
Закодировать сообщение методом шеннона фано теория информации кодирования модуляции
Обновлено: 02.07.2024
Кодирование методом Шеннона – Фано рассмотрим на примере. Пусть алфавит источника содержит шесть элементов , появляющихся с вероятностями , , , , , . Энтропия такого источника:
Алгоритм построения сжимающего кода Шеннона – Фано заключается в следующем.
1. Все символов дискретного источника располагаются в порядке убывания вероятностей их появления (табл. 4.2).
Таблица 4.2. Построение кода Шеннона-Фано
2. Образованный столбец символов делится на две группы таким образом, чтобы суммарные вероятности каждой группы мало отличались друг от друга.
6. Записывается код для каждого символа источника; считывание кода осуществляется слева направо.
что меньше, чем при простейшем равномерном коде и незначительно отличается от энтропии источника.
© 2022 Научная библиотека
Копирование информации со страницы разрешается только с указанием ссылки на данный сайт
СЖАТИЕ ДАННЫХ И ЕЕ ВИДЫ
Сжатие данных, также известное как исходное кодирование, - это процесс кодирования или преобразования данных таким образом, чтобы он потреблял меньше места в памяти. Сжатие данных уменьшает количество ресурсов, необходимых для хранения и передачи данных.
Это можно сделать двумя способами: сжатие без потерь и сжатие с потерями. Сжатие с потерями уменьшает размер данных за счет удаления ненужной информации, в то время как при сжатии без потерь данные отсутствуют.
ЧТО ТАКОЕ FANO CODING SHANNON?
Алгоритм Шеннона Фано - это метод энтропийного кодирования для сжатия мультимедийных данных без потерь. Названный в честь Клода Шеннона и Роберта Фано, он присваивает код каждому символу в зависимости от вероятности их появления. Это схема кодирования переменной длины, то есть коды, присвоенные символам, будут иметь разную длину.
- Создайте список вероятностей или значений частоты для данного набора символов, чтобы известна относительная частота встречаемости каждого символа.
- Отсортируйте список символов в порядке убывания вероятности, наиболее вероятные слева и наименее вероятные справа.
- Разделите список на две части, с полной вероятностью того, что обе части будут как можно ближе друг к другу.
- Присвойте значение 0 левой части и 1 - правой части.
- Повторите шаги 3 и 4 для каждой части, пока все символы не будут разделены на отдельные подгруппы.
Коды Шеннона считаются точными, если код каждого символа уникален.
ПРИМЕР:
Данная задача состоит в построении кодов Шеннона для заданного набора символов с использованием техники сжатия Шеннона-Фано без потерь.

Шаг:
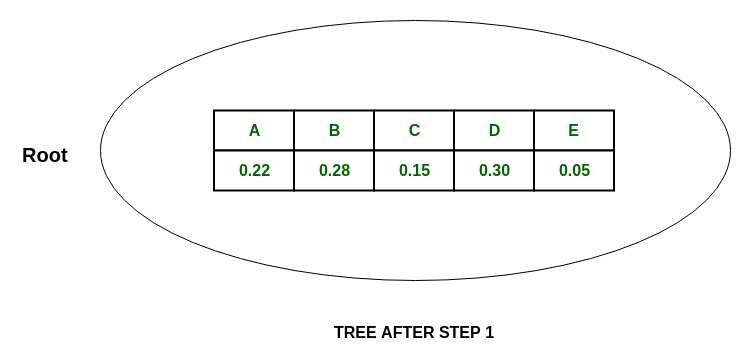
Дерево:
-
Пусть P (x) - вероятность появления символа x:
P(A) + P(C) + P(E) = 0.22 + 0.15 + 0.05 = 0.42
И так как таблица разделена почти поровну, большая часть таблицы цитат разделена на блоки.
и присвоить им значения 0 и 1 соответственно.
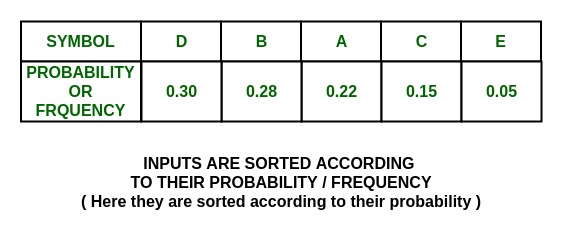
Шаг:
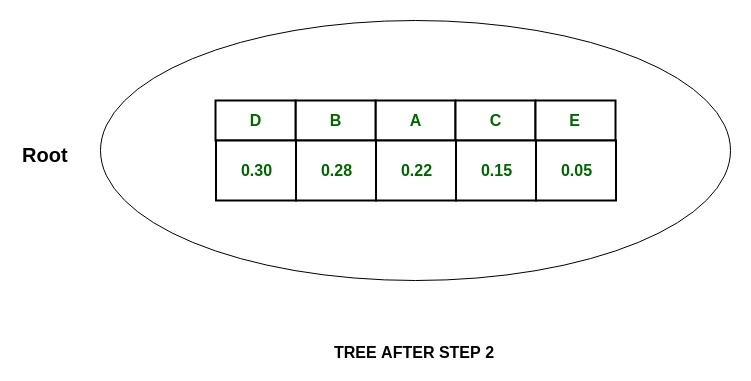
Дерево:
P(D) = 0.30 and P(B) = 0.28
что означает, что P (D) ~ P (B) , поэтому разделите на и и присвойте 0 D и 1 B.
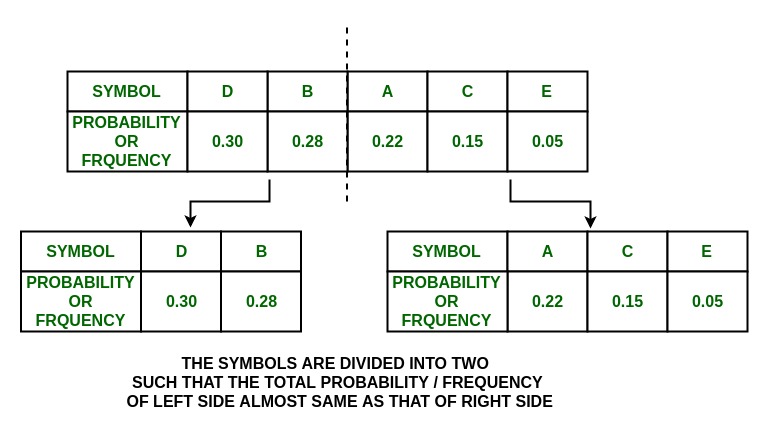
Шаг:
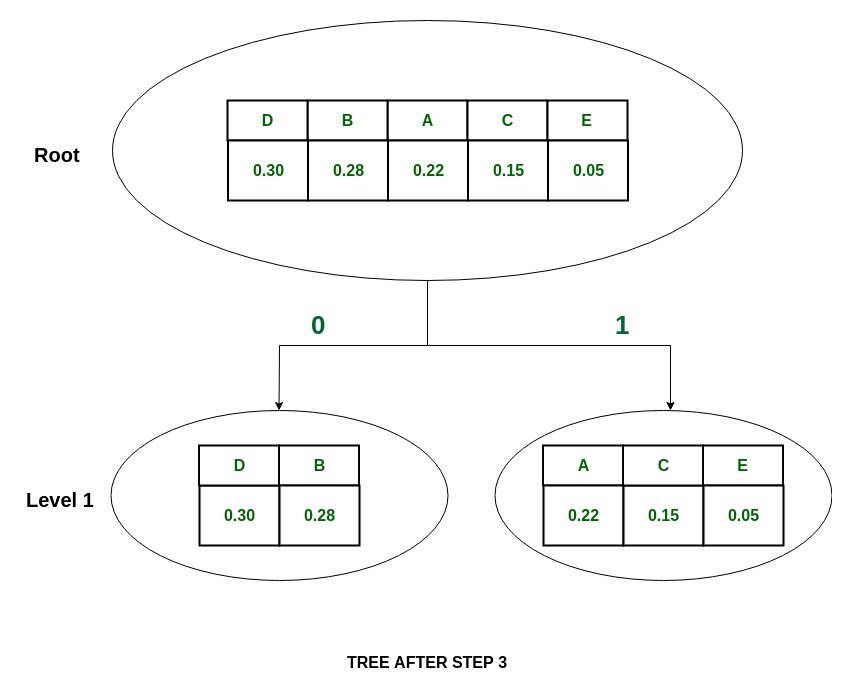
Дерево:
P(A) = 0.22 and P(C) + P(E) = 0.20
Итак, группа делится на
и им присваиваются значения 0 и 1 соответственно.
P(C) = 0.15 and P(E) = 0.05
Разделите их на и и присвойте 0 и 1
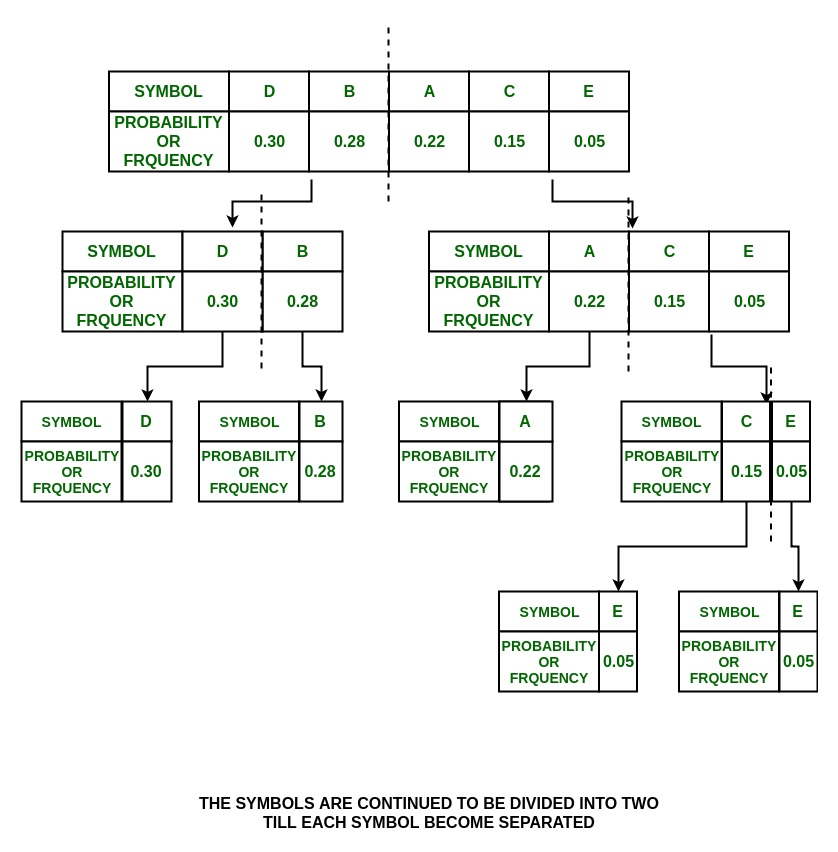
Шаг:
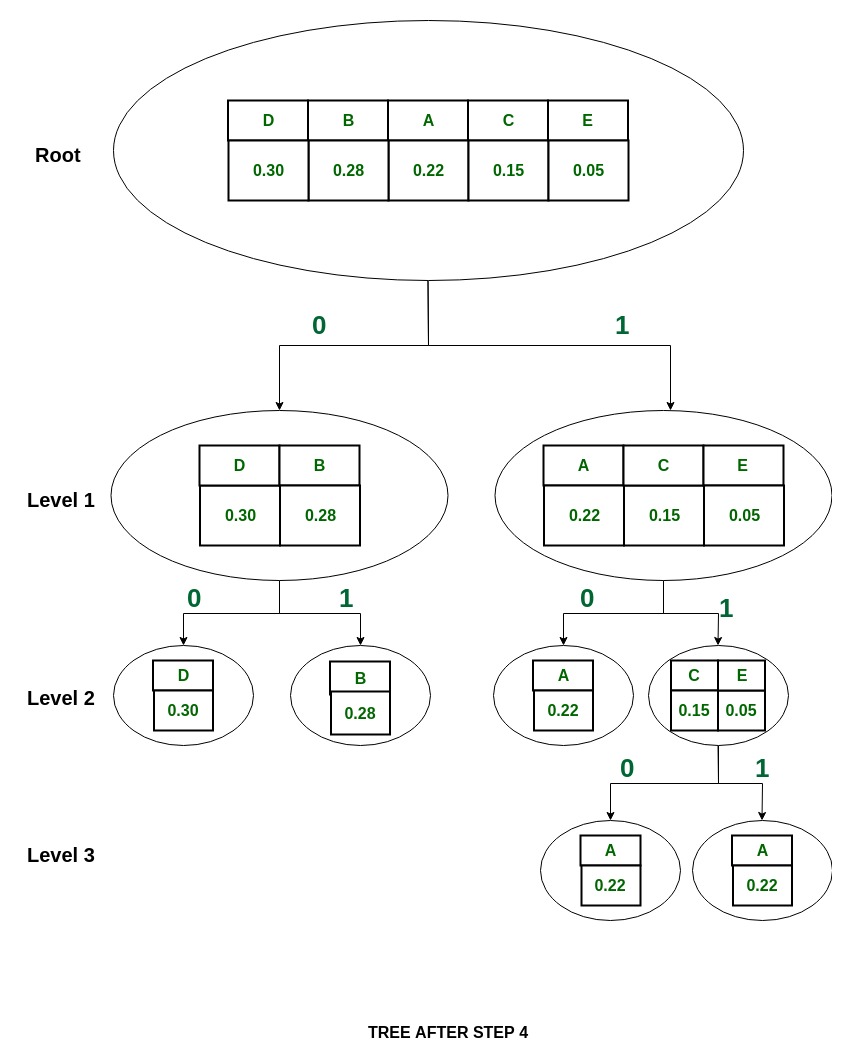
Дерево:
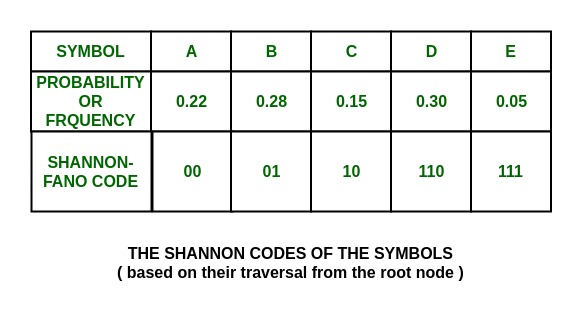
Коды Шеннона для набора символов:
Как видно, все они уникальны и разной длины.
Важнейшей частью информатики как науки является теория информации, которая занимается изучением информации как таковой, ее появлением, развитием и уничтожением. К этой науке близко примыкает теория кодирования, в задачу которой входит изучение форм представления информации при ее передаче по различным каналам связи, а также при хранении и обработке.
Цель курсовой работы — изучение основные методы эффективного кодирования, программно реализовать один из методов.
Для достижения поставленной цели предполагается решение следующих задач:
- изучить методы эффективного кодирования;
- обозначить достоинства и недостатки методов;
- детально разобрать метод, выбранный для реализации;
- выбрать язык программирования, на котором будет реализован данный метод;
- провести тестирование программы.
Объектом курсовой работы является изучение методов эффективного кодирования. Более подробно будет рассмотрен методика кодирования Хаффмана, что является её предметом.
Методы эффективного кодирования
Методы эффективного кодирования некоррелированной последовательности знаков, код Шеннона-Фано
полученную в процессе деления группу подвергают вышеописанной операции до тех пор, пока в результате очередного деления в каждой группе не останется по одному знаку (Таблица 1).
В приведенном примере среднее число символов на один знак , где – число символов в i -м разряде, имеет такую же величину, как и энтропия, рассчитанная в среднем на один знак (Формула 1):

(1)
Таблица 1 — Код Шеннона-Фано по одному знаку
| Знаки | Вероятности | Коды |
| Z1 | 1/2 | |
| Z2 | 1/4 | |
| Z3 | 1/8 | |
| Z4 | 1/16 | |
| Z5 | 1/32 | |
| Z6 | 1/64 | |
| Z7 | 1/128 | |
| Z8 | 1/128 |
Совпадение результатов связано с тем, что вероятности знаков являются целочисленными отрицательными степенями двойки.

В общем случае
Еслиодин из этих знаков кодировать, например, нулем, а другой единицей, по одному символу на знак, имеем соответственно



При переходе к кодированию блоками по два знака (Таблица 2)эффект достигается за счет того, что при укрупнении блоков, группы можно делить на более близкие по значениям суммарных вероятностей подгруппы , где n– число символов в блоке.
Таблица 2 — Код Шеннона-Фано по блокам
| Знаки | Вероятности | Коды |
| Z1Z1 | 0,81 | |
| Z2Z1 | 0,09 | |
| Z1 Z2 | 0,09 | |
| Z2Z2 | 0,01 |
Статьи к прочтению:
Метод Шеннона-Фано
Похожие статьи:
Информация на поверхностях накопителя хранится в виде последовательности мест с переменной намагниченностью, обеспечивающих непрерывный поток данных при…
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем.
Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона-Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий.
Поэтому код Шеннона-Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона-Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона-Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
Пример кодового дерева
Исходные символы:
A (частота встречаемости 50)
B (частота встречаемости 39)
C (частота встречаемости 18)
D (частота встречаемости 49)
E (частота встречаемости 35)
F (частота встречаемости 24)
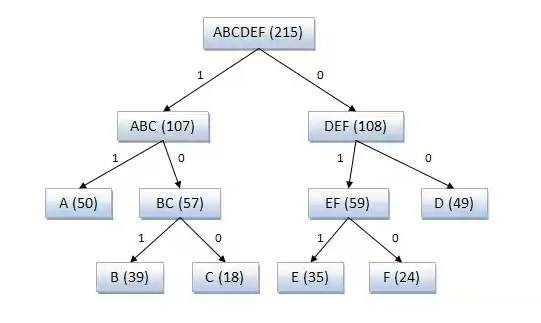
Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона-Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана. Но на некоторых последовательностях могут сформироваться неоптимальные коды Шеннона-Фано, поэтому более эффективным считается сжатие методом Хаффмана.
Пример 1. Закодируем буквы алфавита в коде Шеннона-Фано.
Пусть имеется случайная величина X (x1, x2, x3, x4, x5, x6, x7, x8), имеющая восемь состояний с распределением вероятностей
Для кодирования алфавита из восьми букв без учета вероятностей равномерным двоичным кодом нам понадобятся три символа:
Это 000, 001, 010, 011, 100, 101, 110, 111
Чтобы ответить, хорош этот код или нет, необходимо сравнить его с оптимальным значением, то есть определить энтропию
Определив избыточность L по формуле L=1-H/H0=1-2,75/3=0,084, видим, что возможно сокращение длины кода на 8,4%.
Все буквы записываются в порядке убывания их вероятностей, затем делятся на равновероятные группы, которые обозначаются 0 и 1, затем вновь делятся на равновероятные группы и т.д. (см.табл.4.1)
| X | P | Коды | |
| x1 | 1/4 | ------- | ------- |
| x2 | 1/4 | ------- | ------- |
| x3, | 1/8 | ------- | |
| x4 | 1/8 | ------- | |
| x5 | 1/16 | ||
| x6 | 1/16 | ||
| x7 | 1/16 | ||
| x8 | 1/16 |
Средняя длина полученного кода будет равна
Итак, мы получили оптимальный код. Длина этого кода совпала с энтропией. Данный код оказался удачным, так как величины вероятностей точно делились на равновероятные группы.
Возьмем 32 две буквы русского алфавита. Частоты этих букв известны. В алфавит включен и пробел, частота которого составляет 0,145. Метод кодирования представлен в таблице
| Буква | Рi | Код | ||
| ? | 0.145 | - | ||
| о | 0.095 | - | ||
| е | 0.074 | |||
| а | 0.064 | |||
| и | 0.064 | |||
| н | 0.056 | |||
| т | 0.056 | … | … | - |
| с | 0.047 | … | … | |
| . | … | |||
| ф | 0.03 |
Средняя длина данного кода будет равна, бит/букву;
Энтропия H=4.42 бит/буква. Эффективность полученного кода можно определить как отношение энтропии к средней длине кода. Она равна 0,994. При значении равном единице код является оптимальным. Если бы мы кодировали кодом равномерной длины , то эффективность была бы значительно ниже.
Читайте также: