
Как обучается нейросеть кратко
Обновлено: 04.07.2024
В прошлый раз мы обсудили историю возникновения свёрточных архитектур, а также узнали об их устройстве и широких возможностях применения. В течение следующих двух лекций мы поговорим об особенностях обучения нейросетей и разберёмся, как правильно настраивать параметры, выбирать функцию активации, подготавливать данные и добиваться успешных результатов.
Обучение нейросети — непредсказуемый и захватывающий процесс, который, однако, требует тщательной подготовки. В целом его можно разделить на три основных этапа:
- Однократная настройка
Сюда входят: выбор функции активации, предварительная обработка данных, инициализация весов, регуляризация, градиентная проверка. - Динамика обучения
Отслеживание процесса обучения, оптимизация и обновление гиперпараметров. - Оценка
Использование ансамблевых методов.
В этой лекции мы обсудим некоторые детали первых двух пунктов. Если вы уже знакомы со всеми понятиями и имеете опыт работы с нейросетями, рекомендуем нашу статью с полезными советами по обучению моделей.
Обучение нейросети — непредсказуемый и захватывающий процесс, который, однако, требует тщательной подготовки. В целом его можно разделить на три основных этапа:
Сюда входят: выбор функции активации, предварительная обработка данных, инициализация весов, регуляризация, градиентная проверка.
Отслеживание процесса обучения, оптимизация и обновление гиперпараметров.
В этой лекции мы обсудим некоторые детали первых двух пунктов. Если вы уже знакомы со всеми понятиями и имеете опыт работы с нейросетями, рекомендуем нашу статью с полезными советами по обучению моделей.
Функция активации
Ранее мы выяснили, что в каждый слой нейросети поступают входные данные. Они умножаются на веса полносвязного или свёрточного слоя, а результат передаётся в функцию активации или нелинейность. Мы также говорили о сигмоиде и ReLU, которые часто используются в качестве таких функций. Но список возможных вариантов не ограничивается только ими. Какой же следует выбирать?
Рассмотрим наиболее популярные функции активации и обсудим их преимущества и недостатки.
Сигмоида
Функция сигмоиды преобразовывает поступающие в неё значения в вещественный диапазон [0, 1]. То есть, если входные данные окажутся большими положительными значениями, то после преобразования они будут равны примерно единице, а отрицательные числа станут близки к нулю. Это довольно популярная функция, которую можно интерпретировать как частоту возбуждения нейрона.
Но если внимательнее присмотреться к сигмоиде, можно заметить несколько проблем.
А если X = 0? В этом случае всё будет в порядке, как и для других близких к нулю значений. А вот при X = 10 градиент снова обнулится. Поэтому сигмоида не работает для слишком высоких положительных или отрицательных данных.
2. Выходные значения сигмоиды не центрированы нулем. Пусть исходные данные полностью положительны — что тогда станет с градиентами во время обратного распространения? Они все будут либо положительными, либо отрицательными (в зависимости от градиента f). Это приведёт к тому, что все веса при обновлении также будут либо увеличены, либо уменьшены, и градиентный поток станет зигзагообразным.
Поэтому следует изначально подготавливать данные таким образом, чтобы их средним значением являлся ноль.
3. Функцию exp() достаточно дорого считать. Это не такая существенная проблема, поскольку скалярные произведения во время свёртки тратят гораздо больше вычислительных мощностей, но в сравнении с остальными функциями активации её тоже можно отметить.
Тангенс
Тангенс очень похож на сигмоиду, но обладает двумя существенными отличиями: он преобразует данные в диапазон [-1, 1] и имеет нулевое центрирование, что исключает вторую проблему сигмоиды. Значения градиента при обратном распространении по-прежнему могут обнуляться, тем не менее, использование тангенса обычно более предпочтительно.
ReLU
Проблему можно попробовать решить, задав более низкую скорость обучения и подобрав другие весовые коэффициенты. Или использовать модификации ReLU.
Leaky ReLU
Отличие этой функции в том, что она имеет небольшой наклон в левой полуплоскости — значит, при отрицательных входных данных градиент не будет нулевым.
При этом функцию по-прежнему легко вычислить. То есть, она решает практически все перечисленные проблемы. Одной из её разновидностей является PReLU, которая выглядит как f(x) = max(𝛼x, x).
ELU
Эта функция похожа на leaky ReLU и обладает всеми её преимуществами, но включает в себя экспоненту, что делает её вычисление дороже. Её стоит использовать в тех случаях, когда вам важна устойчивость к шумовым данным.
Maxout
Maxout выбирает максимальную сумму из двух наборов весов, умноженных на исходные данные с учётом смещения. Тем самым он обобщает ReLU и leaky ReLU, не обнуляя градиент. Но, как можно догадаться по виду функции, maxout требует удвоения параметров и нейронов.
Подводя итог: используйте ReLU, можете попробовать взять leaky ReLU/Maxout/ELU. На тангенс и сигмоиду лучше не рассчитывать.
Подготовка данных
Существует три наиболее распространённых способа предварительной обработки данных. Будем полагать, что данные X — это матрица размером [NxD].
1. Вычитание среднего. Чтобы избежать смещения данных и сделать их симметричными относительно нуля, из каждого элемента вычитается среднее значение. Это помогает предотвратить ситуации, когда все исходные числа оказываются только положительными или отрицательными. В NumPy операция выглядит как X -= np.mean(X, axis = 0). В частности, при обработке изображений можно вычитать одно значение из всех пикселей (например, X -= np.mean(X)) или делать это отдельно по каждому из трёх цветовых каналов.
2. Нормализация. Изменение данных таким образом, чтобы они все были приблизительно одного масштаба. Один из вариантов — разделить каждое измерение на его стандартное отклонение: (X /= np.std(X, axis = 0)). Другой вариант — нормализовать каждое значение так, чтобы min и max были равны -1 и 1 соответственно. Нормализацию следует применять только в том случае, если исходные данные имеют разные форматы или единицы измерения. У изображений значения пикселей не выходят за пределы диапазона от 0 до 255, поэтому для них нет необходимости выполнять нормализацию.
Инициализация весов
Итак, мы построили архитектуру нейронной сети и подготовили данные. Прежде чем начать обучение, необходимо инициализировать параметры (веса).
Как не нужно делать: задавать веса нулевыми. Это приведёт к тому, что абсолютно все нейроны будут вести себя одинаково — совсем не то, что мы хотим получить. Нейросеть должна обучаться разным признакам.
Небольшие случайные величины. Более удачный вариант — присвоить весам маленькие значения. Тогда все нейроны будут уникальными и в процессе обучения постепенно интегрируются в различные части сети. Реализация может выглядеть так: W = 0.01* np.random.randn(D,H). Метод randn(n) формирует массив размера n х n, элементами которого являются случайные величины, распределённые по нормальному закону с математическим ожиданием 0 и среднеквадратичным отклонением 1 (распределение Гаусса). Недостаток этого способа в том, что он неплохо работает для небольших архитектур, но гораздо хуже справляется с громоздкими нейросетями.
Калибровка с помощью 1/sqrt(n). Проблема вышеупомянутого метода состоит в том, что дисперсия случайных величин растёт с числом нейронов. Чтобы избежать этого, можно масштабировать веса, поделив их на корень из количества входов: w = np.random.randn(n) / sqrt(n). Это гарантирует, что все нейроны сети изначально будут иметь примерно одинаковое выходное распределение.
Также можно использовать вариант w = np.random.randn(n) * sqrt(2.0/n), который был предложен в одном из исследований. Он приводит к наиболее удачному распределению нейронов, поэтому на практике рекомендуем использовать именно его.
Пакетная нормализация
Метод, известный также как batch normalization, решает множество проблем при инициализации, заставляя все активации (выводы) принимать единичное гауссово распределение в начале обучения.
Как же это работает? Рассмотрим небольшое число выводов нейронов на каком-либо слое. Пусть в функцию активации поступает вектор размерности d: x = (x(1),…,x(d)). Нормализуем его по каждой из размерностей:
Где E(x) — математическое ожидание, D(x) — дисперсия, которые вычисляются по всей обучающей выборке. Таким образом, вместо инициализации весов можно использовать эту простую дифференцируемую функцию и получить нормальное распределение на каждом слое.
Пакетная нормализация обычно применяется между слоями (полносвязными или свёрточными) и функциями активации.
Это очень полезный алгоритм, который часто применяется в современном машинном обучении. Нейросети, использующие batch normalization, значительно более устойчивы к плохой инициализации.
За нейросетью глаз да глаз
Мы выбрали архитектуру сети, подготовили данные, инициализировали веса и нормализовали их. Пришло время начать обучение! Вернее, попытаться начать. Самый простой способ проверить, что нейросеть готова обучаться — взять совсем немного данных и попробовать переобучить её на них, то есть, добиться очень хорошей точности и малых потерь. Для этого мы убираем регуляризацию, устанавливаем необходимое количество эпох обучения и вычисляем потери (они должны уменьшаться).
Теперь можно запустить настоящий процесс: взять все данные, добавить регуляризацию и установить начальную скорость обучения. К сожалению, просто выполнить код и оставить нейросеть на пару часов пока не получится. Необходимо убедиться, что потери постепенно уменьшаются после каждой эпохи. Если этого не происходит, скорее всего, скорость обучения слишком маленькая. Стремительный рост потерь наоборот говорит о слишком высоком значении learning rate.
Оптимизация гиперпараметров
Как мы могли убедиться, обучение нейронных сетей включает множество этапов настройки гиперпараметров. Наиболее распространенными являются:
— начальная скорость обучения;
— график затухания скорости обучения (например, постоянная затухания);
При желании можно даже модернизировать архитектуру сети, если вам кажется, что она выбрана не слишком удачно.
Learning rate — одно из самых важных значений. Попробуйте поэкспериментировать с различными вариантами и построить графики потерь. На рисунке ниже слева показаны эффекты, возникающие при изменении скорости обучения, а справа — типичная функция потерь при обучении небольшой нейросети на наборе данных CIFAR-10.
Вторая важная вещь, которую следует отслеживать — точность сети на обучающих и оценочных данных. Если поместить их на один график, то можно оценить наличие переобучения, о чём свидетельствуют расходящиеся кривые.
Итоги
Кратко изложим всё, что мы узнали про обучение нейросетей из сегодняшней лекции:
— используйте функцию активации ReLU;
— выполняйте предварительную обработку данных (для изображений: вычитайте среднее значение);
— масштабируйте веса при инициализации;
— применяйте пакетную нормализацию;
— следите за процессом обучения;
— оптимизируйте гиперпараметры с помощью случайного поиска.
На следующей лекции мы расскажем ещё о нескольких важных шагах обучения, узнаем про ансамблевые методы и разберёмся, как выполнять передачу обучения (transfer learning) и точную настройку (fine tuning). Пробовали ли вы самостоятельно обучать нейросети? Были ли у вас свои хитрости, или вы полагались на установки по умолчанию? Делитесь с нами успехами и не забывайте задавать вопросы, если что-то непонятно.
Следующие лекции (список будет дополняться по мере появления материалов):

Поэтому сейчас, когда я достаточно хорошо освоил нейронные сети и нашел огромное количество информации с разных иностранных порталов, я хотел бы поделиться этим с людьми в серии публикаций, где я соберу всю информацию, которая потребуется вам, если вы только начинаете знакомство с нейронными сетями. В этой статье, я не буду делать сильный акцент на Java и буду объяснять все на примерах, чтобы вы сами смогли перенести это на любой, нужный вам язык программирования. В последующих статьях, я расскажу о своем приложении, написанном под андроид, которое предсказывает движение акций или валюты. Иными словами, всех желающих окунуться в мир нейронных сетей и жаждущих простого и доступного изложения информации или просто тех, кто что-то не понял и хочет подтянуть, добро пожаловать под кат.
Первым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR). Таблица исключающего или выглядит следующим образом:
| a | b | c |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Что такое нейронная сеть?
Нейронная сеть — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1, Видео 2). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей — это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон — это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить, что нейроны оперируют числами в диапазоне [0,1] или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ — это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр — вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример — смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов — это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить, что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

Функция активации
Функция активации — это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия — это диапазон значений.
Линейная функция

Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.

Это самая распространенная функция активации, ее диапазон значений [0,1]. Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет — это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n
раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.



Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.
Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.

H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Результат — 0.33, ошибка — 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Обучение нейронной сети- это процесс, в котором параметры нейронной сети настраиваются посредством моделирования среды, в которую эта сеть встроена. Тип обучения определяется способом подстройки параметров. Различают алгоритмы обучения с учителем и без учителя.
Процесс обучения с учителем представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети.
Для того, чтобы нейронная сети была способна выполнить поставленную задачу, ее необходимо обучить (см. рис. 1). Различают алгоритмы обучения с учителем и без учителя.
Процесс обучения с учителем представляет собой предъявление сети выборки обучающих примеров. Каждый образец подается на входы сети, затем проходит обработку внутри структуры НС, вычисляется выходной сигнал сети, который сравнивается с соответствующим значением целевого вектора, представляющего собой требуемый выход сети. Затем по определенному правилу вычисляется ошибка, и происходит изменение весовых коэффициентов связей внутри сети в зависимости от выбранного алгоритма. Векторы обучающего множества предъявляются последовательно, вычисляются ошибки и веса подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня.
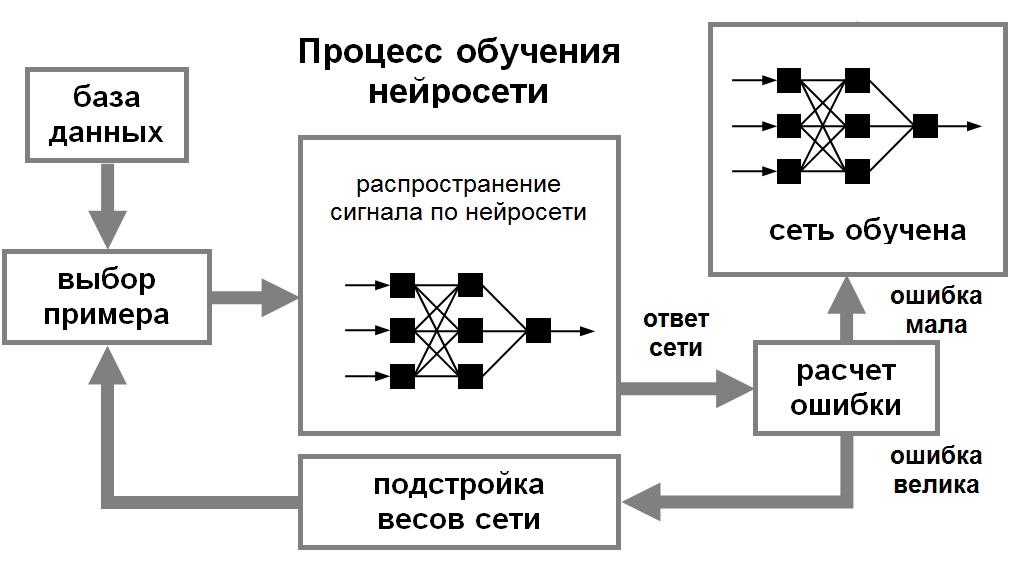
Рис. 1. Иллюстрация процесса обучения НС
При обучении без учителя обучающее множество состоит лишь из входных векторов. Обучающий алгоритм подстраивает веса сети так, чтобы получались согласованные выходные векторы, т.е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы. Процесс обучения, следовательно, выделяет статистические свойства обучающего множества и группирует сходные векторы в классы. Предъявление на вход вектора из данного класса даст определенный выходной вектор, но до обучения невозможно предсказать, какой выход будет производиться данным классом входных векторов. Следовательно, выходы подобной сети должны трансформироваться в некоторую понятную форму, обусловленную процессом обучения. Это не является серьезной проблемой. Обычно не сложно идентифицировать связь между входом и выходом, установленную сетью.
Для обучения нейронных сетей без учителя применяются сигнальные метод обучения Хебба и Ойа.
Математически процесс обучения можно описать следующим образом. В процессе функционирования нейронная сеть формирует выходной сигнал Y, реализуя некоторую функцию Y = G(X). Если архитектура сети задана, то вид функции G определяется значениями синаптических весов и смещенной сети.
Пусть решением некоторой задачи является функция Y = F(X), заданная параметрами входных-выходных данных (X 1 , Y 1 ), (X 2 , Y 2 ), …, (X N , Y N ), для которых Y k = F(X k ) (k = 1, 2, …, N).
Обучение состоит в поиске (синтезе) функции G, близкой к F в смысле некторой функции ошибки E. (см. рис. 1.8).
Если выбрано множество обучающих примеров – пар (X N , Y N ) (где k = 1, 2, …, N) и способ вычисления функции ошибки E, то обучение нейронной сети превращается в задачу многомерной оптимизации, имеющую очень большую размерность, при этом, поскольку функция E может иметь произвольный вид обучение в общем случае – многоэкстремальная невыпуклая задача оптимизации.
Для решения этой задачи могут использоваться следующие (итерационные) алгоритмы:
алгоритмы локальной оптимизации с вычислением частных производных первого порядка:
градиентный алгоритм (метод наискорейшего спуска),
методы с одномерной и двумерной оптимизацией целевой функции в направлении антиградиента,
метод сопряженных градиентов,
методы, учитывающие направление антиградиента на нескольких шагах алгоритма;
алгоритмы локальной оптимизации с вычислением частных производных первого и второго порядка:
методы оптимизации с разреженными матрицами Гессе,
метод Левенберга-Марквардта и др.;
стохастические алгоритмы оптимизации:
поиск в случайном направлении,
метод Монте-Карло (численный метод статистических испытаний);
алгоритмы глобальной оптимизации (задачи глобальной оптимизации решаются с помощью перебора значений переменных, от которых зависит целевая функция).
На сегодняшний день используются различные алгоритмы обучения нейронных сетей. Каждый из них имеет свои достоинства и недостатки. Но конечная цель – самостоятельное извлечение знаний интеллектуальной системой – так или иначе достигается.
Принцип работы искусственной нейронной сети схож с принципом работы человеческого мозга, но это вовсе не значит, что методы обучения НС будут аналогичными. Тут все же требуются несколько иные подходы к проблеме, о которых мы сегодня и поговорим.
Нейронная сеть и возможность ее обучения
Принцип работы нейронной сети (НС) и ее структура взяты из нейробиологии. Сама идея заключалась в том, чтобы получить математическую модель и ее программное воплощение, которые бы имитировали деятельность человеческого мозга. Разработками в этой области ученые занимаются уже с середины прошлого века. Однако лишь в последние годы развитие нейросетей смогло достичь впечатляющих результатов.
Почему работа в этом направлении так важна? Дело в том, что ни одна вычислительная система не в состоянии воплотить аналитические способности человеческого мозга. Между тем, именно эти качества необходимы программам для решения ряда сложных задач.

Нейронная сеть и возможность ее обучения
В настоящее время нейронные сети используют в следующих направлениях:
- Классификационный анализ — разделение вводных данных по каким-либо признакам. Например, в медицине нейросеть облегчает задачи по диагностике: возраст пациента и его пол, жалобы на здоровье, результаты анализа, записи из анамнеза, реакция на препараты и т.д. – все это позволяет распределить больных по степени тяжести состояния.
- Прогнозирование — с учетом показателей можно спрогнозировать последующие события. Например, каршеринг использует нейросети для выявления агрессивных водителей, чтобы в дальнейшем ограничить им доступ к авто.
- Распознавание образов — это наиболее популярная область для использования нейросетей: идентификация символов на бумаге и банковских картах; распознавание лиц для решения вопросов государственной безопасности; поиск по картинке в Google и прочее.
В основе функционирования искусственного интеллекта лежит машинное обучение. Оно позволяет совершенствовать производительность ИИ без перепрограммирования системы. Говоря простым языком, этот процесс похож на обучение ребенка – он учится классифицировать и распознавать объекты, определять взаимосвязь между ними, и день за днем у него это получается все лучше.
Машинное обучение неразрывно связано с НС и представляет собой работу, при которой смоделированная среда имитирует процессы наработки опыта человеком, постепенно повышая точность результатов.
Ваш Путь в IT начинается здесь
Подробнее
2 типа обучения нейронных сетей
Процесс обучение с учителем
Обучающие примеры поступают в НС в определенной последовательности. Для каждого ответа происходит расчет ошибки и подстройка весов. Все это происходит до тех пор, пока неверные ответы по всему объему обучающего материала не примут значение допустимых показателей.
Обучение с учителем подходит для решения вопросов, в которых известен требуемый результат. Например, для классификации изображений, распознавания звуков или голоса, прогнозирования, функции аппроксимации.
Процесс обучение без учителя

Алгоритмы обучения нейросетей без учителя используют данные без классификации или меток. НС сама выстраивает логическую цепочку и усваивает понимание этих действий, ориентируясь лишь на вводные данные. По сути, это повторяет человеческое самообучение: индивид, предпринимая какие-либо действия, делает выводы о правильности либо ошибочности решения, ориентируясь на последствия.
Обучение без учителя применяют для кластеризации, языковых моделей, обнаружения аномалий, статистических моделей.
3 наиболее распространенных алгоритма обучения нейронных сетей
Выделяют три основных вида алгоритмов обучения нейронных сетей.
Метод обратного распространения
Этот метод также называют Backpropagation. Он является одним из основных способов обучения и содержит в своей основе алгоритм вычисления градиентного спуска. Другими словами, двигаясь вдоль градиента, происходит расчет локального максимума и минимума функции.
Команда GeekBrains совместно с международными специалистами по развитию карьеры подготовили материалы, которые помогут вам начать путь к профессии мечты.
Скачивайте и используйте уже сегодня:

Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Подборка 50+ ресурсов об IT-сфере

3,7 MB
Для лучшего понимания процесса необходимо перевести функцию в график, который будет отображать зависимость значений ошибки от веса синапса. На полученной кривой нужно определить точку с наименьшим и наибольшим показателем. В то же время необходимо графически отобразить все веса, и рассчитать для каждого из них глобальный минимум.
Значение градиента будет иметь векторную величину, которая даст представление о направлении и крутизне склона. Поиск значения градиента осуществляется путем вычисления производной от функции в требуемой точке. Такая точка будет иметь значение веса, распределенное случайным образом. В ней следует проводить расчет градиента и определять направленность движения спуска. Вычисления необходимо производить последовательно во всех точках, пока не будет достигнут локальный минимум, останавливающий дальнейший спуск.
На общую скорость обучения нейросети влияет не только момент ускорения, но и еще одно значение, являющееся гиперпараметром и определяющееся методом подбора.

Метод обратного распространения
Наиболее благоприятное сочетание значений невозможно знать предварительно. Оно выявляется в ходе нескольких обучений и корректировок в нужную сторону.
Как только ответ получен, происходит расчет ошибки, и в соответствии с ней выполняется обратная передача. Цель такого действия – приведение синаптических весов к оптимальным значениям при движении от выходного слоя к входному.
Для такого алгоритма обучения нейронных сетей необходимо использовать дифференцируемые функции активации. Это связано с тем, что распространение в обратном направлении определяется разностью между ответами, а также произведением между ним и производной функцией от входного значения.
Для успешного обучения требуется передать ошибку на все веса НС. При расчете ошибки можно высчитать и дельту на выходном слое. Она будет методично переходить от нейрона к нейрону.
Далее нужно рассчитать градиент для всех исходящих связей. После этого, с учетом полученных данных, требуется провести обновление весов и вычислить величину изменения с помощью функции МОР. Вместе с тем следует помнить о скорости обучения и моменте.
Метод упругого распространения
Этот метод называют также Resilient propagation (сокращенно Rprop). Он был предложен как альтернатива предыдущему способу обучения, который требует слишком много времени и становится неудобным, если результаты нужно получить в короткие сроки. Для увеличения скорости операций было разработано много вспомогательных алгоритмов, в том числе и методика упругого распространения.
Этот метод является основным при обучении по принципу epoch (один полный проход датасета через НС). Для подгонки весовых коэффициентов он использует лишь знаки производных частного случая. При этом обязательно выдерживать правило, позволяющее определить значение коррекции коэффициента веса.

Мы вместе с экспертами по построению карьеры подготовили документы, которые помогут не ошибиться с выбором и определить, какая профессия в IT подходит именно вам.
Благодаря этим гайдам 76% наших студентов смогли найти востребованную профессию своей мечты!
Скоро мы уберем их из открытого доступа, успейте скачать бесплатно:
Гайд по профессиям в IT
5 профессий с данными о навыках и средней заработной плате
100 тыс. руб за 100 дней с новой профессией
Список из 6 востребованных профессий с заработком от 100 тыс. руб
Критические ошибки, которые могут разрушить карьеру
Собрали 7 типичных ошибок. Их нужно избегать каждому!
Женщины в IT: мифы и перспективы в карьере
Как делать хороший дизайн интерфейсов
Как прокачать свою технику речи
4,7 MB
Если на этой стадии вычислений производная меняет свой знак на противоположный, то это говорит о чересчур большом изменении и об упущении локального минимума. Следовательно, нужно возвратить весу предыдущее значение и уменьшить величину изменения. Если же знак остался прежним, то следует поднять величину изменения веса для максимальной сходимости.
Если закрепить ключевые показатели подстройки весов, то можно не настраивать глобальные параметры – это является дополнительным плюсом использования метода. Причем существуют готовые значения таких показателей. Их применение рекомендовано, но жестких рамок по выбору значений нет.
Чтобы величина веса не была чрезмерно большой или, наоборот, маленькой, следует оперировать значением коррекции с установленными пределами. При расчете этого значения необходимо придерживаться правила.
В этом случае порядок операций будет таковым:
- определение значения коррекции;
- расчет частных производных;
- расчет новой величины коррекции весовых значений;
- корректировка весов.
Если условие остановки алгоритма не исполняется, то происходит возврат к расчету производных, и цикл запускается по новому кругу.
Благодаря методу упругого распространения сходимость НС добивается в сроки, значительно меньшие, чем при предыдущем алгоритме.
Генетический алгоритм обучения
Еще один распространенный подход – это обучение нейронной сети генетическим алгоритмом (Genetic Algorithm). По своему принципу он схож с эволюционными процессами природы, которые основываются на комбинировании (скрещивании) результатов. Другими словами, происходит естественный отбор, где новое поколение является продуктом комбинации результатов с самыми лучшими свойствами. Если итог такого скрещивания не подходит по каким-то критериям, то отбор совершается вновь, пока продукт не станет совершенным.
Завершение алгоритма происходит в тот момент, когда заканчиваются отведенные ему попытки или время на мутацию. При этом результат может остаться недостигнутым. Данный метод используется для улучшения показателей весов НС при условии, что структура задана по умолчанию. Вес при этом должен быть прописан двоичным кодом, а полный набор веса сформирует итоговый результат. Расчет ошибки на выходе обуславливает оценку эффективности.
В условиях высоких темпов цифровизации общества нейросети являются весьма перспективной областью для развития. Они способны обучиться тем процессам, которые человеческий мозг производит неосознанно, то есть не понимая принципа алгоритма.

Генетический алгоритм обучения
Несмотря на то, что нейронные сети в чем-то повторяют разум человека, нужно понимать, что это лишь искусственное его подобие, но не полноценный эквивалент.

Научиться обучать нейросети гораздо проще, чем кажется
Как появились нейросети
Все началось с попыток ученых приблизить принцип работы компьютера к образу мышления человека. На это ушли десятилетия исследований, и в итоге это стало возможным при помощи нейросетей — компьютерных систем, собранных из сотен, тысяч или миллионов искусственных клеток мозга, которые способны обучаться и действовать по принципу, чрезвычайно похожему на то, как работает мозг человека.
Конечно, нельзя говорить, что нейронная сеть — это точная искусственная копия мозга. Важно отметить, что нейросеть — это прежде всего компьютерная симуляция: такие сети созданы посредством программирования обычных компьютеров, в которых традиционным образом работают обычные транзисторы, объединенные в логические связи.

Как нейросеть генерирует новые фото
Из чего состоят нейросети
Обычная искусственная нейронная сеть состоит из десятков, сотен, тысяч или даже миллионов искусственных нейронов. Их называют блоками — они выстроены в слои, где каждый блок соединен с соседним. Есть блоки ввода, с помощью которых нейросеть получает информацию, и блоки вывода — они как раз отвечают за результат обработки.
Как обучают нейросети
Одна из моделей машинного обучения
Как только нейросеть прошла обучение с использованием достаточного количества примеров, она достигает стадии, когда вы можете предоставить ей совершенно новый набор вводных данных, которого она никогда не видела, и следить за ее реакцией.
Области использования нейросетей ничем не ограничены. Так, они могут осуществлять поиск по картинке или выступать в роли голосового ассистента — та же Алиса уже максимально приблизилась по своему поведению к реальному человеку. Или высчитывать вероятность заболеваний, находить опухоли на снимках, бороться с мошенниками и так далее.
Можно ли самому научиться работать с нейросетями
Как им стать? Самостоятельно сделать это почти невозможно. Это серьезная специализация, которая требует взаимодействия с теми, кто уже работает в данной области. Поэтому школа данных SkillFactory открывает новый набор на полный курс по Data Science. В рамках курса профессионалы отрасли, в том числе сотрудники Яндекса и NVIDIA, обучают тонкостям работы, о которых не пишут в учебниках.

Все преподаватели — специалисты в области Data Science
С помощью этого курса можно освоить науку по работе с данными с нуля, даже если вы ни разу в жизни не занимались программированием. Он позволяет получить все навыки, необходимые специалисту по Data Science — от программирования на Python, в том числе углубленного изучения Pandas для анализа данных, до машинного обучения, глубинного обучения и исследования данных. Курс состоит примерно из 20% теории и 80% практики, поскольку только на реальных примерах возможность стать профи в этой области.

Программа курса рассчитана на 12 месяцев

По окончании обучения выдается сертификат
Читайте также: