
Что такое программирование снизу вверх сверху вниз кратко
Обновлено: 07.07.2024
Я немного запутался. В чем разница между этими двумя?
резюмировать
Динамическое программирование - это все, чтобы упорядочить вычисления таким образом, чтобы избежать пересчета дублирующейся работы. У вас есть основная проблема (корень вашего дерева подзадач) и подзадачи (поддеревья). Подзадачи обычно повторяются и перекрываются .
Например, рассмотрим ваш любимый пример Фибоначчи. Это полное дерево подзадач, если мы сделали наивный рекурсивный вызов:
(В некоторых других редких проблемах это дерево может быть бесконечным в некоторых ветвях, что означает отсутствие завершения, и, следовательно, нижняя часть дерева может быть бесконечно большой. Кроме того, в некоторых задачах вы можете не знать, как выглядит полное дерево впереди. время. Таким образом, вам может понадобиться стратегия / алгоритм, чтобы решить, какие подзадачи выявить.)
Мемоизация, табуляция
Существует как минимум два основных метода динамического программирования, которые не являются взаимоисключающими:
- пример: если вы вычисляете последовательность Фибоначчи fib(100) , вы просто вызвали бы это, и он вызвал бы fib(100)=fib(99)+fib(98) , что бы вызвать fib(99)=fib(98)+fib(97) . и т. д. . который бы вызвал fib(2)=fib(1)+fib(0)=1+0=1 . Затем он, наконец, разрешится fib(3)=fib(2)+fib(1) , но не нужно пересчитывать fib(2) , потому что мы его кэшировали.
- Это начинается в верхней части дерева и оценивает подзадачи от листьев / поддеревьев назад к корню.
Плюсы и минусы
Простота кодирования
* (на самом деле это легко сделать, только если вы пишете функцию самостоятельно и / или пишете на нечистом / нефункциональном языке программирования . например, если кто-то уже написал предварительно скомпилированную fib функцию, она обязательно делает рекурсивные вызовы сама себе, и вы не можете волшебным образом запоминать функцию, не гарантируя, что эти рекурсивные вызовы вызовут вашу новую запомненную функцию (а не оригинальную неметизированную функцию))
Рекурсивность
Обратите внимание, что как сверху вниз, так и снизу вверх могут быть реализованы с помощью рекурсии или итеративного заполнения таблиц, хотя это может быть не естественным.
Практические проблемы
В случае с мемоизацией, если дерево очень глубокое (например fib(10^6) ), вам не хватит места в стеке, потому что каждое отложенное вычисление должно быть помещено в стек, и у вас будет 10 ^ 6 из них.
Оптимальность
Любой подход может не быть оптимальным по времени, если порядок, в котором вы выполняете (или пытаетесь) посещать подзадачи, не является оптимальным, в частности, если существует несколько способов вычисления подзадачи (обычно кеширование решает эту проблему, но теоретически возможно, что кеширование может не в некоторых экзотических случаях). Мемоизация, как правило, добавляет сложность времени к сложности пространства (например, при табулировании у вас больше свободы в отбрасывании вычислений, например, при использовании табуляции с помощью Fib вы можете использовать пространство O (1), но при запоминании с помощью Fib используется O (N). пространство стека).
Расширенные оптимизации
Более сложные примеры
Здесь мы перечислили примеры, представляющие особый интерес, которые представляют собой не только общие проблемы DP, но и интересно различают запоминание и табулирование. Например, одна формулировка может быть намного проще, чем другая, или может быть оптимизация, которая в основном требует табуляции:
- алгоритм вычисления расстояния редактирования [ 4 ], интересный как нетривиальный пример алгоритма заполнения двумерных таблиц
@mgiuffrida: пространство стека иногда обрабатывается по-разному в зависимости от языка программирования. Например, в python попытка выполнения запомненного рекурсивного фиба потерпит неудачу, скажем так fib(513) . Перегруженная терминология, которую я чувствую, мешает здесь. 1) Вы всегда можете выбросить подзадачи, которые вам больше не нужны. 2) Вы всегда можете избежать расчета подзадач, которые вам не нужны. 3) 1 и 2 может быть намного сложнее в кодировании без явной структуры данных для хранения подзадач, или, ИЛИ сложнее, если поток управления должен переплетаться между вызовами функций (вам может потребоваться состояние или продолжения).
Сверху вниз и снизу вверх DP - это два разных способа решения одних и тех же проблем. Рассмотрим запрограммированное (сверху вниз) и динамическое (снизу вверх) программное решение для вычисления чисел Фибоначчи.
Да, это линейно! Я вытащил дерево рекурсии и увидел, каких вызовов можно избежать, и понял, что все вызовы memo_fib (n - 2) будут избегаться после первого обращения к нему, и поэтому все нужные ветви дерева рекурсии будут обрезаны, и это сведу к линейному.
Поскольку DP в основном включает создание таблицы результатов, где каждый результат вычисляется не более одного раза, один простой способ визуализации времени выполнения алгоритма DP состоит в том, чтобы увидеть, насколько большой является таблица. В этом случае он имеет размер n (один результат на входное значение), поэтому O (n). В других случаях это может быть матрица n ^ 2, в результате чего O (n ^ 2) и т. Д.
Используйте свой любимый язык и попробуйте запустить его для fib(50) . Это займет очень и очень много времени. Примерно столько же времени, сколько и fib(50) себя! Тем не менее, много ненужной работы делается. fib(50) будет вызывать fib(49) и fib(48) , но тогда оба из них в конечном итоге вызов fib(47) , даже если значение одинаково. Фактически, fib(47) будет вычислено три раза: прямым вызовом fib(49) , прямым вызовом из fib(48) , а также прямым вызовом другого fib(48) , который был порожден вычислением fib(49) . Итак, вы видите, у нас есть перекрывающиеся подзадачи ,
Обычно вы также можете написать эквивалентную итеративную программу, которая работает снизу вверх без рекурсии. В этом случае это было бы более естественным подходом: цикл от 1 до 50 вычисляет все числа Фибоначчи по мере продвижения.
В любом интересном сценарии восходящее решение обычно труднее понять. Однако, как только вы поймете это, обычно вы получите более ясную картину того, как работает алгоритм. На практике при решении нетривиальных задач я рекомендую сначала написать нисходящий подход и протестировать его на небольших примерах. Затем напишите восходящее решение и сравните оба, чтобы убедиться, что вы получаете то же самое. В идеале, сравните два решения автоматически. Напишите небольшую процедуру, которая будет генерировать множество тестов, в идеале - всенебольшие тесты до определенного размера - и проверить, что оба решения дают одинаковый результат. После этого используйте восходящее решение в производстве, но оставьте код сверху вниз, закомментированный. Это облегчит другим разработчикам понимание того, что вы делаете: код снизу вверх может быть совершенно непонятным, даже если вы его написали и даже если точно знаете, что делаете.
Во многих приложениях восходящий подход немного быстрее из-за накладных расходов на рекурсивные вызовы. Переполнение стека также может быть проблемой в определенных проблемах, и обратите внимание, что это может очень сильно зависеть от входных данных. В некоторых случаях вы не сможете написать тест, вызывающий переполнение стека, если вы недостаточно хорошо разбираетесь в динамическом программировании, но однажды это все же может произойти.
Лично я бы использовал сверху вниз для оптимизации абзацев, иначе говоря, проблему оптимизации переноса в слова (посмотрите алгоритмы переноса строк Кнута-Пласса; по крайней мере, TeX использует их, а некоторые программы Adobe Systems используют аналогичный подход). Я бы использовал снизу вверх для быстрого преобразования Фурье .
Привет. Я хочу определить, правильны ли следующие предложения. - Для алгоритма динамического программирования вычисление всех значений снизу вверх асимптотически быстрее, чем использование рекурсии и запоминания. - Время динамического алгоритма всегда равно Ο (Ρ), где Ρ - количество подзадач. - Каждая проблема в NP может быть решена в геометрической прогрессии.
@evinda, (1) всегда ошибается. Это либо то же самое, либо асимптотически медленнее (когда вам не нужны все подзадачи, рекурсия может быть быстрее). (2) верно только в том случае, если вы можете решить каждую подзадачу в O (1). (3) является своего рода правильным. Каждая проблема в NP может быть решена за полиномиальное время на недетерминированной машине (как квантовый компьютер, который может делать несколько вещей одновременно: есть свой пирог, и одновременно есть его, и отслеживать оба результата). Таким образом, в некотором смысле каждая проблема в NP может быть решена в геометрической прогрессии на обычном компьютере. Примечание: все в P тоже есть в NP. Например, добавив два целых числа
Возьмем ряд Фибоначчи в качестве примера
Еще один способ выразить это,
В случае первых пяти чисел Фибоначчи
Теперь давайте рассмотрим рекурсивный алгоритм ряда Фибоначчи в качестве примера.
Теперь, если мы выполним эту программу с помощью следующих команд
Если мы внимательно посмотрим на алгоритм, для того, чтобы сгенерировать пятое число, требуется 3-е и 4-е числа. Таким образом, моя рекурсия фактически начинается сверху (5), а затем идет до нижних / нижних чисел. Этот подход на самом деле является нисходящим.
Чтобы не выполнять одни и те же вычисления несколько раз, мы используем методы динамического программирования. Мы храним ранее вычисленное значение и используем его повторно. Эта техника называется запоминанием. В динамическом программировании есть нечто большее, чем запоминание, которое не нужно для обсуждения текущей проблемы.
Сверху вниз
Давайте перепишем наш оригинальный алгоритм и добавим запоминающиеся методы.
И мы выполняем этот метод следующим образом
Это решение все еще работает сверху вниз, так как алгоритм запускается с верхнего значения и опускается на каждый шаг вниз, чтобы получить наше максимальное значение.
Вверх дном
Но вопрос в том, можем ли мы начать снизу, как с первого числа Фибоначчи, а затем идти вверх. Давайте переписать его, используя эту технику,
Теперь, если мы посмотрим на этот алгоритм, он на самом деле начинается с более низких значений, а затем идет наверх. Если мне нужно 5-е число Фибоначчи, я на самом деле вычисляю 1-е, затем второе и третье, вплоть до 5-го числа. Эта техника фактически называется восходящей техникой.
Последние два, алгоритмы полного заполнения требований динамического программирования. Но один сверху вниз, а другой снизу вверх. Оба алгоритма имеют одинаковую пространственную и временную сложность.
Вопрос:
Что такое программирование снизу вверх; сверху вниз?
Подробный ответ:
рограммирование сверху вниз или нисходящее программирование - это способ создания программ, когда задача разбивается на подзадачи, и написание программ начинается с разработки процедур и подпрограмм решения этих подзадач, из которых, потом, собирается решение основной задачи.
Программирование снизу вверх или восходящее программирование - это способ создания программ, когда начинаются писаться подпрограммы и процедуры, до конца еще не понимая, что должно получится в результате работы основной программы.
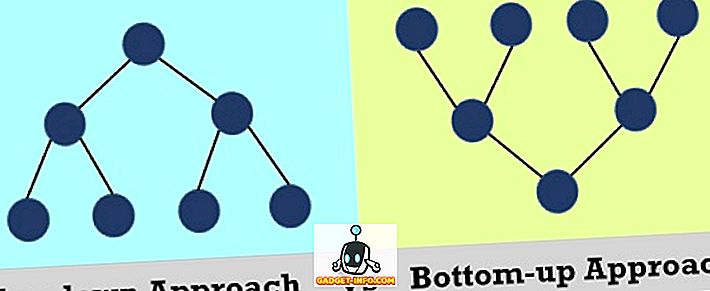
Алгоритмы разработаны с использованием двух подходов: нисходящего и нисходящего. В нисходящем подходе сложный модуль делится на подмодули. С другой стороны, подход снизу вверх начинается с элементарных модулей, а затем объединяет их дальше. Первоочередной целью алгоритма является обработка данных, содержащихся в структуре данных. Другими словами, алгоритм используется для выполнения операций с данными внутри структур данных.
Сложный алгоритм разбивается на маленькие части, называемые модулями, а процесс расщепления известен как модуляризация . Модуляризация значительно уменьшает сложности при разработке алгоритма и упрощает его разработку и реализацию. Модульное программирование - это метод проектирования и написания программы в форме функций, в которых каждая функция отличается от другой и работает независимо. Содержание функций является взаимосвязанным, и между модулями существует слабая связь.
Сравнительная таблица
| Основа для сравнения | Нисходящий подход | Подход «снизу вверх |
|---|---|---|
| основной | Разбивает огромную проблему на более мелкие подзадачи. | Решает фундаментальную проблему низкого уровня и объединяет их в более крупную. |
| Процесс | Подмодули анализируются единолично. | Изучите, какие данные должны быть инкапсулированы, и подразумевает ли концепция сокрытия информации. |
| связь | Не требуется при подходе сверху вниз. | Требуется определенное количество общения. |
| избыточность | Содержать избыточную информацию. | Избыточность может быть устранена. |
| Языки программирования | Структурированные / процедурно-ориентированные языки программирования (т.е. C) следуют нисходящему подходу. | Объектно-ориентированные языки программирования (такие как C ++, Java и т. Д.) Следуют восходящему подходу. |
| В основном используется в | Документация модуля, создание тестового набора, реализация кода и отладка. | тестирование |
Определение нисходящего подхода
Таким образом, нисходящий метод начинается с абстрактного дизайна, а затем последовательно этот дизайн дорабатывается для создания более конкретных уровней, пока не требуется дополнительное уточнение.
Определение восходящего подхода
Ключевые различия между нисходящим и восходящим подходом
Заключение
Почему мы говорим, что язык, такой как C, сверху вниз, а языки ООП, такие как java или C++, снизу вверх?. Имеет ли эта классификация какое-либо значение для разработки программного обеспечения?
подход "сверху вниз" принимает высокоуровневое определение проблемы и подразделяет ее на подзадачи, которые вы затем делаете рекурсивно, пока вы не дойдете до частей, которые очевидны и легко кодировать. Это часто связано со стилем программирования "функциональной декомпозиции", но не обязательно.
в программировании "снизу вверх" вы определяете инструменты нижнего уровня, которые вы можете составить, чтобы стать большей программой.
на самом деле почти все Программирование выполняется с помощью сочетание подходов. в объектно-ориентированном программировании вы обычно подразделяете проблему, идентифицируя объекты домена (что является шагом сверху вниз) и уточняя их, а затем рекомбинируя их в конечную программу - Шаг снизу вверх.
в разработке сверху вниз вы начинаете с вашей основной функции, а затем думаете об основных шагах, которые вам нужно предпринять, затем вы разбиваете каждый из этих шагов на их подпункты и так далее.
в программировании снизу вверх вы думаете об основных функциях и частях, которые вам понадобятся, и создаете их. Вы развиваете актеров и их методы, а затем связываете их вместе, чтобы создать единое целое.
ООП естественно клонит к дну-вверх по мере того как вы начинаете ваши объекты, в то время как процедурное программирование имеет тенденцию к нисходящему, когда вы начинаете с одной функции и медленно добавляете к ней.
Я никогда не слышал, чтобы термины "сверху вниз" и "снизу вверх" использовались таким образом.
термины обычно используются для описания того, как человек подходит к проектированию и реализации программной системы и, таким образом, применяется к любому языку или парадигме программирования.
В "on LISP" Пол Грэм использует термин "снизу вверх" несколько иначе, чтобы означать постоянное извлечение общей функциональности в общие функции, так что вы в конечном итоге создаете новый диалект более высокого уровня LISP, который позволяет вы программируете в терминах домена приложения. Это не обычное употребление термина. В наши дни мы назвали бы это "рефакторингом" и "доменными встроенными языками" (и старые программисты LISP насмехались бы над тем, что LISP смог сделать это с 1950-х годов).
Я никогда не слышал, что классификация применяется к конкретным языкам, а это парадигма программирования - вы сначала заполняете детали (т. е. строите полные методы реализации), а затем объединяете их (например, вызываете их из них main () метод) или начинаете с логического потока, а затем конкретизируете реализацию?
вы действительно можете сделать либо с обоими типами lanugages. Но я бы сказал, что обычно все наоборот, в текущих языках ООП вы сначала определите интерфейсы, формирующие логическую структуру, и только после этого беспокоятся о реализации, тогда как прямые процедурные языки, такие как C, вам нужно фактически реализовать некоторые методы, прежде чем вызывать их.
Читайте также: