
Доклад на тему дерево решений
Обновлено: 14.05.2024
Стремительное развитие информационных технологий, в частности, прогресс в методах сбора, хранения и обработки данных позволил многим организациям собирать огромные массивы данных, которые необходимо анализировать. Объемы этих данных настолько велики, что возможностей экспертов уже не хватает, что породило спрос на методы автоматического исследования (анализа) данных, который с каждым годом постоянно увеличивается.
Содержание
Введение
Понятие дерева решений и типы решаемых задач
Как построить дерево решений?
Этапы построения деревьев решений
Преимущества использования деревьев решений
Области применения деревьев решений
Заключение
Список литературы
Прикрепленные файлы: 1 файл
Деревья решений.doc
Введение
Понятие дерева решений и типы решаемых задач
Как построить дерево решений?
Этапы построения деревьев решений
Преимущества использования деревьев решений
Области применения деревьев решений
Заключение
Список литературы
Стремительное развитие информационных технологий, в частности, прогресс в методах сбора, хранения и обработки данных позволил многим организациям собирать огромные массивы данных, которые необходимо анализировать. Объемы этих данных настолько велики, что возможностей экспертов уже не хватает, что породило спрос на методы автоматического исследования (анализа) данных, который с каждым годом постоянно увеличивается.
Деревья решений – один из таких методов автоматического анализа данных. Первые идеи создания деревьев решений восходят к работам Ховленда (Hoveland) и Ханта(Hunt) конца 50-х годов XX века. Однако, основополагающей работой, давшей импульс для развития этого направления, явилась книга Ханта (Hunt, E.B.), Мэрина (Marin J.) и Стоуна (Stone, P.J) "Experiments in Induction", увидевшая свет в 1966г.
Понятие дерева решений и типы решаемых задач
Деревья решений – это способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение.
Под правилом понимается логическая конструкция, представленная в виде "если . то . ".
Область применения деревья решений в настоящее время широка, но все задачи, решаемые этим аппаратом могут быть объединены в следующие три класса:
- Описание данных: Деревья решений позволяют хранить информацию о данных в компактной форме, вместо них мы можем хранить дерево решений, которое содержит точное описание объектов.
- Классификация: Деревья решений отлично справляются с задачами классификации, т.е. отнесения объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные значения.
- Регрессия: Если целевая переменная имеет непрерывные значения, деревья решений позволяют установить зависимость целевой переменной от независимых(входных) переменных. Например, к этому классу относятся задачи численного прогнозирования(пре дсказания значений целевой переменной).
Как построить дерево решений?
Пусть нам задано некоторое обучающее множество T, содержащее объекты (примеры), каждый из которых характеризуется m атрибутами (атрибутами), причем один из них указывает на принадлежность объекта к определенному классу.
Идею построения деревьев решений из множества T, впервые высказанную Хантом, приведем по Р. Куинлену (R. Quinlan).
Пусть через 1, C2, . Ck> обозначены классы (значения метки класса), тогда существуют 3 ситуации:
- множество T содержит один или более примеров, относящихся к одному классу Ck. Тогда дерево решений для Т – это лист, определяющий класс Ck;
- множество T не содержит ни одного примера, т.е. пустое множество. Тогда это снова лист, и класс, ассоциированный с листом, выбирается из другого множества отличного от T, скажем, из множества, ассоциированного с родителем;
- множество T содержит примеры, относящиеся к разным классам. В этом случае следует разбить множество T на некоторые подмножества. Для этого выбирается один из признаков, имеющий два и более отличных друг от друга значений O1, O2, . On. T разбивается на подмножества T1, T2, . Tn, где каждое подмножество Tiсодержит все примеры, имеющие значение Oi для выбранного признака. Это процедура будет рекурсивно продолжаться до тех пор, пока конечное множество не будет состоять из примеров, относящихся к одному и тому же классу.
Вышеописанная процедура лежит в основе многих современных алгоритмов построения деревьев решений, этот метод известен еще под названием разделения и захвата (divide and conquer). Очевидно, что при использовании данной методики, построение дерева решений будет происходит сверху вниз.
Поскольку все объекты были заранее отнесены к известным нам классам, такой процесс построения дерева решений называется обучением с учителем (supervised learning). Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction).
На сегодняшний день существует значительное число алгоритмов, реализующих деревья решений CART, C4.5, NewId, ITrule, CHAID, CN2 и т.д. Но наибольшее распространение и популярность получили следующие два:
- CART (Classification and Regression Tree) – это алгоритм построения бинарного дерева решений – дихотомической классификационной модели. Каждый узел дерева при разбиении имеет только двух потомков. Как видно из названия алгоритма, решает задачи классификации и регрессии.
- C4.5 – алгоритм построения дерева решений, количество потомков у узла не ограничено. Не умеет работать с непрерывным целевым полем, поэтому решает только задачи классификации.
Большинство из известных алгоритмов являются "жадными алгоритмами". Если один раз был выбран атрибут, и по нему было произведено разбиение на подмножества, то алгоритм не может вернуться назад и выбрать другой атрибут, который дал бы лучшее разбиение. И поэтому на этапе построения нельзя сказать даст ли выбранный атрибут, в конечном итоге, оптимальное разбиение.
Этапы построения деревьев решений
При построении деревьев решений особое внимание уделяется следующим вопросам: выбору критерия атрибута, по которому пойдет разбиение, остановки обучения иотсечения ветвей. Рассмотрим все эти вопросы по порядку.
Правило разбиения. Каким образом следует выбрать признак?
Для построения дерева на каждом внутреннем узле необходимо найти такое условие (проверку), которое бы разбивало множество, ассоциированное с этим узлом на подмножества. В качестве такой проверки должен быть выбран один из атрибутов. Общее правило для выбора атрибута можно сформулировать следующим образом: выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т.е. количество объектов из других классов ("примесей") в каждом из этих множеств было как можно меньше.
Были разработаны различные критерии, но мы рассмотрим только два из них:
Теоретико-информационный критерий
Алгоритм C4.5, усовершенствованная версия алгоритма ID3 (Iterative Dichotomizer), использует теоретико-информационный подход. Для выбора наиболее подходящего атрибута, предлагается следующий критерий:
где, Info(T) – энтропия множества T, а
Множества T1, T2, . Tn получены при разбиении исходного множества T по проверке X. Выбирается атрибут, дающий максимальное значение по критерию (1).
Впервые эта мера была предложена Р. Куинленом в разработанном им алгоритме ID3. Кроме вышеупомянутого алгоритма C4.5, есть еще целый класс алгоритмов, которые используют этот критерий выбора атрибута.
Статистический критерий
Алгоритм CART использует так называемый индекс Gini (в честь итальянского экономиста Corrado Gini), который оценивает "расстояние" между распределениями классов.
Где c – текущий узел, а pj – вероятность класса j в узле c.
CART был предложен Л.Брейманом (L.Breiman) и др.
Правило остановки. Разбивать дальше узел или отметить его как лист?
В дополнение к основному методу построения деревьев решений были предложены следующие правила:
- Использование статистических методов для оценки целесообразности дальнейшего разбиения, так называемая "ранняя остановка" (prepruning). В конечном счете "ранняя остановка" процесса построения привлекательна в плане экономии времени обучения, но здесь уместно сделать одно важное предостережение: этот подход строит менее точные классификационные модели и поэтому ранняя остановка крайне нежелательна. Признанные авторитеты в этой области Л.Брейман и Р. Куинлен советуют буквально следующее: "Вместо остановки используйте отсечение".
- Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение.
- Разбиение должно быть нетривиальным, т.е. получившиеся в результате узлы должны содержать не менее заданного количества примеров.
Этот список эвристических правил можно продолжить, но на сегодняшний день не существует такого, которое бы имело большую практическую ценность. К этому вопросу следует подходить осторожно, так как многие из них применимы в каких-то частных случаях.
Правило отсечения. Каким образом ветви дерева должны отсекаться?
Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые "переполнены данными", имеют много узлов и ветвей. Такие "ветвистые" деревья очень трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств, состоящих из все меньшего количества объектов.
Ценность правила, справедливого скажем для 2-3 объектов, крайне низка, и в целях анализа данных такое правило практически непригодно. Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое количество объектов из обучающей выборки. И тут возникает вопрос: а не построить ли все возможные варианты деревьев, соответствующие обучающему множеству, и из них выбрать дерево с наименьшей глубиной? К сожалению, это задача является NP-полной, это было показано Л. Хайфилем (L. Hyafill) и Р. Ривестом (R. Rivest), и, как известно, этот класс задач не имеет эффективных методов решения.
Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей (pruning).
Пусть под точностью (распознавания) дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой – количество неправильно классифицированных. Предположим, что нам известен способ оценки ошибки дерева, ветвей и листьев. Тогда, возможно использовать следующее простое правило:
- построить дерево;
- отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки.
В отличии от процесса построения, отсечение ветвей происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом.
Хотя отсечение не является панацеей, но в большинстве практических задач дает хорошие результаты, что позволяет говорить о правомерности использования подобной методики.
Правила
Иногда даже усеченные деревья могут быть все еще сложны для восприятия. В таком случае, можно прибегнуть к методике извлечения правил из дерева с последующим созданием наборов правил, описывающих классы.
Для извлечения правил необходимо исследовать все пути от корня до каждого листа дерева. Каждый такой путь даст правило, где условиями будут являться проверки из узлов встретившихся на пути.
Преимущества использования деревьев решений
Рассмотрев основные проблемы, возникающие при построении деревьев, было бы несправедливо не упомянуть об их достоинствах:
- быстрый процесс обучения;
- генерация правил в областях, где эксперту трудно формализовать свои знания;
- извлечение правил на естественном языке;
- интуитивно понятная классификационная модель;
- высокая точность прогноза, сопоставимая с другими методами (статистика, нейронные сети);
- построение непараметрических моделей.
В силу этих и многих других причин, методология деревьев решений является важным инструментом в работе каждого специалиста, занимающегося анализом данных, вне зависимости от того практик он или теоретик.
Дерево решений - это метод, который применяется для принятия решений в условиях неопределенности и риска. Данный метод используется в случае, когда нужно принимать ряд последовательных решений. Дерево решений является графическим методом, который позволяет скоординировать элементы принятия решения, вероятные стратегии (Аi), их последствия (Ei,j) с вероятностными условиями и факторами внешней среды воздействия.
Начинается построение дерева решений с наиболее раннего решения, после разрабатываются возможные результаты и последствия каждого из действий (событий), после вновь определяется выбор направления действия (принимается решение) и так далее до тех пор, пока все последствия результатов решений не будут определены.
Дерево решений составляется на основании 5 последовательных элементов (рисунок 1):
Рисунок 1 – Элементы дерева решений
Простейшее решение
Простейшим решением является выбор из двух вариантов: "нет" или "да". (рисунок 2).
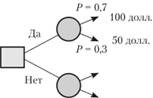
Рисунок 2 - Простейшее дерево решений
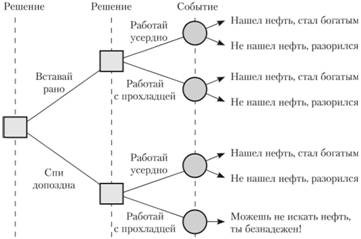
Последовательности решений можно смоделировать следующим образом (рисунок 3):
Рисунок 3 - Дерево (последовательность) принимаемых решений
1) решение: необходимо выбрать между тем, чтобы "Спать допоздна" или "Вставать рано"– простой выбор;
2) решение: необходимо выбрать между тем, чтобы "Работать спустя рукава" или "Работать усердно"– простой выбор;
3) событие: "Найдешь нефть" или нет случается с определенной вероятностью, которая зависит от принимаемых решений.
Поставленные задачи и варианты их решений приведены в таблицах 1 и 2, и отражены на рисунке 4 в виде дерева решений.
Жирным курсивом обозначен путь на дереве, являющийся самым предпочтительным (EV = 820000 долларов) и соответствующий решению, состоящему из элементов "Вставай рано" и "Работай усердно".
Таблица 1 - Вычисление ожидаемых результатов поиска нефти взвешенных по вероятности
| Решение: "Вставай рано" + "Работай усердно" | Возможное событие | |
| Не найти нефть | Найти нефть | |
| Событие: прибыль (убыток), долларов | -200 000 | 10000 000 |
| Событие: вероятность наступления события | 0,90 | 0,10 |
| Риск = Прибыль (убыток) × Вероятность, долларов | -180 000 | 1000 000 |
| Ожидаемое значение результата (EV), долларов | 1000000-180000 = 820 000 | |
Таблица 2 - Ожидаемые результаты решения "Когда встать и как работать"
Вероятность (найти нефть) = 5% (1- Вероятность) (не найти нефть) = 95%
Ожидаемое значение результатов решения: ( 0 , 05 × 10 000 000 ) + 0 , 95 × ( - 200 000 ) = 310000 долларов
Вероятность (найти нефть) = 10% (1- Вероятность) (не найти нефть) = 90%
Ожидаемое значение результатов решения: ( 0 , 1 × 10 000 000 ) + 0 , 9 × ( - 200 000 ) = 820 000 долларов
Вероятность (найти нефть) = 0% (1- Вероятность) (не найти нефть) = 100%
Ожидаемое значение результатов решения: ( 0 - 10 000 000 ) + 1 × ( - 200 000 ) = - 200 000 долларов
Вероятность (найти нефть) = 1% (1- Вероятность) (не найти нефть) = 99%
Ожидаемое значение результатов решения: ( 0 , 01 × 10 000 000 ) + ( 0 , 99 × ( - 200 000 ) = - 98 000 долларов
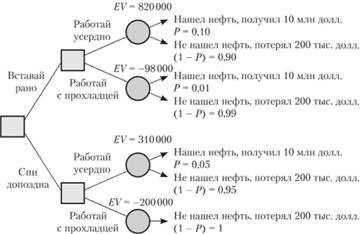
Рисунок 4 - Дерево решений с ожидаемыми значениями результатов(EV), долларов
Дополнительно учтем в примере, приведенном выше, изменение в зависимости от срока окупаемости стоимости проекта.
Установим, что сумма средств, необходимых для поиска нефти, расходуется сразу же. Если находим нефть, то все средства, вложенные в нефтеразведку покрываются сразу же, а доходы от продаж добытой нефти поступают через два года. Чтобы корректно учитывать все данные платежи и поступления, разбросанные во времени, необходимо привести все суммы денежных средств к текущей стоимости.
Установим, что ставка дисконтирования будет принимать значение, равное 20 процентов, тогда таблица 2 будет представлена в следующем виде (таблица 3), а дерево решений (рисунок 4) – в виде, показанном на рисунке 5.
Таблица 3 - Ожидаемая приведенная стоимость и результаты решения "Когда вставать и как работать" с учетом коэффициента дисконтирования
Вероятность (найти нефть) = 5% (1 – Вероятность) (не найти нефть) = 95%
Ожидаемая стоимость: 310000 долл.
Ожидаемая приведенная стоимость: ( 0 , 05 × 10 000 000 ) / 1 , 22 + 0 , 95 × ( - 200000 ) = 157 222 долл.
Вероятность (найти нефть) =10% (1 – Вероятность) (не найти нефть) = 90%
Ожидаемая стоимость: 820 000 долл.
Ожидаемая приведенная стоимость: ( 0 , 1 × 10 000 000 ) / 1 , 22 + 0 , 9 × ( - 200 000 ) = 514 444 долл.
Вероятность (найти нефть) = 0% (1 - Вероятность) (не найти нефть) = 100%
Ожидаемая стоимость: – 200000 долл.
Ожидаемая приведенная стоимость: ( 0 × 10 000 000 ) / 1 , 22 + 1 × ( - 200 000 ) = - 200 000 долл.
Вероятность (найти нефть) =1% (1 - Вероятность) (не найти нефть) = 99%
Ожидаемая стоимость: – 98000 долл.
Ожидаемая приведенная стоимость: ( 0 , 01 × 10 000 000 ) / 1 , 22 + 0 , 99 × ( - 200 000 ) = - 128 555 долл.
Самая эффективная последовательность решений та же (отображен жирной линией путь, который совпадает с решением "Вставай рано" + "Работай усердно", однако изменилось значение ожидаемого выигрыша (514444 долларов), в связи с тем, что учитывалась ставка дисконтирования.
Руководитель организации, выпускающего в настоящее время продукцию X1 в объеме V1тек. = 1000 единиц, считает, что необходимо расширять рынок продукции Х2.
Проведенные маркетинговые исследования определили вилки спроса на продукцию Х2 (V1max = 1000 единиц; V1min = 5000 единиц; V2max = 8000 единиц; V2min = 4000 единиц), а также вероятности низкого и высокого спроса (D1max = 0,7; D1min = 1 -D1max = 0,3; D2max = 0,6; D2min = 1-D2max = 0,4).
Выявлено, что даже минимальный уровень спроса намного превышает имеющиеся мощности организации, которые необходимо использовать для производства обоих видов продукции.
Определен уровень прибыли на единицу продукции каждого из видов (P1 = 1 денежных единиц; Р2 = 0,9 денежных единиц).
Рассчитаны затраты (К = 0,4 * 103 денежных единиц) на удвоение мощности организации (для одновременного производства продукта Х1 в существующем объеме и производства продукции Х2 в эквивалентном объеме) V1тек = 1000 единиц и V2экв = 900 единиц, на увеличение мощности организации под минимальный и максимальный спрос на текущую продукцию (K1min= = 1,4 * 103 денежных единиц и K1max = 2 * 103 денежных единиц) и под минимальный и максимальный уровень спроса на продукцию Х2 (К2 min = 0,8 * 103 денежных единиц и К1max = 1,2 * 103 денежных единиц соответственно).
Необходимо определить рациональность замены продукции и расширения мощностей, под одновременный выпуск продукции в том числе.
Дерево решений и рассчитанные последствия решения отображены на рисунке 5.
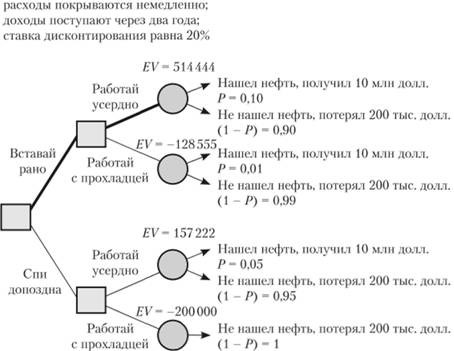
Рисунок 5 - Дерево решений с ожидаемыми значениями приведенных результатов (EV), долларов
Определив результаты решений при производстве продукции одного их видов (Х1 или Х2), выявим эффективные действия во второй точке решений.
Отбросим для этого иррациональные действия по расширению мощностей и данные об ожидаемом выигрыше перенесем в 4 графу. С учетом вероятности существующего спроса на продукты, проведем расчет средней эффективности действий в местах разветвления событий (3 графа). Выявлено, что продолжение производства продукта Х1, при параллельном расширении мощностей является более выгодным вариантом, чем переход на производство продукции Х2 вместо продукции X1.
Однако нами не учитывалась возможность параллельного производства продукции X1 и Х2 при расширении мощностей организации под максимальный уровень спроса. Поэтому проведем еще одно ответвление из первой точки принятия решения, соответствующее этому варианту решения. Эффективность этого варианта состоит из эффективности первого варианта и второго варианта (Э1 и Э2) за минусом вложений на первоначальное удвоение мощностей организации. Эффективность этого варианта самая высокая, поэтому варианты 1 и 2 необходимо вычеркнуть.
Вывод. Необходимо существенно развивать мощности и одновременно выпускать два вида продукции.
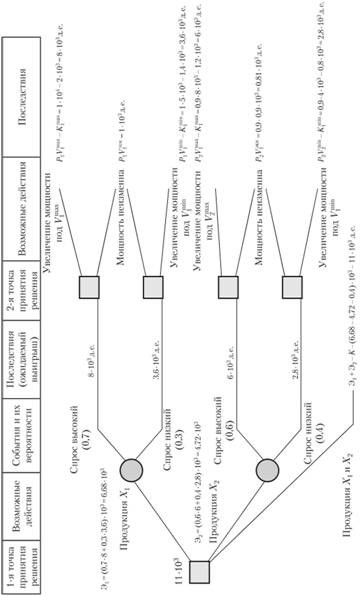
Рисунок 6 - Дерево принятия решений при определении стратегии организации
Представленная схема решения немного упрощена, так как мы не рассматривали варианты привлечения резервов по выпуску продукта одного вида при минимальном уровне спроса для производства продукции другого вида, лимиты по вложениям денежных средств (в условиях задачи для этого недостаточно данных).
Дерево решений — эффективный инструмент интеллектуального анализа данных и предсказательной аналитики. Он помогает в решении задач по классификации и регрессии.
Правила генерируются за счет обобщения множества отдельных наблюдений (обучающих примеров), описывающих предметную область. Поэтому их называют индуктивными правилами, а сам процесс обучения — индукцией деревьев решений.
В обучающем множестве для примеров должно быть задано целевое значение, так как деревья решений — модели, создаваемые на основе обучения с учителем. По типу переменной выделяют два типа деревьев:
- дерево классификации — когда целевая переменная дискретная;
- дерево регрессии — когда целевая переменная непрерывная.
Развитие инструмента началось в 1950-х годах. Тогда были предложены основные идеи в области исследований моделирования человеческого поведения с помощью компьютерных систем.
Дальнейшее развитие деревьев решений как самообучающихся моделей для анализа данных связано с Джоном Р. Куинленом (автором алгоритма ID3 и последующих модификаций С4.5 и С5.0) и Лео Брейманом, предложившим алгоритм CART и метод случайного леса.
Рассмотрим понятие более подробно. Дерево решений — метод представления решающих правил в определенной иерархии, включающей в себя элементы двух типов — узлов (node) и листьев (leaf). Узлы включают в себя решающие правила и производят проверку примеров на соответствие выбранного атрибута обучающего множества.
Простой случай: примеры попадают в узел, проходят проверку и разбиваются на два подмножества:
- первое — те, которые удовлетворяют установленное правило;
- второе — те, которые не удовлетворяют установленное правило.
Далее к каждому подмножеству снова применяется правило, процедура повторяется. Это продолжается, пока не будет достигнуто условие остановки алгоритма. Последний узел, когда не осуществляется проверка и разбиение, становится листом.
Лист определяет решение для каждого попавшего в него примера. Для дерева классификации — это класс, ассоциируемый с узлом, а для дерева регрессии — соответствующий листу модальный интервал целевой переменной. В листе содержится не правило, а подмножество объектов, удовлетворяющих всем правилам ветви, которая заканчивается этим листом.
Пример попадает в лист, если соответствует всем правилам на пути к нему. К каждому листу есть только один путь. Таким образом, пример может попасть только в один лист, что обеспечивает единственность решения.
Изучите основные понятия, которые используются в теории деревьев решений, чтобы в дальнейшем было проще усваивать новый материал.
Его применяют для поддержки процессов принятия управленческих решений, используемых в статистистике, анализе данных и машинном обучении. Инструмент помогает решать следующие задачи:
- Классификация. Отнесение объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные задачи.
- Регрессия (численное предсказание). Предсказание числового значения независимой переменной для заданного входного вектора.
- Описание объектов. Набор правил в дереве решений позволяет компактно описывать объекты. Поэтому вместо сложных структур, используемых для описания объектов, можно хранить деревья решений.
Основная задача при построении дерева решений — последовательно и рекурсивно разбить обучающее множество на подмножества с применением решающих правил в узлах. Но как долго надо разбивать? Этот процесс продолжают до того, пока все узлы в конце ветвей не станут листами.
Узел становится листом в двух случаях:
- естественным образом — когда он содержит единственный объект или объект только одного класса;
- после достижения заданного условия остановки алгоритм — например, минимально допустимое число примеров в узле или максимальная глубина дерева.
- n примеров, для каждого из которых задана метка класса Ci(i = 1..k);
- m атрибутов Aj(j = 1..m), которые определяют принадлежность объекта к тому или иному классу.
Тогда возможно три случая:
Третья применяется в большинстве алгоритмов, используемых для построения деревьев решений. Эта методика формирует дерево сверху вниз, то есть от корневого узла к листьям.
Сегодня существует много алгоритмов обучения: ID3, CART, C4.5, C5.0, NewId, ITrule, CHAID, CN2 и другие. Самыми популярными считаются:
Построение осуществляется в 4 этапа:
- Выбрать атрибут для осуществления разбиения в данном узле.
- Определить критерий остановки обучения.
- Выбрать метод отсечения ветвей.
- Оценить точность построенного дерева.
Далее рассмотрим каждый подробнее.
Разбиение должно осуществляться по определенному правилу, для которого и выбирают атрибут. Причем выбранный атрибут должен разбить множество наблюдений в узле так, чтобы результирующие подмножества содержали примеры с одинаковыми метками класса или были максимально приближены к этому. Иными словами — количество объектов из других классов в каждом из этих множеств должно быть как можно меньше.
Критериев существует много, но наибольшей популярностью пользуются теоретико-информационный и статистический.
В основе критерия лежит информационная энтропия:
где n — число классов в исходном подмножестве, Ni — число примеров i-го класса, N — общее число примеров в подмножестве.
Энтропия рассматривается как мера неоднородности подмножества по представленным в нем классам. И даже если классы представлены в равных долях, а неопределенность классификации наибольшая, то энтропия тоже максимальная. Логарифм от единицы будет обращать энтропию в ноль, если все примеры узла относятся к одному классу.
Если выбранный атрибут разбиения Aj обеспечивает максимальное снижение энтропии результирующего подмножества относительно родительского, его можно считать наилучшим.
Но на деле об энтропии говорят редко. Специалисты уделяют внимание обратной величине — информации. В таком случае лучшим атрибутом будет тот, который обеспечит максимальный прирост информации результирующего узла относительно исходного:
где Info(S) — информация, связанная с подмножеством S до разбиения, Info(Sa) — информация, связанная с подмножеством, полученным при разбиении атрибута A.
Задача выбора атрибута в такой ситуации заключается в максимизации величины Gain(A), которую называют приростом информации. Поэтому теоретико-информационный подход также известен под название «критерий прироста информации.
В основе этого метода лежит использования индекса Джини. Он показывает, как часто случайно выбранный пример обучающего множества будет распознан неправильно. Важное условие — целевые значения должны браться из определенного статистического распределения.
Если говорить проще, то индекс Джини показывает расстояние между распределениями целевых значений и предсказаниями модели. Минимальное значение показателя говорит о хорошей работе модели.
Индекс Джини рассчитывается по формуле:
где Q — результирующее множество, n — число классов в нем, pi — вероятность i-го класса (выраженная как относительная частота примеров соответствующего класса).
Значение показателя меняется от 0 до 1. Если индекс равен 0, значит, все примеры результирующего множества относятся к одному классу. Если равен 1, значит, классы представлены в равных пропорциях и равновероятны. Оптимальным считают то разбиение, для которого значение индекса Джини минимально.
Переобучение в случае дерева решений имеет схожие с нейронными сетями последствия. Оно будет точно распознавать примеры из обучения, но не сможет работать с новыми данными. Еще один минус — структура переобученного дерева сложна и плохо поддается интерпретации.
Для этого используют несколько подходов:
- Ранняя остановка. Алгоритм останавливается после достижения заданного значения критерия (например, процентной доли правильно распознанных примеров). Преимущество метода — сокращение временных затрат на обучение. Главный недостаток — ранняя остановка негативно сказывается на точности дерева. Из-за этого многие специалисты советуют отдавать предпочтение отсечению ветей.
- Ограничение глубины дерева. Алгоритм останавливается после достижения установленного числа разбиений в ветвях. Этот подход также негативно сказывается на точности дерева.
- Задание минимально допустимого числа примеров в узле. Устанавливается ограничение на создание узлов с числом примером меньше заданного (например, 7). В таком случае не будут создаваться тривиальные разбиения и малозначимые правила.
Этими подходами пользуются редко, потому что они не гарантируют лучшего результата. Чаще всего, они работают только в каких-то определенных случаях. Рекомендаций по использованию какого-либо метода нет, поэтому аналитикам приходится набирать практический опыт путем проб и ошибок.
Поэтому многие специалисты отдают предпочтение альтернативному варианту — построить все возможные деревья, а потом выбрать те, которые при разумной глубине обеспечивают приемлемый уровень ошибки распознавания. Основная задача в такой ситуации — поиск наиболее выгодного баланса между сложностью и точностью дерева.
Но и тут есть проблема: такая задача относится к классу NP-полных задач, а они, как известно, эффективных решений не имеют. Поэтому прибегают к методу отсечения ветвей, который реализуется в 3 шага:
- Строительство полного дерева, в котором листья содержат примеры одного класса.
- Определение двух показателей: относительную точность модели (отношение числа правильно распознанных примеров к общему числу примеров) и абсолютную ошибку (число неправильно классифицированных примеров).
- Удаление листов и узлов, потеря которых минимально скажется на точности модели и увеличении ошибки.
Отсечение ветвей проводят противоположно росту дерева, то есть снизу вверх, путем последовательного преобразования узлов в листья.
Иногда упрощения дерева недостаточно, чтобы оно легко воспринималось и интерпретировалось. Тогда специалисты извлекают из дерева решающие правила и составляют из них наборы, описывающие классы.
Для извлечения правил нужно отслеживать все пути от корневого узла к листьям дерева. Каждый путь дает правило с множеством условий, представляющих собой проверку в каждом узле пути.
Если представить сложное дерево решений в виде решающих правил (вместо иерархической структуры узлов), оно будет проще восприниматься и интерпретироваться.
Одним из популярных методов принятия решений являются деревья решений. С помощью этого метода можно принимать решения:
- по социальным и макроэкономическим вопросам;
- по развитию фирмы или в банковской сфере.
Деревья решений используются также для диагностики в медицине, экономике и бизнесе.
Содержание работы
Общая характеристика метода дерева решений ………………………..3
Порядок построения дерева решений …………………………………. 6
Преимущества деревьев решений ………………………………………10
Файлы: 1 файл
lдерево принятия решений попов.docx
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ ЭКОНОМИЧЕСКИЙ УНИВЕРСИТЕТ
КАФЕДРА УПРАВЛЕНИЯ И ПЛАНИРОВАНИЯ СОЦИАЛЬНО ЭКОНОМИЧЕСКИХ ПРОЦЕССОВ
Аналитическая работа на тему:
Дерево принятия решений
Дисциплина: Методы принятия управленческих решений
Выполнил: студент Попов Николай
М-307 группы 3 курса
Руководитель: доцент Пилипенко Валерия Ивановна
- Общая характеристика метода дерева решений ………………………..3
- Порядок построения дерева решений …………………………………. 6
- Преимущества деревьев решений ………………………………………10
- Общая характеристика метода дерева принятия решений
Одним из популярных методов принятия решений являются деревья решений. С помощью этого метода можно принимать решения:
- по социальным и макроэкономическим вопросам;
- по развитию фирмы или в банковской сфере.
Деревья решений используются также для диагностики в медицине, экономике и бизнесе.
Основное отличие деревьев решений от методов распознавания образов и моделирования состоит в том, что проводимое исследование основывается на логических рассуждениях, а не на вычислениях. Деревья решений – это один из методов построения экспертных систем на основе правил вывода. Такие системы называются системами прямого логического вывода, так как мы начинаем с фактов, в результате приходим к тому или иному выводу
Дерево решений – популярный метод науки управления, используемый для выбора наилучшего направления действий из имеющихся вариантов. Дерево решений – это схематичное представление проблемы принятия решений. Оно дает руководителю возможность учесть различные направления действий, соотнести с ними финансовые результаты, скорректировать их в соответствии с приписанной им вероятностью, а затем сравнить альтернативы. Концепция ожидаемого значения является неотъемлемой частью метода дерева решений.
Методом дерева решений можно пользоваться в ситуациях, подобных описанной выше, в связи с рассмотрением платежной матрицы. В этом случае предполагается, что данные о результатах, вероятности и т.п. не влияют на все последующие решения. Однако дерево решений можно построить под более сложную ситуацию, когда результаты одного решения влияют на последующие решения. Таким образом, дерево решений – это полезный инструмент для принятия последовательных решений.
Рис.1 Дерево решений
На рис. 1 проиллюстрировано применение метода дерева решений для разрешения проблемы, требующей определенной последовательности решений. Вице-президент по производству из компании, выпускающей электрические газонокосилки, считает, что расширяется рынок ручных косилок. Он должен решить, стоит ли переходить на производство ручных косилок, и если сделать это, – стоит или не стоит продолжать выпуск электрических газонокосилок. Производство косилок обоих типов потребует увеличения производственных мощностей. До принятия решения руководитель собрал релевантную информацию об ожидаемых выигрышах в случае тех или иных вариантов действий и о вероятности соответствующих событий. Эта информация представлена на дереве решений.
Прогнозы полезны для планирования и осуществления деловых операции только в том случае, если компоненты прогноза тщательно продуманы, а ограничения, содержащиеся в прогнозе, откровенно названы. Существует несколько способов сделать это:
Спросить себя, для чего нужен прогноз, какие решения будут на нем основаны. Этим определяется потребная точность прогноза. Некоторые решения принимать опасно, даже если возможная погрешность прогноза – менее 10%. Другие решения можно принимать безбоязненно даже при значительно более высокой допустимой ошибке.
Определить изменения, которые должны произойти, чтобы прогноз оказался достоверным. Затем с осмотрительностью оцените вероятность соответствующих событий.
Определить компоненты прогноза. Подумайте об источниках данных.
Определить, насколько ценен опыт прошлого в составлении прогноза. Не настолько ли быстры изменения, что основанный на опыте прогноз будет бесполезным? Дают ли данные по подобным продуктам (или вариантам развития) основания для составления прогноза о судьбе вашего продукта? Насколько просто или недорого можно будет получить надежную информацию об опыте прошлого?
Определить, насколько структурированным должен быть прогноз. При прогнозировании сбыта может быть целесообразно выделить отдельные части рынка (развивающиеся потребители, стабильные потребители, крупные и мелкие потребители, вероятность появления новых потребителей и т.п.).
Используя дерево решений, руководитель находит путем возврата от второй точки к началу наиболее предпочтительное решение – наращивание производственных мощностей под выпуск косилок обоих типов. Это обусловлено ожидаемым выигрышем (3 млн. долл.), который превышает выигрыш (1 млн. долл.) при отказе от такого наращивания, если в точке А будет низкий спрос на электрические косилки.
Руководитель продолжает двигаться назад к текущему моменту (первой точке принятия решений) и рассчитывает ожидаемые значения в случаях альтернативных действий – производства только электрических или только ручных косилок. Ожидаемое значение для варианта производства только электрических косилок составляет 6,5 млн. долл. (0,7 х 8 млн. долл. + 0,3 х 3 млн. долл.). Подобным образом рассчитывается ожидаемое значение для варианта выпуска только ручных косилок, которое равно всего 4,4 млн. долл. Таким образом, наращивание производственных мощностей под выпуск косилок обоих типов является наиболее желательным решением, поскольку ожидаемый выигрыш здесь наибольший, если события пойдут, как предполагается.
Дерево решений позволяет представить проблему схематично и сравнить возможные альтернативы визуально. Этот метод можно использовать в применении к сложным ситуациям, когда результат принимаемого решения влияет на последующие.
2. Порядок построения дерева решений
В наиболее простом виде дерево решений – это способ представления правил в иерархической, последовательной структуре. Основа такой структуры – ответы "Да" или "Нет" на ряд вопросов.
Рис.2. Дерево решений "Играть ли в гольф?"
На рис. 2 приведен классический пример дерева решений, задача которого – ответить на вопрос: "Играть ли в гольф?" Чтобы решить задачу, т.е. принять решение, играть ли в гольф, следует отнести текущую ситуацию к одному из известных классов (в данном случае – "играть" или "не играть"). Для этого требуется ответить на ряд вопросов, которые находятся в узлах этого дерева, начиная с его корня.
Первый узел нашего дерева "Солнечно?" является узлом проверки, т.е. условием. При положительном ответе на вопрос осуществляется переход к левой части дерева, называемой левой ветвью, при отрицательном – к правой части дерева. Таким образом, внутренний узел дерева является узлом проверки определенного условия. Далее идет следующий вопрос и т.д., пока не будет достигнут конечный узел дерева, являющийся узлом решения. Для нашего дерева существует два типа конечного узла: "играть" и "не играть" в гольф.
В результате прохождения от корня дерева (иногда называемого корневой вершиной) до его вершины решается задача классификации, т.е. выбирается один из классов – "играть" и "не играть" в гольф.
Целью построения дерева решения в нашем случае является определение значения категориальной зависимой переменной.
Итак, основными элементами дерева решений являются:
Корень дерева: "Солнечно?"
Внутренний узел дерева или узел проверки: "Температура воздуха высокая?", "Идет ли дождь?"
Лист, конечный узел дерева, узел решения или вершина: "Играть", "Не играть"
Ветвь дерева (случаи ответа): "Да", "Нет".
В рассмотренном примере решается задача бинарной классификации, т.е. создается дихотомическая классификационная модель. Пример демонстрирует работу так называемых бинарных деревьев.
Рассмотрим более сложный пример. База данных, на основе которой должно осуществляться прогнозирование, содержит следующие ретроспективные данные о клиентах банка, являющиеся ее атрибутами: возраст, наличие недвижимости, образование, среднемесячный доход, вернул ли клиент вовремя кредит. Задача состоит в том, чтобы на основании перечисленных выше данных (кроме последнего атрибута) определить, стоит ли выдавать кредит новому клиенту. Такая задача решается в два этапа: построение классификационной модели и ее использование.
На этапе построения модели, собственно, и строится дерево классификации или создается набор неких правил. На этапе использования модели построенное дерево, или путь от его корня к одной из вершин, являющийся набором правил для конкретного клиента, используется для ответа на поставленный вопрос "Выдавать ли кредит?"
Правилом является логическая конструкция, представленная в виде "если : то :"
На рис. 3. приведен пример дерева классификации, с помощью которого решается задача "Выдавать ли кредит клиенту?". Она является типичной задачей классификации, и при помощи деревьев решений получают достаточно хорошие варианты ее решения.
Рис. 3 Дерево решений "Выдавать ли кредит?"
Как видно из рисунка, внутренние узлы дерева (возраст, наличие недвижимости, доход и образование) являются атрибутами описанной выше базы данных. Эти атрибуты называют прогнозирующими, или атрибутами расщепления. Конечные узлы дерева, или листы, именуются метками класса, являющимися значениями зависимой категориальной переменной "выдавать" или "не выдавать" кредит.
Каждая ветвь дерева, идущая от внутреннего узла, отмечена предикатом расщепления. Последний может относиться лишь к одному атрибуту расщепления данного узла. Характерная особенность предикатов расщепления: каждая запись использует уникальный путь от корня дерева только к одному узлу-решению. Объединенная информация об атрибутах расщепления и предикатах расщепления в узле называется критерием расщепления.
На рис 3. изображено одно из возможных деревьев решений для рассматриваемой базы данных. Например, критерий расщепления "Какое образование?", мог бы иметь два предиката расщепления и выглядеть иначе: образование "высшее" и "не высшее". Тогда дерево решений имело бы другой вид.
Таким образом, для данной задачи (как и для любой другой) может быть построено множество деревьев решений различного качества, с различной прогнозирующей точностью.
Качество построенного дерева решения весьма зависит от правильного выбора критерия расщепления. Над разработкой и усовершенствованием критериев работают многие исследователи.
Метод деревьев решений часто называют "наивным" подходом. Но благодаря целому ряду преимуществ, данный метод является одним из наиболее популярных для решения задач классификации.
3. Преимущества деревьев решений
Интуитивность деревьев решений. Классификационная модель, представленная в виде дерева решений, является интуитивной и упрощает понимание решаемой задачи. Результат работы алгоритмов конструирования деревьев решений легко интерпретируется пользователем. Это свойство деревьев решений не только важно при отнесении к определенному классу нового объекта, но и полезно при интерпретации модели классификации в целом. Дерево решений позволяет понять и объяснить, почему конкретный объект относится к тому или иному классу.
Деревья решений дают возможность извлекать правила из базы данных на естественном языке. Пример правила: Если Возраст > 35 и Доход > 200, то выдать кредит.
Деревья решений позволяют создавать классификационные модели в тех областях, где аналитику достаточно сложно формализовать знания.
Читайте также: