
Реляционная модель и реляционные базы данных основные термины и понятия кратко
Обновлено: 05.07.2024
База данных (БД) – это организованный набор данных. Организация данных обычно призвана отражать реальную взаимосвязь хранимых данных таким образом, чтобы облегчить обработку этой информации.
СУБД – системы управления базами данных – это специализированное ПО, призванное, ожидаемо, управлять базами данных. Достигается это взаимодействием с пользователем с одной стороны и собственно с базой данных с другой.
СУБД общего назначения должна позволять определение, создание, изменение, администрирование и произведение запросов к БД.
В качестве примеров СУБД можно назвать такие широко известные пакеты, как
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Oracle
- IBM DB2
- Microsoft Access
- SQLite
Базы данных обычно не являются переносимыми между различными СУБД, однако возможно взаимодействие между СУБД (и с пользовательским ПО) с использованием различных стандартов, таких, как SQL, ODBC или JDBC.
СУБД часто классифицируются по поддерживаемой ими модели данных. С 1980х годов, практически все популярные СУБД поддерживают реляционную модель данных, представленную стандартом языка запросов SQL (хотя последние годы набирает популярность NoSQL).
Итак, основные задачи, выполняемые СУБД включают
СУБД широко используются в банковском деле, транспортных компаниях, учебных заведениях, телекоммуникациях, для управления финансовой информацией и человеческими ресурсами. Ну и не стоит забывать, что большинство бэкэндов Web использует ту или иную СУБД.
Одной из основных особенностей разработки БД является факт отсутствия готовых решений и алгоритмов. Каждая БД специфична к задаче, для которой она проектируется. Это отличает разработку БД от разработки типовых приложений, для которых алгоритмы и шаблоны проектирования разработаны уже давно и придумывать особо ничего не приходится. Хотя, безусловно, приемы проектирования БД общие для всех применений.
Как уже говорилось ранее, наиболее широко распространенной моделью данных является реляционная модель. Однако появлению реляционной модели предшествовали другие, в частности
- Иерархическая, или навигационная модель
- Сетевая модель
Иерархическая модель широко использовалась в СУБД, поставляемых компанией IBM в 1960х. Основная идея заключается в том, что запись в такой БД может иметь несколько “дочерних” и одну “родительскую”. В целом, это подозрительно похоже на иерархическую файловую систему. Чтобы получить запись в такой БД, часто необходим проход по всему дереву.
Сетевая модель – более гибкая версия того же подхода. Она позволяет иметь записи несколько “родительских”. Эта модель, появившись в начале 1970х, не получила широкого распространения, и вскоре была вытеснена реляционной моделью.
В 1970х Эдгаром Коддом (сотрудник IBM) была предложена реляционная модель, которая значительно облегчила задачу поиска информации в БД. О реляционной модели можно думать как о “таблицах”, в которых “строки” – это записи в БД. Записи в реляционной БД так же называются кортежами (tuples), а группы записей (“таблицы”) – отношениями (relations). Реляционная модель способна выразить связи иерархической и сетевой моделей, и добавляла собственные связи, соответствующие табличной модели.
На основе предложений Кодда к середине 1970х была разработана СУБД System R, а к концу в ней появилась поддержка стандартизованного языка запросов SQL.
В 1980х, с появлением объектно-ориентированного программирования, все чаще возникали сложности в трансляции объектов на реляционную модель. В конце концов это привело к появлению подходов NoSQL и NewSQL, которые на текущий момент только развиваются. Примерами реализации NoSQL подхода могут быть т.н. документо-ориентированные БД, построенные на основе XML. Основное преимущество NoSQL – высокая горизонтальная масштабируемость, т.е. возможность увеличивать производительность за счет добавления серверов. С появлением облачных технологий, NoSQL стал особенно востребован.
Тем не менее, реляционная модель пока остается самой распространенной, поэтому более подробно остановимся именно на ней.
Реляционная модель оперирует понятиями записей, атрибутов и отношений. Отношение можно представить себе в виде двумерной таблицы, тогда атрибуты – это столбцы таблицы (точнее, названия столбцов), а записи – строки таблицы.
Реляционная модель требует строгого определения структуры данных, хранимых в БД, то есть отношения и атрибуты для данной БД фиксированы.
Введем некоторые определения.
Домен Множество, содержащее полный набор всех возможных значений некоторой переменной. Домены часто так же называют типом данных. Атрибут Упорядоченная пара названия атрибута и домена \(D_j\) . Кортеж Конечное упорядоченное множество \((d_1, d_2, \ldots, d_n)\) Заголовок (схема) отношения Кортеж \((A_1, A_2, \ldots, A_n)\) , где \(A_j\) – атрибуты. Значение атрибута Конкретное значение, принадлежащее домену атрибута. Тело отношения Множество кортежей \((d^i_1, d^i_2, \ldots, d^i_n)\) , где \(d^i_j \in D_j\) , \(D_j\) – домены. Запись Кортеж \((d^i_1, d^i_2, \ldots, d^i_n)\) при фиксированном \(i\) . Отношение Совокупность заголовка отношения и тела отношения. Схема базы данных Множество схем всех отношений, входящих в БД.
Можно представить отношение в виде таблицы. Тогда тело отношения – это тело таблицы, заголовок отношения – заголовок таблицы, атрибуты – названия столбцов, записи – строки, а значения атрибутов находятся в ячейках:
| \(A_1\) | \(A_2\) | \(\ldots\) | \(A_n\) | ← Заголовок |
|---|---|---|---|---|
| \(d^1_1\) | \(d^1_2\) | \(\ldots\) | \(d^1_n\) | ← Запись |
| \(d^2_1\) | \(d^2_2\) | \(\ldots\) | \(d^2_n\) | ← Запись |
| \(\ldots\) | \(\ldots\) | \(\ldots\) | \(\ldots\) | ← Запись |
| \(d^m_1\) | \(d^m_2\) | \(\ldots\) | \(d^m_n\) | ← Запись |
Реляционная модель налагает следующие дополнительные требования на отношения:
- Атрибуты имеют фиксированный тип данных (домен)
- Значения атрибутов атомарны 1
- Записи уникальны
- Порядок записей не имеет значения (нет скрытых атрибутов)
- Порядок атрибутов не имеет значения (нет скрытых зависимостей атрибутов)
Ясно, что атрибуты (точнее, их значения) каким-то образом зависят друг от друга – иначе отношение оказывается просто неструктурированным набором данных. Для определения зависимостей между атрибутами используется понятие функциональной зависимости.
Функциональная зависимость множество атрибутов \(B\) функционально зависит от множества атрибутов \(A\) (записывается \(A\rightarrow B\) ), если для любых двух записей, имеющих одинаковые значения \(A\) , их значения \(B\) совпадают. Иначе, каждому значению \(A\) соответствует единственное значение \(B\) (не обязательно уникальное, именно единственное).
Иными словами, если некоторый набор атрибутов \(A\) однозначно определяет (в рамках данного отношения) значения атрибутов \(B\) , то \(B\) функционально зависит от \(A\) .
В качестве более привычного примера функциональной зависимости, можно привести математическое определение функции. Для функции, каждому значению аргументов соответсвтует единственное значение функции. Обратное в общем случае неверно, например, для функции \(y = sin(x)\) любому значению \(y\) из области определения \(1\geq y \geq -1\) соответствует бесконечное множество значений \(x\) , но для каждого значения \(x\) есть ровно одно значение \(y\) , т.о. \(x \to y\) . Заметим, что понятие функциональной зависимости так же применимо и к функциям многих переменных. Для них, значение функции функционально зависит от всех аргументов одновременно. Скажем, для функции \(z = f(x,y)\) выполняется ФЗ \((x,y)\to z\) , или сокращенно, \(xy\to z\) .
Отношения в данном контексте можно рассматривать как некие табличные или дискретные функции.
Существуют определенные формальные правила работы с ФЗ отношения.
Формальные правила тесно связаны с понятиями замыкания и неприводимой ФЗ.
Аксиомы Армстронга
Существуют правила вывода новых ФЗ из существующих, называемые аксиомами Армстронга.
- Правило рефлексивности: если \(B \subset A\) , то \(A\rightarrow B\)
- Правило дополнения: если \(A\rightarrow B\) , то \(AC\rightarrow BC\)
- Правило транзитивности: если \(A\rightarrow B\) и \(B\rightarrow C\) , то \(A\rightarrow C\)
Из этих аксиом так же могут быть выведены следующие дополнительные правила:
- Правило самоопределения: \(A\rightarrow A\)
- Правило декомпозиции: Если \(A\rightarrow BC\) , то \(A\rightarrow B\) и \(A\rightarrow C\)
- Правило объединения: Если \(A\rightarrow B\) и \(A\rightarrow C\) , то \(A\rightarrow BC\)
- Правило композиции: Если \(A\rightarrow B\) и \(C\rightarrow D\) , то \(AC\rightarrow BD\)
Можно заметить, что, вследствие правила рефлексивности, любое множество атрибутов \(A\) подразумевает ФЗ вида \(A\to A\) . Такие ФЗ, а так же следующие из них, не представляют интереса, и называются тривиальными.
Тривиальная функиональная зависимость ФЗ \(A \to B\) , такая, что \(B \subset A\) .
В принципе, этих правил достаточно для того, чтобы найти все ФЗ, следующие из данных. В связи с этим вводится понятие замыкания множества ФЗ.
Замыкание множества ФЗ Замыканием множества ФЗ называется такое множество ФЗ, которое включает все ФЗ исходного множества, а так же все подразумеваемые ими. Другими словами, для отношения \(R\) , обладающего функциональными зависимостями \(S\) , замыканием \(S^+\) называется множество всех ФЗ, возможных для \(R\) , исходя из \(S\) .
Как правило, требуется установить, будет ли некая ФЗ \(X\rightarrow Y\) следовать из данного множества ФЗ \(S\) . Оказывается, это возможно тогда и только тогда, когда множество атрибутов \(Y\) является подмножеством замыкания атрибутов \(X^+\) в \(S\) .
Замыкание атрибутов Замыканием \(X^+\) атрибутов \(X\) по множеству ФЗ \(S\) называется множество всех атрибутов, которые функционально зависят от какого-либо подмножества \(X\) .
Для вычисления замыкания множества атрибутов \(X^+\) по множеству ФЗ \(S\) существует следующее правило: для каждой ФЗ \(A\rightarrow B\) в \(S\) , если \(A \subset X^+\) , то и \(B \subset X^+\) , причем достаточно начать с предположения, что \(X^+ = X\) .
Следует заметить, что для любого замыкания \(X^+\) , существуют ФЗ вида \(X \to B\) , где \(B \subset X^+\) , таким образом, замыкания всех атрибутов отношения по его ФЗ описывают замыкание ФЗ этого отношения.
Это правило используется для вычисления неприводимого множества ФЗ, эквивалентного данному (в смысле эквивалентности их замыканий). Уменьшение количества ФЗ при сохранении замыкания (и, следовательно, внутренней логики, описываемой ФЗ) является важным шагом в проектировании БД.
Множество ФЗ называется неприводимым, если:
- Правая часть каждой ФЗ содержит только один элемент
- Ни один атрибут ни одной левой части ФЗ множества не может быть удален без изменения замыкания
- Ни одна ФЗ множества не может быть удалена без изменения замыкания.
Для любого множества ФЗ существует хотя бы одно эквивалентное неприводимое множество. Такое множество называется минимальным покрытием.
Под атомарностью в данном случае имеется ввиду неделимость. Иными словами, значения атрибутов не могут являться множествами.↩︎
В этом курсе, главным образом, обсуждаются различные аспекты реляционных баз данных. Принято считать, что реляционный подход к организации баз данных был заложен в конце 1960-х гг. Эдгаром Коддом [2.1]. В последние десятилетия этот подход является наиболее распространенным (с оговоркой, что в называемых в обиходе реляционными системах баз данных, основанных на языке SQL, в действительности нарушаются некоторые важные принципы классического реляционного подхода). Достоинствами реляционного подхода принято считать следующие свойства: реляционный подход основывается на небольшом числе интуитивно понятных абстракций, на основе которых возможно простое моделирование наиболее распространенных предметных областей; эти абстракции могут быть точно и формально определены; теоретическим базисом реляционного подхода к организации баз данных служит простой и мощный математический аппарат теории множеств и математической логики; реляционный подход обеспечивает возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Компьютерный мир далеко не сразу признал реляционные системы. В 70-е года прошлого века, когда уже были получены почти все основные теоретические результаты и даже существовали первые прототипы реляционных СУБД, многие авторитетные специалисты отрицали возможность добиться эффективной реализации таких систем. Однако преимущества реляционного подхода и развитие методов и алгоритмов организации и управления реляционными базами данных привели к тому, что к концу 80-х годов реляционные системы заняли на мировом рынке СУБД доминирующее положение. В этой лекции на сравнительно неформальном уровне вводятся основные понятия реляционных баз данных, а также определяется сущность реляционной модели данных. Основной целью лекции является демонстрация простоты и возможности интуитивной интерпретации этих понятий. В следующих лекциях будут приводиться более формальные определения, на которых основана теория реляционных баз данных.
3.2. Основные понятия реляционных баз данных
Выделим следующие основные понятия реляционных баз данных: тип данных, домен, атрибут, кортеж, отношение, первичный ключ.
Для начала покажем смысл этих понятий на примере отношения СЛУЖАЩИЕ, содержащего информацию о служащих некоторого предприятия (рис. 3.1).
Рис. 3.1. Соотношение основных понятий реляционного подхода
3.2.1. Тип данных
Значения данных, хранимые в реляционной базе данных, являются типизированными, т. е. известен тип каждого хранимого значения. Понятие типа данных в реляционной модели данных полностью соответствует понятию типа данных в языках программирования. Напомним, что традиционное (нестрогое) определение типа данных состоит из трех основных компонентов: определение множества значений данного типа; определение набора операций, применимых к значениям типа; определение способа внешнего представления значений типа (литералов).
3.2.2. Домен
Наиболее правильной интуитивной трактовкой понятия домена является его восприятие как допустимого потенциального, ограниченного подмножества значений данного типа. Например, домен ИМЕНА в нашем примере определен на базовом типе символьных строк, но в число его значений могут входить только те строки, которые могут представлять имена (в частности, для возможности представления русских имен такие строки не могут начинаться с мягкого или твердого знака и не могут быть длиннее, например, 20 символов). Если некоторый атрибут отношения определяется на некотором домене (как, например, на рис. 3.1 атрибут СЛУ_ИМЯ определяется на домене ИМЕНА ), то в дальнейшем ограничение домена играет роль ограничения целостности, накладываемого на значения этого атрибута.
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов НОМЕРА ПРОПУСКОВ и НОМЕРА ОТДЕЛОВ относятся к типу целых чисел, но не являются сравнимыми (допускать их сравнение было бы бессмысленно).
3.2.3. Заголовок отношения, кортеж, тело отношения, значение отношения, переменная отношения
Понятие отношения является наиболее фундаментальным в реляционном подходе к организации баз данных, поскольку n -арное отношение является единственной родовой структурой данных, хранящихся в реляционной базе данных. Это отражено и в общем названии подхода – термин реляционный (relational) происходит от relation (отношение). Однако сам термин отношение является исключительно неточным, поскольку, говоря про любые сохраняемые данные, мы должны иметь в виду тип этих данных, значения этого типа и переменные, в которых сохраняются значения. Соответственно, для уточнения термина отношение выделяются понятия заголовка отношения, значения отношения и переменной отношения. Кроме того, нам потребуется вспомогательное понятие кортежа.
Если все атрибуты заголовка отношения определены на разных доменах, то, чтобы не плодить лишних имен, разумно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это всего лишь удобный способ именования, который не устраняет различия между понятиями домена и атрибута).
Телом Br отношения r называется произвольное множество кортежей tr . Одно из возможных тел отношения СЛУЖАЩИЕ показано на рис. 3.1. Заметим, что в общем случае, как это демонстрируют, в частности, рис. 3.1 и пример предыдущего абзаца, могут существовать такие кортежи tr , которые соответствуют Hr , но не входят в Br .
Значением Vr отношения r называется пара множеств Hr и Br . Одно из допустимых значений отношения СЛУЖАЩИЕ показано на рис. 3.1.
В изменчивой реляционной базе данных хранятся отношения, значения которых изменяются во времени. Переменной VARr называется именованный контейнер, который может содержать любое допустимое значение Vr . Естественно, что при определении любой VARr требуется указывать соответствующий заголовок отношения Hr .
Здесь стоит подчеркнуть, что любая принятая на практике операция обновления базы данных – INSERT (вставка кортежа в переменную отношения), DELETE (удаление кортежа из значения-отношения переменой отношения) и UPDATE (модификация кортежа значения-отношения переменной отношения) – с модельной точки зрения является операцией присваивания переменной отношения некоторого нового значения-отношения. Это совсем не означает, что перечисленные операции должны выполняться именно таким образом в СУБД: главное, чтобы результат операций соответствовал этой модельной семантике.
Заметим, что в дальнейшем в тех случаях, когда точный смысл термина понятен из контекста, мы будем использовать термин отношение как в смысле значение отношения, так и в смысле переменная отношения.
При приведенных определениях разумно считать схемой реляционной базы данных набор пар , включающий имена и заголовки всех переменных отношения, которые определены в базе данных. Реляционная база данных – это набор пар (конечно, каждая переменная отношения в любой момент времени содержит некоторое значение-отношение, в частности, пустое).
Заметим, что в классических реляционных базах данных после определения схемы базы данных могли изменяться только значения переменных отношений. Однако теперь в большинстве реализаций допускается и изменение схемы базы данных: определение новых и изменение заголовков существующих переменных отношений. Это принято называть эволюцией схемы базы данных.
3.2.4. Первичный ключ и интуитивная интерпретация реляционных понятий
По определению, первичным ключом переменной отношения является такое подмножество 5) S множества атрибутов ее заголовка, что в любое время значение первичного ключа (составное, если в состав первичного ключа входит более одного атрибута) в любом кортеже тела отношения отличается от значения первичного ключа в любом другом кортеже тела этого отношения, а никакое собственное подмножество 6) S этим свойством не обладает. В следующем разделе мы покажем, что существование первичного ключа у любого значения отношения является следствием одного из фундаментальных свойств отношений, а именно того свойства, что тело отношения является множеством кортежей.
5 В вырожденном случае, когда заголовок переменной отношения является пустым множеством, первичный ключ этой переменной отношения состоит из пустого подмножества заголовка. Легко проверить, что этот случай не противоречит общему определению.
6 Напомним, что S’ является собственным подмножеством множества S в том и только в том случае, когда S’ входит в S , но не совпадает с S (это обозначается как S’ S ).
Реляционная база данных (БД) — это совокупность связанных между собой двумерных таблиц, в которых хранится информация об объектах. Запись (строка) включает в себя данные об одном объекте, а в полях (столбцах) содержатся различные его характеристики. Основы теории табличной модели впервые были описаны Эдгаром Коддом (IBM) в 1970 году.
Особенности реляционных БД
БД используются для организации хранения данных. Структура реляционной базы данных полностью определяется перечнем названия полей с указанием их типов и свойств. Все записи имеют одинаковые поля, но в них показываются разные свойства объекта. Аналогом реляционной БД считается двумерная таблица. Характерные особенности файла БД:
- Уникальное имя для каждой таблицы.
- Фиксированное число полей.
- На пересечении строки и столбца всегда есть только одно значение.
- Записи отличаются друг от друга хотя бы одним значением элемента.
- Полям присваиваются индивидуальные имена.
- В каждый из столбцов необходимо вставлять однородные данные: целые числа, даты, суммы, имена или фамилии, названия предметов.
- дублирование информации (вид устройства повторяется для разных клиентов), что увеличивает объём БД;
- для обновления информации требуется обрабатывать каждую запись.
Для устранения этих недостатков необходима нормализация с разделением данных на разные таблицы.
Связывание таблиц
Для любой таблицы реляционной БД задаётся первичный ключ (primary key) — поле или сочетание полей, которые определяют каждую запись. Внешний или вторичный ключ (foreign key) — это одно или несколько полей, ссылающихся на поле primary key другой таблицы.

Ячейка — это наименьший структурный элемент, который задаёт определённое значение соответствующего поля. Таблицы связываются друг с другом, и поэтому данные могут выбираться сразу из нескольких таблиц. Связь создаётся, если в них присутствуют одинаковые поля. Типы связей:
- один к одному;
- один ко многим;
- многие ко многим.
- структурный — данные в базе рассматриваются как набор отношений, то есть упорядоченных пар, составленных из заголовка и полей;
- целостности — состоит в проверке правильности согласования данных при обновлении;
- обработки — использование операторов манипулирования таблицами, таких как реляционная алгебра и реляционное исчисление, которые генерируют новые таблицы на основании уже имеющихся.
Управление созданием и использованием БД осуществляется системами управления базами данных (СУБД).
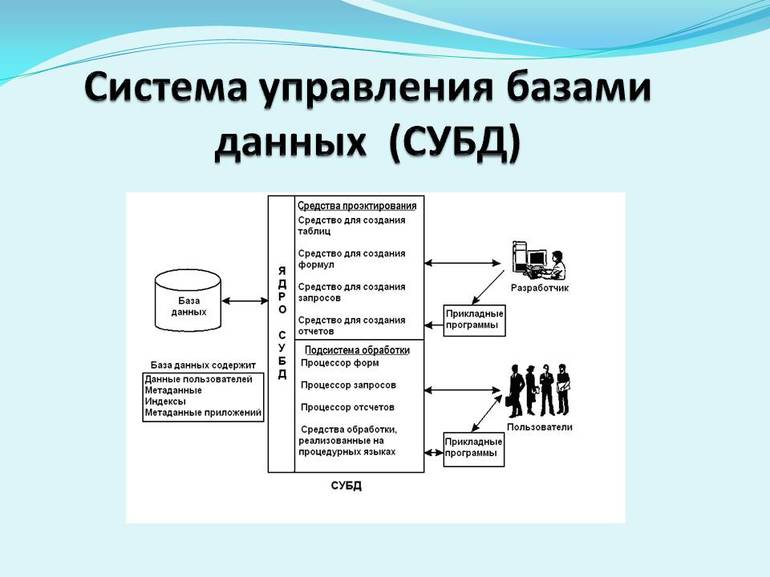
Под их руководством:
- производится добавление, определение, удаление и поиск записей;
- изменяются значения полей.
Для проведения этих операций организуются запросы. Итогом выполнения запросов будут либо изменения в таблицах, либо получение таблицы данных. При этом поддерживается принцип безопасности информации. Для реляционной БД основным языком управления является SQL.
Стадии и пример проектирования хранилища
Приступая к созданию базы, разработчик составляет для объектов манипулирования и их связей представление в терминах реляционной БД (таблицы, поля, записи). Проектирование проходит несколько стадий:

- Первая стадия — это анализ требований. Разработчик должен разрешить главные проблемы: какие элементы данных будут содержаться, как и кто должен к ним обращаться.
- В следующей стадии проектируется логическая структура БД.
- В завершающей стадии проектирования логическая структура БД трансформируется в физическую. Элементы данных определяются как табличные столбцы.
Преимущества этой модели данных состоят в том, что информация отображается в удобной для пользователя форме, а для манипуляций используется развитой математический аппарат.
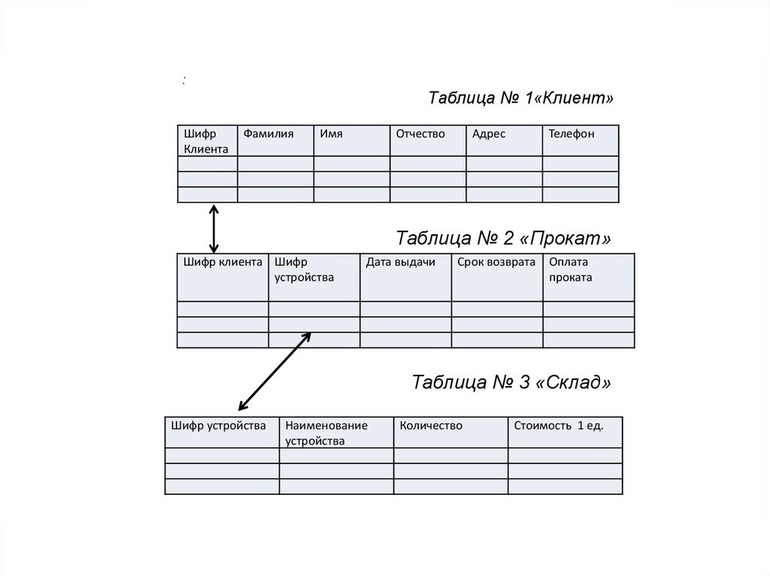
Примером реляционной базы данных может послужить проект оптимизации деятельности пункта проката. Требуется автоматизировать такие процедуры: учёт клиентов; регистрацию инвентаря, выданного в прокат; отслеживание даты выдачи, сроков возврата, оплаты; получение информации по этим позициям; формирование отчёта по задолженностям. Реляционная БД может быть задана в виде трёх связанных таблиц.
Используя имеющиеся данные, следует определить отношения и объекты этих отношений. Объектами будут являться клиенты и устройства. Отношения между ними состоят в том, что каждый клиент может брать в прокат одно или несколько устройств.
Проблемы модели
Преимущество реляционных хранилищ состоит в том, что они способны обеспечить наилучшее соотношение устойчивости, производительности, гибкости, совместимости и масштабируемости. Реляционные БД предоставляют лёгкий доступ к составляемым отчётам и обеспечивают высокую надёжность и целостность информации из-за отсутствия избыточных данных. Но сейчас, когда всё большее количество приложений работает с высокой нагрузкой, увеличивается значение фактора масштабируемости.

Реляционные БД легко масштабируются, только когда они расположены на одном сервере. Если потребуется увеличить количество серверов и разделить нагрузку между ними, то возрастёт сложность хранилищ, что значительно снизит возможность использовать их как платформу для мощных распределённых систем. Поэтому приходится применять другие типы БД, которые обладают лучшей масштабируемостью и отказываться от возможностей, предоставляемых реляционными хранилищами.
Реляционная БД — это совокупность связей, которые способны структурировать данные, что даёт возможность рационального хранения и эффективного использования информационных материалов.
Реляционная модель данных: кем, когда и для чего создана
Реляционная модель данных - созданная Эдгаром Коддом логическая модель данных, описывающая:
- структуры данных в виде (изменяющихся во времени) наборов отношений;
- теоретико-множественные операции над данными: объединение, пересечение разность и декартово произведение;
- специальные реляционные операции: селекция, проекция, соединение и деление;
- специальные правила, обеспечивающие целостность данных.
Реляционная модель данных - это способ рассмотрения данных, то есть предписание для способа представления данных (посредством таблиц) и для способа работы с таким представлением (посредством операторов). Она связана с тремя аспектами данных: структурой (объекты), целостностью и обработкой данных (операторы).
В 2002 журнал Forbes поместил реляционную модель данных в список важнейших инноваций последних 85 лет.
Цели создания реляционной модели данных:
- обеспечение более высокой степени независимости от данных;
- создание прочного фундамента для решения семантических вопросов и проблем непротиворечивости и избыточности данных;
- засширение языков управления данными за счёт включения операций над множествами.
Структура данных в реляционной модели данных
Реляционная модель данных предусматривает структуру данных, обязательными объектами которой являются:
Отношение - это плоская (двумерная) таблица, состоящая из столбцов и строк:
| ID | Фамилия | Имя | Должность | г.р. |
| 1 | Петров | Игорь | Директор | 1968 |
| 2 | Иванов | Олег | Юрист | 1973 |
| 3 | Ким | Елена | Бухгалтер | 1980 |
| 4 | Сенин | Илья | Менеджер | 1981 |
| 5 | Васин | Сергей | Менеджер | 1978 |
Атрибут - это поименованный столбец отношения.
Домен - это набор допустимых значений для одного или нескольких атрибутов.
Кортеж - это строка отношения.
Степень определяется количеством атрибутов, которое оно содержит
Кардинальность - это количество кортежей, которое содержит отношение.
Первичный ключ - это уникальный идентификатор для таблицы.
Соответствие между формальными терминами реляционной модели данных и неформальными:
- отношение (формальный термин) - таблица (неформальный термин);
- атрибут - столбец;
- кортеж - строка или запись;
- степень - количество столбцов;
- кардинальное число - количество строк;
- первичный ключ - уникальный идентификатор;
- домен - общая совокупность допустимых значений.
Отношения и их реализация в реляционной модели данных
Отношение R на множестве доменов D 1 , D 2 , …, D n - это подмножество декартова произведения этих доменов:
Пример 1. Определены домены: D 1 - множество фамилий преподавателей, D 2 - множество аудиторий, D 3 - множество учебных групп, D 4 - множество учебных дисциплин. Записать отношения: 1) закрепление преподавателей за учебными курсами; 2) расписание занятий в группах.
1) закрепление преподавателей за учебными курсами:
Это отношение определяет множество преподавателей, ведущих множество учебных дисциплин.
2) расписание занятий в группах:
Это отношение определяет множество аудиторий, в которых проводятся занятия по множеству учебных дисциплин для множества учебных групп.
Свойства отношений:
- уникальное имя отношения;
- уникальное имя атрибута;
- нет одинаковых кортежей;
- кортежи не упорядочены сверху вниз;
- атрибуты не упорядочены слева направо;
- все значения атрибутов атомарные (нормализованное отношение).
Таким образом, реляционная база данных - это набор нормализованных отношений. Для того, чтобы перейти к видам отношений, введём понятие переменной отношения. Переменная отношения - это именованный объект, значение которого может изменяться с течением времени. Переменная отношения в разное время - это различные таблицы базы данных, у которых разные строки, но одинаковые столбцы.
Виды отношений:
- именованное отношение;
- базовое отношение;
- производное отношение;
- выражаемое отношение;
- представление (view);
- снимки (snapshot);
- результат запроса;
- промежуточный результат.
Именованное отношение - это переменная отношения, определённая в СУБД (системе управления базами данных) посредством оператора CREATE (CREATE TABLE, CREATE BASE RELATION, CREATE VIEW, CREATE SNAPSHOT).
Базовое отношение - это именованное отношение, которое не является производным. Существование базового отношения не зависит от существования других отношений.
Производное отношение - это отношение, которое определено через другие именованные отношения. Производное отношение зависит от существования других - базовых - отношений.
Выражаемое отношение - это отношение, которое можно получить из набора именованных отношений посредством некоторого реляционного выражения. Каждое именованное отношение является выражаемым отношений, но не наоборот. Примеры выражаемых отношений - базовые отношения, представления, снимки, промежуточные и окончательные результаты. Множество всех выражаемых отношений - это множество всех базовых и всех производных отношений.
Представление - это именованное производное отношение. Представлены в базе данных в виде определения. Представление не хранится в физической памяти системы управления базой данных (СУБД), а формируется с использованием других именованных отношений.
Снимки (snapshot) - это то же, что и представление, но с физическим сохранением и с периодическим обновлением.
Результат запроса - это неименованное производное отношение. СУБД не обеспечивает постоянного существования результатов запросов. Для сохранения результата запроса его можно присвоить какому-либо именованному отношению.
Промежуточный результат - это неименованное производное отношение, являющееся результатом подзапроса, вложенного в бОльшее выражение.
Ключи отношения в реляционной модели данных
Ключи отношения могут быть следующми:
- суперключ;
- потенциальный ключ;
- первичный ключ;
- внешний ключ;
- суррогатный ключ.
Ключ отношения - это подсхема исходной схемы отношения, состоящая из одного или нескольких атрибутов, для которых декларируется условие уникальности значений в кортежах отношений. При объявлении схемы базового отношения могут быть заданы объявления нескольких ключей.
Ключ отношения может быть простым или составным. Простой ключ – это ключ, состоящий из одного и не более атрибута. Составной ключ -ключ, состоящий из двух и более атрибутов.
Суперключ - это атрибут или множество атрибутов, которое единственным образом идентифицирует кортеж данного отношения. Он может включать дополнительные атрибуты. Суперключ не обладает свойством неизбыточности.
Потенциальный ключ - это подмножество атрибутов отношения, удовлетворяющее требованиям уникальности и неизбыточности. Он обладает следующими свойствами. Уникальность: в таблице нет двух разных строк с одинаковыми значениями в нашем потенциальном ключе. Неизбыточность: нельзя убрать один из столбцов из ключа, так, чтобы он не потерял уникальности. В отношении может быть больше одного потенциального ключа.
Первичный ключ (primary key, PK) - это один из потенциальных ключей отношения, выбранный в качестве основного ключа. Допустимо объявление одного и только одного первичного ключа. Атрибуты первичного ключа не могут принимать значения Null.
Внешний ключ (foreign key, FK) - это ключ, объявленный в базовом отношении, который при этом ссылается на первичный того же самого или какого-то другого базового отношения.
Суррогатный ключ - это служебный атрибут, добавленный к уже имеющимся информационным атрибутам отношения. Предназначение суррогатного ключа - служить первичным ключом отношения. Значение этого атрибута генерируется искусственно.
Пример 2. Есть база данных сети аптек. В ней есть таблица "Аптеки", в которую занесены все аптеки сети, и есть таблица "Препараты". Кроме того, есть таблица "Наличие", в которую заносятся данные о наличии препаратов в каждой аптеке. В таблице наличие есть поля: "Аптека" (в ней - идентификаторы аптек), "Препарат" (в ней - идентификаторы препаратов), "Количество". Возникает проблема: в случае поступления в аптеку некоторого количества препарата можно не заметить, что в той же аптеке тот же препарат уже содержится в некотором количестве и сделать новую записись в таблице, в которой аптека и препарат будут повторяться. Как на уровне ключей избежать этой проблемы?
Решение. Можно объявить первичным ключём таблицы "Наличие" составной ключ, состоящий из идентификатора аптеки и идентификатора препарата. Тогда в таблице невозможно повторение в разных записях сочетания аптеки и прапарата. Первичный ключ может быть не только простым, но и составным.
Целостность данных в реляционной модели данных
Понятия реляционной целостности:
- определитель NULL;
- целостность сущностей;
- ссылочная целостность;
- корпоративные ограничения целостности.
Целостность сущностей. Требование целостности сущности означает, что первичный ключ должен полностью идентифицировать каждую сущность, а поэтому в составе любого значения первичного ключа не допускается наличие неопределенных значений. Значение атрибута должно быть атомарным.
Ссылочная целостность. Требование целостности по ссылкам состоит в том, что для каждого значения внешнего ключа, появляющегося в кортеже значения-отношения ссылающейся переменной отношения, либо в значении-отношении переменной отношения, на которую указывает ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть полностью неопределенным. Существуют правила удаления кортежа из отношения, на которое ведет ссылка.
Ссылочная целостность: удаление кортежа. Существует три подхода удаления кортежа из отношения, на которое ведет ссылка.
- Ограничение удаления–Delete: Restrict.
- Каскадное удаление–Delete: Cascade.
- Установка значения NULL, перевод значения внешнего ключа в неопределённое состояние – Delete: Set NULL.
Ограничение удаления. Запрещается производить удаление кортежа, для которого существуют ссылки. Сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа.
Каскадное удаление. При удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи.
Установка значения NULL. При удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится полностью неопределенным.
Решение. Первый способ: установить запрет на удаление рубрики или автора из соответствующих таблиц, в случае, если в таблицы "Тексты" есть ссылки на эту рубрику или на этого автора. Второй способ: задать автоматическое удаление из таблицы "Тексты" записей, в которой фигурируют эта рубрика или этот автор. Третий способ: в случае удаления рубрики или автора из соответствующих таблиц в ссылающихся кортежах таблицы "Тексты" значения идентификатора этой рубрики или этого автора становятся неопределёнными (NULL).
Как это делается на уровне языка запросов SQL - в материале SQL ALTER TABLE - изменение таблицы базы данных.
Корпоративные ограничения целостности - это дополнительные правила поддержки целостности данных, определяемые пользователями или администраторами базы данных.
Читайте также: