
Коды с постоянным весом реферат
Обновлено: 05.07.2024
Код с постоянным весом. Одним из простейших блочных неразделимых кодов (см. рис.5.4) является код с постоянным весом. Примером такого кода может служить семибитный телеграфный код МТК-3, в котором каждая разрешенная кодовая комбинация содержит три единицы и четыре нуля (рис.5.7). Весом кодовой комбинации называют число содержащихся в ней единиц. В рассматриваемом коде вес кодовых комбинаций равен трем.
Число разрешенных кодовых комбинаций в кодах с постоянным весом определяется как количество сочетаний из n символов по g и равно
Избыточность кода с постоянным весом МТК-3
Минимальное кодовое расстояние такого кода dmin=2, что дает ему возможность обнаруживать однократные ошибки. Однако код с постоянным весом способен обнаруживать ошибки большей кратности (двойные, тройные и т.д.), при которых нарушается весовое соотношение единиц и нулей. Код не обнаруживает только ошибки, при которых число единиц, перешедших в нули, равно числу нулей, перешедших в единицы.
Следует отметить, что в настоящее время предпочтение отдается разделимым кодам, так как они проще реализуются.
Код с проверкой на четность. Этот код является наиболее простым блочным разделимым кодом, содержащим всего лишь один проверочный символ. Проверочный символ выбирается равным единице или нулю, таким образом, чтобы число единиц во вновь образованной n = k +1 – элементной кодовой комбинации было четным (рис.5.8).
Код с проверкой на четность относится к классу линейных систематических кодов. Формирование проверочных символов кодовых комбинаций кода с четным числом единиц осуществляется путем сложения по модулю 2 информационных символов. Например, к первичной комбинации 01011 следует добавить справа единицу, так как 0Å1Å0Å1Å1=1, следовательно, разрешенная кодовая комбинация запишется так: 010111 (см. также рис.5.6).
Код с проверкой на четность является линейным, поскольку поэлементное сложение по модулю 2 двух разрешенных кодовых комбинаций образует также разрешенную кодовую комбинацию. Действительно, сложив две кодовые комбинации, приведенные на рис.5.7, получим
Число разрешенных кодовых комбинаций равно:
Избыточность кода с проверкой на четность минимальна и равна
Для шестибитного кода (рис.5.8)
Минимальное кодовое расстояние кода с проверкой на четность равно двум (dmin=2). Легко убедиться, что проверка на четность позволяет выявить одиночную ошибку, поскольку она изменяет четность. Кроме однократных ошибок, этот код позволяет обнаруживать все ошибки нечетной кратности. Ошибки четной кратности код не обнаруживает. Например, если в кодовой комбинации будут искажены два символа, то четность не изменится и ошибка не будет обнаружена.
Код Бергера или код с контрольным суммированием является несистематическим кодом, у которого проверочные символы представляют собой двоичную запись числа единиц в последовательности информационных символов. Например, информационная последовательность 01011 содержит три единицы. Десятичному числу 3 соответствует двоичная запись 011, поэтому разрешенная кодовая комбинация кода Бергера примет вид: 01011011. Примеры разрешенных кодовых комбинаций данного кода приведены на рис.5.9, где проверочные символы обозначены затемнением.
Минимальное кодовое расстояние кода равно двум. Коды Бергера обнаруживают все одиночные ошибки и некоторую часть многократных ошибок. Эти коды обладают примерно такой же корректирующей способностью, что и код МТК-3, но имеют важное преимущество – они являются разделимыми, что упрощает реализацию кодирующих и декодирующих устройств.
Код с повторением является простейшим кодом, в котором информационные символы повторяются несколько раз. При этом может дублироваться n-раз каждый символ или каждая информационная кодовая комбинация. Например, пятибитной информационной кодовой комбинации 11010 соответствует разрешенная комбинация кода с повторением при n=2: 1111001100 или 1101011010. Таким образом, проверочными символами данного кода являются информационные символы. Код с повторением является разделимым систематическим кодом.
Основные характеристики кода зависят от числа повторений и равны:
Код с повторением способен не только обнаруживать ошибки, но и исправлять их. Однако для исправления даже одиночных ошибок требуется трехкратное повторение, т.е. трехкратное увеличение длины кода. Это слишком большая цена. Поэтому код с повторением хотя и применяется, но является низкоскоростным, поскольку имеет высокую избыточность. Например, при двукратном повторении минимальное кодовое расстояние равно двум (dmin =2), а избыточность Kи=0.5, которая существенно превышает избыточность, рассмотренных ранее кодов.
Код Бауэра (инверсный код). Этот код является разновидностью кода с двукратным повторением, обеспечивающим минимальное кодовое расстояние, равное четырем (dmin =4). При образовании данного кода, кодовые комбинации с четным числом единиц повторяются в неизменном виде (рис.5.10 а), а кодовые комбинации с нечетным числом единиц – в инвертированном (рис.5.10 б).
Код Бауэра называют также инверсным кодом. При небольших длинах кодовых комбинаций (n=10…14) инверсный код по своим корректирующим способностям не уступает более сложным кодам с такой же величиной избыточности.
Рекуррентный код (цепной код). Это непрерывный код, у которого проверочные символы чередуются с информационными по всей длине кодовой последовательности. Формирование проверочных символов в таких кодах осуществляется по рекуррентным правилам. В простейшем случае проверочные символы формируются путем суммирования по модулю 2 двух соседних информационных символов
где bi – i -й проверочный символ; ai – i -й информационный символ, принимающий значение 0 или 1. Далее проверочные символы, сформированные по правилу (7), перемежаются с информационными, образуя непрерывную последовательность (рис.5.11).
Цепной код позволяет установить, какой из символов был искажен: информационный или проверочный. При приеме сравнивают принятые проверочные элементы с вычисленными , т.е. проверяют выполнение условия
Искажение одного информационного символа ai приводит к невыполнению (5.8) для двух символов: и . Таким образом, если условие (5.8) не выполняется для двух соседних проверочных элементов, то искаженным элементом является информационный элемент, находящийся между ними. Это означает, что его следует изменить на противоположный.
[1] На практике количество символов в блоке может лежать в пределах от трех до нескольких сотен.
[2] Под длиной кода также понимают количество знаков кодовой комбинации или разрядность кода.
[3] Напомним, что кратность ошибки – это число позиций кодовой комбинации, в которых под воздействием помех одни символы оказались замененными другими (нули – единицами, единицы - нулями).
© 2014-2022 — Студопедия.Нет — Информационный студенческий ресурс. Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав (0.005)
Под помехой понимается любое воздействие, накладывающееся на полезный сигнал и затрудняющее его прием. Ниже приведена классификация помех и их источников.
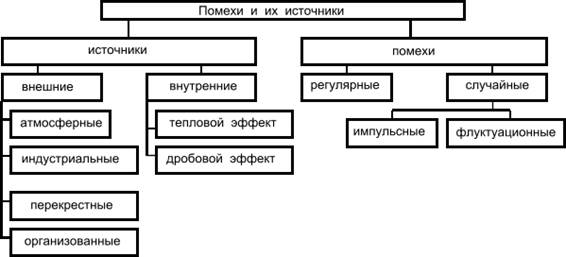
Внешние источники помех вызывают в основном импульсные помехи, а внутренние - флуктуационные. Помехи, накладываясь на видеосигнал, приводят к двум типам искажений: краевые и дробления. Краевые искажения связаны со смещением переднего или заднего фронта импульса. Дробление связано с дроблением единого видеосигнала на некоторое количество более коротких сигналов.
Приведем классификацию помехоустойчивых кодов.
Построение помехоустойчивых кодов в основном связано с добавлением к исходной комбинации (k-символов) контрольных (r-символов) см.на рис.5.1. Закодированная комбинация будет составлять n-символов. Эти коды часто называют (n,k) - коды.
k—число символов в исходной комбинации
r—число контрольных символов
Рис.5.1. Получение (n,k)-кодов.
Коды с обнаружением ошибок
Код с проверкой на четность.
Такой код образуется путем добавления к передаваемой комбинации, состоящей из k информационных символов, одного контрольного символа (0 или 1), так, чтобы общее число единиц в передаваемой комбинации было четным.
Пример 5.1. Построим коды для проверки на четность, где k - исходные комбинации, r - контрольные символы.
Определим, каковы обнаруживающие свойства этого кода. Вероятность Poo обнаружения ошибок будет равна
Так как вероятность ошибок является весьма малой величиной, то можно ограничится
Вероятность появления всевозможных ошибок, как обнаруживаемых так и не обнаруживаемых, равна , где - вероятность отсутствия искажений в кодовой комбинации. Тогда .
При передаче большого количества кодовых комбинаций Nk , число кодовых комбинаций, в которых ошибки обнаруживаются, равно:
Общее количество комбинаций с обнаруживаемыми и не обнаруживаемыми ошибками равно
Тогда коэффициент обнаружения Kобн для кода с четной защитой будет равен
Например, для кода с k=5 и вероятностью ошибки коэффициент обнаружения составит . То есть 90% ошибок обнаруживаем, при этом избыточность будет составлять или 17%.
Код с постоянным весом.
Этот код содержит постоянное число единиц и нулей. Число кодовых комбинаций составит
Пример 5.2. Коды с двумя единицами из пяти и тремя единицами из семи.
Этот код позволяет обнаруживать любые одиночные ошибки и часть многократных ошибок. Не обнаруживаются этим кодом только ошибки смещения, когда одновременно одна единица переходит в ноль и один ноль переходит в единицу, два ноля и две единицы меняются на обратные символы и т.д.
Рассмотрим код с тремя единицами из семи. Для этого кода возможны смещения трех типов.
Вероятность появления не обнаруживаемых ошибок смещения
При p
| k | r | n |
Прием инверсного кода осуществляется в два этапа. На первом этапе суммируются единицы в первой основной группе символов. Если число единиц четное, то контрольные символы принимаются без изменения, если нечетное, то контрольные символы инвертируются. На втором этапе контрольные символы суммируются с информационными символами по модулю два. Нулевая сумма говорит об отсутствии ошибок. При ненулевой сумме, принятая комбинация бракуется. Покажем суммирование для принятых комбинаций без ошибок (1,3) и с ошибками (2,4).
Обнаруживающие способности данного кода достаточно велики. Данный код обнаруживает практически любые ошибки, кроме редких ошибок смещения, которые одновременно происходят как среди информационных символов, так и среди соответствующих контрольных. Например, при k=5, n=10 и . Коэффициент обнаружения будет составлять .
5. Код Грея. Код Грея используется для преобразования угла поворота тела вращения в код. Принцип работы можно представить по рис.5.2. На пластине, которая вращается на валу, сделаны отверстия, через которые может проходить свет. Причём, диск разбит на сектора, в которых и сделаны эти отверстия. При вращении, свет проходит через них, что приводит к срабатыванию фотоприёмников. При снятии информации в виде двоичных кодов может произойти существенная ошибка. Например, возьмем две соседние цифры 7 и 8. Двоичные коды этих цифр отличаются во всех разрядах.
Если ошибка произойдет в старшем разряде, то это приведет к максимальной ошибке, на 360 0 . А код Грея, это такой код в котором все соседние комбинации отличаются только одним символом, поэтому при переходе от изображения одного числа к изображению соседнего происходит изменение только на единицу младшего разряда. Ошибка будет минимальной.
Рис.5.2. Схема съема информации угла поворота вала в код
Код Грея записывается следующим образом
| Номер | Код Грея |
| 0 0 0 0 | |
| 0 0 0 1 | |
| 0 0 1 1 | |
| 0 0 1 0 | |
| 0 1 1 0 | |
| 0 1 1 1 | |
| 0 1 0 1 | |
| 0 1 0 0 | |
| 1 1 0 0 | |
| 1 1 0 1 | |
| 1 1 1 1 | |
| 1 1 1 0 | |
| 1 0 1 0 | |
| 1 0 1 1 | |
| 1 0 0 1 | |
| 1 0 0 0 |
Разряды в коде Грея не имеют постоянного веса. Вес k-разряда определяется следующим образом .
При этом все нечетные единицы, считая слева направо, имеют положительный вес, а все четные единицы отрицательный.
Непостоянство весов разрядов затрудняет выполнение арифметических операций в коде Грея, поэтому необходимо уметь делать перевод кода Грея в обычный двоичный код и наоборот. Алгоритм перевода чисел можно представить следующим образом.
Пусть -- двоичный код, -- код Грея
Тогда переход из двоичного кода в код Грея выполнится по следующему алгоритму
Обратный переход из кода Грея в двоичный код
Корректирующие коды
Корректирующими называются коды позволяющие обнаруживать и исправлять ошибки. Идею представления корректирующих кодов можно представить с помощью N-мерного куба. Возьмем трехмерный куб (рис.5.3), длина ребер, в котором равна одной единице. Вершины такого куба отображают двоичные коды. Минимальное расстояние между вершинами определяется минимальным количеством ребер, находящихся между вершинами. Это расстояние называется кодовым (или хэмминговым) и обозначается буквой d.
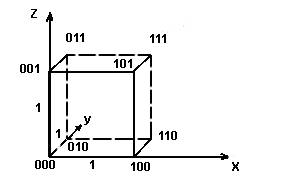
Рис.5.3. Представление двоичных кодов с помощью куба
Иначе, кодовое расстояние - это то минимальное число элементов, в которых одна кодовая комбинация отличается от другой. Для определения кодового расстояния достаточно сравнить две кодовые комбинации по модулю 2. Так, сложив две комбинации
определим, что расстояние между ними d=7.
Для кода с N=3 восемь кодовых комбинаций размещаются на вершинах трехмерного куба. Такой код имеет кодовое расстояние d=1, и для передачи используются все восемь кодовых комбинаций 000,001. 111. Такой код является не помехоустойчивым, он не в состоянии обнаружить ошибку.
Если выберем комбинации с кодовым расстоянием d=2, например, 000,110,101,011, то такой код позволит обнаруживать однократные ошибки. Назовем эти комбинации разрешенными, предназначенными для передачи информации. Все остальные 001,010,100,111 - запрещенные.
Любая одиночная ошибка приводит к тому, что разрешенная комбинация переходит в ближайшую, запрещенную комбинацию (см. рис.5.3). Получив запрещенную комбинацию, мы обнаружим ошибку. Выберем далее вершины с кодовым расстоянием d=3
Большинство корректирующих кодов являются линейными кодами. Линейные коды - это такие коды, у которых контрольные символы образуются путем линейной комбинации информационных символов. Кроме того, корректирующие коды являются групповыми кодами. Групповые коды (Gn) - это такие коды, которые имеют одну основную операцию. При этом, должно соблюдаться условие замкнутости (то есть, при сложении двух элементов группы получается элемент принадлежащий этой же группе ). Число разрядов в группе не должно увеличиваться. Этому условию удовлетворяет операция поразрядного сложения по модулю 2. В группе, кроме того, должен быть нулевой элемент.
Пример 5.3. Ниже приведены кодовые комбинации, являющиеся группой или нет.
1) 1101 1110 0111 1011 – не группа, так как нет нулевого элемента
2) 0000 1101 1110 0111 – не группа, так как не соблюдается условие замкнутости (1101+1110=0011)
3) 000 001 010 011 100 101 110 111 - группа
4) 000 001 010 111 - подгруппа
Большинство корректирующих кодов образуются путем добавления к исходной k - комбинации r - контрольных символов. В итоге в линию передаются n=k+r символов. При этом корректирующие коды называются (n,k) кодами. Как можно определить необходимое число контрольных символов?
Для построения кода способного обнаруживать и исправлять одиночную ошибку необходимое число контрольных разрядов будет составлять
. Это равносильно известной задаче о минимуме числа контрольных вопросов, на которые могут быть даны ответы вида “да” или “нет”, для однозначного определения одного из элементов конечного множества.
Эта формула называется неравенством Хэмминга, или нижней границей Хэмминга для числа контрольных символов.
Код Хэмминга
Код Хэмминга, являющийся групповым (n,k) кодом, с минимальным расстоянием d=3 позволяет обнаруживать и исправлять однократные ошибки. Для построения кода Хэмминга используется матрица H. , где Ak- транспонированная подматрица, En-k - единичная подматрица порядка n-k.
Рассмотрим Построение кода Хэмминга для k=4 символам. Число контрольных символов r=n-k можно определить по неравенству Хэмминга для однократной ошибки. Но так, как нам известно, только исходное число символов k, то проще вычислить по эмпирической формуле
где [.] - означает округление до большего ближайшего целого значения. Вычислим для k=4 . Получим код (n,k)=(7,4); n=7; k=4; r=n-k=3; d=3. Построим матрицу H.
Контрольные символы ej определим по формуле . Например, . Для простоты оставляем только слагаемые с единичными коэффициентами. В результате получим систему линейных уравнений, с помощью которых вычисляются контрольные разряды. Каждый контрольный разряд является как бы дополнением для определенных информационных разрядов для проверки на четность.
При декодировании вычисляем корректор K=k4k2k1
Если корректор равен нулю, следовательно, ошибок нет. Если корректор не равен нулю, то местоположение вектор-столбца матрицы H, совпадающего с вычисленным корректором, указывает место ошибки. При передаче может возникнуть двойная и более ошибка. Корректор также не будет равен нулю. В этом случае произойдет исправление случайного символа и нами будет принят неверный код. Для исключения такого автоматического исправления вводится еще один символ для проверки всей комбинации на четность. Кодовое расстояние d=4. Тогда матрица H будет иметь вид
Пример 5.4. Дана 1101 - исходная комбинация (k=4). Закодировать ее в коде Хэмминга.
По формуле (5.2) находим число контрольных символов r=3. Берем регистр из 7 ячеек памяти. Размещаем исходную комбинацию в ячейках 3,5,6,7.
Находим контрольные символы
е4 = 5 + 6 + 7 = 1 + 0 + 1 = 0
е2 = 3 + 6 + 7 = 1 + 0 + 1 = 0
е1 = 3 + 5 + 7 = 1 + 1 + 1 = 1
Закодированная комбинация будет иметь вид
Допустим, что при передаче возникла ошибка, и мы приняли неверную комбинацию
к 4 = 4 + 5 + 6 + 7 = 0 + 1 + 1 + 1 = 1
к2 = 2 + 3 + 6 + 7 = 0 + 1 + 1 + 1 = 1
к1 = 1 + 3 + 5 + 7 = 1 + 1 + 1 + 1 + 0
K= - в шестом разряде ошибка.
Если бы нам понадобилось построить код и для проверки двойных ошибок, необходимо было бы ввести еще один дополнительный нулевой разряд.
Получим следующий код
0 1 2 3 4 5 6 7
0 1 0 1 0 1 0 1
При передаче и возникновении ошибки код будет иметь вид
0 1 2 3 4 5 6 7
0 1 0 1 0 1 1 1
Проверка в этом случае показала бы, что корректор K=110, а проверка всей комбинации на четность E0 = 0+1+0+1+0+1+1+1=1. Это указывает на одиночную ошибку. Допускается автоматическое исправление ошибки.
Существует следующий алгоритм декодирования кода Хэмминга с d=4
Код (7,4) является минимально возможным кодом с достаточно большой избыточностью. Эффективность кода (k/n) растет с увеличением длины кода
Данные коды относятся к классу блоковых неразделимых кодов, так как в них не представляется возможным выделить информационные и проверочные символы. Все комбинации этих кодов имеют одинаковый вес ( ). Примером является известный код "3 из 7" - семизначный код с постоянным весом .
Одна из основных причин применения этих кодов - их преимущество при использовании в каналах связи, в значительной степени асимметричных. В случае полностью асимметричного канала код с постоянным весом считается совершенным применительно к обнаружению ошибок, так как он обнаруживает все ошибки. Полностью асимметричным является канал, в котором имеет место только один вид ошибок, т.е. возможно только преобразование нулей в единицы либо только единиц в нули.
В двоичном симметричном канале (канал, в котором оба вида ошибок равновероятны) коды с постоянным весом обнаруживают все возможные сочетания нечетного числа ошибок, из которых они не выявляют только те, при которых преобразование нуля в единицу на одних позициях компенсируется преобразованием единиц в нули на других. Кроме того, при заданной длине кодового слова оптимальный код с постоянным весом имеет обычно больше разрешенных комбинаций, чем разделимый код с эквивалентной обнаруживающей способностью. Основной недостаток кода с постоянным весом - его неразделимость.
При использовании кода с постоянным весом прежде всего определяется основной алфавит системы. Затем выбирается код, имеющий достаточное количество кодовых слов. Далее каждой букве алфавита сопоставляется кодовое слово с постоянным весом.

Следовательно, при построении n-разрядного кода с постоянным весом отношение единиц m к количеству нулей (n-m) выбирается таким, чтобы обеспечивалось необходимое количество “разрешенных” комбинаций. Общее количество комбинаций может быть найдено как число сочетаний из n элементов по m: .

Известно, что для любого числа элементов справедливо соотношение: (1).
Максимальное число "разрешенных" кодовых комбинаций для элементов кода с постоянным весом с учетом соотношения (1) выражениями:

при n нечетном;

при n четном.
Очевидно, что во всех остальных случаях, когда

при n нечетном,

при n четном, количество “разрешенных” комбинаций уменьшается.
Например, при применении кода “3 из 7” с количество комбинаций во всех остальных случаях это количество меньше ( ). Поэтому из числа возможных (N= ) отбирается 35 кодовых комбинаций, которые используются в качестве “разрешенных”. Остальные 93 комбинации являются “запрещенными”. Избыточность рассмотренного кода .
Декодирование принятых комбинаций кода с постоянным весом сводится к определению их веса. Если вес отличается от заданного, то это означает, что комбинация принята с ошибкой. При проверке на постоянство веса могут быть обнаружены ошибки любой кратности, за исключением ошибки "сдвига", когда одна из единиц комбинации преобразуется в нуль, а один из нулей - в единицу.
Однако несмотря на простоту, преимущества кодов с постоянным весом невелики. Такие коды используются только в системах, обнаруживающих ошибки. По сравнению с кодом с проверкой на четность для обеспечения той же способности обнаружения ошибок им необходима большая избыточность.
Код "3 из 7" широко применяется при частотной манипуляции в каналах декаметрового диапазона, для которого характерны селективные замирания.
Классификация помех и их источников. Коды с обнаружением ошибок, с проверкой на четность, с постоянным весом. Вероятность возникновения не обнаруживаемых ошибок смещения. Принцип преобразования начального кода и дальнейшая проверка на различные условия.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 10.03.2017 |
| Размер файла | 160,4 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Основы помехоустойчивого кодирования
Актуальность проблемы исследования
Растущая потребность в точной передаче информации
Рассмотреть и проанализировать принцип работы помехоустойчивых кодов
Принципы помехоустойчивого кодирования
· обработка и анализ научных источников
· поиск информации по выбранной теме в Интернет источниках
Помеха - это любое воздействие, которое накладывается на полезный сигнал и затрудняет его прием.
Классификация помех и их источников:
Внешние источники помех создают в основном импульсные помехи, а внутренние флуктуационные. Помехи, накладываясь на видеосигнал, вызываютдва типа искажений: краевые и дробления. Краевые искажения возникают из-за смещения переднего или заднего фронта импульса. Дробление связано с дроблением единого видеосигнала на некоторое количество более коротких сигналов.
2. ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ
В основном принцип помехоустойчивых кодов строится на прибавлении к исходной комбинации (kсимволов) контрольных (rсимволов). Закодированная комбинация будет содержать nсимволов. Коды с таким преобразованием часто называют (n,k) коды.
Где k--число символов в исходной комбинации,
r--число контрольных символов.
2.1.1 Коды с обнаружением ошибок
2.1.1.1 Код с проверкой на четность
Этот код образуется путем прибавления к передаваемому коду, состоящему из k символов, одного контрольного символа (0 или 1), так, чтобы общее число единиц в передаваемом коде было четным.
Определим, каковы обнаруживающие свойства этой комбинации. Вероятность Poo обнаружения ошибок находится по формуле
В связи с тем, что вероятность ошибок является очень малой величиной, то можно сократить формулу
Возможность появления различных ошибок, как обнаруживаемых так и не обнаруживаемых, равна , где - вероятность отсутствия искажений в кодовой комбинации. Тогда .
При передаче большого количества кодовых комбинаций Nk , число комбинаций, в которых ошибка определяется, равно:
Общее число кодовых комбинаций с обнаруживаемыми и не обнаруживаемыми ошибками находится как
Тогда коэффициент обнаружения Kобн для комбинаций с четной защитой равен
2.1.1.2 Код с постоянным весом
Такой код содержит неизменное число единиц и нулей. Число кодовых комбинаций составит
Этот код позволяет найти любые одиночные ошибки и часть многократных ошибок. Не обнаруживаются этим кодом ошибки смещения, когда одновременно одна единица переходит в ноль,а один ноль - в единицу, два ноля и единицы меняются на противоположные символы и т.д.
Для примера возьмём код с тремя единицами из семи. Для такого кода возможны три варианта смещений.
Вероятность возникновения не обнаруживаемых ошибок смещения
Если ошибка произойдет в старшем разряде, то это приведет к максимальной ошибке, на 3600. А код Грея, это такой код в котором все соседние комбинации отличаются только одним символом, поэтому при переходе от изображения одного числа к изображению соседнего происходит изменение только на единицу младшего разряда. Ошибка будет минимальной.
Схема съема информации угла поворота вала в код
Код Грея записывается следующим образом
Разряды в коде Грея не имеют постоянного веса. Вес kразряда определяется следующим образом
При этом все нечетные единицы, считая слева направо, имеют положительный вес, а все четные единицы отрицательный.
2.1.2 Корректирующие коды
Корректирующие коды - это коды, которые позволяют обнаруживать и исправлять ошибки. Принцип представления корректирующих кодов можно представить по средствам N-мерного куба. Возьмем трехмерный куб (рисунок ниже), с длиной ребер равной единице. Вершины куба отображают двоичные коды. Минимальное расстояние между вершинами определяется минимальным количеством ребер, которые находятся между вершинами. Такое расстояние называется кодовым (или хэмминговым) и обозначается буквой d.
Рис.5.3. Представление двоичных кодов с помощью куба
Иначе, кодовое расстояние это то минимальное число элементов, в которых одна кодовая комбинация отличается от другой. Для определения кодового расстояния достаточно сравнить две кодовые комбинации по модулю 2. Так, сложив две комбинации
определим, что расстояние между ними d=7.
Для кода с N=3 восемь кодовых комбинаций размещаются на вершинах трехмерного куба. Такой код имеет кодовое расстояние d=1, и для передачи используются все восемь кодовых комбинаций 000,001. 111. Такой код является не помехоустойчивым, он не в состоянии обнаружить ошибку.
Если выберем комбинации с кодовым расстоянием d=2, например, 000,110,101,011, то такой код позволит обнаруживать однократные ошибки. Назовем эти комбинации разрешенными, предназначенными для передачи информации. Все остальные 001,010,100,111 - запрещенные.
Любая одиночная ошибка приводит к тому, что разрешенная комбинация переходит в ближайшую, запрещенную комбинацию (см. рис.5.3). Получив запрещенную комбинацию, мы обнаружим ошибку. Выберем далее вершины с кодовым расстоянием d=3
Большинство корректирующих кодов представляют собой линейные коды. Линейные коды - это коды, в которых контрольные символы образуются линейным комбинированием информационных символов. Также корректирующие коды являются групповыми кодами. Групповые коды (Gn) - это коды, имеющие одну основную операцию. При том, должно соблюдаться условие замкнутости (то есть, при сложении двух элементов группы получается элемент принадлежащий этой же группе ). Число разрядов в группе не должно увеличиваться. Этому условию удовлетворяет операция поразрядного сложения по модулю 2. В группе, кроме того, должен быть нулевой элемент.
Большая часть корректирующих кодов строятся на добавлении к исходной k комбинации r контрольных символов. По итогу в линию передаются n=k+r символов. Тогда корректирующие коды называются (n,k) кодами. Как определить необходимое количество контрольных символов?
Для построения кодовой комбинации, способной обнаруживать и исправлять одиночную ошибку нужное число контрольных разрядов будет равно
помеха код начальный ошибка
Это равнозначно известной задаче о минимуме числа контрольных вопросов, на которые можно дать ответы вида “да” или “нет”, для однозначного определения одного из элементов конечного множества.
Эта формула называется неравенством Хэмминга, или нижней границей Хэмминга для числа контрольных символов.
Помехоустойчивое кодирование строится на принципе преобразования начального кода и дальнейшей проверке на полученной комбинации того или иного условия. В дальнейшем коды подразделяются на корректирующие и не корректирующие, которые соответственно или исправляют ошибки, или только обнаруживают их. Помехоустойчивое кодирование это наиболее эффективный метод избежать ошибок в передаче данных.
1. Вернер М. Основы кодирования. -- М.: Техносфера, 2004.
2. Зюко А.Г., Кловский Д.Д., Назаров М.В., Финк Л.М. Теория передачи сигналов. М: Радио и связь, 2001 г. -368 с.
3. Кнут Дональд, Грэхем Роналд, Паташник Орен Конкретная математика. Основание информатики -- М.: Мир; Бином. Лаборатория знаний, 2006. -- С. 703.
5. Метрология и радиоизмерения в телекоммуникационных системах. Учебник для ВУЗов. / В.И.Нефедов, В.И. Халкин, Е.В. Федоров и др. - М.: Высшая школа, 2001 г. - 383с.
6. Рудаков А.Н. Числа Фибоначчи и простота числа 2127-1 // Математическое Просвещение, третья серия. -- 2000. -- Т. 4.
7. Стахов А.П. Коды золотой пропорции. -М.: Радио и Связь, 1984.
8. Цапенко М.П. Измерительные информационные системы. - М.: Энергоатом издат, 2005. - 440с.
Подобные документы
Сущность метода перестановочного декодирования. Особенности использования метода вылавливания ошибок. Декодирование циклического кода путем вылавливания ошибок. Распознавание пакетов ошибок как особенность циклических кодов. Вычисление вектора ошибок.
доклад [20,3 K], добавлен 24.05.2012
Коды Боуза-Чоудхури-Хоквингема (БЧХ) – класс циклических кодов, исправляющих многократные ошибки. Отличие методики построения кодов БЧХ от обычных циклических. Конкретные примеры процедуры кодирования, декодирования, обнаружения и исправления ошибок.
реферат [158,2 K], добавлен 16.07.2009
Генерация порождающего полинома для циклического кода. Преобразование порождающей матрицы в проверочную и обратно. Расчет кодового расстояния для линейного блокового кода. Генерация таблицы зависимости векторов ошибок от синдрома для двоичных кодов.
доклад [12,6 K], добавлен 11.11.2010
Использование принципа формирования кода Хэмминга в процессе отладки ошибки. Сложение двоичного числа по модулю в программе и получение кода ошибки для определения разряда, в котором она содержится. Соответствие ошибки определенному разряду операнда.
лабораторная работа [8,0 K], добавлен 29.06.2011
Фаза "избавления" программы от ошибок. Задача обработки ошибок в коде программы. Ошибки с невозможностью автоматического восстановления, оператор отключения. Прекращение выполнения программы. Возврат недопустимого значения. Директивы РНР контроля ошибок.
учебное пособие [62,3 K], добавлен 27.04.2009
Обзор и анализ способов защиты от ошибок и принципы помехоустойчивого кодирования. Проектирование локальной вычислительной сети для компьютеризации рабочих мест персонала коммерческой организации. Выбор топологии сети, оборудования и кабельной системы.
курсовая работа [428,4 K], добавлен 29.04.2015
Определение понятий кода, кодирования и декодирования, виды, правила и задачи кодирования. Применение теорем Шеннона в теории связи. Классификация, параметры и построение помехоустойчивых кодов. Методы передачи кодов. Пример построения кода Шеннона.
Читайте также: