
Первая теорема шеннона кратко
Обновлено: 05.07.2024
Первая теорема Шеннона о передаче информации, которая называется также основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
Алгебра логики. Таблица истинности основных логических операций (И ИЛИ НЕ ИНЕ ИЛИНЕ)
Алгебра логики (алгебра высказываний) — раздел математической логики, в котором изучаются логические операции над высказываниями.Чаще всего предполагается что высказывания могут быть только истинными или ложными. Базовыми элементами, которыми оперирует алгебра логики, являются высказывания.
Логическое сложение или дизъюнкция: Дизъюнкция - это сложное логическое выражение, которое истинно, если хотя бы одно из простых логических выражений истинно и ложно тогда и только тогда, когда оба простых логических выраженныя ложны.
Обозначение: F = A + B.
Логическое умножение или конъюнкция: Конъюнкция - это сложное логическое выражение, которое считается истинным в том и только том случае, когда оба простых выражения являются истинными, во всех остальных случаях данное сложеное выражение ложно.
Обозначение: F = A & B.
Логическое отрицание или инверсия: Инверсия - это сложное логическое выражение, если исходное логическое выражение истинно, то результат отрицания будет ложным, и наоборот, если исходное логическое выражение ложно, то результат отрицания будет истинным. Другими простыми слова, данная операция означает, что к исходному логическому выражению добавляется частица НЕ или слова НЕВЕРНО, ЧТО.
Логическое следование или импликация:Импликация - это сложное логическое выражение, которое истинно во всех случаях, кроме как из истины следует ложь. Тоесть данная логическая операция связывает два простых логических выражения, из которых первое является условием (А), а второе (В) является следствием.
Логическая равнозначность или эквивалентность:Эквивалентность - это сложное логическое выражение, которое является истинным тогда и только тогда, когда оба простых логических выражения имеют одинаковую истинность.
Порядок выполнения логических операций в сложном логическом выражении.
Нечеткая логика
раздел математики, являющийся обобщением классической логики и теории множеств. Понятие нечёткой логики было впервые введено профессором Лютфи Заде в 1965 году. В его статье понятие множества было расширено допущением, что функция принадлежности элемента к множеству может принимать любые значения в интервале [0. 1], а не только 0 или 1. Такие множества были названы нечёткими. Также автором были предложены различные логические операции над нечёткими множествами и предложено понятие лингвистической переменной, в качестве значений которой выступают нечёткие множества.
Предметом нечёткой логики является построение моделей приближенных рассуждений человека и использование их в компьютерных системах. В настоящее время существует по крайней мере два основных направления научных исследований в области нечёткой логики:
-нечёткая логика в широком смысле (теория приближенных вычислений);
-нечёткая логика в узком смысле (символическая нечёткая логика).
Причины вирусной опасности. Рост числа опасностей в сфере информационных
Технологий. Примеры ущерба наносимого информационными технологиями. Кража электронной личности.
По мере развития и модернизации компьютерных систем и программного обеспечения возрастает объем и повышается уязвимость хранящихся в них данных. Одним из новых причин, резко повысивших эту уязвимость, является массовое производство программно-совместимых мощных персональных ЭВМ, которое явилось одной из причин появления нового класса программ-вандалов - компьютерных вирусов. Наибольшая опасность, возникающая в связи с опасностью заражения программного обеспечения компьютерными вирусами, состоит в возможности искажения или уничтожения жизненно-важной информации, которое может привести к финансовым и временным потерям.
Растет количество атак, они становятся все изощреннее. Преступления в сфере информационных технологий включают как распространение вредоносных вирусов, взлом паролей, кражу номеров кредитных карточек и других банковских реквизитов (фишинг), так и распространение противоправной информации (клеветы, материалов порнографического характера, материалов, возбуждающих межнациональную и межрелигиозную вражду и т.п.) через Интернет, коммунальные объекты.
Ущерб, наносимый, например, спамом:
1. Трафик. Трафик входящей почты обычно оплачивает получатель спамерских писем. Это особенно актуально в случае подключения к Интернету по телефонной линии. Но и для компаний, оплачивающих трафик при соединении по выделенной линии, финансовый ущерб из-за большого объема пересылаемой почты и соответственно большого объема спама может оказаться очень существенным.
2. Потери рабочего времени. Средний офисный работник тратит на просмотр и удаление спама от 10 до 20 минут рабочего времени в день. Умножив это время на количество сотрудников в крупной компании, можно получить весьма ощутимые цифры.
3. Дыра в системе безопасности. Однако ущерб от спама определяется не только затратами рабочего времени и оплатой лишнего трафика. Спамерские письма систематически становятся переносчиками вредоносных программ, поскольку довольно часто рассылаются с приложениями в виде программ, документов Word или Excel, в которых могут содержаться вирусы.
Кража личности - Жертвами такого рода воровства сейчас становятся примерно 10 млн. американцев в год. В Штатах на сегодня это наиболее активно развивающийся вид преступности. Суммарно жертвы аферистов потеряли $265 млн. Недавно консультант минфина США заявил, что киберпреступность стала более прибыльным занятием, чем наркоторговля. Полицейские службы просто не поспевают за развитием событий. Общее количество зафиксированных компьютерных преступлений так велико, что его просто трудно осознать.
- Не захламляйте собственный компьютер. Содержите в порядке и вовремя обновляйте антивирусные и антишпионские программы, проводите регулярную чистку компьютера.
- Поставьте заслон. Убедитесь, что задействован встроенный межсетевой экран Windows. Еще лучше обзавестись специализированным межсетевым .
- Сначала думайте, а уж потом жмите на клавиши. Многие приходящие по почте вирусы и черви самоустанавливаются в вашем компьютере после одного-единственного нажатия на клавишу.
- Действуйте без промедления. Если у вас украли идентификационную информацию, сразу бейте тревогу. Позвоните в банк, который отвечает за ваши кредитные карты.
Поколения ЭВМ.
1-ое поколение: 1946 г. создание машины ЭНИАК на электронных лампах.
2-ое поколение: 60-е годы. ЭВМ построены на транзисторах.
3-ье поколение: 70-е годы. ЭВМ построены на интегральных микросхемах (ИС).
4-ое поколение: Начало создаваться с 1971 г. с изобретением микропроцессора (МП). Построены на основе больших интегральных схем (БИС) и сверх БИС (СБИС).
ЭВМ первого поколения были ламповыми машинами 50-х годов. Их элементной базой были электровакуумные лампы. Эти ЭВМ были весьма громоздкими сооружениями, содержавшими в себе тысячи ламп, занимавшими иногда сотни квадратных метров территории, потреблявшими электроэнергию в сотни киловатт.
Например, одна из первых ЭВМ – ENIAC – представляла собой огромный по объему агрегат длиной более 30 метров, содержала 18 тысяч электровакуумных ламп и потребляла около 150 киловатт электроэнергии.
Для ввода программ и данных применялись перфоленты и перфокарты. Не было монитора, клавиатуры и мышки. Использовались эти машины, главным образом, для инженерных и научных расчетов, не связанных с переработкой больших объемов данных. В 1949 году в США был создан первый полупроводниковый прибор, заменяющий электронную лампу. Он получил название транзистор.
ЭВМ второго поколения. В 60-х годах транзисторы стали элементной базой для ЭВМ второго поколения. Машины стали компактнее, надежнее, менее энергоемкими. Возросло быстродействие и объем внутренней памяти. Большое развитие получили устройства внешней (магнитной) памяти: магнитные барабаны, накопители на магнитных лентах.
В этот период стали развиваться языки программирования высокого уровня: ФОРТРАН, АЛГОЛ, КОБОЛ. Составление программы перестало зависеть от конкретной модели машины, сделалось проще, понятнее, доступнее.
В 1959 г. был изобретен метод, позволивший создавать на одной пластине и транзисторы, и все необходимые соединения между ними. Полученные таким образом схемы стали называться интегральными схемами или чипами. Изобретение интегральных схем послужило основой для дальнейшей миниатюризации компьютеров.
В дальнейшем количество транзисторов, которое удавалось разместить на единицу площади интегральной схемы, увеличивалось приблизительно вдвое каждый год.
Третье поколение ЭВМ создавалось на новой элементной базе – интегральных схемах (ИС).
ЭВМ третьего поколения начали производиться во второй половине 60-х годов, когда американская фирма IBM приступила к выпуску системы машин IBM-360. Немного позднее появились машины серии IBM-370.
В Советском Союзе в 70-х годах начался выпуск машин серии ЕС ЭВМ. Скорость работы наиболее мощных моделей ЭВМ достигла уже нескольких миллионов операций в секунду. На машинах третьего поколения появился новый тип внешних запоминающих устройств – магнитные диски . Успехи в развитии электроники привели к созданию больших интегральных схем (БИС), где в одном кристалле размещалось несколько десятков тысяч электрических элементов.
ЭВМ пятого поколения будут основаны на принципиально новой элементной базе. Основным их качеством должен быть высокий интеллектуальный уровень, в частности, распознавание речи, образов. Это требует перехода от традиционной фон-неймановской архитектуры компьютера к архитектурам, учитывающим требования задач создания искусственного интеллекта.

Информационная теория

Обработка информации — важная техническая задача, чем, например, преобразование энергии из одной формы в другую. Важнейшим шагом в развитии теории информации стала работа Клода Шеннона (1948). Логарифмическое измерение количества данных было первоначальной теорией, и прикладными задачами по коммуникации в 1928 году. Наиболее известным является вероятностный подход к измерению информации, на основе которого представлен широкий раздел количественной теории.
Отличительная черта вероятностного подхода от комбинаторного состоит в том, что новые предположения об относительной занятости любой системы в разных состояниях и общего количества элементов не учитываются. Ряд информации взят из отсутствия неопределённости в выборе различных возможностей. В основе такого подхода лежат энтропийные и вероятностные множества.
Основная теорема Шеннона о кодировании
Важный практический вопрос при обработке информации — какова мощность системы передачи данных. Можно получить определённый ответ, используя уравнение Шеннона. Оно позволяет точно понять информационную пропускную способность любого сигнального канала. Формула Шеннона в информатике: I = — (p1log2 p1 + p2 log2 p2 +. + pN log2 pN)
Не существует метода кодирования, который бы позволял передавать со скоростью, превышающей vzm, и с произвольно низкой вероятностью ошибки. Другими словами, если поток информации: H '(Z) = vz * H (Z) C он не существует.

Это приводит к замечательному выводу:
- Сигнал, который эффективно передаёт информацию, будет меняться и непредсказуем.
- Эффективный сигнал очень похож на случайный шум.
Передача сигналов
Это означает:
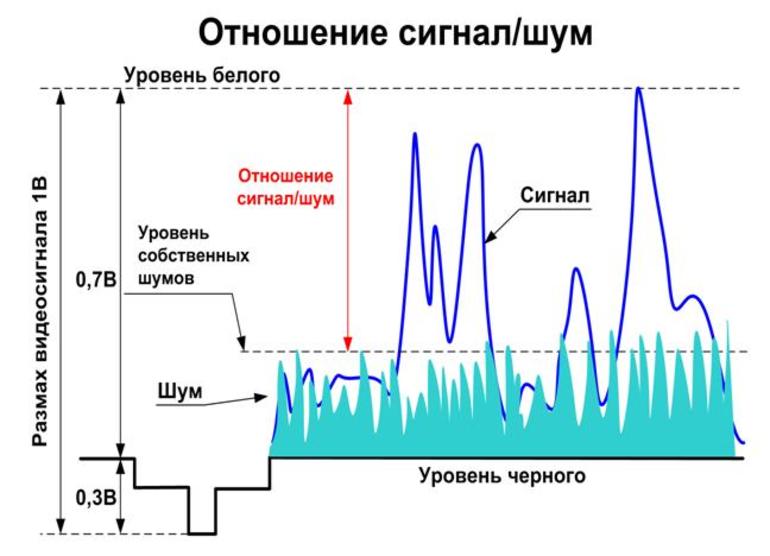
Определённое уравнение
Сигнал и шум не коррелированны, то есть они не связаны каким-либо образом, который позволит предсказать один из них. Суммарная мощность, получаемая при объединении этих некоррелированных ИС, по-видимому, случайно изменяющихся величин, задаётся.
Поскольку сигнал и шум статистически аналогичны, их комбинация будет иметь то же значение форм-фактора, что и сам сигнал или шум. Потому можно ожидать, что комбинированный сигнал и шум, как правило, будут ограничены диапазоном напряжения.
Стоит рассмотреть теперь разделение этого диапазона на полосы одинакового размера. (т. е. каждая из этих полос будет охватывать ИС.) Чтобы предоставить другую метку для каждой полосы, нужны символы или цифры. Поэтому всегда можно указать, какую полосу занимает уровень напряжения в любой момент с точки зрения B-разрядного двоичного числа. По сути, этот процесс является ещё одним способом описания того, что происходит, когда берут цифровые образцы с B-разрядным аналоговым преобразователем, работающим в общем диапазоне.
Нет никакого реального смысла в выборе значения, которое настолько велико. Это потому что шум кубика будет просто иметь тенденцию рандомизировать фактическое напряжение на эту сумму, делая любые дополнительные биты бессмысленными. В результате максимальное количество битов информации, которую можно получить относительно уровня в любой момент, будет определено.
Уравнение Шеннона может использовать:

- Максимально возможную скорость передачи информации по заданному каналу или системе.
- Передачу данных определяется полосой пропускания, уровнем сигнала и шума.
- Поэтому ИС называется законом информационной пропускной способности канала.
При передаче информации некоторые параметры используемых сигналов могут приобретать случайный символ в канале связи, например, из-за многолучевого распространения радиоволн, гетеродинирующих сигналов. В результате амплитуда и начальная фаза данных являются случайными. Согласно статистической теории связи, эти особенности сигналов необходимы для их оптимальной обработки, они определяют как структуру приёмника, так и качество связи.
Помехи разложения всегда присутствуют в границе любого реального сигнала. Однако, если их уровень настолько мал, что вероятность искажения практически равна нулю, можно условно предположить, что все сигналы передаются неискажёнными.
В этом случае средний объём информации, переносимой одним символом, можно считать расчётным: J (Z; Y) = Хапр (Z) — Хапест (Z) = Хапр (Y). Поскольку функция H (Y) = H (Z) и H (Y / Z) = 0, а индекс max = Hmax (Y) — максимальная энтропия источника класса сигнала, возникающая в результате распределения символов Y: p (y1) = p (y2) = … = p (ym) = 1 / My, т. е. Hmax (Y) = logaMy.
Следовательно, главная дискретная ширина полосы таблицы без информации о помехах в единицу времени равна: Cy = Vy • max = Vy • Hmax (Y) = Vy • logaMy или записываться Ck = Vk • logaMy. Где буква Mk — должно быть максимально возможное количество уровней, разрешённых для передачи по этому каналу (конечно, может обозначаться Mk = My).
Согласно теореме, метод кодирования онлайн, который может использоваться и позволяет:
- с данными согласно уравнению H (x) ≤ C — передать всю информацию, сгенерированную источником с ограниченным размером буфера калькулятора;
- в случае H (x)> C такого способа кодирования не существует, поскольку требуется буфер, объём которого определяется избыточной производительностью источника по ширине полосы канала, умноженной на время передачи.
Вероятностный подход к определению вычисления объёма информации — математический вывод формулы Шеннона не является удовлетворительным для метода оценки роли энтропии, отражения элементов системы и может не применяться. Как общий информатический объект невозможно допустить единый способ измерения и его правила.
Задача эффективного кодирования описывается триадой:
Х = 4i> - кодирующее устройство - В.
Выпишем эти значения в виде табл. 1.8. Имеем:
Nmin = H(x) / log2 = 2,85, Ku = (2,92 - 2,85) / 2,92 = 0,024,
Таблица 1.8 Пример к первой теореме Шеннона
| N | Рхi | xi | Код | ni | пi- ∙ Рi | Рхi ∙ log Рхi |
| 0,19 | X1 | 0,38 | -4,5522 | |||
| 0,16 | X2 | 0,48 | -4,2301 | |||
| 0.16 | X3 | 0,48 | -4,2301 | |||
| 0,15 | X4 | 0,45 | -4,1054 | |||
| 0,12 | X5 | 0,36 | -3,6706 | |||
| 0,11 | X6 | 0,33 | - 3,5028 | |||
| 0,09 | X7 | 0,36 | -3,1265 | |||
| 0,02 | X8 | 0,08 | -3,1288 | |||
| Σ=1 | Σ=2,92 | Σ=2,85 |

Доказательство теоремы основывается на следующих рассуждениях. Первоначально последовательность Х = кодируется символами из В так, что достигается максимальная пропускная способность (канал не имеет помех). Затем в последовательность из В длины п вводится r символов и по каналу передается новая последовательность из п + r символов. Число возможных последовательностей длины и + т больше числа возможных последовательностей длины п. Множество всех последовательностей длины п + r может быть разбито на п подмножеств, каждому из которых сопоставлена одна из последовательностей длины п. При наличии помехи на последовательность из п + r выводит ее из соответствующего подмножества с вероятностью сколь угодно малой.
Это позволяет определять на приемной стороне канала, какому подмножеству принадлежит искаженная помехами принятая последовательность длины п + r, и тем самым восстановить исходную последовательность длины п.
Эта теорема не дает конкретного метода построения кода, но указывает на пределы достижимого в создании помехоустойчивых кодов, стимулирует поиск новых путей решения этой проблемы.
Задача эффективного кодирования описывается триадой:
Х = 4i> - кодирующее устройство - В.
Выпишем эти значения в виде табл. 1.8. Имеем:
Nmin = H(x) / log2 = 2,85, Ku = (2,92 - 2,85) / 2,92 = 0,024,
Таблица 1.8 Пример к первой теореме Шеннона
| N | Рхi | xi | Код | ni | пi- ∙ Рi | Рхi ∙ log Рхi |
| 0,19 | X1 | 0,38 | -4,5522 | |||
| 0,16 | X2 | 0,48 | -4,2301 | |||
| 0.16 | X3 | 0,48 | -4,2301 | |||
| 0,15 | X4 | 0,45 | -4,1054 | |||
| 0,12 | X5 | 0,36 | -3,6706 | |||
| 0,11 | X6 | 0,33 | - 3,5028 | |||
| 0,09 | X7 | 0,36 | -3,1265 | |||
| 0,02 | X8 | 0,08 | -3,1288 | |||
| Σ=1 | Σ=2,92 | Σ=2,85 |
Доказательство теоремы основывается на следующих рассуждениях. Первоначально последовательность Х = кодируется символами из В так, что достигается максимальная пропускная способность (канал не имеет помех). Затем в последовательность из В длины п вводится r символов и по каналу передается новая последовательность из п + r символов. Число возможных последовательностей длины и + т больше числа возможных последовательностей длины п. Множество всех последовательностей длины п + r может быть разбито на п подмножеств, каждому из которых сопоставлена одна из последовательностей длины п. При наличии помехи на последовательность из п + r выводит ее из соответствующего подмножества с вероятностью сколь угодно малой.
Это позволяет определять на приемной стороне канала, какому подмножеству принадлежит искаженная помехами принятая последовательность длины п + r, и тем самым восстановить исходную последовательность длины п.
Эта теорема не дает конкретного метода построения кода, но указывает на пределы достижимого в создании помехоустойчивых кодов, стимулирует поиск новых путей решения этой проблемы.
Введем ряд с определений.
Код - (1) правило, описывающее соответствие знаков или их сочетаний первичного алфавита знакам или их сочетаниям вторичного алфавита. (2) набор знаков вторичного алфавита, используемый для представления знаков или их сочетаний первичного алфавита.
Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов.
Кодер - устройство, обеспечивающее выполнение операции кодирования.
Декодер - устройство, производящее декодирование.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Примером обратимого кодирования является представление знаков в телеграфном коде и их восстановление после передачи. Примером кодирования необратимого может служить перевод с одного естественного языка на другой - обратный перевод, вообще говоря, не восстанавливает исходного текста. Безусловно, для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применения кода, поэтому в дальнейшем изложении ограничим себя рассмотрением только обратимого кодирования.
Кодирование предшествует передаче и хранению информации. При этом, как указывалось ранее, хранение связано с фиксацией некоторого состояния носителя информации, а передача - с изменением состояния с течением времени (т.е. процессом). Эти состояния или сигналы будем называть элементарными сигналами - именно их совокупность и составляет вторичный алфавит.
$$n\cdot I_\leqslant m\cdot I_$$ или $$I_\leqslant \frac\cdot I_$$
Отношение m/n, очевидно, характеризует среднее число знаков вторичного алфавита, которое приходится использовать для кодирования одного знака первичного алфавита - будем называть его длиной кода или длиной кодовой цепочки и обозначим К(А,В). Следовательно
Как следует из (3.1), минимально возможным значением средней длины кода будет:
Первая теорема Шеннона, которая называется основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
Приведенное утверждение является теоремой и, следовательно, должно доказываться. Мы опустим доказательство в рамках данного курса. Для нас важно, что теорема открывает принципиальную возможность оптимального кодирования, т.е. построения кода со средней длиной %%K_(A,B)%%. Однако необходимо сознавать, что из самой теоремы никоим образом не следует, как такое кодирование осуществить практически - для этого должны привлекаться какие-то дополнительные соображения, что и станет предметом нашего последующего обсуждения.
Из (3.2) видно, что имеются два пути сокращения %%K_(A,B)%%:
В качестве меры превышения К(А,В) над %%K_(А,В)%% можно ввести относительную избыточность кода Q(А,В):
Используя понятие избыточности кода, можно построить иную формулировку теоремы Шеннона:
- элементарные сигналы (0 и 1) могут иметь одинаковые длительности %%(τ_0= τ_1)%% или разные %%(τ_0 ≠ τ_1)%%;
- длина кода может быть одинаковой для всех знаков первичного алфавита (в этом случае код называется равномерным) или же коды разных знаков первичного алфавита могут иметь различную длину (неравномерный код);
- коды могут строиться для отдельного знака первичного алфавита (алфавитное кодирование) или для их комбинаций (кодирование блоков, слов).
Комбинации перечисленных особенностей определяют основу конкретного способа кодирования, однако, даже при одинаковой основе возможны различные варианты построения кодов, отличающихся своей эффективностью. Нашей ближайшей задачей будет рассмотрение различных схем кодирования для некоторых основ.
Читайте также: