
Назовите основные операции над данными кратко
Обновлено: 30.06.2024
Данные - это совокупность сведений, зафиксированных на определенном носителе в форме, пригодной для постоянного хранения, передачи и обработки. Преобразование и обработка данных позволяет получить информацию.
Информация - это результат преобразования и анализа данных. Отличие информации от данных состоит в том, что данные - это фиксированные сведения о событиях и явлениях, которые хранятся на определенных носителях, а информация появляется в результате обработки данных при решении конкретных задач. Например, в базах данных хранятся различные данные, а по определенному запросу система управления базой данных выдает требуемую информацию.
Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой. По мере развития НТП и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают (постоянное усложнение условий управления производством и обществом + быстрые темпы появления и внедрения новых носителей/хранителей данных – увеличение объёма данных).
1. Сбор – накопление данных с целью обеспечения достаточной полноты информации для принятия решения;
2. Формализация – приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
4. Сортировка – упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
5. Группировка – объединение данных по заданному признаку с целью повышения удобства использования; повышает доступность информации;
6. Архивация – организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат на хранение данных и повышает общую надежность информационного процесса в целом;
7. Защита – комплекс мер, направленных на предотвращение утраты, воспроизведение и модификации данных;
8. Транспортировка – прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя – клиентом;
9. Преобразование – перевод данных из одной формы в другую или из одной структуры в другую. Пример: изменение типа носителя; книги – бумага, электронная форма, микрофотоплёнка. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных.
Универсальных опеределений нет.
Зна́ние — в теории искусственного интеллекта и экспертных систем — совокупность информации и правил вывода (у индивидуума, общества или системы ИИ) о мире, свойствах объектов, закономерностях процессов и явлений, а также правилах использования их для принятия решений. Главное отличие знаний от данных состоит в их структурности и активности, появление в базе новых фактов или установление новых связей может стать источником изменений в принятии решений.
Данные - это совокупность сведений, зафиксированных на определенном носителе в форме, пригодной для постоянного хранения, передачи и обработки. Преобразование и обработка данных позволяет получить информацию.
Информация - это результат преобразования и анализа данных. Отличие информации от данных состоит в том, что данные - это фиксированные сведения о событиях и явлениях, которые хранятся на определенных носителях, а информация появляется в результате обработки данных при решении конкретных задач. Например, в базах данных хранятся различные данные, а по определенному запросу система управления базой данных выдает требуемую информацию.
Для решения задачи данные обрабатываются на основании имеющихся знаний, информация анализируется с помощью знаний. На основе анализа предлагаются варианты решения, принимвается лучшее, пополняет знания.
Принятия решений осуществляются на основе полученной информации и имеющихся знаний. Принятие решений – это выбор наилучшего в некотором смысле варианта решения из множества допустимых на основании имеющейся информации.
DIKW (англ. data, information, knowledge, wisdom — данные, информация, знания, мудрость) — информационная иерархия, где каждый уровень добавляет определённые свойства к предыдущему уровню.
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером , а потребителя - клиентом ; • преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства - телефонные модемы .
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление , наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Чтобы выполнить любое их указанных выше действий, нужный элемент должен быть предварительно найден в информационном массиве, для чего выполняется его поиск (для добавления нового элемента тоже делается попытка его поиска, которая заканчивается неудачно, и тогда элемент добавляется). Под поиском элемента понимается определение его местонахождения в информационном массиве. Таким образом, любой доступ включает поиск, что делает эту фазу доступа наиболее значимой.
Технологии доступа при выполнении действий изменения элемента показана на рис. 79.
Здесь и далее сплошные линии означают управляющие связи, пунктирные - информационные связи.
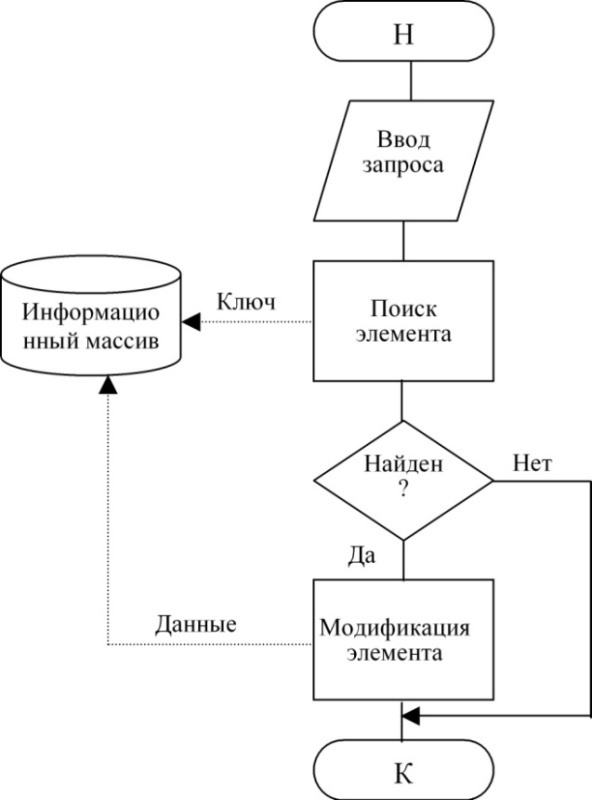
Рисунок 79. Технологии доступа при выполнении действий изменения элемента
Технологии доступа при выполнении действий добавления элемента показаны на рис. 80:
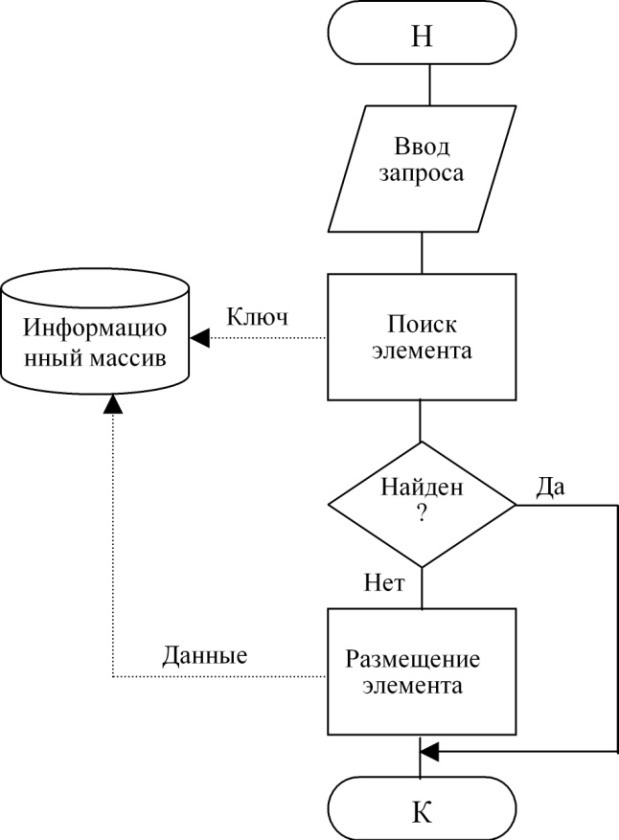
Рисунок 80. Технологии доступа при выполнении действий добавления элемента
Технология удаления изображена на рис. 81.
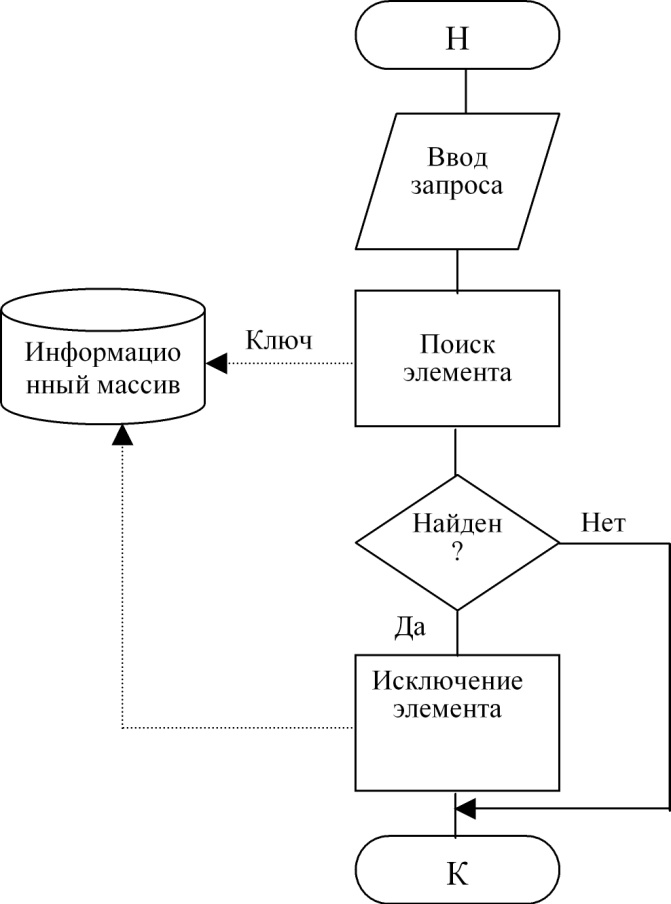
Рисунок 81. Технология удаления элемента
Технология просмотра элемента приведена на рис. 82. Различие в схемах состоит в том, что по технологии рис. 79 и 80 выполняется воздействие на информационный массив с целью его изменения, для чего в него передаются данные, по технологии рис. 81 воздействие не связано с передачей данных, а по схеме рис. 82 данные выводятся из информационного массива без его изменения.
При выполнении рассмотренных действий над элементами информационного массива на практике важны два фактора, противоречащие друг другу: временной фактор, в соответствии с которым запрос пользователя должен обрабатываться в минимальные сроки, и фактор минимизации требуемого объема памяти для хранения данных.
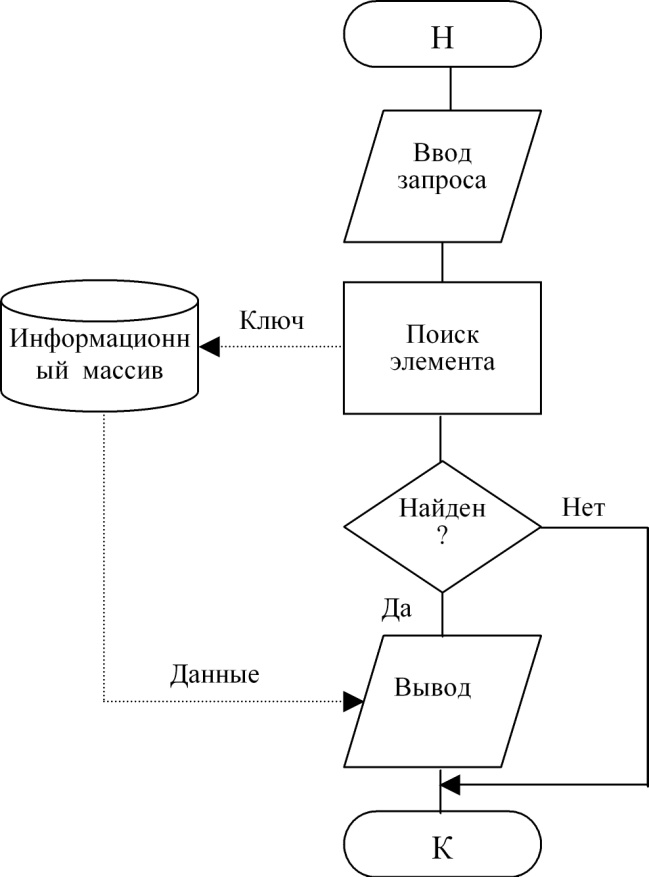
Рисунок 82. Технология просмотра элемента
Для уменьшения времени обработки запроса особые усилия прилагаются к применению таких структур хранения данных, которые позволяли бы оптимизировать поисковые операции, возможно, за счет дополнительных описаний данных. Это, очевидно, повышает расход памяти. Поэтому при проектировании моделей данных учитывается предполагаемый режим эксплуатации информационного массива: если это интерактивный режим, то основное внимание уделяется минимизации времени доступа к данным, если же режим пакетный, то минимизируют требуемую память. Кроме того, на выбор модели влияют особенности той предметной области, которая отражается в структурах хранения.
В силу вышесказанного, основное внимание в данном разделе уделено задачам организации хранения данных разных видов и поиска по ключам, входящим в запросы пользователей, поскольку поисковые операции и определяют, в основном, продолжительность различных действий над информационным массивом. Из приведенных типов действий в рассмотрение включены добавление и просмотр элементов данных, поскольку добавление связано с воздействием на информационный массив и изменением его объема (напомним, что удаление является обратным действием по отношению к добавлению), а просмотр - это наиболее часто выполняемые действия на практике. При этом рассматриваются общие вопросы работы с текстовой и структурированной информацией, методы и модели, используемые при организации хранения, поиска и добавления данных.
Излагаемые модели данных и алгоритмы доступа к ним составляют “brainware” современной информатики, носят универсальный характер и применяются в большинстве систем, связанных с хранением и обработкой информационных массивов.
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно короткое время и с достаточно большой точностью. Для этого (для оптимизации производительности запросов) производят индексирование некоторых полей таблицы. Использовать индексы полезно для быстрого поиска строк с указанным значением одного столбца. Без индекса чтение таблицы осуществляется по всей таблице, начиная с первой записи, пока не будут найдены соответствующие строки. Чем больше объем таблицы, тем выше накладные расходы. Если же таблица содержит индекс по рассматриваемым столбцам, то база данных может быстро определить позицию для поиска в середине файла данных без просмотра всех данных. Это происходит потому, что база данных помещает проиндексированные поля поближе в памяти, так, чтобы можно было побыстрее найти их значения. Для таблицы, содержащей 1000 строк, это будет как минимум в 100 раз быстрее по сравнению с последовательным перебором всех записей. Однако в случае, когда необходим доступ почти ко всем 1000 строкам, быстрее будет последовательное чтение, так как при этом не требуется операций поиска по диску. Так что иногда индексы бывают только помехой. Например, если копируется большой объем данных в таблицу, то лучше не иметь никаких индексов. Однако в некоторых случаях требуется задействовать сразу несколько индексов (например, для обработки запросов к часто используемым таблицам).
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, устанавливающим, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, который может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как описано выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
Строительными кирпичиками любого языка является элементарные типы данных с которыми мы можем работать. Зная их, мы всегда понимаем, что у нас хранится в той или иной переменной, что возвращает та или иная функция. Какие действия мы можем совершить над нашими данными. Это база. Поэтому именно этому я и хотел уделить внимание в данной статье в общем, а так же примерам работы с бинарными данными в частности.
Материал в первую очередь адресую тем кто только начал или хочет начать писать на Erlang-e. Но я постарался максимально полно охватить данный аспект языка и поэтому надеюсь, что написанное будет полезно и более продвинутой аудитории.
Первоначальный материал пришлось разделить на три части, в данной будут рассмотрены базовые типы языка, способы создания базовых типов и потребляемые ресурсы на каждый из типов.
Вступление
Для начала хочу выразить огромную признательность участникам русскоязычной рассылке по Erlang-у в Google-е за поднятие кармы и возможности выложить на хабр данную статью.
В процессе изложения будут приводиться примеры из командной оболочки (шелла) Эрланга. Поэтому нужно усвоить простые принципы работы. Каждая команда в шелле разделяется запятыми. При это совершенно не важно, производится набор в одну строку или в несколько.
1> X=1, Y = 2,
1> Z = 3,
1> S=4.
4
Указателем завершения ввода и запуск на выполнение является точка. При этом шелл выведет на экран значение возвращаемое последней из команд. В примере выше возвращается значение переменной S. Значения всех инициированных переменных запоминается, а так как в Эрланге нельзя переопределить значение инициированной переменной, то попытка переопределения приведет к ошибке:
3> f(Z).
ok
4> X = 4.
** exception error: no match of right hand side value 4
5> f().
ok
6> X = 4. %все, что идет после знака процента является комментарием
4
Для выхода достаточно ввести halt(), или вызвать интерфейс пользовательских команд Crtl+G и ввести q (команда h выведет справку). При выводе цифровых данных в шелле они приводятся к десятичному виду.
Изложенный материал относится к последней, актуальной на данный момент, версии 5.6.5. Для кодирования строк используется ISO-8859-1 (Latin-1) кодировка. Соответственно и все численные коды символов берутся из этой кодировки. Первая половина (коды 0-127) кодировки соответствует кодам US-ASCII, поэтому проблем с латинским алфавитом не возникает.
Eshell V5.6.5 (abort with ^G)
1> [255].
"я"
Причем совершенно не важно, что указано в переменной окружения LANG, главное что бы она была установлена.
1. Элементарные типы
В языке не очень много базовых типов. Это число (целое или с плавающей запятой), атом, двоичные данные, битовые строки, функции-объекты (аналогично JavaScript-у), идентификатор порта, идентификатор процесса (Erlang процесса, а не системного), кортеж, список. Существует ряд псевдотипов: запись, булев, строки. Любой тип данных (не обязательно элементарный) называется терм.
1.1 Число
Потребление памяти и ограничения. Целое занимает одно машинное слово, что для 32-ух и 64-х разрядных процессорах составляет 4 байта и 8 байт соответственно. Для больших целых 1…N машинных слов. Числа с плавающей точкой в зависимости от архитектуры занимают 4 и 3 машинных слова соответственно.
1.2 Список
Список (List) позволяют группировать данные в одну структуру. Список создается при помощи квадратных скобок, элементы списка разделяются запятыми. Элемент списка может быть любого типа. Первый элемент списка называется голова (head), а оставшаяся часть — хвост (tail).
Потребление памяти и ограничения. Каждый элемент списка занимает одно машинное слово (4 или 8 байт в зависимости от архитектуры) + размер хранимых в элементе данных. Таким образом на 32-ух разрядной архитектуре значение переменной List будет занимать (1 + 1) + (1 + 4) + (1 + 1) = 9 слов или 36 байт.
1.3 Строка
На самом деле в Эрланге нет строк (String). Это просто синтаксический сахар который позволяет в более удобной форме записывать список целых чисел. Каждый элемент этого списка представляет собой ASCII код соответствующего символа.
1> "Surprise".
"Surprise"
2> [83,117,114,112,114,105,115,101].
"Surprise"
3> "строка".
"строка"
4> [$с,$т,$р,$о,$к,$а].
"строка"
5> [$с, $т, $р, $о, $к, $а, 1].
[241,242,240,238,234,224,1]
Поэтому когда виртуальная машина видит список, коды элементов которого могут быть переведены в печатные символы, то она понимает, что перед ней строка и выводит в символьном виде. В отличие от многих других языков строки в Эрланге создаются с использованием двойных кавычек и ни когда одиночных. Это объясняется тем, что с помощью одиночных кавычек создаются атомы. Внутри строк допускаются управляющие последовательности (см. ниже).
Потребление памяти и ограничения. Т.к. строка это список целых чисел, а каждый символ это один элемент списка, то на символ уходит 8 или 16 байт (2 машинных слова).
1.4 Атом
Атом (Atom) это просто литерал. Он не может быть связан с каким либо цифровым значением подобно константе в других языках. Значение возвращаемое атомом является самим атомом. Атом должен начинаться со строчной буквы и состоят из цифр, латинских букв, знака подчеркивания _ или собачки @. В этом случае его можно не заключать в одиночные кавычки. Если имеется другие символы, то нужно использовать одиночные кавычки для обрамления. Двойные кавычки для этого не подходят, т.к. в них заключают строки.
Например:
hello
phone_number
'Monday'
'phone number'
В строках и в закавыченных атомах можно использовать такие управляющие последовательности:
| Sequence | Description |
| \b | возврат (backspace) |
| \d | удалить (delete) |
| \e | эскейп (escape) |
| \f | прогон страницы (form feed) |
| \ | новая строка (newline) |
| \r | возврат каретки (carriage return) |
| \s | пробел (space) |
| \t | горизонтальная табуляция (tab) |
| \v | вертикальная табуляция (vertical tab) |
| \XYZ, \YZ, \Z | восьмеричный код символа |
| \^a. \^z \^A. \^Z | Ctrl + A … Ctrl + Z |
| \' | одиночная кавычка |
| \" | двойная кавычка |
| \\ | обратная косая черта |
Имя незаковыченного атома не может быть зарезервированным словом. К таким словам относятся:
after and andalso band begin bnot bor bsl bsr bxor case catch cond div end fun if let not of or orelse query receive rem try when xor.
Потребление памяти и ограничения. Каждый объявленный атом является уникальным и его символьное представление хранится во внутренней структуре виртуальной машины которая называется таблица атомов. Атом занимает 4 или 8 байт (одно машинное слово) и является просто ссылкой на элемент таблицы атомов в котором содержится его символьное представление. Сборщик мусора (garbage-collection) не выполняет очистку таблицы атомов. Сама таблица так же занимает место в памяти. Допускается использовать атомы в 255 символов, в общей сложности допустимо использовать 1 048 576 атомов. Таким образом атом в 255 символов будет занимать 255 * 2 + 1 * N машинных слов, где N – количество упоминаний атома в программе.
1.5 Кортеж
Кортеж (Tuple) подобен списку и состоит из набора элементов. Он так же имеет размер равный количеству элементов, но в отличие от списка его размер фиксирован. Кортеж создается при помощи фигурных скобок и его элементами могут быть любые типы данных, кортежи могут быть вложенными.
Кортежи удобны тем, что позволяют не только включать в структуру конкретные данные, но и описывать их. Это, а так же фиксированность кортежа позволяют очень эффективно применять их в шаблонах. Будет хорошей практикой при создании кортежа в первый элемент записывать атом описывающий сущность кортежа. Если проводить аналогии с РСУБД, то список является таблицей, каждая строка таблицы это элемент списка, а кортеж находящийся в этом элемент – конкретная запись в соответствующем столбце.
Потребление памяти и ограничения. Кортеж занимает 2 машинных слова + размер необходимый для хранения непосредственно самих данных. К примеру, кортеж в строке 5 будет занимать (2 + 1) + (2 + 1) = 6 машинных слов или 24 байта на 32-ой архитектуре. Максимальное количество элементов в кортеже 67 108 863.
1.6 Запись
Запись (Record) на самом деле является еще одним примером синтаксического сахара и во внутреннем представлении хранится как кортеж. Запись на этапе компиляции преобразуется в кортеж, поэтому использовать записи напрямую в шелле невозможно. Но можно воспользоваться rd() функцией для объявления структуры записи (строка 1). Объявление записи всегда состоит из двух элементов. Первый элемент обязательно должен быть атом называемый имя записи. Второй всегда кортежем, возможно даже пустым, элементы которого являются парой имя_поля – значение_поля, при этом имя поля должно быть атомом, а значение любым допустимым типом (в том числе и записью, строка 11).
1.7 Бинарные данные и битовые строки
И бинарный тип (Binaries) и битовые строки (Bit strings) позволяют работать с двоичным кодом напрямую. Отличие бинарного типа от битовой строки в том, что бинарные данные должны состоять только из целого количества байт, т.е. количество бит в них кратно восьми. Битовые же строки позволяют работать с данными на уровне бит, т.е. по сути бинарный тип это частный случай битовой строки количество разрядов в которой кратно восьми. Можно как создавать данные описав их структуру, так и использовать данный тип в шаблонах. Двоичные данные описываются такой структурой:
>
Отдельной элемент такой структуры называется сегмент. Сегменты описывают логическую структуру двоичных данных и могут состоят из произвольного числа битов/байтов. Это дает очень мощный и удобный инструмент при использовании в шаблонах (пример такого применения будет рассмотрен в третьей части).
1> >.
>
2> >.
>
3> >.
>
4> Var = 30.
30
5> >.
>
Что бы понять, почему в результате создания двоичных данных в строке 2 мы получили 144 (т.е. 10010000, ведь мы, надеюсь, еще не забыли, что шелл при выводе приводит все цифровые данные к десятичному виду), а не ожидаемые 400 нужно рассмотреть битовый синтаксис описания сегмента.
Полная форма описания сегмента состоит из значения (Value), размера (Size) и спецификатора ( TypeSpecifierList ). Причем размер и спецификатор являются необязательными и если не заданы принимают значения по умолчанию.
Значение (Value) в конструкторе может быть числом (целым или с плавающей точкой), битовой строкой или строкой, которая, как мы помним, является на самом деле списком целых чисел. Однако вместе с тем значение сегмента не может быть списком даже целых чисел, т.к. внутри конструктора строка является синтаксическим сахаром для посимвольного преобразования в целые числа, а не в список. Т.е. запись > является синтаксическим сахаром для >, а не >.
Внутри шаблонов значение может быть литералом или неопределенной переменной. Вложенные шаблоны недопускаются. В Value так же можно использовать выражения, но в этом случае сегмент должен быть заключен в круглые скобки (строка 5).
Размер (Size) определяет размер сегмента в юнитах (Unit, о них чуть ниже) и должен быть числом. Значение по умолчанию Size зависит от типа (Type, см. ниже) Value, но может быть и явно задано. Для целых это 8, чисел с плавающей точкой 64, бинарный соответствует количеству байт, битовые строки количеству разрядов. Полный размер сегмента в битах можно вычислить как Size * Unit.
При использовании в шаблонах величина Size должна быть явно заданной (строка 7) и может не задаваться только для последнего сегмента поскольку в него попадает остаток данных (сродни чтению строки со start символа и до конца строки без указания нужного length количества символов).
6> Bin = >.
>
7> > = Bin,
8> Z. %переменная размером в 3 разряда, её значение 110
>
9> >.
>
10> >.
>
11> >.
>
Использую битовый синтаксис одни и те же данные могут быть описаны по разному (строки 9 и 11 описывают одну и туже двухбайтовую структуру).
Потребление памяти и ограничения. 3…6 бит + непосредственно сами данные. На 32-ой архитектуре возможна манипуляция 536 870 911байтами, на 64-ех разрядной системе 2 305 843 009 213 693 951 байтами. Для обработки структур бОльшего размера придется самостоятельно написать функции обработки.
Внимание. Запись B= > будет интерпретироваться как B = > (т.е. B меньше-равно >). Правильная форма будет с применением пробелов: B = > .
1.8 Ссылка
Ссылка (Reference) представляет собой терм создаваемый функцией make_ref/0 и может считать уникальным. Она может быть использовать для такой структуры данных как первичный ключ.
Потребление памяти и ограничения. На 32-ух разрядной архитектуре требуется 5 машинных слов на одну ссылку для текущей локальной ноды и 7 слов для удаленной. На 64-ой 4 и 6 слов соответственно. Кроме того ссылка связана с таблицей нод которая также потребляет оперативную память.
1.9 Булев
Булев тип (Boolean) является псевдо типом т.к. на самом деле это всего лишь два атома true и false.
1.10 Объект-функция
Поэтому входные аргументы должны быть того же типа, что объявленные в функции. После ключевого слова when и до -> можно включать выражение результатом которого является true либо false. Тело функции выполняется в случае если выражение возвращает true. Если в ходе всех проверок тело функции так и не было выполнено (т.е. функция ни чего не вернула), то генерируется ошибка (строка 12). Переменные внутри функции являются локальными.
Функции могут быть вложенными, при этом результатом возвращаемым внешней функцией будет внутренняя:
1.11 Идентификатор процесса
Потребление памяти и ограничения. На данный тип уходит 1 машинное слово для локальных и 5 для удаленных нод. Кроме того функция связана с таблицей нод которая так же занимает память.
1.12 Идентификатор порта
Потребление памяти и ограничения. На данный тип уходит 1 машинное слово для локальных и 5 для удаленных нод. Кроме того функция связана с таблицей нод и таблицей портов которые так же занимает память.
Данные - это совокупность сведений, зафиксированных на определенном носителе в форме, пригодной для постоянного хранения, передачи и обработки. Преобразование и обработка данных позволяет получить информацию.
Информация - это результат преобразования и анализа данных. Отличие информации от данных состоит в том, что данные - это фиксированные сведения о событиях и явлениях, которые хранятся на определенных носителях, а информация появляется в результате обработки данных при решении конкретных задач. Например, в базах данных хранятся различные данные, а по определенному запросу система управления базой данных выдает требуемую информацию.
Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой. По мере развития НТП и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают (постоянное усложнение условий управления производством и обществом + быстрые темпы появления и внедрения новых носителей/хранителей данных – увеличение объёма данных).
1. Сбор – накопление данных с целью обеспечения достаточной полноты информации для принятия решения;
2. Формализация – приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
4. Сортировка – упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
5. Группировка – объединение данных по заданному признаку с целью повышения удобства использования; повышает доступность информации;
6. Архивация – организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат на хранение данных и повышает общую надежность информационного процесса в целом;
7. Защита – комплекс мер, направленных на предотвращение утраты, воспроизведение и модификации данных;
8. Транспортировка – прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя – клиентом;
9. Преобразование – перевод данных из одной формы в другую или из одной структуры в другую. Пример: изменение типа носителя; книги – бумага, электронная форма, микрофотоплёнка. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных.
Универсальных опеределений нет.
Зна́ние — в теории искусственного интеллекта и экспертных систем — совокупность информации и правил вывода (у индивидуума, общества или системы ИИ) о мире, свойствах объектов, закономерностях процессов и явлений, а также правилах использования их для принятия решений. Главное отличие знаний от данных состоит в их структурности и активности, появление в базе новых фактов или установление новых связей может стать источником изменений в принятии решений.
Данные - это совокупность сведений, зафиксированных на определенном носителе в форме, пригодной для постоянного хранения, передачи и обработки. Преобразование и обработка данных позволяет получить информацию.
Информация - это результат преобразования и анализа данных. Отличие информации от данных состоит в том, что данные - это фиксированные сведения о событиях и явлениях, которые хранятся на определенных носителях, а информация появляется в результате обработки данных при решении конкретных задач. Например, в базах данных хранятся различные данные, а по определенному запросу система управления базой данных выдает требуемую информацию.
Для решения задачи данные обрабатываются на основании имеющихся знаний, информация анализируется с помощью знаний. На основе анализа предлагаются варианты решения, принимвается лучшее, пополняет знания.
Принятия решений осуществляются на основе полученной информации и имеющихся знаний. Принятие решений – это выбор наилучшего в некотором смысле варианта решения из множества допустимых на основании имеющейся информации.
DIKW (англ. data, information, knowledge, wisdom — данные, информация, знания, мудрость) — информационная иерархия, где каждый уровень добавляет определённые свойства к предыдущему уровню.
Читайте также: