
Конвейерная архитектура процессора кратко
Обновлено: 05.07.2024
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода.
При параллелизме совмещение операций достигается путем воспроизведения аппаратной обрабатывающей структуры в нескольких копиях. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Для иллюстрации основных принципов построения конвейризованных процессоров будем считать, что набор команд процессора включает типичные арифметические и логические операции, операции с плавающей точкой, операции пересылки данных, операции управления потоком команд и системные операции. В арифметических командах используется трехадресный формат, типичный для RISC-процессоров; команды обработки используют регистровую адресацию, а для обращения к памяти используются операции загрузки и записи содержимого регистров в память.
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды - IF (по адресу, заданному счетчиком команд РС, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров - ID;
- выполнение операции / вычисление исполнительного адреса памяти - EX;
- обращение к памяти - MEM;
- запоминание результата - WB.
Для организации конвейра мы можем разбить выполнение команд на указанные этапы, отведя для выполнения каждого этапа один такт синхронизации, и начинать в каждом такте выполнение новой команды. Естественно, для хранения промежуточных результатов каждого этапа необходимо использовать буферные регистровые станции. Хотя общее время выполнения одной команды в таком конвейере будет составлять пять тактов, в каждом такте аппаратура будет выполнять в совмещенном режиме пять различных команд.
Работу конвейера можно условно представить в виде временной диаграммы (рис.1), на которой изображены выполняемые команды, номера тактов и этапы выполнения команд.
| Номер команды | Номер такта | ||||
| Команда i | IF | ID | EX | MEM | WB |
| Команда i+1 | IF | ID | EX | MEM | WB |
| Команда i+2 | IF | ID | EX | MEM | WB |
| Команда i+3 | IF | ID | EX | MEM | WB |
| Команда i+4 | IF | ID | EX | MEM | WB |
Рис. 1. Диаграмма работы простейшего конвейера.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением буферными регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
В качестве примера рассмотрим неконвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно (рис.2). Тогда среднее время выполнения команды в неконвейерной машине будет равно 260 нс. Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. При конвейерной организации длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере.
Конвейеризация эффективна тогда, когда загрузка конвейера близка к полной, скорость подачи новых команд и операндов соответствует максимальной производительности конвейера, а времена обработки на всех этапах конвейра одинаковы.
Рис. 2. Эффект конвейеризации при выполнении команд: а) неконвейризованное исполнение, б) конвейризованное исполнение.
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Существуют три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения. Например, машина может иметь только один порт записи в регистровый файл, но при определенных обстоятельствах конвейеру может потребоваться выполнить две записи в регистровый файл в одном такте. Когда последовательность команд наталкивается на такой конфликт, конвейер приостанавливает выполнение одной из команд до тех пор, пока не станет доступным требуемое устройство. Структурные конфликты возникают, например, и в машинах, в которых имеется единственный конвейер памяти для команд и данных. В этом случае, когда одна команда содержит обращение к памяти за данными, оно будет конфликтовать с выборкой более поздней команды из памяти.
2. Конфликты по данным возникающие в том случае, когда применение конвейерной обработки может изменить порядок обращений за операндами так, что этот порядок будет отличаться от порядка, который наблюдается при последовательном выполнении команд на неконвейерной машине.
ADD R1,R2,R3 - сложить R2 и R3, результат записать в R1
SUB R4,R1,R5 - из R1 вычесть R5, результат записать в R4
Команда ADD записывает результат в регистр R1, а команда SUB читает это значение. Если не предпринять никаких мер для того, чтобы предотвратить этот конфликт, команда SUB прочитает неправильное значение и попытается его использовать.
Конфликты по данным могут быть устранены на этапе генерации кода компилятором. Многие современные компиляторы используют технику планирования команд для улучшения производительности конвейера.
Например, для оператора А = B + С компилятор скорее всего сгенерирует следующую последовательность команд
| Номер команды | Номер такта | |||||
| LW R1,В | IF | ID | EX | MEM | WB | |
| LW R2,С | IF | ID | EX | MEM | WB | |
| ADD R3,R1,R2 | IF | ID | Stall | EX | MEM | WB |
| SW A,R3 | IF | Stall | ID | EX | MEM | WB |
Рис. 2. Конвейерное выполнение оператора А = В + С
Очевидно, выполнение команды ADD должно быть приостановлено до тех пор, пока не станет доступным поступающий из памяти операнд C.
Для данного простого примера компилятор никак не может улучшить ситуацию, однако в ряде более общих случаев он может реорганизовать последовательность команд так, чтобы избежать приостановок конвейера. Эта техника, называемая планированием загрузки конвейера (pipeline scheduling) или планированием потока команд (instruction scheduling), использовалась начиная с 60-х годов и стала особой областью интереса в 80-х годах, когда конвейерные машины стали более распространенными.
Пусть, например, имеется последовательность операторов: a = b + c; d = e - f;
Если код не оптимизирован, при выполнении каждого из этих операторов возникнет по одному такту приостановки. Но существует вариант переупорядочения команд, когда приостановки конвейера не произойдет.
В общем случае планирование загрузки конвейера компилятором может требовать увеличенного количества регистров.
Кроме того, существуют и аппаратные методы, позволяющие изменить порядок выполнения команд программы так, чтобы минимизировать приостановки конвейера.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Основные этапы развития астрономии. Гипотеза Лапласа: С точки зрения гипотезы Лапласа, это совершенно непонятно.
Конвейерная архитектура ( pipelining ) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
· получение и декодирование инструкции ( Fetch )
· адресация и выборка операнда из ОЗУ ( Memory access )
· выполнение арифметических операций ( Arithmetic Operation )
· сохранение результата операции ( Store )
После освобождения k -й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в n ступеней займёт n единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
Действительно, при отсутствии конвейера выполнение команды займёт n единиц времени (так как для выполнения команды по прежнему необходимо выполнять выборку, дешифрацию и т. д.), и для исполнения m команд понадобится n ∙ m единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения m команд понадобится всего лишь n + m единиц времени.
Факторы, снижающие эффективность конвейера:
· простой конвейера, когда некоторые ступени не используются (напр., адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами);
· ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд, out-of-order execution );
· очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода).
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через МП, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах. Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
· SISD — один поток команд, один поток данных;
· SIMD — один поток команд, много потоков данных;
· MISD — много потоков команд, один поток данных;
· MIMD — много потоков команд, много потоков данных.
Конвейерная архитектура (Pipelining) была введена в ЦП с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифровка команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер МП с архитектурой IA-32 содержит 6 модулей, корые выполняют стадии обработки:
· Модуль шинного интерфейса , ввод/вывод данных.
· Модуль предварительной выборки, считывание инструкции и помещение ее в очередь.
· Модуль декодирования, выборка инструкции из очереди и ее декодирование.
· Модуль выполнения, исполняет последовательность инструкций, полученных от модуля декодирования. операций,
· Модуль сегментации, преобразует логические адреса в линейные адреса и выполняет проверки, связанные с защитой памяти.
· Модуль страничной организации преобразует линейные адреса в физические адреса памяти, выполняет проверки адресов, связанные с защитой страниц памяти, а также ведет список страниц, к которым недавно осуществлялся
Предположим, что каждый этап выполнения команды в процессоре длится ровно 1 машинный такт. На рисунке показана матрица шестиступенчатого выполнения команд в процессоре, не поддерживающем режим конвейерной обработки. Подобный режим выполнения команд был реализован в процессорах фирмы Intel до появления на свет модели Intel486.
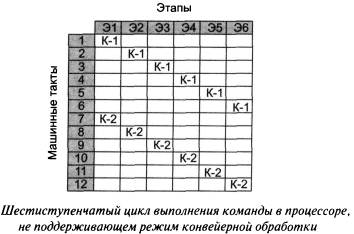
Как только завершается этап Э6 выполнения команды К-1, начинается выполнение этапа Э1 команды К-2. При этом для выполнения двух команд К-1 и К-2 требуется 12 машинных тактов. Другими словами, если цикл выполнения команды состоит из к этапов, то для выполнения последовательности из n команд потребуется n x к машинных тактов. Очевидно, что подобный ЦП работает крайне неэффективно, поскольку за 1 машинный такт выполняется только одна шестая часть команды.
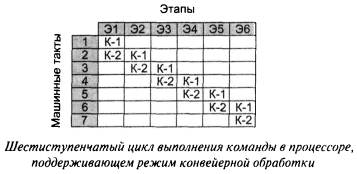
В то же время, если в процессоре поддерживается режим конвейерной обработки, то уже на втором машинном такте процессор может приступить к этапу Э1 выполнения новой команды. При этом предыдущая команда будет находиться на этапе Э2 своего выполнения. Таким образом, конвейерная обработка позволяет совместить выполнение двух машинных команд во времени. Как только процессор переходит к этапу Э2 выполнения команды K1, начинается выполнение этапа Э1 команды К-2. Вследствие этогодля выполнения 2 машинных команд требуется уже не 12, а всего лишь 7 машинных тактов. При полной загрузке конвейера, в текуший момент времени работают все 6 его ступеней.
Факторы, снижающие эффективность конвейера:
· Простой конвейера, когда некоторые ступени не используются (например, адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами).
· Ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд — out-of-order execution).
· Очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода). Не существует единого мнения по поводу оптимальной длины конвейера: различные программы могут иметь существенно различные требования.

Процессор с одним конвейером называется скалярным.
Параллельная архитектура
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через МП, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах. Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
· SISD — один поток команд, один поток данных;
· SIMD — один поток команд, много потоков данных;
· MISD — много потоков команд, один поток данных;
· MIMD — много потоков команд, много потоков данных.
Конвейерная архитектура (Pipelining) была введена в ЦП с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифровка команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер МП с архитектурой IA-32 содержит 6 модулей, корые выполняют стадии обработки:
· Модуль шинного интерфейса , ввод/вывод данных.
· Модуль предварительной выборки, считывание инструкции и помещение ее в очередь.
· Модуль декодирования, выборка инструкции из очереди и ее декодирование.
· Модуль выполнения, исполняет последовательность инструкций, полученных от модуля декодирования. операций,
· Модуль сегментации, преобразует логические адреса в линейные адреса и выполняет проверки, связанные с защитой памяти.
· Модуль страничной организации преобразует линейные адреса в физические адреса памяти, выполняет проверки адресов, связанные с защитой страниц памяти, а также ведет список страниц, к которым недавно осуществлялся
Предположим, что каждый этап выполнения команды в процессоре длится ровно 1 машинный такт. На рисунке показана матрица шестиступенчатого выполнения команд в процессоре, не поддерживающем режим конвейерной обработки. Подобный режим выполнения команд был реализован в процессорах фирмы Intel до появления на свет модели Intel486.
Как только завершается этап Э6 выполнения команды К-1, начинается выполнение этапа Э1 команды К-2. При этом для выполнения двух команд К-1 и К-2 требуется 12 машинных тактов. Другими словами, если цикл выполнения команды состоит из к этапов, то для выполнения последовательности из n команд потребуется n x к машинных тактов. Очевидно, что подобный ЦП работает крайне неэффективно, поскольку за 1 машинный такт выполняется только одна шестая часть команды.
В то же время, если в процессоре поддерживается режим конвейерной обработки, то уже на втором машинном такте процессор может приступить к этапу Э1 выполнения новой команды. При этом предыдущая команда будет находиться на этапе Э2 своего выполнения. Таким образом, конвейерная обработка позволяет совместить выполнение двух машинных команд во времени. Как только процессор переходит к этапу Э2 выполнения команды K1, начинается выполнение этапа Э1 команды К-2. Вследствие этогодля выполнения 2 машинных команд требуется уже не 12, а всего лишь 7 машинных тактов. При полной загрузке конвейера, в текуший момент времени работают все 6 его ступеней.
Факторы, снижающие эффективность конвейера:
· Простой конвейера, когда некоторые ступени не используются (например, адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами).
· Ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд — out-of-order execution).
· Очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода). Не существует единого мнения по поводу оптимальной длины конвейера: различные программы могут иметь существенно различные требования.
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода.
При параллелизме совмещение операций достигается путем воспроизведения аппаратной обрабатывающей структуры в нескольких копиях. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Для иллюстрации основных принципов построения конвейризованных процессоров будем считать, что набор команд процессора включает типичные арифметические и логические операции, операции с плавающей точкой, операции пересылки данных, операции управления потоком команд и системные операции. В арифметических командах используется трехадресный формат, типичный для RISC-процессоров; команды обработки используют регистровую адресацию, а для обращения к памяти используются операции загрузки и записи содержимого регистров в память.
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды - IF (по адресу, заданному счетчиком команд РС, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров - ID;
- выполнение операции / вычисление исполнительного адреса памяти - EX;
- обращение к памяти - MEM;
- запоминание результата - WB.
Для организации конвейра мы можем разбить выполнение команд на указанные этапы, отведя для выполнения каждого этапа один такт синхронизации, и начинать в каждом такте выполнение новой команды. Естественно, для хранения промежуточных результатов каждого этапа необходимо использовать буферные регистровые станции. Хотя общее время выполнения одной команды в таком конвейере будет составлять пять тактов, в каждом такте аппаратура будет выполнять в совмещенном режиме пять различных команд.
Работу конвейера можно условно представить в виде временной диаграммы (рис.1), на которой изображены выполняемые команды, номера тактов и этапы выполнения команд.
| Номер команды | Номер такта | ||||
| Команда i | IF | ID | EX | MEM | WB |
| Команда i+1 | IF | ID | EX | MEM | WB |
| Команда i+2 | IF | ID | EX | MEM | WB |
| Команда i+3 | IF | ID | EX | MEM | WB |
| Команда i+4 | IF | ID | EX | MEM | WB |
Рис. 1. Диаграмма работы простейшего конвейера.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности, она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением буферными регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
В качестве примера рассмотрим неконвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно (рис.2). Тогда среднее время выполнения команды в неконвейерной машине будет равно 260 нс. Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. При конвейерной организации длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере.
Конвейеризация эффективна тогда, когда загрузка конвейера близка к полной, скорость подачи новых команд и операндов соответствует максимальной производительности конвейера, а времена обработки на всех этапах конвейра одинаковы.
Рис. 2. Эффект конвейеризации при выполнении команд: а) неконвейризованное исполнение, б) конвейризованное исполнение.
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Конфликты в конвейере приводят к необходимости приостановки выполнения команд (pipeline stall). Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Существуют три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения. Например, машина может иметь только один порт записи в регистровый файл, но при определенных обстоятельствах конвейеру может потребоваться выполнить две записи в регистровый файл в одном такте. Когда последовательность команд наталкивается на такой конфликт, конвейер приостанавливает выполнение одной из команд до тех пор, пока не станет доступным требуемое устройство. Структурные конфликты возникают, например, и в машинах, в которых имеется единственный конвейер памяти для команд и данных. В этом случае, когда одна команда содержит обращение к памяти за данными, оно будет конфликтовать с выборкой более поздней команды из памяти.
2. Конфликты по данным возникающие в том случае, когда применение конвейерной обработки может изменить порядок обращений за операндами так, что этот порядок будет отличаться от порядка, который наблюдается при последовательном выполнении команд на неконвейерной машине.
ADD R1,R2,R3 - сложить R2 и R3, результат записать в R1
SUB R4,R1,R5 - из R1 вычесть R5, результат записать в R4
Команда ADD записывает результат в регистр R1, а команда SUB читает это значение. Если не предпринять никаких мер для того, чтобы предотвратить этот конфликт, команда SUB прочитает неправильное значение и попытается его использовать.
Конфликты по данным могут быть устранены на этапе генерации кода компилятором. Многие современные компиляторы используют технику планирования команд для улучшения производительности конвейера.
Например, для оператора А = B + С компилятор скорее всего сгенерирует следующую последовательность команд
| Номер команды | Номер такта | |||||
| LW R1,В | IF | ID | EX | MEM | WB | |
| LW R2,С | IF | ID | EX | MEM | WB | |
| ADD R3,R1,R2 | IF | ID | Stall | EX | MEM | WB |
| SW A,R3 | IF | Stall | ID | EX | MEM | WB |
Рис. 2. Конвейерное выполнение оператора А = В + С
Очевидно, выполнение команды ADD должно быть приостановлено до тех пор, пока не станет доступным поступающий из памяти операнд C.
Для данного простого примера компилятор никак не может улучшить ситуацию, однако в ряде более общих случаев он может реорганизовать последовательность команд так, чтобы избежать приостановок конвейера. Эта техника, называемая планированием загрузки конвейера (pipeline scheduling) или планированием потока команд (instruction scheduling), использовалась начиная с 60-х годов и стала особой областью интереса в 80-х годах, когда конвейерные машины стали более распространенными.
Пусть, например, имеется последовательность операторов: a = b + c; d = e - f;
Если код не оптимизирован, при выполнении каждого из этих операторов возникнет по одному такту приостановки. Но существует вариант переупорядочения команд, когда приостановки конвейера не произойдет.
В общем случае планирование загрузки конвейера компилятором может требовать увеличенного количества регистров.
Кроме того, существуют и аппаратные методы, позволяющие изменить порядок выполнения команд программы так, чтобы минимизировать приостановки конвейера.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Читайте также: