
Алгоритм шеннона фано кратко
Обновлено: 30.06.2024
СЖАТИЕ ДАННЫХ И ЕГО ВИДЫ
Сжатие данных, также известное как исходное кодирование, представляет собой процесс кодирования или преобразования данных таким образом, что они занимают меньше места в памяти. Сжатие данных уменьшает количество ресурсов, необходимых для хранения и передачи данных.
Это можно сделать двумя способами: сжатие без потерь и сжатие с потерями. Сжатие с потерями уменьшает размер данных, удаляя ненужную информацию, в то время как при сжатии без потерь потеря данных не происходит.
ЧТО ТАКОЕ КОДИРОВАНИЕ ШЕННОНА ФАНО?
Алгоритм Шеннона Фано — это метод энтропийного кодирования для сжатия данных без потерь в мультимедиа. Названный в честь Клода Шеннона и Роберта Фано, он присваивает код каждому символу на основе их вероятности появления. Это схема кодирования с переменной длиной, то есть коды, назначенные символам, будут иметь различную длину.
КАК ЭТО РАБОТАЕТ?
Шаги алгоритма следующие:
- Создайте список вероятностей или счетчиков частоты для данного набора символов, чтобы была известна относительная частота появления каждого символа.
- Сортируйте список символов в порядке убывания вероятности, наиболее вероятные слева и наименее вероятные справа.
- Разделите список на две части, с общей вероятностью того, что обе части будут как можно ближе друг к другу.
- Присвойте значение 0 левой части и 1 правой части.
- Повторите шаги 3 и 4 для каждой части, пока все символы не будут разделены на отдельные подгруппы.
Коды Шеннона считаются точными, если код каждого символа уникален.
ПРИМЕР:
Данная задача состоит в том, чтобы построить коды Шеннона для данного набора символов, используя технику сжатия без потерь Шеннона-Фано.


Решение:
-
Пусть P (x) — вероятность появления символа x:
P(A) + P(C) + P(E) = 0.22 + 0.15 + 0.05 = 0.42
И так как почти все таблицы делятся поровну, то наибольшее количество делится в таблице блочных котировок.
и присвойте им значения 0 и 1 соответственно.


P(D) = 0.30 and P(B) = 0.28
это означает, что P (D) ~ P (B) , поэтому разделите на и и присвойте 0 для D и 1 для B.


P(A) = 0.22 and P(C) + P(E) = 0.20
Таким образом, группа делится на
и им присвоены значения 0 и 1 соответственно.
P(C) = 0.15 and P(E) = 0.05
Поэтому разделите их на и и присвойте 0 для и 1 для


Примечание: разделение теперь остановлено, поскольку каждый символ теперь разделен.
Коды Шеннона для набора символов:

Как видно, все они уникальны и имеют разную длину.
Ниже приведена реализация вышеуказанного подхода:
// C ++ программа для алгоритма Шеннона Фано
using namespace std;
// объявляем узел структуры
// для хранения символа
// для сохранения вероятности или частоты
typedef struct node node;
// функция для поиска кода Шеннона
void shannon( int l, int h, node p[])
float pack1 = 0, pack2 = 0, diff1 = 0, diff2 = 0;
if ((l + 1) == h || l == h || l > h)
pack1 = pack1 + p[i].pro;
pack2 = pack2 + p[h].pro;
diff1 = pack1 - pack2;
diff1 = diff1 * -1;
while (j != h - l + 1)
pack1 = pack2 = 0;
pack1 = pack1 + p[i].pro;
for (i = h; i > k; i--)
pack2 = pack2 + p[i].pro;
diff2 = pack1 - pack2;
diff2 = diff2 * -1;
if (diff2 >= diff1)
// Вызов функции Шеннона
shannon(k + 1, h, p);
// Функция для сортировки символов
// на основе их вероятности или частоты
Алгоритм Шеннона-Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: часто встречающийся символ кодируется кодом меньшей длины, редко встречающийся — кодом большей длины. Коды Шеннона-Фано префиксные, то есть, никакое кодовое слово не является префиксом любого другого. Это свойство позволяет однозначно декодировать любую последовательность кодовых слов.
Содержание
Основные сведения
Основные этапы
Когда размер подалфавита становится равен нулю или единице, то дальнейшего удлинения префиксного кода для соответствующих ему символов первичного алфавита не происходит, таким образом, алгоритм присваивает различным символам префиксные коды разной длины. На шаге деления алфавита существует неоднозначность, так как разность суммарных вероятностей p0 − p1 может быть одинакова для двух вариантов разделения (учитывая, что все символы первичного алфавита имеют вероятность, большую нуля).
Алгоритм вычисления кодов Шеннона-Фано
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Все множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n+1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути еше не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
A (частота встречаемости 50), B (частота встречаемости 39), C (частота встречаемости 18), D (частота встречаемости 49), E (частота встречаемости 35), F (частота встречаемости 24).

A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина сжатой последовательности, по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях всё же формируются неоптимальные коды Шеннона-Фано, поэтому сжатие методом Хаффмана принято считать более эффективным.
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем.
Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий.
Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
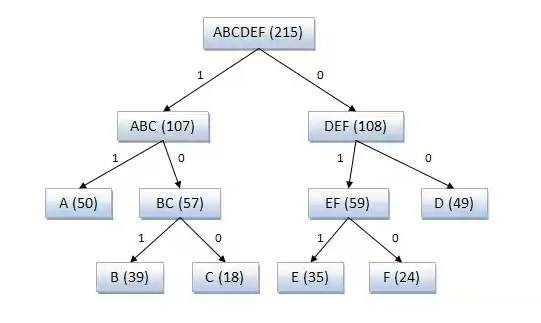
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона-Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Пример 1. Закодируем буквы алфавита в коде Шеннона-Фано.
Пусть имеется случайная величина X (x1, x2, x3, x4, x5, x6, x7, x8), имеющая восемь состояний с распределением вероятностей
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
Определив избыточность L по формуле L=1-H/H0=1-2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
| X | P | Коды | |
| x1 | 1/4 | ------- | ------- |
| x2 | 1/4 | ------- | ------- |
| x3, | 1/8 | ------- | |
| x4 | 1/8 | ------- | |
| x5 | 1/16 | ||
| x6 | 1/16 | ||
| x7 | 1/16 | ||
| x8 | 1/16 |
Средняя длина полученного кода будет равна
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице
| Буква | Рi | Код | ||
| ? | 0.145 | - | ||
| о | 0.095 | - | ||
| е | 0.074 | |||
| а | 0.064 | |||
| и | 0.064 | |||
| н | 0.056 | |||
| т | 0.056 | … | … | - |
| с | 0.047 | … | … | |
| . | … | |||
| ф | 0.03 |
Средняя длина данного кода будет равна, бит/букву;
Энтропия H=4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины , то эффективность была бы значительно ниже.

Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем.
Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий.
Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона-Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Пример 1. Закодируем буквы алфавита в коде Шеннона-Фано.
Пусть имеется случайная величина X (x1, x2, x3, x4, x5, x6, x7, x8), имеющая восемь состояний с распределением вероятностей
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
Определив избыточность L по формуле L=1-H/H0=1-2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
| X | P | Коды | |
| x1 | 1/4 | ------- | ------- |
| x2 | 1/4 | ------- | ------- |
| x3, | 1/8 | ------- | |
| x4 | 1/8 | ------- | |
| x5 | 1/16 | ||
| x6 | 1/16 | ||
| x7 | 1/16 | ||
| x8 | 1/16 |
Средняя длина полученного кода будет равна
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице
| Буква | Рi | Код | ||
| ? | 0.145 | - | ||
| о | 0.095 | - | ||
| е | 0.074 | |||
| а | 0.064 | |||
| и | 0.064 | |||
| н | 0.056 | |||
| т | 0.056 | … | … | - |
| с | 0.047 | … | … | |
| . | … | |||
| ф | 0.03 |
Средняя длина данного кода будет равна, бит/букву;
Энтропия H=4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины , то эффективность была бы значительно ниже.
Алгоритм метода Шеннона-Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано, и он имеет большое сходство с алгоритмом Хаффмана. Алгоритм основан на частоте повторения. Так, часто встречающийся символ кодируется кодом меньшей длины, а редко встречающийся — кодом большей длины.
В свою очередь, коды, полученные при кодировании, префиксные. Это и позволяет однозначно декодировать любую последовательность кодовых слов. Но все это вступление.
Для работы оба алгоритма должны иметь таблицу частот элементов алфавита.
Таким образом, видно, что алгоритм Хаффмана как бы движется от листьев к корню, а алгоритм Шеннона-Фано, используя деление, движется от корня к листям.
Ну вот, быстро осмыслив информацию, можно написать код алгоритма Шеннона-Фано на паскале. Попросили именно на нем написать. Поэтому приведу листинг вместе с комментариями.
Ну вот собственно и все, о чем я хотел рассказать. Всю информацию можно взять из википедии. На рисунках приведены частоты сверху.
Читайте также: