
Методы сжатия графических данных кратко
Обновлено: 02.07.2024
Свидетельство и скидка на обучение каждому участнику
Зарегистрироваться 15–17 марта 2022 г.
Методы сжатия графических данных
При сжатии методом RLE (Run — Length Encoding) последовательность повторяющихся величин (в нашем случае — набор бит для представления видеопикселя ) заменяется парой — повторяющейся величиной и числом её повторений.
Метод сжатия RLE включается в некоторые графические форматы, например, в формат PCX .
Сжатие методом RLE наиболее эффективно для изображений, которые содержат большие области однотонной закраски, и наименее эффективно — для отсканированных фотографий, так как в них нет длинных последовательностей одинаковых видеопикселей .
Метод сжатия LZW основан на поиске повторяющихся узоров в изображении. L ZW (Lempel-Ziv-Welch) разработан в 1978 году израильтянами Лемпелом и Зивом и доработан позднее в США. Сжимает данные путем поиска одинаковых последовательностей (они называются фразы) во всем файле. Выявленные последовательности сохраняются в таблице, им присваиваются более короткие маркеры (ключи). Так, если в изображении имеются наборы из розового, оранжевого и зеленого пикселов, повторяющиеся 50 раз, LZW выявляет это, присваивает данному набору отдельное число (например, 7) и затем сохраняет эти данные 50 раз в виде числа 7. Метод LZW, так же, как и RLE, лучше действует на участках однородных, свободных от шума цветов, он действует гораздо лучше, чем RLE, при сжатии произвольных графических данных, но процесс кодирования и распаковки происходит медленнее.
Рис. 11.3 . Сжатие методом RLE
Метод сжатия JPEG обеспечивает высокий коэффициент сжатия для рисунков фотографического качества. Формат файла JPEG , использующий этот метод сжатия, разработан объединенной группой экспертов по фотографии (Joint Photographic Experts Group ). Сжатие по методу JPEG сильно уменьшает размер файла с растровым рисунком (возможен коэффициент сжатия 100 : 1). Высокий коэффициент сжатия достигается за счет сжатия с потерями, при котором в результирующем файле теряется часть исходной информации. Метод JPEG использует тот факт, что человеческий глаз очень чувствителен к изменению яркости, но изменения цвета он замечает хуже. Поэтому при сжатии этим методом запоминается больше информации о разнице между яркостями видеопикселей и меньше — о разнице между их цветами. Так как вероятность заметить минимальные различия в цвете соседних пикселей мала, изображение после восстановления выглядит почти неизменным. Пользователю предоставляется возможность контролировать уровень потерь, указывая степень сжатия. Благодаря этому, можно выбрать наиболее подходящий режим обработки каждого изображения: возможность задания коэффициента сжатия позволяет сделать выбор между качеством изображения и экономией памяти. Если сохраняемое изображение — фотография, предназначенная для высокохудожественного издания , то ни о каких потерях не может быть и речи, так как рисунок должен быть воспроизведён как можно точнее. Если же изображение — фотография, которая будет размещена на поздравительной открытке, то потеря части исходной информации не имеет большого значения. Эксперимент поможет определить наиболее допустимый уровень потерь для каждого изображения.
JPEG – это алгоритм сжатия, основанный не на поиске одинаковых элементов, как в RLE и LZW, а на разнице между пикселами. Кодирование данных происходит в несколько этапов. Сначала графические данные конвертируются в цветовое пространство типа LAB, затем отбрасывается половина или три четверти информации о цвете (в зависимости от реализации алгоритма). Далее анализируются блоки 8х8 пикселов. Для каждого блока формируется набор чисел. Первые несколько чисел представляют цвет блока в целом, в то время, как последующие числа отражают тонкие делали. Спектр деталей базируется на зрительном восприятии человека, поэтому крупные детали более заметны.
На следующем этапе, в зависимости от выбранного вами уровня качества, отбрасывается определенная часть чисел, представляющих тонкие детали. На последнем этапе используется кодирование методом Хафмана для более эффективного сжатия конечных данных. Восстановление данных происходит в обратном порядке.
Таким образом, чем выше уровень компрессии, тем больше данных отбрасывается, тем ниже качество. Используя JPEG можно получить файл в 1-500 раз меньше, чем ВМР! Формат аппаратно независим, полностью поддерживается на РС и Macintosh, однако он относительно нов и не понимается старыми программами (до 1995 года). JPEG не поддерживает индексированные палитры цветов. Первоначально в спецификациях формата не было и CMYK, Adobe добавила поддержку цветоделения, однако CMYK JPEG во многих программах делает проблемы. Лучшим решением является использование JPEG-сжатия в Photoshop EPS-файлах.
Существуют подформаты JPEG. Baseline Optimized - файлы несколько лучше сжимаются, но не читаются некоторыми программами. JPEG Baseline Optimized разработан специально для Интернета, все основные браузеры его поддерживают. Progressive JPEG так же разработан специально для Сети, его файлы меньше стандартных, но чуть больше Baseline Optimized. Главная особенность Progressive JPEG в поддержке аналога черезстрочного вывода.
Из сказанного можно сделать следующие выводы. JPEG’ом лучше сжимаются растровые картинки фотографического качества, чем логотипы или схемы - в них больше полутоновых переходов, среди однотонных заливок же появляются нежелательные помехи. Лучше сжимаются и с меньшими потерями большие изображения для web или с высокой печатной резолюцией (200-300 и более dpi), чем с низкой (72-150 dpi), т.к. в каждом квадрате 8х8 пикселов переходы получаются более мягкие, за счет того, что их (квадратов) в таких файлах больше. Нежелательно сохранять с JPEG-сжатием любые изображения, где важны все нюансы цветопередачи (репродукции), так как во время сжатия происходит отбрасывание цветовой информации. В JPEG’е следует сохранять только конечный вариант работы, потому что каждое пересохранение приводит ко все новым потерям (отбрасыванию) данных и превращении исходного изображения с кашу.
Цветовое пространство LAB представляет цвет в трех каналах: один канал выделен для значений яркости (L - Lightnes) и два других - для цветовой информации (А и В). Цветовые каналы соответствуют шкале, а не какому-нибудь одному цвету. Канал А представляет непрерывный спектр от зеленого к красному, в то время как канал В - от синего к желтому. Средние значения для А и В соответствуют реальным оттенкам серого.
Существует похожая цветовая модель YCC, используемая в форматах Kodak Photo CD и FlashPix, здесь не описываемых.
Метод сжатия Хаффмана (Huffman) разработан в 1952 году и используется как составная часть в ряде других схем сжатия, таких как LZW, Дефляция, JPEG. В методе Хаффмана берется набор символов, который анализируется, чтобы определить частоту каждого символа. Затем для наиболее часто встречающихся символов используется представление в виде минимально возможного количества битов. Например, буква "е" чаще всего встречается в английских текстах. Используя кодировку Хаффмана вы можете представить "е" всего лишь двумя битами (1 и 0), вместо восьми битов, необходимых для представления буквы "е" в кодировке ASCII.
Информация о методах сжатия, используемых в растровых форматах файлов, приведена в таблице 11.2.
Таблица 11.2. Растровые форматы графических файлов
О некотоых других форматах
Adobe PostScript
PostScript - язык описания страниц (язык управления лазерными принтерами) фирмы Adobe. Был создан в 80-х годах для реализации принципа WYSIWYG (What You See is What You Get). Файлы этого формата представляют из себя программу с командами на выполнение для выводного устройства. Они имеют расширение .ps или, реже, .prn и получаются с помощью функции Print to File графических программ при использовании драйвера PostScript-принтера. Такие файлы содержат в себе сам документ (только то, что располагалось на страницах), все связанные файлы (как растровые, так и векторные), использованные шрифты, а так же другую информацию: платы цветоделения, дополнительные платы, линиатуру растра и форму растровой точки для каждой платы и другие данные для выводного устройства. Если файл создан правильно, не имеет значения на какой платформе он делался, были использованы шрифты True Type или Adobe Type 1 - все равно. Тем не менее нужно учитывать, что даже в том случае, когда вы сделали верные установки в окне печати, могут возникнуть проблемы связанные с некорректным переводом используемой вами программы ее графического языка на язык PostScript (например, внедрением информации о неиспользуемых шрифтах). Наиболее корректные PS-файлы создают программы Adobe.
Данные в PostScript-файле, как правило, записываются в двоичной кодировке (Binary). Бинарный код занимает вдвое меньше места, чем ASCII. Кодировка ASCII иногда требуется для передачи файлов через сети, для кроссплатформенного обмена, для печати через последовательные кабели. В приведенных случаях двоичная кодировка может исказиться (что сделает файл нечитаемым) или вызвать "странное" поведение файл-сервера. Эти проблемы давно изжиты в современных системах, но старые компьютеры и серверы бывают им подвержены. Сказанное относится ко всем форматам, основанным на языке PostScript: EPS и PDF, которые описываются ниже.
PDF ( Portable Document Format )
PDF предложен фирмой Adobe как независимый от платформы формат для создания электронной документации, презентаций, передачи верстки и графики через сети. Используется как внутренний графический формат в Mac OS X.
PDF-файлы создаются путем конвертации из PostScript-файлов или функцией экспорта ряда программ. Для конвертации используется программа Adobe Acrobat Distiller, это лучший способ создания PDF. Создание PDF методом экспорта из программ дает, как правило худший результат - файлы получаются более тяжелыми, часто имеют проблемы со встраиванием шрифтов.
Для создания PDF так же существует программа PDFWriter, работающая как виртуальный принтер. PDFWriter не основан на PostScript и не может корректно обрабатывать графику. Он предназначен для быстрого изготовления простых текстовых документов. У него наблюдается та же проблема со встраиванием шрифтов, что и многих программ, умеющих экспортировать PDF. Самые надежные и максимально близкие к оригиналу PDF создает из PostScript и EPS-файлов программа Acrobat Distiller, поставляемая в пакете Adobe Acrobat.
PDF первоначально проектировался как компактный формат электронной документации. Поэтому все данные в нем могут сжиматься, причем к разного типа информации применяются разные, наиболее подходящие для них типы сжатия: JPEG, RLE, CCITT, ZIP (похожее на LZW и известное еще как Deflate). Программа Acrobat Exchange 3 (которая в 4-й версии стала называться просто Acrobat 4.0) позволяет расставлять гиперссылки, заполняемые поля, включать в файл PDF видео и звук, другие действия.
Файл PDF может быть оптимизирован. Из него удаляются повторяющиеся элементы, устанавливается постраничный порядок загрузки страниц через web, с приоритетом сначала для текста, потом графика, наконец шрифты. Однако, когда повторяющихся элементов нет, файл, после оптимизации, как правило, несколько увеличивается.
PDF все больше используется для передачи по сетям в компактном виде графики и верстки. Он может сохранять всю информацию для выводного устройства, которая была в исходном PostScript-файле. Это касается PDF версий 1.2 (Acrobat 3) и выше. Однако, версия 1.2 не может включать сведения о треппинге, некоторые другие специфические данные (DSC, например), не использует цветовые профили. Все это реализовано в последующих вариантах формата.
Adobe Photoshop Document
Внутренний формат популярного растрового редактора Photoshop в последнее время стал поддерживаться все большим количеством программ. Он позволяет записывать изображение со многими слоями (до 1000), их масками, дополнительными Альфа-каналами и каналами простых (spot) цветов, корректирующими, векторными, текстовыми слоями, контурами и другой информацией - все, что может сделать Photoshop. В версии 3.0 появляются слои, контуры и RLE-компрессия, в 4-й версии алгоритм улучшается, файлы становятся еще меньше. В версии 5 реализован принципиально иной подход к управлению цветом. В программу была внедрена архитектура управления цветом, основанная на профилях для сканеров, мониторов и принтеров Международного консорциума по цвету (International Color Consortium, ICC). В шестой версии метод управления цветом переработан.
Несмотря на многочисленные дополнения функциями формат Photoshop'a имеет полную совместимость от 3-й до 7-й версии. В Photoshop'e 2.5 не было слоев и контуров, поэтому он выступает, как отдельный подформат.
Однослойный Photoshop Document понимают ряд программ, многослойные могут импортировать Illustrator и InDesidn. Corel Painter и Corel PHOTO-PAINT открывают на редакцию многослойные документы Photoshop.
Одной из простейших форм сжатия является метод RLE (Run Length Encoding - кодирование с переменной длиной строки). Действие метода RLE заключается в поиске одинаковых пикселов в одной строке. Если в строке, допустим, имеется 3 пиксела белого цвета, 21 - черного, затем 14 - белого, то применение RLE дает возможность не запоминать каждый из них (38 пикселов), а записать как 3 белых, 21 черный и 14 белых в первой строке.
Так же как и LZW, RLE хорошо работает с искусственными и пастеризованными картинками и плохо с фотографиями. В действительности, если фотография детализирована, RLE может даже увеличить размер файла.
Adobe Illustrator Document
Adobe Illustrator - самый первый продукт Adobe. Он был создан сразу же после выхода PostScript Level 1, его можно назвать интерфейсом для PostScript. До 9-й версии ядро формата основывалось на EPS, с 9-й в основе лежит ядро PDF. Это дает основание полагать, что в будущем появится, наконец, многостраничность. Формат Illustrator'а напрямую открывается Photoshop'ом, его поддерживают почти все программы Макинтош и Windows так или иначе связанные с векторной графикой и графикой вообще. Все, что создает Adobe Illustrator, совместимо PostScript (исключение составляют, разве что Gradient Meshes, которые нужно растеризовать перед закрытием на печать).
Формат Illustrator’ра является наилучшим посредником при передаче векторов из одной программы в другую, с РС на Macintosh и назад. Наиболее совместимыми можно назвать 3-ю и 4-ю версии. При передаче градиентных заливок между векторными редакторами в редактируемом виде (когда они не конвертируются в последовательность фигур) нужно использовать версии формата, начиная с 6-й. Внедренные или связанные с документом растровые файлы при обмене через формат Illustrator'a во всех программах, кроме FreeHand версии 9 и выше, теряются. Начиная с 9-й версии формат Illustrator'а может содержать внедренные шрифты (включая такие особенные шрифтовые форматы как Adobe Type 3 и Adobe Multiple Master) и ICC-профиль. Illustrator 9 позволяет сориентировать проект на цветовое пространство RGB или CMYK и сохранить это в файле.
CorelDRAW Document
Формат известен в прошлом низкой устойчивостью, плохой совместимостью файлов, искажением цветовых характеристик внедряемых битовых карт, тем не менее пользоваться CorelDRAW чрезвычайно удобно, он имеет неоспоримое лидерство на платформе РС. Многие программы на РС (FreeHand, Illustrator, PageMaker - среди них) могут импортировать файлы CorelDRAW.
Файлы формата CorelDRAW можно применять для переноса/передачи работ на PC, но нежелательно импортировать в программы верстки. На Макинтош файлы CorelDRAW для Windows открывают версия CorelDRAW для Макинтош и Adobe Illustrator 8 и выше.
PICT (Macintosh QuickDraw Picture Format)
PICT - собственный формат Mac OS Classic. Стандарт для буфера обмена, использует графический язык Mac OS. PICT способен нести растровую, векторную информацию, текст и звук, использует RLE-компрессию. Поддерживается на Mac’e всеми программами. Чисто битовые PICT-файлы могут иметь любую глубину битового представления (от Lineart до CMYK). Векторные PICT-файлы, которые почти исчезли из употребления в наши дни, имели странные проблемы с толщиной линии и другими отклонениями при печати. Формат используется для потребностей Mac OS, и при создании определенных типов презентаций только для Макинтош. Вне Макинтош PICT имеет расширение .pic или .pct, читается отдельными программами, но работа с ним редко бывает простой и бесхитростной.
RTF (Microsoft Rich Text Format)
Текстовый формат RTF попал сюда за свои неординарные способности к переносу текстов из одной программы в другую. Он позволяет передавать форматированный текст из программ оптического распознавания символов или текстовых редакторов в графические программы или в любых других направлениях. RTF может оказаться хорошим решением (а, иногда, и единственным выходом) при переброске из программы в программу нелатинского, например, ивритского текста или русского в Windows 95/98 Hebrew Edition.
Секрет совместимости заключается в использовании специальных тегов форматирования RTF и Unicode. Именно Unicode (использованный как основа формата Microsoft Word 97/98 для Макинтош и PC) позволяет легко переносить русские тексты с PC на Мак и обратно в файлах MS Word 97/98 (верно и для более высоких версий Word’а).
RTF используется как основной в поставляемом вместе с Mac OS X редакторе TextEdit и в прилагаемом к Windows программе WordPad.
Рис. 11.4 . Диалоговое окно для сохранения в CorelDRAW изображения в формате JPEG
Для уменьшения объема дискового пространства файлы подвергаются компрессии (сжатию). Существует два основных принципа сжатия: сжатие без потерь, когда информация полностью восстанавливается, и сжатие с потерями, когда информация до и после сжатия отличается в определенной и регулируемой степени.
Алгоритмы сжатия без потерь
В качестве примеров таких алгоритмов сжатия без потерь можно рассмотреть следующие:
Ø кодирование длин серий;
Ø метод Хаффмана;
Кодирование длин серий (Run Length Encoding )
Как известно, все документы (графика, тексты, программы и т. п.) хранятся в компьютере в виде файлов — организованных записей. Изображения хранятся в файлах специальных графических форматов, которых сейчас насчитывается более десятка. Основой для разложения изображения на множество элементов является пиксель. Основа файла — это описание цветов всех пикселей. Описание цвета пикселя (три / четыре числа) является кодом цвета в соответствии с той или иной цветовой моделью. Указание на цветовую модель также включается в файл. Кроме того, записывается размер изображения в пикселях.
Итак, условная структура файла (аналог формата BMP), будет содержать: сведения о цветовой модели; габаритах изображения; и, например, об авторе картинки, включенные в специальный раздел файла, называемый заголовком . После заголовка в файле записываются друг за другом коды цветов (или параметров цветовой модели) отдельных пикселей, слева направо и сверху вниз.
Пиксельное изображение при сохранении фактически вытягивается в цепочку и логично предположить, что встречаются цепочки (последовательности) одинаковых байтов. Самым простым способом, который позволяет уменьшить объем файла, является поиск повторяющихся кодов (символов, цвета и т. п.) — серий одинаковых значений. Каждая такая серия фиксируется двумя числами: первое указывает количество одинаковых значений, а второе — само значение.
Заменим для простоты значения цвета буквами. Если в документе, скажем, имеется такая последовательность "АААААВВВВВВВСССССС", ее можно сжать таким образом: 5А7В6С. В результате вместо 18 символов в документе достаточно хранить всего 6.
Алгоритм рассчитан на деловую или декоративную графику — изображения с большими областями локального (повторяющегося) цвета.
Достоинством такого алгоритма является простота (что очень важно, т. к. позволяет выполнять процедуры компрессии и декомпрессии достаточно быстро), а недостатками — необходимость различать собственно данные и числа повторений, а также возможное увеличение объема файла, если в документе мало повторений (например, серия АВСАВС не уменьшит, а увеличит объем документа, поскольку будет иметь следующий вид: 1А1В1С1А1В1С, т. е. вместо 6 символов получится вдвое больше).
Если система выводит ошибку, возможно программа, считывающая файл ожидает появление данных в ином порядке, чем программа, сохраняющая этот файл на диске. Требуется преобразование в иной формат
Метод RLE включается в некоторые графические форматы, например:
Ø BMP (для 16 и 256 по желанию);
Ø TGA (по желанию);
Алгоритм Хаффмана
Алгоритм Хаффмана основан на определенном анализе документа и вычислении частоты встречаемости цветовых значений (или значений других видов информации), а затем этим значениям в соответствии с рангом присваиваются коды сначала с минимальным количеством битов, а затем по мере снижения частоты (уменьшения ранга) используется все большее количество двоичных разрядов. Такой способ кодирования иногда называют алфавитным кодированием.
Заменим также для простоты значения цвета буквами. Например, в следующей последовательности букв ААСАААВАВАВВАВСАСВСАСААССС заметно, что чаще всего встречается символ А (12 раз), затем символ С (9 раз) и, наконец, символ В (5 раз). Следовательно, символ А можно заменять кодом 0, символ С — кодом 1, а символ В — кодом 00. И так далее, если элементов для кодирования больше. В результате, если считать, что каждый символ в нашем примере кодируется 1 битом, то для передачи строки потребуется 208 битов, а в сжатом виде объем информации составит только 31 бит.
Алгоритм LZW
Алгоритм, названный в честь своих создателей Лемпеля, Зива и Велча (Lempel, Ziv и Welch), не требует вычисления вероятностей встречаемости символов или кодов. Основная идея состоит в замене совокупности байтов в исходном файле ссылкой на предыдущее появление той же совокупности.
Процесс сжатия выглядит следующим образом. Последовательно считываются символы входного потока и происходит проверка, существует ли в созданной таблице строк такая строка. Если такая строка существует, считывается следующий символ, а если строка не существует, в поток заносится код для предыдущей найденной строки, строка заносится в таблицу, а поиск начинается снова.
Например, если сжимают байтовые данные (текст), то строк в таблице окажется 256 (от "0" до "255"). Для кода очистки и кода конца информации используются коды 256 и 257. Если используется 10-битный код, то под коды для строк остаются значения в диапазоне от 258 до 1023. Новые строки формируют таблицу последовательно, т. е. можно считать индекс строки ее кодом.
Пусть сжимается последовательность символов АВВСВВВ. Сначала в сжатый документ сохраняется код удаления [256], затем считывается символ "А" и проверяется, существует ли в таблице строка "А". Поскольку при инициализации в таблицу сохраняются все строки длиной в один символ, то строка "А", конечно, существует в таблице.
Далее считывается следующий символ "В" и проверяется, существует ли в таблице строка "АВ". Такая строка в таблице пока отсутствует, поэтому с первым свободным кодом [258] в таблицу вносится строка "АВ", а в документе сохраняется код [А]. Последовательность "АВ" в таблице отсутствует, поэтому в таблицу добавляется код [258] для сочетания "АВ", а в документе сохраняется код [А].
Далее рассматривается последовательность "ВВ", которая отсутствует в таблице, в таблицу заносится код [259] для символов "ВВ", а в документе сохраняется код [В].
Считывается символ "С" и проверяется наличие символов "ВС" в таблице, поскольку такая последовательность отсутствует, то в таблицу заносится кед [260] для последовательности "ВС", а в документ — код [В].
Снова добавляется из исходного файла символ "В" и теперь уже проверяется сочетание "СВ", которое тоже отсутствует. В таблицу записывается код [261] для "СВ", а в документ — код [С].
Затем считывается символ "В" и строка "ВВ", наконец, имеется в таблице, поэтому считывается следующий символ и рассматривается последовательность "ВВВ", которая, конечно, в таблице отсутствует. В таблицу заносится код [262] для "ВВВ", а в документ (внимание!) — код [259].
В результате в документе окажется следующая последовательность кодов [256][А][В][В][С][259], что короче исходной последовательности. К сожалению, последовательность слишком короткая, а алгоритм достатчно сложен, чтобы выгода оказалась реальной. При значительном объеме коэффициент сжатия может достигать несколько сот единиц.
Особенностью рассматриваемого алгоритма LZW является то, что для выполнения обратного процесса ("распаковки") нет необходимости сохранять таблицу в документе (алгоритм позволяет восстановить таблицу строк только из сохраненных в документе кодов).
Этот метод гораздо совершеннее RLE для областей с переходами цветов, однако кодировка в него требует больше системных ресурсов.
Метод LZW включается в некоторые графические форматы, например: TIFF ; GIF .
Алгоритмы сжатия с потерями
JPEG (Joint Photographic Experts Group)
Исследователями визуального восприятия человека отмечено, что далеко не вся информация требуется для того, чтобы адекватно воспринимать цветное изображение. Для реализации этого закона были разработаны алгоритмы с потерей информации, которые обеспечивают выбор уровня компрессии с уровнем качества изображения (рис. 1). Тем самым достигается компромисс между размером и качеством изображений.
Наиболее известным методом компрессии с потерями является JPEG-компрессия. Метод компрессии основан на особенности человеческого восприятия: глаз достаточно четко различает яркость объекта и цветовые контрасты, а плавные изменения в светах и тенях значительно меньше. При записи такой изобразительной информации часть цветовых данных может быть опущена, как предполагается, без заметного ущерба для восприятия.
Рис. 1. Компромисс между качеством и уровнем компрессии
Для этого обработка изображения происходит в несколько этапов. Сначала изображение конвертируется в особое цветовое пространство, напоминающее цветовую модель CIE Lab, в котором один канал сохраняет яркостные характеристики, а в остальных двух цветовых каналах уменьшается разрешение (по методу мозаики).
Замечание: RGB-изображение конвертируется в пространство YUV (иногда называемое также YcrCb), основанное на характеристиках яркости (составляющая Y) и цветности (составляющие U и V).
Затем изображение разбивается на фрагменты квадратной формы со стороной в 8 пикселей. Каждый фрагмент подвергается достаточно сложным математическим преобразованиям. Записывается два типа информации — усредненная информация о блоке и информация о его деталях, далее, в зависимости от выбранной степени сжатия, удаляется то или иное количество дополнительной информации. Чем меньше будет размер файла, тем хуже будет его качество.
Одновременно каждый блок разлагается на составляющие цвета и производится подсчет частоты встречаемости каждого цвета. Информация о частоте позволяет исключить небольшую часть яркостной характеристики и довольно значительную цветовой. Уровень исключения информации как раз и определяется установкой требуемого качества.
Затем информация о яркости и цвете кодируется таким образом, что остаются только различия между соседними блоками. Результатом всего процесса обработки являются последовательности простых чисел, которые в свою очередь легко сжимать каким-либо алгоритмом сжатия без потерь из уже упомянутых, например алгоритмом Хаффмана.
Алгоритмы сжатия с потерями, в частности алгоритм JPEG, не позволяют полностью восстановить изображение до его исходного состояния, а, следовательно, не рекомендуется сжимать изображения несколько раз.
Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит.
Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит.
Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов.
Словарные алгоритмы
Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности.
Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча.
Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом.
Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками.
Рассмотрим пример сжатия алгоритмом. Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.

В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит.
По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются.
Алгоритмы статистического кодирования
Алгоритмы этой серии ставят наиболее частым элементам последовательностей наиболее короткий сжатый код. Т.е. последовательности одинаковой длины кодируются сжатыми кодами различной длины. Причём, чем чаще встречается последовательность, тем короче, соответствующий ей сжатый код.
Алгоритм Хаффмана
- Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который равен частоте появления символа
- Выбираются два свободных узла дерева с наименьшими весами
- Создается их родитель с весом, равным их суммарному весу
- Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка
- Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0
- Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Арифметическое кодирование
Алгоритмы арифметического кодирования кодируют цепочки элементов в дробь. При этом учитывается распределение частот элементов. На данный момент алгоритмы арифметического кодирования защищены патентами, поэтому мы рассмотрим только основную идею.
Пусть наш алфавит состоит из N символов a1,…,aN, а частоты их появления p1,…,pN соответственно. Разобьем полуинтервал [0;1) на N непересекающихся полуинтервалов. Каждый полуинтервал соответствует элементам ai, при этом длина полуинтервала пропорциональна частоте pi.
Кодирующая дробь строится следующим образом: строится система вложенных интервалов так, чтобы каждый последующий полуинтервал занимал в предыдущем место, соответствующее положению элемента в исходном разбиении. После того, как все интервалы вложены друг в друга можно взять любое число из получившегося полуинтервала. Запись этого числа в двоичном коде и будет представлять собой сжатый код.
Декодирование – расшифровка дроби по известному распределению вероятностей. Очевидно, что для декодирования необходимо хранить таблицу частот.
Арифметическое кодирование чрезвычайно эффективно. Коды, получаемые с его помощью, приближаются к теоретическому пределу. Это позволяет утверждать, что по мере истечения сроков патентов, арифметическое кодирование будет становиться всё более и более популярным.
Алгоритмы сжатия с потерями
Не смотря на множество весьма эффективных алгоритмов сжатия без потерь, становится очевидно, что эти алгоритмы не обеспечивают (и не могут обеспечить) достаточной степени сжатия.
Сжатие с потерями (применительно к изображениям) основывается на особенностях человеческого зрения. Мы рассмотрим основные идеи, лежащие в основе алгоритма сжатия изображений JPEG.
Алгоритм сжатия JPEG
JPEG на данный момент один из самых распространенных способов сжатия изображений с потерями. Опишем основные шаги, лежащие в основе этого алгоритма. Будем считать, что на вход алгоритма сжатия поступает изображение с глубиной цвета 24 бита на пиксел (изображение представлено в цветовой модели RGB).
Перевод в цветовое пространство YCbCr
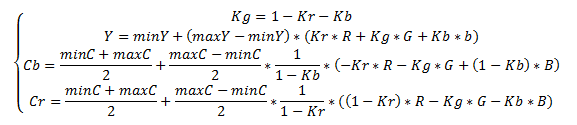
В цветовой модели YCbCr мы представляем изображение в виде яркостной компоненты (Y) и двух цветоразностных компонент (Cb,Cr). Человеческий глаз более восприимчив к яркости, а не к цвету, поэтому алгоритм JPEG вносит по возможности минимальные изменения в яркостную компоненту (Y), а в цветоразностные компоненты могут вноситься значительные изменения. Перевод осуществляется по следующей формуле:
Выбор Kr и Kb зависит от оборудования. Обычно берётся Kb=0.114;Kr=0.299. В последнее время также используется Kb=0.0722;Kr=0.2126, что лучше отражает характеристики современных устройств отображения.
Субдискретизация компонент цветности
- :4:4 – отсутствует субдискретизация;
- 4:2:2 – компоненты цветности меняются через одну по горизонтали;
- 4:2:0 – компоненты цветности меняются через одну строку по горизонтали, при этом по вертикали они меняются через строку.
Дискретное косинусное преобразование
Изображение разбивается на компоненты 8*8 пикселов, к каждой компоненте применятся ДКП. Это приводит к уплотнению энергии в коде. Преобразования применяются к компонентам независимо.
Квантование
Человек практически не способен замечать изменения в высокочастотных составляющих, поэтому коэффициенты, отвечающие за высокие частоты можно хранить с меньшей точностью. Для этого используется покомпонентное умножение (и округление) матриц, полученных в результате ДКП, на матрицу квантования. На данном этапе тоже можно регулировать степень сжатия (чем ближе к нулю компоненты матрицы квантования, тем меньше будет диапазон итоговой матрицы).
Зигзаг-обход матриц

Зигзаг-обход матрицы – это специальное направление обхода, представленное на рисунке:
При этом для большинства реальных изображений в начале будут идти ненулевые коэффициенты, а ближе к концу будут идти нули.
RLE- кодировние
Используется особый вид RLE-кодирования: выводятся пары чисел, причём первое число в паре кодирует количество нулей, а второе – значение после последовательности нулей. Т.е. код для последовательности 0 0 15 42 0 0 0 44 будет следующим (2;15)(0;42)(3;44).
Кодирование методом Хаффмана
Используется описанный выше алгоритм Хаффмана. При кодировании используется заранее определённая таблица.
Алгоритм декодирования заключается в обращении выполненных преобразований.
К достоинствам алгоритма можно отнести высокую степень сжатие (5 и более раз), относительно невысокая сложность (с учётом специальных процессорных инструкций), патентная чистота. Недостаток – артефакты, заметные для человеческого глаза.
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
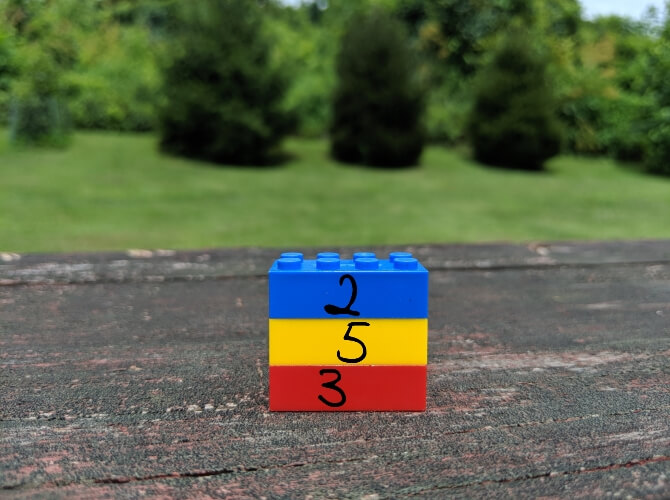
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
Присжатии методом RLE(Run — Length Encoding) последовательность повторяющихся величин (в нашем случае — набор бит для представления видеопикселя ) заменяется парой — повторяющейся величиной и числом её повторений.
Метод сжатия RLE включается в некоторые графические форматы, например, в формат PCX .
Сжатие методом RLE наиболее эффективно для изображений, которые содержат большие области однотонной закраски, и наименее эффективно — для отсканированных фотографий, так как в них нет длинных последовательностей одинаковых видеопикселей .
| Хорошо сжимаемое изображение | Плохо сжимаемое изображение |
Рис. 4. Сжатие методом RLE
Метод сжатия JPEGобеспечивает высокий коэффициент сжатия для рисунков фотографического качества. Формат файла JPEG ,использующий этот метод сжатия, разработан объединенной группой экспертов по фотографии (Joint Photographic Experts Group ). Сжатие по методу JPEGсильно уменьшает размер файла с растровым рисунком (возможен коэффициент сжатия 100 : 1). Высокий коэффициент сжатия достигается за счет сжатия с потерями, при котором в результирующем файле теряется часть исходной информации. Метод JPEGиспользует тот факт, что человеческий глаз очень чувствителен к изменению яркости, но изменения цвета он замечает хуже. Поэтому при сжатии этим методом запоминается больше информации о разнице между яркостями видеопикселей и меньше — о разнице между их цветами. Так как вероятность заметить минимальные различия в цвете соседних пикселей мала, изображение после восстановления выглядит почти неизменным. Пользователю предоставляется возможность контролировать уровень потерь, указывая степень сжатия. Благодаря этому, можно выбрать наиболее подходящий режим обработки каждого изображения: возможность задания коэффициента сжатия позволяет сделать выбор между качеством изображения и экономией памяти. Если сохраняемое изображение — фотография, предназначенная для высокохудожественного издания , то ни о каких потерях не может быть и речи, так как рисунок должен быть воспроизведён как можно точнее. Если же изображение — фотография, которая будет размещена на поздравительной открытке, то потеря части исходной информации не имеет большого значения. Эксперимент поможет определить наиболее допустимый уровень потерь для каждого изображения.
Информация о методах сжатия, используемых в растровых форматах файлов, приведена в таблице 2.
Присжатии методом RLE(Run — Length Encoding) последовательность повторяющихся величин (в нашем случае — набор бит для представления видеопикселя ) заменяется парой — повторяющейся величиной и числом её повторений.
Метод сжатия RLE включается в некоторые графические форматы, например, в формат PCX .

Сжатие методом RLE наиболее эффективно для изображений, которые содержат большие области однотонной закраски, и наименее эффективно — для отсканированных фотографий, так как в них нет длинных последовательностей одинаковых видеопикселей .
| Хорошо сжимаемое изображение | Плохо сжимаемое изображение |
Рис. 4. Сжатие методом RLE
Метод сжатия JPEGобеспечивает высокий коэффициент сжатия для рисунков фотографического качества. Формат файла JPEG ,использующий этот метод сжатия, разработан объединенной группой экспертов по фотографии (Joint Photographic Experts Group ). Сжатие по методу JPEGсильно уменьшает размер файла с растровым рисунком (возможен коэффициент сжатия 100 : 1). Высокий коэффициент сжатия достигается за счет сжатия с потерями, при котором в результирующем файле теряется часть исходной информации. Метод JPEGиспользует тот факт, что человеческий глаз очень чувствителен к изменению яркости, но изменения цвета он замечает хуже. Поэтому при сжатии этим методом запоминается больше информации о разнице между яркостями видеопикселей и меньше — о разнице между их цветами. Так как вероятность заметить минимальные различия в цвете соседних пикселей мала, изображение после восстановления выглядит почти неизменным. Пользователю предоставляется возможность контролировать уровень потерь, указывая степень сжатия. Благодаря этому, можно выбрать наиболее подходящий режим обработки каждого изображения: возможность задания коэффициента сжатия позволяет сделать выбор между качеством изображения и экономией памяти. Если сохраняемое изображение — фотография, предназначенная для высокохудожественного издания , то ни о каких потерях не может быть и речи, так как рисунок должен быть воспроизведён как можно точнее. Если же изображение — фотография, которая будет размещена на поздравительной открытке, то потеря части исходной информации не имеет большого значения. Эксперимент поможет определить наиболее допустимый уровень потерь для каждого изображения.
Информация о методах сжатия, используемых в растровых форматах файлов, приведена в таблице 2.
Читайте также: