобы повесить картину на стену, нужен комплект крепления, который состоит из дюбеля, самореза и шуруповёрта. Я специально опускаю детали типа необходимости сверления отверстия или необходимости иметь дрель.
Концептуальный уровень позволяет нам определить основные объекты, их связи друг с другом, не впадая в детализацию (вес картины, длинна самореза и так далее).
Концептуальный уровень позволяет быстро сформировать набросок логической модели, договориться о понятиях и выровнять понимание.
В жизни мы часто очень неосторожно используем понятия, буквально жонглируем ими. Но когда дело доходит до автоматизации, часто возникают проблемы в реализации.
Один из моих любимых примеров на этот счёт является сервис Яндекс такси. Для пользование сервисом нужно создать аккаунт и согласиться с условиями соглашения (договора), т.е. стать Клиентом. При этом нужно привязать карту для оплаты, владельцем карты не обязательно должны быть вы, потому появляется понятие Плательщик. Однако, относительно недавно появилась функция – Такси другому человеку, которая явно указывает на тот факт, что пользоваться услугой может другой человек – Потребитель. (рис.4)

Рис.4 Концептуальная модель данных
Здесь я специально не использую слово пассажир, т.к. хочу сфокусировать ваше внимание на ключевых объектах и их отношениях.
Краткий итог по данным и их уровням
Физический уровень – как организовываем и храним данные.
Логический уровень – описываем и манипулируем данными.
Концептуальный – рассуждаем о данных и их связях.
Надеюсь, статья была вам полезной и занимательной.
P.S.: эта статья не для ИТ специалистов, статья рассчитана на средне статического человека, не связанного с ИТ, с максимальным упрощением. А как в любом упрощении, в статье сделаны осознанные допущения и упущены некоторые детали.
Например, объяснить что такое ключи и гипер ссылки, я не стал да и пример для этого нужен другой.
Читайте также: