
Организация поиска информации в сети интернет кратко
Обновлено: 02.07.2024
Проблема поиска во Всемирной паутине не в том, что информации мало, а в том, что ее много. Поиск информации в Интернете — краеугольный камень эффективной работы в Сети. Владение навыками поиска делает Интернет для пользователя полезным как во время работы, так и во время отдыха.
Для организации поиска в Интернете существуют специализированные службы, называемые поисковыми системами.
Поисковые системы.
Принципы работы поисковых систем
Поисковые системы работают, храня информацию о многих web -страницах, которые они получают из HTML страниц. Основные составляющие поисковой системы: поисковый робот, индексатор, поисковик. Обычно системы работают поэтапно. Сначала поисковый робот получает контент, затем он просматривает содержимое web -сайтов. Только после этого индексатор генерирует доступный для поиска индекс. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы.
В основе работы большинства современных поисковиков лежит индекс цитирования, который вычисляется индексатором в результате анализа ссылок на текущую страницу с других страниц Интернета. Чем их больше, тем выше индекс цитирования анализируемой страницы, тем выше эта страница будет отображена в результатах поиска и тем выше страница будет представлена в списке найденных ресурсов.
Правила построения поисковых запросов
Зарубежные поисковые серверы: Google ( www . google . com ); Altavista ( www . altavista . com ) и Yahoo ! ( www . yahoo . com ).
Для поиска на русском языке лучше подходят российские серверы, на иностранном — зарубежные, хотя, Google неплохо справляется с поиском на многих языках. Несмотря на заявления многих владельцев поисковых систем, что запросы могут быть написаны практически на языке, который люди используют для общения между собой, это далеко не так. Благодаря внедрению новых языковых технологий поисковые системы стали гораздо лучше понимать пользователя. Поисковики теперь ищут не только запрашиваемое слово, но и его словоформы, что позволяет делать результаты поиска более точными. Например, если в поисковом запросе присутствует слово умный, то его результаты будут содержать не только это слово, но и его производные: умного, умная, а также ум и даже разум. Естественно, страницы со словоформами будут не в числе первых результатов поиска, но элементы искусственного интеллекта налицо. Этот факт полезно учитывать при построении поисковых запросов.
Следует помнить о том, что поисковые системы при обработке запроса не учитывают регистр символов, а применять знаки препинания в поисковых запросах вовсе не обязательно, так как они также игнорируются поисковыми серверами. Однако при построении сложных расширенных запросов, результаты поиска по которым обычно гораздо ближе к ожидаемым, используют традиционные знаки препинания. Большинство поисковых систем может бороться с опечатками. Если поисковому серверу покажется, что в слове допущена ошибка или опечатка, то он предупредит об этом той же фразой: Быть может, вы искали….
Cлова для запроса поисковому серверу
Расширенный поиск

Рассмотрим дополнительные возможности, которые можно использовать на странице расширенного поиска: указать собственное местоположение (Москва), указать в каком виде должна быть представлена информация (Тип файла), период времени в котором ищем информацию (за сутки, за 2 недели, за месяц, От..До), на каком языке должна быть представлена информация (Русский, Английский Еще), а также можно указать URL -адрес сайта и т.д
Выбор (Точно как в запросе) указывается поисковику для того, чтобы морфологию слов запроса не изменять, а искать только ту форму слова, которая задана.
Язык запросов
Поиск документов, в которых обязательно присутствует выделенное слово.
Допустимо использовать несколько операторов + в одном запросе.
Поиск по цитате.
Поиск документов, содержащих слова запроса в заданной последовательности и форме.
Будут найдены документы, содержащие данную цитату.
Поиск по цитате с пропущенным словом (словами).
Один оператор * соответствует одному пропущенному слову.
Внимание! Используется только в составе оператора ".
Оператор отделяется пробелами.
Будут найдены документы, содержащие данную цитату, включая пропущенное слово.
Будут найдены документы, содержащие данную цитату, включая пропущенные слова.
Для поиска информации используются специальные внешние службы - поисковые серверы: поисковые машины и каталоги.
Поисковые машины - это такие серверы, которые накапливают информацию о содержимом сайтов автоматически, при помощи специальных программ-роботов.
Информацию для серверов-каталогов отбирают люди. В отличие от поисковых машин, информация в каталогах более точно структурирована, причем в вертикальном иерархическом виде.
И поисковые машины, и каталоги являются внешними службами или, как их еще называют, автономными системами. Особенностью автономных систем является то, что цикл работы с информацией выполняется полностью непосредственно на этой системе, начиная с получения информации от первоисточника и заканчивая предоставлением поискового сервиса конечному пользователю.
Каталоги WWW, содержащие большое количество записей, часто размещают на своих страницах локальные поисковые машины. Реализуемые в виде традиционных шаблонов, которые мало чем отличаются от шаблонов на автоматических индексах.
Как для поисковых машин, так и для каталогов устанавливается некий принцип отбора информации. Этот принцип закладывается либо в алгоритмы работы поисковых машин, либо в регламент работы людей (для каталогов). В зависимости от того, откуда и какой тип информации накапливается, оценивают две характеристики автономных систем - пространственный масштаб и специализацию.
Пространственный масштаб призван ограничить количество первоисточников информации до некоего конечного предела. Например, поисковая система может быть построена в рамках только одного сайта. Поиск может быть ограничен рамками одного географического домена (например, ru). Такие системы называют региональными.
Существует множество поисковых серверов, которые не имеют подобных ограничений. Их называют глобальными информационно-поисковыми системами.
Наиболее популярные поисковые сервера загружены настолько, что возникает необходимость в создании "зеркал" (mirrors). Зеркала должны содержать точную копию первичной поисковой системы и гарантировать быстрое обслуживание обращений, поступающих из определенной географической зоны.
4.5.2. Метапоисковые системы
Еще одним перспективным направлением развития поисковых сервисов в сети является использование метапоисковых систем. Основа метапоисковых систем - это интерфейс между пользователем и множеством поисковых систем. Метапоисковая система не предназначена для индексирования и накопления информации. назначение ее - чистый поиск и обработка результатов поиска.
Метасистема позволяет, в соответствии с пожеланиями пользователя, ограничить свой поиск определенными поисковыми серверами, проверять существование ресурсов, на которые указывают результаты поиска, осуществлять уточненный поиск в результатах поиска и т.д. Метапоисковые системы часто называют клиентами к поисковым серверам.
Основной чертой метапоисковых систем нового поколения является объединение поисковых серверов различных специализаций. В рамках одного приложения можно осуществлять поиск информации различного типа. При обработке поискового запроса допускается соединение более чем со 100 поисковыми системами (в т.ч. и со специализированными). Результаты поиска дополнительно обрабатываются: ссылки, дублирующие уже найденные, системой исключаются; полученные адреса проверяются на доступность. Есть возможность конфигурации работы с поисковыми серверами (можно выбрать серверы, с которыми будет работать система, указать максимальное число ссылок, получаемых с каждого сервера и т.д.).
Однако и в случае использования метапоисковых систем не обойтись без знаний о традиционных поисковых серверах - именно они служат базой для всякого поиска.
Поиск информации в Интернете проводится двумя основными способами – с помощью каталогов (их еще называют директориями) и с помощью поисковых машин.
Директории обеспечивают контекстный поиск для структурированного просмотра, тогда как поисковые машины, как следует из их названия, контекста не обеспечивают, однако позволяют находить конкретные слова или фразы.
Директории можно уподобить оглавлению книги, а поисковые машины – предметному указателю.
Часто поисковые системы объединяют в себе как поисковую машину, так и директории.
Это хорошо видно на примере первой страницы Яндекса, где под поисковой строкой размещается список директорий, которые позволяют пользователю уточнять запрос по мере продвижения в глубь каждой из них.
Все поисковые машины работают по одному и тому же алгоритму и основаны на одних и тех же принципах. Различия между ними возникают лишь на уровне технической реализации этих принципов в работе.
Чтобы понять принцип работы поисковой машины, попробуем разделить вопрос на две части: на чем основан поиск и как он реализован.
Все поисковые машины базируются на трех основных операторах, лежащих в основе Булевой алгебры (ее также называют Булевой логикой или Boolean).
Если мы не сделаем специальных ограничительных оговорок, то материалы, в которых оба эти слова присутствуют, также будут найдены.
Часто встречается чуть более сложный вариант написания запроса, который содержит все или почти все вышеперечисленные операторы. В этом случае лучше пользоваться таким элементом, как круглые скоби. Скобки позволяют отделять однотипные слова запроса от остальных. Кроме того, самому составителю при этом визуально гораздо удобнее различать отдельные фрагменты запроса. Мы не будем чересчур теоретизировать о скобках, а просто продемонстрируем работу указанного элемента на конкретных примерах. На наш взгляд, так будет понятнее, как и для чего используются скобки.
Так, запрос пушистые И (собаки ИЛИ кошки)
выдаст документы, в которых написано про пушистых собак или пушистых кошек, но не будет содержать текстов, где одновременно будут упомянуты и кошки, и собаки.
Еще раз повторимся, все поисковые машины сегодня работают на основе анализа этих трех операторов, хотя нюансы их написания в разных поисковых машинах могут отличаться.
Каждая полноценная поисковая машина располагает собственным штатом роботов, или пауков. Их еще называют краулерами (crawlers) и спайдерами (spiders,). Это программы, которые перескакивают со страницы на страницу и сканируют находящиеся на них тексты, не вникая при этом в их содержание. После чего сбрасывают документы на серверы своих хозяев и идут к следующим страницам. Как паук определяет, куда ему пойти? Он находит так называемую гиперссылку (ту самую, при наведении на которую курсор приобретает вид раскрытой ладони, и при клике по которой происходит переход на другую страницу) и идет по ней. Вот почему, если на страницу не ведет ни одна ссылка, паук на нее тоже не придет. Исключение составляет ситуация, когда владелец страницы вручную сообщит о ней поисковой машине, заполнив специальную форму на сайте поисковой машины.
На сервере поисковой машины текст разбивается на отдельные слова, каждому из которых присваиваются координаты, после чего они заносятся в таблицу сервера вместе со ссылкой на тот адрес в Интернете, по которому текст размещался в момент посещения его пауком.
Сам по себе поисковик представляет собой большую локальную сеть, состоящую из мощных компьютеров с огромным объемом дисковой памяти. Эти машины разделены на подгруппы (так называемые кластеры), между которыми распределяется информация, собранная пауками.
Когда поисковая система получает запрос, она ищет ответ именно в своей таблице, а не в Интернете.
При этом важно понять, как паук решает, с какой частотой ему следует посещать ту или иную страницу. Выглядит этот алгоритм приблизительно следующим образом. Поработав со страницей, паук возвращается на нее, н у, например, через две недели. И если видит, что никаких изменений не произошло, он планирует следующее посещение через более длительный период – скажем, через месяц. А если и тогда не обнаружит ничего нового, то наведаетсяя сюда еще позже, месяца через полтора-два.
Вот почему нередко бывает так, что поисковая машина по запросу результат выдает, а попытка перейти на страницу по полученной ссылке безрезультатна – вероятнее всего, никакой страницы уже просто не существует на прежнем месте, но паук на нее давно не заходил, и, соответственно, поисковая система о ее удалении не знает.
Весь комплекс процессов, описанных выше, называется индексацией.
До середины 1960-х годов компьютеров было немного. Изолированные друг от друга, они не могли обмениваться информацией.
По мере того, как количество присоединенных к Интернету машин увеличивалось, объективно назрел вопрос о необходимости инструментов, позволяющих легко находить текст и другие файлы на удаленном компьютере, в идеале – на любом, где бы он ни располагался в Сети.
Доступ к файлам на самых ранних этапах развития Интернета осуществлялся в два этапа, каждый из которых выполнялся вручную: специальные команды вводились с клавиатуры. Кстати, тогда компьютеры могли управляться лишь специалистами, способными вводить команды в соответствующую строку. Графического интерфейса, позволяющего комфортно работать с машиной неподготовленному человеку, еще не изобрели. Так вот первым делом с помощью программы Telnet устанавливалось прямое соединение с компьютером, на котором находится нужный файл. На данном этапе лишь налаживалась связь, ничего и никуда в этот момент еще не передавалось. И только затем с помощью специальной программы – FTP – можно было этот конкретный файл взять.
Очевидно, что на поиски нужного документа уходила масса времени: требовалось знать точный адрес компьютера, на котором он находится.
Между тем файлов становилось все больше, интерес к ним постоянно рос, и для того, чтобы найти адрес одного из них, обычно приходилось обращаться в дискуссионные группы с просьбой о помощи и в надежде на то, что кто-нибудь из собеседников подскажет заветный адрес, по которому хранится нужная информация.
В результате, стали появляться специальные FTP-серверы, которые представляли собой хранилище файлов, организованных в директории, по принципу хранения информации на персональном компьютере. Такие серверы существуют и по сей день.
Этот каталог затем обрабатывался и хранился в центральной базе данных, внутри которой можно было организовать поиск. Поиск на собственном компьютере к тому моменту существовал уже издавна и, несмотря на то, что тоже требовал ввода команд, трудностей в работе не создавал. Однако без специальной подготовки использовать компьютер полноценно человек не мог. База данных находилась в университете Мак Джилл и обновлялась ежемесячно.
Программа показывала пользователю последовательно возникающие пошаговые меню, что позволяло ему без проблем идти в глубь базы директорий, все более приближаясь к специфическим документам, которые и составляли цель поиска. Этот алгоритм, по сути, сохранен и сегодня в Каталогах, расположенных в Интернете.
Стало возможно получать как текстовые документы, так и графические, и музыкальные, без привязки к какому-то определенному формату. А самое главное, стало в принципе возможно легко найти и получить в Интернете нужную информацию.
Объективно назревала идея, согласно которой компьютеры разных платформ должны иметь возможность работать в одном протоколе, позволяющем просматривать страницы вне зависимости от того, на какой конкретно машине эти страницы созданы. Требовалось придумать такой универсальный протокол и сделать его удобным для пользователей. Первым, кто догадался объединить известную к тому времени простую форму гипертекста с универсальными коммуникационными протоколами, был Тим Бернерс-Ли (Tim Berners-Lee).
Чтобы пользователь получил в руки независимый от платформы и при этом простой инструмент, Бернерс-Ли создал HTML (HyperText Markup Language, то есть Язык гипертекстовой разметки). Все Web-документы, отформатированные с помощью тегов HTML, видны совершенно одинаково во всем мире, вне зависимости от типа компьютера, на котором человек открыл страницу сайта. Поэтому и сегодня при переводе файла в формат HTML, например, на машине, работающей под управлением операционной системы MacOS, можно быть уверенным в том, что этот файл будет выглядеть точно так же и на компьютере, работающем под управлением Windows.
Но Бернерс-Ли хотел видеть Интернет как информационное пространство, в котором можно получить свободный доступ к данным любых типов. На ранних этапах развития глобальной Сети преобладали простые текстовые документы HTML. К тому времени существовали системы поиска информации на локальных машинах, поэтому появилось несколько серверов, которые пытались проиндексировать какую-то часть страниц Web и прежде, чем отправляться за чем-то в Интернет, предлагали поискать необходимые сведения на этих серверах.
При этом основная проблема заключалась в том, чтобы отыскать страницы, которые в принципе можно бы было индексировать. Поскольку Интернет лишен централизованной структуры и общего оглавления, единственный способ, позволявший добиться этого, состоял в поиске ссылки на страницу и переходе по этой ссылке, с последующим добавлением найденного ресурса к индексу.
Ну а далее ситуация развивалась еще более стремительно. Крис Шерман и Гари Прайс приводят такую хронологию возникновения и развития современных поисковых машин.
1994 г. – WebCrawler, Lycos, Yahoo!
1995 г. – Infoseek, SavvySearch, AltaVista, MetCrawler, Excite. Появление метапоисковых машин.
1996 г. – HotBot, LookSmart.
1997 г. – NorthernLight.
2000 г. и далее – Сотни новых поисковых машин.
Русскоязычные поисковые машины появлялись в такой последовательности:
Прежде, чем перейти к описанию языка запросов поисковых машин, рассмотрим, из каких элементов, с которыми предстоит работать пауку, состоит обычно сайт.
Надо сказать, что язык HTML достаточно прост и логичен. Он представляет собой способ разбивки текста с помощью специальных элементов – тегов, которые определяют структуру и внешний вид текста при просмотре его в браузере. О тегах следует знать, что они всегда парные и что они бывают открывающими (обозначают начало определенного форматирования) и закрывающими (обозначают его окончание). Закрывающий тег – такой же по написанию, как открывающий, но перед ним стоит косая черта.
Приведем пример очень простого сайта (рис. 1).

Рис. 1. Пример сайта, как его видно в браузере Мозилла Файрфокс.
– жирный (пишется под тегом );
– курсив (пишется под тегом );
Основной текст сайта, вне зависимости от того, каким вариантом шрифта он написан, располагается внутри тега . Именно содержимое тега представляет собой основной объект для паука и рассматривается им как текст страницы (собственно, это действительно текст страницы).
Применительно к сайту, который мы рассматривали на рис. 1, этот исходный код будет выглядеть следующим образом:
Здесь можно увидеть все элементы, описанные нами выше. Кроме того, в исходном коде видны теги
, которые обеспечивают расположение текста в новой строке и с промежутком по отношению к тексту, расположенному в предыдущей строке.
Разметка HTML по умолчанию не предполагает переноса текста и его форматирования. Поэтому текст, не содержащий никаких тегов, воспроизводится подряд, но с соблюдением пробелов между словами. Для того чтобы текст оказался написан не просто в новой строке, а с промежутком относительно находящейся выше строки, используется, как мы уже показали, тег
, а для того, чтобы текст был написан в новой строке, но без промежутка между выше– и нижерасположенной строками, применяется тег
.
Начало сайта, созданного с помощью разметки HTML, отмечено тегом , а его окончание – тегом .

Полезные советы

Поиск по сайту
Поиск информации в Интернете
Для поиска информации в обычно используются три способа (См. Рис.1). Первый из них - поиск по адресу. Он применяется, когда пользователю известен адрес информационного ресурса, содержащего необходимую ему информацию. При организации поиска информации по адресу (форма адреса - IP, доменный или URL - в этом случае значения не имеет) пользователю достаточно просто ввести адрес ресурса в соответствующее поле браузера – программы, предназначенной для обеспечения доступа к сетевым ресурсам.
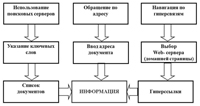
Рис. 1. Способы поиска информации в гипертекстовых базах данных
Второй – поиск с помощью навигации по гиперсвязям. При использовании этого вида поиска случае пользователь сначала должен получить доступ к серверу, связанному с соответствующей БД. После этого можно найти документ, используя гиперссылки. Очевидно, что этот способ удобен, когда адрес ресурса неизвестен пользователю. Для использования в качестве исходной точки для поиска при реализации этого способа предназначены Web-порталы - серверы, предоставляющие прямой доступ к некоторому множеству серверов, включая установленные на них информационные ресурсы, а также Web-приложения, которые реализуют Web-сервисы, соответствующие назначению портала. Доступные через портал серверы могут относиться к определенной системе (например - корпоративной) или различным системам и быть специально подобраны по видовому, тематическому или другим признакам документов и данных, содержащихся на их сайтах. Обычно порталы совмещают в себе разнообразные функции с целью удержать клиента как можно дольше. Доминирующим сервисом портала является сервис справочной службы: поиск, рубрикаторы, финансовые индексы, информация о погоде и т.д. Если Web-сайты в большинстве случаев представляют собой наборы статических Web-страниц, то порталы являются совокупностями программных средств и заранее неструктурированной информации, которую эти средства превращают в структурированные данные по запросу конкретных пользователей.
Третий способ поиска предполагает использование поисковых серверов Интернета. Поисковыми серверами называют выделенные хост - компьютеры, в которых размещаются базы данных ресурсов Интернета. Пользовательский интерфейс такого сервера имеет поле для ввода ключевых слов, описывающих тему, интересующую пользователя (См. Рис. 2).
Рис.2. Вид окна поискового сервера системы Яндекс
Табл. 1. Наиболее популярные поисковые системы
Примечание: Рунет – это русскоязычная часть Интернета, составляющая домены с именами ru и рф.
Необходимо упомянуть, что существует особая категория поисковых серверов – метапоисковые системы. Их принципиальное отличие от поисковых машин и предметных каталогов состоит в том, что у них отсутствует собственная индексная база данных, и поэтому они, получив запрос пользователя, перенаправляют его сразу к нескольким поисковым серверам (См. Рис. 3).
Читайте также: