
Архитектура многопользовательских субд кратко
Обновлено: 04.07.2024
Существует три типовых архитектурных решения при реализации многопользовательских СУБД:
Телеобработка (рис.8) предполагает наличие одного компьютера с единственным процессором, который соединен с несколькими терминалами.
Центральный компьютер выполняет действия прикладных программ и СУБД, а также значительную работу по обслуживанию терминалов (например, форматирование данных, выводимых на экраны терминалов, управление обменом данными со всеми терминалами). В результате на центральный процессор ложится чрезвычайно большая нагрузка, с которой могут справляться большие мейнфреймы.
Существенный прогресс в разработке высокопроизводительных персональных компьютеров и составленных из них сетей обусловил тенденцию к децентрализации и замене дорогих мейнфреймов более эффективными сетями персональных компьютеров. Эта тенденция привела к появлению следующих двух типов архитектуры СУБД – технологии файлового сервера и технологии клиент/сервер.
Файловый сервер ( рис.9) используется в локальной вычислительной сети (ЛВС) и служит для распределенной обработки данных. Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и сама СУБД размещены и функционируют на отдельных рабочих станциях и обращаются к файловому серверу только по
Файловый сервер функционирует просто как совместно используемый жесткий диск. СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файл – сервера. Поскольку файл-сервер не обрабатывает запросы пользователей, то СУБД рабочей станции должна запросить у файлового сервера все файлы, соответствующие таблицам БД, содержащим необходимые данные. А затем СУБД извлечет из этих файлов нужные ей записи из соответствующих таблиц БД.
Такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом.
Поэтому архитектура с использованием файлового сервера обладает следующими основными недостатками:
большим объемом сетевого трафика;
на каждой рабочей станции должна работать полная копия СУБД;
управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
Технология клиент/сервер (рис.10) была разработана с целью устранения недостатков, имеющихся в первых двух подходах. Клиент/сервер означает такой способ взаимодействия программных компонентов, при котором они образуют единую систему. Существует некий клиентский процесс, требующий определенных ресурсов, а также серверный процесс, который эти ресурсы предоставляет. При этом совсем необязательно, чтобы оба процесса находились на одном и том же компьютере. На практике принято размещать сервер на одном узле локальной сети, а клиенты – на других узлах.
Пользовательское приложение баз данных представляет собой клиентский процесс, выполняющийся на рабочей станции. Этот клиент принимает от пользователя запрос, проверяет его и генерирует запрос к базе данных на языке SQL. Затем он передает этот запрос серверу и ожидает поступления ответа. Сервер принимает и обрабатывает запросы к базе данных, а затем передает полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также выполнение запроса и при необходимости обновление данных. Помимо этого, поддерживается управление параллельностью и восстановлением.
Клиент, получив ответ от сервера, отображает полученные данные пользователю.
Этот тип архитектуры обладает приведенными ниже преимуществами:
обеспечивает более эффективный доступ к существующим базам данных;
повышается общая производительность системы (клиенты и серверы находятся на разных компьютерах, на сервере выполняется только работа с БД).
стоимость аппаратного обеспечения снижается (достаточно мощный компьютер нужен только серверу);
сокращаются коммуникационные расходы (существенно сокращается объем пересылаемых по сети данных);
повышается уровень непротиворечивости данных (все ограничения определяются и проверяются только в одном месте – на сервере, каждому приложению не надо выполнять собственную проверку).
Разработано дальнейшее расширение двухуровневой архитектуры клиент/сервер, при котором функциональная часть прежнего толстого (интеллектуального) клиента разделяется на две части. В трехуровневой архитектуре клиент/сервер тонкий (неинтеллектуальный) клиент на рабочей станции управляет только пользовательским интерфейсом, тогда как средний уровень обработки данных управляет всей остальной логикой приложения. Третьим уровнем здесь является сервер базы данных. Такая трехуровневая архитектура оказалась более подходящей для некоторых сред – например, для сетей Internet и Intranet, где в качестве клиента может использоваться обычный Web-браузер.
Языки баз данных
Внутренний язык СУБД для работы с данными состоит из двух частей: языка определения данных (DDL) и языка управления данными (DML). Язык DDL используется для определения схемы базы данных, а язык DML – для чтения и обновления данных, хранимых в базе. Эти языки называются подъязыками данных, поскольку в них отсутствуют конструкции для выполнения всех вычислительных операций, обычно используемых в языках программирования высокого уровня. Во многих СУБД предусмотрена возможность внедрения операторов подъязыка данных в программы, написанные на таких языках программирования высокого уровня, как Pascal или C. В этом случае язык высокого уровня принято называть базовым языком (host language). Перед компиляцией файла программы на базовом языке эти операторы подъязыка предварительно удаляются и заменяются на вызовы соответствующих функций СУБД. Затем этот предварительно обработанный файл компилируется обычным образом в объектный модуль, который затем компонуется с библиотекой, содержащей вызываемые в программе функции СУБД.
Язык определения данных – DDL, является описательным языком, который позволяет АБД или пользователю описать и поименовать сущности, необходимые для работы некоторого приложения, а также связи, имеющиеся между различными сущностями. Схема базы данных состоит из набора определений, выраженных на специальных языке определения данных – DDL. Язык DDL используется как для определения новой схемы, так и для модификации уже существующей. Этот язык нельзя использовать для управления данными. Результатом компиляции DDL-операторов является набор таблиц, хранимых в особых файлах, в которых хранятся данные, описывающие объекты базы данных – метаданные. Такой особый файл называется системным каталогом (иногда каталогом данных). Метаданные включают определения записей элементов данных, а также другие объекты, необходимые пользователям или для работы СУБД. Перед доступом к реальным данным, СУБД обычно обращается к системному каталогу.
Язык управления данными – DML, это язык, содержащий набор операторов для поддержки основных операций манипулирования данными, содержащимися в базе.
К операциям управления данными относятся: вставка в базу данных новых сведений; модификация сведений, хранимых в базе данных; извлечение сведений, содержащихся в базе данных; удаление сведений из базы данных.
Одна из основных функций СУБД заключается в поддержке языка манипулирования данными (ЯМД), с помощью которого пользователь может создавать выражения для выполнения перечисленных выше операций с данными.
Языки DML отличаются базовыми конструкциями извлечения данных. Следует различать два типа языков DML: процедурный и непроцедурный. Основное отличие между ними заключается в том, что процедурные языки указывают то, как можно получить результат оператора языка DML, тогда как непроцедурные языки описывают то, какой результат будет получен. Как правило, в процедурных языках записи БД рассматриваются по отдельности, тогда как непроцедурные языки оперируют целыми наборами данных.
Процедурные языки DML – это языки, которые позволяют сообщить системе о том, какие данные необходимы, и точно указать, как их можно извлечь. С помощью процедурного языка программист указывает на то, какие данные ему необходимы, и как их можно получить. Программист должен определить все операции доступа к данным (осуществляемые посредством вызова соответствующих процедур), которые должны быть выполнены для получения требуемой информации. Обычно такой процедурный язык позволяет извлечь запись, обработать ее, и, в зависимости от полученных результатов, извлечь другую запись, которая должна быть подвергнута аналогичной обработке, и т.д. Подобный процесс извлечения данных продолжается до тех пор, пока не будут извлечены все запрашиваемые данные. Языки DML сетевых и иерархических СУБД обычно являются процедурными.
Непроцедурные языки DML – это языки, которые позволяют указать лишь то, какие данные требуются, но не то, как их следует извлекать. Непроцедурные языки позволяют определить весь набор требуемых данных с помощью одного оператора извлечения или обновления. С помощью этих языков пользователь указывает, какие данные ему нужны без определения способа их получения. СУБД транслирует выражение на языке DML в процедуру (или набор процедур), которая обеспечивает манипулирование затребованным набором записей. Данный подход освобождает пользователя от необходимости знать детали внутренней реализации структур данных и особенности алгоритмов, используемых для извлечения и возможного преобразования данных. В результате работа пользователя получает определенную степень независимости от данных. Непроцедурные языки часто также называют декларативными языками. Реляционные СУБД обычно включают поддержку непроцедурных языков DML – чаще всего это бывает язык структурированных запросов SQL или язык запросов по образцу QBE (Query-by-Example). Непроцедурные языки обычно проще понимать и использовать, чем процедурные языки DML, поскольку пользователем выполняется меньшая часть работы, а СУБД – большая.
Аннотация: В лекции рассматриваются различные варианты технологии работы с базой данных в многопользовательском режиме (централизованная архитектура, компьютерная сеть с файловым сервером, клиент-серверная архитектура). Дается краткий обзор современных СУБД.
Цель лекции: показать основные варианты технологии работы нескольких пользователей с одной базой данных, связанные как с основными свойствами вычислительной техники, так и с развитием программного обеспечения.
Как уже отмечалось, понятие базы данных изначально предполагало возможность решения многих задач несколькими пользователями. В связи с этим, важнейшей характеристикой современных СУБД является наличие многопользовательской технологии работы. Разная реализация таких технологий в разное время была связана как с основными свойствами вычислительной техники, так и с развитием программного обеспечения. Дадим краткую характеристику этих технологий в хронологическом порядке.
3.1. Централизованная архитектура
При использовании этой технологии база данных , СУБД и прикладная программа ( приложение ) располагаются на одном компьютере (мэйнфрейме или персональном компьютере) (рис.3.1.). Для такого способа организации не требуется поддержки сети и все сводится к автономной работе. Работа построена следующим образом:
- База данных в виде набора файлов находится на жестком диске компьютера.
- На том же компьютере установлены СУБД и приложение для работы с БД .
- Пользователь запускает приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
- Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД.
- СУБД инициирует обращения к данным, обеспечивая выполнение запросов пользователя (осуществляя необходимые операции над данными).
- Результат СУБД возвращает в приложение.
- Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
Подобная архитектура использовалась в первых версиях СУБД DB2 , Oracle , Ingres [ [ 3.1 ] ].
Многопользовательская технология работы обеспечивалась либо режимом мультипрограммирования (одновременно могли работать процессор и внешние устройства – например, пока в прикладной программе одного пользователя шло считывание данных из внешней памяти, программа другого пользователя обрабатывалась процессором), либо режимом разделения времени (пользователям по очереди выделялись кванты времени на выполнение их программ). Такая технология была распространена в период "господства" больших ЭВМ (IBM-370, ЕС-1045, ЕС-1060). Основным недостатком этой модели является резкое снижение производительности при увеличении числа пользователей.
3.2. Технология с сетью и файловым сервером (архитектура "файл-сервер")
Увеличение сложности задач, появление персональных компьютеров и локальных вычислительных сетей явились предпосылками появления новой архитектуры файл-сервер . Эта архитектура баз данных с сетевым доступом предполагает назначение одного из компьютеров сети в качестве выделенного сервера, на котором будут храниться файлы базы данных [ [ 3.2 ] ]. В соответствии с запросами пользователей файлы с файл-сервера передаются на рабочие станции пользователей, где и осуществляется основная часть обработки данных. Центральный сервер выполняет в основном только роль хранилища файлов, не участвуя в обработке самих данных ( рис. 3.2.).
Работа построена следующим образом:
- База данных в виде набора файлов находится на жестком диске специально выделенного компьютера (файлового сервера).
- Существует локальная сеть, состоящая из клиентских компьютеров, на каждом из которых установлены СУБД и приложение для работы с БД.
- На каждом из клиентских компьютеров пользователи имеют возможность запустить приложение. Используя предоставляемый приложением пользовательский интерфейс, он инициирует обращение к БД на выборку/обновление информации.
- Все обращения к БД идут через СУБД, которая инкапсулирует внутри себя все сведения о физической структуре БД, расположенной на файловом сервере.
- СУБД инициирует обращения к данным, находящимся на файловом сервере, в результате которых часть файлов БД копируется на клиентский компьютер и обрабатывается, что обеспечивает выполнение запросов пользователя (осуществляются необходимые операции над данными).
- При необходимости (в случае изменения данных) данные отправляются назад на файловый сервер с целью обновления БД.
- Результат СУБД возвращает в приложение.
- Приложение, используя пользовательский интерфейс, отображает результат выполнения запросов.
В рамках архитектуры " файл-сервер " были выполнены первые версии популярных так называемых настольных СУБД , таких, как dBase и Microsoft Access.
В литературе [ [ 3.2 ] ] указываются следующие основные недостатки данной архитектуры:
В реляционных базах данных вся информация представляется в виде двумерных таблиц. С ее созданием начинается новый этап в эволюции СУБД. Простота и гибкость модели привлекли к ней внимание разработчиков и снискали ей множество сторонников. Несмотря на некоторые недостатки, реляционная модель данных стала доминирующей, а реляционные СУБД стали промышленным стандартом “де-факто”.
Реляционная модель опирается на систему понятий реляционной алгебры, важнейшими из которых являются “таблица”, “отношение”, “строка”, “первичный ключ”. Все операции над реляционной базой данных сводятся к манипуляциям с таблицами. Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строки (кортеж) – конкретный объект (рис. 2.7). Например, таблица “Сотрудники отдела” содержит сведения обо всех сотрудниках отдела, каждая ее строка – набор значений атрибутов конкретного сотрудника. Значения конкретного атрибута выбираются из домена (domain) – множества всех возможных значений атрибута объекта. Имя столбца должно быть уникальным в таблице. Столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. Любая таблица должна иметь по крайней мере один столбец. В отличие от столбцов строки не имеют имен. Порядок их следования в таблице не определен, а количество логически не ограничено.
Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или набор столбцов) называется первичным ключом. В таблице “Сотрудники отдела” первичным ключом служит столбец “Номер пропуска”. В таблице не должно быть строк, имеющих одно и то же значение первичного ключа. Если таблица удовлетворяет этому требованию, она называется отношением.
Взаимосвязь таблиц в реляционной модели поддерживается внешними ключами. Внешний ключ – это столбец, значения которого однозначно характеризуют сущности, подставленные строками некоторого другого отношения, т. е. задают значения их первичного ключа. Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом.
Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют “данные о данных” (метаданные), например, описатели таблиц, столбцов и т. д. Метаданные также представлены в табличной форме и хранятся в словаре данных. Помимо таблиц в базе данных могут храниться и другие объекты, такие как экранные формы, шаблоны отчетов и прикладные программы, работающие с информацией базы данных.
Реляционная модель поддерживает связи типа “один к одному” и “один ко многим”. Связи типа “многие ко многим” и рекурсивные связи поддерживаются с помощью декомпозиции.
Функции СУБД.
Приведем краткое описание функций СУБД, которые должны быть реализованы в любой полномасштабной СУБД:
1. Хранение, извлечение и обновление данных. СУБД должна предоставлять пользователям возможность сохранять, извлекать и обновлять данные в базе данных. Это самая фундаментальная функция СУБД. Причем, способ реализации этой функции должен быть скрыт от конечного пользователя.
2. Каталог, доступный конечным пользователям. СУБД должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных. Ключевой особенностью архитектуры ANSI/SPARC является наличие интегрированного системного каталога с данными о схемах, пользователях, приложениях и т. д. Предполагается, что каталог доступен как пользователям, так и функциям СУБД. Системный каталог или словарь данных является хранилищем информации, описывающей данные в базе данных (метаданные). В зависимости от типа используемой СУБД количество информации и способ ее применения могут варьироваться. Обычно в системном каталоге хранятся следующие сведения:
· имена, типы и размеры элементов данных;
· накладываемые на данные ограничения поддержки целостности;
· имена санкционированных пользователей;
· внешняя, концептуальная и внутренняя схемы и отображения между ними;
· статистические данные (частота транзакций, счетчик обращения к объектам базы данных).
3. Поддержка транзакций. СУБД должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них. Транзакция представляет собой набор действий, выполняемых отдельным пользователей или прикладной программой с целью доступа или изменения содержимого базы данных (например, удаление сведений о сотруднике из база данных и передача ответственности за всю курируемую им работу другому сотруднику).
4. Сервисы управления параллельностью. СУБД должны иметь механизм, который гарантирует корректное обновление базы данных при параллельном выполнении операций обновления многими пользователями. Одна из основных целей создания и использования СУБД заключается в том, чтобы множество пользователей могло осуществлять доступ к совместно обрабатываемым данным.
5. Сервисы восстановления. СУБД должна предоставлять средства восстановления базы данных на случай какого-либо ее повреждения или разрушения. Сбой может произойти в результате выхода из строя системы или запоминающего устройства, возможны ошибки аппаратного и программного обеспечения, которые могут привести к остановке СУБД.

6. Сервисы контроля доступа к данным. СУБД должна иметь механизм, гарантирующий возможность только санкционированного доступа к базе данных. Иногда требуется скрыть некоторые хранимые в базе данных сведения от других пользователей. Термин безопасность относится к защите базе данных от преднамеренного или случайного несанкционированного доступа.
8. Службы поддержки целостности данных. СУБД должна обладать инструментами контроля за тем, чтобы данные и их изменения соответствовали заданным правилам. Целостность базы данных означает корректность и непротиворечивость хранимых данных. Она может рассматриваться как еще один тип защиты базы данных, но в более широком смысле целостность связана с качеством самих данных. Целостность обычно выражается в виде ограничений или правил сохранения непротиворечивости данных (например, сотрудник не имеет права работать больше, чем на полторы ставки в данной организации).
9. Службы поддержки независимости от данных. СУБД должна обладать инструментами поддержки независимости программ от фактической структуры базы данных. Обычно она достигается за счет реализации механизма поддержки представлений или подсхем. Физическая независимость от данных достигается достаточно просто, что нельзя сказать о логической независимости от данных. Как правило, система легко адаптируется к добавлению нового объекта, атрибута или связи, но не к их удалению. В некоторых системах вообще запрещается вносить любые изменения в уже существующие компоненты логической схемы.
10. Вспомогательные службы. СУБД должна предоставлять некоторый набор различных вспомогательных служб. Вспомогательные утилиты обычно предназначены для оказания помощи АБД в эффективном администрировании базы данных. Приведем примеры таких утилит:
· утилиты импортирования, предназначенные для загрузки данных из плоских файлов или других СУБД, а также утилиты экспортирования, которые служат для выгрузки базы данных в плоские файлы или другие СУБД;
· средства мониторинга, предназначенные для отслеживания характеристик функционирования и использования базы данных;
· программы статистического анализа, позволяющие оценить производительность или степень использования базы данных;
· инструменты реорганизации индексов, предназначенные для перестройки индексов и обработки случаев их переполнения;
· инструменты сборки мусора и перераспределения памяти для физического устранения удаленных записей с запоминающих устройств, объединения освобожденного пространства и перераспределения памяти в случае необходимости.
Компоненты СУБД.
СУБД является весьма сложным видом программного обеспечения, предназначенная для предоставления перечисленных выше сервисов. Структуру компонентов СУБД практически невозможно обобщить, поскольку она сильно различается в разных системах. Однако можно представить обобщенную структуру в виде набора нескольких компонентов и определенных связей между ними.
СУБД состоит из нескольких программных компонентов (модулей), каждый их которых предназначен для выполнения специфической операции. При этом некоторые функции СУБД могут поддерживаться операционной системой, предоставляющей базовые службы, а сама СУБД всегда представляет надстройку над ними. Таким образом, при проектировании СУБД следует учитывать особенности интерфейса между создаваемой СУБД и конкретной операционной системой.
Основные программные компоненты среды СУБД представлены на рис. 2.8. На этой схеме также показано, как СУБД взаимодействует с другими программными компонентами, например, с такими, как пользовательские запросы и методы доступа к данным.
Приведем краткую характеристику программных компонентов среды СУБД:
· процессор запросов. Это основной компонент СУБД, который преобразует запросы в последовательность низкоуровневых инструкций для контроллера базы данных;
· контроллер базы данных. Этот компонент взаимодействует с запущенными пользователями прикладными программами и запросами. Контроллер базы данных принимает запросы и проверяет внешние и концептуальные схемы для определения тех концептуальных записей, которые необходимы для удовлетворения требований запросов. Затем контроллер базы данных вызывает контроллер файлов для выполнения поступившего запроса. Компоненты контроллера базы данных представлены на рис. 2.9;
· контроллер файлов. Манипулирует предназначенными для хранения данных файлами и отвечает за распределение доступного дискового пространства. Он создает и поддерживает список структур и индексов, определенных во внутренней схеме. Если используются хешированные файлы, то в его обязанности входит и вызов функций хеширования для генерации адресов записей. Однако контроллер файлов не управляет физическим вводом и выводом данных непосредственно, а лишь передает запросы соответствующим методам доступа, которые считывают данные в системные буферы или записывают их оттуда на диск;
· препроцессор языка DML. Этот модуль преобразует внедренные в прикладные программы DML-операторы в вызовы стандартных процедур базового языка. Для генерации соответствующего кода препроцессор языка DML должен взаимодействовать с процессором запросов;
· компилятор языка DDL. Компилятор языка DDL преобразует DDL-команды в набор таблиц, содержащих метаданные. Затем эти таблицы сохраняются в системном каталоге, а управляющая информация – в заголовках файлов с данными;
· контроллер словаря. Контроллер словаря управляет доступом к системному каталогу и обеспечивает работу с ним. Системный каталог доступен большинству компонентов СУБД.
Кратко рассмотрим основные программные компоненты, входящие в состав контроллера базы данных:
· контроль прав доступа. Этот модуль проверяет наличие у данного пользователя полномочий для выполнения затребованной операции;
· процессор команд. После проверки полномочий пользователя для выполнения затребованной операции управление передается процессору команд;
· средства контроля целостности. В случае операций, которые изменяют содержимое базы данных, средства контроля целостности выполняют проверку того, удовлетворяет ли затребованная операция всем установленным ограничениям поддержки целостности данных;
· оптимизатор запросов. Этот модуль определяет оптимальную стратегию выполнения запросов;
· контроллер транзакций. Этот модуль осуществляет требуемую обработку операций с базой данных. Он управляет относительным порядком выполнения операций, затребованных в отдельных транзакциях;
· планировщик. Этот модуль отвечает за бесконфликтное выполнение параллельных операций с базой данных. Он управляет относительным порядком выполнения операций, затребованных в отдельных транзакциях;
· контроллер восстановления. Этот модуль гарантирует восстановление базы данных до непротиворечивого состояния при возникновении сбоев. В частности, он отвечает за фиксацию и отмену результатов выполнения транзакций;
· контроллер буферов. Этот модуль отвечает за перенос данных между оперативной памятью и вторичным запоминающим устройством (жестким диском, магнитной лентой). Контроллер восстановления и контроллер буферов иногда называют контроллером данных.
Архитектура многопользовательских СУБД.
Телеобработка
В последние годы был достигнут существенный прогресс в разработке высокопроизводительных персональных компьютеров и составленных из них сетей. При этом во всей индустрии наблюдается заметная тенденция к децентрализации (downsizing), т. е. замене дорогих мейнфреймов более эффективными с точки зрения эксплуатационных затрат, сетями персональных компьютеров, позволяющими получить аналогичные и даже лучшие результаты. Эта технология привела к появлению двух типов архитектуры СУБД: технологии файлового сервера и технологии клиент/сервер.
Файловый сервер
В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и сама СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлам (рис. 2.11). Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск. СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файл-сервера. Такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом.
Таким образом, архитектура с использованием файлового сервера обладает следующими основными недостатками:
· большой объем сетевого трафика;
· на каждой рабочей станции должна находиться полная копия СУБД;
· управление параллельностью, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
Технология клиент/сервер
Технология клиент/сервер разработана с целью устранения недостатков, имеющихся в первых двух подходах. Термин “клиент/сервер” означает такой способ взаимодействия программных компонентов, при котором они образуют единую систему: существует клиентский процесс, требующий определенных ресурсов, а также серверный процесс, который эти ресурсы предоставляет. Как правило, принято размещать сервер на одном узле локальной сети, а клиентов – на других узлах. На рис. 2.12 показана общая архитектура типа клиент/сервер, хотя возможны и альтернативные варианты топологии: один клиент – один сервер; несколько клиентов – один сервер; несколько клиентов – несколько серверов.
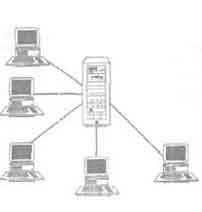
Традиционной архитектурой многопользовательских систем раньше считалась схема, получившая название телеобработки, при которой один компьютер с единственным процессором был соединен с несколькими терминалами.
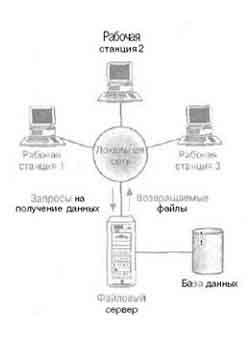
В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлами.
Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск.
СУБД на каждой рабочей станции посылает запросы файловому серверу по всем необходимым ей данным, которые хранятся на диске файлового сервера. Такой подход характеризуется значительным сетевым трафиком, что может привести к снижению производительности всей системы в целом.
Поскольку файловый сервер не воспринимает команд на языке SQL, то СУБД должна запросить у файлового сервера файлы необходимые для совершения запроса.
Таким образом, архитектура с использованием файлового сервера обладает следующими основными недостатками.
1. Большой объем сетевого трафика.
2. На каждой рабочей станции должна находиться полная копия СУБД.
3. Управление параллельной работой, восстановлением и целостностью усложняется, поскольку доступ к одним и тем же файлам могут осуществлять сразу несколько экземпляров СУБД.
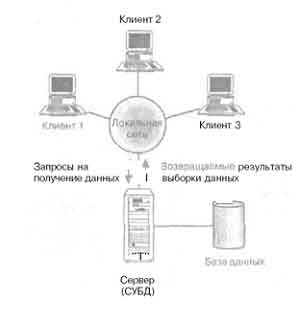
Технология "клиент/сервер" была разработана с целью устранения недостатков, имеющихся в первых двух подходах. В этой технологии используется способ взаимодействия программных компонентов, при котором они образуют единую систему. Как видно из самого названия, существует некий клиентский процесс, требующий определенных ресурсов, а также серверный процесс, который эти ресурсы предоставляет. При этом совсем не обязательно, чтобы они находились на одном и том же компьютере. На практике принято размещать сервер на одном узле локальной сети, а клиенты — на других узлах.
В контексте базы данных клиент управляет пользовательским интерфейсом и логикой приложения, действуя как сложная рабочая станция, на которой выполняются приложения баз данных.
Сервер принимает и обрабатывает запросы к базе данных, а затем передает полученные результаты обратно клиенту. Такая обработка включает проверку полномочий клиента, обеспечение требований целостности, поддержку системного каталога, а также выполнение запроса и обновление данных. Помимо этого, поддерживается управление параллельной работой и восстановлением.
Выполняемые клиентом и сервером операции приведены в следующей таблице:

Этот тип архитектуры обладает приведенными ниже преимуществами:
- Обеспечивается более широкий доступ к существующим базам данных.
- Повышается общая производительность системы. Поскольку клиенты и сервер находятся на разных компьютерах, их процессоры способны выполнять приложения параллельно. При этом настройка производительности компьютера с сервером упрощается, если на нем выполняется только работа с базой данных.
- Стоимость аппаратного обеспечения снижается. Достаточно мощный компьютер с большим устройством хранения нужен только серверу — для хранения и управления базой данных.
- Сокращаются коммуникационные расходы. Приложения выполняют часть операций на клиентских компьютерах и посылают через сеть только запросы к базе данных, что позволяет существенно сократить объем пересылаемых по сети данных.
- Повышается уровень непротиворечивости данных. Сервер может самостоятельно управлять проверкой целостности данных, поскольку все ограничения определяются и проверяются только в одном месте. При этом каждому приложению не приходится выполнять собственную проверку.
- Эта архитектура весьма естественно отображается на архитектуру открытых систем.
Некоторые разработчики баз данных использовали эту архитектуру для организации средств работы с распределенными базами данных, т.е. с набором нескольких баз данных, логически связанных и распределенных в компьютерной сети. Однако, несмотря на то, что архитектура "клиент/сервер" вполне может быть использована для организации распределенной СУБД, сама по себе она не образует распределенную СУБД.
Существует дальнейшее расширение двухуровневой архитектуры "клиент/сервер", при котором функциональная часть прежнего, толстого клиента разделяется на две части. В трехуровневой архитектуре "клиент/сервер" тонкий клиент на рабочей станции управляет только пользовательским интерфейсом, тогда как средний уровень обработки данных управляет всей остальной логикой приложения. Третьим уровнем здесь является сервер базы данных. Эта трехуровневая архитектура оказалась более подходящей для некоторых сред — например, для сетей Internet и внутренних сетей компании, где в качестве клиента может использоваться обычный Web-браузер. Такая архитектура применяется также в сочетании с мониторами обработки транзакций.
Читайте также: