
Распознавание печатного и рукописного текста кратко
Обновлено: 02.07.2024
В повседневной жизни мы почти перестали писать от руки, ведь у многих работа и общение связаны со смартфоном, компьютером, и куда быстрее напечатать, нежели написать ручкой или стилусом. Тем не менее, иногда эта возможность не была бы лишней. Сейчас много разговоров про искусственный интеллект, машинное обучение, и кажется, что это можно дать на откуп девайсам. В этой статье мы разберем, как работают алгоритмы распознавания рукописного текста, какие есть проблемы, ведь до сих пор ввод текста на клавиатуре считается более надежным и быстрым, чем написание с помощью стилуса.
В качестве результата распознавания мы должны получить текст в цифровом формате. Существует два вида распознавания: — онлайновый и оффлайновый. Онлайновый — распознавание текста при написании стилусом или пальцем на экране или планшете. Сразу понятно, где написано слово, а где полотно. Первым КПК, который мог распознавать рукописный текст — Apple Newton (1993 год).
Оффлайновый — распознавание уже написанного текста на бумаге. Текст предоставляется в виде скана или фотографии документа, страницы книги и т.п. Является более сложным способом, т.к. в случае онлайн-метода можно проследить процесс написания текста и на этом факте построить алгоритм распознавания. Сложность задачи распознавания рукописного текста — это большое разнообразие почерков, форм, размеров букв и многообразие языков. Так же бумага с текстом может содержать “шумы” — дефекты бумаги, посторонние пятна, что так же усложняет весь процесс.
Существует по крайней мере два подхода, которые дают приемлемый результат: с использованием скрытой марковской модели и искусственной нейронной сети (ИНС). На практике так же применяется гибридный подход с использованием одновременно двух подходов.
Подготовка включает выпрямление, пороговую бинаризацию, удаление шумов.
-
— процесс отделения фона от объекта, в данном случае текст. В результате получаем чёрный текст на белом фоне.
- Удаление шумов — удаление артефактов с изображения, не затрагивая написанный текст.
Также выполняется сегментация строк, слов, символов. Это разделение текста на строки, слова и символы, чтобы в дальнейшем распознавать их с помощью ИНС. Чем меньше строки в тексте похоже на прямые, тем хуже будет работать алгоритм сегментации на строки. Элементарная сегментация на слова работает по принципу, что расстояние между словами больше, чем между буквами.
Рассмотрим подробнее несколько из шагов.
Угол наклона — угол между вертикалью и направлением письма. Шаг выпрямления направление на то, чтобы максимально снизить этот угол.
Не во всех алгоритмах требуется сегментация. Тем не менее, рассмотрим несколько способов разбиения текста на слова.
- Текст разбивается на составные части — компоненты и рассчитывается расстояние между их центрами. В качестве параметра алгоритма принимается какое-то пороговое значение расстояния, которое в дальнейшем можно подобрать исходя из успешности результатов.
- Следующий подход тоже основан на расчете расстояний. С помощью метода опорных векторов находится плоскость, которая разделяет два разных типа данных (символа), а затем с помощью порогового значения текст разбивается на слова.
- Последний подход использует несколько способов расчета расстояния между и их комбинация.
a — исходный кусок текста, b — ограничивающий прямоугольник, с — Евклидово расстояние, d — горизонтальное расстояние
Алгоритм поиска слова по префиксу достаточно быстрый и простой для понимания. Как можно догадаться, используется структура дерево, где рёбра — буквы, а вершина содержит признак слова. Таким образом, слово представляется в виде пути от корневого узла (первой буквы слова) через рёбра — составные буквы слова к вершине с признаком слова.
На вход классификатора может поступать как изображения отдельных слов, так и целых строк. ИНС состоит из слоёв. Именно здесь и происходит вся магия и математека: сначала используются свёрточные нейронные сети (СНС) — операции свёртки и пулинга, и рекуррентные нейронные сети (РНС), а именно один из типов типы LSTM, mdlstm, IDCN. Суть свёртки в том, что каждый фрагмент изображения умножается на матрицу (ядро) свёртки поэлементно, а результат суммируется и записывается в аналогичную позицию выходного изображения (формируется карта признаков — feature map). Операция пулинга позволяет существенно уменьшить объём изображения. Пулинг интерпретируется так: если на предыдущей операции свёртки уже были выявлены некоторые признаки, то для дальнейшей обработки настолько подробное изображение уже не нужно, и оно уплотняется до менее подробного — выполняется уменьшение размерности сформированных карт признаков. Так же конечный результат зависит от датасета — набора изображений для модели для каждой буквы разного почерка.
Текст после классификации может быть проверен на орфографию. На данном этапе в нашем распоряжении только текстовая информация без исходных графических данных. Например, текст разбивается на слова, затем проверяется на наличие в словаре. Если в словаре нет слова, но оно похоже на какое-то, предлагается вариант для исправления. Исправления можно так же тренировать параллельно от классификатора.
Максимальная точность распознавания рукописного текста на английском, результаты которого удалось найти в открытых источниках, достигает величины от 55 до 75%. Пост-обработка дает улучшение результатов в среднем на 15% для каких-то алгоритмов, а может и ухудшить результаты (до 3-6%).
Не забывайте, что большое значение имеет датасет. Каких-то данных про точность инструментов для распознавания русского языка я найти не смог. Тем не менее, на данный момент задача не выглядит нерешаемой, и при серьезном подходе к созданию модели, ее обучению, можно достигнуть высоких результатов распознавания.
Если вас заинтересовала тема глубокого обучения, советую для прочтения эту книгу. Пример реализации алгоритма для распознавания рукописного текста можно найти на GitHub, например, у этого автора.
Несмотря на то, что в настоящее время большинство документов составляется на компьютерах, задача создания полностью электронного документооборота ещё далека до полной реализации. Как правило, существующие системы охватывают деятельность отдельных организаций, а обмен данными между организациями осуществляется с помощью традиционных бумажных документов.
Задача перевода информации с бумажных на электронные носители актуальна не только в рамках потребностей, возникающих в системах документооборота. Современные информационные технологии позволяют нам существенно упростить доступ к информационным ресурсам, накопленным человечеством, при условии, что они будут переведены в электронный вид.
Наиболее простым и быстрым является сканирование документов с помощью сканеров. Результат работы является цифровое изображение документа – графический файл. Более предпочтительным, по сравнению с графическим, является текстовое представление информации. Этот вариант позволяет существенно сократить затраты на хранение и передачу информации, а также позволяет реализовать все возможные сценарии использования и анализа электронных документов. Поэтому наибольший интерес с практической точки зрения представляет именно перевод бумажных носителей в текстовый электронный документ.
На вход системы распознавания поступает растровое изображение страницы документа. Для работы алгоритмов распознавания желательно, чтобы поступающее на вход изображение было как можно более высокого качества. Если изображение зашумлено, нерезко, имеет низкую контрастность, то это усложнит задачу алгоритмов распознавания.
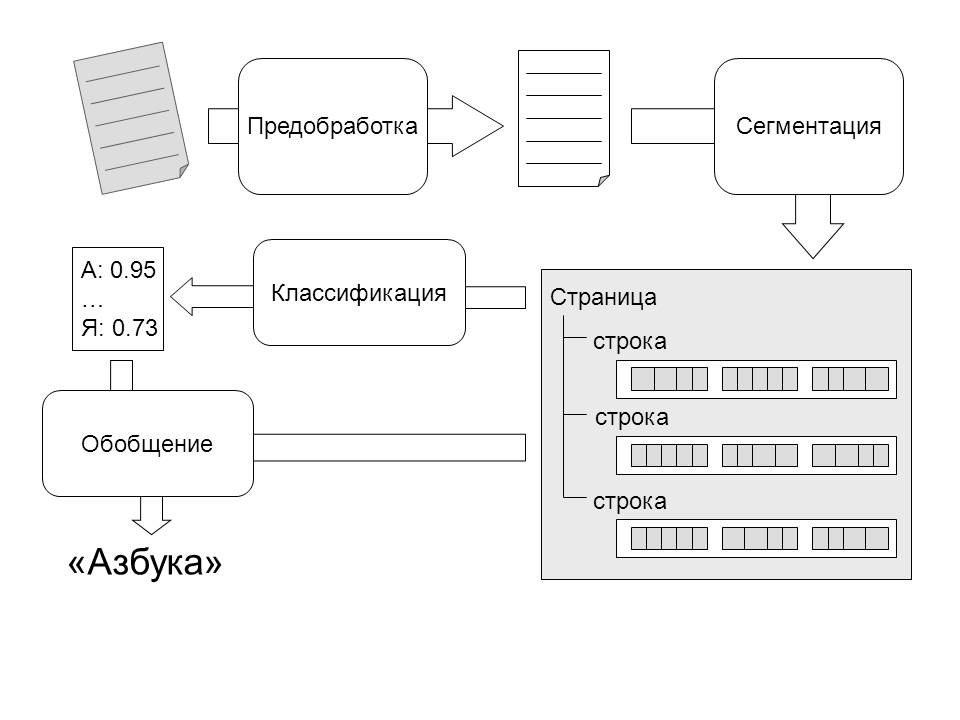
Подготовленное изображение попадает на вход модуля сегментации. Задачей этого модуля является выявление структурных единиц текста – строк, слов и символов. Выделение фрагментов высоких уровней, таких как строки и слова, может быть осуществлено на основе анализа промежутков между тёмными областями.
К сожалению, такой подход не может быть применён для выделения отдельных букв, поскольку, в силу особенностей начертания или искажений, изображения соседних букв могут объединяться в одну компоненту связанности (рис. 1) или наоборот — изображение одной буквы может распадаться на отдельные компоненты связанности (рис. 2). Во многих случаях для решения задачи сегментации на уровне букв используются сложные эвристические алгоритмы.

Рисунок 1. Объединение нескольких букв в одну компоненту связанности.

Рисунок 2. Распадение изображений букв на несвязанные компоненты вследствие низкого качества сканирования.
Полагаем, что для принятия окончательного решения о прохождении границы букв на таком раннем этапе обработки, системе распознавания недостаточно информации. Поэтому задачей модуля сегментации на уровне букв в разработанном алгоритме является нахождение возможных границ символов внутри буквы, а окончательное решение о разбиении слова принимается на последнем этапе обработки, с учётом идентификации отдельных фрагментов изображения как букв. Дополнительным преимуществом такого подхода является возможность работы с начертаниями букв, состоящих из нескольких компонент связанности без специальной обработки таких случаев.
Результатом работы модуля сегментации является дерево сегментации – структура данных, организация которой отражает структуру текста на странице. Самому верхнему уровню соответствует объект страница. Он содержит массив объектов, описывающих строки. Каждая строка в свою очередь включает набор объектов слов. Слова являются листьями этого дерева. Информация о возможных местах разделения слова на буквы храниться в слове, однако отдельные объекты для букв не выделяются. В каждом объекте дерева хранится информация об области, занимаемой соответствующим объектом на изображении. Данная структура легко может быть расширена для поддержки других уровней разбиения, например колонок, таблиц.
Выявленные фрагменты изображения подаются на вход классификатора, выходом которого является вектор возможности принадлежности изображения к классу той или иной буквы. В разработанном алгоритме используется классификатор составной архитектуры, организованный в виде дерева, листьями которого являются простые классификаторы, а внутренние узлы соответствуют операциям комбинирования результатов низлежащих уровней (рис. 3).

Рисунок 3. Архитектура классификатора.
Работа простого классификатора осуществляется в два шага (рис. 4). Сначала по исходному изображению вычисляются признаки. Значение каждого признака является функцией от яркостей некоторого подмножества пикселей изображения. В результате получается вектор значений признаков, который поступает на вход нейронной сети. Каждый выход сети соответствует одной из букв алфавита, а получаемое на выходе значение рассматривается как уровень принадлежности буквы нечёткому множеству.

Рисунок 4. Простой классификатор.
Задачей алгоритма комбинирования является обобщение информации, поступающей в виде входных нечётких множеств и вычисление на их основе выходного нечёткого подмножества множества распознаваемых символов. В качестве алгоритмов комбинирования используются операции теории нечётких множеств (такие как t-нормы и s-нормы), выбор наиболее уверенного эксперта.
Результатом работы классификатора является нечёткое множество, полученное в результате комбинирования на самом верхнем уровне.
На последнем этапе принимается решение о наиболее правдоподобном варианте прочтения слова. Для этого используются уровни возможности прочтения отдельных букв, межбуквенной сегментации и частоты сочетаний букв в русском языке.
Для оценки эффективности разработанного алгоритма было проведено сравнение с двумя существующими системами OCR. Это бесплатная open-source система CuneiForm v12 и коммерческая система ABBYY FineReader 10 Professional Edition.
Сравнение производилось на образцах с разрешением 96 dpi и 180 dpi. В сравнении участвовал текст, состоящий из 300 слов, набранных шрифтами Arial 14pt и Times New Roman 14pt. Текст разрешением 96 dpi был создан на компьютере непосредственно в виде графического файла. Для теста с разрешением 180 dpi текст был распечатан на лазерном принтере, а затем сканирован с указанным разрешением. Фрагмент использованного текста приведен на рис. 5.

Рисунок 5. Фрагмент текста, использованного для тестирования систем распознавания.
Результаты сравнения для 96 dpi представлены в таблице 1.

Таблица 1. Результаты распознавания текста разрешением 96 dpi.
Результаты сравнения для текста с разрешением 180 dpi представлены в таблице 2.

Таблица 2. Результаты распознавания текста разрешением 180 dpi.
Лучшие результаты распознавания для 96 dpi можно объяснить тем, что текущая конфигурация системы была обучена на шрифтах Times New Roman 14pt и Arial 14pt при разрешающей способности 96 dpi. Можно ожидать улучшения результатов для этого текста при добавлении в систему простых классификаторов, обученных распознавать шрифты такого размера.
Суммарно, из 1200 слов было распознано:
• разработанным алгоритмом: 1180 слов (98,33%);
• системой с открытыми кодами CuneiForm: 597 слов (49,75%);
• коммерческой системой ABBYY FineReader: 1200 слов (100%).
Стоит отметить, что при низком разрешении, наличии большого числа шума Cuneiform не справляется с распознаванием текста, в то время как предложенный алгоритм распознает текст в таком качестве.
В целом, можно заключить, что хотя предложенный алгоритм уступает лучшему в данном классе коммерческому продукту фирмы Abbyy, он способен распознавать текст худшего качества, чем способна распознать система c открытыми исходными кодами CuneiForm.
Список использованной литературы.
Квасников В.П., Дзюбаненко А.В. Улучшение визуального качества цифрового изображения путем поэлементного преобразования // Авиационно-космическая техника и технология 2009 г., 8, стр. 200-204
Багрова И. А., Грицай А. А., Сорокин С. В., Пономарев С. А., Сытник Д. А. Выбор признаков для распознавания печатных кириллических символов // Вестник Тверского Государственного Университета 2010 г., 28, стр. 59-73
The concept of a linguistic variable and its application to approximate reasoning, Information Sciences, 8, 199-249; 9, 43-80.
Melin P., Urias J., Solano D., Soto M., Lopez M., Castillo O., Voice Recognition with Neural Networks, Type-2 Fuzzy Logic and Genetic Algorithms. Engineering Letters, 13:2, 2006.
Панфилов С. А. Методы и программный комплекс моделирования алгоритмов управления нелинейными динамическими системами на основе мягких вычислений. Диссертация на соискание ученой степени кандидата технических наук. Тверь, 2005.

Оптическое распознавание символов (англ. Optical Character Recognition – OCR) это новейший метод механического перевода, который преобразует изображения рукописного текста в редактируемый текст на вашем компьютере. Например, он может сделать обычный PDF с отсканированного файла с помощью OCR или PDF на основе изображения, или преобразует рукописный текст в печатный. Технология была разработана в 1933 году, и с каждым годом развивалась. В настоящее время инструменты OCR способны выполнять огромную работу в преобразовании газет, писем, книг и любых других печатных или рукописных материалов в компьютерные редактируемые тексты.
Технология распознавания OCR рукописных текстов в настоящее время используется в больших масштабах, при этом уровень точности транскрипции растет день ото дня, и она уже близка к совершенству. В настоящее время, вы можете просто взять рецепт от врача и использовать технологию OCR, чтобы расшифровать его. Это невероятно!
Часть 1. Рекомендуемые программы для OCR распознавания рукописных текстов
Поиск лучших программ по OCR распознаванию рукописного текста может стать реальной проблемой, тем более, с тех пор как в Интернете появилось множество таких инструментов. Не беспокойтесь! Мы проанализировали рынок за вас, и выделили 3 лучших инструмента по OCR распознаванию рукописного ввода:
PDFelement ProPDFelement Pro- идеальный инструмент для OCR распознавания PDF-файлов. Он может автоматически распознавать отсканированные файлы PDF и делать их редактируемыми с помощью встроенных инструментов редактирования. Кроме этого, он поддерживает несколько языков OCR. Вы можете легко редактировать ваши PDF-тексты, изображения, ссылки и другие элементы. Также у вас есть возможность конвертировать PDF-файлы в другие форматы.
Основные функции данной PDF OCR программы:
- Расширенная функция OCR позволяет легко конвертировать и редактировать отсканированные PDF-файлы.
- Редактирование текстов PDF, изображений и ссылок – такое же простое, как и внесение изменений в Word.
- С легкостью добавляйте подпись, пароль, водяные знаки, знаки, нарисованные от руки в PDF-файлы.
- Размещайте комментарии и примечание, где вам необходимо.
- Вы также можете просто создавать PDF из множества других форматов.
- Кроме этого, у вас есть возможность конвертировать PDF в такие форматы, как Excel, MS Word и другие.

SimpleOCR – одна из самых популярных бесплатных программ OCR доступных в сети. Она довольно проста, но в ее арсенале есть все основные функции сканирования и конвертации, которые важны при работе с OCR распознаванием рукописных текстов. Однако если вы хотите расширенные возможности, то тогда вам необходимо воспользоваться платной версией.
Создатели TopOCR говорят, что они создали наиболее мощную систему распознавания, на основе нейронной сети, которая доступна на рынке, а также обещают пользователям лучшие результаты OCR распознавания данных, сделанных с помощью цифровой камеры. Поэтому, если у вас есть письмо, которое вы хотите оцифровать, сфотографируйте его и позвольте TopOCR выполнить свою работу. К сожалению, приложение было бесплатным некоторое время назад, но сегодня вам придется купить его, чтобы использовать. Но разработчики действительно используют сложные алгоритмы обработки изображений, чтобы гарантировать отличный результат!
Часть 2. Советы по распознаванию рукописного текста с помощью OCR
Применение OCR технологии:Технология OCR широко используется во многих сферах: от юристов и учителей до менеджеров и библиотекарей, любой, кто пишет во время своей работы или имеет дело с рукописями, письмами или подобными документами, считает эту технологию невероятной. Вы можете оцифровать любой рукописный документ быстро и просто, превратить его в редактируемый текст, с которым вы можете работать на вашем компьютере.
Советы: Чтобы улучшить использование OCR распознания рукописного текста, убедитесь, что ваши документы написаны четким почерком и чистые, то есть без помарок, а также используйте мощный сканер. Но главное - выберите профессиональную программу распознавания рукописного текста, которая может гарантировать точность редактируемого текста. Если вы решили использовать инструмент OCR на своем компьютере, вам просто нужно выбрать надежное программное обеспечение, доступное в интернете. Вы также можете попробовать использовать онлайн инструменты, но имейте в виду, что они, возможно, имеют довольно ограниченные функции.

Вам нужно оцифровать рукописные заметки, чтобы отредактировать или проиндексировать их? Или вы хотите скопировать текст с картинки рукописной цитаты? Что вам нужно, так называемый инструмент оптического распознавания символов (OCR).
Инструменты OCR анализируют рукописный или напечатанный текст на изображениях и преобразуют его в редактируемый текст. Некоторые инструменты даже имеют средства проверки орфографии, которые дают дополнительную помощь в случае неузнаваемых слов.
Мы протестировали шесть из лучших инструментов OCR для преобразования рукописного текста в текстовый.
1. Microsoft OneNote

Доступность: Windows, Mac, Интернет, iOS и Android
Microsoft OneNote — это цифровая программа для создания заметок, которая превращается в приложение для распознавания рукописного текста.
Щелкните правой кнопкой мыши на импортированном изображении, и вы увидите опцию Копировать текст из рисунка . Используйте эту команду, чтобы извлечь буквы из изображения и преобразовать их в текст, который вы можете редактировать.
Эта опция работает за считанные секунды, и Microsoft OneNote — это бесплатная облачная программа, которую вы можете использовать на разных устройствах, включая смартфоны, планшеты и компьютеры.
Как и во всех приложениях OCR для рукописного ввода, результаты могут быть неоднозначными. Тем не менее, в целом, он работает довольно хорошо, даже с труднее читать написание. Напишите свои заметки в верхнем регистре, и вы увидите, что это более чем удобное средство.
OneNote — это удивительное приложение. OCR — это одна из многих менее известных функций OneNote , которые стоит попробовать.
Загрузить: Microsoft OneNote для iOS | Android (бесплатно)
2. Google Диск и Google Документы

У Google есть несколько инструментов, которые могут превратить рукописный текст в текст, и есть вероятность, что вы уже получили их.
Сохраненные PDF-файлы не редактируются в самом Drive, но они доступны для поиска. Если у вас есть рукописные заметки, которые вам просто нужно проиндексировать, это идеальное решение.
Но когда вам нужно превратить рукописные заметки в редактируемый текст, вам понадобится сочетание Drive с Google Docs.
Это откроет PDF как текстовый файл в Документах, и вы сможете редактировать или копировать и вставлять текст в другой документ. Он также автоматически сохраняет редактируемую версию в Drive.
Есть третий вариант. Приложение Google Lens (оно входит в состав Google Фото на iOS) позволяет выполнять поиск объектов реального мира, направляя на них камеру. Работает и с текстом тоже. Наведите камеру вашего телефона на какой-нибудь печатный или рукописный текст и подождите несколько секунд, пока он декодируется. Затем нажмите, чтобы завершить поиск.
Благодаря мощному машинному обучению у Google есть одни из лучших инструментов распознавания рукописного ввода.
Загрузить: Google Drive для Android | iOS (бесплатно)
Загрузить: Google Lens для Android | iOS (бесплатно)
3. Простое распознавание текста

Доступность: только для настольных компьютеров
Этот бесплатный инструмент распознает приблизительно 120000 слов и позволяет добавлять больше слов в его словарь. Обладая точностью до 99 процентов, SimpleOCR даже идентифицирует форматированный текст, и можно также настроить его на игнорирование форматирования.
Используйте функцию удаления документов или шумный документ, если конвертируемый вами почерк является грязным.
SimpleOCR — это быстрый инструмент, особенно потому, что вы можете настроить его для расшифровки целых документов, частей или нескольких документов в пакетном режиме.
Однако вышеупомянутая оценка точности явно относится к печатному тексту на рисунках и в меньшей степени к рукописным носителям. Сравнивая SimpleOCR с инструментами Microsoft или Google, вы, вероятно, обнаружите, что последние работают лучше.
4. Интернет-распознавание

Доступность: Интернет
Этот простой веб-сайт позволяет вам пройти процесс загрузки изображения, выбора формата вывода и загрузки готового файла менее чем за минуту.
Однако во время проверки фотографии почерка в формате PNG в формате TXT Online OCR выкладывал случайные тарабарщины, которые вообще не соответствовали почерку, поэтому используйте этот инструмент с недоверием.
Поскольку это дешево и просто в использовании, нет ничего плохого в том, чтобы увидеть, если вы получите лучшие результаты. Одно из возможных преимуществ OCR в Интернете — распознавание множества языков.
Попробуйте: онлайн OCR (бесплатно)
5. TopOCR

Доступность: только для Windows
TopOCR — одна из лучших программ для распознавания рукописного ввода.
Используя исходное изображение, снятое сканером или цифровой камерой, TopOCR предлагает двухпанельный формат, который отображает исходное изображение слева и преобразование справа. Ожидайте, что он будет работать достаточно хорошо, если ваш рукописный текст будет отображаться слева направо. Если в нем есть столбцы, программа, скорее всего, не будет точной.
TopOCR эффективен, поддерживает 11 языков и имеет функцию экспорта в PDF. Бесплатная пробная версия достаточно эффективна, чтобы вы могли легко проверить, будет ли она работать для вас и принять решение о покупке полной, функционально разблокированной программы. Одним из возможных ограничений TopOCR является то, что он работает только на компьютерах с Windows.
Загрузить: TopOCR (бесплатная пробная версия или $ 4.99 за полную программу)
6. FreeOCR

Доступность: только для Windows
Созданная для платформы Windows, FreeOCR работает с изображениями и PDF-файлами. Время преобразования очень быстрое, но точность мрачна.
Оригинальная технология, использующая FreeOCR, никогда не была предназначена для преобразования отсканированного почерка в текст. Тем не менее, некоторые пользователи говорят, что после того, как они использовали программу для этой цели многократно и тщательно следовали инструкциям в руководствах пользователей и форумах, точность стала лучше.
Бесплатные и платные приложения OCR
Когда вам нужно отсканировать рукописный текст в текст, трудно выйти за рамки того, что может предложить Google. Он не безупречен и во многом зависит от того, насколько четким является ваше письмо, но способен дать очень хорошие результаты.
Один верный способ получить лучшие результаты — убедиться в том, что ваше письмо легко читается. Проверьте эти ресурсы для улучшения вашего почерка для советов по этому вопросу.
В этом руководстве мы сосредоточились на бесплатных инструментах. Вы бы лучше с платным приложением вместо этого? Взгляните на наше сравнение OneNote и OmniPage. Сравнение чтобы узнать, стоит ли инвестировать в профессиональное программное обеспечение для распознавания текста.
Читайте также: