
Код это в информатике кратко
Обновлено: 04.07.2024
Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернете, создавать и обрабатывать графические изображения и и.д
Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года.
Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила - законы записи этих кодов, т.е. уметь кодировать.
Код - набор условных обозначений для представления информации.
Кодирование - процесс представления информации в виде кода.
Для общения друг с другом мы используем код - русский язык. При разговоре этот код передается звуками, при письме - буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Способ кодирования (форма представления) информации зависит от цели, ради которой осуществляется кодирование. Такими целями могут быть сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. п.
Чаще всего применяют следующие способы кодирования информации:
1) графический - с помощью рисунков или значков;
2) числовой - с помощью чисел:
3) символьный с помощью символов того же алфавита, что и исходный текст.
Переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки, также называют кодированием .
Действия по восстановлению первоначальной формы представления информации принято называть декодированием . Для декодирования надо знать код.
Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute). В системе ASCII закреплены две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы. В настоящее время существует много различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Mac, ISO),поэтому тексты, созданные в одной кодировке , могут не правильно отображаться в другой.
Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей). Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”. Тогда для его кодирования достаточно 1 бита:
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов:
00 – черный 10 – зеленый
01 – красный 11 – коричневый
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Из трех цветов можно получить восемь комбинаций:
1 1 0 Коричневый
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
Содержание
Кодирование
Кодовые деревья
Для наглядного описания кодов используются кодовые деревья. Если число узлов на каждом его уровне содержит узлов, где l — номер уровня (корень дерева находится на нулевом уровне), оно называется полным. Очевидно, величина >" width="" height="" />
, называемая объёмом дерева, характеризует максимальное число кодовых комбинаций, которое можно построить при помощи данного дерева.
В теории построения трансляторов, такое дерево описывает множество всех возможных цепочек-выводов из формальной грамматики.
Префиксный код
Префиксным называется код, не имеющий ни одного кодового слова, которое было бы префиксом (началом) любого другого кодового слова данного кода. Любой префиксный код является разделимым (то есть любую последовательность кодовых слов всегда можно однозначно разделить на отдельные из них). [1] Примерами префиксных кодов являются коды Шеннона, Шеннона-Фано и Хаффмана.
Примеры
Равномерное кодирование: для алфавита с m1 символами используются кодовые слова с длиной m_1)" width="" height="" />
, где up — округление до большего целого. В этом случае неиспользованными остаются m_1-n" width="" height="" />
кодовых слов, а остальным проставляются в соответствие символы первичного алфавита. Код Бодо имеет фиксированную длину 5 символов.
Префиксные коды: Код Шеннона-Фано — первый алгоритм неравномерного кодирования. Код Хаффмана — известный метод построения оптимального неравномерного кода (ОНК) с использованием деревьев. Арифметическое кодирование — обобщение кода Хаффмана.
Литература
- Цымбал В. П. Теория информации и кодирование. — Киев: Выща Школа, 1977. — 288 с.
См. также
Примечания
- ↑Габидулин, Э. М., Пилипчук, Н. И. 3.3. Префиксный код. // Лекции по теории информации. — М .: МФТИ, 2007. — С. 43—49. — 214 с. — ISBN 5-7417-0197-3
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое "Код" в других словарях:
код — код, а … Русский орфографический словарь
код — код/ … Морфемно-орфографический словарь
код — сущ., м., употр. сравн. часто Морфология: (нет) чего? кода, чему? коду, (вижу) что? код, чем? кодом, о чём? о коде; мн. что? коды, (нет) чего? кодов, чему? кодам, (вижу) что? коды, чем? кодами, о чём? о кодах 1. Код это система сигналов или… … Толковый словарь Дмитриева
КОД — коллоидно онкотическое давление КОД коллоидно осмотическое давление Словарь: С. Фадеев. Словарь сокращений современного русского языка. С. Пб.: Политехника, 1997. 527 с. КОД колодец оперативного доступа связь КОД … Словарь сокращений и аббревиатур
код — а; м. [франц. code] Система условных обозначений или сигналов для передачи (по каналу связи), обработки и хранения различной информации. Цифровой код. Телеграфный код. Знать код. Передать по коду важную информацию. Генетический код. (свойственная … Энциклопедический словарь
код — (фр. code) 1) система условных сокращенных обозначений и названий, применяемых для передачи, обработки, хранения различной информации (напр., дипломатического, коммерческого, военного или иного характера); шифр; 2) система символов, применяемая… … Словарь иностранных слов русского языка
Код — система условных знаков, символов, сокращенных обозначений и названий, применяемых для передачи, обработки, хранения информации. В информатике код определяет способ описания информации в символьной форме, воспринимаемой устройствами и программным … Финансовый словарь
код IK — [IEC 62262, ed. 1.0 (2002 02)] IK код Международная числовая классификация степеней защиты, обеспечиваемых корпусами электрооборудования от внешних механических воздействий. Он определяет устойчивость оболочек (корпусов) электрооборудования к… … Справочник технического переводчика
КОД — КОД, кода, муж. (франц. code) (спец.). Список условных сокращений, напр. для переписки по телеграфу, для сигнализации. Телеграфный код. Сигнальный код. Коммерческий код. Толковый словарь Ушакова. Д.Н. Ушаков. 1935 1940 … Толковый словарь Ушакова
код — адрес, шифр Словарь русских синонимов. код см. шифр Словарь синонимов русского языка. Практический справочник. М.: Русский язык. З. Е. Александрова. 2011 … Словарь синонимов
Код ОГЭ: 1.2.2 Кодирование и декодирование информации.
Кодирование информации
■ Кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
В процессах восприятия, передачи и хранения информации живыми организмами, человеком и техническими устройствами происходит кодирование информации. В этом случае информация, представленная в одной знаковой системе, преобразуется в другую. Каждый символ исходного алфавита представляется конечной последовательностью символов кодового алфавита. Эта результирующая последовательность называется информационным кодом (кодовым словом, или просто кодом).
Примерами кодов являются последовательность букв в тексте, цифр в числе, двоичный компьютерный код и др.
Преобразование знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы называется перекодированием.
Кодирование может быть равномерным и неравномерным. При равномерном кодировании все символы заменяются кодами равной длины; при неравномерном кодировании разные символы могут кодироваться кодами разной длины (это затрудняет декодирование). Неравномерный код называют еще кодом переменной длины.
Вначале код Морзе был создан для букв английского алфавита, цифр и знаков препинания. Принцип этого кода заключался в том, что часто встречающиеся буквы кодировались более простыми сочетаниями точек и тире. Это делало код компактным. Позже код был разработан и для символов других алфавитов, включая русский.
Коды Морзе для некоторых букв.
Чтобы избежать неоднозначности, код Морзе включает также паузы между кодами разных символов.
Декодирование информации
В зависимости от системы кодирования информационный код может или не может быть декодирован однозначно. Равномерные коды всегда могут быть декодированы однозначно.
Для однозначного декодирования неравномерного кода важно, имеются ли в нем кодовые слова, которые являются одновременно началом других, более длинных кодовых слов.
Неравномерные коды, для которых выполняется условие Фано, называются префиксными. Префиксный код — такой неравномерный код, в котором ни одно кодовое слово не является началом другого, более длинного слова. В таком случае кодовые слова можно записывать друг за другом без разделительного символа между ними.
Например, код Морзе не является префиксным — для него не выполняется условие Фано. Поэтому в кодовый алфавит Морзе, кроме точки и тире, входит также символ–разделитель — пауза длиной в тире. Без разделителя однозначно декодировать код Морзе в общем случае нельзя.
Не являясь специалистом в обозначенной области я, тем не менее, прочитал много специализированной литературы для знакомства с предметом и прорываясь через тернии к звёздам набил, на начальных этапах, немало шишек. При всём изобилии информации мне не удалось найти простые статьи о кодировании как таковом, вне рамок специальной литературы (так сказать без формул и с картинками).
Статья, в первой части, является ликбезом по кодированию как таковому с примерами манипуляций с битовыми кодами, а во второй я бы хотел затронуть простейшие способы кодирования изображений.
0. Начало
Поскольку я обращаюсь к новичкам в этом вопросе, то не посчитаю зазорным обратиться к Википедии. А там, для обозначения кодирования информации, у нас есть такое определение - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
Чего мне не хватало в 70-80-е, так это в школе, пусть не на информатике, а, например, на уроках математики - базовой информации по кодированию. Дело в том, что кодированием информации каждый из нас занимается ежесекундно, постоянно и в целом - не концентрируясь на самом кодировании. То есть в быту мы это делаем постоянно. Так как это происходит?
Мимика, жесты, речь, сигналы разного уровня - табличка с надписью, знак на дороге, светофоры, и для современного мира - штрих- и бар-коды, URL, хэш-тэги.
Давайте рассмотрим некоторые более подробно.
1.1 Речь, мимика, жесты
Удивительно, но всё это - коды. С помощью них мы передаём информацию о своих действиях, ощущениях, эмоциях. Самое важное, чтобы коды были понятны всем. Например, родившись в густых лесах у Амазонки и не видя современного городского человека, можно столкнуться с проблемой непонимания кода - улыбка, как демонстрация зубов, будет воспринята как угроза, а не как выражение радости.
Следуя определению, что же происходит когда мы говорим? Мысль - как форма, удобная для непосредственного использования, преобразуется в речь - форму удобную для передачи. И, смотрите, так как у звука есть ограничение как на скорость, так и на дальность передачи, то, например, жест, в какой-то ситуации, может быть выбран для передачи той же информации, но на большее расстояние.
Но мы всё еще будем ограничены дальностью остроты нашего зрения, и тогда - человек начинает придумывать другие способы передачи и преобразования информации, например огонь или дым.
1.2 Чередующиеся сигналы

Индеец пингует
В примитивном виде кодирование чередующимися сигналами используется человечеством очень давно. В предыдущем разделе мы сказали про дым и огонь. Если между наблюдателем и источником огня ставить и убирать препятствие, то наблюдателю будет казаться, что он видит чередующиеся сигналы "включено/выключено". Меняя частоту таких включений мы можем выработать последовательность кодов, которая будет однозначно трактоваться принимающей стороной.
Наряду с сигнальными флажками на морских и речных судах, при появлении радио начали использовать код Морзе. И при всей кажущейся бинарности (представление кода двумя значениями), так как используются сигналы точка и тире, на самом деле это тернаный код, так как для разделения отдельных кодов-символов требуется пауза в передаче кода. То есть код Морзе кроме "точка-тире", что нам даёт букву "A" может звучать и так - "точка-пауза-тире" и тогда это уже две буквы "ET".

1.3 Контекст
Когда мы пользуемся компьютером, мы понимаем, что информация бывает разной - звук, видео, текст. Но в чем основные различия? И до того, как начать информацию кодировать, чтобы, например, передавать её по каналам связи, нужно понять, что из себя представляет информация в каждом конкретном случае, то есть обратить внимание на содержание. Звук - череда дискретных значений о звуковом сигнале, видео - череда кадров изображений, текст - череда символов текста. Если мы не будем учитывать контекст, а, например, будем использовать азбуку Морзе для передачи всех трёх видов информации, то если для текста такой способ может оказаться приемлемым, то для звука и видео время, затраченное на передачу например 1 секунды информации, может оказаться слишком долгим - час или даже пара недель.
2. Кодирование текста
От общего описания кодирования перейдём к практической части. Из условностей мы за константу примем то, что будем кодировать данные для персонального компьютера, где за единицу информации приняты - бит и байт. Бит, как атом информации, а байт - как условный блок размером в 8 бит.
Текст в компьютере является частью 256 символов, для каждого отводится один байт и в качестве кода могут быть использованы значения от 0 до 255. Так как данные в ПК представлены в двоичной системе счисления, то один байт (в значении ноль) равен записи 00000000, а 255 как 11111111. Чтение такого представления числа происходит справа налево, то есть один будет записано как 00000001.
Итак, символов английского алфавита 26 для верхнего и 26 для нижнего регистра, 10 цифр. Так же есть знаки препинания и другие символы, но для экспериментов мы будем использовать только прописные буквы (верхний регистр) и пробел.
Тестовая фраза "ЕХАЛ ГРЕКА ЧЕРЕЗ РЕКУ ВИДИТ ГРЕКА В РЕЧКЕ РАК СУНУЛ ГРЕКА РУКУ В РЕКУ РАК ЗА РУКУ ГРЕКУ ЦАП".

2.1 Блочное кодирование
Информация в ПК уже представлена в виде блоков по 8 бит, но мы, зная контекст, попробуем представить её в виде блоков меньшего размера. Для этого нам нужно собрать информацию о представленных символах и, на будущее, сразу подсчитаем частоту использования каждого символа:

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобретя в каталоге.
Получите невероятные возможности



Конспект урока "Кодирование информации. Коды. Системы кодирования"
Для обмена информацией с другими людьми человек использует естественные и формальные языки. Представление информации с помощью какого-либо языка часто называют кодированием.
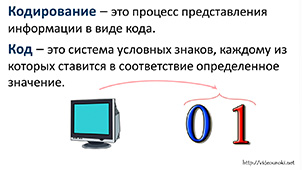
Кодирование - это процесс представления информации в виде кода.
Код - система условных знаков (символов), каждому из которых ставится в соответствие определенное значение.
Все множество символов, используемых для кодирования, называется алфавитом кодирования. Например, в памяти компьютера любая информация кодируется с помощью двоичного алфавита, содержащего всего два символа: 0 и 1.

Код состоит из определенного количества знаков, т. е. имеет определенную длину.
Количество знаков в коде называется длиной кода.
В процессе обмена информацией между людьми часто приходится переходить от одной формы представления информации к другой. Так, в процессе чтения вслух производится переход от письменной формы представления информации к устной и, наоборот, в процессе диктанта или записи объяснения учителя происходит переход от устной формы к письменной. В процессе преобразования информации из одной формы представления в другую происходит перекодирование информации.

Перекодирование - это операция преобразования знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы.
Информация может быть представлена в форме числа, текста, графики или звука.

Средством перекодирования служит таблица соответствия знаковых систем (таблица перекодировки), которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем.
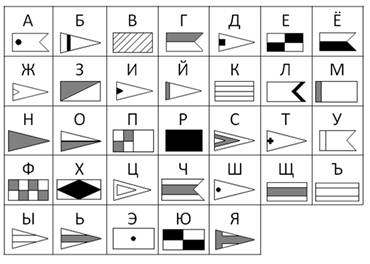
Чаще всего кодированию подвергаются тексты на естественных языках. Существуют 3 основных способа кодирования текста:
1. графический - с помощью специальных рисунков или значков;
2. числовой - с помощью чисел;
3. символьный - с помощью символов того же алфавита, что и исходный текст.
Полный набор символов, используемый для кодирования текста, называется алфавитом или азбукой.
Рассмотрим некоторые способы кодирования.

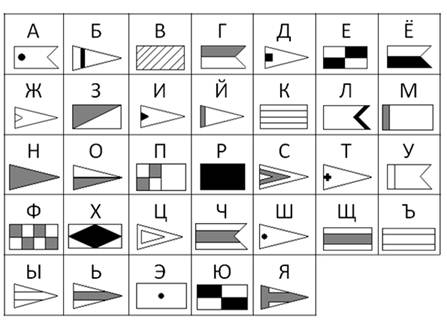
· длинный сигнал (тире),
· короткий сигнал (точка),
· отсутствие сигнала (пауза) для разделения букв.
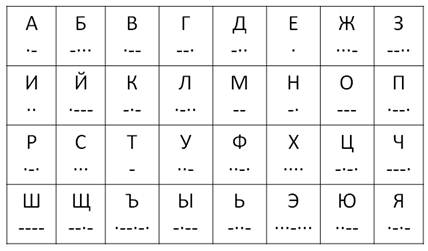
Таким образом, кодирование сводится к использованию набора символов, расположенных в строго определенном порядке.
4. Шифр Цезаря. Этот шифр реализует следующее преобразование текста: каждая буква исходного текста заменяется третьей после нее буквой в алфавите, которая считается написанным по кругу.

5. Перевод чисел из одной системы счисления в другую.
Пусть требуется перевести двоичное число в десятичную систему счисления.
Чтобы осуществлять перевод из двоичной системы счисления в десятичную, следует для начала пронумеровать разряды исходного числа справа налево, начиная с нуля.
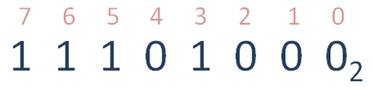
Запишем число в виде многочлена, состоящего из произведений цифр числа и соответствующей степени числа 2:
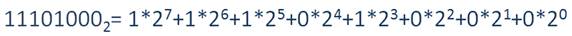
И вычислив по правилам десятичной арифметики, получили число 232.
Пусть теперь требуется перевести двоичное число в восьмеричную систему счисления. Для этого следует разбить это двоичное число на триады, начиная с младшего бита.
Если старшая триада не заполнена до конца, как в нашем случае, следует дописать в ее старшие разряды нули. После этого необходимо заменить двоичные триады, начиная с младшей, на числа, равные им в восьмеричной системе. Это числа: 4, 7, 6, 6, 4, 5, 5, 2.
Таким образом, наше двоичное число запишется в виде:

Аналогично поступаем при переводе чисел из двоичной системы счисления в шестнадцатеричную, но разбиение двоичного числа производим на тетрады. Для примера будем использовать то же двоичное число, что и при переводе в восьмеричную систему счисления.
Заменяя двоичные тетрады на их шестнадцатеричные значения, то есть на C, B, D, C, 6, 5, получим искомое шестнадцатеричное число:
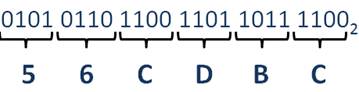
А теперь давайте мы попробуем перевести число 158 из десятичной в двоичную систему счисления. Для этого нужно выполнить последовательное деление нацело числа 158 на основании новой системы счисления, то есть на 2. Получим:
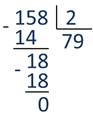
Далее число 79 делим на 2. Аналогичные действия выполняем до тех пор, пока частное не станет равным единице.
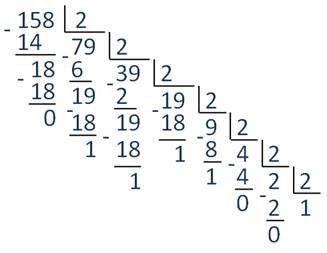
Затем запишем остатки от деления в обратном порядке, заменив их цифрами новой системы счисления, т.е. получили число 11101000.
При переводе числа из шестнадцатеричной системы счисления в двоичную, необходимо только заменить каждую цифру шестнадцатеричного числа ее эквивалентом в двоичной системе счисления (используя таблицу соответствия). И не забываем, что каждое шестнадцатеричное число следует заменять двоичным, дополняя его до 4 разрядов (в сторону старших разрядов).
Пусть требуется перевести шестнадцатеричное число F1 в двоичное число. Воспользовавшись таблицей соответствия, получим:
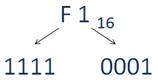
F соответствуют четыре единицы в двоичной системе счисления, а 1 соответствует такая запись 0, 0, 0, 1 в двоичной системе счисления.
Итак, число F1 в двоичной системе счисления запишется так 11110001.
Пусть теперь нам нужно перевести число F1 из шестнадцатеричной системы счисления в восьмеричную. Обычно при таком переводе чисел вначале шестнадцатеричное число переводят в двоичное, затем разбивают его на триады, начиная с младшего бита, а потом заменяют триады соответствующими им эквивалентами в восьмеричной системе. В итоге у на получится, что исходному числу в восьмеричной системе счисления соответствует число 361.
Читайте также: