
Параметрические и непараметрические методы статистики кратко
Обновлено: 05.07.2024
Большая часть области статистики и статистических методов посвящена данным, для которых известно распределение.
Образцы данных, где мы уже знаем или можем легко определить распределение, называются параметрическими данными. Часто параметрический используется для ссылки на данные, которые были взяты из гауссовского распределения в обычном использовании. Данные, в которых распределение неизвестно или не может быть легко идентифицировано, называют непараметрическими.
В случае, когда вы работаете с непараметрическими данными, могут использоваться специализированные непараметрические статистические методы, которые отбрасывают всю информацию о распределении. Как таковые, эти методы часто называют методами без распространения.
В этом уроке вы узнаете непараметрическую статистику и ее роль в прикладном машинном обучении.
После завершения этого урока вы узнаете:
- Разница между параметрическими и непараметрическими данными.
- Как ранжировать данные, чтобы отбросить всю информацию о распределении данных.
- Пример статистических методов, которые можно использовать для ранжированных данных.

Обзор учебника
Этот урок разделен на 4 части; они есть:
- Параметрические данные
- Непараметрические данные
- Данные рейтинга
- Работа с ранжированными данными
Параметрические данные
Параметрические данные - это выборка данных, полученных из известного распределения данных.
Это означает, что мы уже знаем распределение или мы определили распределение, и что мы знаем параметры распределения. Зачастую параметрический является сокращением для вещественных данных, взятых из гауссовского распределения. Это полезное сокращение, но строго это не совсем точно.
Если у нас есть параметрические данные, мы можем использовать параметрические методы. Продолжая с сокращением параметрического значения Gaussian. Если у нас есть параметрические данные, мы можем использовать весь набор статистических методов, разработанных для данных, предполагающих распределение по Гауссу, таких как:
- Сводные статистические данные.
- Корреляция между переменными.
- Тесты значимости для сравнения средств.
В целом, мы предпочитаем работать с параметрическими данными и даже заходим так далеко, что используем методы подготовки данных, которые делают данные параметрическими, такие как преобразования данных, чтобы мы могли использовать эти понятные статистические методы.
Непараметрические данные
Данные, которые не соответствуют известному или понятному распределению, называются непараметрическими данными.
Данные могут быть непараметрическими по многим причинам, таким как:
- Данные не являются действительными, а представляют собой порядковые номера, интервалы или какую-либо другую форму.
- Данные являются реальными, но не соответствуют хорошо понятной форме.
- Данные являются почти параметрическими, но содержат выбросы, множественные пики, сдвиг или некоторые другие особенности.
Есть набор методов, которые мы можем использовать для непараметрических данных, которые называются непараметрическими статистическими методами. Фактически, большинство параметрических методов имеют эквивалентную непараметрическую версию.
В целом, результаты непараметрических методов менее эффективны, чем их параметрические аналоги, а именно потому, что они должны быть обобщены для работы со всеми типами данных. Мы все еще можем использовать их для вывода и делать заявления о результатах и результатах, но они не будут иметь такой же вес, как аналогичные утверждения с параметрическими методами. Информация о распространении отбрасывается.
В случае порядковых или интервальных данных непараметрическая статистика является единственным типом статистики, которую можно использовать. Для реальных данных непараметрические статистические методы требуются в прикладном машинном обучении, когда вы пытаетесь претендовать на данные, которые не соответствуют известному распределению Гаусса.
Данные рейтинга
Прежде чем применять непараметрический статистический метод, данные должны быть преобразованы в ранговый формат.
Таким образом, статистические методы, которые ожидают данные в формате ранга, иногда называют статистикой ранга, такой как ранговая корреляция и тесты статистической гипотезы ранга.
Данные рейтинга в точности соответствуют его названию. Процедура выглядит следующим образом:
- Сортировка всех данных в образце в порядке возрастания.
- Присвойте целочисленный ранг от 1 до N для каждого уникального значения в выборке данных.
Например, представьте, что у нас есть следующий образец данных, представленный в виде столбца:
Мы можем отсортировать это следующим образом:
Затем присваивайте ранг каждому значению, начиная с 1:
Затем мы можем применить эту процедуру к другой выборке данных и начать использовать непараметрические статистические методы.
Существуют вариации этой процедуры для особых обстоятельств, таких как обработка связей, использование обратного ранжирования и использование дробного ранга, но общие свойства сохраняются.
Библиотека SciPy предоставляетrankdata ()функция ранжирования числовых данных, которая поддерживает ряд вариаций ранжирования.
Пример ниже демонстрирует, как ранжировать числовой набор данных.
При выполнении примера сначала генерируется выборка из 1000 случайных чисел из равномерного распределения, затем ранжируется выборка данных и печатается результат
Работа с ранжированными данными
Существуют статистические инструменты, которые вы можете использовать для проверки соответствия ваших выборочных данных заданному распределению.
Например, если мы берем непараметрические данные в качестве данных, которые не выглядят гауссовскими, то вы можете использовать статистические методы, которые количественно определяют гауссовскую выборку данных, и использовать непараметрические методы, если данные не проходят эти тесты.
Вот три примера статистических методов проверки нормальности:
- Тест Шапиро-Вилка.
- Тест Колмогорова-Смирнова.
- Тест Андерсона-Дарлинга
Как только вы решили использовать непараметрическую статистику, вы должны затем упорядочить свои данные.
Фактически, большинство инструментов, которые вы используете для вывода, будут автоматически ранжировать данные выборки. Тем не менее, важно понимать, как преобразуются данные вашего образца перед выполнением тестов.
В области прикладного машинного обучения у вас могут быть два основных типа вопросов о ваших данных, которые вы можете решать непараметрическими статистическими методами.
Связь между переменными
Методы количественной оценки зависимости между переменными называются методами корреляции.
Два непараметрических метода статистической корреляции, которые вы можете использовать:
- Коэффициент ранговой корреляции Спирмена.
- Коэффициент корреляции ранга Кендалла.
Сравнить образец средства
Методы количественной оценки того, значительно ли среднее между двумя популяциями, называются тестами статистической значимости.
Вы можете использовать три непараметрических критерия статистической значимости:
- Тест Фридмана.
- U-тест Манна-Уитни.
- Знак Уилкоксона.
расширения
В этом разделе перечислены некоторые идеи по расширению учебника, которые вы, возможно, захотите изучить.
- Перечислите три примера, когда вы думаете, что вам может понадобиться использовать непараметрические статистические методы в прикладном проекте машинного обучения.
- Разработайте свой собственный пример, чтобы продемонстрировать возможностиrankdata ()функция.
- Напишите свою собственную функцию для ранжирования предоставленного одномерного набора данных.
Если вы исследуете какое-либо из этих расширений, я хотел бы знать.
Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
книги
статьи
Резюме
В этом уроке вы обнаружили непараметрическую статистику и ее роль в прикладном машинном обучении.
В частности, вы узнали:
- Разница между параметрическими и непараметрическими данными.
- Как ранжировать данные, чтобы отбросить всю информацию о распределении данных.
- Пример статистических методов, которые можно использовать для ранжированных данных.
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Непараметрическая статистика и подгонка распределения
Краткий обзор понятия "критерий значимости". Для того чтобы понять идеи непараметрической статистики (термин был впервые введен Wolfowitz, 1942), следует познакомиться с идеями параметрической статистики. Глава Элементарные понятия статистики знакомит с понятием статистической значимости критерия, основанного на выборочном распределении определенной статистики (вы можете просмотреть эту главу, прежде чем продолжить чтение). Говоря кратко, если вы знаете распределение наблюдаемой переменной, то можете предсказать, как в повторных выборках равного объема будет "вести себя" используемая статистика - т.е. каким образом она будет распределена. Пусть, например, имеется 100 случайных выборок, из одной популяции по 100 взрослых человек в каждой. Вычислим средний рост субъектов в каждой выборке, т.е. построим выборочное среднее. Тогда распределение выборочных средних можно хорошо аппроксимировать нормальным распределением (более точно, t распределением Стьюдента с 99 степенями свободы). Теперь представьте, что случайным образом извлечена еще одна выборка из жителей некоего города ("Вышгород"), где, по вашим представлениям, проживают люди с ростом выше среднего. Если средний рост людей в этой выборке попадает в верхнюю 95% критическую область t распределения, то можно сделать обоснованный вывод, что жители Вышгорода, действительно, в среднем более высокие (чем в целом в популяции), т.е. что это действительно город высоких людей.
Действительно ли большинство переменных имеют нормальное распределение? В рассмотренном примере использовался тот факт, что в повторных выборках равного объемы средние значения (роста людей) будут иметь t распределение (с определенным средним и дисперсией). Однако, это верно лишь, если рассматриваемая переменная (рост) имеет нормальное распределение, т.е. что распределение людей определенного роста нормально распределено.
Для многих изучаемых переменных невозможно сказать с уверенностью, что это действительно так. Например, является ли доход нормально распределенной величиной? - скорее всего, нет. Случаи редких болезней не являются нормально распределенными в популяции, число автомобильных аварий также не является нормально распределенным, как и многие переменные, интересующие исследователя.
Дополнительную информацию о нормальном распределении можно посмотреть в разделе Элементарные понятия статистики.
Объем выборки. Другим фактором, часто ограничивающим применимость критериев, основанных на предположении нормальности, является объем или размер выборки, доступной для анализа. До тех пор пока выборка достаточно большая (например, 100 или больше наблюдений), можно считать, что выборочное распределение нормально, даже если вы не уверены, что распределение переменной в популяции, действительно, является нормальным. Тем не менее, если выборка очень мала, то критерии, основанные на нормальности, следует использовать только при наличии уверенности, что переменная действительно имеет нормальное распределение. Однако нет способа проверить это предположение на малой выборке.
Проблемы измерения. Использование критериев, основанных на предположении нормальности, кроме того, ограничено точностью измерений. Например, рассмотрим исследование, в котором средний балл успеваемости (СБУ) является основной переменной. Можно ли сказать, что средняя успеваемость студента A в два раза выше, чем успеваемость студента C? Является ли различие между средним баллом студентов B и A сравнимым с различием между студентами D и C? Индекс СБУ является грубой мерой, позволяющей только ранжировать студентов в порядке "хороший" - "плохой". Эта общая задача измерений обычно обсуждается в учебниках по статистике в терминах типов измерений или шкалы измерения. Не вдаваясь в детали, отметим, что наиболее общие статистические методы, такие как дисперсионный анализ (t-критерий), регрессия и т.д. предполагают, что исходные измерения выполнены, по крайней мере, в интервальной шкале, в которой интервалы можно разумным образом сравнивать между собой (например, B минус A равняется D минус C). Тем не менее, как в данном примере, такие предположения часто неестественны, и данные скорее просто упорядочены (измерены в порядковой шкале), чем измерены точно.
Параметрические и непараметрические методы. Надеемся, что после этого введения становится ясной необходимость наличия статистических процедур, позволяющих обрабатывать данные "низкого качества" из выборок малого объема с переменными, про распределение которых мало что или вообще ничего не известно. Непараметрические методы как раз и разработаны для тех ситуаций, достаточно часто возникающих на практике, когда исследователь ничего не знает о параметрах исследуемой популяции (отсюда и название методов - непараметрические). Говоря более специальным языком, непараметрические методы не основываются на оценке параметров (таких как среднее или стандартное отклонение) при описании выборочного распределения интересующей величины. Поэтому эти методы иногда также называются свободными от параметров или свободно распределенными.
Краткий обзор непараметрических процедур
- критерии различия между группами (независимые выборки);
- критерии различия между группами (зависимые выборки);
- критерии зависимости между переменными.
Различия между независимыми группами. Обычно, когда имеются две выборки (например, мужчины и женщины), которые вы хотите сравнить относительно среднего значения некоторой изучаемой переменной, вы используете t-критерий для независимых выборок (в модуле Основные статистики и таблицы). Непараметрическими альтернативами этому критерию являются: критерий серий Вальда-Вольфовица, U критерий Манна-Уитни и двухвыборочный критерий Колмогорова-Смирнова. Если вы имеете несколько групп, то можете использовать дисперсионный анализ (см. Дисперсионный анализ). Его непараметрическими аналогами являются: ранговый дисперсионный анализ Краскела-Уоллиса и медианный тест.
Различия между зависимыми группами. Если вы хотите сравнить две переменные, относящиеся к одной и той же выборке (например, математические успехи студентов в начале и в конце семестра), то обычно используется t-критерий для зависимых выборок (в модуле Основные статистики и таблицы. Альтернативными непараметрическими тестами являются: критерий знаков и критерий Вилкоксона парных сравнений. Если рассматриваемые переменные по природе своей категориальны или являются категоризованными (т.е. представлены в виде частот попавших в определенные категории), то подходящим будет критерий хи-квадрат Макнемара. Если рассматривается более двух переменных, относящихся к одной и той же выборке, то обычно используется дисперсионный анализ (ANOVA) с повторными измерениями. Альтернативным непараметрическим методом является ранговый дисперсионный анализ Фридмана или Q критерий Кохрена (последний применяется, например, если переменная измерена в номинальной шкале). Q критерий Кохрена используется также для оценки изменений частот (долей).
Зависимости между переменными. Для того, чтобы оценить зависимость (связь) между двумя переменными, обычно вычисляют коэффициент корреляции. Непараметрическими аналогами стандартного коэффициента корреляции Пирсона являются статистики Спирмена R, тау Кендалла и коэффициент Гамма (см. Непараметрические корреляции). Если две рассматриваемые переменные по природе своей категориальны, подходящими непараметрическими критериями для тестирования зависимости будут: Хи-квадрат, Фи коэффициент, точный критерий Фишера. Дополнительно доступен критерий зависимости между несколькими переменными так называемый коэффициент конкордации Кендалла. Этот тест часто используется для оценки согласованности мнений независимых экспертов (судей), в частности, баллов, выставленных одному и тому же субъекту.
Описательные статистики. Если данные не являются нормально распределенными, а измерения, в лучшем случае, содержат ранжированную информацию, то вычисление обычных описательных статистик (например, среднего, стандартного отклонения) не слишком информативно. Например, в психометрии хорошо известно, что воспринимаемая интенсивность стимулов (например, воспринимаемая яркость света) представляет собой логарифмическую функцию реальной интенсивности (яркости, измеренной в объективных единицах - люксах). В данном примере, обычная оценка среднего (сумма значений, деленная на число стимулов) не дает верного представления о среднем значении действительной интенсивности стимула. (В обсуждаемом примере скорее следует вычислить геометрическое среднее.) Модуль Непараметрическая статистика вычисляет разнообразный набор мер положения (среднее, медиану, моду и т.д.) и рассеяния (дисперсию, гармоническое среднее, квартильный размах и т.д.), позволяющий представить более "полную картину" данных.
Какой метод использовать
Нелегко дать простой совет, касающийся использования непараметрических процедур. Каждая непараметрическая процедура в модуле имеет свои достоинства и свои недостатки. Например, двухвыборочный критерий Колмогорова-Смирнова чувствителен не только к различию в положении двух распределений, например, к различиям средних, но также чувствителен и к форме распределения. Критерий Вилкоксона парных сравнений предполагает, что можно ранжировать различия между сравниваемыми наблюдениями. Если это не так, лучше использовать критерий знаков. В общем, если результат исследования является важным (например, оказывает ли людям помощь определенная очень дорогостоящая и болезненная терапия?), то всегда целесообразно применить различные непараметрические тесты. Возможно, результаты проверки (разными тестами) будут различны. В таком случае следует попытаться понять, почему разные тесты дали разные результаты. С другой стороны, непараметрические тесты имеют меньшую статистическую мощность (менее чувствительны), чем их параметрические конкуренты, и если важно обнаружить даже слабые отклонения (например, является ли данная пищевая добавка опасной для людей), следует особенно внимательно выбирать статистику критерия.
Большие массивы данных и непараметрические методы. Непараметрические методы наиболее приемлемы, когда объем выборок мал. Если данных много (например, n > 100), то не имеет смысла использовать непараметрические статистики. Глава Элементарные понятия статистики предлагает краткое ознакомление с центральной предельной теоремой. Главное здесь состоит в том, что когда выборки становятся очень большими, то выборочные средние подчиняются нормальному закону, даже если исходная переменная не является нормальной или измерена с погрешностью. Таким образом, параметрические методы, являющиеся более чувствительными (имеют большую статистическую мощность), всегда подходят для больших выборок. Большинство критериев значимости многих непараметрических статистик, описанных далее, основываются на асимптотической теории (больших выборок) поэтому соответствующие тесты часто не выполняются, если размер выборки становится слишком малым. Обратитесь к описаниям определенных критериев, чтобы узнать больше об их мощности и эффективности.
В некоторых исследовательских проектах можно сформулировать гипотезы относительно распределения рассматриваемой переменной. Например, переменные, значения которых определяются бесконечным числом независимых факторов, распределены по нормальному закону: можно предположить, что рост индивидуума является результатом воздействия многих независимых факторов, таких как различные генетические предрасположенности, болезни, перенесенные в раннем возрасте и т.д. Как следствие, рост имеет тенденцию к нормальному распределению в населении. С другой стороны, если наблюдаемые значения переменной являются результатом очень редких событий, то переменная будет иметь распределение Пуассона (которое иногда называется распределением редких событий). Например, несчастные случаи на производстве можно рассматривать как результат пересечения ряда неудачных событий (на житейском языке стечением маловероятных обстоятельств), поэтому их частота приближенно описывается распределением Пуассона. Эти и другие полезные распределения подробно описываются в соответствующих разделах.
Гипотеза нормальности. Другим обычным приложением процедуры подгонки распределения является проверка гипотезы нормальности до того, как использовать какой-либо параметрический тест (см. выше).
Все права на материалы электронного учебника принадлежат компании StatSoft

Параметрические и непараметрические методы статистики

Параметрические и непараметрические методы статистики
29.05.2020
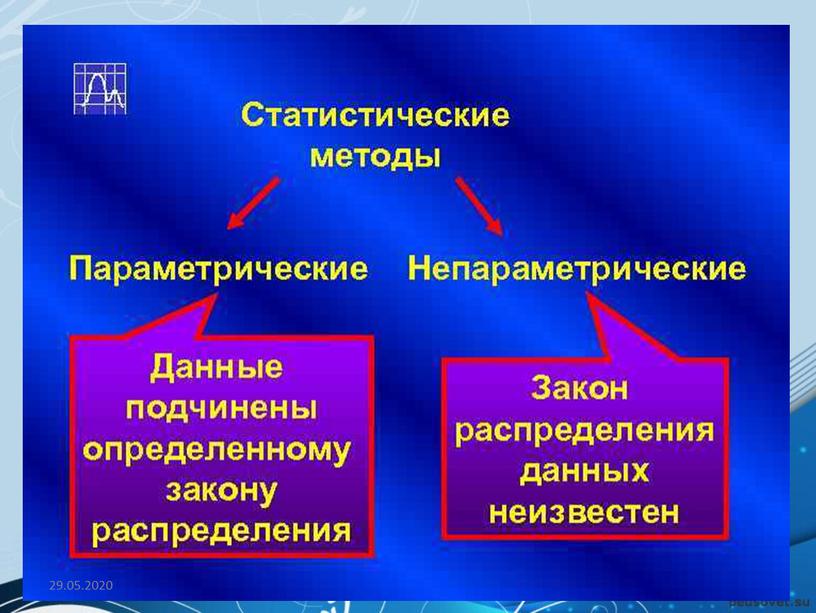
Параметрические и непараметрические методы – это методы математической статистики, в параметрических методах генеральное распределение известно с точностью до конечного числа параметров, а непараметрические методы не…

Параметрические и непараметрические методы – это методы математической статистики, в параметрических методах генеральное распределение известно с точностью до конечного числа параметров, а непараметрические методы не предполагают знания функционального вида генеральных распределений.
Параметрическая статистика Параметрическая статистика – это научная дисциплина, изучающая количественную сторону массовых общественных явлений, представленных в числовой форме, и выявляющая отношения между ними

Параметрическая статистика – это научная дисциплина, изучающая количественную сторону массовых общественных явлений, представленных в числовой форме, и выявляющая отношения между ними.
Параметрическая статистика Основанием параметрических методов являются вполне вероятные предположения о характере распределения случайной величины

Основанием параметрических методов являются вполне вероятные предположения о характере распределения случайной величины. Чаще всего эти методы используются в анализе экспериментальных данных и предположении нормальности распределения этих данных.
Метод параметрического анализа имеет достоинство, заключающееся в том, что обладает высокой мощностью, т.е. способностью избегать ошибки второго рода или β-ошибки.
Параметрическая статистика Параметрические тесты требуют специальных метрических шкал для описания имеющихся данных

Параметрические тесты требуют специальных метрических шкал для описания имеющихся данных. Интервальная шкала и шкала отношений, которую называют абсолютной шкалой, относятся к метрическим шкалам.
С помощью интервальной шкалы исследователь может выяснить отношения равенства или неравенства элементов выборки, может оценить эквивалентность интервалов.
Абсолютная шкала оценивает эквивалентность отношений между элементами множества, которые получают в ходе измерения.
Исходя из этого, метрические шкалы относятся к сильным измерительным шкалам, поэтому параметрические методы точно выражают различия в распределении случайной величины при условии истинности гипотез.
Параметрическая статистика Параметрическая статистика имеет постоянное число параметров и делает больше предположений

Параметрическая статистика имеет постоянное число параметров и делает больше предположений. При правильности дополнительных предположений, параметрические методы дают более точные оценки. При неправильности предположений параметрические методы могут исследователя ввести в заблуждение. Параметрические формулы, однако, просты, их можно быстро записать и так же быстро вычислить.
Параметрическая статистика Методы параметрической статистики, которые рассматриваются во всех руководствах по статистике, относятся к рабочим инструментам в решении многих задач

Методы параметрической статистики, которые рассматриваются во всех руководствах по статистике, относятся к рабочим инструментам в решении многих задач.
Для решения этих задач требуется большой статистический материал, что на практике оказывается недостаточно эффективно.
Гипотезы о законе распределения и согласования выборки проверяются при помощи различных критериев.
Параметрическая статистика При использовании параметрических критериев заключение о случайности или неслучайности различий между выборочными совокупностями происходит на основании сравнения параметров распределений

При использовании параметрических критериев заключение о случайности или неслучайности различий между выборочными совокупностями происходит на основании сравнения параметров распределений.
Каждый из этих параметров, отражает характерные свойства распределения данной случайной величины в виде единственного числа – это количественные меры этих свойств.
Параметрическая статистика На практике рассматривают два параметра – среднее значение и дисперсию, но чаще всего, стандартное отклонение, которое является мерой вариации

На практике рассматривают два параметра – среднее значение и дисперсию, но чаще всего, стандартное отклонение, которое является мерой вариации. Оба эти параметра имеют два популярных параметрических критерия:
критерий Стьюдента,
критерий Фишера.
КРИТЕРИЙ СТЬЮДЕНТА - МЕТОД ОЦЕНКИ

КРИТЕРИЙ СТЬЮДЕНТА - МЕТОД ОЦЕНКИ ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ ВЕЛИЧИН
t-критерий Стьюдента используется для определения статистической значимости различий средних величин. Может применяться как в случаях сравнения независимых выборок (например, группы больных сахарным диабетом и группы здоровых), так и при сравнении связанных совокупностей (например, средняя частота пульса у одних и тех же пациентов до и после приема антиаритмического препарата).
ТОЧНЫЙ КРИТЕРИЙ ФИШЕРА Точный критерий

ТОЧНЫЙ КРИТЕРИЙ ФИШЕРА
Точный критерий Фишера в основном применяется для сравнения малых выборок. Этому есть две весомые причины. Во-первых, вычисления критерия довольно громоздки и могут занимать много времени или требовать мощных вычислительных ресурсов. Во-вторых, критерий довольно точен (что нашло отражение даже в его названии), что позволяет его использовать в исследованиях с небольшим числом наблюдений.
Особое место отводится точному критерию Фишера в медицине. Это важный метод обработки медицинских данных, нашедший свое применение во многих научных исследованиях. Благодаря ему можно исследовать взаимосвязь определенных фактора и исхода, сравнивать частоту патологических состояний между двумя группами исследуемых
Непараметрическая статистика Непараметрическая статистика — раздел статистики, который не базируется исключительно на параметризованных семействах вероятностных распределений (примером могут служить матожидание и дисперсия)

Непараметрическая статистика — раздел статистики, который не базируется исключительно на параметризованных семействах вероятностных распределений (примером могут служить матожидание и дисперсия).
Непараметрическая статистика включает в себя описательную статистику и статистический вывод.
Непараметрическая статистика Непараметрическими называются такие методы, при которых не происходит выдвижение каких-либо предположений о характере распределения исследуемых данных

Непараметрическими называются такие методы, при которых не происходит выдвижение каких-либо предположений о характере распределения исследуемых данных.
Непараметрическая статистика Преимущество непараметрической статистики полно раскрывается тогда, когда полученные в эксперименте результаты, оказываются представлены в слабой неметрической шкале, представляя собой результаты ранжирования

Преимущество непараметрической статистики полно раскрывается тогда, когда полученные в эксперименте результаты, оказываются представлены в слабой неметрической шкале, представляя собой результаты ранжирования.
Эта шкала носит название шкалы порядка.
Непараметрическая статистика Непараметрические методы широко используются для изучения популяций, которые принимают ранжированный порядок (например, обзоры фильмов, которые могут получать от одной до четырех звезд)

Непараметрические методы широко используются для изучения популяций, которые принимают ранжированный порядок (например, обзоры фильмов, которые могут получать от одной до четырех звезд). Использование непараметрических методов может быть необходимым, когда данные имеют ранжирование, но не имеют ясной численной интерпретации, например, при оценке предпочтений. С точки зрения шкал, результатами работы непараметрических методов являются порядковые данные.
Непараметрическая статистика Наиболее часто используемые методы:

Наиболее часто используемые методы:
Анализ сходства: проверяет статистическую значимость различия между группами состоящими выборок;
Критерий Андерсона-Дарлинга: проверяет принадлежность анализируемой выборки данному закону распределения;
Бутстрэп: позволяет просто и быстро оценивать разные статистики для сложных моделей;
Дисперсионный анализ Фридмана: применяется для исследования влияния разных значений фактора (градаций фактора) на одну и ту же выборку;
Оценка Каплана-Майера: оценивает функцию выживаемости по данным времени жизни;
Тау-коэффициент Кендалла: измеряет статистическую зависимость между двумя переменными;
W Кендалла: непараметрическая статистика, которая измеряет степень сходства между двумя ранжированиями и может быть использован для оценки значимости отношения между ними;
Двухвыборочный критерий Колмогорова—Смирнова: используется для проверки гипотезы о принадлежности двух независимых выборок одному закону распределения;

Двухвыборочный критерий Колмогорова—Смирнова: используется для проверки гипотезы о принадлежности двух независимых выборок одному закону распределения;
Дисперсионный анализ Краскела—Уоллиса: проверяет гипотезу о том, имеют ли сравниваемые выборки одно и то же распределение или же распределения с одной и той же медианой;
Критерий согласия Кёйпера: используется для проверки того, противоречит ли данное распределение или семейство распределений признакам выборки данных;
Логарифмический ранговый (логранговый) критерий: сравнение распределений выживаемости двух выборок;
U-критерий Манна — Уитни: используется для оценки различий между двумя независимыми выборками по уровню какого-либо признака, измеренного количественно;
Критерий хи-квадрата МакНемара: проверяет, значимо или нет различаются между собой несколько сравниваемых переменных, принимающих значения 0 / 1;
Медианный критерий: проверяет гипотезу о том, что распределения двух выборок имеют одинаковую форму и отличаются только сдвигом на константу;

Медианный критерий: проверяет гипотезу о том, что распределения двух выборок имеют одинаковую форму и отличаются только сдвигом на константу;
Критерий Зигеля-Туки: проверка на различия в масштабе между двумя группами;
Критерий знаков: применяется в ситуациях, когда два измерения (например, при разных условиях) одних и тех же субъектов нужно проверить на наличие или отсутствие различия результатов;
Критерий квадратов рангов: проверяет равенство дисперсий в двух или более выборках;
Критерий Туки-Дакворта: проверяет, был ли одна из двух выборок значительно больше другой;
Критерий серий Вальда—Вольфовица: проверяет, являются ли элементы последовательности взаимно независимыми / случайными;
Критерий Уилкоксона: используемый для проверки различий между двумя выборками парных измерений.
Что такое параметрическая статистика?
Что такое непараметрическая статистика?
Непараметрическая статистика также известна как статистика без распределения. Преимущество этого типа статистики заключается в том, что он не должен делать предположений, как ранее было сделано с параметризацией. Расчеты непараметрической статистики обращают внимание на медианы, а не на средние. Следовательно, если одно или два отклонения от среднего значения не учитываются. Обычно параметрическая статистика предпочтительнее, чем это, потому что она имеет больше возможностей для отклонения ложной гипотезы, чем непараметрический метод. Одним из самых известных непараметрических тестов является критерий хи-квадрат. Существуют непараметрические аналоги для некоторых параметрических тестов, таких как T-критерий Вилкоксона для парного выборочного t-критерия, U-критерий Манна-Уитни для t-критерия независимых выборок, корреляция Спирмена для корреляции Пирсона и т. Д. Для одного образца t-критерия не существует сопоставимый непараметрический тест.
В чем разница между параметрическим и непараметрическим?
• Параметрическая статистика зависит от нормального распределения, но непараметрическая статистика не зависит от нормального распределения.
• Параметрическая статистика делает больше предположений, чем непараметрическая статистика.
• Параметрическая статистика использует более простые формулы по сравнению с непараметрической статистикой.
• Если предполагается, что популяция имеет нормальное или близкое к нормальному распределению распределение, лучше всего использовать параметрическую статистику. Если нет, лучше всего использовать непараметрический метод.
• Большинство общеизвестных методов элементарной статистики относятся к параметрической статистике. Непараметрическая статистика используется редко и применяется в особых случаях.
Читайте также: