
От чего зависят способы кодирования и декодирования информации в компьютере кратко
Обновлено: 06.07.2024
Одно из основных достоинств компьютера связано с тем, что это удивительно универсальная машина. Каждый, кто хоть когда-нибудь с ним сталкивался, знает, что занятие арифметическими подсчетами составляет совсем не главный метод использования компьютера. Компьютеры прекрасно воспроизводят музыку и видеофильмы, с их помощью можно организовывать речевые и видеоконференции в Интернете, создавать и обрабатывать графические изображения и и.д
Одна и та же запись может нести разную смысловую нагрузку. Например, набор цифр 251299 может обозначать: массу объекта; длину объекта; расстояние между объектами; номер телефона; запись даты 25 декабря 1999 года.
Для представления информации могут использоваться разные коды и, соответственно, надо знать определенные правила - законы записи этих кодов, т.е. уметь кодировать.
Код - набор условных обозначений для представления информации.
Кодирование - процесс представления информации в виде кода.
Для общения друг с другом мы используем код - русский язык. При разговоре этот код передается звуками, при письме - буквами. Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора. Таким образом, кодирование сводиться к использованию совокупности символов по строго определенным правилам.
Кодировать информацию можно различными способами: устно; письменно; жестами или сигналами любой другой природы.
Способ кодирования (форма представления) информации зависит от цели, ради которой осуществляется кодирование. Такими целями могут быть сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. п.
Чаще всего применяют следующие способы кодирования информации:
1) графический - с помощью рисунков или значков;
2) числовой - с помощью чисел:
3) символьный с помощью символов того же алфавита, что и исходный текст.
Переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки, также называют кодированием .
Действия по восстановлению первоначальной формы представления информации принято называть декодированием . Для декодирования надо знать код.
Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно 28 = 256. Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute). В системе ASCII закреплены две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы. В настоящее время существует много различных кодовых таблиц для русских букв (КОИ-8, СР1251, СР866, Mac, ISO),поэтому тексты, созданные в одной кодировке , могут не правильно отображаться в другой.
Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек (пикселей). Каждому пикселю присвоен код, хранящий информацию о цвете пикселя.
Для получения черно-белого изображения (без полутонов) пиксель может принимать только два состояния: “белый” или “черный”. Тогда для его кодирования достаточно 1 бита:
Пиксель на цветном дисплее может иметь различную окраску. Поэтому 1 бита на пиксель – недостаточно.
Для кодирования 4-цветного изображения требуется два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов:
00 – черный 10 – зеленый
01 – красный 11 – коричневый
Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Из трех цветов можно получить восемь комбинаций:
1 1 0 Коричневый
Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности, тогда количество различных вариантов их сочетаний, дающих разные краски и оттенки, увеличивается.
Шестнадцатицветная палитра получается при использовании 4-разрядной кодировки пикселя: к трем битам базовых цветов добавляется один бит интенсивности. Этот бит управляет яркостью всех трех цветов одновременно.
Лекция № 2 Кодирование информации. Коды, применяемые в ЭВМ: двоичные, позиционные, комбинационные, самокорректирующиеся, параллельные, последовательные.
Формы представления чисел : с фиксированной и плавающей точкой.
1.Коды, применяемые в ЭВМ
Каким образом обрабатывается информация в компьютере и как обеспечить обмен информацией между пользователем и ЭВМ?
Процесс приема и передачи информации можно изобразить на схеме:

Кодирование – операция, связанная с переходом от исходной формы представления информации в форму, удобную для хранения, передачи или обработки.
Декодирование – связано с обратным переходом к исходному представлению информации.
В настоящее время существуют разные способы кодирования и декодирования информации в компьютере.
Выбор способа зависит от вида информации, которую необходимо кодировать: текст, число, графическое изображение и т.д.
ЭВМ может обрабатывать информацию, представленную только в числовой форме. Любая другая информация (текстовая, графическая) преобразуется в числовую информацию. Так, например, при вводе текста, каждый символ кодируется определенным числом (существуют специальные таблицы кодировки, наиболее известные и распространенные коды ASCII), а при выводе наоборот, каждому числу соответствует изображение определенного символа.
Восемь двоичных разрядов позволяют закодировать 2 8 =256 символов, этого достаточно, чтобы закодировать любую букву, цифру или служебный символ. Нажатие клавиши на клавиатуре приводит к тому, что сигнал посылается в компьютер в виде двоичного числа, которое хранится в кодовой таблице.
2. Кодовая таблица символов
Кодовая таблица символов — это внутреннее представление символов в компьютере. Во всем мире в качестве стандарта принята таблица ASCII (American Standart Code for Information Interchange) – Американский стандартный код для обмена информацией.
Первые 128 символов (от 0 до 127) – это цифры, прописные и строчные буквы латинского алфавита, управляющие символы. Вторая половина кодовой таблицы (от 128 до 255) предназначена для национальных символов (в том числе кириллицы), математических символов и так называемых псевдографических символов, которые используются для рисования рамок.
Нужно помнить о трех особенностях алфавита в кодовой таблице и их следствия:
1) прописные и строчные буквы представлены разными кодами, т.е. “А” и “а” – разные объекты;
2) при упорядочивании слов по алфавиту сравниваются между собой десятичные коды букв. Поэтому, чтобы избежать недоразумений, если не указано “нечувствителен к регистру”, используйте только латинский или русский алфавит и только прописные или только строчные первые буквы. Необходимо помнить, что любая цифра “меньше” любой буквы, код латинских букв “меньше” чем русских;
3) Многие латинские и русские буквы имеют визуально неразличимое начертание, но разные коды.
Итак, компьютер способен распознавать только значения бита. Однако он редко работает с конкретными битами в отдельности, а совокупность из 8 битов, воспринимаемая компьютером как единое целое, называется байтом.
Вся работа компьютера – это управление потоками байтов, которые устремляются в компьютер с клавиатуры или дисков (или по линии связи), преобразовываются по командам программ, запоминаются временно или записываются на постоянное хранение на магнитный диск, а также выводятся на экран дисплея или бумагу принтера в виде букв, цифр, значков.


3.Кодирование информации. Кодирование данных в ЭВМ
В ЭВМ применяется двоичная система счисления, т.е. все числа в компьютере представляются с помощью нулей и единиц, поэтому компьютер может обрабатывать только информацию, представленную в цифровой форме.
Для преобразования числовой, текстовой, графической, звуковой информации в цифровую необходимо применить кодирование.
Кодирование – это преобразование данных одного типа через данные другого типа. В ЭВМ применяется система двоичного кодирования, основанная на представлении данных последовательностью двух знаков: 1 и 0, которые называются двоичными цифрами (binary digit – сокращенно bit).
Целые числа кодируются двоичным кодом довольно просто (путем деления числа на два). Для кодирования нечисловой информации используется следующий алгоритм: все возможные значения кодируемой информации нумеруются и эти номера кодируются с помощью двоичного кода.
Кодирование чисел
Есть два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел.
Для кодирования действительных чисел существует специальный формат чисел с плавающей запятой. Число при этом представляется в виде:

где M – мантисса, p – порядок числа N, q – основание системы счисления. Если при этом мантисса M удовлетворяет условию , то число N называют нормализованным.

Кодирование координат
Закодировать можно не только числа, но и другую информацию, например, о том, где находится некоторый объект. Величины, определяющие положение объекта в пространстве, называются координатами. В любой системе координат есть начало отсчёта, единица измерения, масштаб, направление отсчёта, или оси координат. Примеры систем координат – декартовы координаты, полярная система координат, шахматы, географические координаты.
Кодирование текста
Для представления текстовой информации используется таблица нумерации символов или таблица кодировки символов, в которой каждому символу соответствует целое число (порядковый номер). Восемь двоичных разрядов могут закодировать 256 различных символов.
Существующий стандарт ASCII (сокращение от American Standard Code for Information Intercange – американский стандартный код для обмена информацией; 8 – разрядная система кодирования) содержит две таблицы кодирования – базовую и расширенную. Первая таблица содержит 128 основных символов, в ней размещены коды символов английского алфавита, а во второй таблице кодирования содержатся 128 расширенных символов.
Так как в этот стандарт не входят символы национальных алфавитов других стран, то в каждой стране 128 кодов расширенных символов заменяются символами национального алфавита. В настоящее время существует множество таблиц кодировки символов, в которых 128 кодов расширенных символов заменены символами национального алфавита.
Так, например, кодировка символов русского языка Widows – 1251 используется для компьютеров, работающих под ОС Windows. Другая кодировка для русского языка – это КОИ – 8, которая также широко используется в компьютерных сетях и российском секторе Интернет.
В настоящее время существует универсальная система UNICODE, основанная на 16 – разрядном кодировании символов. Эта 16 – разрядная система обеспечивает универсальные коды для 65536 различных символов, т.е. в этой таблице могут разместиться символы языков большинства стран мира.
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие группы – растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. picture element). Код пикселя содержит информации о его цвете.
Для описания черно-белых изображений используются оттенки серого цвета, то есть при кодировании учитывается только яркость. Она описывается одним числом, поэтому для кодирования одного пикселя требуется от 1 до 8 бит: чёрный цвет – 0, белый цвет – N = 2 k -1, где k – число разрядов, которые отводятся для кодирования цвета. Например, при длине ячейки в 8 бит это 256-1 = 255. Человеческий глаз в состоянии различить от 100 до 200 оттенков серого цвета, поэтому восьми разрядов для этого вполне хватает.
Цветные изображения воспринимаются нами как сумма трёх основных цветов – красного, зелёного и синего. Например, сиреневый = красный + синий; жёлтый = красный + зелёный; оранжевый = красный + зелёный, но в другой пропорции. Поэтому достаточно закодировать цвет тремя числами – яркостью его красной, зелёной и синей составляющих. Этот способ кодирования называется RGB (Red – Green – Blue). Его используют в устройствах, способных излучать свет (мониторы). При рисовании на бумаге действуют другие правила, так как краски сами по себе не испускают свет, а только поглощают некоторые цвета спектра. Если смешать красную и зелёную краски, то получится коричневый, а не жёлтый цвет. Поэтому при печати цветных изображений используют метод CMY (Cyan – Magenta – Yellow) – голубой, сиреневый, жёлтый цвета. При таком кодировании красный = сиреневый + жёлтый; зелёный = голубой + жёлтый.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент такого изображения – линия, прямоугольник, окружность или фрагмент текста – располагается в своем собственном слое, пиксели которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.) Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
Кодирование звука
Как всякий звук, музыка является не чем иным, как звуковыми колебаниями, зарегистрировав которые достаточно точно, можно этот звук безошибочно воспроизвести. Нужно только непрерывный сигнал, которым является звук, преобразовать в последовательность нулей и единиц. С помощью микрофона звук можно превратить в электрические колебания и измерить их амплитуду через равные промежутки времени (несколько десятков тысяч раз в секунду). Каждое измерение записывается в двоичном коде. Этот процесс называется дискретизацией. Устройство для выполнения дискретизации называется аналогово-цифровым преобразователем (АЦП). Воспроизведение такого звука ведётся при помощи цифро-аналогового преобразователя (ЦАП). Полученный ступенчатый сигнал сглаживается и преобразуется в звук при помощи усилителя и динамика. На качество воспроизведения влияют частота дискретизации и разрешение (размер ячейки, отведённой под запись значения амплитуды). Например, при записи музыки на компакт-диски используются 16-разрядные значения и частота дискретизации 44 032 Гц.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Издавна используется достаточно компактный способ представления музыки – нотная запись. В ней с помощью специальных символов указывается высота и длительность, общий темп исполнения и как сыграть. Фактически, такую запись можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI (Musical Instrument Digital Interface). При таком кодировании запись компактна, легко меняется инструмент исполнителя, тональность звучания, одна и та же запись воспроизводится как на синтезаторе, так и на компьютере.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Есть и другие форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18 – 20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Информация бывает разных видов, таких как запах, вкус, звук; символы и знаки. В различных отраслях науки, техники и культуры применяются особые формы и методики для кодирования и записи информации.
- Числовой способ — с помощью чисел.
- Символьный способ — информация кодируется с помощью символов того же алфавита, что и исходящий текст.
- Графический способ — информация кодируется с помощью рисунков или значков.

Трактовка понятий
Количество и графическое отображение символов в алфавитах естественных языков сложилось исторически и характеризуется особенностями языка (произносимыми звуками). Например русский алфавит имеет 33 символа, латинский – 26, китайский несколько тысяч.
К основным способам кодирования информации в информатике относятся: числовой, символьный (текстовый), графический. В первом случае используются числа, во втором — символы того алфавита, что и первоначальный текст, в третьем — картинки, рисунки, значки.
Двоичная методика
На английском языке используется выражение binary digit либо сокращённо bit (бит). Через 1 бит можно выразить: да либо нет; белое или чёрное; ложь либо истина.
Двоичное кодирование информации привлекает тем, что легко реализуется технически. Электронные схемы для обработки двоичных кодов должны находиться только в одном из двух состояний: есть сигнал/нет сигнала или высокое напряжение/низкое напряжение. В результате любая информация кодируется в компьютерах с помощью последовательностей лишь двух цифр — 0 и 1.
Итак, минимальные единицы измерения информации – это бит и байт. Один бит позволяет закодировать 2 значения (0 или 1). Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11. Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111. Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать. 1 байт состоит из 8 бит и способен закодировать 256 значений.
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Наряду с битами и байтами используют и большие единицы измерения информации.
- 1 бит ;
- 1 байт = 8 бит;
- 1 Кбайт = 2 10 байт = 1024 байт;
- 1 Мбайт = 2 10 Кбайт = 1024 Кбайт = 2 20 байт;
- 1 Гбайт = 2 10 Мбайт = 1024 Мбайт = 2 30 байт;
- 1 Тбайт = 2 10 Гбайт = 1024 Гбайт = 2 40 байт.
- 1 Пбайт = 2 10 Тбайт = 1024 Тбайт = 2 50 байт.
Подробнее о информации в компьютерных системах можно прочтитать в статье Понятие информации. Информатика
Текстовое значение
Кодирование и обработка текстовой информации Уже с 60-х годов прошлого столетия, компьютеры всё больше стали использовать для обработки текстовой информации. Для кодирования текстовой информации в компьютере применяется двоичное кодирование, т.е. представление текста в виде последовательности 0 и 1. Чтобы выразить текст числом, каждая буква сопоставляется с числовым значением. Смысл кодирования: одному символу принадлежит код в пределах 0−255 либо двоичный код от 00000000 до 11111111.
Текстовая информация состоит из символов: букв, цифр, знаков препинания и др. Одного байта достаточно для хранения 256 различных значений, что позво ляет размещать в нем любой из алфавитно-цифровых символов. Первые 128 сим волов (занимающие семь младших бит) стандартизированы с помощью кодировки ASCII (American Standart Code for Information Interchange). Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 0000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
В мировой практике для кодирования текста при помощи байтов используются разные стандарты. Самым распространенным, но не единственным видом кодирования является код ASCII. В соответствии с этим стандартом, знаки в пределах 0−32 соответствуют операциям, а 33−127 — символам из латинского алфавита, знакам препинания и арифметики. Для национальных кодировок применяются значения 128−255. В разных национальных кодировках одному и тому же коду соответствуют различные символы. К примеру, существует 5 кодировочных таблиц для русских букв (Windows, MS-DOS, Mac, ISO, КОИ – 8). Поэтому тексты созданные в одной кодировке не будут правильно отображаться в другой.
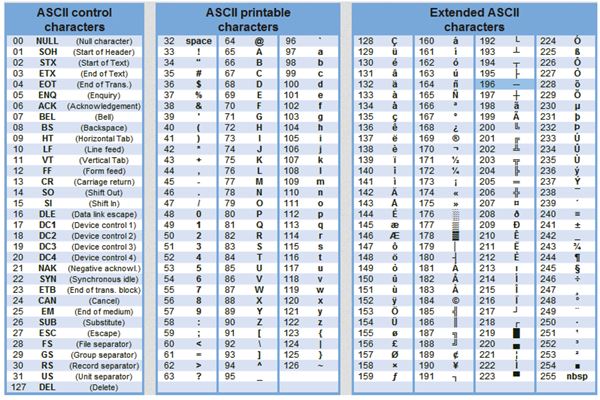
Таблица стандартной и альтернативной частей кодов ASCII
В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица СР1251, которая используется в операционных системах семейства Windows фирмы Microsoft. Во всех современных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В конце прошлого века появился новый международный стандарт Unicode, в котором один символ представляется двухбайтовым двоичным кодом. Применение этого стандарта – продолжение разработки универсального международного стандарта, позволяющего решить проблему совместимости национальных кодировок символов. С помощью данного стандарта можно закодировать 65536 различных символов.
Растровое изображение
Графическая информация, представленная в виде рисунков, фотографий, слайдов, подвижных изображений (анимация, видео), схем, чертежей, может создаваться и редактироваться с помощью компьютера, при этом она соответствующим образом кодируется. В настоящее время существует достаточно большое количество прикладных программ для обработки графической информации, но все они реализуют три вида компьютерной графики: растровую, векторную и фрактальную. Мы рассмотрим самую распространенный, растровый формат кодирования изображения.
Графические данные на мониторе представляются в качестве растрового изображения. Если более пристально рассмотреть графическое изображение на экране монитора компьютера, то можно увидеть большое количество разноцветных точек (пикселов – от англ. pixel, образованного от picture element – элемент изображения), которые, будучи собраны вместе, и образуют данное графическое изображение. Каждому пикселю присвоен особый код, в котором хранится информация об оттенке пикселя. Из этого можно сделать вывод: графическое изображение в компьютере определенным образом кодируется и должно быть представлено в виде графического файла.
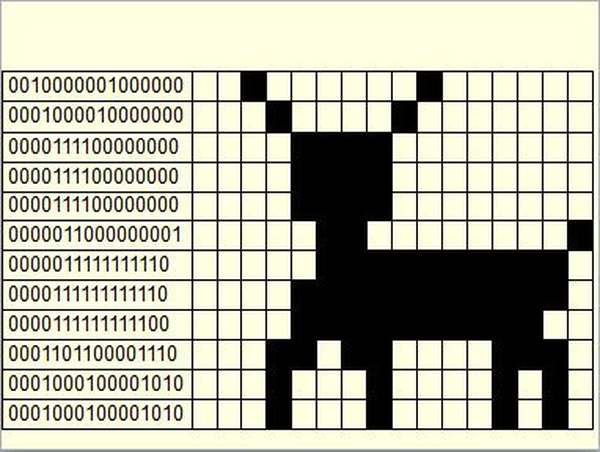
Файлы, созданные на основе растровой графики, предполагают хранение данных о каждой отдельной точке изображения. Для отображения растровой графики не требуется сложных математических расчетов, достаточно лишь получить данные о каждой точке изображения (ее координаты и цвет) и отобразить их на экране монитора компьютера.
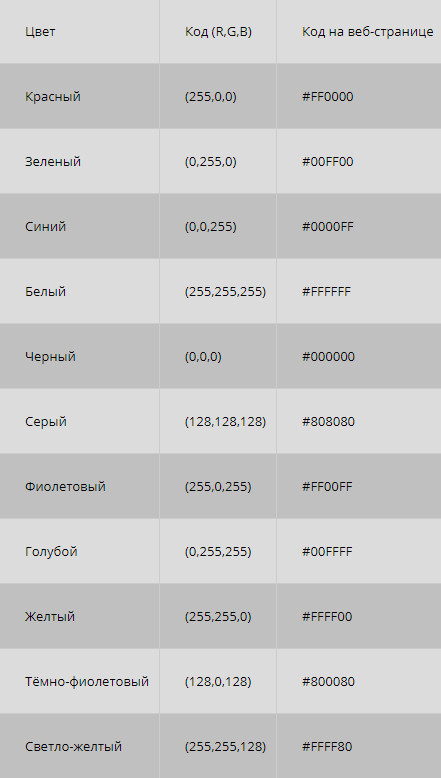
Всего есть по 256 вариантов яркости каждого из трех цветов. Это позволяет закодировать 256 3 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 2 8 , каждая из трех составляющих занимает в памяти 8 бит или 1 байт, а вся информация о каком-то цвете — 24 бита (или 3 байта). Эта величина называется глубиной цвета.
Звуки и их разрядность
Человек воспринимает звуковые волны (колебания воздуха) с помощью слуха в форме звука различных громкости и тона. Чем больше интенсивность звуковой волны, тем громче звук, чем больше частота волны, тем выше тон звука. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, для каждого такого участка устанавливается определенная величина интенсивности звука.
В каждом современном компьютере предусмотрена звуковая плата, колонки, микрофон. С их помощью производится запись, сохраняются и воспроизводятся звуки — волны с определённой частотой и амплитудой. Программное обеспечение для компьютеров преобразовывает звуковые сигналы в последовательность нулей и единиц. Для этого использунтся аудиоадаптер или звуковая плата. Устройство подключается к компьютеру с целью преобразования электроколебаний звуковой частоты в двоичный код. Процесс преобразования выполняется как при вводе звуков в компьютер так и при обратном их преобразовании.
Для человека звук тем громче, чем больше амплитуда сигнала, и тем выше тон, чем больше частота сигнала. Компьютер — устройство цифровое, поэтому непрерывный звуковой сигнал должен быть преобразован в последовательность электрических импульсов (нулей и единиц). Оцифровку звука выполняет специальное устройство на звуковой плате. Называется оно аналого-цифровой преобразователь (АЦП). Обратный процесс — воспроизведение закодированного звука производится с помощью цифро-аналогового преобразователя (ЦАП).
Глубина кодирования звука — это количество бит, используемое для кодирования различных уровней сигнала или состояний. Современные звуковые карты обеспечивают 16-битную глубину кодирования звука, и тогда общее количество различных уровней громкомти, который сможет распознать компьютер будет: N = 2 16 = 65536.
Частота дискретизации- это количество измерений уровня звукового сигнала в единицу времени. Эта характеристика показывает качество и точность процедуры двоичного кодирования. Измеряется в герцах (Гц).
Одно измерение за одну секунду соответствует частоте 1 Гц, 1000 измерений за одну секунду — 1 килогерц (кГц). Частота дискретизации звукового сигнала может принимать значения от 8 до 196 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-CD. Достаточно высокое качество звучания достигается при частоте дискретизации 44 кГц и глубины кодирования звука, равной 16 бит.
Оцифрованный сигнал в виде набора последовательных значений амплитуды уже можно сохранить в памяти компьютера. В случае, когда записываются абсолютные значения амплитуды, такой формат записи называется PCM ( Pulse Code Modulation). Стандартный аудио компакт-диск (CD-DA), применяющийся с начала 80-х годов 20-го столетия, хранит информацию в формате PCM с частотой дискретизации 44.1 кГц и разрядностью квантования 16 бит.
Подробнее о свойствах звука можно прочитать в статье Звук
Машинные команды
В вычислительных машинах, включая компьютеры, предусмотрена программа для управления их работой. Все команды кодируются в определённой последовательности с помощью нулей и единиц. Подобные действия называются машинными командами (МК).
Машинная команда представляет собой закодированное по определенным правилам указание микропроцессору на выполнение некоторой операции или действия. Каждая команда содержит элементы, определяющие:
- указание на то, какие действия должен сделать микропроцессор (ответ па этот вопрос дает часть команды, которая называется кодом операции (КОП));
- указание на объекты, над которыми надо провести какие-то действия (эти элементы машинной команды называются операндами);
- указание на способ действия (эти элементы называются типами операндов).
Структура машинной команды состоит из операционной и адресной части. В операционной части содержится код операции. Чем длиннее операционная часть, тем большее количество операций можно в ней закодировать.
В адресной части машинной команды содержится информация об адресах операндов. Это либо значения адресов ячеек памяти, в которых размещаются сами операнды (абсолютная адресация), либо информация, по которой процессор определяет значения их адресов в памяти (относительная адресация). Абсолютная адресация использовалась только в машинах 1 и 2-го поколений. Начиная с машин 3-го поколения, наряду с абсолютной используется относительная адресация.
Подробнее о поколениях компьютеров смотрите в статье История развития компьютеров
Заключение
Информацию необходимо представлять в какой — либо форме, т.е. кодировать. Для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причём, такое преобразование не должно приводить к потере информации.

Эксплуатация электронно-вычислительной техники для обработки данных стала важным этапом в процессе совершенствования систем управления и планирования. Но такой метод сбора и обработки информации несколько отличается от привычного, поэтому требует преобразования в систему символов, понятных компьютеру.
Что такое кодирование информации?
Кодирование данных – это обязательный этап в процессе сбора и обработки информации.
Как правило, под кодом подразумевают сочетание знаков, которое соответствует передаваемым данным или некоторым их качественным характеристикам. А кодирование – это процесс составления зашифрованной комбинации в виде списка сокращений или специальных символов, которые полностью передают изначальный смысл послания. Кодирование еще иногда называют шифрованием, но стоит знать, что последняя процедура предполагает защиту данных от взлома и прочтения третьими лицами.

Цель кодирования заключается в представлении сведений в удобном и лаконичном формате для упрощения их передачи и обработки на вычислительных устройствах. Компьютеры оперируют лишь информацией определенной формы, поэтому так важно не забывать об этом во избежание проблем. Принципиальная схема обработки данных включает в себя поиск, сортировку и упорядочивание, а кодирование в ней встречается на этапе ввода сведений в виде кода.
Что такое декодирование информации?
Вопрос о том, что такое кодирование и декодирование, может возникнуть у пользователя ПК по различным причинам, но в любом случае важно донести корректную информацию, которая позволит юзеру успешно продвигаться в потоке информационных технологий дальше. Как вы понимаете, после процесса обработки данных получается выходной код. Если такой фрагмент расшифровать, то образуется исходная информация. То есть декодирование – это процесс, обратный шифрованию.
Если во время кодирования данные приобретают вид символьных сигналов, которые полностью соответствуют передаваемому объекту, то при декодировании из кода изымается передаваемая информация или некоторые ее характеристики.
Кодирование и декодирование текстовой информации
При нажатии на клавиатурную клавишу компьютер получает сигнал в виде двоичного числа, расшифровку которого можно найти в кодовой таблице – внутреннем представлении знаков в ПК. Стандартом во всем мире считают таблицу ASCII.

Однако мало знать, что такое кодирование и декодирование, необходимо еще понимать, как располагаются данные в компьютере. К примеру, для хранения одного символа двоичного кода электронно-вычислительная машина выделяет 1 байт, то есть 8 бит. Эта ячейка может принимать только два значения: 0 и 1. Получается, что один байт позволяет зашифровать 256 разных символов, ведь именно такое количество комбинаций можно составить. Эти сочетания и являются ключевой частью таблицы ASCII. К примеру, буква S кодируется как 01010011. Когда вы нажимаете ее на клавиатуре, происходит кодирование и декодирование данных, и мы получаем ожидаемый результат на экране.
Половина таблицы стандартов ASCII содержит коды цифр, управляющих символов и латинских букв. Другая ее часть заполняется национальными знаками, псевдографическими знаками и символами, которые не имеют отношения к математике. Совершенно ясно, что в различных странах эта часть таблицы будет отличаться. Цифры при вводе также преобразовываются в двоичную систему вычисления согласно стандартной сводке.

Кодирование чисел
В двоичной системе счисления, которую активно используют компьютеры, встречаются лишь две цифры – 0 и 1.
Действия с образовывающимися числами двоичной системы изучает двоичная арифметика. Большинство законов основных математических действий для таких цифр остаются актуальными.
Примеры кодирования и декодирования чисел
Предлагаем рассмотреть 2 способа кодировки числа 45. Если эта цифра встречается в пределах текстового фрагмента, то каждая ее составляющая будет закодирована, согласно таблице стандартов ASCII, 8 битами. Четверка превратится в 01000011, а пятерка – в 01010011.
Если число 45 используется для вычислений, то будет задействована специальная методика преобразования в восьмиразрядный двоичный код 001011012, для хранения которого нужен будет всего лишь 1 байт.

Кодирование графической информации
Увеличив монохромное изображение с помощью лупы, вы увидите, что оно состоит из огромного количества мелких точек, формирующих полноценный узор. Индивидуальные качества каждой картинки и линейные координаты любой точки можно отобразить в форме чисел. Поэтому растровое кодирование базируется на двоичном коде, приспособленном для отображения графической информации.
Черно-белые картинки – это комбинации точек с различными оттенками серого цвета, то есть яркость любой точки изображения определяют восьмиразрядные двоичные числа. Принцип разложения произвольного градиента на базовые составляющие – это основа такого процесса, как кодирование графической информации. Декодирование картинок происходит таким же путем, но в обратном направлении.
При разложении используются три основных цвета: зеленый, красный и синий, ведь любой естественный оттенок можно получить, комбинируя эти градиенты. Такую систему кодирования принято называть RGB. В случае использования двадцати четырех двоичных разрядов для шифрования графического изображения режим преобразования называют полноцветным.
Все основные цвета сопоставляются с оттенками, которые дополняют базовую точку, делая ее белой. Дополнительный цвет – это градиент, образованный суммой прочих основных тонов. Выделяют желтый, пурпурный и голубой дополнительные цвета.
Подобный метод кодирования точек изображений применяется и в полиграфической отрасли. Только здесь принято задействовать четвертый цвет – черный. По этой причине полиграфическую систему преобразования обозначают аббревиатурой CMYK. Эта система для представления изображений использует целых тридцать два двоичных разряда.

Способы кодирования и декодирования информации предполагают использование различных технологий, в зависимости от типа вводимых данных. К примеру, метод шифрования графических изображений шестнадцатиразрядными двоичными кодами называется High Color. Эта технология дает возможность передавать на экран целых двести пятьдесят шесть оттенков. Уменьшая количество задействованных двоичных разрядов, применяемых для шифрования точек графического изображения, вы автоматически уменьшаете объем, необходимый для временного хранения информации. Такой метод кодирования данных принято называть индексным.
Кодирование звуковой информации
Теперь, когда мы рассмотрели, что такое кодирование и декодирование, и методы, лежащие в основе этого процесса, стоит остановиться на таком вопросе, как кодирование звуковых данных.
Звуковую информацию можно представить в виде элементарных единиц и пауз между каждой их парой. Каждый сигнал преобразовывается и сохраняется в памяти компьютера. Звуки выводятся с помощью синтезатора речи, который используется хранящиеся в памяти ПК зашифрованные комбинации.
Что касается человеческой речи, то ее гораздо сложнее закодировать, ведь она отличается многообразием оттенков, и компьютеру приходится сравнивать каждое словосочетание с эталоном, предварительно занесенным в его память. Распознавание произойдет лишь в случае, когда сказанное слово будет найдено в словаре.
Кодирование информации в двоичном коде
Существуют различные методики реализации такой процедуры, как кодирование числовой, текстовой и графической информации. Декодирование данных обычно происходит по обратной технологии.
При кодировании чисел даже учитывается цель, с которой цифра была введена в систему: для арифметических вычислений или просто для вывода. Все данные, кодируемые в двоичной системе, шифруются с помощью единиц и ноликов. Эти символы еще называют битами. Этот метод кодировки является наиболее популярным, ведь его легче всего организовать в технологическом плане: присутствие сигнала – 1, отсутствие – 0. У двоичного шифрования есть лишь один недостаток – это длина комбинаций из символов. Но с технической точки зрения легче орудовать кучей простых, однотипных компонентов, чем малым числом более сложных.
Преимущества двоичного кодирования
- Такая форма представления информации подходит для различных ее видов.
- При передаче данных не возникает никаких ошибок.
- ПК намного легче обрабатывать данные, закодированные таким способом.
- Требуются устройства с двумя состояниями.
Недостатки двоичного кодирования
- Большая длина кодов, которая несколько замедляет их обработку.
- Сложность восприятия двоичных комбинаций человеком без специального образования или подготовки.

Заключение
Ознакомившись с этой статьей, вы смогли узнать, что такое кодирование и декодирование и для чего его используют. Можно сделать вывод, что используемые методики преобразования данных полностью зависят от типа информации. Это может быть не только текст, а еще и числа, изображения и звук.
Кодирование различной информации позволяет унифицировать форму ее представления, то есть сделать однотипной, что значительно ускоряет процессы обработки и автоматизации данных при дальнейшем использовании.
В электронно-вычислительных машинах чаще всего используют принципы стандартного двоичного кодирования, которое исходную форму представления информации преобразовывает в формат, более удобный для хранения и дальнейшей обработки. При декодировании все процессы происходят в обратном порядке.
Читайте также: