
Организация доступа к данным адресация доступа кратко
Обновлено: 04.07.2024
Физическая организация файла – способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Размещение файла в виде связанного списка кластеров. В начале каждого кластера содержится указатель на следующий кластер. В отличие от предыдущего способа, каждый кластер может быть присоединен к цепочке кластеров какого-либо файла, следовательно, фрагментация на уровне кластеров отсутствует. Файл может изменять свой размер во время своего существования, наращивая число кластеров. Недостатки – сложность реализации доступа к произвольному месту файла; количество данных файла, содержащихся в одном кластере, не равно степени двойки (одно слово израсходовано на номер следующего кластера), а многие программы читают данные кластерами, размер которых равен степени двойки.
Использование связанного списка индексов. Модификация предыдущего способа. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент – индекс. Индексы располагаются в отдельной области диска – в MS-DOS это таблица FAT (File Allocation Table), занимающая один кластер. Когда память свободна, все индексы имеют нулевое значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого кластера становится равным либо номеру М следующего кластера данного файла, либо принимает специальное значение, являющееся признаком того, что этот кластер является для файла последним. Индекс же предыдущего кластера файла принимает значение N, указывая на вновь назначенный кластер. При такой физической организации сохраняются все достоинства предыдущего способа: минимальность адресной информации, отсутствие фрагментации, отсутствие проблем при изменении размера. Дополнительные преимущества: 1) высокая скорость доступа (для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера). 2) Данные файла заполняют кластер целиком, а значит, имеют объем, равный степени двойки. Недостаток: Вся таблица должна постоянно находиться в ОП.
Перечисление номеров кластеров (или метод i-узлов), занимаемых этим файлом. Этот перечень и служит адресом файла. С каждым файлом связана структура данных i-узел, содержащая также атрибуты файла. Недостаток: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Достоинства: высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла; фрагментация на уровне кластеров отсутствует; каждый i-узел должен находиться в ОП только тогда, когда соответствующий ему файл открыт.
Модифицированный подход перечисления номеров кластеров используется в традиционных файловых системах ОС UNIX s5 и ufs и в наиболее распространенных файловых системах ОС Linux – ext2fs, ext3fs (последняя отличается от первой только наличием журналирования). Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным.
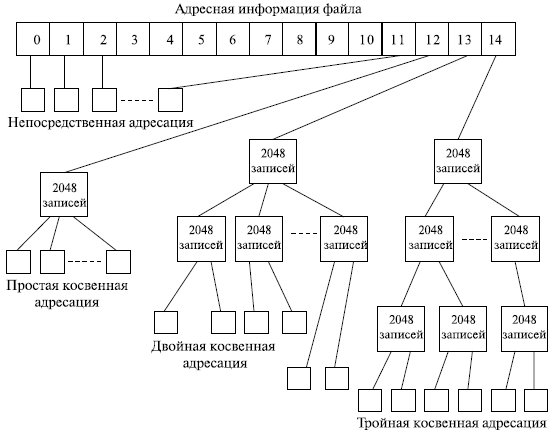
В стандартной для UNIX ФС ufs используется следующая схема адресации кластеров файла (рис. 18.1). Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт. Если размер файла меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса.
Если размер файла превышает 12 кластеров, то следующее 13-е поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров файла. Если размер файла превышает 12+2048 = 2060 кластеров, то используется 14-е поле, в котором находится номер кластера, содержащего 2048 номеров кластеров, каждый из которых хранят 2048 номеров кластеров данных файла. Здесь применяется уже двойная косвенная адресация. И, наконец, если файл включает более 12+2048+2048 =4 196 364 кластеров, то используется последнее 15-е поле для тройной косвенной адресации.
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, используемой в ОС Windows NT/2000. Здесь он дополнен достаточно естественным приемом, сокращающим объем адресной информации: адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область, называемая группой (в ext2fs), или экстентом (extent), описывается с помощью двух чисел: начального номера кластера и количества кластеров в отрезке. Так как для сокращения времени операции обмена ОС старается разместить файл в последовательных кластерах диска, то в большинстве случаев количество последовательных областей файла будет меньше количества кластеров файла и объем служебной адресной информации в NTFS сокращается по сравнению со схемой адресации файловых систем ufs/s5.
Вопросы для самоконтроля
1. Что такое физическая организация файловой системы?
2. Какой типичный размер сектора диска?
3. В чем разница между физическим форматированием диска и логическим форматированием?
4. Что такое физическая организация файла?
5. Что представляет собой i-узел?
6. Перечислите и кратко опишите методы размещения файлов.
7. Какие преимущества и недостатки у метода непрерывного размещения файла?
8. Используется ли в современных операционных системах метод непрерывного размещения файла?
Физическая организация файла – способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Размещение файла в виде связанного списка кластеров. В начале каждого кластера содержится указатель на следующий кластер. В отличие от предыдущего способа, каждый кластер может быть присоединен к цепочке кластеров какого-либо файла, следовательно, фрагментация на уровне кластеров отсутствует. Файл может изменять свой размер во время своего существования, наращивая число кластеров. Недостатки – сложность реализации доступа к произвольному месту файла; количество данных файла, содержащихся в одном кластере, не равно степени двойки (одно слово израсходовано на номер следующего кластера), а многие программы читают данные кластерами, размер которых равен степени двойки.
Использование связанного списка индексов. Модификация предыдущего способа. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент – индекс. Индексы располагаются в отдельной области диска – в MS-DOS это таблица FAT (File Allocation Table), занимающая один кластер. Когда память свободна, все индексы имеют нулевое значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого кластера становится равным либо номеру М следующего кластера данного файла, либо принимает специальное значение, являющееся признаком того, что этот кластер является для файла последним. Индекс же предыдущего кластера файла принимает значение N, указывая на вновь назначенный кластер. При такой физической организации сохраняются все достоинства предыдущего способа: минимальность адресной информации, отсутствие фрагментации, отсутствие проблем при изменении размера. Дополнительные преимущества: 1) высокая скорость доступа (для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера). 2) Данные файла заполняют кластер целиком, а значит, имеют объем, равный степени двойки. Недостаток: Вся таблица должна постоянно находиться в ОП.
Перечисление номеров кластеров (или метод i-узлов), занимаемых этим файлом. Этот перечень и служит адресом файла. С каждым файлом связана структура данных i-узел, содержащая также атрибуты файла. Недостаток: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Достоинства: высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла; фрагментация на уровне кластеров отсутствует; каждый i-узел должен находиться в ОП только тогда, когда соответствующий ему файл открыт.
Модифицированный подход перечисления номеров кластеров используется в традиционных файловых системах ОС UNIX s5 и ufs и в наиболее распространенных файловых системах ОС Linux – ext2fs, ext3fs (последняя отличается от первой только наличием журналирования). Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным.
В стандартной для UNIX ФС ufs используется следующая схема адресации кластеров файла (рис. 18.1). Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт. Если размер файла меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса.
Если размер файла превышает 12 кластеров, то следующее 13-е поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров файла. Если размер файла превышает 12+2048 = 2060 кластеров, то используется 14-е поле, в котором находится номер кластера, содержащего 2048 номеров кластеров, каждый из которых хранят 2048 номеров кластеров данных файла. Здесь применяется уже двойная косвенная адресация. И, наконец, если файл включает более 12+2048+2048 =4 196 364 кластеров, то используется последнее 15-е поле для тройной косвенной адресации.
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, используемой в ОС Windows NT/2000. Здесь он дополнен достаточно естественным приемом, сокращающим объем адресной информации: адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область, называемая группой (в ext2fs), или экстентом (extent), описывается с помощью двух чисел: начального номера кластера и количества кластеров в отрезке. Так как для сокращения времени операции обмена ОС старается разместить файл в последовательных кластерах диска, то в большинстве случаев количество последовательных областей файла будет меньше количества кластеров файла и объем служебной адресной информации в NTFS сокращается по сравнению со схемой адресации файловых систем ufs/s5.
Вопросы для самоконтроля
1. Что такое физическая организация файловой системы?
2. Какой типичный размер сектора диска?
3. В чем разница между физическим форматированием диска и логическим форматированием?
4. Что такое физическая организация файла?
5. Что представляет собой i-узел?
6. Перечислите и кратко опишите методы размещения файлов.
7. Какие преимущества и недостатки у метода непрерывного размещения файла?
8. Используется ли в современных операционных системах метод непрерывного размещения файла?
Записи логического файла идентифицируются с помощью уникальной последовательности символов или некоторого числа — ключа. Таким ключом обычно является значение поля, расположенное в каждой записи в одной и той же позиции. Иногда бывает необходимо объединить несколько полей, чтобы обеспечить уникальность ключа, который в этом случае называется сцепленным ключом.
В некоторых файлах записи имеют несколько ключей. Запись ЗАКУПКА может иметь различные НОМЕР ПОСТАВЩИКА и НОМЕР ПОКУПАТЕЛЯ, каждый из которых является ключом.
Во многих приложениях требуется идентифицировать записи по ключам, которые не являются уникальными. Однако при этом все равно должен существовать один уникальный ключ, тот, который используется для размещения записи в файле и выборки ее из файла. Такой ключ называется первичным ключом или идентификатором.
Основную проблему при адресации файла можно сформулировать следующим образом: как по первичному ключу определить местоположение записи с данным ключом? Как надо организовать набор записей чтобы поиск потребовал как можно меньше затрат?
При разработке схем адресации файлов и определяемого ими размещения записей в файлах большое значение имеет вопрос о том, как включаются в файл новые записи и удаляются старые.
Последовательное сканирование файла.Наиболее простым способом локализации записи является сканирование файла с проверкой ключа каждой записи. Этот способ, однако, требует слишком много времени и может применяться, когда каждая запись все равно должна быть прочитана.
Блочный поиск.Если записи упорядочены по ключу, то при сканировании файла не требуется чтения каждой записи. ЭВМмогла бы, например, просматривать каждую сотую запись в последовательности возрастания ключей. При нахождении записи с ключом большим, чем искомое значение, просматриваются последние 99 записей, которые были пропущены.
Этот способ называется блочным поиском. Записи группируются в блоки и каждый блок проверяется по одному разу до тех пор, пока не будет найден нужный блок. Иногда данный способ называют поиском с пропусками.
Двоичный поиск.При двоичном поиске в файле записей, упорядоченных по ключу, анализируется запись, находящаяся в середине поисковой области файла (изначально всего файла), а ее ключ сравнивается с поисковым ключом. Затем поисковая область делится пополам, и процесс повторяется для соответствующей половины области, пока не будет обнаружено искомое значение или длина области не станет равной 1. Число сравнений в этом случае будет меньше, чем для случая блочного поиска.
Двоичный поиск эффективен для поиска в файлах, организованных в виде двоичного дерева с указателями, когда поиск происходит в направлении, задаваемом указателями. Кроме того, добавление в файл новых записей не приводит ксдвигу других записей, что требует много времени и является достаточно сложной процедурой.
Таким образом, двоичный поиск более пригоден для поиска в индексе файла, чем в самом файле.
Индексно-последовательные файлы.Если файл упорядочен по ключам, то для адресации может использоваться таблица, называемая индексом, связывающая ключ хранимой записи с ее относительным или абсолютным адресом во внешней памяти.
Индекс можно определить как таблицу, с которой связана процедура, воспринимающая на входе информацию о некоторых значениях атрибутов и выдающая на выходе информацию, способствующую быстрой локализации записи или записей, которые имеют заданные значения атрибутов.
Если записи файла упорядочены по ключу, индекс обычно содержит не ссылки на каждую запись, а ссылки на блоки записей, внутри которых можно выполнять поиск или сканирование. Хранение ссылок на блоки записей, а не на отдельные записи в значительной степени уменьшает размер индекса. Причем даже в этом случае индекс часто оказывается слишком большим для поиска, и поэтому используется индекс индекса.
Индексно-произвольные файлы.Произвольный (не упорядоченный по ключу) файл можно индексировать точно так же, как и последовательный файл. Однако при этом индекс должен содержать по одному элементу для каждой записи файла, а не для блока записей. Более того, в нем должны содержаться полные абсолютные (или относительные) адреса, в то время как в индексе последовательного файла адреса могут содержаться в усеченном виде, так как старшие знаки последовательных адресов будут совпадать.

Произвольные файлы в основном используются для обеспечения возможности адресации записей файла с несколькими ключами. Если файл упорядочен по одному ключу, то он не упорядочен по другому ключу. Для каждого типа ключей может существовать свой индекс: для упорядоченных ключей индекс будет иметь по одному элементу на блок записей, для других ключей индексы будут более длинными, так как должны будут содержать по одному элементу для каждой записи. Ключ, который чаще всего используется при адресации файла, обычно служит для его упорядочения.
В индексно-произвольных файлах часто используются символические, а не абсолютные адреса, так как при добавлении новых или удалении старых записей изменяется местоположение записей. Если в записях имеется несколько ключей, то индекс вторичного ключа может содержать в качестве выхода первичный ключ записи. При определении же местоположения записи по ее первичному ключу можно использовать какой-нибудь другой способ адресации. По этому методу поиск осуществляется медленнее, чем поиск, при котором физический адрес записи определяется по индексу. В файлах, в которых положение записей часто изменяется, символическая адресация может оказаться предпочтительнее.
Адресация с помощью ключей, преобразуемых в адрес.Известно много методов преобразования ключа непосредственно в значение адреса в файле. В тех случаях, когда возможно преобразование значения ключа непосредственно в значение адреса в файле, такой способ адресации обеспечивает самый быстрый доступ; при этом нет необходимости организовывать поиск внутри файла или выполнять операции с индексами.
В некоторых приложениях адрес может быть вычислен на основе значений некоторых элементов данных записи.
К недостаткам данного способа относится малое заполнение файла: в файле остаются свободные участки, поскольку ключи преобразуются не в непрерывное множество адресов.
Другим недостатком схем прямой адресации является их малая гибкость. Машинные адреса записей могут измениться при обновлении файла. Для устранения этого недостатка прямую адресацию обычно выполняют в два этапа. Сначала ключ преобразуется впорядковый номер, который затем преобразуется в машинный адрес.
Хэширование.Простым и полезным способом вычисления адреса является хэширование (перемешивание). В данном методе ключ преобразуется в квазислучайное число, которое используется для определения местоположения записи.
Более экономичным является указание на область, в которой размещается группа записей. Эта область называется участком записей (slot, bucket).
При первоначальной загрузке файла адрес, по которому должна быть размещена запись, определяется следующим образом:
1. Ключ записи преобразуется в квазислучайное число, находящееся в диапазоне от 1 до числа участков, используемых для размещения записей.
2. Число преобразуется в адрес участка и, если на участке есть свободное место, то логическая запись размещается на нем.
3. Если участок заполнен, запись должна быть размещена на участке переполнения — следующий по порядку участок либо участок в отдельной области переполнения.
При чтении записей из файла их поиск выполняется аналогично, причем может оказаться, что для поиска записи потребуется чтение нескольких участков переполнения.
Из-за вероятностной природы алгоритма в этом способе не удается достичь 100 % плотности заполнения памяти, однако для большинства файлов может быть достигнута плотность 80 или 90 %; при этом память для индексов не требуется. Большинство записей можно найти за одно обращение, но для некоторых потребуется второе обращение (при переполнении). Для очень небольшой части записей потребуется третье или четвертое обращение к файлу.
Кроме того, в этом случае менее эффективно используется память, чем в индексных методах; записи не упорядочены для последовательной обработки.
Комбинации способов адресации.При адресации записей некоторых файлов используются комбинации перечисленных выше способов. Например, с помощью индекса может определяться ограниченная поисковая область файла, затем эта область просматривается последовательно, либо в ней выполняется двоичный поиск. С помощью алгоритма прямой адресации может определяться нужный раздел индекса, и, таким образом, исчезает необходимость поиска во всем индексе.
Записи логического файла идентифицируются с помощью уникальной последовательности символов или некоторого числа — ключа. Таким ключом обычно является значение поля, расположенное в каждой записи в одной и той же позиции. Иногда бывает необходимо объединить несколько полей, чтобы обеспечить уникальность ключа, который в этом случае называется сцепленным ключом.
В некоторых файлах записи имеют несколько ключей. Запись ЗАКУПКА может иметь различные НОМЕР ПОСТАВЩИКА и НОМЕР ПОКУПАТЕЛЯ, каждый из которых является ключом.
Во многих приложениях требуется идентифицировать записи по ключам, которые не являются уникальными. Однако при этом все равно должен существовать один уникальный ключ, тот, который используется для размещения записи в файле и выборки ее из файла. Такой ключ называется первичным ключом или идентификатором.
Основную проблему при адресации файла можно сформулировать следующим образом: как по первичному ключу определить местоположение записи с данным ключом? Как надо организовать набор записей чтобы поиск потребовал как можно меньше затрат?
При разработке схем адресации файлов и определяемого ими размещения записей в файлах большое значение имеет вопрос о том, как включаются в файл новые записи и удаляются старые.
Последовательное сканирование файла.Наиболее простым способом локализации записи является сканирование файла с проверкой ключа каждой записи. Этот способ, однако, требует слишком много времени и может применяться, когда каждая запись все равно должна быть прочитана.
Блочный поиск.Если записи упорядочены по ключу, то при сканировании файла не требуется чтения каждой записи. ЭВМмогла бы, например, просматривать каждую сотую запись в последовательности возрастания ключей. При нахождении записи с ключом большим, чем искомое значение, просматриваются последние 99 записей, которые были пропущены.
Этот способ называется блочным поиском. Записи группируются в блоки и каждый блок проверяется по одному разу до тех пор, пока не будет найден нужный блок. Иногда данный способ называют поиском с пропусками.
Двоичный поиск.При двоичном поиске в файле записей, упорядоченных по ключу, анализируется запись, находящаяся в середине поисковой области файла (изначально всего файла), а ее ключ сравнивается с поисковым ключом. Затем поисковая область делится пополам, и процесс повторяется для соответствующей половины области, пока не будет обнаружено искомое значение или длина области не станет равной 1. Число сравнений в этом случае будет меньше, чем для случая блочного поиска.
Двоичный поиск эффективен для поиска в файлах, организованных в виде двоичного дерева с указателями, когда поиск происходит в направлении, задаваемом указателями. Кроме того, добавление в файл новых записей не приводит ксдвигу других записей, что требует много времени и является достаточно сложной процедурой.
Таким образом, двоичный поиск более пригоден для поиска в индексе файла, чем в самом файле.
Индексно-последовательные файлы.Если файл упорядочен по ключам, то для адресации может использоваться таблица, называемая индексом, связывающая ключ хранимой записи с ее относительным или абсолютным адресом во внешней памяти.
Индекс можно определить как таблицу, с которой связана процедура, воспринимающая на входе информацию о некоторых значениях атрибутов и выдающая на выходе информацию, способствующую быстрой локализации записи или записей, которые имеют заданные значения атрибутов.
Если записи файла упорядочены по ключу, индекс обычно содержит не ссылки на каждую запись, а ссылки на блоки записей, внутри которых можно выполнять поиск или сканирование. Хранение ссылок на блоки записей, а не на отдельные записи в значительной степени уменьшает размер индекса. Причем даже в этом случае индекс часто оказывается слишком большим для поиска, и поэтому используется индекс индекса.
Индексно-произвольные файлы.Произвольный (не упорядоченный по ключу) файл можно индексировать точно так же, как и последовательный файл. Однако при этом индекс должен содержать по одному элементу для каждой записи файла, а не для блока записей. Более того, в нем должны содержаться полные абсолютные (или относительные) адреса, в то время как в индексе последовательного файла адреса могут содержаться в усеченном виде, так как старшие знаки последовательных адресов будут совпадать.
Произвольные файлы в основном используются для обеспечения возможности адресации записей файла с несколькими ключами. Если файл упорядочен по одному ключу, то он не упорядочен по другому ключу. Для каждого типа ключей может существовать свой индекс: для упорядоченных ключей индекс будет иметь по одному элементу на блок записей, для других ключей индексы будут более длинными, так как должны будут содержать по одному элементу для каждой записи. Ключ, который чаще всего используется при адресации файла, обычно служит для его упорядочения.
В индексно-произвольных файлах часто используются символические, а не абсолютные адреса, так как при добавлении новых или удалении старых записей изменяется местоположение записей. Если в записях имеется несколько ключей, то индекс вторичного ключа может содержать в качестве выхода первичный ключ записи. При определении же местоположения записи по ее первичному ключу можно использовать какой-нибудь другой способ адресации. По этому методу поиск осуществляется медленнее, чем поиск, при котором физический адрес записи определяется по индексу. В файлах, в которых положение записей часто изменяется, символическая адресация может оказаться предпочтительнее.
Адресация с помощью ключей, преобразуемых в адрес.Известно много методов преобразования ключа непосредственно в значение адреса в файле. В тех случаях, когда возможно преобразование значения ключа непосредственно в значение адреса в файле, такой способ адресации обеспечивает самый быстрый доступ; при этом нет необходимости организовывать поиск внутри файла или выполнять операции с индексами.
В некоторых приложениях адрес может быть вычислен на основе значений некоторых элементов данных записи.
К недостаткам данного способа относится малое заполнение файла: в файле остаются свободные участки, поскольку ключи преобразуются не в непрерывное множество адресов.
Другим недостатком схем прямой адресации является их малая гибкость. Машинные адреса записей могут измениться при обновлении файла. Для устранения этого недостатка прямую адресацию обычно выполняют в два этапа. Сначала ключ преобразуется впорядковый номер, который затем преобразуется в машинный адрес.
Хэширование.Простым и полезным способом вычисления адреса является хэширование (перемешивание). В данном методе ключ преобразуется в квазислучайное число, которое используется для определения местоположения записи.
Более экономичным является указание на область, в которой размещается группа записей. Эта область называется участком записей (slot, bucket).
При первоначальной загрузке файла адрес, по которому должна быть размещена запись, определяется следующим образом:
1. Ключ записи преобразуется в квазислучайное число, находящееся в диапазоне от 1 до числа участков, используемых для размещения записей.
2. Число преобразуется в адрес участка и, если на участке есть свободное место, то логическая запись размещается на нем.
3. Если участок заполнен, запись должна быть размещена на участке переполнения — следующий по порядку участок либо участок в отдельной области переполнения.
При чтении записей из файла их поиск выполняется аналогично, причем может оказаться, что для поиска записи потребуется чтение нескольких участков переполнения.
Из-за вероятностной природы алгоритма в этом способе не удается достичь 100 % плотности заполнения памяти, однако для большинства файлов может быть достигнута плотность 80 или 90 %; при этом память для индексов не требуется. Большинство записей можно найти за одно обращение, но для некоторых потребуется второе обращение (при переполнении). Для очень небольшой части записей потребуется третье или четвертое обращение к файлу.
Кроме того, в этом случае менее эффективно используется память, чем в индексных методах; записи не упорядочены для последовательной обработки.
Комбинации способов адресации.При адресации записей некоторых файлов используются комбинации перечисленных выше способов. Например, с помощью индекса может определяться ограниченная поисковая область файла, затем эта область просматривается последовательно, либо в ней выполняется двоичный поиск. С помощью алгоритма прямой адресации может определяться нужный раздел индекса, и, таким образом, исчезает необходимость поиска во всем индексе.
Модуль 8. Управление данными
Тема 15. Способы доступа и организации файлов. Распределение файлов на диске
С точки зрения внутренней структуры (логической организации) файл - это совокупность однотипных записей, каждая из которых информирует о свойствах одного объекта. Записи могут быть фиксированной длины, переменной длины или неопределенной длины. Записи переменной длины в своем составе содержат длину записи, а неопределенной длины – специальный символ конца записи.
При этом каждая запись может иметь идентификатор, представляющий собой ключ, который может быть сложным и состоять из нескольких полей.
Существует три способа доступа к данным, расположенным во внешней памяти:
- Физически последовательный по порядку размещения записи в файле.
- Логически последовательный в соответствии с упорядочением по значению ключей. Для выполнения упорядочения создается специальный индексный файл, в соответствии с которым записи представляются для обработки.
- Прямой - непосредственно по ключу или физическому адресу записи.
Для организации доступа записи должны быть определенным образом расположены и взаимосвязаны во внешней памяти. Есть несколько способов логической организации памяти.
Записи располагаются в физическом порядке и обеспечивают доступ в физической последовательности. Таким образом, для обработки записи с номером N+1 необходимо последовательно обратиться к записям с номером 1, 2,….,N. Это универсальный способ организации файла периферийного устройства. Используется так же для организации входного/выходного потока.
Индексно-последовательный.
Записи располагаются в логической последовательности в соответствии со значением ключей записи. Физически записи располагаются в различных местах файла. Логическая последовательность файла фиксируется в специальной таблице индексов, в которой значение ключей связывается с физическим адресом записи. При такой организации доступ к записям осуществляется логически последовательно в порядке возрастания или убывания значения ключа или по значению ключа.
Место записи в файле, ее физический адрес, определяется алгоритмом преобразования для ключа. Доступ к записям возможен только прямой. Алгоритм преобразования ключа называется хешированием. Ключ, использующий алгоритм хеширования, преобразуется в номер записи.
Это организация, при которой осуществляется прямой доступ по порядковому номеру записи или по физическому адресу.
Организация, в которой файл состоит из последовательных подфайлов (разделов), первый из которых является оглавлением и содержит имена и адреса остальных подфайлов. При такой организации осуществляется комбинированныйдоступ: индексный прямой к разделу и последовательный в разделах.
Определить права доступа к файлу - значит определить для каждого пользователя набор операций, которые он может применить к данному файлу. В разных файловых системах может быть определен свой список дифференцируемых операций доступа. Этот список может включать следующие операции:
- создание файла;
- уничтожение файла;
- открытие файла;
- закрытие файла;
- чтение файла;
- запись в файл;
- дополнение файла;
- поиск в файле;
- получение атрибутов файла;
- установление новых значений атрибутов;
- переименование;
- выполнение файла;
- чтение каталога;
- и другие операции с файлами и каталогами.
В самом общем случае права доступа могут быть описаны матрицей прав доступа, в которой столбцы соответствуют всем файлам системы, строки - всем пользователям, а на пересечении строк и столбцов указываются разрешенные операции. В некоторых системах пользователи могут быть разделены на отдельные категории. Для всех пользователей одной категории определяются единые права доступа. Например, в системе UNIX все пользователи подразделяются на три категории: владельца файла, членов его группы и всех остальных. Различают два основных подхода к определению прав доступа:
- избирательный доступ, когда для каждого файла и каждого пользователя сам владелец может определить допустимые операции;
- мандатный подход, когда система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу (в данном случае файлу) в зависимости от того, к какой группе пользователь отнесен.
Физически том дисковой памяти - это отдельный носитель внешней памяти, представляющий собой совокупность блоков данных. Блок - это единица физической передачи данных (единица обмена данных с устройством). Запись - это единица ввода/вывода программы. Блок может содержать несколько логических записей, что минимизирует число операций ввода/вывода (рис.1).
Рисунок 1. Коэффициент блокирования 7
Физически файл - это совокупность выделенных блоков памяти (область внешней памяти). Существует два вида организации накопителей на магнитном диске:
1.Трековый, в котором весь диск подразделяется на треки (дорожки) фиксированной длины, на которых размещаются блоки переменного размера. Адресом блока является тройка:
Единицей выделения памяти является трек или цилиндр. Цилиндр представляет собой область памяти, образованную всеми дорожками, доступными на магнитных поверхностях без перемещения магнитных головок.
2.Секторный, в котором диск разбивается на блоки фиксированного размера, обычно кратного 256 байтам. Адресом блока является его порядковый номер на носителе.
Работа с дисковой памятью включает в себя 4 основные процедуры:
- Инициализация тома (форматирование).
- Выделение и освобождение памяти файлу.
- Уплотнение внешней памяти (дефрагментация).
- Копирование, восстановление томов для обеспечения целостности.
- форматирования диска на дорожки (сектора);
- определения сбойных участков диска;
- присвоения метки тому;
- создания оглавления тома;
- записи ОС, если это необходимо.
Выделение и освобождение места для файлов на томе аналогично стратегии размещения ОП.
- Непрерывное распределение памяти, когда файлу выделяется непрерывный участок памяти. Для задания адреса файла в этом случае достаточно указать только номер начального блока. Достоинство этого метода - простота. Очевидный недостаток - проблема расширения файла и фрагментация. Уплотнение или дефрагментация используется для восстановления памяти.
- Секторное или блочное распределение, когда файлу выделяется логически связанные блоки, физически размещенные в любом месте. При таком способе в начале каждого блока содержится указатель на следующий блок. В этом случае адрес файла также может быть задан одним числом - номером первого блока. В отличие от предыдущего способа, каждый блок может быть присоединен в цепочку какого-либо файла и, следовательно, фрагментация отсутствует. Файл может изменяться во время своего существования, наращивая число блоков. Недостатком является сложность реализации доступа к произвольно заданному месту файла: для того чтобы прочитать пятый по порядку блок файла, необходимо последовательно прочитать четыре первых блока, прослеживая цепочку номеров блоков.
Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является использование связанного списка индексов. С каждым блоком (кластером) связывается некоторый элемент - индекс. Индексы располагаются в отдельной области диска (в MS-DOS это таблица FAT). Если некоторый блок распределен файлу, то индекс этого блока содержит номер следующего блока данного файла. При этом для каждого файла в каталоге имеется поле, в котором отмечается номер начального индекса для кластера, входящего в файл. Последний индекс содержит специальный маркер конца файла. Такая физическая организация сохраняет все достоинства предыдущего способа и снимает отмеченный недостаток: для доступа к произвольному месту файла достаточно прочитать только блок индексов, отсчитать нужное количество блоков файла по цепочке и определить номер нужного блока.
В некоторых файловых системах запросы к внешним устройствам, в которых адресация осуществляется блоками (диски, ленты), перехватываются промежуточным программным слоем-подсистемой буферизации. Подсистема буферизации представляет собой буферный пул, располагающийся в оперативной памяти, и комплекс программ, управляющих этим пулом и позволяющий выполнять опережающее считывание блоков файла при последовательном доступе. Каждый буфер пула имеет размер, равный одному блоку. При поступлении запроса на чтение некоторого блока подсистема буферизации просматривает свой буферный пул и, если находит требуемый блок, то копирует его в буфер запрашивающего процесса. Операция ввода-вывода считается выполненной, хотя физического обмена с устройством не происходило. Очевиден выигрыш во времени доступа к файлу. Если же нужный блок в буферном пуле отсутствует, то он считывается с устройства и одновременно с передачей запрашивающему процессу копируется в один из буферов подсистемы буферизации. При отсутствии свободного буфера на диск вытесняется наименее используемая информация. Таким образом, подсистема буферизации работает по принципу кэш-памяти. Кроме того, буферизация позволяет одновременно обрабатывать программой текущий блок и читать/писать в другие буфера следующий блок.

Субъект доступа – это лицо или процесс, действия которого регламентируются правилами разграничения доступа: учетная запись, пользователь или иная сущность, выполняющая какие-либо действия с объектами доступа.
Объект доступа – это единица информационного ресурса автоматизированной системы, доступ к которой регламентируется правилами разграничения доступа: файл, документ или иной объект, с которым взаимодействует субъект доступа.
Дискреционная модель управления доступом (Discretionary Access Control, DAC, от англ. Discretion – по усмотрению) – владелец объекта сам устанавливает и меняет права доступа субъектов. Минусы данной модели:
• Нет гарантий конфиденциальности информации при чтении данных из одного документа и записи в другой документ с другими правами доступа;
• Игнорирование атрибутов прав доступа при копировании файла на другое устройство (другой домен, другая ОС).

Мандатная модель управления доступом (Mandatory Access Control, MAC, от англ. Mandatory - обязательный) – использование меток/грифов конфиденциальности (англ. Classification) для объектов доступа и формы допуска (англ. Clearance) для субъектов доступа.
Основные правила (для защиты от утечек информации):
• Чтение только объектов, чей уровень безопасности не выше уровня субъекта доступа;
• Запись только в те объекты, чей уровень безопасности не ниже уровня субъекта доступа.
Ролевая модель управления доступом (Role-Based Access Control, RBAC) – предоставление прав доступа ролям (по функционалу), применяется для упрощения администрирования.
RBAC позволяет реализовать:
• Статическое разделение полномочий – невозможность одновременного присвоения субъекту нескольких ролей (например, для противодействия мошенничеству);
• Динамическое разделение полномочий – роли могут быть присвоены, но в каждый конкретный момент можно выполнять функции только одной из ролей (например, залогиниться только под кем-то одним).
Контенто-зависимая модель управления доступом (Content-dependent Access Control) – предоставление доступа субъекту в зависимости от содержания объекта (прообраз DLP-системы предотвращения утечек данных).
Контекстно-зависимая модель управления доступом (Context-dependent Access Control) – предоставление доступа субъекту в зависимости от предыдущего запроса для невозможности агрегировать информацию (не даем субъекту больше, чем он должен знать, анализируя его предыдущие запросы).
Риск-ориентированная модель управления доступом (Risk-Based/Adaptable Access Control) – предоставление доступа к объекту в зависимости от уровня риска субъекта доступа (IP-адрес, история ранее выполненных действий, скоринговый балл, иные атрибуты) и от ИБ-свойств самого объекта (атрибуты объекта, состояние защищенности, наличие инцидентов/уязвимостей на нем).
Права доступа к объекту описываются в ACL (access control list), состоящем из ACE (access control entries). Права доступа субъекта описываются в его Capability table.
Факторы аутентификации:
1. То, что субъект знает: пароли, парольные фразы, ключевые слова, контрольные вопросы.
2. То, чем субъект владеет: OTP, токены (программные, аппаратные), номер мобильного телефона, смарт-карты.
3. То, чем субъект является: биометрия (отпечатки пальцев, сетчатки глаз, радужной оболочки глаз, голос, изображение, походка).

OTP (one-time password) устройства:
1.1. time-based synchronization (TOTP): OTP получается смешиванием (имитовставкой) секретного ключа и текущего времени, этот OTP отправляется серверу вместе с ID пользователя, сервер сравнивает то, что он сам получил (время+ключ) и то, что пришло от пользователя. Есть некая временная дельта, в пределах которой сработает OTP.
Примеры второго фактора: ruToken,RSA SecurID, FIDO U2F, Google/Microsoft Authenticator
FAR - false acceptance rate – уровень ложного предоставления доступа (пустили злоумышленника в помещение).
FRR - false rejection rate – уровень ложного отказа в доступе (не пускаем легитимного пользователя).
CER - crossover error rate – уровень пересечения ошибок (чем он ниже, тем более точная система, т.е. при приемлемом уровне false acceptance/rejection мы сохраняем высокий процент прохода легитимных юзеров).
На графике CER – это точка, в которой кривые false rejection rate и false acceptance rate пересекаются (т.е. когда false rejection rate = false acceptance rate).

Ошибки I рода (False Positive) (ложноположительные срабатывания) – неверно детектируем чистое письмо как спам.
True Positive – спам верно задетектировали как спам.
True Negative – чистое письмо верно задетектировали как чистое.

NTLM - NT LAN Manager, протокол сетевой аутентификации в инфраструктуре Microsoft. Основан на использовании NTLM-хэша пароля пользователя в качестве секретного ключа и на знании сервером NTLM-хэша пароля пользователя для его аутентификации. Старые версии LM, NTLMv1 небезопасны, не применяются.
NTLMv2 – взаимная аутентификация клиента и сервера, использование меток времени (для исключения накопления и повторного использования устаревших данных аутентификации).
Атака Pass The Hash - возможность использования NTLM-хэша от пароля пользователя для получения доступа к ресурсам из-под его УЗ по NTLM-хэшу, без необходимости получения самого пароля.
Утилиты для атаки Pass The Hash:
• Mimikatz – получение NTLM-хэшей и их повторное использование для имперсонации учетной записи.
• Procdump (официальная утилита Microsoft) – доступ к памяти системного процесса lsass.exe, хранящего NTLM-хэши, для последующего брутфорса или повторного использования.
• Работа с hiberfil.sys (файл, хранящий данные ОЗУ во время гибернации – закрытие крышки ноутбука).
Kerberos - протокол сетевой аутентификации для гетерогенных сред, использует симметричное шифрование. Также основан на использовании NTLM-хэша пароля пользователя в качестве секретного ключа и на знании Керберос-сервером NTLM-хэша пароля пользователя для его аутентификации. Пароли (хэши) не передаются по сети, не требуется множественная аутентификация для работы с различными сервисами в пределах Керберос-домена, происходит взаимная аутентификация клиента и сервера.
1. KDC (key distribution center) - содержит в себе все закрытые ключи (secret key) пользователей и сервисов, они доверяют KDC. KDC - единая точка отказа, должен быть всегда online.
2. AS (authentication service) - компонент KDC, принимает запросы от пользователей.
3. TGS (ticket granting service) - компонент KDC, который принимает запросы на сессионные ключи (TGS-тикеты/мандаты) и выдаёт их.
4. TGT (ticket granting ticket) - тикет/мандат, который выдаётся AS'ом в зашифрованном виде клиенту на некоторое время (Windows default setting - 10 часов), далее клиент его использует для подтверждения того, что он уже был авторизован.
Описание процесса аутентификации с использованием Керберос:
1. Клиент обращается к AS для получения TGT. Клиент пересылает данные (идентификатор клиента, метку времени и идентификатор сервера), зашифрованные NTLM-хэшем от пароля (секретным ключом) клиента. Этот пакет данных называется AS-REQ.
Этот пакет данных называется TGS-REP.
Схема работы Керберос:
Domain Controller = KDC+AS
Application Server = сервис, требующийся клиенту, работающему на User’s Workstation

Атаки на Kerberos:
• доступ к сессионным ключам;
• доступ к секретным ключам (NTLM-хэшам от паролей пользователей и сервисов).
Pass The Ticket - возможность использования пользовательского TGS или TGT-билета Керберос для получения доступа к ресурсам из-под УЗ (например, путем доступа к памяти процесса lsass.exe, в котором хранятся Керберос-тикеты).
Golden Ticket - возможность выдавать себя за любого пользователя в домене, используя NTLM-хэш учетной записи KRBTGT и выдавая любые TGT кому угодно.
Silver Ticket - возможность использования NTLM-хэша от пароля ПК или сервиса для создания TGS/TGT и получения доступа к ресурсам из-под этой УЗ.
Kerberoasting - возможность брутфорса и получения пароля сервисной УЗ в офлайне (без риска блокировки аккаунта).
Overpass The Hash - возможность подделки TGT любого пользователя при наличии NTLM-хэша от его пароля.
Защита учетных записей:
• Identity & Access Management системы
• HR-системы (актуальная информация)
• Системы токенизации (предоставление временного псевдо-пароля)
• Смарт-карты (вход не по паролю, а по сертификату)
• Программы повышения осведомленности
• Фишинговые учебные рассылки
• Работа с пользователями
• Доступ при наличии подтвержденной служебной необходимости и при наличии согласования от руководителя
Физическая организация выделяет способ размещения файлов на диске и учет соответствия блоков диска файлам. Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Наиболее часто используются следующие схемы размещения файлов:
- непрерывное размещение (непрерывные файлы);
- сводный список блоков (кластеров) файла;
- сводный список индексов блоков (кластеров) файла;
- перечень номеров блоков (кластеров) файла в структурах, называемых i-узлами (index-node – индекс-узел).
Простейший вариант физической организации – непрерывное размещение в наборе соседних кластеров (рис. 7.15a). Достоинство этой схемы – высокая скорость доступа и минимальный объем адресной информации, поскольку достаточно хранить номер первого кластера и объем файла. Размер файла при такой организации не ограничивается.
Однако у этой схемы имеется серьезный недостаток – фрагментация, возрастающая по мере удаления и записи файлов. Кроме того, возникает вопрос, какого размера область нужно выделить файлу, если при каждой модификации он может увеличить свой размер.
И все-таки есть ситуации, в которых непрерывные файлы могут эффективно использоваться и действительно широко применяются – на компакт-дисках. Здесь все размеры файлов заранее известны и не могут меняться.
Второй метод размещения файлов состоит в представлении файла в виде связного списка кластеров дисковой памяти (рис. 7.15б). Первое слово каждого кластера используется как указатель на следующий кластер . В этом случае адресная информация минимальна, поскольку расположение файла задается номером его первого кластера.
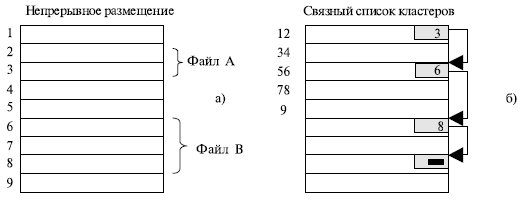
Кроме того, отсутствует фрагментация на уровне кластеров, а файл легко может изменять размер наращиванием или удалением цепочки кластеров. Однако доступ к такому файлу может оказаться медленным, так как для получения доступа к кластеру n операционная система должна прочитать первые n-1 кластеры. Кроме того, размер кластера уменьшается на несколько байтов, требуемых для хранения. Указателю это не очень важно, но многие программы читают и пишут блоками, кратными степени двойки.
Оба недостатка предыдущей схемы организации файлов могут быть устранены, если указатели на следующие кластеры хранить в отдельной таблице, загружаемой в память . Таким образом, образуется связный список не самих блоков (кластеров) файла, а индексов, указывающих на эти блоки (рис. 7.16).
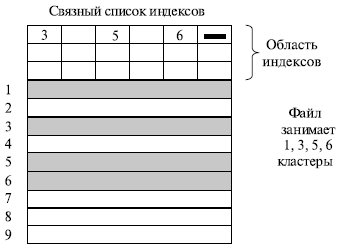
Такая таблица , называемая FAT -таблицей (File Allocation Table ), используется в файловых системах MS- DOS и Windows ( FAT 16 и FAT 32). Файлу выделяется память на диске в виде связного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. С каждым кластером диска связывается индекс . Индексы располагаются в FAT -таблице в отдельной области диска. Когда память свободна, все индексы равны нулю. Если некоторый кластер N назначен файлу, то индекс этого кластера либо становится равным номеру M следующего кластера файла, либо принимает специальное значение , являющееся признаком того, что кластер является последним для файла. Вообще индексы могут содержать следующую информацию о кластере диска (для FAT 32):
- не используется (Unused) – 0000.0000;
- используется файлом (Cluster in use by a file) – значение, отличное от 000.000, FFFF.FFFF и FFFF.FFF7;
- плохой кластер ( Bad cluster ) – FFFF.FFF7;
- последний кластер файла (Last cluster in a file) – FFFF.FFFF.
При такой организации сохраняются все достоинства второго метода организации файлов: отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами: для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать FAT -таблицу, отсчитать нужное количество кластеров файла по цепочке и определить номера нужного кластера. Во-вторых, данные файла заполняют кластер целиком в объеме, кратном степени двойки.
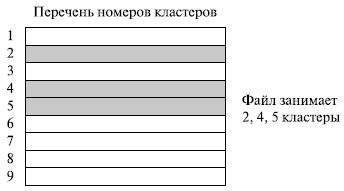
Еще один способ заключается в простом перечислении номеров кластеров, занимаемых файлом (рис. 7.17). Этот перечень и служит адресом файла. Недостаток такого подхода – длина адреса зависит от размера файла. Достоинства – высокая скорость доступа к произвольному кластеру благодаря прямой адресации, отсутствие внешней фрагментации.
Эффективный метод организации файлов, используемый в Unix -подобных операционных системах, состоит в связывании с каждым файлом структуры данных, называемой i-узлами. Такой узел содержит атрибуты файла и адреса кластеров файла (рис. 7.18). Преимущество такой схемы перед FAT -таблицей заключается в том, что каждый конкретный i-узел должен находиться в памяти только тогда, когда открыт соответствующий ему файл . Если каждый узел занимает n байт , а одновременно может быть открыто k файлов, то массив i-узлов займет в памяти k * n байт , что значительно меньше, чем FAT - таблица .
Это объясняется тем, что размер FAT -таблицы растет линейно с размером диска и даже быстрее, чем линейно, так как с увеличением количества кластеров на диске может потребоваться увеличить разрядность числа для хранения их номеров.
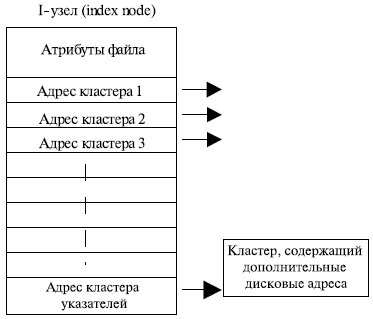
Достоинством i-узлов является также высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация . Фрагментация на уровне кластеров также отсутствует.
Однако с такой схемой связана проблема, заключающаяся в том, что при выделении каждому файлу фиксированного количества адресов кластеров этого количества может не хватить. Выход из этой ситуации может быть в сочетании прямой и косвенной адресации. Такой поход реализован в файловой системе ufs , используемой в ОС UNIX , схема адресации в которой приведена на рис. 7.19.
Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт . Если размер файлов меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт, то можно адресовать файл размеров до 8 Кбайт * 12 = 98304 байт . Если размер кластера превышает 12 кластеров, то следующее 13 поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров, и размер файла может возрасти до 8192 * (12 + 2048) = 16.875.520 байт .
Следующий уровень адресации, обеспечиваемый 14-м полем, позволяет адресовать до 8192 * (12 + 2048 + 20482) = 3,43766*1020 байт . Если и этого недостаточно, используется следующее 15-е поле . В этом случае максимальный размер файла может составить 8192 * (12 + 2048 + 20482 + 20483) = 7,0403*1013 байт .
При этом объеме самой адресной информации составит всего 0,05% от объема адресуемых данных (задачи. ).
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS , применяемой в Windows NT/2000/2003. Для сокращения объема адресной информации в NTFS адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область называется экстентом ( extent ) и описывается двумя числами: номером начального кластера и количеством кластеров.
Читайте также: