
Почему необходимо использовать транслятор кратко
Обновлено: 05.07.2024
К сожалению, очень быстро пришло понимание того, что:
- CPython довольно слабо поддерживается для такого популярного проекта, и имеет кучу старых проблем, которые вылазят наружу при попытке перекроить реализацию. В итоге Эрик уже несколько лет ковыряет интерпретатор с переменным прогрессом;
- даже после успешной реализации множественных интерпретаторов не совсем ясно, как дальше организовывать параллельное выполнение. В PEP предлагается использовать простые каналы, но этот инструмент становится опасным по мере усложнения задачи, с угрозами зависания и непредсказуемого поведения;
- сам язык имеет большие проблемы, не дающие интерпретаторам непосредственно обмениваться данными и давать некую гарантию предсказуемости поведения.
Теперь более детально о проблемах.
Изменяемые определения классов
Да, я понимаю, что класс в питоне объявляется во время выполнения. Но, блин, зачем в него совать переменные? Зачем в старые объекты добавлять новые методы? В какой-нибудь Java нельзя объявлять функции и переменные вне классов, но в питоне такого ограничения нет (и питон создан до джавы). Причем, попрошу обратить внимание на то, как нужно нагибаться раком для того, чтобы добавить аналогичные методы в сам объект, а не в класс — для этого нужны types.MethodType, function.__get__, functools.partial, и так далее.
Я бы хотел для начала задать странный вопрос: а зачем вообще в питоне нужны методы? Не функции, как в близком JavaScript, а именно методы класса. Один из факторов: Гвидо не придумал лучше способов сделать короткие имена функций (чтобы не было сишного gtk_button_set_focus_on_click), поскольку не ясно, как выбирать из кучи похожих функций с коротким именем нужную под этот конкретный объект. Тем не менее, в питоне появились len, iter, next, isinstance, slice, dict, dir, str, repr, hash, type — сейчас это обертки над соответствующими методами классов с подчеркиваниями в имени, а когда-то встроенные простые типы не являлись классами и работали только через эти функции. Лично я не вижу особой разницы между записью method(object) и object.method — особенно если method является статичной функцией, которой, в общем-то, все равно, какой первый аргумент (self) принимать.
Динамические определения классов в общем случае:
- не дают модульно тестировать. Правильно отработавший в тесте кусок кода может выдать ошибку при работе целой системы, и никак вы от этого не защититесь в рамках CPython;
- создают большие сложности оптимизации. Объявление класса не дает вам гарантии по поводу фактической работы класса. По этой причине единственный успешный проект оптимизатора, PyPy, использует трассировку для обнаружения фактической последовательности выполняемых действий методом пробы;
- не состыковываются с параллельным выполнением кода. Например, тот же multiprocessing работает с копиями определений классов, и если вы не дай бог измените описание классов в одной из копий, то ваше приложение рискует развалиться.
Горячая замена классов нужна для целей отладки и банальной кодописи, но это все-таки должен быть специализированный инструмент для разработчика, а не артефакт во время выполнения, от которого нельзя избавиться.
Компилируемые классы — это только маленький шаг, который уже сделали в Cython и Nuitka, но одного этого шага без других изменений недостаточно для получения какого-то значимого эффекта даже в плане скорости выполнения, поскольку, например, питон широко использует динамическое связывание переменных, которое никуда не девается в откомпилированном коде.
Множественное наследование
Множественное наследование не является прямой проблемой для параллелизации и оптимизации, но усложняет читаемость и поддерживаемость кода — это так называемый лазанья-код (по аналогии со спагетти-кодом).
Генераторы
Это прямо-таки запущенный случай GoTo, когда выполнение не просто бесконтрольно прыгает по коду — оно прыгает по стэкам. Особенно лютая дичь происходит, когда генераторы пересекаются с менеджерами контекста (привет PEP 567). Если в питоне есть общая тенденция запутывать приложение в тесный клубок связанных изменяемых состояний, не дающих пространства для маневров тестирования, параллелизации, и оптимизации программы, то генераторы — вишенка на этом торте.
Как вы думаете, какой будет результат выполнения программы:
Если этот пример показался вам слишком простым, то предлагаю с такой же легкостью предсказать выполнение немного измененной версии:
Интересный факт: транслятор RPython превращает генератор в класс-итератор. Это то, как генераторы и должны были быть сделаны. Ну а пока что наличие генераторов в коде не дает возможности для оптимизации, параллелизации, и тестирования.
Изменяемые значения
Что же это за такой странный зверь тогда — списки [] питона? Это оптимизация кортежей, костыль, потому что операции с пересозданием кортежей на большом числе значений становятся очень медленными. К слову, создатель Clojure не согласился с таким подходом, и сделал быстрые неизменяемые списки с чем-то вроде partial-copy-on-write при выполнении операций над этими списками. Гвидо же сделал доживший до наших дней костыль, и не сделал адекватные средства работы с этими костылями.
Что делать с изменяемыми данными? К которым, кстати, также относятся и объекты в целом. Например, можно делать copy-on-write на присвоении, и явные операции изменения данных по месту без копирования: b.append. b[]. b +=… Результат: устранение случайных связей между объектами, гарантия неизменяемости извне обладаемого объекта, а в итоге — упрощение параллелизации, оптимизации, тестирования. К сожалению, отваливается код, который опирался на старую логику работы списков, когда автору понадобилось, чтобы список/объект/ассоциативный массив таки менялся из разных мест, пусть это поведение и не очевидно из самого кода.
Почему Гвидо сразу не сделал язык с copy-on-write? Потому что та реализация оригинального интерпретатора не давала простой возможности отслеживать ссылки и копировать объекты, в частности, это требовало как минимум введения двойного указателя (вложенного), где указатель из функции на Си читает адрес объекта (который может меняться), а уже по этому адресу лежат сами данные, скопированные или общие неизмененные.
Полиморфизм и множественная диспетчеризация
Например, в Си тип данных — это не сами данные, это способы работы с ними. По этой причине Си глубоко полиморфичен, то есть, позволяет однообразно обрабатывать разные типы данных. Например, вы можете превратить указатель на double в указатель на char, скопировать байты через последний указатель, потом взять эти байты как указатель на double и работать дальше с ними как с числом.
При этом, язык способен сам совмещать в операциях (сложение, сравнение, присвоение) различные типы данных — эта фича давным давно возникла в самых разных ЯП и почему-то воспринимается как данность, но это весьма сложный и, порой, коварный механизм.
Вернемся к нашим баранам: Гвидо не придумал, как сделать множественный полиморфизм. В языке, фундамент которого представляет собой полиформизм всех аргументов. Есть и утешительный вывод: он здесь не одинок, и куча создателей ООП языков тоже не придумали ничего годного. К сожалению, чисто классовая модель решительно провальна в этом плане, потому что дает исключительно одиночный полиморфизм — через виртуальный метод класса.
В тех же крестах и жаве для обхода ограничения существуют перегруженные методы, которые позволяют реализовывать один и тот же метод для разных аргументов типов. В этом решении есть проблема, которая привела к появлению такого уродливого подхода, как шаблон Посетитель. А именно, с перегрузкой методов класс опять-таки должен уметь всё на свете вместо того, чтобы нужные частные реализации принадлежали частными комбинациям типов.
Поскольку полиформизм на уровне ООП работает отвратительно, то целая куча функций из стандартной библиотеки питона представляют из себя отдельный интерпретатор, который самостоятельно читает программу (то есть тип и значение аргументов), и принимает решение о принимаемых действиях (приведение к единому типу или ветвление), а потом выбрасывает результат на вход следующему интерпретатору. И самое печальное здесь то, что теперь такой способ выполнения программы диктует расширениями питона и другим реализациям питона действовать точно так же, повторяя заморочки реализации всех мелких интерпретаторов (функций стандартной библиотеки). Помимо банальной производительности, это лишает предсказуемости, поскольку тип на выходе может неожидано измениться при неизвестных обстоятельствах — у нас же нет никакой гарантии типов, помните? Построение языка на мелких недостаточно предсказуемых интерпретаторах в итоге является одной из ключевых причин потери возможности оптимизации кода и статической проверки типов.
Здесь мы создаем оператор вычитания с типажем аргумента MyList, который как бы наследует Iterable (наличие метода __iter__) и Container (метод __contains__), которые оба поддерживаются list, и потому list можно как бы приводить к MyList, хотя ни MyList не является наследником list, ни list не является наследником MyList. Этот код в классическом питоне выглядел бы как:
Оператор присвоения и статическая типизация
Давайте вспомним, что многие классы из стандартной библиотеки питона скомпилированы статически, в виде встроенных функций интерпретатора или расширений на Си. Очевидно, что они ждут вполне конкретный ограниченный набор входных параметров, для проверки которых применяют собственные велосипеды, и они хранят внутренние данные в фиксированном формате, который не может внезапно измениться, например, с массива на строку. Огромное количество проблем в программах на чистом питоне возникло из-за того, что присваивание питоне абсолютно слепо — оно просто берет любую ссылку-объект на вход, и присваивает эту ссылку левому выражению. Например:
Удачи вам искать подобную ошибку в коде на сотни тысяч строк.
Конечно, мы не можем заставлять программистов использовать только один тип в одной переменной, поскольку запихивание кучи типов в одну переменную стало уже сложившейся традицией. Даже банальный None — это уже другой тип, NoneType. Однако же, есть законченные куски кода — модули и объекты, которые в реализации на Си более-менее блюдут чистоту типов, но при написании на питоне внезапно эту чистоту теряют. Давайте рассматрим на простейшем примере теоретическую новую модель:
Здесь создается класс A с полиморфным типом атрибута val, который конкретизируется выводом типа из конструктора. Естественно, кто-то извне может захотеть добавить свой собственный атрибут в объект (myattr) — этот атрибут будет уже находиться на уровне экземпляра объекта, и дальше уже создающий и использующий экземпляр код будет разбираться, нужно ли проверять тип или нет.
Ожидаемо, такие финты ушами плохо состыковываются с динамически изменяемым описанием класса. Класс здесь должен быть не просто статичен — он является шаблоном, обобщением для частного класса, генерируемого в коде создания и использования объекта. Возьмем тот же класс, только теперь зададим ему несколько иной тип:
Здесь вызывающий код создает как бы A , в результате чего функция успешно выполняется. Естественно, при строго построчной интерпретации проверить тип не представляется возможным, потому код создания и инициализации объекта завернут в функцию.
Вывод типов
PyPy, а также аналогичные V8 для JavaScript и LuaJIT, испытывают проблемы с выводом типов до выполнения программы, потому они предпочитают конкретизировать типы уже после выполнения кода. Отсюда возникает проблема избыточного использования ресурсов из-за компиляции во время выполнения, и проблема параллелизации, которая не может происходить во время оптимизации и разоптимизации функций. По этой причине так активно развиваются проекты AOT компиляции, как то asm.js, WebAssembly, и почивший с миром PNaCl.
Давайте поверхностно пробежимся по истории развития идеи вывода типов:
- Bauer, A.M. and Saal, H.J. (1974). Does APL really need run-time checking? Software — Practice and Experience 4: 129–138.
- Kaplan, M.A. and Ullman, J.D. (1980). A scheme for the automatic inference of variable types. J. A CM 27(1): 128–145.
- Borning, A.H. and Ingalls, D.H.H. (1982). A type declaration and inference system for Smalltalk. In Conference Record of the Ninth Annual ACM Symposium on Principles of Programming Languages (pp. 133–141) — 1984 год.
Насколько мне известно, Standard ML был первым языком, который полноценно опирался на вывод типов, а не использовал его в качестве дополнительного инструмента.
Конечно, вывод по Хиндли-Милнеру больше подходит для функциональных языков и достаточно простой системы типов, в которой полный вывод составных типов не приводит к безграничному числу справедливых сочетаний конкретных типов. К сожалению, обычно математики отвратительно программируют, а программисты — ничего не могут понять в математике, потому довольно долгое время математики прыгали на единорогах по радуге, выдавая бесполезные абстрактные модели (чем они до сих пор и занимаются), пока постепенно чудом не возникло локальное выведение типов:
Последний вариант вывода типов — это примерно то, вокруг чего возникла Scala, создание которой началось в 2001 году.
Я — глупый и наивный максималист. Для вас не составит труда показать мне моё место, или пояснить, как вы могли бы сделать лучше.
Транслятор — это программа, преобразующая программу, написанную на одном из языков высокого уровня, в программу, состоящую из машинных команд.
Программу, которая написана на языке высокого уровня, перед применением необходимо преобразовать в программу на машинном языке, то есть в машинных кодах. Этот процесс носит название трансляции, или компиляции. По типу выходных данных существуют следующие основные виды трансляторов:
- Трансляторы, компилирующие окончательный исполняемый код.
- Трансляторы, компилирующие интерпретируемый код, для выполнения которого требуется дополнительное программное обеспечение.
Окончательным исполняемым кодом считаются приложения, которые реализованы как EXE-файлы, DLL-библиотеки, COM-компоненты. К интерпретируемому коду могут быть отнесены байт-коды JAVA-программ, исполняемых при посредстве виртуальной машины JVM.
Языки, которые формируют окончательный исполняемый код, именуются компилируемыми языками. К ним относятся языки С, C++, FORTRAN, Pascal. Языки, которые реализуют интерпретируемый код, носят название интерпретируемых языков. К таким языкам могут быть отнесены языки Java, LISP, Perl, Prolog.
Практически всегда код, который получается в результате процесса трансляции, создаётся из набора программных модулей. Программным модулем является определенным образом сформированный код на языке высокого уровня. Процесс трансляции в таком случае может исполняться как единое целое, то есть как компиляция и редактирование связей, или как два раздельных этапа, а именно, вначале компиляция объектных модулей, а далее обращение к редактору связей, который создаёт итоговый код. Последний вариант считается более удобным для формирования программ. Его реализовали в трансляторах языков С и С++.
Объектный код, который создаётся компилятором, состоит из области данных и области машинных команд, обладающих адресами, далее согласуемых редактором связи (иногда именуемым). Редактор связи распределяет в едином адресном пространстве все, по отдельности, откомпилированные, объектные модули и разные, подключаемые статически, библиотеки. Исполняемой формой программы является код, получаемый в результате трансляции исходной программы.
Готовые работы на аналогичную тему
Процесс трансляции
Программа, которая написана на языке программирования высокого уровня, называется исходной программой, а каждая самостоятельная программная единица, входящая в состав данной программы, называется программным модулем. Для того чтобы преобразовать исходную программу в её исполняемую форму (исполняемый файл) транслятор должен выполнить определённую последовательность действий. Данная последовательность определяется как языком программирования, так конкретной реализацией самого транслятора. В процессе трансляции нужно не просто осуществить компиляцию программы, а сформировать при этом достаточно эффективный код.
- Трансляторы однопроходного типа.
- Трансляторы двухпроходного типа.
- Трансляторы, выполняющие более двух проходов.
Основным достоинством однопроходного компилятора считается высокая скорость компиляции, а главным недостатком является формирование, как правило, не очень эффективного кода.
Широко распространены двухпроходные компиляторы, поскольку они дают возможность на первом проходе осуществить анализ программы и сформировать информационные таблицы, которые используются при втором проходе для создания объектного кода.
На рисунке ниже изображены основные этапы, исполняемые в процессе трансляции исходной программы.
Рисунок 1. Этапы трансляции. Автор24 — интернет-биржа студенческих работ
Фаза анализа программы включает в свой состав следующие шаги:
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
При осуществлении анализа исходной программы транслятор поочерёдно выполняет просмотр текста программы, представленной в виде набора символов, осуществляя разбор структуры программы.
На этапе лексического анализа реализуется выделение главных составных компонентов программы, называемых лексемами. Лексемами считаются ключевые слова, идентификаторы, символы операций, комментарии, пробелы и разделители. Лексический анализатор осуществляет выделение лексем, а также определение типа каждой лексемы. Причём на этапе лексического анализа формируется таблица символов, в которой все идентификаторы получают свои адреса. Это даёт возможность в ходе дальнейшего анализа вместо конкретного значения (строки символов) применять его адрес в таблице символов.
На этапе синтаксического анализа осуществляется разбор найденных лексем для получения семантически ясных синтаксических элементов, обрабатываемых далее семантическим анализатором. Таким образом, синтаксическими единицами могут выступать выражения, объявление, оператор языка программирования, вызов функции.
При реализации семантического анализа осуществляется обработка синтаксических элементов (единиц) и формирование промежуточного кода. В зависимости от того, присутствует или отсутствует фаза оптимизации, итогом семантического анализа могут являться промежуточный код или уже окончательно сформированный объектный модуль.
Наиболее общими задачами, решаемыми семантическим анализатором, считаются следующие задачи:

- Трансля́тор — программа или техническое средство, выполняющее трансляцию программы.
Трансля́ция програ́ммы — преобразование программы, представленной на одном из языков программирования, в объектный файл. Транслятор обычно выполняет также диагностику ошибок, формирует словари идентификаторов, выдаёт для печати текст программы и т. д.
Язык, на котором представлена входная программа, называется исходным языком, а сама программа — исходным кодом. Выходной язык называется целевым языком, а выходная (результирующая) программа — объектным кодом.
трансля́тор
1. комп. программа или техническое средство, выполняющее трансляцию программы
Делаем Карту слов лучше вместе
Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать Карту слов. Я отлично умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова ассирийский (прилагательное):
Наверное, каждый сталкивался с такой проблемой, когда сигнал Wi-Fi сети слабый или вообще не доходит до нужной комнаты. К сожалению, перестановка роутера в другое место помогает не всегда. При таких обстоятельствах следует задуматься о покупке Wi-Fi ретранслятора.
Общие сведения
Что такое репитер? Это девайс, который копирует Wi-Fi сеть и распространяет ее в пределах своей мощности. Также приспособление еще называют Wi-Fi повторитель.
Принцип работы
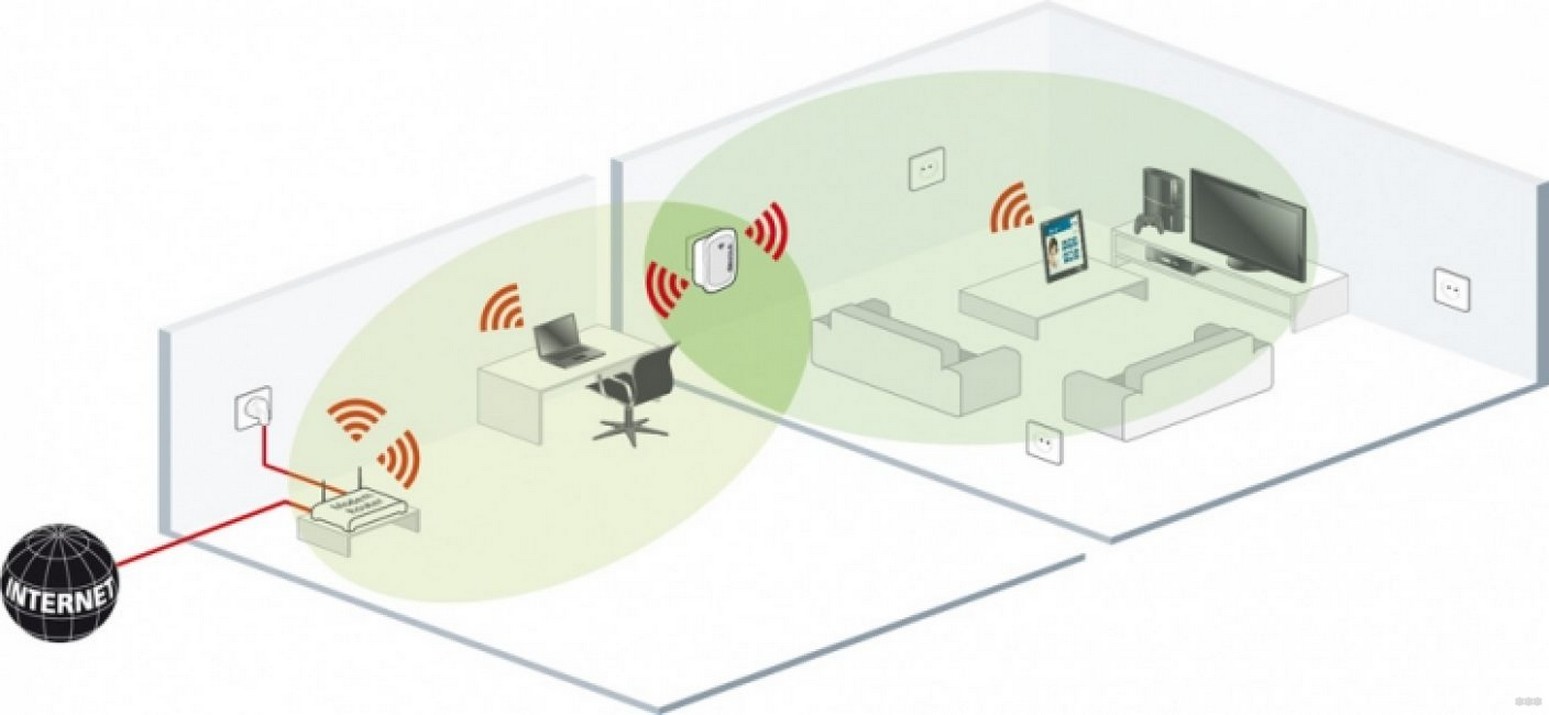
Некоторые думают, что подсоединение устройства к домашней сети сделает уже существующий сигнал мощнее. Сформировалось ложное представление о том, что прибор может повышать скорость интернета и невообразимо далеко распространять сигнал. Но репитер работает не так.
Для чего же нужен ретранслятор? Приспособление рассчитано исключительно на копирование и расширение области покрытия там, где уже имеется подача сети. То есть в ту область, где сигнал слабый или отсутствует. Это может быть аграрная территория, большой загородный дом или коттедж, большая площадь в каком-нибудь офисном здании или другом общественном месте.
Для наглядности и большего понимания предлагаю посмотреть видео:
Когда устройство необходимо?
Перед тем, как покупать девайс, нужно подумать о других возможных решениях вопроса:
- Иногда качество сигнала может зависеть от неправильного позиционирования роутера. В такой ситуации нужно просто переставить его так, чтобы сигнал распространялся дальше, преодолевая препятствия в виде стен. Чем ближе к центру пространства, с геометрической точки зрения, будет располагаться роутер, тем лучше будет сигнал во всем доме.
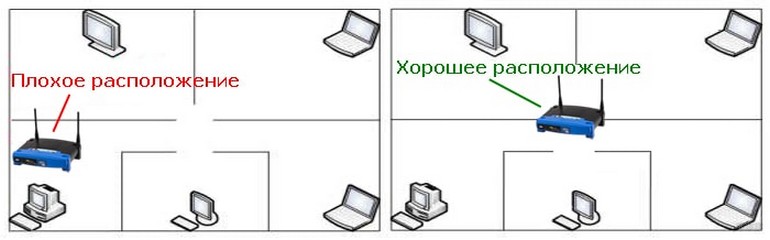
- Не лишним будет настроить направление антенн роутера. Если вам необходимо, чтобы сигнал распространялся вертикально, то нужно устанавливать их концом вверх.
- Если у вас двухдиапазонный роутер, попробуйте переключиться на частоту 5 ГГц. Если же маршрутизатор работает только на 2,4 ГГц, смените канал.
- В настройках роутера найдите пункт, который отвечает за мощность сигнала и выставьте его параметры на максимальное значение.
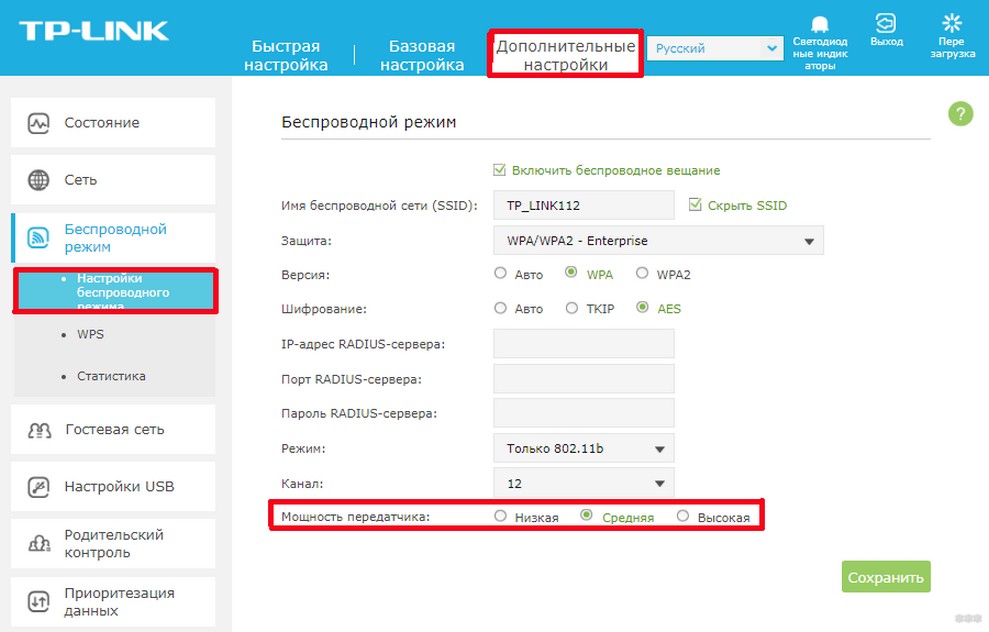
Если вышеперечисленные действия не помогли расширить диапазон сигнала, и он не доходит до необходимого места, то стоит основательно задуматься о покупке репитера.
В следующем видео – 5 способов усилить сигнал Вай-Фай:
Как выглядит?

В зависимости от конфигурации и других технических характеристик, Wi-Fi репитер может принимать внешний вид от подобия небольшой зарядки для смартфона и до габаритного роутера. Первый вариант выглядит как небольшой блок питания или дугообразная пластина с вилкой для подключения в розетку. На таких устройствах расположено несколько LED-индикаторов, Ethernet-порт и клавиши управления.
Второй вариант практически идентичен простому роутеру. Большой репитер имеет одну или пару антенн, Ethernet-порт и USB-вход для подключения накопителя и установки драйверов.
Подключение через кнопку WPS

Теперь переходим непосредственно к использованию Wi-Fi повторителя. Многие устройства оснащены кнопкой WPS. Ее цель – упростить соединение роутера с репитером. Но не все так однозначно. При определенных обстоятельствах она создает препятствия в работе с сетью.
Если на корпусе ретранслятора и маршрутизатора имеется кнопка WPS, для связывания двух устройств нужно проделать несколько действий:
- Нажать и удержать кнопку WPS на роутере.
- То же проделать и с клавишей на повторителе (кнопки нажимают одновременно!).
Метод подключения Вай-Фай повторителя вручную является более безопасным. Ведь во время работы WPS к роутеру может подсоединиться кто угодно, а это не всегда хорошо заканчивается.
Не стоит забывать о том, что в определенных моделях роутеров кнопка WPS наделена также функцией перезагрузки устройства. При долгом удерживании зажатой клавиши можно перезагрузить девайс, тем самым сбив некоторые установки.
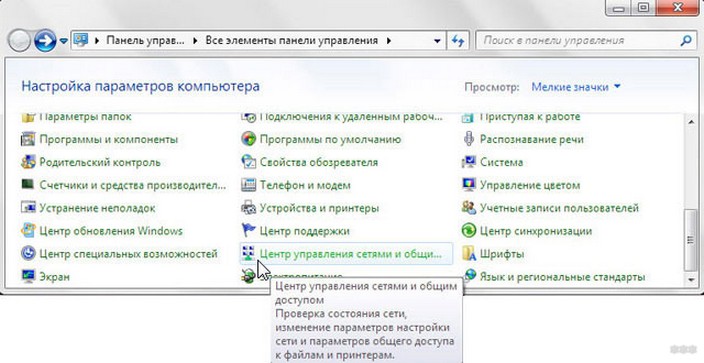
Ручной способ подключения
Этот метод посложнее, чем через WPS, но безопаснее. Осуществляется он так:
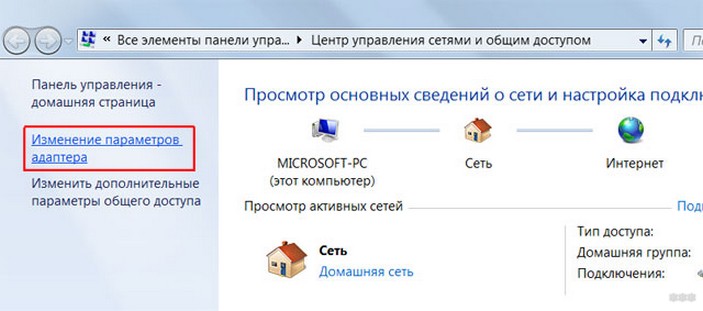
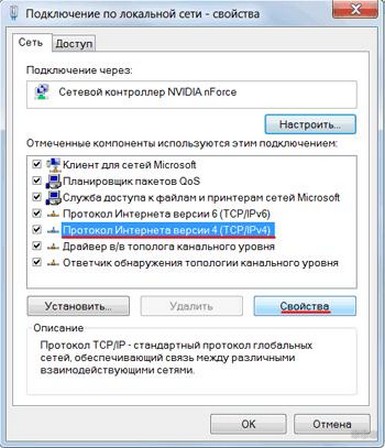
Роутер как замена репитеру

Есть вариант заменить Wi-Fi ретранслятор роутером. Если вдруг у вас где-то завалялся запасной работающий маршрутизатор, то он в состоянии полноценно выполнять функции ретранслятора. Чтобы роутер выполнял задачу репитера, нужно всего-навсего правильно его настроить. Однако, на это способны не все модели.
Процесс настройки роутера под репитер сложный, гораздо сложнее настройки Wi-Fi ретранслятора. Однако осилить его сможет практически каждый. Задача значительно упростится, если у приборов будет один и тот же производитель.
После детального ознакомления с роутером можно приступать к самому процессу настройки:
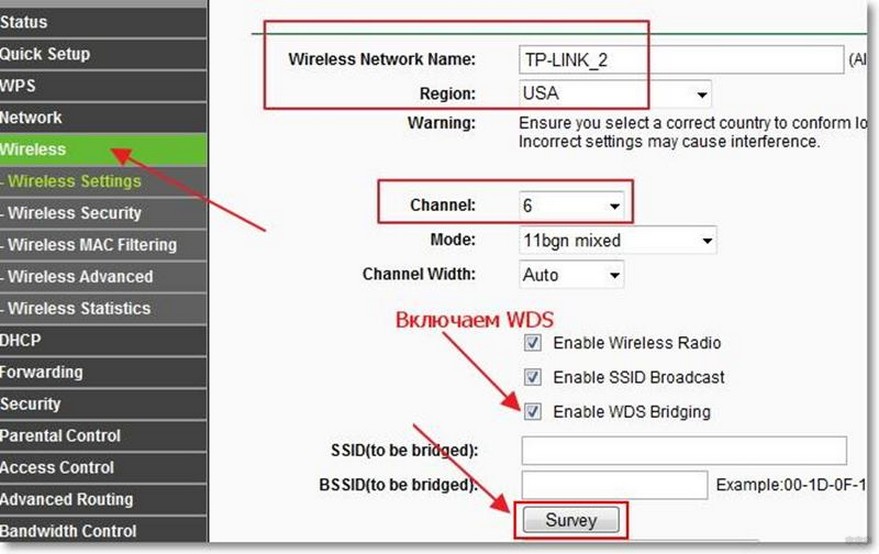
Обследуем статус подключения
После того, как процесс настройки закончен, проверяем, насколько вас удовлетворит результат. Для этого нужно проверить, с какой скоростью интернет соединения работает репитер.
Помимо этого, посмотрите, насколько хорошо ловят сеть ваши домашние девайсы. Они должны улавливать ту сеть, которую раздает ретранслятор. Чтобы не путаться в сетях, нужно в настройках переименовать одну из них.
Что лучше – роутер или репитер? Читал результаты тестов, оба устройства выполняют свои функции на должном уровне. НО! Роутер сложнее настроить, он более габаритный (больше многих ретрансляторов).
В общем, скажу так. Если у вас есть второй маршрутизатор и нет лишних денег, настройте его как репитер. Если стоит выбор, что купить, то однозначно – повторитель. И настроить проще, и выглядит симпатично.
Лучшие репитеры по соотношению цены и качества
Ну и наконец, обзор самых доступных и интересных моделей:

- TP-Link RE350 – данный репитер идеально подходит для корпоративного использования в больших офисах. Устройство способно работать на двух частотах 2,4 ГГц и 5 ГГц, что существенно расширяет область применения. Набор индикаторов на передней части устройства показывает уровень сигнала, который помогает правильно позиционировать репитер по отношению к роутеру. При тестировании было замечено, что эта модель режет скорость в 2 раза. Этот повторитель уже подороже. Его покупка обойдется в 3 тысячи рублей.

- ASUS RP-N Ретранслятор Wi-Fi с 2 антеннами для дома и офиса. Качество сигнала легко определяется по цвету индикатора: зеленый – хорошее соединение, красный – слишком далеко. Быстро и легко подключается. Можно использовать как точку доступа. Единственное, при длительной работе отключается от сети, что требует перезагрузки. Цена, конечно, высоковата – почти 4 тысячи рублей.


- TP-Link AC Репитер, способный копировать сеть в двух диапазонах – 2,4 и 5 ГГц. Максимальная скорость – 750 Мбит/сек. Можно использовать как адаптер для подключения ТВ приставки, игровой консоли. При этом репитер не перестанет выполнять свою основную функцию. Отличный девайс по хорошей цене (2000 рублей).

- Netgear Orbi AC Это комплект из роутера и спутника. Производитель заявил шокирующие цифры – эти устройства способны выдавать максимальную скорость до 1500 Мбит/сек. Обеспечивает покрытие площади до 350 кв. м. Сложно найти в продаже, да и цена впечатляет (20000 рублей).

- ASUS RP- AC68U. Двухдиапазонный репитер, работающий в режимах повторителя, моста и точки доступа. Оснащен портом USB и 5 портами LAN. Стоит порядка 12000 рублей.
Итак, что нового мы сегодня узнали? Разобрались, что такое Wi-Fi repeater, как он выглядит, как его подключить. Если у вас большая квартира или дом, покупка этого девайса будет как нельзя кстати. И избавит вас от поисков ответа на вопросы – почему плохо ловит Wi-Fi или как усилить сигнал. Всем добра!
Читайте также: