
Разработка базы данных sql конспект
Обновлено: 07.07.2024
Итак, вы установили MySQL, и мы начинаем осваивать язык SQL. В уроке 3 по основам баз данных, мы создали концептуальную модель маленькой БД для форума. Пришло время реализовать ее в СУБД MySQL.
Для этого прежде всего надо запустить сервер MySQL. Идем в системное меню Пуск - Программы - MySQL - MySQL Server 5.1 - MySQL Command Line Client. Откроется окно, предлагающее ввести пароль.
Нажимаем Enter на клавиатуре, если вы не указывали пароль при настройке сервера или указываем пароль, если вы его задавали. Ждем приглашения mysql>.
Нам надо создать базу данных, которую мы назовем forum. Для этого в SQL существует оператор create database. Создание базы данных имеет следующий синтаксис:
Итак, создадим БД forum:
Нажимаем Enter и видим ответ "Query OK . ", означающий, что БД была создана:
Итак, выберем для работы нашу БД forum:
Нажимаем Enter и видим ответ "Database changed" - база данных выбрана.
Выбирать БД необходимо в каждом сеансе работы с MySQL.
Для создания таблиц в SQL существует оператор create table. Создание базы данных имеет следующий синтаксис:
create table имя_таблицы (имя_первого_столбца тип, имя_второго_столбца тип, . имя_последнего_столбца тип );
Требования к именам таблиц и столбцов такие же, как и для имен БД. К каждому столбцу привязан определенный тип данных, который ограничивает характер информации, которую можно хранить в столбце (например, предотвращает ввод букв в числовое поле). MySQL поддерживает несколько типов данных: числовые, строковые, календарные и специальный тип NULL, обозначающий отсутствие информации. Подробно о типах данных мы будем говорить в следующем уроке, а пока вернемся к нашим таблицам. В них у нас всего два типа данных - целочисленные значения (int) и строки (text). Итак, создадим первую таблицу - Темы:
Нажимаем Enter - таблица создана:
Итак, мы создали таблицу topics (темы) с тремя столбцами:
id_topic int - id темы (целочисленное значение),
topic_name text - имя темы (строка),
id_author int - id автора (целочисленное значение).
Итак, мы создали БД forum и в ней три таблицы. Сейчас мы об этом помним, но если наша БД будет очень большой, то удержать в голове названия всех таблиц и столбцов просто невозможно. Поэтому надо иметь возможность посмотреть, какие БД у нас существуют, какие таблицы в них присутствуют, и какие столбцы эти таблицы содержат. Для этого в SQL существует несколько операторов:
show databases - показать все имеющиеся БД,
show tables - показать список таблиц текущей БД (предварительно ее надо выбрать с помощью оператора use),
describe имя_таблицы - показать описание столбцов указанной таблицы.
Давайте попробуем. Смотрим все имеющиеся базы данных (у вас она пока одна - forum, у меня 30, и все они перечислены в столбик):
Теперь посмотрим список таблиц БД forum (для этого ее предварительно надо выбрать), не забываем после каждого запроса нажимать Enter:
В ответе видим названия наших трех таблиц. Теперь посмотрим описание столбцов, например, таблицы topics:
Первые два столбца нам знакомы - это имя и тип данных, значения остальных нам еще предстоит узнать. Но прежде мы все-таки узнаем какие типы данных бывают, какие и когда следует использовать.
А сегодня мы рассмотрим последний оператор - drop, он позволяет удалять таблицы и БД. Например, давайте удалим таблицу topics. Так как мы два шага назад выбирали БД forum для работы, то сейчас ее выбирать не надо, можно просто написать:
Теперь снова посмотрим список таблиц нашей БД:
Наша таблица действительно удалена. Теперь давайте удалим и саму БД forum (удаляйте, не жалейте, ее все равно придется переделывать). Для этого напишем:
И убедитесь в этом, сделав запрос на все имеющиеся БД:
У вас, наверно, нет ни одной БД, у меня их стало 29 вместо 30.
На сегодня все. Мы научились создавать базы данных и таблицы, удалять их и извлекать информацию об имеющихся базах данных, таблицах и их описаниях.
Видеоуроки php + mysql
Если этот сайт оказался вам полезен, пожалуйста, посмотрите другие наши статьи и разделы.
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам
Конспект к уроку на тему
" Создание баз данных
в InterBase SQL Server"
Выполнил учитель информатики и математики
Садовникова Вероника Сергеевна
Создание баз данных в InterBase SQL Server
Я не буду загромождать текст подробным описанием всех операторов для создания объектов в базе данных. Для этого есть документация. Наоборот, на простых примерах постараюсь показать как и когда нужно делать так или иначе. Здесь описывается работа с SQL сервером InterBase 6.0.
Создание базы данных
База данных создается простым скриптом. Здесь и в дальнейшем я буду SQL операторы выделять жирным шрифтом.
CREATE DATABASE '. PFO_POKAZATELI.GDB'USER 'ADM_PFO_POK' PASSWORD '12345'
DEFAULT CHARACTER SET WIN1251;
CREATE DATABASE - это и есть оператор, который создаст базу данных. База данных будет представлять из себя файл, который будет создан в каталоге, указанном после оператора. Расширение файла может быть любым, но принято, что GDB - расширение для файла базы данных, а, например, GBP - для резервной копии.
PAGE SIZE задает размер странички данных в файле по умолчанию. Страничка будет скачиваться с жесткого диска только целиком. Поэтому, можно считать, что это минимальный размер буфера работы с файлом базы данных. Страничка должна быть такого размера, чтобы в неё поместилась хотя бы одна запись в любой из таблиц. Здесь не нужно учитывать размер BLOB поля, т.к. для его хранения выделяются дополнительные страницы. Размеры страниц могут быть от 1024 до 8192 Kb. Размер страниц влияет на быстродействие и степень заполнения данными файла базы данных. Так, если следующая запись не помещается полностью в активную страницу, то для неё будет выделена новая страница. Поэтому следует стремиться к кратному странице размеру записи. Это, конечно весьма проблематично, т.к. у Вас в БД может быть несколько таблиц с разными размерами записи. Слишком большой размер страницы приводит к считыванию с диска записей, которые могут не понадобиться в выходных данных запроса, что должно снижать быстродействие всей системы в целом. Очевидно, это происходит при маленьких размерах записи по сравнению с размером страницы. Однако, многочисленные опыты показывают, что быстродействие может и снижается, но на такую маленькую величину, которую невозможно зафиксировать и измерить в реальных грамотно построенных приложениях.
DEFAULT CHARACTER SET определяет кодировку символов в базе данных. Если Вы намереваетесь использовать русский язык, то Вам следует установить значение WIN 1251. Для других языков есть свои кодировочные таблицы. Обычно базу данных создают в IBConsole. Там нужно выбрать пункт меню "Database|Create Database". В появившемся окне заполнить поля ввода параметров операторов для создания БД.
Вы можете создать БД из нескольких файлов, которые будут заполняться данными по очереди. Или создать зеркало на другом жестком диске для защиты от крушения основного жесткого диска (см. документацию).Создание таблиц
InterBase - это не совсем то, о чем писал Кодд. Здесь полностью не реализовано понятие домена. Домены служат в InterBase не для связи таблиц по первичному и внешнему ключу, а для описания типа поля, определенного пользователем. Более того, если Вы начнете создавать таблицы с полями стандартного типа, то каждому из этих полей будет поставлен в соответствие свой домен. Это приводит к тому, что количество объектов в базе данных прирастает за счет доменов прямо пропорционально количеству полей всех таблиц. Поэтому, обычно создают достаточное количество доменов для описания таблиц в БД, а потом создают сами таблицы. Вот выдержка из реальной базы данных для создания доменов:
CREATE DOMAIN IZMER_NUM INTEGER NOT NULL;
CREATE DOMAIN ACTIVITIES_NUM INTEGER NOT NULL;
CREATE DOMAIN NAMES_TYPE VARCHAR(45) COLLATE PXW_CYRL;
CREATE DOMAIN FLOAT_TYPE DOUBLE PRECISION;
CREATE DOMAIN BOOL_TYPE CHAR(1) DEFAULT "F" CHECK(VALUE = "T" OR VALUE = "F");
CREATE DOMAIN FORMULA_TYPE BLOB SUB_TYPE 1 SEGMENT SIZE 256 CHARACTER SET WIN1251;
CREATE DOMAIN INTEGER_TYPE INTEGER;
CREATE DOMAIN BY_USER VARCHAR(30) DEFAULT USER;
CREATE DOMAIN BY_DATE TIMESTAMP DEFAULT "now";
Команда CREATE DOMAIN создает новый домен. Далее, идет имя домена. Затем - его тип. Есть множество типов данных, которые поддерживает InterBase. Вы можете узнать эту информацию из документации. Далее, можно задать ограничения на значение, заводимое в поле таблицы типа этого домена. Например, NOT NULL обязывает всегда заводить какие-нибудь данные в это поле при добавлении новой строки в таблицу, т.е. это поле обязательно должно быть заполнено. DEFAULT "F" заполняет поле значением по умолчанию - символом "F". Конструкция CHECK(VALUE = "T" OR VALUE = "F") проверяет выход значения поля за заданные границы. Конструкция COLLATE PXW_CYRL позволяет правильно вести сортировку строк таблицы по полю типа этого домена. Эта конструкция применяется при создании домена или при объявлении индекса (об этом позже). Конструкция CREATE DOMAIN FORMULA_TYPE BLOB SUB_TYPE 1 SEGMENT SIZE 256 CHARACTER SET WIN1251 создает домен типа BLOB, т.е. набор байтов, которые рассматриваются как текст (SUB_TYPE 1), странички в файле БД для этого текста выделяются по 256 байт сразу и текст в этом поле записывается в кодировке WIN1251. Последние два домена могут хранить информацию о пользователе и дату и время о последнем изменении записи. Теперь создадим какую-нибудь таблицу.
CREATE TABLE IZMER_NAMES
Оператор CREATE TABLE собственно, создает таблицу, далее идет её уникальное в пределах БД имя. Между скобками стоят определения столбиков таблицы и дополнительные операторы. Мы видим, что таблица состоит из четырех столбиков, а их тип описан через домены, которые мы описали ранее. Если Вы создадите еще одну таблицу с полем типа NAMES_TYPE, то количество доменов у Вас не увеличится, а если бы Вы создали две таблицы, у которых было бы по одному полю типа VARCHAR(45), то это привело бы к созданию двух доменов, описывающих эти поля. Причем, имена этих доменов присвоились бы по умолчанию, а значит, совершенно нечитабельные. Оператор PRIMARY KEY пределяет имя или имена полей, которые рассматриваются как первичный ключ. Поля первичного ключа должны быть NOT NULL и сочетание их значений должно быть уникально в пределах таблицы. Это как бы отпечаток пальцев записи - набор значений полей, по которым мы всегда сможем отличить одну запись от другой. Если Вы не можете выделить первичный ключ в таблице для хранения Ваших данных, значит, скорее всего, Вы недостаточно хорошо продумали все вопросы по хранению данных в таблице.Связывание таблиц
Связать можно хотя бы две таблицы, поэтому определим вторую:
CREATE TABLE ACTIVITIES
FOREIGN KEY(ID_IZMER_NAMES) REFERENCES IZMER_NAMES(ID_NUM));
Во второй таблице есть поле с типом IZMER_NUM - это домен, который используется в первой таблице для определения поля первичного ключа. Мы можем создать внешний ключ для связи двух таблиц: FOREIGN KEY(ID_IZMER_NAMES) REFERENCES IZMER_NAMES(ID_NUM). Что буквально означает: "Внешний ключ по полю ID_IZMER_NAMES как ссылка в таблицу IZMER_NAMES по полю ID_NUM". Такая связь гарантирует нам, что в таблице IZMER_NAMES всегда будет присутствовать строка с номером, который мы запишем в поле ID_IZMER_NAMES. Если кто-нибудь попытается удалить из справочника единиц измерения строку, которую мы используем в справочнике деятельности, то произойдет исключительная ситуация. Такое поведение БД называется контроль ссылочной целостности. Теперь, немного слов о плане построения БД. Хорошо, если у Вас есть какой никакой Case инструмент, например, Rational Rose. Говорят, что в Microsoft Office появился Visio. Я подозреваю, что это что-то не совсем то, что нужно, но лучше сейчас работать хоть на чем-то, чем долго ждать хороший инструмент. Ну, а если нет Case, то следует учитывать ряд небольших правил:
Составьте текст БД, а потом вводите запросы. Текст пригодится Вам для проверки перед вводом. В процессе ввода, Вы найдете ряд ошибок, которые сразу заносите в текст БД (скрипт).
Сначала создаются справочники, которые не имеют внешних связей, затем те таблицы, которые имеют связи на эти справочники и т.д. от простого к сложному, или Вам придется все связи определять после создания таблиц.
Не используйте для создания БД визуальные программы типа Database Desctop или SQL Explorer. Вводите все в виде SQL запросов, например в Interactive SQL. По крайней мере, Вы точно будете знать какой именно запрос Вы пытаетесь выполнить.
Суррогатные ключи
Есть два типа ключевых полей. Первое - это естественные ключи. Возьмем, к примеру, медицинскую карту в поликлинике. Естественный ключ - это номер медицинской карты. На медицинскую карту "цепляются" талоны (связь главный - подчиненные), у которых естественный ключ - это номер медицинской карты больного, отчетный год и номер талона (с нового года нумерация начинается с единицы). К талонам "цепляются" посещения, у которых естественный ключ - номер медицинской карты больного, отчетный год, номер талона и дата посещения. К посещениям - услуги и т.д. Мы видим, что размер первичного ключа увеличивается, по крайней мере, на одно поле с каждой новой таблицей. Соответственно, растет вычислительная нагрузка, которую можно оценить мощностью домена, на сервер БД. Как же можно противостоять разрастанию первичного ключа? Многие программисты, и я в том числе, считают, что уникальность записи и первичный ключ - это понятия, вообще-то разные, поэтому мы всегда, где это нужно, применяем т.н. сокращение первичного ключа. Для этого используются суррогатные (т.е. неестественные) ключи. Что такое суррогатный ключ? Это поле целого типа, которое имеет уникальное значение, образующее домен с другими таблицами. Возьмем, для примера, случай с поликлиникой. Для таблицы с талонами вводится уникальное поле целого типа, в котором будет хранится последовательность целых чисел 1, 2, 3 . N и т.д. Это поле объявлено первичным ключом, а чтобы не завести несколько талонов с одинаковыми номерами, объявляется уникальный индекс по полям отчетный год и номер талона. Внешний ключ, как и положено - по полю номера медицинской карты. В результате, мы сократили размер первичного ключа, который теперь является суррогатным. Эти целые числа будут использоваться в таблице с посещениями, где тоже можно сокращать первичный ключ. Заметьте, что в таблице с посещениями, теперь, не нужно хранить не номер медицинской карты, не отчетный год, не номер талона, а только значение первичного ключа, т.е. одно целое число на запись.
Вот несколько примеров для работы с суррогатными ключами.
Для начала, нужно создать механизм поддержки уникальности значений суррогатного ключа.CREATE GENERATOR GET_IZMER_NAMES_NUM;
Этот оператор создает т.н. генератор, где будет хранится предыдущее значение нашей уникальной последовательности целых чисел. Механизм гарантирует, что только один пользователь может иметь доступ к генератору в один момент времени. Остальные будут ждать, пока генератор не освободится.
SET GENERATOR GET_IZMER_NAMES_NUM TO 50;
Этим оператором мы установили начальное значение генератора. Далее, можно либо создать триггер, который сработает при добавлении новой записи в таблицу, либо создать простенькую процедуру, которая вернет очередное значение из генератора:
CREATE PROCEDURE SET_IZMER_NAMES_NUM
BEGINNUM = GEN_ID(GET_IZMER_NAMES_NUM, 1);
GEN_ID - это встроенная процедура, которая просто увеличивает значение генератора на величину, переданную во втором параметре и возвращает результат. Если Вы используете триггер, то после добавления новой записи, Вам придется обновлять весь набор данных, чтобы знать значение первичного ключа, поэтому лучше использовать процедуру.
"Деревянные" списки
Бывают случаи, когда отношение главный-подчиненный присуще записям одной и той же таблице, например, отношения между отделами организации или между структурами госаппарата и т.д. и т.п. Одна запись может быть главной для нескольких других, которые в свою очередь могут быть главными для следующих. Такая структура напоминает дерево с ветвями, расположенными вниз по таблице. Первая запись (записи) - главный узел (узлы) от которых идут ветви (подчиненные записи). Если эти записи имеют свои подчиненные (вложенные) записи, то они образуют следующие по иерархическому списку узлы. Проще всего, представить это в пространстве в виде слоев записей. Каждая запись может содержать в себе вложенный слой с записями. Несмотря на всю кажущуюся сложность, реализация такой структуры очень проста. Для этого нужно иметь, как минимум, два столбика в таблице: первый столбик - это суррогатный первичный ключ, а второй - ссылка на первый столбик со значением первичного ключа записи - владельца. Вот реализация такой таблицы :
CREATE TABLE ACTIVITIES
FOREIGN KEY(ID_IZMER_NAMES) REFERENCES IZMER_NAMES(ID_NUM));
Таблица содержит первичный ключ в поле ID_NUM, ссылку на главную запись в поле ID_OWNER, ссылку на единицу измерения в поле ID_IZMER, поле POZITION целого типа, определяющее позицию записи, для возможности перемещения записи вверх и низ, наименование вида дечтельности в поле NAME. Далее, идут счетчик и процедура для работы с первичным ключом.
CREATE GENERATOR GET_ACTIVITIES_NUM;
SET GENERATOR GET_ACTIVITIES_NUM TO 50;
CREATE PROCEDURE SET_ACTIVITIES_NUM
BEGINNUM = GEN_ID(GET_ACTIVITIES_NUM, 1);
Далее, идет индекс для сортировки строк по позиции. Имя POZITION принято мной не потому, что я не знаю о английском слове POSITION, а потому, что POSITION - зарезервированный идентификатор SQL.
CREATE UNIQUE INDEX ACTIVITIES_POSITION ON ACTIVITIES(ID_OWNER, POZITION);
Триггер UPDATE_ACTIVITIES обновляет значения полей, идентифицирующиз пользователя внесшего последние изменения.
CREATE TRIGGER UPDATE_ACTIVITIES FOR ACTIVITIES
BEFORE UPDATE AS
Наконец, добавлен внешний индекс таблицы на саму себя. В описании таблице это нельзя было сделать,т.к. ни поля ID_OWNER, ни поля ID_NUM, ни самой таблицы не существовало.
ALTER TABLE ACTIVITIES
FOREIGN KEY (ID_OWNER) REFERENCES ACTIVITIES(ID_NUM) ON DELETE CASCADE;
Далее, идет процедура перемещения строки в слое данных вверх или низ. Подразумевается , что в слое не более 2147483646 строк .
CREATE PROCEDURE SET_ACTIVITIES_POSITION(OWNER_NUM INTEGER, OLD_POSITION INTEGER, NEW_POSITION INTEGER)
В этой статье мы рассмотрим создание базы данных SQL и создание таблицы SQL, используя команды в клиенте mysql. Предполагается, что этот инструмент запущен и подключен к серверу базы данных MySQL.
Создание новой базы данных MySQL
Новая база данных создается с помощью оператора SQL CREATE DATABASE, за которым следует имя создаваемой базы данных. Для этой цели также используется оператор CREATE SCHEMA. Например, для создания новой базы данных под названием MySampleDB в командной строке mysql нужно ввести следующий запрос:
Если все прошло нормально, команда сгенерирует следующий вывод:
В этой ситуации следует выбрать другое имя базы данных или использовать опцию IF NOT EXISTS. Она создает базу данных только в том случае, если она еще не существует:
Создание таблицы SQL
Новые таблицы добавляются в существующую базу данных с помощью оператора CREATE TABLE SQL. За оператором CREATE TABLE следует имя создаваемой таблицы, а далее через запятые список имен и определений каждого столбца таблицы:
CREATE TABLE имя_таблицы ( определение имени_столбца, определение имени_таблицы …, PRIMARY KEY = (имя_столбца) ) ENGINE = тип_движка;
В определении столбца задается тип данных, может ли столбец быть NULL, AUTO_INCREMENT. Оператор CREATE TABLE также позволяет указать столбец (или группу столбцов) в качестве первичного ключа.
Прежде чем будет создавать таблицу, нужно выбрать базу данных. Это делается с помощью оператора SQL USE:
Создадим таблицу, состоящую из трех столбцов: customer_id , customer_name и customer_address . Столбцы customer_id и customer_name не должны быть пустыми (то есть NOT NULL). customer_id содержит целочисленное значение, которое будет автоматически увеличиваться при добавлении новых строк. Остальные столбцы будут содержать строки длиной до 20 символов. Первичный ключ определяется как customer_id.
Значения NULL и NOT NULL
Если для столбца указано значение NULL, тогда пустые строки будут добавляться в таблицу. И наоборот, если столбец определяется как NOT NULL, тогда пустые строки не будут добавлены.
Первичные ключи
Первичный ключ — это столбец, используемый для идентификации записей в таблице. Значение столбца первичного ключа должно быть уникальным. Если несколько столбцов объединены в первичный ключ, то комбинация значений ключей должна быть уникальной для каждой строки.
Первичный ключ определяется с помощью оператора PRIMARY KEY во время создания таблицы. Если используется несколько столбцов, они разделяются запятой:
В следующем примере создается таблица с использованием двух столбцов в качестве первичного ключа:
AUTO_INCREMENT
Когда столбец определяется с помощью AUTO_INCREMENT, его значение автоматически увеличивается каждый раз, когда в таблицу добавляется новая запись. Это удобно при использовании столбца в качестве первичного ключа. Благодаря AUTO_INCREMENTне нужно писать инструкции SQL для вычисления уникального идентификатора для каждой строки.
AUTO_INCREMENT может быть присвоен только одному столбцу в таблице. И он должен быть проиндексирован (например, объявлен в качестве первичного ключа).
Значение AUTO_INCREMENT для столбца можно переопределить, указав новое при выполнении инструкции INSERT.
Можно запросить у MySQL самое последнее значение AUTO_INCREMENT, используя функцию last_insert_id() следующим образом:
Определение значений по умолчанию при создании таблицы
Значения по умолчанию используются, когда значение не определено при вставке в базу данных.
Значения по умолчанию задаются с помощью ключевого слова DEFAULT в операторе CREATE TABLE. Например, приведенный ниже запрос SQL задает значение по умолчанию для столбца sales_quantity:
Типы движков баз данных MySQL
Каждый из примеров создания таблицы в этой статье до этого момента включал в себя определение ENGINE= . MySQL поставляется с несколькими различными движками баз данных, каждый из которых имеет свои преимущества. Используя директиву ENGINE =, можно выбрать, какой движок использовать для каждой таблицы. В настоящее время доступны следующие движки баз данных MySQL:
- InnoDB — был представлен вMySQL версии 4.0 и классифицирован как безопасная среда для транзакций.Ее механизм гарантирует, что все транзакции будут завершены на 100%. При этом частично завершенные транзакции (например, в результате отказа сервера или сбоя питания) не будут записаны. Недостатком InnoDB является отсутствие поддержки полнотекстового поиска.
- MyISAM — высокопроизводительный движок с поддержкой полнотекстового поиска. Эта производительность и функциональность обеспечивается за счет отсутствия безопасности транзакций.
- MEMORY — с точки зрения функционала эквивалентен MyISAM, за исключением того, что все данные хранятся в оперативной памяти, а не на жестком диске. Это обеспечивает высокую скорость обработки. Временный характер данных, сохраняемых в оперативной памяти, делает движок MEMORY более подходящим для временного хранения таблиц.
Движки различных типов могут сочетаться в одной базе данных. Например, некоторые таблицы могут использовать движок InnoDB, а другие — MyISAM. Если во время создания таблицы движок не указывается, то по умолчанию MySQL будет использовать MyISAM.
Чтобы указать тип движка, который будет использоваться для таблицы, о поместите соответствующее определение ENGINE= после определения столбцов таблицы:
Пожалуйста, опубликуйте ваши комментарии по текущей теме статьи. За комментарии, отклики, лайки, дизлайки, подписки низкий вам поклон!
Пожалуйста, опубликуйте ваши мнения по текущей теме материала. За комментарии, отклики, подписки, дизлайки, лайки низкий вам поклон!
Пожалуйста, оставьте ваши мнения по текущей теме материала. За комментарии, лайки, подписки, отклики, дизлайки огромное вам спасибо!
Аннотация: Определяется процесс создания базы данных. Описываются операторы создания, изменения базы данных. Рассматривается возможность указания имени файла или нескольких файлов для хранения данных, размеров и местоположения файлов. Анализируются операторы создания, изменения, удаления пользовательских таблиц. Приводится описание параметров для объявления столбцов таблицы. Дается понятие и характеристика индексов. Рассматриваются операторы создания и изменения индексов. Определяется роль индексов в повышении эффективности выполнения операторов SQL.
База данных
Создание базы данных
В различных СУБД процедура создания баз данных обычно закрепляется только за администратором баз данных . В однопользовательских системах принимаемая по умолчанию база данных может быть сформирована непосредственно в процессе установки и настройки самой СУБД. Стандарт SQL не определяет, как должны создаваться базы данных , поэтому в каждом из диалектов языка SQL обычно используется свой подход. В соответствии со стандартом SQL, таблицы и другие объекты базы данных существуют в некоторой среде. Помимо всего прочего, каждая среда состоит из одного или более каталогов , а каждый каталог – из набора схем . Схема представляет собой поименованную коллекцию объектов базы данных , некоторым образом связанных друг с другом (все объекты в базе данных должны быть описаны в той или иной схеме ). Объектами схемы могут быть таблицы , представления, домены, утверждения, сопоставления, толкования и наборы символов. Все они имеют одного и того же владельца и множество общих значений, принимаемых по умолчанию.
Стандарт SQL оставляет за разработчиками СУБД право выбора конкретного механизма создания и уничтожения каталогов , однако механизм создания и удаления схем регламентируется посредством операторов CREATE SCHEMA и DROP SCHEMA . В стандарте также указано, что в рамках оператора создания схемы должна существовать возможность определения диапазона привилегий, доступных пользователям создаваемой схемы . Однако конкретные способы определения подобных привилегий в разных СУБД различаются.
В настоящее время операторы CREATE SCHEMA и DROP SCHEMA реализованы в очень немногих СУБД. В других реализациях, например, в СУБД MS SQL Server, используется оператор CREATE DATABASE .
Создание базы данных в среде MS SQL Server
Процесс создания базы данных в системе SQL-сервера состоит из двух этапов: сначала организуется сама база данных , а затем принадлежащий ей журнал транзакций . Информация размещается в соответствующих файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf . (для журнала транзакций ). В файле базы данных записываются сведения об основных объектах ( таблицах , индексах , представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль целостности данных, состояния базы данных до и после выполнения транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE . Следует отметить, что процедура создания базы данных в SQL-сервере требует наличия прав администратора сервера.
Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими правилами именования объектов. Если имя базы данных содержит пробелы или любые другие недопустимые символы, оно заключается в ограничители (двойные кавычки или квадратные скобки). Имя базы данных должно быть уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который будет для нее создан, изменить имя, путь и исходный размер этого файла. Если в процессе использования базы данных планируется ее размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf . В этом случае основная информация о базе данных располагается в первичном ( PRIMARY ) файле, а при нехватке для него свободного места добавляемая информация будет размещаться во вторичном файле . Подход, используемый в SQL-сервере, позволяет распределять содержимое базы данных по нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения информации, хранящейся в базе данных .
Параметр PRIMARY определяет первичный файл . Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций . Имя файла для журнала транзакций генерируется на основе имени базы данных , и в конце к нему добавляются символы _log .
При создании базы данных можно определить набор файлов, из которых она будет состоять. Файл определяется с помощью следующей конструкции:
Здесь логическое имя файла – это имя файла, под которым он будет опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и названия соответствующего физического файла, который будет создан на жестком диске. Это имя останется за файлом на уровне операционной системы.
Параметр SIZE определяет первоначальный размер файла; минимальный размер параметра – 512 Кб, если он не указан, по умолчанию принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных . При значении параметра UNLIMITED максимальный размер базы данных ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический рост ее размера (это определяется параметром FILEGROWTH ) и указать приращение с помощью абсолютной величины в Мб или процентным соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
Пример 3.1. Создать базу данных , причем для данных определить три файла на диске C, для журнала транзакций – два файла на диске C.
Изменение базы данных
Большинство действий по изменению конфигурации базы данных выполняется с помощью следующей конструкции:
Как видно из синтаксиса, за один вызов команды может быть изменено не более одного параметра конфигурации базы данных . Если необходимо выполнить несколько изменений, придется разбить процесс на ряд отдельных шагов.
В базу данных можно добавить ( ADD ) новые файлы данных (в указанную группу файлов или в группу, принятую по умолчанию) или файлы журнала транзакций .
Параметры файлов и групп файлов можно изменять ( MODIFY ).
Для удаления из базы данных файлов или групп файлов используется параметр REMOVE . Однако удаление файла возможно лишь при условии его освобождения от данных. В противном случае сервер не разрешит удаление.
В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE – в группе файлов разрешаются изменения; DEFAULT – указанная группа файлов принимается по умолчанию.
Удаление базы данных
Удаление базы данных осуществляется командой:
Удаляются все содержащиеся в базе данных объекты, а также файлы, в которых она размещается. Для исполнения операции удаления базы данных пользователь должен обладать соответствующими правами.
Сегодняшний материал, как я уже сказал, ориентирован на начинающих программистов, которые хотят научиться работать с Microsoft SQL Server. Поэтому я и буду исходить из того, что Вам нужно создать базу данных для обучения, т.е. основной посыл этой статьи направлен на то, чтобы тот, кто хочет создать базу данных в Microsoft SQL Server, после прочтения статьи четко знал, что ему для этого нужно сделать.
Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
В данном разделе я представлю своего рода этапы создания базы данных в Microsoft SQL Server, т.е. это как раз то, что Вы должны знать и что у Вас должно быть, для того чтобы создать базу данных:
- У Вас должна быть установлена СУБД Microsoft SQL Server. Для обучения идеально подходит бесплатная редакция Microsoft SQL Server Express. Если Вы еще не установили SQL сервер, то вот подробная видео-инструкция, там я показываю, как установить Microsoft SQL Server 2017 в редакции Express;
- У Вас должна быть установлена среда SQL Server Management Studio (SSMS). SSMS – это основной инструмент, с помощью которого осуществляется разработка баз данных в Microsoft SQL Server. Эта среда бесплатная, если ее у Вас нет, то в вышеупомянутой видео-инструкции я также показываю и установку этой среды;
- Спроектировать базу данных. Перед тем как переходить к созданию базы данных, Вы должны ее спроектировать, т.е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
- Создать пустую базу данных. В среде SQL Server Management Studio создать базу данных можно двумя способами: первый — с помощью графического интерфейса, второй — с помощью языка T-SQL;
- Создать таблицы в базе данных. К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
- Наполнить БД данными. В базе данных уже есть таблицы, но они пусты, поэтому сейчас уже можно переходить к добавлению данных в таблицы;
- Создать другие объекты базы данных. У Вас уже есть и база данных, и таблицы, и данные, поэтому можно разрабатывать другие объекты БД, такие как: представления, функции, процедуры, триггеры, с помощью которых реализуется бизнес-правила и логика приложения.
Вот это общий план создания базы данных, который Вы должны знать, перед тем как начинать свое знакомство с Microsoft SQL Server и языком T-SQL.
В этой статье мы рассмотрим этап 4, это создание пустой базы данных, будут рассмотрены оба способа создания базы данных: и с помощью графического интерфейса, и с помощью языка T-SQL. Первые три этапа Вы должны уже сделать, т.е. у Вас уже есть установленный SQL Server и среда Management Studio, и примерная структура базы данных, которую Вы хотите реализовать, как я уже сказал, на этапе обучения этот пункт можно пропустить, а в следующих материалах я покажу, как создавать таблицы в Microsoft SQL Server пусть с простой, но с более-менее реальной структурой.
Создание базы данных в SQL Server Management Studio
Первое, что Вам нужно сделать, это запустить среду SQL Server Management Studio и подключиться к SQL серверу.
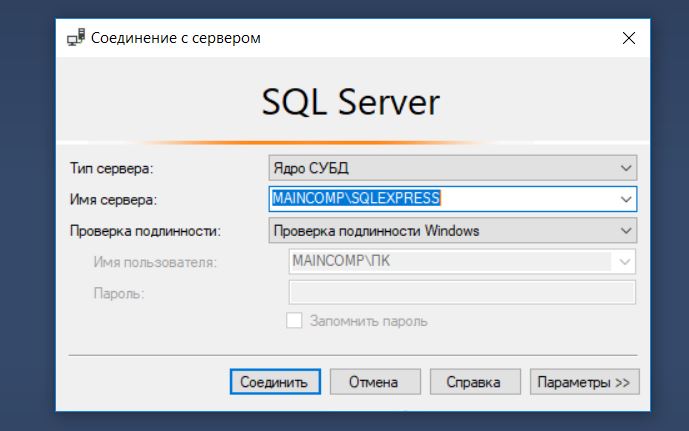
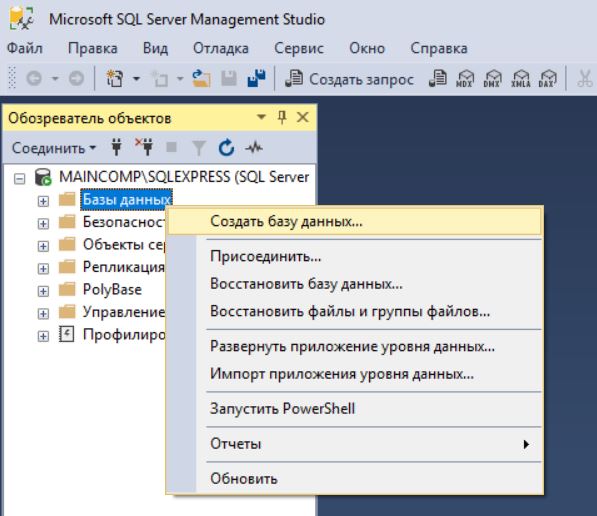
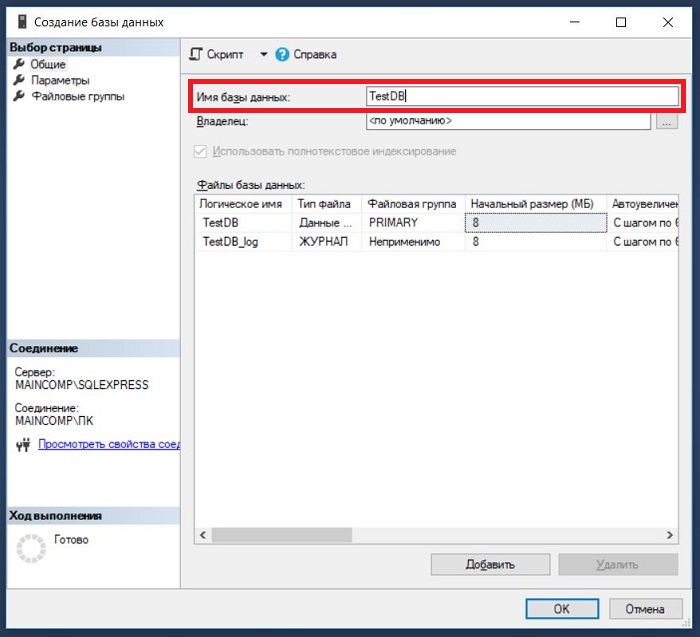
Если БД с таким именем на сервере еще нет, то она будет создана, в обозревателе объектов она сразу отобразится.
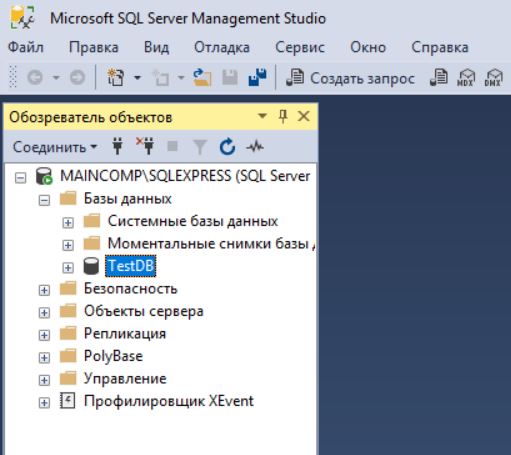
Как видите, база данных создана, и в этом нет ничего сложного.
Создание базы данных на T-SQL (CREATE DATABASE)
Процесс создания базы данных на языке T-SQL, наверное, еще проще, так как для того чтобы создать БД с настройками по умолчанию (как мы это сделали чуть выше), необходимо написать всего три слова в редакторе SQL запросов – инструкцию CREATE DATABASE и название БД.
Где CREATE – это команда языка T-SQL для создания объектов на SQL сервере, командой DATABASE мы указываем, что хотим создать базу данных, а TestDB — это имя новой базы данных.
С помощью инструкции CREATE DATABASE можно задать абсолютно все параметры, которые отображались у нас в графическом интерфейсе SSMS. Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.

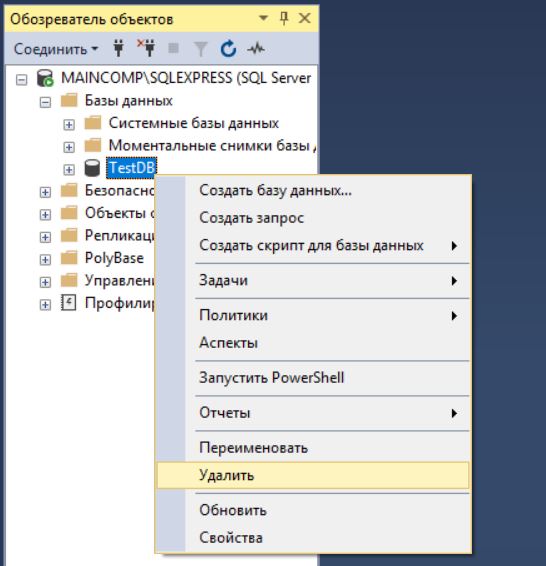
Удаление базы данных в Microsoft SQL Server
В случае необходимости можно удалить базу данных. В реальности, конечно же, такое редко будет требоваться, но в процессе обучения, может быть, и часто. Это можно сделать также, как с помощью графического интерфейса, так и с помощью языка T-SQL.
Примечание! Удалить базу данных возможно, только если к ней нет никаких подключений, т.е. в ней никто не работает, даже Ваш собственный контекст подключения в SSMS должен быть настроен на другую БД (например, с помощью команды USE). Поэтому предварительно перед удалением необходимо попросить всех завершить сеансы работы с БД, или в случае с тестовыми базами данных принудительно закрыть все соединения.
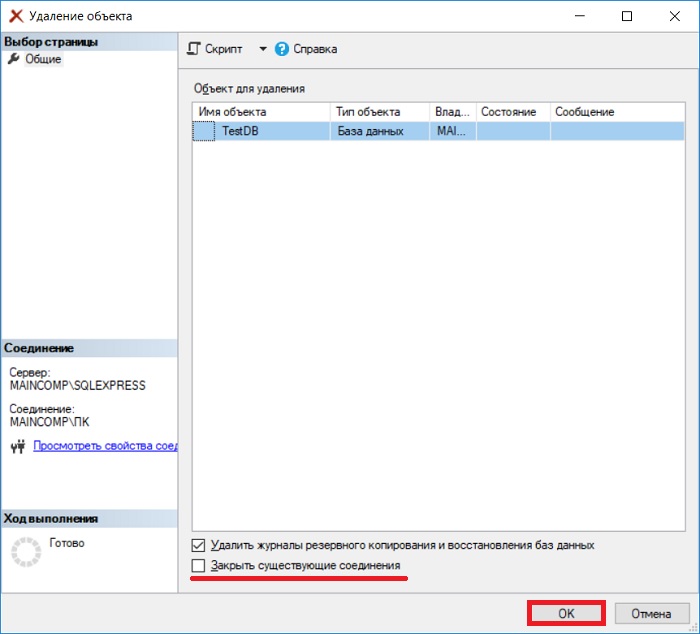
В случае с T-SQL, для удаления базы данных достаточно написать следующую инструкцию (в БД также никто не должен работать).
Где DROP DATABASE — это инструкция для удаления базы данных, TestDB – имя базы данных. Иными словами, командой DROP объекты на SQL сервере удаляются.
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
Видео-урок по созданию базы данных в Microsoft SQL Server
На этом наш сегодняшний урок закончен, надеюсь, материал был Вам интересен и полезен, в следующем материале я расскажу про то, как создавать таблицы в Microsoft SQL Server, удачи Вам, пока!
Читайте также: