
Алгоритмы сжатия видеоданных реферат
Обновлено: 05.07.2024
Аннотация: В последней лекции речь пойдет об алгоритмах сжатия видео. Будет дан подробный перечень специфических требований, предъявляемых к этим алгоритмам. В лекции подробно рассмотрен алгоритм сжатия MPEG, от истории его создания до последовательности шагов, выполняемых при сжатии изображения
Введение
Основной сложностью при работе с видео являются большие объемы дискового пространства, необходимого для хранения даже небольших фрагментов. Причем даже применение современных алгоритмов сжатия не изменяет ситуацию кардинально. При записи на один компакт-диск "в бытовом качестве", на него можно поместить несколько тысяч фотографий, примерно 10 часов музыки и всего полчаса видео. Видео "телевизионного" формата 720х576 пикселов 25 кадров в секунду в системе RGB требует потока данных примерно в 240 Мбит/сек (т.е. 1.8 Гб в минуту). При этом традиционные алгоритмы сжатия изображений, ориентированные на отдельные кадры , не спасают ситуации, поскольку даже при уменьшении потока в 10 раз он составляет достаточно большие величины.
В результате подавляющее большинство сегодняшних алгоритмов сжатия видео являются алгоритмами с потерей данных. При сжатии используется несколько типов избыточности:
- Когерентность областей изображения - малое изменение цвета изображения в соседних пикселах (свойство, которое эксплуатируют все алгоритмы сжатия изображений с потерями).
- Избыточность в цветовых плоскостях - используется большая важность яркости изображения для восприятия.
- Подобие между кадрами - использование того факта, что на скорости 25 кадров в секунду, как правило, соседние кадры изменяются незначительно.
Первые два пункта знакомы вам по алгоритмам сжатия графики. Использование подобия между кадрами в самом простом и наиболее часто используемом случае означает кодирование не самого нового кадра, а его разности с предыдущим кадром. Для видео типа "говорящая голова" (передача новостей, видеотелефоны), большая часть кадра остается неизменной, и даже такой простой метод позволяет значительно уменьшить поток данных . Более сложный метод заключается в нахождении для каждого блока в сжимаемом кадре наименее отличающегося от него блока в кадре , используемом в качестве базового. Далее кодируется разница между этими блоками. Этот метод существенно более ресурсоемкий.
Основные понятия
Определимся с основными понятиями, которые используются при сжатии видео. Видеопоток характеризуется разрешением, частотой кадров и системой представления цветов. Из телевизионных стандартов пришли разрешения в 720х576 и 640х480, и частоты в 25 (стандарты PAL или SECAM ) и 30 (стандарт NTSC ) кадров в секунду. Для низких разрешений существуют специальные названия CIF - Common Interchange Format, равный 352х288 и QCIF - Quartered Common Interchange Format, равный 176х144. Поскольку CIF и QCIF ориентированы на крайне небольшие потоки, то с ними работают на частотах от 5 до 30 кадров в секунду.
Требования приложений к алгоритму
Для алгоритмов сжатия видео характерны большинство тех же требований приложений, которые предъявляются к алгоритмам сжатия графики, однако есть и определенная специфика:
- Произвольный доступ - подразумевает возможность найти и показать любой кадр за ограниченное время. Обеспечивается наличием в потоке данных так называемых точек входа - кадров , сжатых независимо (т.е. как обычное статическое изображение). Приемлемым временем поиска произвольного кадра считается 1/2 секунды.
- Быстрый поиск вперед/назад - подразумевает быстрый показ кадров , не следующих друг за другом в исходном потоке. Требует наличия дополнительной информации в потоке. Эта возможность активно используется всевозможными проигрывателями.
- Показ кадров фильма в обратном направлении. Редко требуется в приложениях. При жестких ограничениях на время показа очередного кадра выполнение этого требования может резко уменьшить степень сжатия.
- Аудио-визуальная синхронизация - самое серьезное требование. Данные, необходимые для того, чтобы добиться синхронности аудио и видео дорожек, существенно увеличивают размер фильма. Для видеосистемы это означает, что, если мы не успеваем достать и показать в нужный момент времени некий кадр , то мы должны уметь корректно показать, например, кадр , следующий за ним. Если мы показываем фильм без звука, то можно позволить себе чуть более медленный или более быстрый показ. Во времена сравнительно несовершенного немого кино кадры шли настолько неравномерно, насколько неравномерно крутил ручку камеры оператор. Показ без звука фильма, снятого столь несовершенными методами, воспринимается нормально даже при условии, что частота показываемых кадров постоянна (и герои фильма то передвигаются карикатурно быстро, то медленно). Однако смотреть фильм (например, боевик), в котором видеосистема не успевает за звуком - становится мучением.
- Устойчивость к ошибкам - требование, обусловленное тем, что большинство каналов связи ненадежны. Испорченное помехой изображение должно быстро восстанавливаться. Требование достаточно легко удовлетворяется необходимым числом независимых кадров в потоке. При этом также уменьшается степень сжатия, так как на экране 2-3 секунды (50-75 кадров ) может быть одно и то же изображение, но мы будем вынуждены нагружать поток независимыми кадрами.
- Время кодирования/декодирования. Во многих системах (например, видеотелефонах) общая задержка на кодирование-передачу- декодирование должна составлять не более 150 мс. Кроме того, в приложениях, где необходимо редактирование, нормальная интерактивная работа невозможна, если время реакции системы составляет более 1 секунды.
- Редактируемость. Под редактируемостью понимается возможность изменять все кадры так же легко, как если бы они были записаны независимо.
- Масштабируемость - простота реализации концепции "видео в окне". Мы должны уметь быстро изменять высоту и ширину изображения в пикселах. Масштабирование способно породить неприятные эффекты в алгоритмах основанных на ДКП (дискретном косинусном преобразовании). Корректно реализовать эту возможность для MPEG на данный момент можно, пожалуй, лишь при достаточно сложных аппаратных реализациях, только тогда алгоритмы масштабирования не будут существенно увеличивать время декодирования . Интересно, что масштабирование достаточно легко осуществляется в так называемых фрактальных алгоритмах. В них, даже при увеличении изображения в несколько раз, оно не распадается на квадраты , т.е. отсутствует эффект "зернистости". Если необходимо уменьшать изображение (что, хоть и редко, но бывает нужно), то с такой задачей хорошо справляются алгоритмы, основанные на wavelet преобразовании (см. описание JPEG -2000).
- Небольшая стоимость аппаратной реализации. При разработке хотя бы приблизительно должна оцениваться и учитываться конечная стоимость. Если эта стоимость велика, то даже при использовании алгоритма в международных стандартах , производители будут предлагать свои, более конкурентоспособные, алгоритмы и решения. На практике это требование означает, что алгоритм должен реализовываться небольшим набором микросхем.
Упражнение: Покажите, что требования произвольного доступа, быстрого поиска, показа в обратном направлении, аудио-визуальной синхронизации и устойчивости к ошибкам противоречат условию высокой степени сжатия потока.
Описанные требования к алгоритму противоречивы. Очевидно, что высокая степень сжатия подразумевает архивацию каждого последующего кадра с использованием предыдущего. В то же время требования на аудио -визуальную синхронизацию и произвольный доступ к любому кадру за ограниченное время не дают возможности вытянуть все кадры в цепочку. И, тем не менее, можно попытаться прийти к некоторому компромиссу . Сбалансированная реализация, учитывающая систему противоречивых требований , может достигаться на практике за счет настроек компрессора при сжатии конкретного фильма.
С момента опубликования алгоритма сжатия видео Pixel Behaviour Check прошло уже больше полугода (по состоянию на январь 2003 года). Поначалу я даже написал кое-какой код для декодера этого формата. Но вскоре проблемы искусственного интеллекта поглотили мое внимание полностью. Жизнь закружила, заставляя решать совершенно другие вопросы, и увела в сторону от видеосжатия. К сожалению, чтобы довести идею до работающего коммерческого продукта, требуется уделить ей очень много времени. На это времени уже не хватало, а идея осталась ждать лучших времен.
Тогда я как-то упустил из виду, что надо было сделать доступными мои исходники декодера. По себе знаю: желание поработать с любой идеей убивает необходимость писать пробную программу, без которой невозможно проверить идею на деле. Как правило, приходится потратить уйму времени на написание взаимодействия блоков программы, прежде чем дело дойдет до проверки самой идеи. Поэтому я выкладываю исходники декодера. Можете скачать их здесь в виде RAR-архива (205,5 Кбайт). Исходники нормально документированы, так что не составит большого труда в них разобраться. В исходниках не ставилась как таковая цель: написать оптимальный по быстродействию код. Как вы вывернете код декодера, что из этого получится - это уже ваш личный вопрос. Дальнейший же разговор об этом алгоритме пойдет совсем в другом ракурсе.
Погружаясь в пучину искусственного разума, я все более поражался тем обстоятельствам, что работе живого организма вообще чужды те принципы, которыми мы руководствуемся в компьютерном мире. Пытаясь найти связующие нити между необычным устройством частей живого организма и их функциями, мне удалось сделать очень необычную находку. Вот о ней как раз и пойдет речь, так как она позволяет по-другому взглянуть на сжатие видео. Кого интересует более детальная информация об этом, читайте статью вот здесь, правда, по понятным причинам, там больше уклон в сторону искусственного интеллекта, чем в сторону сжатия видео. А мы возвращаемся к нашей теме.
Необычное решение обычной проблемы
Для начала хочу вкратце ознакомить вас с сутью вышеупомянутой статьи. Во время разглядывания изображения наши глаза совершают микродвижения, не заметные ни стороннему наблюдателю, ни нам лично. В среднем частота таких движений - около 100 раз в секунду. Величина смещения изображения по сетчатке глаза во время микродвижения ничтожно мала - в пределах 1-2 соседних рецепторов. То есть видимое изображение как бы дрожит на сетчатке в пределах соседних пикселей (рецепторов). Все эти микродвижения обеспечивают удержание на рецепторах сетчатки контуров всех объектов в видимом изображении. Причем рецепторы очень удачно преобразовывают изображение, и в мозг поступает уже закодированное видео.
Если вы интересовались особенностью современных алгоритмов кодирования видео, то могли обратить внимание, что MPEG и ему подобные модификации стараются выделить контуры двигающихся объектов в сцене, чтобы закодировать только их и тем самым снизить объем видеопотока. Вообще в истории сжимающих алгоритмов прослеживается изживание математических методов сжатия. Постепенно математические алгоритмы достигли того предела, после которого блок данных нельзя больше сжать, не потеряв информации. На смену им появились JPEG и MPEG. Здесь уже сжатие достигалось за счет потерь избыточной информации. В конечном итоге в MPEG добавилась еще и компенсация движения, когда отслеживаются контуры смещающихся объектов, чтобы в следующем кадре передвинуть объекты в новое положение без повторного кодирования их содержимого (которое внутри их контуров). Но беда MPEG заключалась в том, что контуры отслеживались в виде целых блоков (квадратиков), ибо отслеживать реальные контуры слишком сложно. Должно быть, вы видели, как при неуверенном приеме кабельного канала на экране телевизора изображение начинает выводиться скачущими квадратиками.
И вот когда соизмеряешь все это с принципами устройства живого организма, оказывается, что достаточно лишь следовать этим принципам и никакой сложной математики не нужно вообще. Имитируем микродвижение глаза, и вот получили контурное изображение.

Забавное получается изображение. Это не негатив, хотя очень похоже. Можно заметить, как контуры объектов (лепестки, пестик) окрашены разными цветами, а внутри контуров находится черный цвет. Вот по такому изображению можно восстановить все, что было в оригинале, включая тональную окраску объектов. Для этого лишь нужно знать, в какую сторону имитировалось микродвижение глаза.

А вот на этом изображении посмотрите на цвет неба за статуей. Он не однородный, а переходит от светлого тона у плеч статуи в темный тон над ее головой. На контурном изображении вы не заметите в этих местах никаких тональных переходов, хотя они там есть. Разумеется, на темном фоне легко принять слабый переход за его полное отсутствие. В дальнейшем я объясню, что имел в виду, говоря: "не заметите в этих местах никаких тональных переходов".

Любой нацеленный на удаление избыточной информации алгоритм иногда вынужден удалять важную информацию. Вопрос только в том, насколько сильны потери. Обязательно есть места, где алгоритм справляется удачно, и есть места, где происходят большие потери. Очень проблематично найти приемлемое решение. Например, возьмем тот же пример с цветом неба за статуей. При уменьшении объема видеопотока MPEG-алгоритм начинает срезать частотный диапазон тональных переходов неба, в результате чего небо имитируется выложенными рядом квадратиками с близкими цветами.
Выкинуть максимум, ничего не выкидывая
Если мы посмотрим на решение природы, которое она реализовала в рецепторах сетчатки глаза, то вообще не увидим никакого удаления информации. В контурном изображении статуи действительно нет никакого тонального перехода неба, потому что переход в таком изображении закодирован, и просто так разглядеть его не удастся. Объясню это на примере. Допустим, у нас есть изображение с возрастающим цветом.

Возьмем из изображения одну горизонтальную линию. В ней 256 зеленых пикселей. Байтовые значения пикселей различаются на 1. Самый левый пиксель имеет значение 0, самый правый - 255. В итоге имеем 256 возрастающих по значениям байт.
Так вот после микродвижения глаза и последующего преобразования этой линии рецепторами сетчатки, линия превратится в набор 256 байт из одних единичек (или -1, если микродвижение глаза было в другую сторону). То есть из линии исчезнет наглядный для нас тональный переход. А происходит это потому, что рецепторы держат на своих выходах разницу между предыдущим и вновь виденным изображением. В глаз попадает изображение линии, затем происходит микродвижение, теперь в глаз попадает смещенная линия, и только после этого рецепторы выдают в мозг информацию. И каждый рецептор сигнализирует о том, что его "пиксель" отличается на 1 по значению от рядом стоящего "пикселя".
Как можно догадаться, линия из возрастающего зеленого цвета превратилась в линию со сплошным цветом со значением 1. И только зная о микродвижении, можно сказать, что эта сплошная линия обозначает линию с возрастающим цветом. По этим же причинам в контурном изображении статуи мы не увидим никаких тональных переходов неба, а лишь одни единички (двойки, тройки или насколько там сильно изменялся переход). Черный фон изображения, напоминающий о негативе, на самом деле обозначает, что в этих местах находится цвет, принадлежащий некоторому объекту в сцене. Цвет объекта закодирован разницей тонального перехода в контуре объекта. Кстати, не стоит забывать, что у объекта может быть множество внутренних подобъектов, имеющих свои контуры.
Новая последовательность операций
Теперь возвратимся к MPEG-алгоритму. Все его удаление избыточной информации сводится к тому, чтобы привести блок (квадратик) изображения к максимальному содержанию одинаковых по значению байт. Конечно, 256 нулей, единичек, двоек или троек сжать проще всего. На этом основаны все алгоритмы сжатия видео, только каждый из них прокладывает свой путь, чтобы превратить блок данных в набор одинаковых байт. Понятное дело, не каждый путь приводит к хорошим результатам.
В связи с этим работа алгоритмов сжатия видео следующего поколения, как мне кажется, должна выглядеть следующим образом. Сначала кадр изображения преобразуется вот таким "рецепторным" образом. Это сразу снимает избыточную информацию (посмотрите на размеры и количество черных областей в контурных изображениях). Существенный плюс - снятие избыточной информации вообще не обозначает ее потерю. Природа не зря придумывала столь изощренные и не всегда понятные "фокусы" с живыми организмами. Почему же нам не воспользоваться ее принципами. Второй плюс - "рецепторное" преобразование настолько просто реализуется, что имитация рецепторного поля не представляет сложностей на программном уровне.
Но есть и свой минус. А он заключается в том, что нам сейчас известна только маленькая находка с рецепторами. Всего лишь капля в море секретов природы. Возможно, в скором времени мы сможем проникнуть в ее секреты поглубже (имеется в виду способ обработки видеоряда), но пока остальные преобразования придется выполнять стандартными математическими средствами. Поэтому за "рецепторным" преобразованием вероятнее всего должны выполняться самые обычные операции из уже известных алгоритмов сжатия. В принципе, очищенное от избыточной информации изображение можно еще раз "очистить" уже операциями MPEG-сжатия, хотя, по моему мнению, это уже лишнее. Если уж удалось избавиться от избытка, не потеряв при этом информацию, тогда зачем терять ее дальше. Зато компенсация движения из MPEG подойдет сюда как раз кстати. Правда, ее бы немного модифицировать, чтобы уже четко выделенные контуры объектов не испортить.
Что касается алгоритма Pixel Behaviour Check
Дальше разговор пойдет для тех, кто захочет повозиться с доводкой идеи. У меня совсем нет времени заниматься и вопросами искусственного разума, и алгоритмом сжатия. "Рецепторное" преобразование открывает новые возможности в сжатии, поэтому его просто необходимо использовать в PBC-алгоритме. Основная фишка алгоритма - сжатие за счет контроля поведения пикселей видеокадров. Направление контроля - вдоль кадров, а не вдоль линий одиночного кадра, как в обычных алгоритмах. Думаю, такая мысль уже давно обсуждалась, просто никто не предлагал более-менее подходящее ее воплощение. В общем-то, компенсация движения из MPEG немного похожа по сути, но там ведется наблюдение за двигающимися объектами. Здесь же контролируется поведение каждого пикселя кадра, не обращая внимания на двигающиеся объекты. Вполне реально объединить компенсацию движения с контролем поведения остальных пикселей.
Во-вторых, коды поведений пикселей можно перестроить так, чтобы стало возможным кодировать поведение пикселей не только через массив поведений, но и с помощью дополнительных алгоритмов. Если подключать еще и компенсацию движений, тогда для нее также выделяется отдельный код. При желании коды поведений можно перестроить, не прибегая к изменению структур данных. Например, в моих исходных кодах декодера вы можете посмотреть, как я выделил определенные коды для перезагрузки массива поведений, для титров и тому подобного. Вы можете поступить точно таким же образом. Ну, тут не мне вас учить.
В-третьих, в декодере нужно будет написать обратное "рецепторное" преобразование. Оно не сложное, главное - заведомо знать, в какую сторону выполнялась имитация микродвижения глаза. Очень даже возможно, чтобы направление микродвижения могло меняться по ходу кодирования видео. Но это уже частности.
Касательно исходников декодера могу сказать, что я использовал самый простой вариант чтения байт из видеофайла. По этой причине скорость извлечения информации из видеопотока невысока. Лучше всего создать буфер в памяти, куда изначально читается большой блок файла, затем извлекая байты прямо из памяти. По мере опустошения буфера выполняется подгрузка блоков файла в память. Для этого в исходниках придется переписать процедуру чтения из файла.
Когда я экспериментировал с декодером, то заметил, что сам алгоритм декодирования очень прост и не требует серьезной производительности, хотя поначалу мне казалось, что алгоритм сильно нагрузит процессор. Оперировать многопиксельным видеопотоком при декодировании оказалось делом несложным. Совсем другое дело было при кодировании. Я набросал каркас кодировщика на скорую руку (сразу предупрежу: исходники кодировщика в связи с большим периодом времени хранения были утеряны, так что рабочие исходники, к сожалению, нет возможности предоставить). Из-за этого он кодировал видео просто с черепашьей скоростью, к тому же из него как из дырявой бочки начали сыпаться ошибки. А затем жизнь закружила: проблемы, вопросы, решения и так далее. И кодировщик выпал из моего поля зрения, так и оставшись недоработанным.
Надеюсь, вы будете более удачливы. А со своей стороны мне остается только пожелать вам удачи и достаточного времени.
Идут дни, требования к качеству видео постоянно растут. При этом ширина каналов и емкость носителей не могла бы поспевать за этим ростом, если бы не совершенствовались алгоритмы сжатия видео.
Далее пойдет речь именно о некоторых базовых понятиях сжатия видео. Некоторые из них несколько устарели или описаны слишком просто, но при этом дают минимальное представление о том, как все работает.

Поиск векторов движения для компенсации движения (-: Об этом далее.
Характеристики видеопотока
- Формат пикселя. Пиксель не дает нам никакой информации кроме его цвета. Однако восприятие цвета сильно субъективно и были приложены большие усилия для создания систем цветопредставления и цветопередачи, которые были бы приемлемы для большинства людей. Так цвет, видимый нами в реальном мире, является достаточно сложным по спектру частот света, что передать его в цифровом виде крайне сложно, а отобразить еще сложней. Однако было замечено, что все тремя точками в спектре можно достаточно точно приблизить отображаемый цвет к настоящему в метрике восприятия цвета обычным человеком. Эти три точки: красный, зеленый и синий. То есть их линейной комбинацией мы можем покрыть большую часть видимого спектра цветов. Поэтому самый простой способ представления пикселя: RGB24, где под компоненты Red, Green и Blue отводится ровно по 8 бит информации. И так мы можем передать 256 градаций каждого цвета и всего 16,777,216 всевозможных оттенков. Но на практике при хранении такое цветопредставление практически не используется, не только потому что мы тратим целых 3 байта на пиксель, но и по другим причинам, но об этом позже (про YV12).
- Размер кадра. Мы уже взяли и закодировали все пиксели видеопотока и получили огромный массив данных, но он неудобен в работе. Поначалу все очень просто, кадр характеризуется: шириной, высотой, размерами видимой части и форматом (об этом чуть позже). Тут наверняка многим покажутся знакомыми цифры: 640x480, 720x480, 720x576, 1280x720, 1920x1080. Почему? Да потому что, они фигурируют в разных стандартах, например разрешение 720x576 имеет большая часть европейских DVD. Нет, конечно, можно сделать видео размером 417x503, но не думаю, что в этом будет что-то хорошее.
- Формат кадра. Даже зная размеры кадра, мы не можем представить массив пикселей в более удобной форме, не имея информации о способе “упаковки” кадра. В простейшем случае ничего хитрого: берем строку пикселей и выписываем подряд биты каждого закодированного пикселя и так строчку за строчкой. То есть выписываем столько строк, сколько у нас высота по столько пикселей, сколько у нас ширина и все подряд, по порядку. Такая развертка называется прогрессивной (Progressive). Но может быть вы пытались смотреть телепередачи на компьютере без должных настроек и видели “эффект гребенки”, это когда один и тот же объект находится в разных положениях относительно четных и нечетных строк. Можно очень долго спорить о целесообразности чересстрочной (Interlaced) развертки, но факт, что она осталась как пережиток прошлого от традиционного телевидения (кому интересно почитайте про устройство кинескопа). Про методы устранения (деинтерлейсинга) этого неприятного эффекта сейчас говорить не буду. Отсюда и исходят магические обозначения: 576i, 720p, 1080i, 1080p, где указано количество строк (высота кадра) и тип развертки.
- Частота кадров. Одни из стандартных значений: 23.976, 24, 25 и 29.97 кадров в секунду. Например, 25 к/с используется в европейском телевидении, 29.97 в американском, а с частотой 24 к/с снимают на кинопленку. Но откуда взялись “странные” 23.976 и 29.97? Открою секрет: 23.976 = 24/1.001, а 29.97 = 30/1.001, то есть в стандарт американского телевещания NTSC заложен делитель 1.001. Соответственно при показе киноленты произойдет совсем небольшое замедление, которое не будет заметно зрителю, но если это музыкальный концерт, то скорость показа настолько критична, что лучше изредка пропускать кадры и опять же зритель ничего не заметит. Хотя я немного обманул, по американскому телевизору никогда не показывается “24” кадра в секунду, а показывается “30” чересстрочных кадров (и того 59.94 полукадра в секунду, что соответствует частоте их электросети), но они получаются “методом спуска” (3:2 pulldown). Суть метода состоит в том, что у нас есть 2 полных кадра и 5 полукадров, и мы информацией из первого кадра заполним первые 3 полукадра, а из второго оставшиеся 2. То есть последовательность полукадров такова: [1 top, 1 bottom], [1 top, 2 bottom], [2 top, 3 bottom], [3 top, 3 bottom], [4 top, 4 bottom] и т.д. Где top – верхние строки (поля, fields), а bottom нижние, то есть, нечетные и четные начиная сверху соответственно. Таким образом, пленочная картинка вполне смотрибельна на телевизоре, но на динамичных сценах заметны подергивания. Частота кадров может быть и переменной, но с этим связано много проблем, поэтому рассматривать этот случай не буду.
- Глобальные характеристики. Все вышерассмотренное относится к локальным свойствам, то есть тех, которые отражаются во время воспроизведения. Но длительность видеопотока по времени, объем данных, наличие дополнительной информации, зависимости и т.п. Например: видеопоток может содержать в себе один поток, отвечающий левому глазу, а другой поток некоторым образом будет хранить информацию об отличии потока правого глаза от левого. Так можно передавать стерео видео или всенародно известное “3D”.
Почему видео нужно сжимать?
Если мы будем передавать видео несжатым, то ни на что серьезное нам не хватит ни каналов связи, ни места для хранения данных. Пусть мы имеем HD поток с характеристиками:
1920x1080p, 24 к/с, RGB24 и подсчитаем “стоимость” такого потока.
1920*1080*24*24 = 1139 Мегабит/с, а если захотим записать 90 минутный фильм, то потребуется 90*60*1139 = 750 Гигабайт! Круто? Это при том, что видео фильма изумительного качества с тем же 1920x1080p на BluRay будет занимать 20 Гб, то есть разница почти в 40 раз!
Очевидно, что видео требует сжатия, особенно учитывая то, что можно сократить размер в 40 и более раз, оставив при этом зрителя в восторге.
На чем можно сэкономить?
- Кодирование цвета. Наверняка многие знают, что когда-то давно телевидение было черно-белым, но сегодняшнее телевидение целиком в цвете. Но черно-белый телевизор по-прежнему может показывать передачи. Дело в том, что в телесигнале яркость кодируется отдельно от цветных составляющих и представляется в формате YUV (подробнее на википедии). Где Y компонента – это яркость, а U и V – цветовые компоненты и все это вычисляется по “волшебной” формуле:
Y = 0.299 * R + 0.587 * G + 0.114 * B
U = -0.14713 * R - 0.28886 * G + 0.436 * B
V = 0.615 * R - 0.51499 * G - 0.10001 * B
Как видно, преобразование линейное и невырожденное. Следовательно, мы можем с легкостью получать обратно значения R, G и B. Допустим под хранение Y, U и V мы выделим по 8 бит, тогда было 24 бита на пиксель и так и осталось. Никакой экономии. Но человеческий глаз чувствителен к яркости, а вот к цвету он не сильно притязателен. Да и почти на всех изображениях цвета сменяют друг друга не так часто. Если мы условно разделим изображение на слои Y, U и V и яркостный слой оставим без изменений, а слои U и V в два раза сократим по высоте и в два раза по ширине и того в четыре раза. Если раньше на каждый пиксель тратили 24 бита, то теперь тратим 8*4+8+8=48 бит на 4 пикселя, то есть, грубо говоря, 12 бит на пиксель (именно поэтому данный формат кодирования называется YV12). За счет цветового прореживания мы сжали поток в два раза без особых потерь. Например, JPEG всегда выполняет подобное преобразование, но по сравнению с другими возможными артефактами прореживание цвета не несет никакого вреда. - Избыточность изображения. Здесь особо останавливаться не буду, поскольку здесь нет никаких отличий от алгоритмов сжатия изображений. Тот же JPEG сжимает изображение за счет его локальной избыточности методами дискретного косинусного преобразования (DCT) и квантования, о чем опять же можно прочитать на википедии. Обозначу лишь то, что встроенный в кодек алгоритм сжатия статичных изображений должен хорошо сжимать даже отдаленно напоминающее реальные изображения, скоро узнаете зачем.
- Межкадровая разность. Наверняка, любой, посмотрев любое видео, заметит, что изображения не меняются резко, а соседние кадры достаточно похожи. Конечно, резкие смены бывают, но они обычно происходят при смене сцен. И тут возникает проблема: как компьютер должен представлять все то многообразие возможных преобразований изображения? На помощь приходит алгоритм компенсации движения. Про него мной написана статья на википедии. Чтобы не производить копипаст, ограничусь лишь основными моментами. Изображение делится на блоки и в окрестности каждого из них ищется похожий блок на другом кадре (motion estimation), так получается поле векторов движения. А уже при компенсации (motion compensation) учитываются вектора движения, и создается изображение в целом похожее на исходный кадр.

Разница до компенсации движения

Разница между оригиналом и скомпенсированным кадрами
Существуют несколько основных технологий, реализованных в различных кодеках AVI. Например, Indeo 3.2 и Cinepak используют векторную квантизацию, международные стандарты MPEG-1, MPEG-2, MPEG-4, H.261 и H.263 - комбинацию дискретного косинус- преобразования и компенсацию движения. Некоторые из кодеков последнего поколения основаны на дискретном преобразовании элементарной волны (Discrete Wavelet Transform or DWT ). Другие технологии включают алгоритм рекурсивного сжатия изображения, разработанный кампанией Iterated Systems.
Файлы: 1 файл
Методы сжатия видео.doc
Технологии Сжатия Видео
Существуют несколько основных технологий, реализованных в различных кодеках AVI. Например, Indeo 3.2 и Cinepak используют векторную квантизацию, международные стандарты MPEG-1, MPEG-2, MPEG-4, H.261 и H.263 - комбинацию дискретного косинус- преобразования и компенсацию движения. Некоторые из кодеков последнего поколения основаны на дискретном преобразовании элементарной волны (Discrete Wavelet Transform or DWT ). Другие технологии включают алгоритм рекурсивного сжатия изображения, разработанный кампанией Iterated Systems.
1. СЖАТИЕ БЕЗ ПОТЕРЬ
Изображение, полученное после декодирования, полностью совпадает с первоначальным.
2. СЖАТИЕ С ПОТЕРЯМИ
Часть информации теряется в процессе сжатия. Принцип сжатия с потерями основан на ограниченных возможностях человеческого зрения.
СЖАТИЕ С ПРОЦЕНТНЫМИ ПОТЕРЯМИ
Все потери информации лежат в границах, когда человеческий глаз не видит разницу между первоначальным изображением и декомпрессированным сжатым изображением, содержащим ошибки сжатия с потерями.
СЖАТИЕ С ЕСТЕСТВЕННЫМИ ПОТЕРЯМИ
При использовании JPEG, MPEG и других форматов компрессии видео с потерями изображение часто повреждается больше, чем при сжатии с процентными потерями, однако, видео все еще остается приемлемым для человеческого восприятия. Если сжатие и декомпрессия в процессе преобразования повреждают изображение, аналогично естественным повреждениям, то зрение не будет сильно “протестовать”.
Потеря большой детализации в изображении часто приемлема, потому что люди воспринимают объекты в естественном мире с различными уровнями детализации, в зависимости от расстояния до объекта и угла зрения. Люди также привыкли к некоторым естественным помехам, как, например, дождь и туман. Человеческий глаз различает острые грани и линии в изображении, независимо от уровня детализации. Таким образом, человек воспринимает объекты, несмотря на изменения в уровне детализации.
СЖАТИЕ С НЕЕСТЕСТВЕННЫМИ ПОТЕРЯМИ
Достаточно низкое качество сжатия с потерями проявляется в визуальных артефактах, которые резко бросаются в глаза. Примером являются блочные артефакты, видимые в сильно сжатом MPEG видео, и других декодерах, основанных на дискретном косинус - преобразовании изображения.
В некоторый момент алгоритм сжатия выдает неестественные артефакты, воспринимаемые как новые объекты в сцене. Человеческий глаз очень чувствителен к линиям и граням. Одна из его основных функций - распознавать физические объекты, такие как другие люди, потенциальные угрозы и т.д. Объекты для человека ограничены гранями. Следовательно, действие алгоритма сжатия, уничтожающего или создающего кромку изображения, особенно заметно, если человеческий глаз не воспринимает ее как границу объекта.
Все широко используемые кодеки видео являются алгоритмами сжатия с потерями. При достаточно высоком уровне сжатия возникают проблемы с отображением граней. Сжатие на основе векторной квантизации, дискретного косинус - преобразования и преобразования элементарной волны работают с растровым изображением, в котором отсутствует понятия края и линии.
Последовательное кодирование длины (ПКД)
Кодек, использующий последовательное кодирование длины - Microsoft RLE (MRLE)
ПКД также используется, для кодирования коэффициентов DCT в блоках дискретного косинус - преобразования, которые входят в реализацию форматов MPEG, H.261, H.263, и JPEG.
- Хорошо подходит для черно-белых или 8 разрядных графических изображений, таких как кадры анимации.
- Не подходит для естественных изображений с высоким разрешением.
ПКД кодирует последовательность пикселей одинакового цвета (например, черного или белого) как одиночное ключевое слово. Так, например, последовательность пикселей:
77 77 77 77 77 77 77
может быть закодирована как
ПКД хорошо работает с изображениями двоичного уровня (например, черно-белый текст или графика) и 8 битными образами, особенно кадрами мультипликации, содержащими большие последовательности одинакового цвета.
ПКД практически не работает с 24 разрядными естественными изображениями, поскольку в подобных изображениях последовательности пикселей одного цвета практически отсутствуют.
Векторная квантизация
Кодеки, использующие векторную квантизацию: Indeo 3.2, Cinepak.
Indeo и Cinepak работают с YUV представлением цвета.
- Процесс кодирования в вычислительном отношении интенсивен и не может быть выполнен в реальном времени без специализированных аппаратных средств.
- Быстрый процесс декодирования.
- Появление блочных артефактов при высоком сжатии.
При векторной квантизации изображение делится на блоки (4x4 пикселя для Indeo и Cinepak). Как правило, некоторые блоки подобны другим блокам, хотя обычно, они не идентичны. Кодер идентифицирует класс подобных блоков и заменяет их на "универсальный" блочный представитель, составляет поисковую таблицу коротких двоичных кодов к "универсальным" блокам. Как правило, самые короткие двоичные коды представляют наиболее общие классы блоков в изображении. При векторной квантизации (VQ) декодер использует поисковую таблицу, чтобы транслировать приблизительное изображение, составленное из "универсальных" блоков согласно поисковой таблице.
Потери при сжатии неизбежны, поскольку фактические блоки заменены универсальным, который является "достаточно хорошим" приближением к первоначальному блоку. Процесс кодирования медленен и в вычислительном отношении интенсивен, потому что кодер должен накопить статистику по частоте блоков и формировать классы подобных блоков для поисковой таблицы. Процесс декодирования очень быстрый, поскольку основывается на уже созданной поисковой таблице. В векторной квантизации поисковая таблица называется книгой ключей, а индексирующие таблицу двоичные коды - ключевыми словами. Более высокое сжатие достижимо при уменьшении поисковой таблицы. При этом качество изображения ухудшается (появляются блочные артефакты), т.к. поисковая таблица уменьшается.
Дискретное косинус преобразование (ДКП)
Кодеки, использующие дискретное косинус преобразование:
- Появление блочных артефактов при высоком сжатии.
- Излом острых граней. Случайное размытие в острых граней.
- Большие требования к вычислительным мощностям.
ДКП - широко используемое преобразование при сжатии изображения. Двумерное ДКП применяется к блокам 8*8 пикселей.
Человеческий глаз менее чувствителен к высоким компонентам частоты изображения, представленного более высокими коэффициентами ДКП. Больший коэффициент квантования обычно применяется к этим более высоким компонентам частоты. Фактическая стандартная матрица квантования (матрица 64 коэффициентов квантования, один для каждого из 64 коэффициентов ДКП) в JPEG стандарте имеет более высокие коэффициенты квантования для более высокой частоты коэффициенты ДКП. Квантуемые коэффициенты ДКП- тогда выполняемая длина, закодированная как коды переменной длины, которые указывают некоторое число нулевых коэффициентов, сопровождаемых ненулевым коэффициентом. Например, код выполняемой - длины мог бы указывать 4 нулевых коэффициента, сопровождаемые ненулевым коэффициентом уровня 2. Короткие коды переменной длины (например 0110) используются для общих комбинаций, последовательностей из нулей и уровней ненулевого коэффициента. Более длинные коды переменной длины (например 0000001101) используются для менее общих комбинаций, последовательностей из нулей и уровней ненулевого коэффициента. Таким образом, существенное сжатие изображения возможно. ДКП матрица NxN, строки которой - функции косинуса:
N - число выборок в блоке
Дискретное преобразование элементарной волны (DWT- Discrete Wavelet Transform)
Кодеки, использующие DWT:
- В отличие от ДКП, большинство DWT кодеков осуществляют преобразование без блочных артефактов.
- Алгоритмы сжатия, основанные на DWT, часто превосходят по быстродействию ДКП.
- Субъективное качество видеоизображений, сжатых с DWT, может быть лучше, чем при ДКП с таким же коэффициентом сжатия.
- По мере увеличения сжатия на острых гранях появляются размывающие и окружающие артефакты. Этот недостаток является общим с ДКП.
DWT по существу состоит из прохождения сигнала через два фильтра - ФВЧ и ФНЧ. Перед вводом на фильтры, сигнал разбивается на два одинаковых. Далее эти сигналы уменьшаются вдвое. Параметры фильтров выбраны так, чтобы при сложении сигналов с ФНЧ и ФВЧ воспроизводился первоначальный сигнал. Вывод ФВЧ или ФНЧ, может тогда быть подан в другую пару фильтров для повторного процесса.
Простым примером DWT является Haar преобразование элементарной волны:
Haar НПФ (среднее число двух последовательных выборок):
Haar ВПФ (различие двух последовательных выборок):
Вывод ФНЧ - грубое приближение первоначального входного сигнала. Если входной сигнал - изображение, то на выходе фильтра получается изображение с низкой разрешающей способностью. Вывод ФВЧ - добавление деталей (при работе с изображением).
Грубое приближение иногда называется основным уровнем, а добавление деталей - уровнем расширения. Вывод ФВЧ h [n], может подаваться на другую пару фильтров.
При сжатии видеоизображения, DWT может повторяться несколько раз. Алгоритм производит такое же число бит, что и подается на его вход. Результаты на выходе называются коэффициентами преобразования.
Haar преобразование элементарной волны используется, прежде всего, для иллюстративных целей. На практике применяются более сложные фильтры.
Алгоритмы, основанные на DWT позволяют добиться лучших результов, чем ДКП. В последнее время, DWT становится все более популярным.
Контур - основанное кодирование изображения.
Примером контур - основанного кодирования изображения может служить Crystal Net's Surface Fitting Method (SFM). Стандарт MPEG-4 также включает некоторые идеи, связанные с контур - основанным кодированием изображения.
Контур - линия, ограничивающая объект. Текстура - представление структуры поверхности. Контур - основанное кодирование изображения представляет изображения как контуры, ограничивающие текстурируемые области.
Поскольку контуры часто соответствуют границам объектов в сцене, имеются близкие отношения между контур - основанным кодированием изображения и основанным на объектах (представляет изображение как совокупность объектов).
Например, как только текстуры и контуры извлекаются из изображения, последние могут быть закодированы как контрольные точки сплайна (полиномиальная функция представления кривых). Текстуры, в свою очередь, могут быть закодированы с использованием ДКП илиDWT.
Контур - основанное кодирование - одна из новейших технологий сжатия изображений (май 1999г.). Выявление контуров остается нерешенной задачей.
Достигая более высокого сжатия, контур - основанное кодирование изображения может обходить проблемы, с которыми сталкиваются ДКП (JPEG, MPEG, H.261, H.263, DV, и т.д.) и DWT (Intel Indeo, VDONet VDOWave, и т.д.).
Кодирование разности кадров
Кодек, использующий кодирование разности кадров - Cinepak.
- Может достигать лучшего сжатия, чем независимое кодирование отдельных кадров.
- Ошибки накапливаются в кадрах после ключевого кадра, в конечном счете, требуя следующий ключевой кадр. (см. ниже)
Обычно изменения между соседними кадрами незначительны (например, в случае шара, летящего перед статическим фоном, большая часть изображения не меняется между кадрами). На этом основан алгоритм кодирования разности кадров.
Разности кадров кодируются при помощи алгоритмов сжатия неподвижных изображений (DWT, ДКП). Ключевые кадры сжимаются независимо от предыдущих, что ограничивает накопленные ошибки и делает возможным поиск в пределах потока видео. Например, в широко используемом кодеке Cinepak ключевой кадр устанавливается каждые 15 кадров.
Компенсация движения (КД)
Кодеки, использующие КД:
- ClearVideo (RealVideo) Fractal Video Codec от Iterated Systems
- VDOWave от VDONet
- Сжатия видео выше, чем при кодировании разности кадров.
- Стадия кодирования алгоритма КД в вычислительном отношении интенсивна.
- Схема КД, используемая в международных стандартах MPEG, H.261, и H.263 работает лучше всего для сцен с ограниченным движением.
Стандарты MPEG-1, MPEG-2, MPEG-4, H.261 и H.263, основанные на ДКП, используют КД, Iterated Systems ClearVideo (Real Video), VDOWave и VxTreme's - различные формы КД. Метод КД, используемый в MPEG, H.261 и H.263, работает только для переводного движения, т.е. для объектов, перемещающихся поперек фона или панорамирования камеры, но практически не работает для вращения объектов, изменения их размеров или увеличения камеры (см. ниже). Существуют и альтернативные формы КД, обрабатывающие вращательное движение, масштабирование, искажение и другие виды движения в сцене.
Стандарты MPEG-1, MPEG-2, MPEG-4, H.261 и H.263, основанные на ДКП, используют КД , Iterated Systems ClearVideo (Real Video), VDOWave и VxTreme's - различные формы КД. Метод КД, используемый в MPEG , H.261 и H.263 , работает только для переводного движения, т.е. для объектов, перемещающихся поперек фона или панорамирования камеры, но практически не работает для вращения объектов, изменения их размеров или увеличения камеры ( см. ниже ) . Существуют и альтернативные формы КД , обрабатывающие вращательное движение, масштабирование, искажение и другие виды движения в сцене.
Распознавание объектов - нерешенная проблема в обработке изображения. При сжатии , изображение делится на блоки (16x16 пикселей в MPEG-1). Для каждого блока кодируется вектор движения , указывающий на блок в предыдущем или следующем кадре, который схож с кодируемым блоком . Блок ссылки может совпадать с исходным (отсутствие движения) или отличаться от него (движение). Кодеку не требуется распознавать присутствие шара или другого объекта. Он лишь сравнивает блоки пикселей в декодированном кадре и кадре ссылки.
Сжатие достигается путем пересылки или сохранения только вектора движения вместо значений пикселей для полного блока. Кодированные ( "предсказанные" ) блоки формируют декодируемый кадр. Блоком ссылки может быть любой 16x16 блок пикселей в кадре ссылки, который больше всего схож с кодированным блоком. Кадр ссылки должен быть декодирован до начала декодирования текущего кадра. Однако, кадр ссылки не обязательно должен идти перед текущим декодируемым кадром. Фактически, кадром ссылки может быть будущий кадр. MPEG учитывает это через так называемый B (двунаправленный предсказанный) кадр.
В большинстве блоков, как в примере с шаром на статическом фоне , движение отсутствует. Для этих случаев, векторы движения - нулевые .
Для блока или блоков, содержащих перемещающийся шар, векторы движения будут не нулевыми, указывая на блок в предыдущем (или будущем) кадре, который содержит шар. Перемещенный блок вычитается из текущего блока. Вообще, там будут оставлены некоторые ненулевые значения которые будут закодированы, используя ДКП, или DWT . В MPEG, векторы движения закодированы как коды переменной длины для большего сжатия. Процесс кодирования в данном случае называется Оценкой Движения.
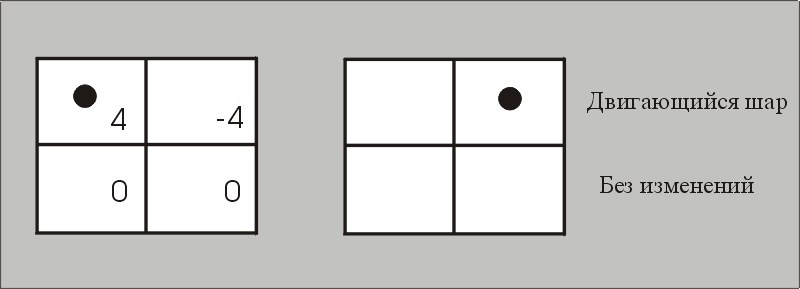
Четыре блока со связанными векторами движения (4, -4, 0, и 0). Верхний левый блок напоминает верхний правый блок в области ссылки (где шар был). Верхний правый блок напоминает верхнюю левую область в области ссылки. Более низкие левые и более низкие правые блоки были неизменны. В этом простом примере, вертикальное смещение нулевое и игнорируется. В этом простом примере, область может быть декодирована, используя один векторы движения. В большем количестве общих случаев, имеется ошибка между предсказанным кадром и текущим кадром. Эта ошибка кодирована, используя все еще схему сжатия изображения(образа) типа блока ДКП.
В этом простом примере, предварительно декодированный кадр также является предыдущим в представленном порядке. Предварительно декодированный или кадр ссылки предшествует текущему кадру по времени. Вообще, имеются различие между декодированным порядком и представленным и порядком. Кадр ссылки может быть и будущим кадром.
Читайте также: