
Возможности систем распознавания текстов кратко
Обновлено: 04.07.2024
Любая сканированная информации представляет собой графический файл (картинку). Следовательно, отсканированный текст невозможно редактировать без специального перевода в текстовый формат. Этот перевод можно осуществить с помощью систем оптического распознавания символов (optical character recognition – OCR).
Для получения электронной (готовой к редактированию) копии печатного документа, программе OCR необходимо выполнить ряд операций, среди которых можно выделить следующие:
2. Распознавание – текст переводится из графической формы в обычную текстовую.
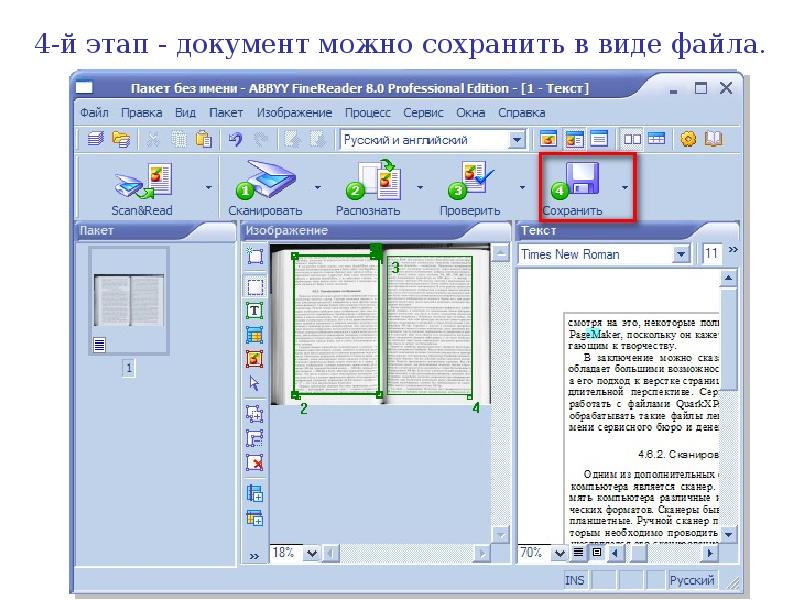
4. Сохранение – запись распознанного документа в файл нужного формата для дальнейшего редактирования в соответствующей программе.
Перечисленные выше операции в большинстве OCR-систем могут выполняться как в автоматическом (с помощью программы-мастера), так и в ручном режиме (по отдельности).
Современные OCR-системы распознают тексты, набранные различными шрифтами; корректно работают с текстами, содержащими слова на нескольких языках; распознают таблицы и рисунки; позволяют сохранять результат в файле текстового или табличного формата и др.
В качестве примера OCR-систем можно привести CuneiForm от фирмы Cognitive и FineReader от ABBYY Software.
OCR-системаFineReader выпускается в различных версиях (Sprint, Home Edition, Professional Edition, Corporate Edition, Office) и все они, от самой простой до самой мощной имеют очень удобный интерфейс, а также (в зависимости от модификации) имеют ряд достоинств, которые выделяют их среди аналогичных программ.
Например, FineReader Professional Edition (FineReader Pro) обладает следующими функциональными возможностями:
§ поддерживает почти двести языков (даже древние языки и популярные языки программирования);
§ распознает графику, таблицы, документы на бланках и т.п.;
§ полностью сохраняет все особенности форматирования документов и их графическое оформление;
§ позволяет сохранить полученный текст в одном из множества популярных форматах (от документов Microsoft Office до HTML или PDF);
Любая сканированная информации представляет собой графический файл (картинку). Следовательно, отсканированный текст невозможно редактировать без специального перевода в текстовый формат. Этот перевод можно осуществить с помощью систем оптического распознавания символов (optical character recognition – OCR).
Для получения электронной (готовой к редактированию) копии печатного документа, программе OCR необходимо выполнить ряд операций, среди которых можно выделить следующие:
2. Распознавание – текст переводится из графической формы в обычную текстовую.
4. Сохранение – запись распознанного документа в файл нужного формата для дальнейшего редактирования в соответствующей программе.
Перечисленные выше операции в большинстве OCR-систем могут выполняться как в автоматическом (с помощью программы-мастера), так и в ручном режиме (по отдельности).
Современные OCR-системы распознают тексты, набранные различными шрифтами; корректно работают с текстами, содержащими слова на нескольких языках; распознают таблицы и рисунки; позволяют сохранять результат в файле текстового или табличного формата и др.

В качестве примера OCR-систем можно привести CuneiForm от фирмы Cognitive и FineReader от ABBYY Software.
OCR-системаFineReader выпускается в различных версиях (Sprint, Home Edition, Professional Edition, Corporate Edition, Office) и все они, от самой простой до самой мощной имеют очень удобный интерфейс, а также (в зависимости от модификации) имеют ряд достоинств, которые выделяют их среди аналогичных программ.
Например, FineReader Professional Edition (FineReader Pro) обладает следующими функциональными возможностями:
§ поддерживает почти двести языков (даже древние языки и популярные языки программирования);
§ распознает графику, таблицы, документы на бланках и т.п.;
§ полностью сохраняет все особенности форматирования документов и их графическое оформление;
§ позволяет сохранить полученный текст в одном из множества популярных форматах (от документов Microsoft Office до HTML или PDF);

Файл содержит методические указания для выполнения практической работы "Возможности систем распознавания текста". Используется при узучении темы "Способы создания текстовых документов". Этапы работы: сканирование документа, передача документа по локальной сети, работа в программе Fine Reader, форматирование документа в среде MS Word.
Тема: Возможности систем распознавания текстов.
Цель. Изучить возможности и порядок работы с программой распознавания текста Fine Reader.
Оборудование: ЛВС, персональный компьютер, среда MS Word, программа FineReader.
Краткая теория
Процесс ввода текстов в компьютер осуществляется в несколько этапов: сканирование; выделение блоков на изображении; распознавание; проверка ошибок; сохранение результата распознавания (передача его в другое приложение, в буфер и т. п.).
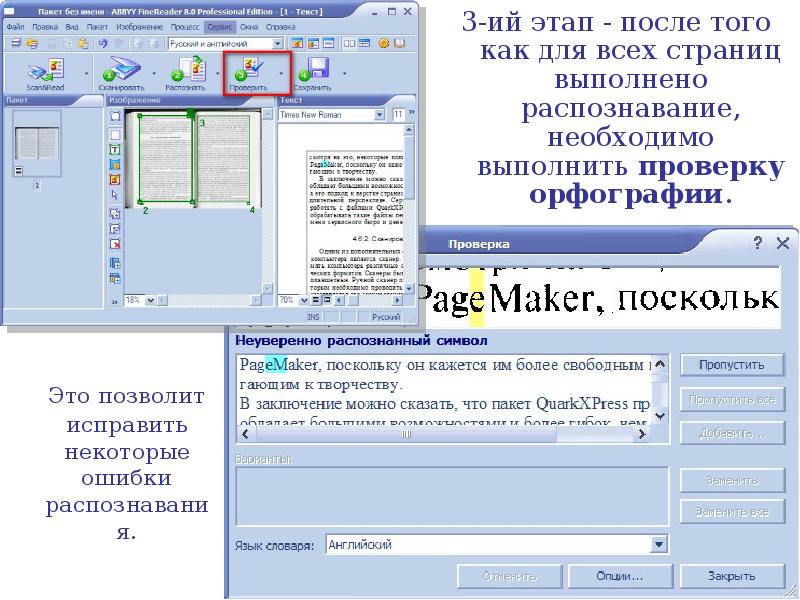
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (или с многостраничными документами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
Fine Reader работает с разными моделями сканеров. В частности, Программа поддерживает стандарт TWAIN.
Порядок выполнения работы
По локальной сети откройте эту папку на вашем компьютере. Скопируйте свой документ в свою папку.
Запустите программу FineReader (Пуск – Программы )
В окне FineReader выполните команду Файл – Открыть изображение, найдите свой документ и откройте его в окне программы FineReader.
Выберите язык для распознавания документа.
Выполните распознавание графического файла, сегментируйте текстовые блоки, таблицы и рисунки.
Выполните проверку отсканированного документа. Ошибки исправляйте в окне Текст или в диалоговом окне Проверка.
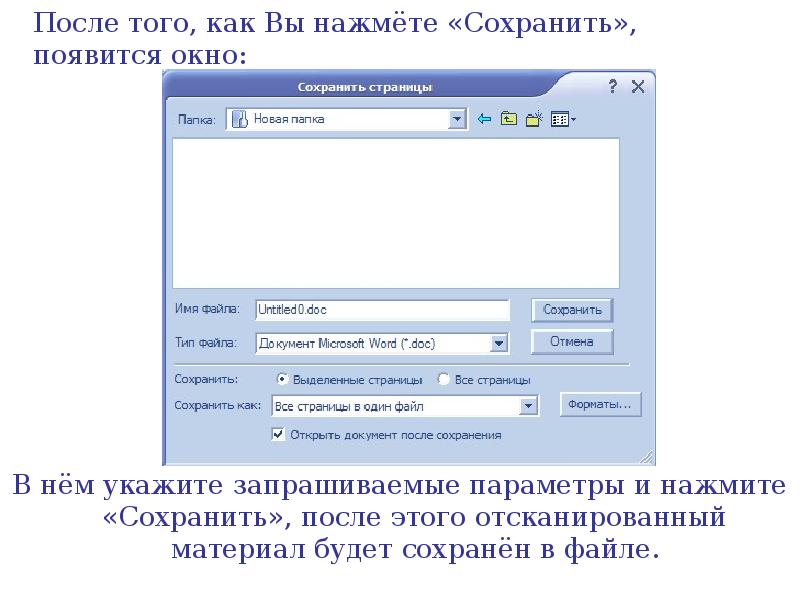
Сохраните отсканированный документ в формате Word .
Задайте параметры страниц документа (вкладка Разметка страницы – группа Параметры страницы): ориентация альбомная, левое поле 1,5 см, правое 1,5 см, верхнее 3см, нижнее 2 см., расстановка переносов Автоматическая. Параметры абзацев: выравнивание по ширине, отступ первой строки 1,5см, интервал перед абзацем 6пт, интервал между строчками 1,15. Для картинки используйте команду Обтекание текстом – по контуру.
В верхний колонтитул запишите дату и номер работы. В нижний колонтитул запишите виши фамилию, имя и группу. В готовый документ запишите тему и цель работы.
Выведите готовый документ на печать.
Контрольные вопросы
Перечислите основные элементы окна программы Fine Reader.
Дайте понятие сегментации изображения.
Как выполняется настройка операций, выполняемых программой Fine Reader?
Вы можете изучить и скачать доклад-презентацию на тему Возможности систем распознавания текстов. Презентация на заданную тему содержит 20 слайдов. Для просмотра воспользуйтесь проигрывателем, если материал оказался полезным для Вас - поделитесь им с друзьями с помощью социальных кнопок и добавьте наш сайт презентаций в закладки!










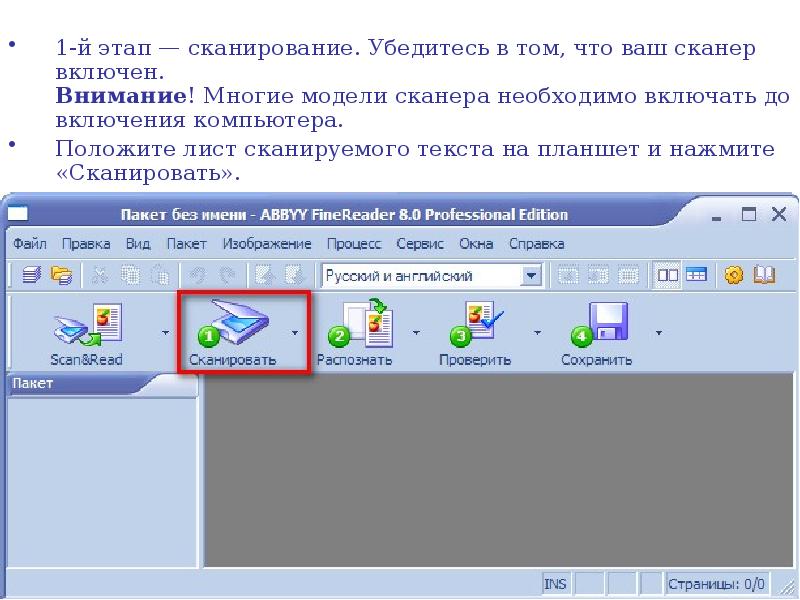





Возможности систем распознавания текстов Задание: письменно ответить на вопросы (последний слайд), фото прислать.
Одним из средств ввода информации в память компьютера является сканер. Одним из средств ввода информации в память компьютера является сканер. Сканеры позволяют вводить в память компьютера различные изображения в виде файлов графических форматов. Обычно при сканировании получают файл форматов JPEG, TIFF, PCX, BMP и др.
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Оно регулируется установкой основных параметров сканирования: Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Оно регулируется установкой основных параметров сканирования: типа изображения, разрешения, яркости.
С помощью сканера можно получить изображение страницы текста в графическом файле. Но работать с таким текстом невозможно: страница с текстом представляет собой обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать картинку в символы. С помощью сканера можно получить изображение страницы текста в графическом файле. Но работать с таким текстом невозможно: страница с текстом представляет собой обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать картинку в символы. Преобразованием графического изображения в текст занимаются специальные программы распознавания текста (Optical Character Recognition - OCR). Наиболее распространенная из них - ABBYY FineReader.
Возможности современных OCR Возможности современных OCR распознавание текста, набранного любым шрифтом, работа с текстами, содержащими слова на нескольких языках, распознавание таблиц, распознавание нечётко набранных текстов, например, текст с пожелтевшей газетной вырезки. сохранять результат в файл, например, Microsoft Word, Excel и т.д.
Одним из козырей FineReader является поддержка неимоверного количества языков распознавания — 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования. Одним из козырей FineReader является поддержка неимоверного количества языков распознавания — 176, в числе которых вы найдете экзотические и древние языки, и даже популярные языки программирования. Но далеко не все возможности включены в самую простую модификацию программы, которую вы можете получить бесплатно вместе со сканером. Пакетное сканирование, грамотная обработка таблиц и изображений — для всего этого стоит приобрести профессиональную версию программы.
FineReader работает со сканерами через FineReader работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт, введенный в 1992 году для унификации взаимодействия устройств для ввода изображений в компьютер (например, сканера) с внешними приложениями.
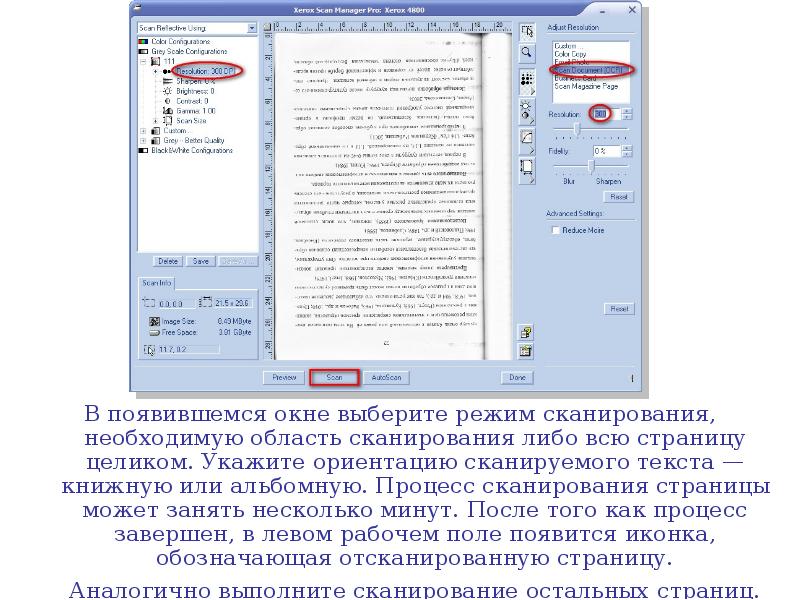
Для распознавания печатных текстов в большинстве случаев достаточно сканировать в чёрно-белом режиме и с разрешением 300 dpi. Для распознавания печатных текстов в большинстве случаев достаточно сканировать в чёрно-белом режиме и с разрешением 300 dpi. Если текст слишком мелкий и при распознавании программа допускает много ошибок, попробуйте увеличить разрешение при сканировании. Помните: при увеличении разрешения время сканирования значительно увеличивается, поэтому без необходимости не сканируйте тексты с разрешением более 300 dpi.
В появившемся окне выберите режим сканирования, необходимую область сканирования либо всю страницу целиком. Укажите ориентацию сканируемого текста — книжную или альбомную. Процесс сканирования страницы может занять несколько минут. После того как процесс завершен, в левом рабочем поле появится иконка, обозначающая отсканированную страницу. В появившемся окне выберите режим сканирования, необходимую область сканирования либо всю страницу целиком. Укажите ориентацию сканируемого текста — книжную или альбомную. Процесс сканирования страницы может занять несколько минут. После того как процесс завершен, в левом рабочем поле появится иконка, обозначающая отсканированную страницу. Аналогично выполните сканирование остальных страниц.
2-й этап — распознавание. Выберите на левом поле страницу, с которой вы будете работать, при этом справа высветится ее отсканированное изображение. Выберите язык распознаваемого текста: русский, русско-английский, английский. Затем необходимо выполнить разбивку текста на блоки. Разбивка может осуществляться автоматически, с помощью встроенной процедуры, либо вручную. Ручная разбивка может потребоваться, если структура текста на странице достаточно сложна — в текст врезаны таблицы, диаграммы, рисунки. После разбивки текста можно приступать собственно к распознаванию. Распознавание производится по блокам и в зависимости от мощности компьютера может занимать от нескольких секунд до нескольких минут. На Рабочем поле уже распознанные страницы отображаются в правой части окна. 2-й этап — распознавание. Выберите на левом поле страницу, с которой вы будете работать, при этом справа высветится ее отсканированное изображение. Выберите язык распознаваемого текста: русский, русско-английский, английский. Затем необходимо выполнить разбивку текста на блоки. Разбивка может осуществляться автоматически, с помощью встроенной процедуры, либо вручную. Ручная разбивка может потребоваться, если структура текста на странице достаточно сложна — в текст врезаны таблицы, диаграммы, рисунки. После разбивки текста можно приступать собственно к распознаванию. Распознавание производится по блокам и в зависимости от мощности компьютера может занимать от нескольких секунд до нескольких минут. На Рабочем поле уже распознанные страницы отображаются в правой части окна.

Пармон Анна Сергеевна Ответственный редактор
Решения с OCR пригодятся не только крупным организациям, но и небольшим компаниям: когда в штате немного людей, каждый из них выполняет сразу несколько задач. Поэтому еще важнее снизить времязатраты на работу с документами как внутри компании, так и вовне: с клиентами, партнерами и поставщиками услуг.
Читайте также:
- Национальное воспитание учащихся старших классов общеобразовательной средней школы
- Психологическая готовность ребенка к школе в доу
- Порядок определения радиоактивного заражения местности кратко
- Особенности формирования и бытования этнокультурных стереотипов кратко
- Рисунок в детский сад на тему пдд светофор