
Поясните за счет чего происходит сжатие с потерями кратко
Обновлено: 04.07.2024
Недавно мы рассказывали про сжатие данных без потерь . Смысл в том, что существуют некие алгоритмы, которые позволяют уложить данные более компактно и передать их другому человеку, не потеряв ни байта.
Часто сжатия без потерь недостаточно. Сегодня поговорим о сжатии с потерями.
Чем отличается от сжатия без потерь
При таком сжатии мы теряем часть информации. Но смысл алгоритмов сжатия в том, чтобы мы этого не замечали: сжатие должно происходить так, чтобы всё важное передалось, а неважное — нет.
Можно представить, что мы говорим с человеком по телефону. Его голос немного искажён, может прерываться или немного сбоить. Но если мы смогли понять собеседника, то нам достаточно такого качества. При этом мы можем не расслышать какие-то нюансы, не ощутить всю глубину баса или не оценить все оттенки интонаций, но это нам и неважно. Разговор по телефону — это пример передачи информации с использованием сжатия с потерями.
Сжатие фотографий
Есть алгоритм сжатия для фотографий, который используют для изображений типа JPEG. В этом алгоритме изображение разделяется на один слой яркости и два слоя цвета (если упрощённо, то картинка разделяется, на чёрно-белый слой и на слой с красками).
Эти слои нарезаются на квадраты 8 × 8 пикселей и кодируются с помощью особой математики. Её смысл в том, чтобы понять: есть ли в этом квадрате 8 × 8 что-то важное. Если оно есть, то оно кодируется и данные сохраняются. Если квадрат более-менее однородный, то он записывается как однородный, данных мало.
А если у вас картинка нарезана отдельно на яркость и отдельно на цвет, вы экономите ещё больше данных: в слое с яркостью у вас будут все контрастные детали, а в цветовых слоях — плавные цветовые переливы. Плавные переливы легче закодировать, это будет незаметно для глаза.
Сжатие JPEG идеально подходит для фотографий, где размер деталей намного больше, чем размер пикселей.
Возьмём странное изображение винограда на ржавой трубе. Найдите различия между двумя картинками:
Теперь сожмём оригинал в 415 раз: было 10 мегабайт, стало 24 килобайта. При этом мы всё равно понимаем, что на фотографии — виноград с плодами на ржавой трубе. Наш мозг сглаживает эти неровности и узнаёт картинку.
Сжатие звука
Существуют алгоритмы сжатия для аудиозаписей. Их смысл в том, чтобы не кодировать ту часть данных, которая не особо влияет на восприятие аудиосигнала.
Например, человеческое ухо в среднем воспринимает звуки частотой от 20 герц до 20 килогерц. 20 Гц — это супергрудной бас, а 20 КГц — это супертонкий писк. Чтобы закодировать волну с максимальной частотой 20 КГц, на каждую секунду вам нужно 40 тысяч чисел размером 2 байта. Получается, что секунда несжатого звука будет занимать 80 килобайт.
Тогда из звука отсекается лишняя информация и кодируется только диапазон до 4 КГц. Для этого кодирования достаточно 16 килобайт в секунду. Это уже экономия в 5 раз!
Самая важная часть голоса вообще болтается в районе 1000—2000 герц. Если отрезать у голоса всё от 2 до 20 КГц, то нам хватит 8 КБ в секунду, а это экономия в 10 раз по сравнению с несжатым файлом.
Когда вы говорите по телефону, ваш голос сжимается в несколько сотен раз, потому что телефонный разговор заточен только под частоты голоса. Поэтому любая музыка в телефонной трубке звучит так погано.
Сжатие видео
Чтобы сжать видео, используют комбинацию сжатия картинок и звука. И есть один дополнительный момент: сжатие только изменяющихся частей кадра. Как это работает:
Пример кодирования одной и той же сцены с разной чувствительностью — на видео она отображена в килобитах в секунду. Чувствительность влияет на итоговый размер видеофайла:
Стримы и потоковое видео
В потоковом видео ситуация усугубляется тем, что данные нужно передавать миллионам людей как можно скорее. Поэтому, помимо того чтобы сжимать видео, стриминговые сервера ещё и меняют его физический размер, то есть из большой картинки делают маленькую.
- 144p — кадр состоит из 144 строк, то есть его высота — 144 пикселя
- 480p — кадр высотой 480 пикселей
- …
- 1080p — кадр высотой 1080 пикселей
Соответственно, чем выше кадр, тем он шире; тем больше размер изображения; тем больше деталей в него влезает.
Самое низкое качество, которое есть в потоковом видео — 144p. Мутная картинка и пиксели, зато можно смотреть даже с медленным интернетом
Самое низкое качество, которое есть в потоковом видео — 144p. Мутная картинка и пиксели, зато можно смотреть даже с медленным интернетом
То же самое видео в формате HD или 1080p — можно прочитать даже мелкие надписи в интерфейсе игры, запущенной на умных часах. Но для этого нужен быстрый интернет/img]
То же самое видео в формате HD или 1080p — можно прочитать даже мелкие надписи в интерфейсе игры, запущенной на умных часах. Но для этого нужен быстрый интернет/img]
Буква p в 1080p означает progressive — то есть кодируется каждая строка видеофайла. А бывает ещё буква i, которая означает interlaced. Это значит, что в одном кадре кодируются каждые чётные строки, а в следующем — каждые нечётные. Потом их объединяют в одной картинке, и если не знать, куда смотреть, то можно не заметить подвоха.
Машина кажется раздвоенной, потому что в одном кадре она была левее, в другом — правее, а потом эти два кадра соединили в одном, используя чересстрочное кодирование
Машина кажется раздвоенной, потому что в одном кадре она была левее, в другом — правее, а потом эти два кадра соединили в одном, используя чересстрочное кодирование
И что нам с этим делать
Да ничего особо. Радоваться, что в наше время можно смотреть потоковое видео в прямом эфире с телефона в разрешении 1080p через сотовую вышку, пользуясь роскошным сжатием и широкополосным доступом в интернет.
Идея, лежащая в основе всех алгоритмов сжатия с потерями, довольно проста: на первом этапе удалить несущественную информацию, а на втором этапе к оставшимся данным применить наиболее подходящий алгоритм сжатия без потерь. Основные сложности заключаются в выделении этой несущественной информации. Подходы здесь существенно различаются в зависимости от типа сжимаемых данных. Для звука чаще всего удаляют частоты, которые человек просто не способен воспринять, уменьшают частоту дискретизации, а также некоторые алгоритмы удаляют тихие звуки, следующие сразу за громкими, для видеоданных кодируют только движущиеся объекты, а незначительные изменения на неподвижных объектах просто отбрасывают. Методы выделения несущественной информации на изображениях будут подробно рассмотрены далее.
Прежде чем говорить об алгоритмах сжатиях с потерями, необходимо договориться о том, что считать приемлемыми потерями. Понятно, что главным критерием остаётся визуальная оценка изображения, но также изменения в сжатом изображении могут быть оценены количественно. Самый простой способ оценки – это вычисление непосредственной разности сжатого и исходного изображений. Договоримся, что под мы будем понимать пиксел, находящийся на пересечении i-ой строки и j-ого столбца исходного изображения, а под — соответствующий пиксел сжатого изображения. Тогда для любого пиксела можно легко определить ошибку кодирования , а для всего изображения, состоящего из N строк и M столбцов, можно вычислить суммарную ошибку . Очевидно, что, чем больше суммарная ошибка, тем сильнее искажения на сжатом изображении. Тем не менее, эту величину крайне редко используют на практике, т.к. она никак не учитывает размеры изображения. Гораздо шире применяется оценка с использованием среднеквадратичного отклонения .
Другой (хотя и близкий по сути) подход заключается в следующем: пиксели итогового изображения рассматриваются как сумма пикселей исходного изображения и шума. Критерием качества при таком подходе называют величину отношения сигнал-шум (SNR), вычисляемую следующим образом: .
Обе эти оценки являются т.н. объективными критериями верности воспроизведения, т.к. зависят исключительно от исходного и сжатого изображения. Тем не менее, эти критерии не всегда соответствуют субъективным оценкам. Если изображения предназначены для восприятия человеком, единственное, что можно утверждать: плохие показатели объективных критериев чаще всего соответствуют низким субъективным оценкам, в то же время хорошие показатели объективных критериев вовсе не гарантируют высоких субъективных оценок.
С процессом квантования и дискретизации связано понятие визуальной избыточности. Значительная часть информации на изображении не может быть воспринята человеком: например, человек способен замечать незначительные перепады яркости, но гораздо менее чувствителен к цветности. Также, начиная с определённого момента, повышение точности дискретизации не влияет на визуальное восприятие изображения. Таким образом, некоторая часть информации может быть удалена без ухудшения визуального качества. Такую информацию называют визуально избыточной.
Самым простым способом удаления визуальной избыточности является уменьшение точности дискретизации, но на практике этот способ можно применять только для изображений с простой структурой, т.к. искажения, возникающие на сложных изображениях, слишком заметны (см. Табл. 1)

Для удаления избыточной информации чаще уменьшают точность квантования, но нельзя уменьшать её бездумно, т.к. это приводит к резкому ухудшению качества изображения.
Рассмотрим уже известное нам изображение с. Предположим, что изображение представлено в цветовом пространстве RGB, результаты кодирования этого изображения с пониженной точностью квантования представлены в Табл. 2.

В рассмотренном примере используется равномерное квантование как наиболее простой способ, но, если важно более точно сохранить цветопередачу, можно использовать один из следующих подходов: либо использовать равномерное квантование, но значением закодированной яркости выбирать не середину отрезка, а математическое ожидание яркости на этом отрезке, либо использовать неравномерное разбиение всего диапазона яркостей.
Внимательно изучив полученные изображения, можно заметить, что на сжатых изображениях возникают отчётливые ложные контуры, которые значительно ухудшают визуальное восприятие. Существуют методы, основанные на переносе ошибки квантования в следующий пиксел, позволяющие значительно уменьшить или даже совсем удалить эти контуры, но они приводят к зашумлению изображения и появлению зернистости. Перечисленные недостатки сильно ограничивают прямое применение квантования для сжатия изображений.
Большинство современных методов удаления визуально избыточной информации используют сведения об особенностях человеческого зрения. Всем известна различная чувствительность человеческого глаза к информации о цветности и яркости изображения. В Табл. 3 показано изображение в цветовом пространстве YIQ, закодированное с разной глубиной квантования цветоразностных сигналов IQ:
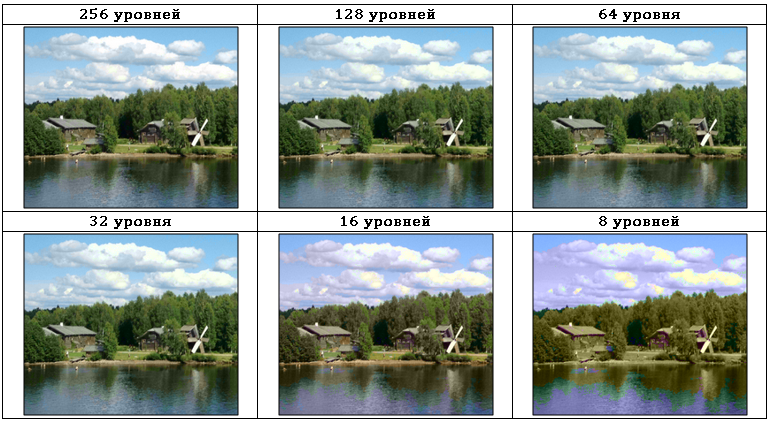
Как видно из Табл. 3, глубина квантования цветоразностных сигналов может быть понижена с 256 до 32 уровней с минимальными визуальными изменениями. В то же время потери в I и Q составляющих весьма существенны и показаны в Табл. 4

Несмотря на простоту описанных методов, в чистом виде они применяются редко, чаще всего они служат одним из шагов более эффективных алгоритмов.
Мы уже рассматривали кодирование с предсказанием как весьма эффективный метод сжатия информации без потерь. Если совместить кодирование с предсказанием и сжатие посредством квантования, получится весьма простой и эффективный алгоритм сжатия изображения с потерями. В рассматриваемом методе будет квантоваться ошибка предсказания. Именно точность её квантования будет определять как степень сжатия, так и искажения, вносимые в сжатое изображение. Выбор оптимальных алгоритмов для предсказания и для квантования — довольно сложная задача. На практике широко используют следующие универсальные (обеспечивающие приемлемое качество на большинстве изображений) предсказатели:


Мы же в свою очередь подробно рассмотрим самый простой и в тоже время весьма популярный способ кодирования с потерями – т.н. дельта-модуляцию. Этот алгоритм использует предсказание на основе одного предыдущего пиксела, т.е. . Полученная после этапа предсказания ошибка квантуется следующим образом:
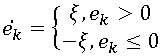
На первый взгляд это очень грубый способ квантования, но у него есть одно неоспоримое преимущество: результат предсказания может быть закодирован единственным битом. В Табл. 5 показаны изображения, закодированные с помощью дельта-модуляции (обход по строкам) с различными значениями ξ.

Наиболее заметны два вида искажений – размытие контуров и некая зернистость изображения. Это наиболее типичные искажения, возникающие из-за перегрузки по крутизне и из-за т.н. шума гранулярности. Такие искажения характерны для всех вариантов кодирования с потерями с предсказанием, но именно на примере дельта-модуляции они видны лучше всего.
Шум гранулярности возникает в основном на однотонных областях, когда значение ξ слишком велико для корректного отображения малых колебаний яркости (или их отсутствия). На Рис. 1 жёлтой линией отмечена исходная яркость, а синие столбцы показывают шум, возникающий при квантовании ошибки предсказания.

Ситуация перегрузки по крутизне принципиально отличается от ситуации с шумом гранулярности. В этом случае величина ξ оказывается слишком малой для передачи резкого перепада яркости. Из-за того, что яркость закодированного изображения не может расти также быстро, как яркость исходного изображения, возникает заметная размытость контуров. Ситуация с перегрузкой по крутизне поясняется на Рис. 2

Легко заметить, что шум гранулярности уменьшается вместе с уменьшением ξ, но вместе с этим растут искажения из-за перегрузки по крутизне и наоборот. Это приводит к необходимости оптимизации величины ξ. Для большинства изображений рекомендуется выбирать ξ∈[5;7].
Все рассмотренные ранее методы сжатия изображений работали непосредственно с пикселами исходного изображения. Такой подход называют пространственным кодированием. В текущем разделе мы рассмотрим принципиально иной подход, называемый трансформационным кодированием.
Основная идея подхода похожа на рассмотренный ранее способ сжатия с использованием квантования, но квантоваться будут не значения яркостей пикселов, а специальным образом рассчитанные на их основе коэффициенты преобразования (трансформации). Схемы трансформационного сжатия и восстановления изображений приведены на Рис. 3, Рис. 4.
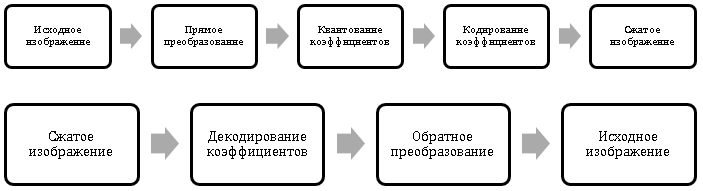
Непосредственно сжатие происходит не в момент кодирования, а в момент квантования коэффициентов, т.к. для большинства реальных изображений большая часть коэффициентов может быть грубо квантована.
Для получения коэффициентов используют обратимые линейные преобразования: например преобразование Фурье, дискретное косинусное преобразование или преобразование Уолша-Адамара. Выбор конкретного преобразования зависит от допустимого уровня искажения и имеющихся ресурсов.
В общем случае изображение размерами N*N пикселов рассматривается как дискретная функция от двух аргументов I(r,c), тогда прямое преобразование можно выразить в следующем виде:


Набор как раз и является искомым набором коэффициентов. На основе этого набора можно восстановить исходное изображение, воспользовавшись обратным преобразованием:
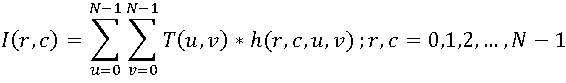

Функции называют ядрами преобразования, при этом функция g – ядро прямого преобразования, а функция h — ядро обратного преобразования. Выбор ядра преобразования определяет как эффективность сжатия, так и вычислительные ресурсы, требуемые для выполнения преобразования.
Широкораспространённые ядра преобразования
Наиболее часто при трансформационном кодировании используются ядра, перечисленные ниже.
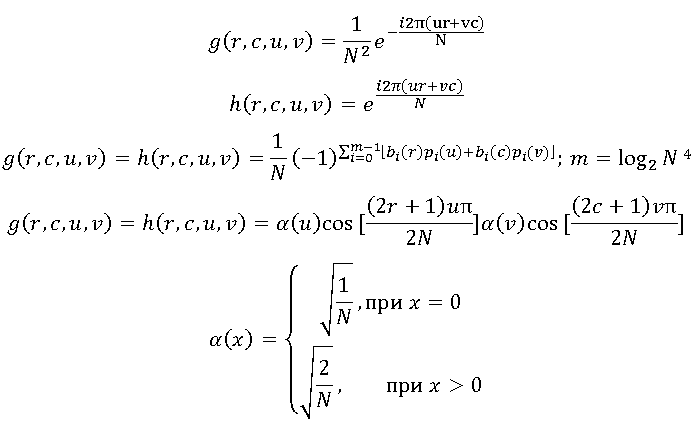
Использование первых двух ядер этих ядер приводит к упрощённому варианту дискретного преобразования Фурье. Вторая пара ядер соответствует довольно часто используемому преобразованию Уолша-Адамара. И, наконец, наиболее распространённым преобразованием является дискретное косинусное преобразование:
Широкая распространённость дискретного косинусного преобразования обусловлена его хорошей способностью производить уплотнение энергии изображения. Строго говоря, есть более эффективные преобразования. Например, преобразование Кархунена-Лоэва имеет наилучшую эффективность в плане уплотнения энергии, но его сложность практически исключает возможность широкого практического применения.
Сочетание эффективности уплотнения энергии и сравнительной простоты реализации сделало дискретное косинусное преобразование стандартом трансформационного кодирования.
Графическое пояснение трансформационного кодирования
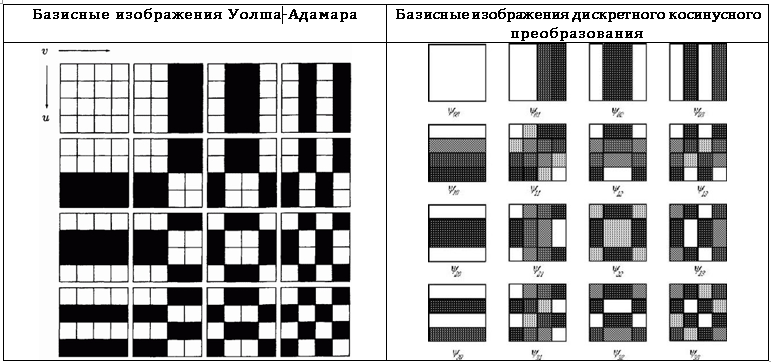
В контексте функционального анализа рассмотренные преобразования можно рассматривать как разложение по набору базисных функций. В то же время в контексте обработки изображений эти преобразования можно воспринимать как разложение по базисным изображениям. Чтобы пояснить эту идею, рассмотрим квадратное изображение I размером n*n пикселов. Ядра преобразований не зависят ни от коэффициентов преобразования, ни от значения пикселов исходного изображения, поэтому обратное преобразование можно записать в матричном виде:

Если эти матрицы расположить в виде квадрата, а полученные значения представить в виде пикселов определённого цвета, можно получить графическое представление базисных функций, т.е. базисные изображения. Базисные изображения преобразования Уолша-Адамара и дискретного косинусного преобразования для n=4 приведены в Табл. 7.
Особенности практической реализации трансформационного кодирования
Общая идея трансформационного кодирования была описана ранее, но, тем не менее, практическая реализация трансформационного кодирования требует прояснения нескольких вопросов.
Перед кодированием изображение разбивается на квадратные блоки, а затем каждый блок подвергается преобразованию. От выбора размера блока зависит как вычислительная сложность, так и итоговая эффективность сжатия. При увеличении размера блока растёт как эффективность сжатия, так и вычислительная сложность, поэтому на практике чаще всего используются блоки размером 8*8 или 16*16 пикселов.
После того, как для каждого блока вычислены коэффициенты преобразования, необходимо их квантовать и закодировать. Наиболее распространёнными подходами являются зональное и пороговое кодирование.
При зональном подходе предполагается, что наиболее информативные коэффициенты будут находиться вблизи нулевых индексов полученного массива. Это значит, что соответствующие коэффициенты должны быть наиболее точно квантованы. Другие коэффициенты можно квантовать значительно грубее или просто отбросить. Проще всего понять идею зонального кодирования можно, посмотрев на соответствующую маску (Табл. 8):

Число в ячейке показывает количество бит, отводимых для кодирования соответствующего коэффициента.
В отличие от зонального кодирования, где для любого блока используется одна и та же маска, пороговое кодирование подразумевает использование уникальной маски для каждого блока. Пороговая маска для блока строится, исходя из следующих соображений: наиболее важными для восстановления исходного изображения являются коэффициенты с максимальным значением, поэтому, сохранив эти коэффициенты и обнулив все остальные, можно обеспечить как высокую степень сжатия, так и приемлемое качество восстановленного изображения. В Табл. 9 показан примерный вид маски для конкретного блока.

Единицы соответствуют коэффициентам, которые будут сохранены и квантованы, а нули соответствуют выброшенным коэффициентам После применения маски полученная матрица коэффициентов должна быть преобразована в одномерный массив, причём для преобразования необходимо использовать обход змейкой. Тогда в полученном одномерном массиве все значимые коэффициенты будут сосредоточены в первой половине, а вторая половина будет практически полностью состоять из нулей. Как было показано в ранее, подобные последовательности весьма эффективно сжимаются алгоритмами кодирования длин серий.
Вейвлеты – математические функции, предназначенные для анализа частотных компонент данных. В задачах сжатия информации вейвлеты используются сравнительно недавно, тем не менее исследователям удалось достичь впечатляющих результатов.
В отличие от рассмотренных выше преобразований, вейвлеты не требуют предварительного разбиения исходного изображения на блоки, а могут применяться к изображению в целом. В данном разделе вейвлет сжатие будет пояснено на примере довольно простого вейвлета Хаара.
Для начала рассмотрим преобразование Хаара для одномерного сигнала. Пусть есть набор S из n значений, при преобразовании Хаара каждой паре элементов ставится в соответствие два числа: полусумма элементов и их полуразность. Важно отметить, что это преобразование обратимо: т.е. из пары чисел можно легко восстановить исходную пару. На Рис. 5 показан пример одномерного преобразования Хаара:

Видно, что сигнал распадается на две составляющее: приближенное значение исходного (с уменьшенным в два раза разрешением) и уточняющую информацию.
Двумерное преобразование Хаара – простая композиция одномерных преобразований. Если исходные данные представлены в виде матрицы, то сначала выполняется преобразование для каждой строки, а затем для полученных матриц выполняется преобразование для каждого столбца. На Рис. 6 показан пример двумерного преобразования Хаара.

Цвет пропорционален значению функции в точке (чем больше значение, тем темнее). В результате преобразования получается четыре матрицы: одна содержит аппроксимацию исходного изображения (с уменьшенной частотой дискретизации), а три остальных содержат уточняющую информацию.
Сжатие достигается путём удаления некоторых коэффициентов из уточняющих матриц. На Рис. 7 показан процесс восстановления и само восстановленное изображение после удаления из уточняющих матриц малых по модулю коэффициентов:

Очевидно, что представление изображения с помощью вейвлетов позволяет добиваться эффективного сжатия, сохраняя при этом визуальное качество изображения. Несмотря на простоту, преобразование Хаара сравнительно редко используется на практике, т.к. существуют другие вейвлеты, обладающие рядом преимуществ (например, вейвлеты Добеши или биортогональные вейвлеты).
Однако очевидно, что процесс этот не бесконечен. Где лежит этот предел, какие архиваторы доступны сегодня, по каким параметрам они конкурируют между собой, где найти свежий архиватор — вот далеко не полный перечень вопросов, которые освещаются в данной статье. Помимо рассмотрения теоретических вопросов мы сделали подборку архиваторов, которые можно загрузить с нашего диска, чтобы самим убедиться в эффективности той или иной программы и выбрать из них оптимальную — в зависимости от специфики решаемых вами задач.
Совсем немного теории для непрофессионалов
Позволю себе начать эту весьма серьезную тему со старой шутки. Беседуют два пенсионера:
— Вы не могли бы сказать мне номер вашего телефона? — говорит один.
— Вы знаете, — признается второй, — я, к сожалению, точно его не помню.
— Какая жалость, — сокрушается первый, — ну скажите хотя бы приблизительно…
Действительно, ответ поражает своей нелепостью. Совершенно очевидно, что в семизначном наборе цифр достаточно ошибиться в одном символе, чтобы остальная информация стала абсолютно бесполезной. Однако представим себе, что тот же самый телефон написан словами русского языка и, скажем, при передаче этого текста часть букв потеряна — что произойдет в подобном случае? Для наглядности рассмотрим себе конкретный пример: телефонный номер 233 34 44.
Избыточность естественных языков
R = (Hmax — H)/ Hmax
Измерение избыточности естественных языков (тех, на которых мы говорим) дает потрясающие результаты: оказывается, избыточность этих языков составляет около 80%, а это свидетельствует о том, что практически 80% передаваемой с помощью языка информации является избыточной, то есть лишней. Любопытен и тот факт, что показатели избыточности разных языков очень близки. Данная цифра примерно определяет теоретические пределы сжатия текстовых файлов.
Кодирование информации
Сжатие с потерями
В целом ряде случаев сжатие графики с потерями, обеспечивая очень высокие степени компрессии, практически незаметно для человека. Так, из трех фотографий, показанных ниже, первая представлена в TIFF-формате (формат без потерь), вторая сохранена в формате JPEG c минимальным параметром сжатия, а третья с максимальным. При этом можно видеть, что последнее изображение занимает почти на два порядка меньший объем, чем первая.Однако методы сжатия с потерями обладают и рядом недостатков.
Вторая причина заключается в том, что повторная компрессия и декомпрессия с потерями приводят к эффекту накопления погрешностей. Если говорить о степени применимости формата JPEG, то, очевидно, он полезен там, где важен большой коэффициент сжатия при сохранении исходной цветовой глубины. Именно это свойство обусловило широкое применение данного формата в представлении графической информации в Интернете, где скорость отображения файла (его размер) имеет первостепенное значение. Отрицательное свойство формата JPEG — ухудшение качества изображения, что делает практически невозможным его применение в полиграфии, где этот параметр является определяющим.
Теперь перейдем к разговору о сжатии информации без потерь и рассмотрим, какие алгоритмы и программы позволяют осуществлять эту операцию.
Сжатие без потерь
Сжатие, или кодирование, без потерь может применяться для сжатия любой информации, поскольку обеспечивает абсолютно точное восстановление данных после кодирования и декодирования. Сжатие без потерь основано на простом принципе преобразования данных из одной группы символов в другую, более компактную.
Наиболее известны два алгоритма сжатия без потерь: это кодирование Хаффмена (Huffman) и LZW-кодирование (по начальным буквам имен создателей Lempel, Ziv, Welch), которые представляют основные подходы при сжатии информации. Кодирование Хаффмена появилось в начале 50-х; принцип его заключается в уменьшении количества битов, используемых для представления часто встречающихся символов и соответственно в увеличении количества битов, используемых для редко встречающихся символов. Метод LZW кодирует строки символов, анализируя входной поток для построения расширенного алфавита, основанного на строках, которые он обрабатывает. Оба подхода обеспечивают уменьшение избыточной информации во входных данных.
Кодирование Хаффмена
Статическое кодирование
Статическое кодирование предполагает априорное знание таблицы вероятностей символов. К примеру, если вы сжимаете файл, состоящий из текста, написанного на русском языке, то такая информация может быть получена из предварительного статистического анализа русского языка.
Динамическое кодирование
LZW-сжатие
Алгоритм LZW [2], предложенный сравнительно недавно (в 1984 году), запатентован и принадлежит фирме Sperry.
Какой же выбрать архиватор?
Наверное, читателю будет интересно узнать, какой же архиватор лучше. Ответ на этот вопрос далеко не однозначен.
Если вас не волнуют меркантильные соображения, то прежде всего необходимо уяснить, что имеется целый ряд архиваторов, которые оптимизированы на решение конкретных задач. В связи с этим существуют различные виды специализированных тестов, например на сжатие только текстовых файлов или только графических. Так, в частности, Wave Zip в первую очередь умеет сжимать WAV-файлы, а мультимедийный архиватор ERI лучше всех упаковывает TIFF-файлы. Поэтому если вас интересует сжатие какого-то определенного типа файлов, то можно подыскать программу, которая изначально предназначена специально для этого.
Одними из лучших в данной категории можно назвать программы ASPACK и Petite. Более подробную информацию о программах данного класса, а также соответствующие рейтинги можно найти по адресу [4].
При этом необходимо отметить, что в тестах анализируются лишь количественные параметры, такие как скорость сжатия, коэффициент сжатия и некоторые другие, однако существует еще целый ряд параметров, которые определяют удобство пользования архиваторами. Перечислим некоторые из них.
Поддержка различных форматов
Большинство программ поддерживают один или два формата. Однако некоторые, такие, например, как программа WinAce, поддерживают множество форматов, осуществляя компрессию в форматах ACE, ZIP, LHA, MS-CAB, JAVA JAR и декомпрессию в форматах ACE, ZIP, LHA, MS-CAB, RAR, ARC, ARJ, GZip, TAR, ZOO, JAR.
Умение создавать solid-архивы
Создание solid-архивов — это архивирование, при котором увеличение сжатия возрастает при наличии большого числа одновременно обрабатываемых коротких файлов. Часть архиваторов, например ACB, всегда создают solid-архивы, другие, такие как RAR или 777, предоставляют возможность их создания, а некоторые, например ARJ, этого делать вообще не умеют.
Возможность создавать многотомные архивы
Многотомные архивы необходимы, когда файлы переносятся с компьютера на компьютер с помощью дискет и архив не помещается на одной дискете.
Возможность работы в качестве менеджера архивов
Различные программы в большей или меньшей степени способны вести учет архивам на вашем диске. Некоторые архиваторы, например WinZip, позволяют быстро добраться до любого архивного файла (и до его содержимого), в каком бы месте диска он ни находился.
Возможность парольной защиты
В принципе, архивирование есть разновидность кодирования, и если раскодирование доступно по паролю, то это, естественно, может использоваться как средство ограничения доступа к конфиденциальной информации.
Удобство в работе
Не последним фактором является удобство в работе — наличие продуманного меню, поддержка мыши, оптимальный набор опций, наличие командной строки и т.д. При этом необходимо отметить, что для многих (особенно непрофессионалов) важен фактор привычки. Если вы привыкли работать с определенной программой и вам сообщают, что есть альтернативная программа, которая на каком-либо тесте выигрывает у вашей десять пунктов, — это вполне может означать, что программа-победитель сжимает файлы лишь на 2% лучше, а для вас это не принципиально. При этом вероятно, что эта программа менее удобна в работе и т.д. Однако если вам не хватает именно 2%, чтобы сжать распространяемую вами программу до размера дискеты, то подобный архиватор для вас — находка.
Сегодня мы с вами познакомимся с процессом сжатия информации с потерями. Вышеназванный процесс означает, что после распаковки архива мы получим документ, несколько отличающийся от первоначального. Логически можно понять, что чем выше степень сжатия, тем больше величина потери и наоборот.
Сжатие с потерями используется в основном для архивации трех видов данных. Это:
- полноцветная графика;
- звук;
- видеоинформация.
Процесс сжатия с потерями обычно проходит в два этапа. Во время первого этапа исходная информация приведется (с потерями) к виду, в котором ее можно эффективно сжимать алгоритмами второго этапа сжатия без потерь.
Основное достоинство алгоритмов сжатия с потерями - это простота их реализации. Кроме того, эти алгоритмы обеспечивают очень высокую степень сжатия, при этом сохраняют необходимое для восстановления количество информации. Использование подобных алгоритмов, как правило, выгодно использовать для сжатия аналоговых величин, например, звуков или изображений. В подобных случаях конечный результат, вероятнее всего, будет очень отличаться от оригинала. Однако человек, который не снабжен специальным оборудованием, эту разницу может совсем не заметить.
Готовые работы на аналогичную тему
К алгоритмам сжатия с потерей информации относят, как правило, такие распространенные алгоритмы, как JPEG и MPEG. Первый можем использовать для сжатия фотоизображений. Полученные в итоге графические файлы будут иметь расширение .jpg. Алгоритмы MPEG будем использовать для сжатия видеоинформации и музыки. Эти файлы могут иметь различные расширения, что зависит от программы, в которой они сжимались, но наиболее распространенные из них: .mpg (для видео) и .мрз (для музыки).
Алгоритмы сжатия с потерей информации применяют лишь для решения каких-либо задач пользователя. Например, если фото нужно передать для просмотра, а музыку - для воспроизведения. Если же фото и музыку необходимо передать для дальнейшей обработки, например для редактирования, то даже минимальная потеря информации в исходном материале приведет к удручающим последствиям.
Величиной допустимой потери при сжатии обычно можно управлять. Это позволяет экспериментировать и добиваться оптимального соотношения размера и качества.
Алгоритмы сжатия с потерей информации
Алгоритм JPEG разработала группа фирм под названием Joint Photographic Experts Group. Целью данной разработки стало создание высокоэффективного стандарта сжатия как черно-белых, так и цветных изображений. С помощью этого формата можно регулировать степень сжатия информации, если задавать при этом степень потери качества. В настоящее время JPEG широко применяется там, где необходима высокая степень сжатия информации, например, в Интернете.
Представьте себе принцип действия алгоритма, при котором изображение нужно разбить на квадраты размером $8х8$ пикселей, после этого каждый квадрат, в свою очередь, преобразовать в последовательную цепочку, состоящую из $64$ пикселей. Каждую такую цепочку снова преобразовать, при этом входная последовательность пикселей будет представлена в виде суммы синусоидальных и косинусоидальных составляющих с кратными частотами. Эти составляющие называют гармониками. В данном случае нужно знать лишь амплитуду этих гармоник, чтобы восстановить входную последовательность с достаточной степенью точности. Чем больше количество известных нам гармонических составляющих, тем меньше будет расхождение между оригиналом и сжатым изображением. Большинство кодеров JPEG разрешают регулировать степень сжатия. Достигается это очень просто: чем выше степень сжатия устанавливаем, тем меньшее количество гармоник будет определять каждый блок из $64$ пикселей. Конечно же, достоинством этого кодирования является высокий коэффициент сжатия и сохранение при этом исходной глубины цвета. Именно это свойство способствует его широкому использованию в сети Интернет, где уменьшение размеров файлов имеет наиважнейшее значение, в мультимедийных энциклопедиях, где хранится максимальное количество графики в ограниченном объеме.
Недостатком данного формата является внутреннее ухудшение качества изображения. Именно это не позволяет применять его в полиграфии, где качество ценится превыше всего.
Однако формат JPEG не является единственным в своем роде, способным уменьшить размер конечного файла. В последнее время стал разрабатываться и использоваться алгоритм вейвлет-преобразования (или всплеск-преобразования). Основанные на сложнейших математических принципах вейвлет-кодеры способствуют получению большего сжатия, чем JPEG, при меньших потерях информации. Несмотря на сложность математики вейвлет-преобразования в программной реализации гораздо проще, чем JPEG. Хотя алгоритмы вейвлет-сжатия только начинают развиваться, им уготовано большое будущее.
Идея данного метода сжатия информации состоит в представлении изображений в более компактной форме - с помощью коэффициентов системы итерируемых функций (Iterated Function System - далее IFS). Давайте разберемся, как же с помощью IFS строится изображение, т.е. происходит процесс декомпрессии.
IFS представляют собой набор трехмерных аффинных преобразований, с помощью которых можно перевести одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве ($x$ - координата, $y$ - ордината, яркость).
Очень наглядно этот процесс продемонстрировал Барнсли, который описал принцип построения фотокопировальной машины, состоящей, в свою очередь, из экрана, на котором изображена исходная картинка, и системы линз, которая способна проецировать это изображение на другой экран.
Причем линзы проецируют часть изображения произвольной формы в любое место нового изображения, при этом области с новыми изображениями не пересекаются. Линза может менять яркость, контрастность, зеркально отражать и поворачивать свой фрагмент изображения. Она может масштабировать (уменьшать) свой фрагмент изображения.
Расставляя линзы и меняя их характеристики, можно управлять получаемым изображением. Одна итерация работы машины заключается в том, что согласно исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждают, что в процессе итераций можно получить изображение, которое не станет больше изменяться. Оно станет зависеть лишь от расположения и характеристик линз, и не станет зависеть от исходной картинки. Такое изображение называют "неподвижной точкой" или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Так как отображение линз является сжимающим, то каждая из них, в свою очередь, в явном виде задает самоподобные области в изображении. Благодаря этому подобию самой себе образуется довольно сложная структура изображения при любом увеличении. Таким образом, интуитивно мы понимаем, что система итерируемых функций задает фрактал (самоподобный математический объект).
Из вышесказанного становится понятным, как работает архиватор, и почему ему требуется так много времени для работы. То есть фрактальная компрессия – это, ничто иное, как поиск подобных самой себе областей в изображении и определение для них параметров.
Сравнение с JPEG
В настоящее время наиболее распространен алгоритм архивации графики JPEG. Давайте попробуем сравнить его с фрактальной компрессией. Для начала можно отметить, что оба алгоритма работают с $8$-битными (в градациях серого) и $24$-битными полноцветными изображениями. Оба принадлежат к классу алгоритмов сжатия с потерями и способны обеспечивать близкие коэффициенты архивации. И фрактальный алгоритм, и JPEG могут увеличивать степень сжатия за счет увеличения потерь. Помимо этого, оба довольно таки хорошо распараллеливаются.
Различия начинаются, когда мы начинаем рассматривать время, затраченное алгоритмами на процессы архивации и разархивации. Фрактальный алгоритм сжимает в сотни и даже в тысячи раз дольше, чем JPEG. Распаковку изображения, наоборот, данный алгоритм выполняет в $5-10$ раз быстрее. Исходя из этого, можно сделать вывод, что фрактальный алгоритм выгоднее применять в том случае, когда изображение будет сжато только 1 раз, а передавать его будут по сети и распаковывать много раз.
В алгоритме JPEG используют принцип разложения изображения по косинусоидальным функциям, в связи с этим потери могут проявляться в волнах и ореолах на границах резких переходов цветов. Этот эффект, как правило, сразу заметен при качественной печати.
Фрактальный алгоритм не обладает этим недостатком. Кроме того, при печати изображения всякий раз приходится выполнять масштабирование, так как растр печатающего устройства никак не может совпасть с растром изображения. При преобразовании также могут возникнуть другие достаточно неприятные эффекты, которые легко можно устранить при программном масштабировании изображения или же нужно укомплектовать устройство печати своими процессором, винчестером и набором программ обработки изображений (для дорогих фотонаборных автоматов). При использовании фрактального алгоритма подобные проблемы не возникают.
И, все-таки, методы сжатия с потерями имеют свои недостатки. Один из них состоит в том, что компрессия с потерями информации может применяться не во всех случаях анализа графики. К примеру, если в процессе сжатия изображения на лице вдруг изменится форма родинки (лицо же при этом все равно останется узнаваемым), то эта фотография окажется вполне пригодной, чтобы выслать ее почтой друзьям или же родственникам. Но в случае, когда пересылается снимок, например, какого-либо органа человека на медицинскую экспертизу для анализа, в этом случае искажения просто нельзя допускать. Другой недостаток заключается в том, что с каждой повторной компрессией и декомпрессией погрешности будут накапливаться все больше и больше.
Читайте также:
- Приоритетность образования требует выделения значительных средств из бюджета как государства кратко
- Тотальный диктант создан для тех кому в школе нравилось писать
- От чего зависят вкусовые качества бульона кратко
- Почему военное дело было в средние века основным занятием феодалов кратко
- Какие главные перемены на руси и в облике москвы произошли при иване третьем кратко