
Что такое таблица кодировки какие таблицы кодировки вы знаете кратко
Обновлено: 02.07.2024
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
Наиболее популярные таблицы кодировки:
- ASCII,
- MS-DOS,
- ISO,
- Windows,
- КОИ8,
- CP866,
- Mac,
- CP 1251,
- Unicode,
- и др.
Заключение
Кодирование текстовой информации — это обычный и стандартный процесс, который происходит во всех современных компьютерах. Раньше чаще ощущалась проблема с кодировками при переносе одного текста между компьютерами. Теперь таких проблем меньше, потому что во многих устройствах имеются встроенные программы-конверторы, которые автоматически отслеживают кодировки и находят нужную, чтобы пользователь об этом вообще не беспокоился.

В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE).
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности 16-битных слов (англ. code unit).
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно 32 бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Таблица кодировки - это таблица, где каждой букве алфавита (а также цифрам и специальным знакам) присвоен уникальный номер - код символа.
Первой широко используемой кодировкой, в которую вошли символы кириллицы, была KOI8.
Семейство ОС Windows 9.x преподнесло нам Win-1251. Наконец, от международной организации по стандартам ISO нам досталась кодировка ISO-8859-5.
Сейчас идет активная работа над перспективной кодировкой UNICODE

Таблица кодировки - это таблица, где каждой букве алфавита (а также цифрам и специальным знакам) присвоен уникальный номер - код символа.
Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира.
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта.

Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды.

Информатика
Память компьютера устроена таким образом, что символы и числа могут храниться в ней исключительно как определённые последовательности бит. И чтобы корректно отображать и передавать информацию о конкретной цифре или букве, были разработаны специальные кодовые таблицы. На информатике в 7 классе изучают уникальную последовательность из нулей и единиц, готовую к обработке вычислительными машинами. В таблицах каждой из них соответствует определённый графический символ.
Основные кодировки
В начале эры компьютеров на шифровку одного символа отводилось пять бит информации. Причиной этому был сильно ограниченный объём оперативной памяти вычислительных машин тех лет. Зашифровывалось всего 32 элемента, представляющие собой строчные буквы латиницы и символы управления.
Рост производительности так называемого железа привёл к появлению кодировочных таблиц, включающих в себя гораздо большее количество элементов. Так, первой кодировкой, где использовалось уже 7 бит для шифрования одного символа, стала ASCII7. Она включала в себя прописные буквы английского алфавита, цифры в арабском представлении и знаки препинания.

Вскоре появилась расширенная версия ASCII8 — с возможностью использования 256 закодированных двоичным кодом символов, причём вторая половина из 128 ячеек отводилась для национальных алфавитов.
Но для многих языков даже расширенная ASCII8 была недостаточна, поэтому для удовлетворения требований кодировок японского, арабского и других национальных языков, где необходимо большее количество структурных элементов, чем 256, была создана система UNICODE.
Win1251, ср866 используются для отображения кириллицы. Стоит также отметить отдельное развитие целой группы кодировок КОI для отображения кириллических шрифтов.
Краткая история кода ASCII
Американский стандартный код для обмена информацией, или код ASCII, был создан в 1963 году Комитетом Американской ассоциации стандартов. Этот код возник в результате изменения порядка и расширения набора символов и символов, которые уже использовались в телеграфии в то время компанией Bell.
Сначала включались только заглавные буквы и цифры, но в 1967 году были добавлены строчные буквы и некоторые управляющие символы, образующие так называемый US-ASCII, то есть символы от 0 до 127. Таким образом, этот набор, состоящий всего из 128 символов, был опубликован в 1967 году как стандарт, содержащий всё необходимое для написания текстов на английском языке.

IBM включает поддержку этой кодовой страницы в аппаратное обеспечение своей модели 5150, известной как IBM-PC, которая считается первым персональным компьютером. Операционная система этой модели MS-DOS также использовала расширенный числовой код ASCII. И сегодня почти все компьютерные системы применяют код ASCII для представления символов и текстов.
Русские версии — группа КОI

Группа KOI делится на основные кодировки — KOI8 и KOI7 (теперь историческую). Кодировки KOI7 предназначены и использовались в RSX-11, RT-11 и аналогичных системах. Все кодировки KOI8 имеют идентичное содержимое кодов 0x00−0x 7 °F (так же как в US-ASCII) и 0xC0−0xFF (32 русских буквы, то есть полный алфавит без Io / IO в обоих случаях).
Порядок русских букв не столько является алфавитным, сколько связан с порядком букв латинского алфавита с таким же произношением. Несвязанные буквы связаны практически произвольным образом (Ю (Yu) — @, Я (Ya) — Q, Э (E) — \). Кроме того, большие буквы ставятся после маленьких; это проблема совместимости с кодировками KOI7.

Универсальная шифровка
Стандарт Unicode предоставляет уникальный номер для каждого символа, независимо от платформы, вида техники, приложения или языка. Он был принят всеми современными поставщиками программного обеспечения и теперь позволяет передавать данные через множество различных платформ, устройств и приложений без повреждения.
Поддержка Unicode формирует основу для представления языков и символов во всех основных операционных системах, поисковых системах, браузерах, ноутбуках и смартфонах, а также в интернете:

Использование Unicode — лучший способ реализации ISO / IEC 10646. Появление стандарта Unicode и доступность инструментов для его поддержки являются одними из наиболее значительных международных тенденций в области программных технологий.
Кодирование символов специального языка было окончательно решено благодаря введению кодировки символов Unicode (юникод). Система кодирования способна шифровать все специальные символы, какие используются для корректной работы, и при этом соблюдается правильность кодируемого языка. Решение основано на том факте, что символ больше не сохраняется в 1 байт (только 256 возможных вариантов), но он сохраняется в 2 байта (т. е. 65536 возможных вариантов). Эта система считается брендом UTF16.
Основное преимущество UTF-16 — очень простое управление всеми возможными символами, а недостаток — несовместимость двойного размера и таблицы ASCII. Проблема несовместимости является значительной при сохранении текстовых файлов. Поэтому была создана альтернативная система кодирования Unicode, которая работает с переменной длиной сохраняемого символа. Символы таблицы ASCII сохраняются в 1 байте, а не-ASCII символы сохраняются в 2 или более байтах. Эта система кодирования приписывается бренду UTF-8, который в основном используется для текстовых (XML, HTM) файлов.
При работе с такими текстами символы преобразуются в UTF-16 уже в оперативной памяти компьютера, что ускоряет его работу. Кодирование символов UTF-16 и UTF-8 используется системой PROMOTIC начиная с версии Pm7.1.0, поэтому можно создавать многоязычные приложения без необходимости смены кодовой страницы символов или использования специальных версий ОС Windows.
UTF-16 также применяют во время работы приложения (текстовые панели, в сценарии), в то время как кодирование UTF-8 используется для текстовых файлов (например, текстовых файлов XML для макрокоманды $.text).
Современные международные десятичные кодировочные таблицы позволяют представлять практически любой язык в виде машинного кода. А использование того или иного способа шифрования зависит от условий конкретной задачи и технических возможностей компьютерных устройств.

Для представления букв в вычислительной технике используют кодовые таблицы. Кратко о видах таблиц символов и их использовании рассказано в данной статье.
Что такое кодовая таблица
Известно, что числа в ЭВМ представляются в двоичной форме, в виде набора нулей и единиц. Для этого разработаны специальные приемы перевода числовых значений в двоичную последовательность. А как же компьютером обрабатываются текстовая информация – предложение, слова и буквы? Точно также как и числа – в виде последовательности нулей и единиц.
Для представления буквы в компьютере ее заменяют числовым эквивалентом, а затем переводят в двоичный код. Каждой букве соответствует своя цифра. Все буквы с их числовыми эквивалентами сведены в кодовую таблицу символов, которая может называться ASCII, Unicode, КОИ-7, КОИ-8, Windows-1251.
Таблица ASCII
Самой первой системой кодирования текстовой информации была ASCII (американский стандартный код для обмена информацией).
Таблица ASCII была разработана в США в шестидесятые годы прошлого столетия. Появление такой единой унифицированной системы кодировки символов было продиктовано необходимостью реализации компьютерного взаимодействия и обмена информацией. В то время каждый производитель вычислительной техники самостоятельно представлял буквы, цифры и управляющие коды. Только специалистами корпорации IBM применялись девять различных наборов кодировки символов.
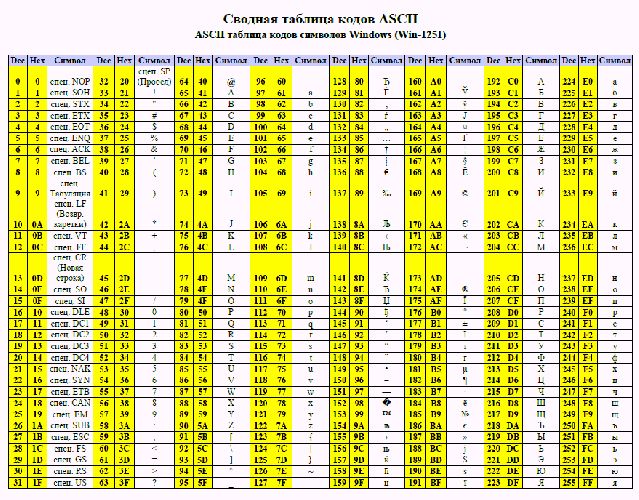
Рис. 1. Символы таблицы ASCII.

Рис. 2. Боб Бемер.
Первоначально таблица использовалась для кодировки только 128 знаков, затем была расширена до 256 символов. Первые тридцать два символа в таблице ASCI не имеют печатных эквивалентов и используются для управления. Числа в диапазоне 32 –127 предназначены для кодирования прописных и строчных латинских букв, цифр и знаков препинания.
Знак пробела имеет код 32 и также является печатным символом. Проверить соответствие символа печатному коду легко. Для этого можно воспользоваться простейшим текстовым редактором Блокнот в группе программ Стандартные операционной системы Windows. Нажав одновременно функциональную клавишу Alt и введя код символа – десятичное число, в окне редактора на месте расположения курсора будет напечатан соответствующий символ.
Национальные версии таблицы ASCII
Таблица ASCII в интервале символов от 0 до 127 остается неизменной для любых программ. Диапазон кодовых значений от 128 до 255 может варьироваться в зависимости от языковых и национальных особенностей.
Существуют различные национальные варианты системы кодирования. Для кодирования букв русского алфавита используются:
Unicode
Unicode представляет собой промышленный стандарт для кодирования символов всех письменных языков мира. Он был предложен в 1991 году некоммерческой организацией Unicode Consortium.
Рис. 3. Логотип Unicode Consortium.
Кодовое пространство Unicode разделено на несколько областей. Диапазон кодовых значений от 0 до 127 полностью дублирует кодовую систему ASCII. Затем располагаются области знаков разных языков, пунктуационные знаки и некоторые технические символы.
Unicode имеет несколько форм представления: UTF-8, UTF-16 и UTF-32.
Что мы узнали?
Для представления символьных значений в ЭВМ используются таблицы кодирования символов. Каждому символу в такой таблице соответствует числовое значение. Использование стандартизированных кодовых таблиц позволило обеспечить взаимодействие и информационный обмен между средствами вычислительной техники.
Читайте также: