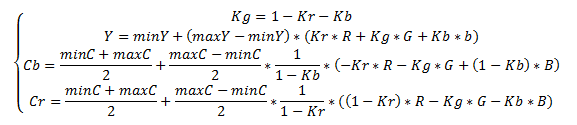Алгоритмы сжатия изображений реферат
Обновлено: 07.07.2024
Степень исключения этой информации как раз и определяется установкой требуемого качества. Далее информация о яркости и цвете кодируется так, что остаются только различия между соседними блоками. В результате процессе обработки остаются только последовательности простых чисел, которые далее легко сжимаютсялюбым алгоритмом сжатия без потерь (например, алгоритмом Хаффмана).Достоинства алгоритма… Читать ещё >
Методы сжатия графической информации ( реферат , курсовая , диплом , контрольная )
Содержание
- Введение
- 1. Виды графической информации по способу кодировки
- 2. Алгоритмы сжатия данных
- 2. 1. Групповое кодирование (RLE)
- 2. 2. Алгоритм Хаффмана
- 2. 3. Алгоритм Хаффмана с фиксированной таблицей CCITTGroup
- 2. 4. LZW-сжатие
- 2. 4. JPEG (Joint Photographic Experts Group)
Далее, этот ряд уже, в свою очередь, сжимается по Хаффману с фиксированной таблицей. Каждая строка изображения сжимается независимо. Считается, что в изображении существенно преобладает белый цвет, и все строки изображения начинаются с белой точки. Для строки, начинающейся с черной точки, считают, что строка начинается белой серией длины 0. На практике в тех случаях, когда в изображении преобладает черный цвет, перед компрессией изображение инвертируется, что записывается в заголовок файла. Достоинства алгоритма в том, что он чрезвычайно прост в реализации, быстр и может быть легко реализован аппаратно. Алгоритм CCITTGroup 3 реализован в формате TIFF.
Схема сжатия Лемпела — Зива — Велча (LZW) (по первым буквам фамилий его разработчиков) — одиниз наиболее распространенных в компьютерной графике. Существует довольно большое семейство LZ-подобных алгоритмов, различающихся, например, методом поиска повторяющихся цепочек. Алгоритм LZW позволяет работать с любым типом данных. Он относится к алгоритмам подстановок, основанными на словарях. Этот алгоритм из данных входного потока строит словарь данных (также называемый переводной таблицей или таблицей строк). В таблице инициализируются все 1-символьные строки. Алгоритм сверяет каждый символ данных, и каждую уникальную2х-символьную строку сохраняет в таблице в виде кода, ссылающегося на соответствующий первый символ. При просматривании очередного символа, для него из таблицы находится уже встречавшаяся строка максимальной длины, затем в таблице сохраняется код для этой строки со следующим символом на входе; на выход выдаётся код этой строки, а следующий символ используется в качестве начала следующей строки. При раскодировании требуется только закодированные данные, а по нему воссоздается соответствующая таблица строк непосредственно по закодированным данным. Декодирование LZW-данных осуществляется в порядке, обратном кодированию. Достоинства алгоритма LZW: — нетнеобходимости вычислять вероятности встречаемости символов;
— таблицу строкможно восстановить, пользуясь только потоком кодов, поэтому нет необходимости сохранять её вместе со сжатыми;
— в исходный графический файл не вносятся искажения, поэтому алгоритм подходит для сжатия растровых данных любого типа. Недостатки:
алгоритм не проводит анализ входных данных поэтому не оптимален. Применяется в форматах GIFи TIFF, включен в стандарт сжатия для модемов V.42bisи PostScriptLevel 2.
2.4 JPEG (Joint Photographic Experts Group) Наиболее известным методом компрессии с потерями является JPEG-компрессия. В основе метода лежит особенность человеческого восприятия: глаз может достаточно четко различать яркость объекта и цветовые контрасты, а плавные изменения в светах и тенях различает значительно меньше. Поэтому при записи часть цветовых данных можно опустить, как предполагается, без заметного ущерба для восприятия. Рисунок2 — Компромисс между качеством и уровнем компрессии
Алгоритм разрабатывалсяспециально для сжатия 24-битных изображений группой экспертов в области фотографииJPEG — JointPhotographicExpertGroup — подразделение в рамках ISO — Международной организации по стандартизации. В JPEGизображение обрабатывается в несколько этапов. Сначала оно конвертируется в особое цветовое пространство, похожее на цветовую модель CIE Lab, где один канал определяет яркость, а в остальных двух каналах уменьшается разрешение (по методу мозаики).Далее изображение разбивается на области квадратной формы размером 8×8 пикселей. В каждойобластиосуществляются достаточно сложные математические преобразования. Происходит запись двух типов информации — усредненной информации о блоке и информации о его деталях. Дальше, в зависимости от необходимой степени сжатия, удаляется то или иное количество дополнительной информации. Соответственно, у файла меньшего размера, качество будет хуже. Одновременно каждаяобластьподвергается разложению на составляющие цвета и происходит подсчет частоты встречаемости каждого цвета. Это позволяет исключить небольшую часть яркостной характеристики, и довольно значительную часть цветовой.
Степень исключения этой информации как раз и определяется установкой требуемого качества. Далее информация о яркости и цвете кодируется так, что остаются только различия между соседними блоками. В результате процессе обработки остаются только последовательности простых чисел, которые далее легко сжимаютсялюбым алгоритмом сжатия без потерь (например, алгоритмом Хаффмана).Достоинства алгоритма LPEG: — можно задать степень сжатия, соответственно подобрать необходимый размер и качество изображения;
при высокой степени сжатия происходит распад изображения на отдельные квадраты (8×8), за счет больших потерь в низких частотах при квантовании и что делает невозможным восстановление исходных данных;
— по границам резких переходов цветов проявляется заметные ореолы — эффект Гиббса. Алгоритмы сжатия с потерями, в частности алгоритм JPEG, не позволяют полностью восстановить изображение до его исходного состояния, а, следовательно, не рекомендуется сжимать изображения несколько раз. Заключение
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.![]()
В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.Алгоритм Хаффмана
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).Перевод в цветовое пространство YCbCr
![]()
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.Субдискретизация компонент цветности
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).Зигзаг-обход матриц
![]()
Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.Одним из наиболее важных и определяющих аспектов как для хранения, так и для передачи является сжатие исходной информации. Форматы графических файлов: JPEG, BMP, PCX. Алгоритм архивации графики, дискретно-косинусное преобразование, этап квантования.
Рубрика Программирование, компьютеры и кибернетика Вид курсовая работа Язык русский Дата добавления 12.03.2009 Размер файла 97,1 K Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
ПОЯСНИТЕЛЬНАЯ ЗАПИСКА
К КУРСОВОЙ РАБОТЕ
Содержание
1. ОБЗОР МЕТОДОВ СЖАТИЯ ИЗОБРАЖЕНИЙ
1.1 Общие понятия, связанные с изображениями
1.2 Требования к JPEG
1.3 Форматы графических файлов
1.4 Сравнительная характеристика алгоритмов сжатия
2 ВЫБОР И ОБОСНОВАНИЕ ВЫБРАННОГО МЕТОДА
2.1 Обоснование выбора метода сжатия изображения
2.2 Алгоритм архивации графики JPEG
2.2.1 Дискретно-косинусное преобразование
2.2.2 Этап квантования
2.2.3 Этап вторичного сжатия
3 РАЗРАБОТКА ПРОГРАММНО-АППАРАТНЫХ МОДУЛЕЙ
3.1 Разработка программного модуля на языке MatLab
3.2 Разработка программно-аппаратного модуля на языке С++
4 АНАЛИЗ ВЫЧИСЛИТЕЛЬНОЙ СЛОЖНОСТИ
5 РУКОВОДСТВО ПОЛЬЗОВАТЕЛЯ
ПРИЛОЖЕНИЕ А. Текст программы на MatLab
Введение
В 1990 году была завершена большая часть технических работ по разработке основных стандартов цифровых систем мультимедиа. Это дает возможность создавать интегрированные цифровые архивы, что в свою очередь будет способствовать развитию средств записи и хранения видео и аудио массивов информации в дополнение к имеющейся текстовой информации. При этом еще большее распространение получат цветные факсы, сканеры, принтеры; еще большим станет их быстродействие. Возникает обширное поле деятельности практически для каждой отрасли научной деятельности, связанной так или иначе с компьютерами: связь, системы обработки данных реального времени, параллельная обработка, разработка микросхем, объектно-ориентированное программирование, микропрограммирование и т.д.
Следует отметить, что одним из наиболее важных и определяющих аспектов как для хранения, так и для передачи является сжатие исходной информации. Большинство пользователей компьютерами уже знакомы со сжатием текстовой информации, позволяющей экономить место на дисках. Для текста необходима компрессия без потерь (нешумовая), если, конечно в дальнейшем потребуется восстановление текста. Такое сжатие обычно позволяет сократить занимаемое место в соотношении 2 : 1.
С другой стороны компрессия с потерями (шумовая) позволяет достичь значительно большего коэффициента - 1000 : 1, однако она применяется только в случае, когда условием ставится только визуальное распознавание изображения.
1 ОБЗОР МЕТОДОВ СЖАТИЯ ИЗОБРАЖЕНИЙ
1.1 Общие понятия, связанные с изображениями
Оцифрованный кадр цветного ТВ-изображения содержит информацию объемом порядка в миллион байт, а снимок на 35-миллиметровой фотопленке - где-то в десять раз больше. Это обширное количество данных - серьезное препятствие перед непосредственным использованием без предварительного сжатия оцифрованного изображения. Современные технические средства позволяют сжимать исходные изображения от 10 до 50 раз без заметного ухудшения их визуального качества. Технология сжатия не существует сама по себе. Для широкого применения систем сжатия информации то ли в целях передачи, то ли в целях хранения изображений, на рынке, куда поступают изделия от многих изготовителей, должен существовать определенный стандарт, позволяющий устройствам разных фирм работать совместно. Существующие ныне рекомендации Международного Телефонного и Телеграфного Консультативного Комитета (CCITT), известные под названием метода Группы 3, определяют условия работы только с двух градационными изображениями. За последние несколько лет был разработан стандарт JPEG, определяющий правила сжатия много градационных как полутоновых, так и цветных неподвижных изображений. Это результат сотрудничества ССITT и ISO (Международная Организация по стандартизации).
Использование компрессии позволяет:
снизить стоимость систем хранения и передачи информации;
увеличить количество каналов связи при сохранении заданной скорости передачи;
хранить больший объем информации;
облегчить сравнение хранимой информации (одинаковые участки данных, сжатые одним и тем же образом, не различаются и в компрессированном виде).
Методы сжатия изображений подразделяются на две большие группы:
в первой предполагается частично утраченная информация (сжатие изображений с потерями);
во второй - информация полная (сжатие без потерь).
В первом случае усеченная часть информации либо субъективно не будет заметна, либо, будучи замеченной, не окажет существенного влияния на восприятие информации в целом. Обычно такие методы применяются для передачи изображения и звука, исходя из особенностей нашего восприятия. Так, на движущемся объекте мы не замечаем мелких деталей, поэтому при сжатии видеозаписи быстродвижущихся предметов их можно не передавать и подробнее прорисовывать только на статичных картинах. Воспроизводя музыку, мы в момент звучания громкого инструмента не обращаем внимание на одновременно звучащий, но более тихий инструмент. Значит, при громком звучании можно не заботиться о качестве синхронных тихих звуков, а передавать их с высокой точностью лишь в моменты низкого уровня громкости. Методы сжатия с потерями позволяют достичь коэффициента десятикратного сжатия, но без значительного ухудшения качества изображения и звука. Наиболее известны сжатия с потерями в форматах JPEG для неподвижных изображений. Однако у десятикратного коэффициента сжатия есть оборотная сторона - это погрешности в записываемой информации.
Методы сжатия без потерь дают более низкий коэффициент сжатия, но зато сохраняют точное значение пикселов исходного изображения. Методы с потерями дают более высокие коэффициенты сжатия, но не позволяют воспроизвести первоначальное изображение с точностью до пиксела. Для файлов, создаваемых программами автоматизированного проектирования или электронных таблиц, очень важно сохранить всю информацию, потому что потеря хотя бы одного бита может изменить смысл всего файла. Совсем другое дело с растровыми данными. Человеческий глаз не воспринимает все тонкие оттенки цвета в обычном растровом изображении. Таким образом, некоторые детали могут быть опущены без видимого нарушения информационного содержания картинки.
1.2 Требования к JPEG
Визуально после сжатия изображение должно оцениваться как "отлично" или "хорошо" в сравнении с оригиналом; метод должен быть применим и удобен при практическом применении для любых многоградационных изображений; иметь невысокую расчетную сложность, что позволило бы избежать дополнительных аппаратных разработок и ограничиться лишь несложным программным обеспечением; JPEG должен иметь следующие режимы работы:
Последовательное кодирование: компоненты изображения кодируются слева направо, сверху вниз;
Прогрессивное кодирование: изображение кодируется при многократном сканировании, в случаях, когда время передачи велико;
Нешумовое кодирование: изображение кодируется с гарантией точного воспроизведения каждого элемента (даже, если это приводит к заметному снижению коэффициента сжатия);
Иерархическое кодирование: изображение разбивается и кодируется по многим уровням, причем нижние уровни могут быть доступны сразу и без предварительного декомпрессирования изображения на всех его уровнях.
1.3 Форматы графических файлов
Одна из основных технологий сегодня, заключается в хранении файлов растровой графики (bitmap file). В файле растровой графики содержится информация, необходимая компьютеру для воссоздания изображения. Мы с вами на экране можем увидеть красивое изображение заката солнца, но компьютер воспринимает эту картину в виде единиц и нулей. То, что делает компьютер с этими единицами и нулями, и позволяет воспроизвести первоначальное изображение. В конечном итоге биты и байты в растровом массиве (bitmap) сообщают компьютеру, в какой цвет окрасить каждый пиксел изображения. Затем компьютер преобразует цвета растрового массива в формат, совместимый с адаптером его дисплея, и передает этот формат аппаратуре вывода видеоизображения.
Вызывает интерес та часть процесса, где происходит преобразование данных в растровый массив. Существует несколько форматов файлов растровой графики, и каждый формат предусматривает собственный способ кодирования информации о пикселах и другой присущей компьютерным изображениям информации. Именно поэтому программа Paint, поставляемая в комплекте ОС Windows 95, совместима с BMP-файлами, но не может считывать файлы формата GIF. Создатели программы Paint наделили ее способностью декодировать графическую информацию, хранящуюся в формате BMP, но не сможет прочитать формат GIF
Распространенные форматы файлов растровой графики:
Макс. число бит/пиксел
Макс. число цветов
Макс. размер изображения, пиксел
Методы сжатия
Кодирование нескольких изображений
2'147'483'647 x 2 147 483 647
Deflation (вариант LZ77)
LZW, RLE и другие*
1.3.1 Файлы BMP
Формат файла BMP (сокращенно от BitMaP) - это "родной" формат растровой графики для Windows, поскольку он наиболее близко соответствует внутреннему формату Windows, в котором эта система хранит свои растровые массивы. Для имени файла, представленного в BMP-формате, чаще всего используется расширение BMP, хотя некоторые файлы имеют расширение RLE, означающее run length encoding (кодирование длины серий). Расширение RLE имени файла обычно указывает на то, что произведено сжатие растровой информации файла одним из двух способов сжатия RLE, которые допустимы для файлов BMP-формата.
В файлах BMP информация о цвете каждого пиксела кодируется 1, 4, 8, 16 или 24 бит (бит/пиксел). Числом бит/пиксел, называемым также глубиной представления цвета, определяется максимальное число цветов в изображении. Изображение при глубине 1 бит/пиксел может иметь всего два цвета, а при глубине 24 бит/пиксел - более 16 млн. различных цветов.
Файл разбит на четыре основные раздела: заголовок файла растровой графики, информационный заголовок растрового массива, таблица цветов и собственно данные растрового массива. Заголовок файла растровой графики содержит информацию о файле, в том числе адрес, с которого начинается область данных растрового массива. В информационном заголовоке растрового массива содержатся сведения об изображении, хранящемся в файле, например, его высоте и ширине в пикселах. В таблице цветов представлены значения основных цветов RGB (красный, зеленый, синий) для используемых в изображении цветов. Программы, считывающие и отображающие BMP-файлы, в случае использования видеоадаптеров, которые не позволяют отображать более 256 цветов, для точной цветопередачи могут программно устанавливать такие значения RGB в цветовых палитрах адаптеров.
Формат собственно данных растрового массива в файле BMP зависит от числа бит, используемых для кодирования данных о цвете каждого пиксела. При 256-цветном изображении каждый пиксел в той части файла, где содержатся собственно данные растрового массива, описывается одним байтом (8 бит). Это описание пиксела не представляет значений цветов RGB, а служит указателем для входа в таблицу цветов файла. Таким образом, если в качестве первого значения цвета RGB в таблице цветов файла BMP хранится R/G/B=255/0/0, то значению пиксела 0 в растровом массиве будет поставлен в соответствие ярко-красный цвет. Значения пикселов хранятся в порядке их расположения слева направо, начиная (как правило) с нижней строки изображения. Таким образом, в 256-цветном BMP-файле первый байт данных растрового массива представляет собой индекс для цвета пиксела, находящегося в нижнем левом углу изображения; второй байт представляет индекс для цвета соседнего справа пиксела и т. д. Если число байт в каждой строке нечетно, то к каждой строке добавляется дополнительный байт, чтобы выровнять данные растрового массива по 16-бит границам.
Структура файла BMP:
1. Заголовок файла растровой графики (14 байт) Сигнатура файла BMP (2 байт) Размер файла (4 байт) Не используется (2 байт) Не используется (2 байт) Местонахождение данных растрового массива (4 байт)
2. Информационный заголовок растрового массива (40 байт) Длина этого заголовка (4 байт) Ширина изображения (4 байт) Высота изображения (4 байт) Число цветовых плоскостей (2 байт) Бит/пиксел (2 байт) Метод сжатия (4 байт) Длина растрового массива (4 байт) Горизонтальное разрешение (4 байт) Вертикальное разрешение (4 байт) Число цветов изображения (4 байт) Число основных цветов (4 байт)
3. Таблица цветов (длина изменяется от 8 до 1024 байт)
4. Собственно данные растрового массива (длина переменная)
1.3.2 Файлы PCX
PCX стал первым стандартным форматом графических файлов для хранения файлов растровой графики в компьютерах IBM PC. На этот формат, применявшийся в программе Paintbrush фирмы ZSoft, в начале 80-х гг. фирмой Microsoft была приобретена лицензия, и затем он распространялся вместе с изделиями Microsoft. В дальнейшем формат был преобразован в Windows Paintbrush и начал распространяться с Windows. Хотя область применения этого популярного формата сокращается, файлы формата PCX, которые легко узнать по расширению PCX, все еще широко распространены сегодня.
1.3.3 Файлы JPEG
Формат файла JPEG (Joint Photographic Experts Group - Объединенная экспертная группа по фотографии, произносится "джейпег) был разработан компанией C-Cube Microsystems как эффективный метод хранения изображений с большой глубиной цвета, например, получаемых при сканировании фотографий с многочисленными едва уловимыми (а иногда и неуловимыми) оттенками цвета. Самое большое отличие формата JPEG от других рассмотренных здесь форматов состоит в том, что в JPEG используется алгоритм сжатия с потерями (а не алгоритм без потерь) информации. Алгоритм сжатия без потерь так сохраняет информацию об изображении, что распакованное изображение в точности соответствует оригиналу. При сжатии с потерями приносится в жертву часть информации об изображении, чтобы достичь большего коэффициента сжатия. Распакованное изображение JPEG редко соответствует оригиналу абсолютно точно, но очень часто эти различия столь незначительны, что их едва можно (если вообще можно) обнаружить.
Процесс сжатия изображения JPEG достаточно сложен и часто для достижения приемлемой производительности требует специальной аппаратуры. Вначале изображение разбивается на квадратные блоки со стороной размером 8 пиксел. Затем производится сжатие каждого блока отдельно за три шага. На первом шаге с помощью формулы дискретного косинусоидального преобразования фуры (DCT) производится преобразование блока 8х8 с информацией о пикселах в матрицу 8x8 амплитудных значений, отражающих различные частоты (скорости изменения цвета) в изображении. На втором шаге значения матрицы амплитуд делятся на значения матрицы квантования, которая смещена так, чтобы отфильтровать амплитуды, незначительно влияющие на общий вид изображения. На третьем и последнем шаге квантованная матрица амплитуд сжимается с использованием алгоритма сжатия без потерь.
Поскольку в квантованной матрице отсутствует значительная доля высокочастотной информации, имеющейся в исходной матрице, первая часто сжимается до половины своего первоначального размера или даже еще больше. Реальные фотографические изображения часто совсем невозможно сжать с помощью методов сжатия без потерь, поэтому 50%-ное сжатие следует признать достаточно хорошим. С другой стороны, применяя методы сжатия без потерь, можно сжимать некоторые изображения на 90%. Такие изображения плохо подходят для сжатия методом JPEG.
При сжатии методом JPEG потери информации происходят на втором шаге процесса. Чем больше значения в матрице квантования, тем больше отбрасывается информации из изображения и тем более плотно сжимается изображение. Компромисс состоит в том, что более высокие значения квантования приводят к худшему качеству изображения. При формировании изображения JPEG пользователь устанавливает показатель качества, величине которого "управляет" значениями матрицы квантования. Оптимальные показатели качества, обеспечивающие лучший баланс между коэффициентом сжатия и качеством изображения, различны для разных изображений и обычно могут быть найдены только методом проб и ошибок.
1.4 Сравнительная характеристика алгоритмов сжатия
В данном разделе были описаны методы сжатия изображений с потерей данных и без потерь. Перечень приведенных алгоритмов далеко не полон, но, дает представление об основных тенденциях развития алгоритмов архивации статических растровых изображений. Во-первых, это ориентация на фотореалистичные изображения с 16 миллионами цветов (24 бита). Во-вторых, использование сжатия с потерями, возможность за счет потерь регулировать качество изображений. В-третьих - использование избыточности изображений в двух измерениях. В-четвертых - появление существенно несимметричных алгоритмов. И, наконец, что для нас важнее всего - увеличивающаяся степень сжатия изображений.
Сейчас не редкость создание базы данных, хранящей изображения, активное использование изображений в программах. Критичность их размеров дает себя знать довольно быстро, поэтому резонно применить один или несколько алгоритмов сжатия. Возможно, идеальным решением будет воспользоваться парой-тройкой новых универсальных алгоритмов, а может быть, стоит разработать специальный. Для электронных фотографий из досье, отпечатков пальцев, рентгеновских снимков созданы специальные алгоритмы, обеспечивающие сжатие до 1000 раз. Если планируется создание большой многогигабайтной базы данных, содержащей однородную информацию, то уменьшение ее хотя бы в 10 раз - это уже серьезно.
При выборе алгоритмов важно понимать их положительные и отрицательные стороны. Если выбран алгоритм с потерей данных, то стоит понять его природу и условия, при которых изображения будут портиться. Использование новых оптимальных алгоритмов позволит сохранить качество изображений, десятки и сотни мегабайт дискового пространства, уменьшит трафик в сети. Методы сжатия развиваются очень быстро. Ежегодно появляются новые алгоритмы и десятки модификаций известных
2 ВЫБОР И ОБОСНОВАНИЕ ВЫБРАННОГО МЕТОДА
2.1 Обоснование выбора метода сжатия изображения
В данном курсовом проекте реализуется сжатие изображений на основе дискретного косинусного преобразования, (дискретное косинусное преобразование используется в широко распространенном стандарте сжатия изображений - JPEG). Рассмотрим сравнительную характеристику выше рассмотренных алгоритмов сжатия изображений (таблица 2.1).
В результате сжатия уменьшается размер изображения, из-за чего уменьшается время передачи изображения по сети и экономится пространство для хранения. Сжатие изображений подразделяют на сжатие с потерями качества и сжатие без потерь. Сжатие уменьшает физический размер изображения, что может потребоваться, если он достаточно велик. Метод сжатия состоит из компрессора и декомпрессора. Компрессор включает в себя математический алгоритм, использованный для уменьшения размера изображения; декомпрессор состоит из информации о том, как реконструировать изображение. При работе с видео чаще всего применяется сжатие с потерями, т.к глаз не в состоянии воспринять потери в изображении при их быстрой смене
1. RLE-сжатие (групповое кодирование). Большая часть растровых изображений, используют RLE-метод сжатия(TIFF, BMP и PCX.). RLE в действительности не сжимает информацию заголовка или цветовую палитру , но сжимает только данные изображения. RLE является методом сжатия без потерь. RLE кодирует данные изображения по строке просмотра за один раз. Оно начинается с первого байта изображения и заканчиваются последним. Имеются два типа проходов, в соответствие с которыми осуществляется сжатие RLE - кодированные и литеральный. Кодированный проход всегда содержит байт для числа пикселов и байт для информации о пикселе. Литеральный проход может содержать пять и более байтов данных. Данный метод сжатия иногда увеличивает размер растрового файла. RLE - метод сжатия является быстрым, простым. Эффективность сжатия зависит от типа данных изображения, подлежащего кодированию. Черно-белые изображения, кодируются хорошо, Сложные изображения, кодируются плохо.
2. LZW — сжатие. Используется форматами TIF и GIF. Предназначен для сжатия неподвижных изображений. LZW сжатие является методом сжатия без потерь. алгоритм, основанный на поиске и замене в исходном файле одинаковых последовательностей данных, для их исключения, и уменьшения размера архива. Данный тип компрессии не вносит искажений в исходный графический файл, и подходит для сжатия растровых данных любого типа. Алгоритм LZW - сжатия уменьшает строку, которая имеет идентичные значения байтов до одного слова кода, а затем сохраняет эту информацию в горизонтальных полосках. Метод сжатия LZW может уменьшить размер изображения до 40%.
3. JPEG был создан в качестве метода сжатия, превосходящего существующие методы. JPEG может сжимать изображения с непрерывными тонами (любое растровое изображение) которые содержат пикселы глубиной 24 бита - с превосходной скоростью и качеством. JPEG является методом сжатия, который теряет данные, которые человеческий глаз не в состоянии воспринять. Он достигает этого путем отбрасывания переходов между цветами. Но переходы между светом и тенью замечаются и не отбрасываются. Т.о. изображение, подвергшееся декомпрессии JPEG, выглядит практически таким же, как и оригинал, хотя не является таковым.
4.CCITT- алгоритм для сжатия факсимальных изображений, метод исп кодир хоффмана (Идея, кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.). Кодир строк происх независ одной от другой, данные идущие до строки и после нее не оказ на нее влияния. Такой вар наз однонапр или гр 3. Сущ еще гр 4-кодир осущ в 2х напр-кодир предыд строки влияет на текущ. Коэф сжатия для гр 3 1/15, для гр 4- 1/20
5. Фрактальное сжатие. Ученые выяснили, что при разбиении сложной структуры на набор фракталов, можно хранить фрагментарный набор на меньшем пространстве по сравнению с оригинальным объектом. Можно масштабировать изображения без искажений и разрешения .
6. Волновое сжатие. Описывает данные, подлежащие сжатию, в терминах частоты, энергии и тактов, а затем записывает определенные атрибуты изображения. Единственным примером этой технологии сжатия, является HARC-CHARC-C демонстрирует весьма поразительные коэффициенты сжатия, в среднем равные 300:1. HARC-C является методом сжатия без потерь.
Читайте также: