
Механизмы поиска это кратко
Обновлено: 05.07.2024
В Интернете размещены миллионы сайтов, причем наряду с современной актуальной информацией имеется много устаревших ресурсов, немало мусора и недобросовестной рекламы — сайтов, которые рекламируют себя только для того, чтобы повысить собственный рейтинг. Интернет — это наиболее демократичный источник информации, где нет единоличного управления и почти нет цензуры. Каждый может разместить в Сети собственный ресурс и высказать свое мнение. В результате мало кто озабочен тем, чтобы избежать дублирования информации или следовать стандартам, принятым на сайте соседа.
Не зря бытует мнение, что в Сети есть все, но найти там что-либо практически невозможно. Впрочем, противоположная точка зрения, взятая на вооружение поисковой системой Яндекс, гласит, что найти в Интернете можно все. Видимо, для того чтобы находить, нужно уметь искать. В настоящей статье представлен обзор инструментов поиска в сети Интернет, объясняется механизм работы поисковых систем, даются практические рекомендации по оптимизации поиска.
Инструменты поиска
ля поиска в Интернете предназначены различные инструменты: поисковые машины (поисковики), индексированные каталоги (рубрикаторы), рейтинги и топы, метапоисковые системы и тематические списки ссылок, онлайновые энциклопедии и справочники (рис. 1). При этом для поиска разного рода информации наиболее эффективными оказываются различные инструменты. Рассмотрим каждую категорию по отдельности.
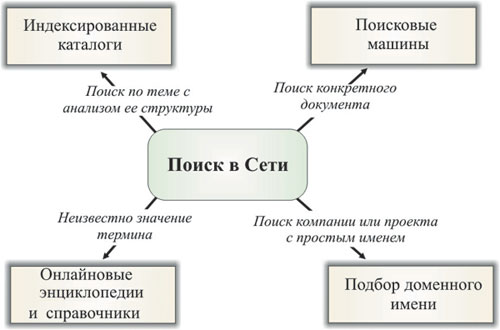
Рис. 1. Для каждого типа информации следует выбирать соответствующий инструмент поиска
Индексированные каталоги
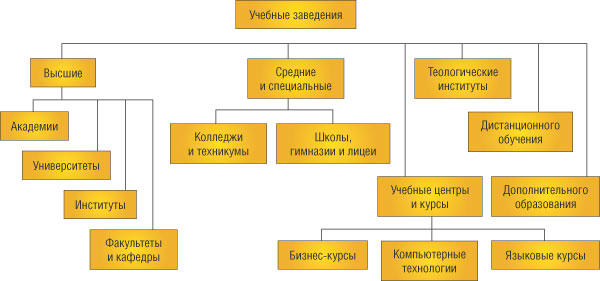
Рис. 2. Классификатор образовательных ресурсов дает наглядное представление о типах учебных заведений в системе образования
Помимо каталогов в Сети существуют рейтинги. От каталога рейтинг отличается тем, что в нем описание ресурсов делают непосредственно их владельцы, а в каталоге — авторы, то есть редакторы каталога.
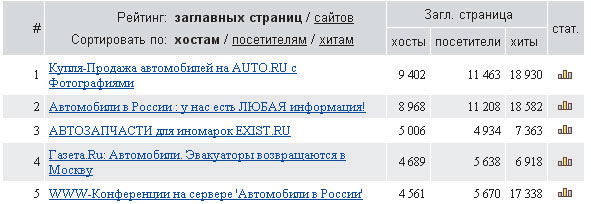
Рис. 3. Пример ранжирования ссылок в рейтинге Rambler Top 100
Тематические коллекции ссылок
Тематические коллекции ссылок — это списки, составленные группой профессионалов или коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним-единственным специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Поисковые машины
Прежде чем рассказать, как функционируют поисковые машины, следует ввести ряд терминов. Если бы компьютер был высокоинтеллектуальной системой, которой можно было бы легко объяснить, что вы ищете, то он выдавал бы вам два-три документа — именно те, которые вам нужны. Но это, к сожалению, не так, и в ответ на запрос вы обычно получаете длинный список документов, многие из которых не имеют никакого отношения к тому, о чем вы спрашивали. Такие документы называются нерелевантными (от англ. relevant подходящий, относящийся к делу). Таким образом, релевантный документ это документ, содержащий искомую информацию. Очевидно, что от умения грамотно делать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантны (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска 100%.
Таким образом, качество поиска определяется двумя параметрами: точностью и полнотой поиска. Стоит отметить, что они взаимозависимы, причем увеличение полноты снижает точность, и наоборот.
Поиск слова
Система позволяет находить:
- все формы слова для русского, английского, польского и других языков; в том числе все формы неизвестных Яндексу слов (отсутствующих в базовом словаре языка) при помощи автоматического моделирования их словоизменения;
- только заданную точную словоформу;
- только формы, производные от заданной формы.
Поиск нескольких слов
Поиск нескольких слов может происходить при:
Поиск в социальной сети
Под поиском в социальной сети понимается учет внетекстовых критериев в поиске, ранжировании и индексировании:
Дополнительные поисковые возможности
К таким возможностям относятся следующие:
Как работает поисковая машина
Поисковая машина состоит из двух частей: робота и поискового механизма. База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в существенно меньшей степени — владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (паука, червяка), который обходит все предписанные серверы и формирует базу данных, существует программа, определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности.
Следует отметить, что поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, понятно, ограничены. Несмотря на то что база данных поисковой машины постоянно обновляется за счет опроса узловых адресов в Сети, внутренние ресурсы поисковой машины и ресурсы Сети несопоставимы, и поэтому вероятность того, что машина даст устаревший адрес или не найдет нужный ресурс, всегда больше нуля. При этом проблема состоит не только в ограниченности внутренних ресурсов, но и в том, что скорость робота ограничена. Увеличение внутренних ресурсов поисковой машины не решает проблемы в силу того, что скорость обхода конечна. При этом нельзя сказать, что поисковая машина внутри имеет копию определенной части исходных ресурсов Интернета, разложенных по каталогу. Полностью информация (исходные документы) хранится отнюдь не всегда, чаще хранится лишь ее часть — так называемый индексированный список (индекс), который гораздо компактнее текста документов.
Для построения индекса исходные данные преобразуются таким образом, чтобы объем базы был минимальным, а поиск осуществлялся очень быстро и давал максимум полезной информации. Объясняя, что такое индексированный список, можно провести параллель с его бумажным аналогом — так называемым конкордансом, то есть словарем, в котором в алфавитном порядке перечислены слова, употребляемые определенным писателем, а также указаны ссылки на них и частота их употребления в произведениях писателя.
Очевидно, что поиск ключевых слов с подобным словарем (индексом) гораздо эффективнее, чем поиск по книге. Отыскать нужное слово в конкордансе и посмотреть по ссылкам, где оно употребляется, намного проще, нежели перелистывать книгу в надежде наткнуться на это слово.
Построение индекса
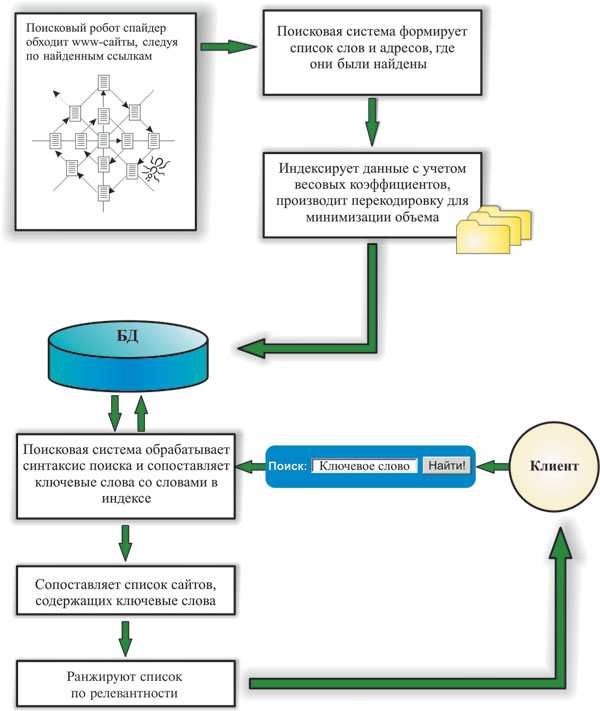
Рис. 4. Роботы-пауки просматривают информационное наполнение Web-страниц и создают индексированную базу поиска по ключевым словам, а затем по запросу пользователя выдают ранжированный по релевантности список сайтов
Поиск по индексу
Поиск по индексу заключается в том, что пользователь формирует запрос и передает его поисковой машине. В случае когда у пользователя имеется несколько ключевых слов, весьма полезно использование булевых операторов.
Наиболее часто используемые булевы операторы:
После того как пользователь передал запрос поисковой системе, она обрабатывает синтаксис запроса и сравнивает ключевые слова со словами в индексе. После этого составляется список сайтов, отвечающих запросу, они ранжируются по релевантности и формируется результат поиска, который и выдается пользователю.
Метапоисковые системы
Интернет развивается стремительными темпами — каждый день появляются сотни тысяч новых документов. Рост количества документов происходит быстрее, чем поисковые системы успевают их проиндексировать. Отсюда следует неутешительный вывод, что даже если в Сети и есть то, что вы ищете, вовсе не обязательно, что об этом знает поисковая машина, к которой вы обратились. Поисковых систем в мире сотни, и велика вероятность, что нужный вам документ не попал в ваш поисковик, но проиндексирован другой поисковой системой. Поэтому существуют службы, позволяющие транслировать ваш запрос сразу в несколько поисковых систем, — это метапоисковые системы. Однако пользоваться ими во всех случаях не следует. Если документов по теме много, то метапоиск не нужен и, возможно, даже вреден, поскольку смешивает разные логики ранжирования. Но если документов по теме мало, то метапоиск может быть полезен именно благодаря тому, что объединяет большое число поисковиков. Весьма удобной является отечественная программа ДИСКо Искатель, о которой стоит рассказать подробнее.
ДИСКо Искатель
ДИСКо Искатель (рис. 5) это метапоисковая система, инструмент для поиска информации на нескольких поисковых серверах одновременно. Главной особенностью этой программы является возможность запоминать как параметры поиска, так и его результаты и использовать их впоследствии.
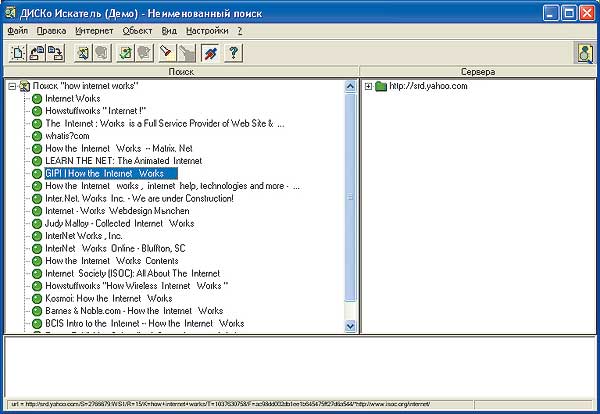
Рис. 5. Метапоисковая система ДИСКо Искатель
Двойным щелчком на любую ссылку вы можете вызвать свой Интернет-браузер для просмотра этой страницы. Выбрав любое подмножество страниц, можно потребовать создать HTML-страницы со ссылками на все эти страницы. ДИСКо Искатель запускает одновременно несколько соединений со всеми указанными поисковыми серверами, что существенно ускоряет время поиска. Оперативная информация о соединениях выводится в окно соединения. Вы можете сохранить параметры и результаты поиска в файле с расширением dio, чтобы в следующий раз снова запустить этот же поиск или внимательнее просмотреть его результаты.
Есть два способа экспорта подмножества страниц из дерева поиска: в закладки (избранное) Интернет-проводника и в HTML-страницу для последующего вызова ее из браузера.
Онлайновые энциклопедии и справочники
Очень часто нужно найти не документ, содержащий то или иное ключевое слово, а именно толкование искомого слова. Можно, конечно, поискать незнакомый вам термин с помощью поисковой машины, но в этом случае вы рискуете получить целый ряд статей, в которых этот термин используется, и при этом так и не узнать, что же он все-таки обозначает. В данном случае лучше обратиться к онлайновым энциклопедиям.
Будущее поисковых систем
Рис. 6. Поисковая система AskJeeves
Анализ социальных сетей разновидность структурного подхода, концентрирующего внимание на анализе возникающих в ходе социального взаимодействия связей (сетей), рассматриваемых в качестве структурных образований. Поведение личности или группы объясняется как производное от социальных сетей, элементами которых оно выступает. Метод получил широкое распространение при изучении процессов коммуникации в различных социальных группах. Всемирная паутина ярчайший пример социальной сети.
Булева модель, булевая, двоичная (boolean) — модель поиска, опирающаяся на операции пересечения, объединения и вычитания множеств.
Дубликаты (duplicates) разные документы с идентичным, с точки зрения пользователя, содержанием; приблизительные дубликаты, почти дубликаты (near duplicates), в отличие от точных дубликатов, содержат незначительные отличия.
Единица поиска текст, в пределах которого проверяется логическая комбинация.
Конкорданс словарь, в котором в алфавитном порядке перечислены слова, употребляемые писателем, а также указаны их адрес и частота употребления.
Индекс цитирования (citation index) число упоминаний (цитирований) научной статьи, в традиционной библиографии рассчитывается за промежуток времени, например за год.
Индексирование, индексация (indexing) процесс составления или приписывания индекса (указателя) служебной структуры данных, необходимой для последующего поиска.
Поиск похожих документов (similar document search) — задача информационного поиска, в которой в качестве запроса выступает сам документ и необходимо найти документы, максимально напоминающие данный.
Полнота, охват (recall) доля релевантного материала, заключенного в ответе поисковой системы, по отношению ко всему релевантному материалу в коллекции.
Релевантность (relevance, relevancy) соответствие документа запросу.
Словоизменение (inflection) образование определенной грамматической формы слова, обычно обязательной в определенном контексте.
Стоп-слова (stop-words) союзы, предлоги и другие частотные слова, которые поисковая система исключила из процесса индексирования и поиска для повышения своей производительности и/или точности поиска.
Точность (precision) доля релевантного материала в ответе поисковой системы.
Хиты количество заходов на сайт за определенный промежуток времени.
Хосты количество уникальных посетителей в единицу времени.

Конспект учеников по теме Информатики "".
Поиск информации. Поисковые системы
Код ОГЭ по информатике: 2.4.1. Компьютерные энциклопедии и справочники; информация в компьютерных сетях, некомпьютерных источниках информации. Компьютерные и некомпьютерные каталоги, поисковые машины, формулирование запросов
Поиск информации (информационный поиск) — это информационный процесс, цель которого — получение информации из информационного объекта или из хранилища информационных объектов. Поиск информации является разновидностью процесса обработки информации. Для ускорения информационного поиска создают и используют информационно-поисковые системы.
Информационно-поисковая система (ИПС) — система, выполняющая функции хранения больших объёмов информации, быстрого поиска требуемой информации и её вывода в удобном для человека виде.
Информационно-поисковые системы позволяют добавлять, удалять и изменять хранимую информацию. Существуют информационно-поисковые системы двух видов:
- документальные (в результате поиска выдаётся документ);
- справочные (в результате поиска информация предъявляется или сообщается).
Справочные ИПС, в свою очередь, делятся на:
- фактографические (в результате поиска предъявляется искомая информация, факт);
- адресные (в результате поиска предъявляется адрес, где информация хранится).
Документальные и фактографические ИПС. Документальными ИПС являются книжные фонды, открытые для доступа в читальных залах библиотек или в магазинах. Однотипные информационные объекты (книги) стоят на стеллажах чаще всего в порядке отраслей знаний (философия, математика, физика и т. п.). Читатель (покупатель), проходя вдоль стеллажей, ищет сначала названия отраслей знаний, а затем книги в разделах.
В словарях однотипные информационные объекты (слова и связанные с ними описания) расположены в алфавитном порядке, что существенно ускоряет поиск нужного слова или словосочетания. В энциклопедиях в аналогичном порядке расположены другие однотипные информационные объекты — статьи с описанием понятий. По такому же принципу организованы алфавитные книжки для записи телефонов и адресов, а также список учеников класса в классном журнале.
В другом порядке — хронологическом — организованы фактографические ИПС, которые называются расписаниями. Имеются в виду расписания занятий, расписания движения поездов, самолётов и т. п.
Адресные ИПС в документах. Адресные ИПС распространены гораздо шире документальных и фактографических. Каждый бумажный документ, исключая словари и энциклопедии, имеет собственную адресную ИПС в виде оглавления (содержания). В оглавлении записаны названия разделов документа и указаны их адреса — номера страниц, на которых эти названия находятся.
Поиск информации в документе состоит из трёх этапов:
- поиск в оглавлении подходящего названия раздела с адресом (номером страницы);
- поиск в документе страницы по адресу (номеру);
- поиск информации в разделе.
Адресные ИПС в хранилищах информационных объектов. В хранилищах бумажных документов (библиотеках, архивах) создаются адресные ИПС, которые называются каталогами.
Традиционные каталоги содержат бумажные карточки с описаниями документов и их адресов в хранилище (номер хранилища, номер стеллажа и т. д.). Адрес документа в хранилище называется шифром. Аналогичным образом организуется хранение и адресация звуко-, кино- и видеозаписей.
Поиск информации в хранилище информационных объектов состоит также из трёх этапов:
- поиск в каталоге карточки подходящего информационного объекта с адресом (шифром);
- поиск в хранилище информационного объекта по адресу (шифру);
- поиск информации в информационном объекте.
Оценка результатов поиска информации. Поиск информации в информационных объектах или в хранилищах информационных объектов редко бывает однократным. Результат поиска всегда оценивается с точки зрения полноты требуемой информации. Если информации недостаточно, поиск других источников информации проводят снова и снова, пока результат не станет удовлетворительным.
Поиск внутри компьютера
Для запуска процесса поиска в поле поиска вводят символы из имени файла или его содержимого. В области просмотра появляется список файлов и папок, которые отвечают запросу. В строке каждого файла указан реальный путь к нему.
Список с результатами поиска анализируется пользователем самостоятельно. Одно можно сказать точно: если файл на самом деле находится в компьютере, то его имя непременно окажется в списке результатов поиска.
Чтобы просмотреть файл в содержащей его папке, по строке файла щёлкают левой, потом правой клавишей мыши, а затем в контекстном меню щёлкают по пункту Расположение файла. В области просмотра открывается папка, содержащая файл.
Поиск в Интернете
Существует несколько сайтов, которые представляют в Интернете поисковые системы (поисковые машины), в том числе русскоязычные:
Поисковые системы представляют собой адресные информационно-поисковые системы. Они обычно включают два компонента:
- базу рефератов электронных документов, которые размещены на серверах Интернета, вместе с гиперссылками на эти документы;
- поисковый механизм, который позволяет автоматически по запросу найти информацию в этой базе данных (базе рефератов).
Процедура поиска информации. Для проведения автоматического поиска вводят текстовый запрос в поле поиска поисковой системы.

По умолчанию поисковые системы настроены на поиск в Интернете веб-страниц, которые содержат ключевые слова. Иногда требуется сузить область поиска, чтобы, например, найти новостную страницу или страницу-словарь, либо изменить объект поиска, чтобы, например, найти картинку, музыку, видео.

Для выбора объекта и области поиска поисковые системы в Интернете предлагают меню. После ввода данных щёлкают по кнопке Найти (или аналогичной). Через некоторое время окно браузера обновляется и в нём появляются результаты поиска в виде списка гиперссылок на документы. Этот список может содержать тысячи гиперссылок. По первой двадцатке списка всегда видно, точным ли был запрос. Иногда запрос следует уточнить и запустить поисковую систему ещё раз. В любом случае для получения ответа достаточно просмотреть первую сотню документов, обращаясь к ним с помощью гиперссылок из списка.
Поисковые каталоги. Многие поисковые системы на своих веб-страницах имеют поисковые каталоги, которые построены в виде меню, пунктами которого являются разделы каталога. Принцип построения поисковых каталогов аналогичен принципу построения дерева папок в компьютере. Выбор пункта каталога открывает новое меню, в котором также делают выбор. И так до тех пор, пока на экран не будет выведен список ссылок, входящих в конечный пункт каталога. В процессе поиска следует только правильно определяться с выбором пунктов каталога.
Сохранение информации из Интернета. Просмотр веб-страниц может сопровождаться сохранением информации с этих страниц.
Именно так в Интернете можно собрать информацию для подготовки реферата практически на любую тему.

Поисковые системы
Порядка 95% интересующей пользователя информации в интернете он находит в поисковых сервисах, Google, Yandex, Bing, Yahoo, DuckDuckGo и т.д (Смотрите — Рейтинг поисковых систем интернета). Но сам сайт, где вводится запрос — это лишь обертка, под которой скрывается сложный программно-аппаратный комплекс, анализирующий миллиарды сайтов ежедневно и составляющий на их основе базы данных. В статье я расскажу, как работают алгоритмы поисковых систем, как именно идет поиск и ранжирование нужной информации и почему мы так быстро получаем ответ на свои запросы.

Работа поисковых систем
Условно считается, что история создания поисковых систем берет свое начало с 1989 года. Именно тогда был создан сервис Арчи, главная задача которого была индексация информации, которую можно найти в интернете (в пространстве WWW). Система изобретена и создана программистом Аланом Эмтеджем. И алгоритмы, которые он в ней использовал, в базовом понимании используются и по сегодняшний день. Правда, данный сервис был локальным.
А уже в 1996 году была создана программа BackRub. Её главное преимущество — она выполняет глобальную индексацию. Уже в 1998 году система будет переименована в Google. А сейчас это — самый популярный сервис в мире для поиска информации в интернете (по данным аналитиков, его использует порядка 85% всех интернет-пользователей).
Общий принцип работы любой поисковой системы условно можно разделить на следующие этапы:
- Сбор информации. Специальная программа сканирует веб-пространство, открывает каждый доступный для неё сайт и анализирует его по заданным алгоритмам.
- Все документы закачиваются на сервер поисковой системы и создается база данных, которая содержит информацию о сайте.
- На основе полученных по сайту данных проводится построения индекса. То есть определяется, какие данные на нём содержатся, к какой группе запросов относятся данный контент их можно отнести и так далее.
- Программа определяет релевантность страницы, в момент когда она получает пользовательский поисковый запрос, на его основе предоставляет перечень сайтов, которые по результатам индексирования содержат запрашиваемую информацию.
- Сервис проводит ранжирование результатов выдачи. То есть выстраивает порядок ссылок, которые будут показаны пользователю, отправившему запрос.

Описанный принцип работы информационно поисковых систем — это лишь условное пояснение, как работает тот же Google или Яндекс. Но вот алгоритмы, которые они используют для обхода, сайтов, индексации и ранжирования, обычным пользователям неизвестны, каждая поисковая система применяет свои алгоритмы и постоянно их совершенствует, так как обработка информации занимает большое количество ресурсов сервера, расходы на который лежат на поисковой системе.
Понятно лишь одно — каждый сайт анализируется по более чем 1000 критериев. И именно благодаря этому пользователь, отправивший поисковый запрос, в 99% случаев в ответ получает ссылку, на страницу с полезной информацией.
Поисковые системы бывают нескольких подвидов и существуют и другие вариации таких сервисов:
- управляемые человеком (то есть каталог сайтов, каждый пункт которого и общая их база данных сформированы вручную пользователем, яркий пример каталог Rambler, );
- гибридные поисковые системы (где часть работы выполняет человек, часть — программа,принцип работы поисковой системы Google как раз таковой);
- мета-системы (которые не составляют базу данных, а дают результат сразу из нескольких поисковых сервисов пример Vivisimo).
И многие рядовые пользователи ошибочно полагают, что особенности работы поисковых систем таковы, что поиск оптимальных результатов для выдачи выполняется в режиме реального времени. Нет, выполнить анализ значительной части веб-пространства за несколько секунд — невозможно. Даже суперкомпьютерам для этого понадобится несколько месяцев, а то и лет. Поэтому без предварительной обработки информации, и постоянного ранжирования не обойтись.
Общие принципы обработки информации

Spider
Робот закачивающий веб страницы на сервер, он скачивает интернет-сайт, что в дальнейшем будет проиндексирован. Причем, загружает он все страницы и готовит полученные данные для анализа следующей программой. Если пользователя на загружаемом сайте интересует только контент (текст, картинки, мультимедиа), то spider работает именно с исходным кодом и html документами.
Crawler
Indexer
Программа которая проводит индексацию, всех полученных данных от Spider и Crawler. То есть делит загруженную страницу на составные части (по html-тегам) и формирует список данных, которые здесь представлены.
Database
Вторая база данных — это результаты индексации. Та самая информация, на основе которой определяется условный рейтинг сайта, а также составляется перечень поисковых запросов, в ответ на которые можно предоставить ссылку.
Search Engine Results Engine
Алгоритм, который выполняет окончательное ранжирование сайтов при получении конкретного поискового запроса. Именно этот алгоритм выбирает ссылки, которые будут показаны пользователю, а также определяет режим их сортировки с 1 места по 10 место , и так 100 места.
Web server
Сервер, на котором хранится сайт поискового сервиса. Именно его открывает пользователь, там же он вводит свой запрос и просматривает результаты выдачи.
Принципы работы поисковой системы

Сбор данных
После создания сайта и получения на него ссылки, система автоматически анализирует его с помощью инструментов Spyder и Crawling. Информация собирается и систематизируется из каждой страницы.
Индексация
Индексация выполняется с определенной периодичностью. И по её прохождению сайт добавляется в общий каталог поисковой системы. Результата этого процесса — создание файла индекса, который используется для быстрого нахождения запрашиваемой информации на ресурсе.
Обработка информации
Система получает пользовательский запрос, анализирует его. Определяются ключевые слова, которые в дальнейшем и используются для поиска по файлам индекса. Из базы данных извлекаются все документы, схожие на пользовательский запрос.
Ранжирование
Из всех документов, отобранных для выдачи, составляется список, где каждому сайту отведена своя позиция. Выполняется на основании ранее вычисленных показателей релевантности.
На этом этапе принцип работы поисковых систем немного разнится. Формула ранжирования — тоже уникальная. Но ключевые факторы, влияющие на релевантность сайта, следующие:
- индекс цитируемости (как часто сторонние ресурсы ссылаются на информацию из конкретной страницы);
- авторитетность домена (определяется на основании его истории изменения);
- релевантность текстовой информации по запросу;
- релевантность иных форматов контента, представленных на странице;
- качество оптимизации сайта.
СПРАВКА! Если вам необходимо заказать продвижение сайта в поисковых системах, я могу Вам помочь, сделать качественный SEO аудит сайта и составить план продвижения.
Основные характеристики поисковых систем
Главный параметр — это наглядность. То есть насколько точная информация представлена в выдаче на усмотрение самого пользователя, который и отправлял запрос. Но есть и другие характеристики для оценки поисковых систем.

Полнота
Условный параметр, который указывает соотношение от общего числа документов, дающих ответ на пользовательский запрос, от их количества, представленного системой в выдаче. Чем выше соотношение — тем более полный анализ производится сервисом.
Точность
Актуальность
Имеется ввиду время, прошедшее с момента публикации данных на сайте до его добавления в каталог индексации. Чем быстрее этот процесс будет завершен, тем более актуальную информацию пользователю представят в выдаче. Для современных сервисов, типа Bing или Google периодичность обновления базы данных индексации составляет до 3-х месяцев. Для релевантных сайтов — несколько дней.
Скорость поиска
Наглядность
Пользовательская оценка в работе сервиса. Во многом зависит от того, какие ссылки рядовой пользователь увидит в ТОП выдачи. Ведь именно их он изучает в первую очередь. И полученная на них информация должна на 100% ответить на его запросы.
Выводы
Постоянная индексация и ранжирование — это основной принцип работы поисковых интернет систем. А за написание алгоритмов и программ, которые выполняют большую часть всей этой работы, отвечают тысячи программистов. Именно благодаря их работе каждый пользователь за несколько секунд может отыскать в веб-пространстве необходимую для него прямо сейчас информацию.
Если Вам понравилась статья поделитесь ей в социальных сетях, так же рекомендую прочитать статью — методах продвижения сайта в интернете.
Если вы хотите более глубоко понимать принцип работы поисковых систем рекомендую посмотреть видео от Сергея Кокшарова и почитать его SEO блог
С каждым годом объемы Интернета увеличиваются в разы, поэтому вероятность найти необходимую информацию резко возрастает. Интернет объединяет миллионы компьютеров, множество разных сетей, число пользователей увеличивается на 15-80% ежегодно. И, тем не менее, все чаще при обращении к Интернет основной проблемой оказывается не отсутствие искомой информации, а возможность ее найти. Как правило, обычный человек в силу разных обстоятельств не может или не хочет тратить на поиск нужного ему ответа больше 15-20 минут. Поэтому особенно актуально правильно и грамотно научиться, казалось бы, простой вещи – где и как искать, чтобы получать ЖЕЛАЕМЫЕ ответы.
Чтобы найти нужную информацию, необходимо найти её адрес. Для этого существуют специализированные поисковые сервера (роботы индексов (поисковые системы), тематические Интернет-каталоги, системы мета-поиска, службы поиска людей и т.д.). В данном мастер-классе раскрываются основные технологии поиска информации в Интернете, предоставляются общие черты поисковых инструментов, рассматриваются структуры поисковых запросов для наиболее популярных русскоязычных и англоязычных поисковых систем.
2. Технологии поиска
2.1 Поисковые инструменты
Поисковые инструменты - это особое программное обеспечение, основная цель которого – обеспечить наиболее оптимальный и качественный поиск информации для пользователей Интернета. Поисковые инструменты размещаются на специальных веб-серверах, каждый из которых выполняет определенную функцию:
- Анализ веб-страниц и занесение результатов анализа на тот или иной уровень базы данных поискового сервера.
- Поиск информации по запросу пользователя.
- Обеспечение удобного интерфейса для поиска информации и просмотра результата поиска пользователем.
Приемы работы, используемые при работе с теми или другими поисковыми инструментами, практически одинаковы. Перед тем как перейти к их обсуждению, рассмотрим следующие понятия:
- Интерфейс поискового инструмента представлен в виде страницы с гиперссылками, строкой подачи запроса (строкой поиска) и инструментами активизации запроса.
- Индекс поисковой системы – это информационная база, содержащая результат анализа веб-страниц, составленная по определенным правилам.
- Запрос – это ключевое слово или фраза, которую вводит пользователь в строку поиска. Для формирования различных запросов используются специальные символы ("", , ~), математические символы (*, +, ?).
Схема поиска информации в сети Интернет проста. Пользователь набирает ключевую фразу и активизирует поиск, тем самым получает подборку документов по сформулированному (заданному) запросу. Этот список документов ранжируется по определенным критериям так, чтобы вверху списка оказались те документы, которые наиболее соответствуют запросу пользователя. Каждый из поисковых инструментов использует различные критерии ранжирования документов, как при анализе результатов поиска, так и при формировании индекса (наполнении индексной базы данных web-страниц).
Таким образом, если указать в строке поиска для каждого поискового инструмента одинаковой конструкции запрос, можно получить различные результаты поиска. Для пользователя имеет большое значение, какие документы окажутся в первых двух-трех десятках документов по результатам поиска и на сколько эти документы соответствуют ожиданиям пользователя.
Большинство поисковых инструментов предлагают два способа поиска – simple search (простой поиск) и advanced search (расширенный поиск) с использованием специальной формы запроса и без нее. Рассмотрим оба вида поиска на примере англоязычной поисковой машины.
Освоение критериев уточнения запроса и приемов расширенного поиска, позволяет увеличивать эффективность поиска и достаточно быстро найти необходимую информацию. Прежде всего, увеличить эффективность поиска Вы можете за счет использования в запросах логических операторов (операций) Or, And, Near, Not, математических и специальных символов. С помощью операторов и/или символов пользователь связывает ключевые слова в нужной последовательности, чтобы получить наиболее адекватный запросу результат поиска. Формы запросов приведены в таблице 1.
| Простой запрос |
| account |
| merchant account |
| internet merchant account |
| "merchant account" |
| "internet merchant account" |
| Расширенный запрос |
| internet merchant account and online payments |
| internet merchant near gov* |
| internet merchant near education |
| Расширенный запрос с использованием математических символов |
| +internet +merchant +account |
| internet ~merchant ~gov* |
| internet ~merchant ~governor |
| Internet ~merchant ~(governor account) |
Простой запрос дает некоторое количество ссылок на документы, т.к. в список попадают документы, содержащие одно из слов, введенных при запросе, или простое словосочетание (см. таблицу 1). Оператор and позволяет указать на то, что в содержании документа должны быть включены все ключевые слова. Тем не менее, количество документов может быть все еще велико, и их просмотр займет достаточно времени. Поэтому в ряде случаев гораздо удобнее применить контекстный оператор near, указывающий, что слова должны располагаться в документе в достаточной близости. Использование near значительно уменьшает количество найденных документов. Наличие символа "*" в строке запроса означает, что будет осуществляться поиск слова по его маске. Например, получим список документов, содержащих слова, начинающиеся на "gov", если в строке запроса запишем "gov*". Это могут быть слова government, governor и т.д.
Не менее популярная поисковая система Rambler ведет статистику посещаемости ссылок из собственной базы данных, поддерживаются те же логические операторы И, ИЛИ, НЕ, метасимвол * (аналогично расширяющему диапазон запроса символу * в AltaVista), коэффициентные символы + и -, для увеличения или уменьшения значимости вводимых в запрос слов.
Давайте рассмотрим наиболее популярные технологии поиска информации в Интернет.
2.2 Поисковые машины (search engines)
Машины веб-поиска - это сервера с огромной базой данных URL-адресов, которые автоматически обращаются к страницам WWW по всем этим адресам, изучают содержимое этих страниц, формируют и прописывают ключевые слова со страниц в свою базу данных (индексирует страницы).
Более того, роботы поисковых систем переходят по встречаемым на страницах ссылкам и переиндексируют их. Так как почти любая страница WWW имеет множество ссылок на другие страницы, то при подобной работе поисковая машина в конечном результате теоретически может обойти все сайты в Интернет.
Именно этот вид поисковых инструментов является наиболее известным и популярным среди всех пользователей сети Интернет. У каждого на слуху названия известных машин веб-поиска (поисковых систем) – Яndex, Rambler, Aport.
Чтобы воспользоваться данным видом поискового инструмента, необходимо зайти на него и набрать в строке поиска интересующее Вас ключевое слово. Далее Вы получите выдачу из ссылок, хранящихся в базе поисковой системы, которые наиболее близки Вашему запросу. Чтобы поиск был наиболее эффективен, заранее обратите внимание на следующие моменты:
- определитесь с темой запроса. Что именно в конечном итоге Вы хотите найти?
- обращайте внимание на язык, грамматику, использование различных небуквенных символов, морфологию.Важно также правильно сформулировать и вписать ключевые слова. Каждая поисковая система имеет свою форму составления запроса — принцип один, но могут различаться используемые символы или операторы. Требуемые формы запроса различаются также в зависимости от сложности программного обеспечения поисковых систем и предоставляемых ими услуг. Так или иначе, каждая поисковая система имеет раздел "Help" ("Помощь"), где все синтаксические правила, а также рекомендации и советы по поиску, доступно объясняются (скриншот страничек поисковиков).
- используйте возможности разных поисковых систем. Если не нашли на Яndex, попробуйте на Google. Пользуйтесь услугами расширенного поиска.
- чтобы исключить документы, содержащие определенные термины, используйте знак "-" перед каждым таким словом. Например, если Вам нужна информация о работах Шекспира, за исключением "Гамлета", то введите запрос в виде: "Шекспир-Гамлет". И для того, чтобы, наоборот, в результаты поиска обязательно включались определенные ссылки, используйте символ "+". Так, чтобы найти ссылки о продаже именно автомобилей, Вам нужен запрос "продажа+автомобиль". Для увеличения эффективности и точности поиска, используйте комбинации этих символов.
- каждая ссылка в списке результатов поиска содержит сниппет – несколько строчек из найденного документа, среди которых встречаются Ваши ключевые слова. Прежде чем переходить по ссылке, оцените соответсвие сниппета теме запроса. Перейдя по ссылке на определенный сайт, внимательно окиньте взглядом главную страничку. Как правило, первой страницы достаточно, чтобы понять – по адресу Вы пришли или нет. Если да, то дальнейшие поиски нужной информации ведите на выбранном сайте (в разделах сайта), если нет – возвращайтесь к результатам поиска и пробуйте очередную ссылку.
- помните, что поисковые системы не производят самостоятельную информацию (за исключением разъяснений о самих себе). Поисковая система – это лишь посредник между обладателем информации (сайтом) и Вами. Базы данных постоянно обновляются, в них вносятся новые адреса, но отставание от реально существующей в мире информации все равно остается. Просто потому, что поисковые системы не работают со скоростью света.
К наиболее известным машинам веб-поиска относятся Google, Yahoo, Alta Vista, Excite, Hot Bot, Lycos. Среди русскоязычных можно выделить Яndex, Rambler, Апорт.
Поисковые системы являются самыми масштабными и ценными, но далеко не единственными источниками информации в Сети, ведь помимо них существуют и другие способы поиска в Интернете.
2.3 Каталоги (directories)
На главной странице данного сайта расположен тематический рубрикатор,
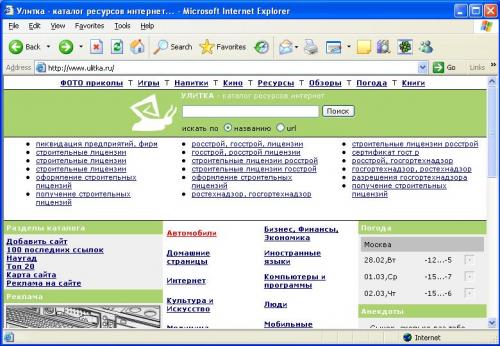
с помощью которого пользователь попадает в рубрику со ссылками на интересующую его продукцию.

Кроме того, некоторые тематические каталоги позволяют искать по ключевым словам. Пользователь вводит необходимое ключевое слово в строку поиска
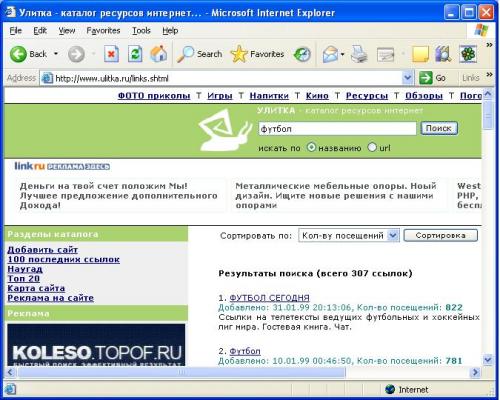
и получает список ссылок с описаниями сайтов, которые наиболее полно соответствуют его запросу. Стоит отметить, что этот поиск происходит не в содержимом WWW-серверов, а в их кратком описании, хранящихся в каталоге.
В нашем примере в каталоге также имеется возможность сортировки сайтов по количеству посещений, по алфавиту, по дате занесения.
2.4 Подборки ссылок
Подборки ссылок – это отсортированные по темам ссылки. Они достаточно сильно отличаются друг от друга по наполнению, поэтому чтобы найти подборку, наиболее полно отвечающую Вашим интересам, необходимо ходить по ним самостоятельно, дабы составить собственное мнение.
В качестве примера приведем Подборку ссылок "Сокровища Интернет" АО "Релком"

Пользователь, нажимая на любую из заинтересовавших его рубрик
- Астрономия и астрология
- Ваш дом
- Ваши питомцы
- Дети - цветы жизни
- Досуг
- Города в Сети Internet
- Здоровье и медицина
- Информационные агентства и службы
- Краеведческий музей и т.д.,
попадает на подборку со ссылками на полезные Интернет-ресурсы
Автомобилистам
- Автомобильная электроника.
- Музей автомото старины.
- Коллегия Правовой Защиты Автовладельцев.
- Sportdrive.
Преимуществом такого вида поисковых инструментов является их целенаправленность, обычно подборка включает в себя редкие интернет ресурсы, подобранные конкретным веб-мастером или хозяином интернет странички.
2.5 Базы данных адресов ( addresses database)
Базы данных адресов – это специальные поисковые сервера, которые обычно используют классификации по роду деятельности, по выпускаемой продукции и оказываемым услугам, по географическому признаку. Иногда они дополнены поиском по алфавиту. В записях базы данных хранится информация о сайтах, которые предоставляют информацию об электронном адресе, организации и почтовом адресе за определенную плату.

представляет собой рубрикатор со множеством поддиректорий, таких как: Find Person, Phone Numbers, Name Search и другие.
Попадая в данные поддиректории, пользователь обнаруживает ссылки на сайты, которые и предлагают интересующую его информацию.

2.6 Поиск в архивах Gopher (Gopher archives)
Gopher – это взаимосвязанная система серверов (Gopher-пространство), распределенная по Интернет.
В пространстве Gopher собрана богатейшая литературная библиотека, однако материалы недоступны для просмотра в удаленном режиме: пользователь может только просматривать иерархически организованное оглавление и выбирать файл по названию. С помощью специальной программы (Veronica) такой поиск можно сделать и автоматически, используя запросы, построенные на ключевых словах.
До 1995 года Gopher являлся самой динамичной технологией Интернет: темпы роста числа соответствующих серверов опережали темпы роста серверов всех других типов Интернет. В сети EUnet/Relcom активного развития серверы Gopher не получили, и сегодня о них практически никто не вспоминает.
2.7 Система поиска FTP файлов (FTP Search)
Основным критерием поиска является название файла, задаваемое разными способами (точное соответствие, подстрока, регулярное выражение и т.д.). Данный тип поиска, конечно же, не может соперничать по возможностям с поисковыми машинами, так как содержимое файлов никак не учитывается при поиске, а файлам, как известно, можно давать произвольные имена. Тем не менее, если Вам требуется найти какую-нибудь известную программу или описание стандарта, то с большой долей вероятности файл, его содержащий, будет иметь соответствующее имя, и Вы сможете найти его при помощи одного из серверов FTP Search :
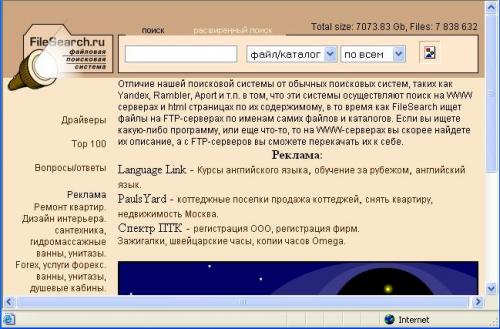
FileSearch ищет файлы на FTP-серверах по именам самих файлов и каталогов. Если Вы ищете какую-либо программу или еще что-то, то на WWW-серверах Вы скорее найдете их описание, а с FTP-серверов Вы сможете перекачать их к себе.
2.8 Система поиска в конференциях Usenet News
USENET NEWS – это система телеконференций сообщества сетей Интернет. На Западе этот сервис принято называть новостями. Близким аналогом телеконференций являются и так называемые "эхи" в сети FIDO.
С точки зрения абонента телеконференции, USENET представляют из себя доску объявлений, в которой есть разделы, где можно найти статьи на любую тему - от политики до садоводства. Эта доска объявлений доступна через компьютер, подобно электронной почте. Не отходя от компьютера, можно читать или помещать статьи в ту или иную конференцию, найти полезный совет или вступать в дискуссии. Естественно, статьи занимают место на компьютерах, поэтому не хранятся вечно, а периодически уничтожаются, освобождая место для новых. Во всем мире лучшим сервисом для поиска информации в конференциях Usenet является сервер Google Groups (Google Inc.).
2.9 Системы мета-поиска
Для быстрого поиска в базах сразу нескольких поисковых систем лучше обратиться к системам мета-поиска.
Системы мета-поиска – это поисковые машины, которые посылают Ваш запрос на огромное количество разных поисковых систем, затем обрабатывают полученные результаты, удаляют повторяющиеся адреса ресурсов и представляют более широкий спектр того, что представлено в сети Интернет.

С помощью данного вида поисковых инструментов пользователь может искать информацию во множестве поисковых систем, однако отрицательной стороной данных систем можно назвать их нестабильность.
2.10 Системы поиска людей
Системы поиска людей – это специальные сервера, которые позволяют осуществлять поиск людей в Интернет, пользователь может указать Ф.И.О. человека и получить его адрес электронной почты и URL-адрес. Однако, следует отметить, что системы поиска людей, в основном, берут информацию об электронных адресах из открытых источников, таких как конференции Usenet. Среди самых известных систем поиска людей можно выделить:
WhoWhere? - поиск адресов e-mail
в специальные графы поиска контактные данные (First Name. City, Last Name, Phone number), Вы можете найти интересующую Вас информацию.

Системы поиска людей - это действительно большие сервера, их базы данных содержат порядка 6 000 000 адресов.
3. Заключение
Мы рассмотрели основные технологии поиска информации в Интернет и представили в общих чертах поисковые инструменты, которые существуют на данный момент в Интернете, а также структуру поисковых запросов для наиболее популярных русскоязычных и англоязычных поисковых систем и, подводя итог вышесказанному, хотим отметить, что единой оптимальной схемы поиска информации в Интернет не существует. В зависимости от специфики нужной Вам информации, Вы можете использовать соответствующие поисковые инструменты и службы. А от того, как грамотно будут подобраны поисковые службы, зависит качество результатов поиска.
Читайте также: