
Принципы вычислений в многопроцессорных системах кратко
Обновлено: 05.07.2024
Глобальная распределенная система
Подключение через глобальную сеть, например через Интернет,
Мультипроцессор - это аббревиатура мультипроцессора с разделяемой памятью, а несколько процессоров имеют общую оперативную память.
Следовательно, мультипроцессоры обладают тем свойством, что каждый ЦП может иметь доступ ко всей памяти, а некоторые мультипроцессоры имеют некоторые характеристики.
2.1. UMA(Uniform Memory Access)
Читайте каждое слово в памяти как можно быстрее
2.1.1 Шинная многопроцессорная архитектура UMA
2.1.2 Мультипроцессор UMA на основе коммутатора
2.1.3 Мультипроцессор UMA на основе многоуровневой коммутации
Этот переключатель проверяет поле модуля, чтобы определить, к какой памяти подключиться, то есть подключить x или y
например Омега сеть
| Интернет | Количество выключателей | Стоит ли блокировать |
|---|---|---|
| Перекладина | n 2 | Неблокируемая |
| Омега сеть | n/2*log2n | блок |
2.2. NUMA(nonuniform memory access)
- Имеет одно адресное пространство, видимое для всех процессоров
- Доступ к удаленной памяти с помощью инструкций LOAD и STORE
- Доступ к удаленному хранилищу медленнее, чем доступ к локальному хранилищу
Файловый мультипроцессор
Основная идея: ведение базы данных для записи местоположения и состояния строки кэша. При обращении к строке кэша запросите базу данных, чтобы выяснить расположение строки кэша и ее грязную Запись (была ли она изменена),
2.3 Многоядерные чипы
Каждое ядро представляет собой полноценный процессор, который может совместно использовать память, но кеш не обязательно используется совместно. Его часто называютМультипроцессор уровня чипа (Chip-level MultiProcessors, CMP) .
Он не сильно отличается от многопроцессорных систем на базе шины и многопроцессорных систем, использующих коммутируемые сети:
- Каждый процессор на базе шины имеет свой кеш
- Отказоустойчивость CMP низкая: соединение плотное, отказ одного общего модуля может вызвать другие ошибки процессора
Система на чипе (system on a chip)
Микросхема содержит несколько ядер, но также содержит несколько профессиональных ядер, таких как декодеры видео и аудио, микросхемы шифрования, сетевые интерфейсы и т. д.
3.1 Каждый ЦП имеет свою собственную операционную систему
Плюсы: общий код операционной системы
нота
- Когда процесс выполняет системный вызов, он записывается и обрабатывается на ЦП компьютера и использует структуру данных в таблице операционной системы.
- Поскольку каждая операционная система имеет свою собственную таблицу, она также имеет свой собственный набор процессов. Эти процессы планируются самостоятельно без совместного использования процессов. Если пользователь входит в CPU1, то все его процессы находятся в CPU1, что может вызвать другие ЦП выгружен
- Нет совместного использования страниц: может случиться так, что CPU2 продолжает заменять страницы, в то время как CPU1 имеет дополнительные страницы
- несовместимый кеш
3.2 Master-Slave Мультипроцессор
проблема
Если процессоров много, основной ЦП станет узким местом, а скорость будет низкой
3.3 Симметричный мультипроцессор (SMP)
Асимметрия главного-подчиненного процессора устранена, и в памяти есть копия операционной системы, но любой процессор может ее запустить.
Эта модель динамически уравновешивает процессы и память, потому что у нее есть только один набор таблиц данных операционной системы.
Его проблема: когда два или более ЦПУ одновременно выполняют код операционной системы, например, запрашивают одну и ту же страницу свободной памяти, следует использовать семафор взаимного исключения (блокировка), чтобы сделать Вся система становится большой критической областью, так что только один процессор может одновременно запускать операционную систему
Объект планирования: один процесс или несколько процессов, независимо от того, является ли поток процессом ядра или потоком пользователя.
- Пользовательский поток: невидим для ядра, затем запланируйте отдельный процесс.
- Поток ядра: блок планирования является потоком,
4.1 Разделение времени
Сначала обсудите ситуацию с планированием независимых потоков. Если процессор не используется, выберите поток с наивысшим приоритетом в очереди с приоритетом для этого процессора.
- По мере увеличения числа процессоров это создает потенциальную конкуренцию за планирование структур данных.
- Затраты на переключение контекста, когда потоки блокируются во время ввода-вывода (издержки)
Планирование соответствия: основная идея - попытаться запустить поток на процессоре, который он запускал раньше,
4.2 Совместное использование пространства
Этот метод может использоваться, когда потоки связаны друг с другом определенным образом. Предполагая, что группа связанных потоков создается одновременно, при создании проверьте, достаточно ли свободного ЦП, если он есть, они получат выделенный ЦП, в противном случае ждите ,
Преимущества: устраняет многопрограммный дизайн, тем самым устраняя издержки переключения контекста
Недостаток: время тратится впустую, когда процессор заблокирован или делать нечего
4.3 Планирование банд
4.3.1 Основная идея
В многопроцессорностьПрименительно к вычислениям - это форма работы компьютера, в которой физически имеется более одного процессора. Цель состоит в том, чтобы иметь желание запускать разные части программы одновременно.
Эти несколько центральных процессоров (ЦП) находятся в тесном взаимодействии, разделяя шину, память и другие периферийные устройства компьютера. Поскольку доступно несколько процессоров, несколько процессов могут выполняться одновременно.
Многопроцессорность относится больше к количеству модулей ЦП, а не к количеству процессов, выполняющихся одновременно. Если оборудование предоставляет более одного процессора, то это многопроцессорность. Это способность системы использовать вычислительную мощность нескольких процессоров.
Многопроцессорная система очень полезна, когда вы хотите иметь достаточно высокую скорость для обработки большого набора данных. Эти системы в основном используются в таких приложениях, как прогнозирование погоды, спутниковое управление и т. Д.
Этот тип многопроцессорной системы впервые появился на больших компьютерах или мэйнфреймах, прежде чем снизить ее стоимость, чтобы обеспечить ее включение в персональные компьютеры.
Что такое многопроцессорность?
Благодаря поддержке многопроцессорной системы несколько процессов могут выполняться параллельно.
Предположим, что процессы Pr1, Pr2, Pr3 и Pr4 ожидают своего выполнения. В однопроцессорной системе сначала будет выполняться один процесс, затем следующий, затем другой и так далее.
Однако при многопроцессорной обработке каждый процесс может быть настроен на определенный ЦП для обработки.
Если это двухъядерный процессор с двумя процессорами, два процесса могут выполняться одновременно, и поэтому они будут в два раза быстрее. Точно так же четырехъядерный процессор будет в четыре раза быстрее, чем одинарный.
Поскольку конкретная функция назначается для выполнения каждому процессору, они смогут выполнять свою работу, доставлять набор инструкций следующему процессору и начинать работу над новым набором инструкций.
Точно так же разные процессоры могут использоваться для обработки передачи данных, хранения в памяти или арифметических функций.
Разница между многопроцессорностью и мультипрограммированием
Система является многопроцессорной, поскольку физически имеет более одного процессора, и может быть многопроцессорной, если в ней одновременно запущено несколько процессов.
Следовательно, разница между многопроцессорностью и многопроцессорностью заключается в том, что при многопроцессорности одновременно выполняется несколько процессов на нескольких процессорах, в то время как многопроцессорность сохраняет несколько программ в основной памяти и запускает их одновременно через один ЦП.
То есть многопроцессорность происходит за счет параллельной обработки, а многопроцессорность происходит, когда один ЦП переключается с одного процесса на другой.
Требования
Чтобы эффективно использовать многопроцессорную систему, компьютерная система должна иметь следующее:
Поддержка процессора
У вас должен быть набор процессоров, которые могут использовать их в многопроцессорной системе.
Кронштейн материнской платы
Материнская плата, способная содержать и обрабатывать несколько процессоров. Это означает дополнительные гнезда или слоты для добавленных чипов.
Поддержка операционной системы
Вся задача многопроцессорности управляется операционной системой, которая назначает различные задачи для выполнения различными процессорами в системе.
Приложения, предназначенные для использования в многопроцессорной обработке, называются сшитыми, что означает, что они разделены на более мелкие процедуры, которые можно запускать независимо.
Это позволяет операционной системе разрешать этим потокам выполняться на нескольких процессорах одновременно, что приводит к многопроцессорной обработке и повышению производительности.
Типы многопроцессорности
Симметричная многопроцессорная обработка
Все процессоры взаимодействуют друг с другом, поскольку каждый из них содержит копию одной и той же операционной системы.
Примером симметричной многопроцессорной системы является версия Unix Encore для компьютера Multimax.
Асимметричная многопроцессорность
В этом типе многопроцессорной обработки есть главный процессор, который дает инструкции всем остальным процессорам, назначая каждому из них заранее определенную задачу. Это наиболее экономичный вариант, позволяющий поддерживать связь между процессорами как главный-подчиненный.
Этот тип многопроцессорной обработки существовал только до появления симметричных мультипроцессоров.
Преимущество
Более высокая производительность
Благодаря многопроцессорности вы сможете выполнить больше задач за гораздо более короткий промежуток времени.
Если несколько процессоров работают вместе, производительность системы увеличивается за счет увеличения количества процессов, выполняемых за единицу времени.
Более высокая надежность
Когда процессор выходит из строя, многопроцессорность оказывается более надежной, потому что в этой ситуации система будет тормозить, но не выйдет из строя. Эта способность продолжать работать, несмотря на сбой, известна как постепенная деградация.
Например, если один процессор выйдет из строя из пяти, то задание не завершится ошибкой, но остальные четыре процессора поделят работу с вышедшим из строя процессором. Таким образом, система будет работать на 20% медленнее вместо полного сбоя.
Экономить деньги
Эти системы могут обеспечить долгосрочную экономию денег по сравнению с однопроцессорными системами, поскольку процессоры могут совместно использовать источники питания, периферийные устройства и другие устройства.
Если существует несколько процессов, которые совместно используют данные, лучше запрограммировать их в многопроцессорных системах для совместного использования данных, чем иметь разные компьютерные системы с несколькими копиями этих данных.
Недостатки
Более высокая стоимость покупки
Хотя многопроцессорные системы в долгосрочной перспективе дешевле, чем использование нескольких компьютерных систем, они все же довольно дороги.
Гораздо дешевле купить простую систему с одним процессором, чем многопроцессорную.
Сложная операционная система
В многопроцессорных системах требуется более сложная операционная система.
Это связано с тем, что наличие нескольких процессоров с общей памятью, устройствами и т. Д. распределение ресурсов по процессам сложнее, чем если бы был только один процессор.
Требуется большой объем памяти
Все процессоры в многопроцессорной системе совместно используют основную память. Следовательно, требуется гораздо больший пул памяти по сравнению с однопроцессорными системами.
Аннотация: Цель лекции: рассмотреть способы организации и области применения многопроцессорных и многомашинных вычислительных систем.
Многопроцессорные и многомашинные вычислительные системы
В настоящее время тенденция в развитии микропроцессоров и систем, построенных на их основе, направлена на все большее повышение их производительности. Вычислительные возможности любой системы достигают своей наивысшей производительности благодаря двум факторам:
использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Направления, связанные с повышением производительности отдельных микропроцессоров, мы рассматривали в предыдущих лекциях, а в этой лекции остановимся на вопросах распараллеливания обработки информации.
Существует несколько вариантов классификации систем параллельной обработки данных . По -видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных выделяются четыре класса архитектур:
SISD , MISD , SIMD , MIMD .
SISD ( sINgle INsTRuction sTReam / sINgle data sTReam ) - одиночный поток команд и одиночный поток данных . К этому классу относятся прежде всего классические последовательные машины, или, иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд , все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций процессор может использовать конвейерную обработку . В таком понимании машины данного класса фактически не относятся к параллельным системам.
SIMD ( sINgle INsTRuction sTReam / multIPle data sTReam ) - одиночный поток команд и множественный поток данных . Применительно к одному микропроцессору этот подход реализован в MMX - и SSE - расширениях современных микропроцессоров. Микропроцессорные системы типа SIMD состоят из большого числа идентичных процессорных элементов , имеющих собственную память . Все процессорные элементы в такой машине выполняют одну и ту же программу. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Очевидно, что такая система, составленная из большого числа процессоров, может обеспечить существенное повышение производительности только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу.
MISD (multIPe INsTRuction sTReam / sINgle data sTReam ) - множественный поток команд и одиночный поток данных . Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Ряд исследователей к данному классу относят конвейерные машины.
MIMD (multIPe INsTRuction sTReam / multIPle data sTReam ) - множественный поток команд и множественный поток данных . Базовой моделью вычислений в этом случае является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным . В такой системе каждый процессорный элемент выполняет свою программу достаточно независимо от других процессорных элементов . Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей. К тому же архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе строгого учета соотношения стоимость / производительность . В действительности практически все современные многопроцессорные системы строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Как и любая другая, приведенная выше классификация несовершенна: существуют машины, прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. Рассмотрим классификацию многопроцессорных и многомашинных систем на основе другого признака - степени разделения вычислительных ресурсов системы.
В этом случае выделяют следующие 4 класса систем:
- системы с симметричной мультипроцессорной обработкой ( symmeTRic multIProcessINg ), или SMP -системы;
- системы, построенные по технологии неоднородного доступа к памяти (non-un IForm memory access ), или NUMA -системы;
- кластеры;
- системы вычислений с массовым параллелизмом ( massively parallel processor ), или MPP -системы.
Самым высоким уровнем интеграции ресурсов обладает система с симметричной мультипроцессорной обработкой, или SMP-система (рис. 13.1).
В этой архитектуре все процессоры имеют равноправный доступ ко всему пространству оперативной памяти и ввода/вывода. Поэтому SMP - архитектура называется симметричной. Ее интерфейсы доступа к пространству ввода/вывода и ОП, система управления кэш-памятью, системное ПО и т. п. построены таким образом, чтобы обеспечить согласованный доступ к разделяемым ресурсам . Соответствующие механизмы блокировки заложены и в шинном интерфейсе, и в компонентах операционной системы, и при построении кэша.
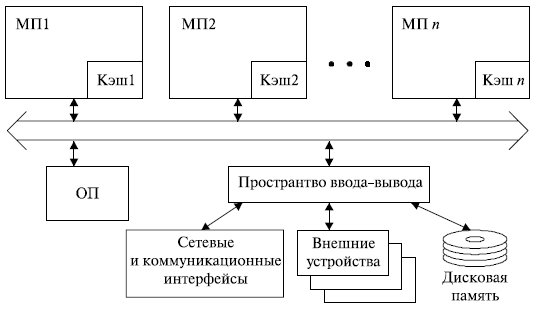
С точки зрения прикладной задачи, SMP-система представляет собой единый вычислительный комплекс с вычислительными ресурсами, пропорциональными количеству процессоров. Распараллеливание вычислений обеспечивается операционной системой, установленной на одном из процессоров. Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается WINdows NT).
ОС автоматически в процессе работы распределяет процессы по процессорным ядрам , оптимизируя использование ресурсов. Ядра задействуются равномерно, и прикладные программы могут выполняться параллельно на всем множестве ядер. При этом достигается максимальное быстродействие системы. Важно, что для синхронизации приложений вместо сложных механизмов и протоколов межпроцессорной коммуникации применяются стандартные функции ОС. Таким образом, проще реализовать проекты с распараллеливанием программных потоков. Общая для совокупности ядер ОС позволяет с помощью служебных инструментов собирать статистику, единую для всей архитектуры. Соответственно, можно облегчить отладку и оптимизацию приложений на этапе разработки или масштабирования для других форм многопроцессорной обработки.
В общем случае приложение , написанное для однопроцессорной системы, не требует модификации при его переносе в мультипроцессорную среду. Однако для оптимальной работы программы или частей ОС они переписываются специально для работы в мультипроцессорной среде.
Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины.
Сдерживающим фактором в подобных системах является пропускная способность магистрали, что приводит к их плохой масштабируемости. Причиной этого является то, что в каждый момент времени шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Вычислительные элементы начинают мешать друг другу. Когда произойдет такой конфликт , зависит от скорости связи и от количества вычислительных элементов. Кроме того, системная шина имеет ограниченное число слотов . Все это очевидно препятствует увеличению производительности при увеличении числа процессоров. В реальных системах можно задействовать не более 32 процессоров.
В современных микропроцессорах поддержка построения мультипроцессорной системы закладывается на уровне аппаратной реализации МП, что делает многопроцессорные системы сравнительно недорогими.
Так, для обеспечения возможности работы на общую магистраль каждый микропроцессор фирмы Intel начиная с Pentium Pro имеет встроенную поддержку двухразрядного идентификатора процессора - APIC ( Advanced Programmable INTerrupt ConTRoller ). По умолчанию CPU с самым высоким номером идентификатора становится процессором начальной загрузки. Такая идентификация облегчает арбитраж шины данных в SMP-системе. Подобные средства мы видели и в МП Power4, где на аппаратном уровне поддерживается создание микросхемного модуля MCM из 4 микропроцессоров, включающего в совокупности 8 процессорных ядер.
Сегодня SMP широко применяют в многопроцессорных суперкомпьютерах и серверных приложениях . Однако если необходимо детерминированное исполнение программ в реальном масштабе времени, например, при визуализации мультимедийных данных, возможности сугубо симметричной обработки весьма ограничены. Может возникнуть ситуация, когда приложения, выполняемые на различных ядрах, обращаются к одному ресурсу ОС. В этом случае доступ получит только одно из ядер.
Остальные будут простаивать до высвобождения критической области .
Естественно, при этом резко снижается производительность приложений реального времени.
Исчерпание производительности системной шины в SMP-системах при доступе большого числа процессоров к общему пространству оперативной памяти и принципиальные ограничения шинной технологии стали причиной сдерживания роста производительности SMP-систем. На данный момент эта проблема получила два решения. Первое - замена системной шины на высокопроизводительный коммутатор , обеспечивающий одновременный неблокирующий доступ к различным участкам памяти. Второе решение предлагает технология NUMA.
Система, построенная по технологии NUMA, представляет собой набор узлов, каждый из которых, по сути, является функционально законченным однопроцессорным или SMP -компьютером. Каждый имеет свое локальное пространство оперативной памяти и ввода/вывода. Но с помощью специальной логики каждый имеет доступ к пространству оперативной памяти и ввода/вывода любого другого узла (рис. 13.2). Физически отдельные устройства памяти могут адресоваться как логически единое адресное пространство - это означает, что любой процессор может выполнять обращения к любым ячейкам памяти, в предположении, что он имеет соответствующие права доступа . Поэтому иногда такие системы называются системами с распределенной разделяемой памятью ( DSM - disTRibuted shared memory ).
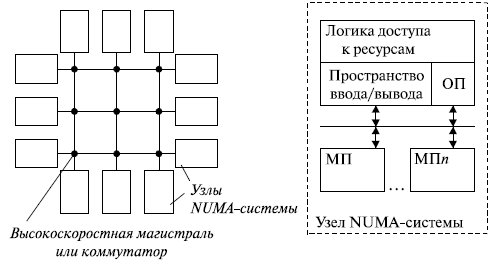
При такой организации память каждого узла системы имеет свою адресацию в адресном пространстве всей системы. Логика доступа к ресурсам определяет, к памяти какого узла относится выработанный процессором адрес . Если он не принадлежит памяти данного узла, организуется обращение к другому узлу согласно заложенной в логике доступа карте адресов. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной.
При использовании наиболее распространенного сейчас варианта cc-NUMA (cache- coherent NUMA - неоднородный доступ к памяти с согласованием содержимого кэш-памяти) обеспечивается кэширование данных оперативной памяти других узлов.
Обычно вся система работает под управлением единой ОС, как в SMP . Возможны также варианты динамического разделения системы, когда отдельные разделы системы работают под управлением разных ОС.
Довольно большое время доступа к оперативной памяти соседних узлов по сравнению с доступом к ОП своего узла в NUMA-системах на настоящий момент делает такое использование не вполне оптимальным.
Так что полной функциональностью SMP-систем NUMA-компьютеры на сегодняшний день не обладают. Однако среди систем общего назначения NUMA-системы имеют один из наиболее высоких показателей по масштабируемости и, соответственно, по производительности. На сегодня максимальное число процессоров в cc-NUMA -системах может превышать 1000 (серия OrigIN3000). Один из наиболее производительных суперкомпьютеров - Tera 10 - имеет производительностью 60 Тфлопс и состоит из 544 SMP -узлов, в каждом из которых находится от 8 до 16 процессоров Itanium 2.
Следующим уровнем в иерархии параллельных систем являются комплексы, также состоящие из отдельных машин, но лишь частично разделяющие некоторые ресурсы. Речь идет о кластерах.
По топологии межмодульных функциональных и управляющих связей и организации работы выделяются два типа многопроцессорных систем МКМД
¨ с использованием многовходовой памяти (многошинные-многовходовые вычислительные системы).
Многопроцессорные вычислительные системы с общей шиной.
В МПВС с общей шиной(Shared Memory Proccessing – мультипроцессоры с разделением памяти, SMP-архитектура) все функциональные модули (процессоры П1, П2, . ПМ, модули памяти МП1, МП2, . МПК, устройства ввода-вывода УВВ1, УВВ2, . УВВМ) подсоединены к одной общей шине межмодульных связей, ширина которой может быть от одного бита до нескольких байтов. Между модулями системы нет постоянных связей, информация между ними передается в режиме разделения времени. В каждый данный момент времени по шине передается лишь один пакет информации от какого-то одного источника. Другие источники информации должны ожидать, пока не освободится системная шина.
Основные преимущества системы с общей шиной межмодульных связей:
¨ система характеризуется относительно низкой функциональной сложностью и невысокой стоимостью;
¨ в системе легко осуществляется реконфигурация структуры путем добавления или удаления функциональных модулей.
Недостатки таких систем:
¨ ограничение производительности системы пропускной способностью общей шины;
¨ ухудшение общей производительности системы при ее расширении путем добавления модулей;
¨ потери производительности системы, связанные с разрешением конфликтов, которые возникают в случае, когда несколько модулей одновременно претендуют на занятие общей шины для передачи информации. Эти потери можно снизить, если, кроме общей памяти, доступной всем процессорам, каждый из них снабдить местной (локальной, процессорной) памятью для хранения информации, участвующей в ближайшем ряду вычислений. При наличии местной памяти частота обращения процессоров к общей памяти уменьшается, следовательно, уменьшается частота возникновения конфликтов и потери времени на их разрешение;
¨ отказ общей шины приводит к выходу из строя всей системы.
Организация связей между элементами системы на основе общей шины является одним из распространенных способов построения не только многопроцессорных, но и многомашинных вычислительных комплексов небольшой мощности.
Архитектура SMP стала своего рода стандартом для всех современных многопроцессорных серверов (например, НР9000 и DEC Alpha Server AXP).
Многопроцессорные вычислительные системы с многовходовыми модулями ОП.
В МПВС с многовходовыми модулями ОП или симметричных МПВС взаимные соединения выполняются с помощью индивидуальных шин, подключающих каждый процессор и каждое устройство ввода-вывода к отдельному входу оперативной памяти. Для этого необходимо, чтобы модули ОП имели по несколько входов и снабжались управляющими схемами для разрешения конфликтов в случаях, когда два или более процессора или устройства ввода-вывода требуют доступа к одному и тому же модулю памяти в пределах одного временного цикла. Число подключаемых элементов системы к одному модулю памяти ограничивается числом его входов.
При построении общего поля ОП МПВС целесообразной оказывается реализация метода расслоения оперативной памяти, при которой ячейки с соседними адресами оказываются расположенными в соседних модулях. Обязательными условиями применения этого метода являются модульность структуры ОП и наличие для каждого модуля памяти автономного блока управления памятью.
Преимущества МПВС с многовходовыми модулямиОП:
¨ скорость передачи информации значительно выше, чем в МПВС с общей шиной;
¨ система может работать и в режиме однопроцессорной конфигурации.
Недостатки таких систем следующие:
¨ большое число линий связи и разъемов, усложняющих конструкцию системы и снижающих ее надежность;
¨ оперативная память, составленная из многовходовых модулей, является дорогостоящей.
Принципы построения МПВС с многовходовыми модулями ОП используются в мэйнфреймах.
Многомашинные вычислительные системы (ММВС)
В системах типа МКМД реализуется асинхронный вычислительный процесс, при котором каждый процессор системы выполняет свою программу (или свой участок сложной программы) с собственными данными. В таких системах происходит постоянное распараллеливание вычислений. Две основных причины создания этого типа ВС – дублирование важных блоков вычислений или модулей ВС и повышение производительности систем.
Многомашинные комплексы
Вычислительные системы со слабой связью или распределенные вычислительные системы, как правило, представляются многомашинными комплексами, в которых отдельные компьютеры объединяются либо с помощью сетевых средств, либо с помощью общей внешней памяти (обычно — дисковые накопители большой емкости). Каждая ЭВМ системы имеет свою оперативную память и работает под управлением своей операционной системы. Каждая машина использует другую как канал или устройство ввода-вывода. Обмен информацией между машинами происходит в результате взаимодействия их операционных систем.
ММВС строится из логически независимых компонентов: процессоров, устройств оперативной памяти, каналов ввода-вывода, ВЗУ, устройств управления ВЗУ, устройств ввода-вывода, устройств управления УВВ. Логическая независимость процессоров системы определяется возможностью их независимого функционирования. Для остальных компонентов эта независимость определяется возможностью их подсоединения к одному или к нескольким процессорам ММВС.
Связь между машинами (процессорами) ММВС может осуществляться на уровне любого из его логически независимых компонентов с помощью специальных мультисистемных средств или средств комплексирования. Такая связь должна быть достаточно гибкой и обеспечивать независимость функционирования различных модулей системы и их взаимодействие с различной скоростью, соответствующей скорости обмена информацией между элементами системы. Для этого на разных уровнях комплексирования применяются различные по тактовой частоте, разрядности, пропускной способности шины интерфейсов.
Очевидно, что система со всеми возможными уровнями связей будет наиболее совершенной, гибкой и надежной в функционировании. Но с другой стороны, система с полными связями получается сложной по своей структуре и организации функционирования. В каждом конкретном многомашинном комплексе не обязательно реализуются все уровни комплексирования.
Рассмотрим уровни связи вычислительной системы в порядке возрастания скорости обмена информацией.
Межмашинная связь на уровне внешних устройств используется главным образом для организации общего поля внешней памяти. Такая связь организуется через каналы ввода-вывода этих устройств и шинные интерфейсы. При этом обычно часть ВЗУ остается в индивидуальном пользовании отдельных машин. Преимуществом комплексирования на уровне ВЗУ является значительное увеличение объемов информации (данных и программ), одновременно доступных процессорам ММВС.
Наибольшее распространение получила взаимодействие вычислительных средств на уровне канал-канал через адаптер канал-канал. Адаптер подключается к двум каналам, причем функционально он рассматривается как устройство управления ввода-вывода для каждого из каналов, а каждая из связанных адаптером машин по отношению друг к другу является внешним устройством. В отличие от любого другого устройства управления внешними устройствами адаптер не управляет устройствами ввода-вывода, а только осуществляет связь между каналами и синхронизирует их работу. Адаптер обеспечивает быстрый обмен информацией между каналами, а следовательно, и между ОП взаимодействующих процессоров, если общее поле оперативной памяти не организовано.
Взаимодействие на уровне ОП осуществляется для создания общего поля оперативной памяти, что значительно ускоряет обмен информацией между процессорами и повышает возможности функционирования системы. Наибольшая оперативность обмена информацией достигается при реализации именно такого уровня связи. Построение ММВС с общим полем ОП связано с необходимостью применения многовходовых модулей памяти. При этом существенно усложняются структура и функции устройства управления общей оперативной памятью. С помощью УУ должны решаться такие задачи, как реализация установленной очередности обращения к модулям памяти со стороны процессоров, решение конфликтных ситуаций, возникающих при одновременном обращении к одному и тому же модулю памяти со стороны обоих процессоров, поддержание когерентности памяти. Наибольшие затруднения связаны с созданием программных средств, обеспечивающих функционирование системы с общим полем ОП.
Взаимодействие на уровне процессоров через интерфейс межпроцессорной связи осуществляется с целью синхронизации единого вычислительного процесса путем передачи между процессорами сигналов внешних прерываний и команд прямого управления.
Для оценки эффективности взаимодействия вычислительных средств системы на различных уровнях могут привлекаться такие показатели эффективности ВС, как время реакции системы на запросы с учетом их приоритетов, пропускная способность, время на решение заданного набора задач.
ММР архитектура
К достоинствам данной архитектуры относится то, что она использует стандартные микропроцессоры и обладает неограниченным быстродействием (порядка TFLOPS).
Однако есть и недостатки — программирование коммутаций процессов является слабо автоматизированной и очень сложной процедурой. Так что для коммерческих задач и даже для подавляющего большинства инженерных приложений системы с массовым параллелизмом недоступны.
Многомашинные вычислительные системы создаются и на базе мини- и микро-ЭВМ.
Сравнивая между собой ММВС и МПВС, можно отметить, что в МПВС достигается более высокая скорость обмена информацией между элементами системы и поэтому более высокая производительность, более высокая реакция на возникающие в системе и ее внешней среде нестандартные ситуации, более высокие надежность и живучесть (МПВС сохраняет работоспособность, пока работоспособны хотя бы по одному модулю каждого типа устройств). С другой стороны, построение ММВС из серийно выпускаемых ЭВМ с их стандартными операционными системами значительно проще, чем построение МПВС, требующих преодоления определенных трудностей, связанных главным образом с организацией общего поля оперативной памяти и созданием единой операционной системы. Разница организации MIMD-систем с сильной и слабой связью проявляются ещё и при обработке приложений, отличающихся интенсивностью обменов между взаимодействующими процессами (см. раздел Вычислительные системы).
Вычислительные сети являются дальнейшим развитием вычислительных систем распределенного типа. Они представляют собой новый, более совершенный этап в использовании средств вычислительной техники - переход к коллективному их использованию.
* теория классификации и систематизации сложноорганизованных областей действительности, имеющих обычно иерархическое строение ©2001 "Большая Российская энциклопедия"
Читайте также:
- Титульный лист исследовательской работы образец для школы беларусь
- Карантинный журнал в детском саду образец по ветрянке
- Принцип работы жидкостного хроматографа кратко
- Назовите различия в формировании совета федерации и государственной думы кратко обществознание
- Развитие бытового жанра в живописи 70 80 годов xix века кратко