
Практическое значение расшифровки генетического кода сообщение
Обновлено: 05.07.2024
Под генетическим кодом принято понимать такую систему знаков, обозначающих последовательное расположение соединений нуклеотидов в ДНКа и РНКа, которая соответствует другой знаковой системе, отображающей последовательность аминокислотных соединений в молекуле белка.
Когда учёным удалось изучить свойства генетического кода, одним из главных была признана универсальность. Да, как ни странно это звучит, все объединяет один, универсальный, общий генетический код. Формировался он на протяжении большого временного промежутка, и процесс закончился около 3,5 миллиардов лет назад. Следовательно, в структуре кода можно проследить следы его эволюции, от момента зарождения до сегодняшнего дня.
Когда говорится о последовательности расположения элементов в генетическом коде, имеется в виду, что она далеко не хаотична, а имеет строго определённый порядок. И это тоже во многом определяет свойства генетического кода. Это равнозначно расположению букв и слогов в словах. Стоит нарушить привычный порядок, и большинство того, что мы будем читать на книжных или газетных страницах, превратится в нелепую абракадабру.
Основные свойства генетического кода
Обычно код несёт в себе какую-либо информацию, зашифрованную особым образом. Для того чтобы расшифровать кода, необходимо знать отличительные особенности.
Итак, основные свойства генетического кода - это:
- триплетность;
- вырожденность или избыточность;
- однозначность;
- непрерывность;
- уже указанная выше универсальность.
Остановимся подробнее на каждом свойстве.
Это когда три соединения нуклеотидов образуют последовательную цепочку внутри молекулы (т.е. ДНК или же РНК). В результате создаётся соединение триплета или кодирует одну из аминокислот, место её нахождения в цепи пептидов.
Различают кодоны (они же кодовые слова!) по их последовательности соединения и по типу тех азотистых соединений (нуклеотидов), которые входят в их состав.
В генетике принято выделять 64 кодоновых типа. Они могут образовывать комбинации из четырёх типов нуклеотидов по 3 в каждом. Это равносильно возведению числа 4 в третью степень. Таким образом, возможно образование 64-х нуклеотидных комбинаций.
2. Избыточность генетического кода
Это свойство прослеживается тогда, когда для шифрования одной аминокислоты требуется несколько кодонов, обычно в пределах 2-6. И только и триптофана можно кодировать с помощью одного триплета.
Она входит в свойства генетического кода как показатель здоровой генной наследственности. Например, о хорошем состоянии крови, о нормальном гемоглобине может рассказать медикам стоящий на шестом месте в цепочке триплет ГАА. Именно он несёт информацию о гемоглобине, и им же кодируется А если человек болен анемией, один из нуклеотидов заменяется на другую букву кода - У, что и является сигналом заболевания.
При записи этого свойства генетического кода следует помнить, что кодоны, как звенья цепочки, располагаются не на расстоянии, а в прямой близости, друг за другом в нуклеиновой кислотной цепи, и цепь эта не прерывается - в ней нет начала или конца.
Никогда не следует забывать, что всё сущее на Земле объединено общим генетическим кодом. И потому у примата и человека, у насекомого и птицы, столетнего баобаба и едва проклюнувшейся из-под земли травинки одинаковыми триплетами кодируются схожие аминокислоты.
Именно в генах заложена основная информация о свойствах того или иного организма, своего рода программа, которую организм получает в наследство от живших ранее и которая существует как генетический код.
При необходимости синтеза белков перед клеткой возникает одна серьезная проблема – информация в ДНК хранится в виде последовательности, закодированной 4 символами (нуклеотидами), а белки состоят из 20 различных символов (аминокислот). Если попытаться использовать сразу все четыре символа для кодировки аминокислот, то получится всего 16 сочетаний, в то время как протеиногенных аминокислот насчитывается 20. Не хватает.
На этот счет существует пример гениального мышления:
" Возьмем, например, колоду игральных карт, в которой мы обращаем внимание только на масть карты. Сколько триплетов одного и того же вида можно получить? Четыре, конечно: трое червей, трое бубен, трое пик и трое треф. Сколько триплетов с двумя картами одной и той же масти и одной другой? Пусть мы имеем четыре выбора для третьей карты. Поэтому мы имеем 4x3 = 12 возможностей. В дополнение мы имеем четыре триплета со всеми тремя различными картами. Итак, 4+12+4=20, а это и есть точное число аминокислот, которое мы хотели получить" (Георгий Гамов, англ. George Gamow, 1904-1968г, советский и американский физик-теоретик, астрофизик и популяризатор науки).
Действительно, экспериментами доказано, что для каждой аминокислоты имеется по два обязательных нуклеотида и третий вариабельный, менее специфичный ("эффект качания "). В случае, если брать три символа из четырех, то получится 64 комбинации, что намного перекрывает число аминокислот. Таким образом выяснено, что любая аминокислота кодируется тремя нуклеотидами. Эта тройка получила название кодон . Их, как уже сказано, существует 64 варианта. Три из них не кодируют никакой аминокислоты, это так называемые "нонсенс-кодоны " (франц. non-sens - бессмыслица) или "стоп-кодоны".
Генетический код
Генетический (биологический) код – это способ кодирования информации о строении белков в виде нуклеотидной последовательности. Он предназначен для перевода четырехзначного языка нуклеотидов (А, Г, У, Ц) в двадцатизначный язык аминокислот. Он обладает характерными особенностями:
- Триплетность – три нуклеотида формируют кодон, кодирующий аминокислоту. Всего насчитывают 61 смысловой кодон.
- Специфичность (или однозначность ) – каждому кодону соответствует только одна аминокислота.
- Вырожденность – одной аминокислоте может соответствовать несколько кодонов.
- Универсальность – биологический код одинаков для всех видов организмов на Земле (однако в митохондриях млекопитающих есть исключения).
- Колинеарность – последовательность кодонов соответствует последовательности аминокислот в кодируемом белке.
- Неперекрываемость – триплеты не накладываются друг на друга, располагаясь рядом.
- Отсутствие знаков препинания – между триплетами нет дополнительных нуклеотидов или каких-либо иных сигналов.
- Однонаправленность – при синтезе белка считывание кодонов идет последовательно, без пропусков или возвратов назад.
Однако ясно, что биологический код не может проявить себя без дополнительных молекул, которые выполняют переходную функцию или функцию адаптора .
Адапторная роль транспортных РНК
Транспортные РНК являются единственным посредником между 4-х буквенной последовательностью нуклеиновых кислот и 20-ти буквенной последовательностью белков.
Каждая транспортная РНК имеет определенную триплетную последовательность в антикодоновой петле (антикодон ) и может присоединить только такую аминокислоту, которая соответствует этому антикодону. Именно от наличия того или иного антикодона в тРНК зависит, какая аминокислота включится в белковую молекулу, т.к. ни рибосома, ни мРНК не узнают аминокислоту.
Таким образом, адапторная роль тРНК заключается:
- в специфичном связывании с аминокислотами,
- в специфичном, согласно кодон-антикодоновому взаимодействию, связывании с мРНК,
- и, как результат, во включении аминокислот в белковую цепь в соответствии с информацией мРНК.
Присоединение аминокислоты к тРНК осуществляется ферментом аминоацил-тРНК-синтетазой , имеющей специфичность одновременно к двум соединениям: какой-либо аминокислоте и соответствующей ей тРНК. Для реакции требуется две макроэргические связи АТФ. Аминокислота присоединяется к 3"-концу акцепторной петли тРНК через свою α-карбоксильную группу, и связь между аминокислотой и тРНК становится макроэргической . α-Аминогруппа остается свободной.
Реакция синтеза аминоацил-тРНК
Так как существует около 60 различных тРНК, то некоторым аминокислотам соответствует по две или более тРНК. Различные тРНК, присоединяющие одну аминокислоту, называют изоакцепторными .
ГЕНЕТИЧЕСКИЙ КОД (греч, genetikos относящийся к происхождению; син.: код, биологический код, аминокислотный код, белковый код, код нуклеиновых к-т ) - система записи наследственной информации в молекулах нуклеиновых кислот животных, растений, бактерий и вирусов чередованием последовательности нуклеотидов.
Генетическая информация (рис.) из клетки в клетку, из поколения в поколение, за исключением РНК-содержащих вирусов, передается путем редупликации молекул ДНК (см. Репликация). Реализация наследственной информации ДНК в процессе жизнедеятельности клетки осуществляется через 3 типа РНК: информационную (иРНК или мРНК), рибосомную (рРНК) и транспортную (тРНК), которые с помощью фермента РНК-полимеразы синтезируются на ДНК как на матрице. При этом последовательность нуклеотидов в молекуле ДНК однозначно определяет последовательность нуклеотидов во всех трех типах РНК (см. Транскрипция). Информацию гена (см.), кодирующего белковую молекулу, несет только иРНК. Конечным продуктом реализации наследственной информации является синтез белковых молекул, специфичность которых определяется последовательностью входящих в них аминокислот (см. Трансляция).
Поскольку в составе ДНК или РНК представлено только по 4 разных азотистых основания [в ДНК - аденин (А), тимин (Т), гуанин (Г), цитозин (Ц); в РНК - аденин (А), урацил (У), цитозин (Ц), гуанин (Г)], последовательность которых определяет последовательность 20 аминокислот в составе белка, возникает проблема Г. к., т. е. проблема перевода 4-буквенного алфавита нуклеиновых к-т в 20-буквенный алфавит полипептидов.
Впервые идея матричного синтеза белковых молекул с правильным предсказанием свойств гипотетической матрицы была сформулирована Н. К. Кольцовым в 1928 г. В 1944 г. Эйвери (О. Avery) с соавт, установил, что за передачу наследственных признаков при трансформации у пневмококков ответственны молекулы ДНК. В 1948 г. Чаргафф (E. Chargaff) показал, что во всех молекулах ДНК имеет место количественное равенство соответствующих нуклеотидов (А-T, Г-Ц). В 1953 г. Ф. Крик, Дж. Уотсон и Уилкинс (М. H. F. Wilkins), исходя из этого правила и данных рентгеноструктурного анализа (см.), пришли к выводу, что молекул а ДНК представляет собой двойную спираль, состоящую из двух полинуклеотидных нитей, соединенных между собой водородными связями. Причем против А одной цепи во второй может находиться только Т, против Г - только Ц. Эта комплементарность приводит к тому, что последовательность нуклеотидов одной цепи однозначно определяет последовательность другой. Второй существенный вывод, вытекающий из этой модели,- молекула ДНК способна к самовоспроизведению.
В 1954 г. Гамов (G. Gamow) сформулировал проблему Г. к. в ее современном виде. В 1957 г. Ф. Крик высказал Гипотезу адаптера, предположив, что аминокислоты взаимодействуют с нуклеиновой к-той не непосредственно, а через посредников (теперь известных под названием тРНК). В ближайшие после этого годы все принципиальные звенья общей схемы передачи генетической информации, вначале гипотетичные, были подтверждены экспериментально. В 1957 г. были открыты иРНК [А. С. Спирин, А. Н. Белозерский с соавт.; Фолькин и Астрахан (E. Volkin, L. Astrachan)] и тРНК [Хоугленд (М. В. Hoagland)]; в 1960 г. синтезирована ДНК вне клетки с использованием в качестве матрицы существующих макромолекул ДНК (А. Корнберг) и открыт ДНК-зависимый синтез РНК [Вейсс (S. В. Weiss) с соавт.]. В 1961 г. была создана бесклеточная система, в к-рой в присутствии естественной РНК или синтетических полирибонуклеотидов осуществлялся синтез белковоподобных веществ [М. Ниренберг и Маттеи (J. H. Matthaei)]. Проблема познания Г. к. состояла из исследования общих свойств кода и собственно его расшифровки, т. е. выяснения, какие комбинации нуклеотидов (кодоны) кодируют определенные аминокислоты.
Общие свойства кода были выяснены независимо от его расшифровки и в основном до нее путем анализа молекулярных закономерностей образования мутаций (Ф. Крик и соавт., 1961; Н. В. Лучник, 1963). Они сводятся к следующему:
1. Код универсален, т. е. идентичен, по крайней мере в основном, для всех живых существ.
2. Код триплетен, т. е. каждая аминокислота кодируется тройкой нуклеотидов.
3. Код неперекрывающийся, т. е. данный нуклеотид не может входить в состав более чем одного кодона.
4. Код вырожден, т. е. одна аминокислота может кодироваться несколькими триплетами.
5. Информация о первичной структуре белка считывается с иРНК последовательно, начиная с фиксированной точки.
Прямая расшифровка кода состояла бы в сравнении последовательности нуклеотидов в структурном гене (или синтезированной на нем иРНК) с последовательностью аминокислот в соответствующем белке. Однако такой путь пока технически невозможен. Были применены два других пути: синтез белка в бесклеточной системе с использованием в качестве матрицы искусственных полирибонуклеотидов известного состава и анализ молекулярных закономерностей образования мутаций (см.). Первый принес положительные результаты раньше и исторически сыграл в расшифровке Г. к. большую роль.
Основные данные о Г. к. in vivo получены при анализе аминокислотного состава белков у организмов, обработанных мутагенами (см.) с известным механизмом действия, напр, азотистой к-той, к-рая вызывает в молекуле ДНК замену Ц на У и А на Г. Полезную информацию дают также анализ мутаций, вызванных неспецифическими мутагенами, сравнение различий в первичной структуре родственных белков у разных видов, корреляция между составом ДНК и белков и т. п.
Расшифровка Г. к. на основании данных in vivo и in vitro дала совпадающие результаты. Позже были разработаны три других метода расшифровки кода в бесклеточных системах: связывание аминоацил-тРНК (т. е. тРНК с присоединенной активированной аминокислотой) тринуклеотидами известного состава (М. Ниренберг и соавт., 1965), связывание аминоацил-тРНК полинуклеотидами, начинающимися с определенного триплета (Маттеи с соавт., 1966), и использование в качестве иРНК полимеров, в которых известен не только состав, но и порядок нуклеотидов (X. Корана и соавт., 1965). Все три метода дополняют друг друга, а результаты находятся в соответствии с данными, полученными в опытах in vivo.
В 70-х гг. 20 в. появились методы особенно надежной проверки результатов расшифровки Г. к. Известно, что мутации, возникающие под действием профлавина, состоят в выпадении или вставке отдельных нуклеотидов, что приводит к сдвигу рамки считывания. У фага Т4 был вызван профлавином ряд мутаций, при которых изменился состав лизоцима. Этот состав был проанализирован и сопоставлен с теми кодонами, которые должны были получиться при сдвиге рамки считывания. Получилось полное соответствие. Дополнительно этот метод позволил установить, какие именно триплеты вырожденного кода кодируют каждую из аминокислот. В 1970 г. Адамсу (J. М. Adams) с сотрудниками удалось провести частичную расшифровку Г. к. прямым методом: у фага R17 определили последовательность оснований во фрагменте длиной в 57 нуклеотидов и сравнили с аминокислотной последовательностью белка его оболочки. Результаты полностью совпали с полученными менее прямыми методами. Т. о., код расшифрован полностью и верно.
Нонсенс-кодоны, 2 из которых имеют специальные названия, соответствующие обозначению фаговых мутантов (УАА-охра, УАГ-амбер, УГА-опал), хотя и не кодируют каких-либо аминокислот, но имеют большое значение при считывании информации, кодируя конец полипептидной цепи.
Считывание информации происходит в направлении от 5 1 -> 3 1 - к концу нуклеотидной цепи (см. Дезоксирибонуклеиновые кислоты). При этом синтез белка идет от аминокислоты со свободной аминогруппой к аминокислоте со свободной карбоксильной группой. Начало синтеза кодируется триплетами АУГ и ГУГ, которые в этом случае включают специфичную стартовую аминоацил-тРНК, а именно N-формилметио-нил-тРНК. Эти же триплеты при локализации внутри цепи кодируют соответственно метионин и валин. Неоднозначность снимается тем, что началу считывания предшествует нонсенс. Есть данные, говорящие в пользу того, что граница между участками иРНК, кодирующими разные белки, состоит более чем из двух триплетов и что в этих местах меняется вторичная структура РНК; этот вопрос находится в стадии исследования. Если нонсенс-кодон возникает внутри структурного гена, то соответствующий белок строится только до места расположения этого кодона.
Открытие и расшифровка генетического кода - выдающееся достижение молекулярной биологии - оказало влияние на все биол, науки, положив в ряде случаев начало развитию специальных крупных разделов (см. Молекулярная генетика). Эффект открытия Г. к. и связанных с ним исследований сравнивают с тем эффектом, который оказала на биол, науки теория Дарвина.
Универсальность Г. к. является прямым доказательством универсальности основных молекулярных механизмов жизни у всех представителей органического мира. Между тем большие различия в функциях генетического аппарата и его строении при переходе от прокариотов к эукариотам и от одноклеточных к многоклеточным, вероятно, связаны и с молекулярными различиями, исследование которых - одна из задач будущего. Поскольку исследования Г. к.- дело лишь последних лет, значение полученных результатов для практической медицины носит лишь Косвенный характер, позволяя пока понять природу заболеваний, механизм действия возбудителей болезней и лекарственных веществ. Однако открытие таких явлений, как трансформация (см.), трансдукция (см.), супрессия (см.), указывает на принципиальную возможность исправления патологически измененной наследственной информации или ее коррекции - так наз. генная инженерия (см.).
Введение
В качестве объекта анализа выбран генетический код (ГК). С любопытным примером использования ГК в области информационной защиты (по-видимому непрофессиональной и потому не успешной) можно познакомиться здесь.
В этой работе займемся подробно анализом очень важного Генетического кода, который создан не разумом человека, а самой природой (редкий случай).
История одного открытия и Нобелевская премия
Зададимся вопросом, как природой на уровне генетики и метаболизма организмов (клеток) реализованы такие положения информационного обмена в жизнедеятельности видов и их отдельных представителей?
Научному миру еще до Второй мировой войны было известно, что у живых организмов передача от поколения к поколению наследственных признаков осуществляется через относительно простые химические единицы (гены), включающие огромное количество информации, необходимой для продолжения и воспроизводства жизни.
Все гены (не являются белками) связываются в цепочки (хромосомы) и материализуются в дезоксирибонуклеиновой кислоте (ДНК). У специалистов не было ясности в том, как все происходит и как устроена сама ДНК.
Эта спираль ДНК – носитель генетического кода – кода наследственности признаков организмов животных и растений. Это была совершенно необычная новая работа о строении и свойствах молекулы дезоксирибонуклеиновой кислоты.
Модель ДНК молодых авторов получила подтверждение при сопоставлении ее с рентгеновской дифракционной картиной кристаллической структуры ДНК английского биофизика Мориса Уилкинса. Позднее был открыт генетический код, содержащий и передающий информацию о синтезе структуры и состава белков – основных составляющих каждой клетки живых организмов, реализующей клеточный цикл.
Определение. Клеточный цикл — правильное чередование периодов относительного покоя с периодами деления клетки.
Они располагали информацией о следующих фактах:
Действительно, после 1960 года было показано, что кодоны, считавшиеся Криком бессмысленными, в пробирке реализовывали белковый синтез, а к 1965 году был установлен смысл всех 64 кодонов-триплетов. Выяснилось также, что ряд аминокислот кодируется двумя, тремя, четырьмя и даже шестью разными триплетами, т. е. имеет место определенная избыточность, назначение которой еще предстоит определить.
Генетический код жизни. Наследственная информация
Определение. Генетический код – множество слов, задающих способ кодирования цепочками нуклеотидов (букв алфавита А, G, C, T), последовательности аминокислот синтеза белков, свойственных всем живым организмам. Цепочки триплетов (кодовых слов) образуют хромосомы – носители наследственной информации. Каждому виду живых организмов соответствует свой хромосомный набор. Этот способ кодирования универсален и реализуется в каждой клетке растительного и животного организма при ее делении.
Классическое представление информации (линейность ее записи) – это тексты в широком понимании (речь, письма, книги, изображения, фильмы, музыка и т. п.) этого слова в некотором естественном языке (ЕЯ). Язык включает обширный словарь (лексику), а если ЕЯ кроме устной речи имеет письменность, то и алфавит с грамматикой.
Процессы и пути переноса информации, записанной на естественных её носителях-молекулах, сформулированы Ф. Криком (1958 г.) в форме центральной догмы молекулярной биологии. Три основных процесса обеспечивают управление всеми остальными процессами функционирования клетки и жизни организмов в целом.
Эти процессы: репликация, транскрипция и трансляция. Далее о них будет сказано более подробно. Информация в организмах передается только в одном направлении от нуклеиновых кислот (ДНК → РНК →белок) к белку, обратной передачи не существует. Возможны особые случаи ДНК → белок, РНК→ РНК, РНК → ДНК.
Определение. Рамкой считывания (открытой) называется последовательность неперекрывающихся кодонов, способная синтезировать белок, начинающаяся со старт-кодона и завершающаяся стоп-кодоном. Рамка определяется самым первым триплетом, с которого начинается трансляция.
Для начала трансляции старт-кодона недостаточно, необходим ещё инициационный кодон (их три: AUG, GUG, UUG). После его считывания трансляция идет путем последовательного считывания кодонов рибосомальной рРНК и присоединения аминокислот друг к другу рибосомой до достижения стоп-кодона.
Эти факты обобщаются в таблице способов передачи генетической информации.

Таблица 1 – Центральная догма молекулярной биологии
История изучения текстов наследственности организмов, их осмысления, длительная, богатая открытиями, достижениями, заблуждениями и разочарованиями. Перечень событий истории постижения (познания) текстов природы представляет несомненный интерес, как для науки, так и для каждого отдельного человека.
Биологами установлено, что каждое слово текста наследственности образовано полимерной молекулой ДНК (дезоксирибонуклеиновой кислоты, открытой в 1868 г. врачом И. Ф. Мишером), построенной из 4-х оснований (нуклеотидов – от nuclear — ядерный).
Основания скрепляются (соединяются) между собой в пары, А ←→ Т, Т←→ А, G ←→ C, С ←→ G особыми водородными связями, реализующими принцип дополнительности (комплементарности). Эти факты устанавливались в разное время, разными учеными и методами многих наук (физики, химии, биологии, цитологии, генетики и др.). Сложности на пути познания этого ЕЯ встречались постоянно.
Молекулы ДНК не кристаллизовались, но когда это удалось сделать, то задача установления структуры ДНК свелась к решению обратной задачи рентгеноструктурного анализа (преобразованием Фурье дифракционной картины кристалла, созданной на экране рентгеновскими лучами).
Эта модель практически подтвердила многообразные гипотезы теоретиков и убедительно доказала отсутствие расхождений с практическими экспериментами и результатами рентгеноструктурного анализа кристаллической ДНК.

С позиций математики четырем буквам алфавита можно приписать четыре элемента конечного расширенного поля Галуа GF(2 2 ) = (0, 1, α, β), операции с которыми выполняются по модулю неприводимого многочлена р(х) = х 2 + х + 1. Тогда α + β = 1, α∙β = 1 и сопоставление элементов поля буквам принимает вид
, а дополнительный (комплементарный) нуклеотид вычисляется по правилу ¬х → х + 1, откуда Т → А + 1, С → G + 1.
Т А G G T T C G Т …
A T C C A A G C A …
Две цепи повторяют последовательность букв, но начало одной расположено напротив конца другой. Информация в молекулах ДНК записывается с большой степенью избыточности, что, конечно, обеспечивает высокий уровень надежности при считывании информации и ее копировании (репликации: ДНК → ДНК). К исходному слову приписывается еще одно, но в дополнительном коде.
Определение. Ген (греч.γενοζ – род). Структурная и функциональная единица наследственности живых организмов. Гены (точнее аллели) определяют наследственные признаки организмов, передающиеся от родителей потомству при размножении.
В словах ДНК можно выделить и рассматривать отдельные части-подслова (гены), которые несут целостную информацию о строении одной молекулы белка или одной молекулы РНК. Кроме того, гены характеризуются регуляторными последовательностями (промоторами).
Каждый ген предназначен и отвечает за создание определенного белка, необходимого для жизнедеятельности организма. Понятием генотип обозначается наследственная конституция гамет (половых клеток) и зигот (соматических клеток) в отличие от фенотипа, описывающего благоприобретенные признаки, которые по наследству не передаются.
Блоковые коды
При формировании кодовых слов используется однозначное отображение конечного упорядоченного множества символов, принадлежащих некоторому конечному алфавиту, на иное, не обязательно упорядоченное, как правило, более обширное множество символов для кодирования передачи, хранения или преобразования информации
Перечислим свойства рассматриваемого генетического кода (ГК):
- Универсальность. Общность кода для всего живого мира. Универсальность подтверждена экспериментами по синтезу белков in Vitro (в пробирке). В бесклеточную систему одного организма (животного) помещали мРНК другого (растительного) и при этом реализовывался белковый синтез.
- Полярность. Однонаправленность считывания генов ДНК, РНК.
- Триплетность. Значащей единицей ГК является триплет или кодон. Три нуклеотида (буквы алфавита) – кодон, триплет, кодовое слово.
Г. Гамовым было высказано предположение о триплетности кода. Поскольку речь идет о 4-х нуклеотидах, образующих алфавит, и о 20 аминокислотах, используемых при синтезе белков, каждая из них должна в качестве прообраза иметь одно (или более) синтезирующее ее слово.
Свойство связано с избыточностью. Состав каждого слова из 64 возможных был установлен лишь в 1965 году на основе многочисленных опытов. Выяснилось, что избыточность числа слов при синтезе некоторых белков используется природой для надежности правильности считывания информации. В итоге получилось, что каждая аминокислота кодируется разным числом триплетов (кодонов). Свойство кода назвали вырожденностью.

Таблица 2 — Количественные соотношения триплетов и аминокислот
Формирование кода предполагает выбор алфавита, определение регулярности, а при выборе регулярного кода, определение длины кодового слова, определение количества кодовых слов, определение побуквенного состава каждого слова.

Таблица 3 — Генетический код состоит из 64 кодовых слов из 3-х букв каждое

Таблица 4 — Обратные значения кодовой последовательности триплетов РНК
Дополнительные свойства кода, например, код не должен иметь запятой, определяются более жесткими требованиями к названным параметрам кода. Код без запятой должен иметь слова с максимальным периодом. Такие требования ориентированы на удобство последующего синтеза кодека. С этими положениями синтеза кода тесно связаны вопросы кодирования информации и ее декодирования.
Анализ кода
Собственно, сама система кодирования также доступна для наблюдения и изучения, но уровень сложности ее построения и функционирования не позволяет получить полное качественное и достоверное описание.
Определение. Процесс установления позиции, содержащей стартовый (начальный) символ кодового слова, называется синхронизацией.
Задача синхронизации просто решается, если в алфавите используется специальный символ-разделитель слов, например, запятая. Рамка считывания очередного кодового слова устанавливается непосредственно за разделителем.
Такой разделитель удобен, но нежелателен по нескольким причинам.
Для лучшей различимости слов кода они в полном списке возможных слов должны быть удалены одно от другого на некоторое расстояние, т.е. различаться составом значений символов, как векторы векторного пространства компонентами.
Следовательно, кодовыми словами могут быть не все и не любые слова множества Х n , а только лишь некоторое их подмножество D є Х n . Выбор символьного состава слов кода и представляет основную задачу его формирования, так как именно состав слов кода должен обеспечивать удовлетворение сформулированным требованиям к коду. Таким образом, будем далее рассматривать код без запятой.
Синхронизация кода без запятой. Покажем здесь, как может быть обеспечена однозначность синхронизации кода без запятой. Выберем два триплета кодовых слова вида х = (х1, х2, …, хn) и у = (у1, у2, …, уn). Образуем их конкатенацию х||у = (х1, х2, …, хn, у1, у2, …, уn). Эта конкатенация из двух слов позволяет породить еще n – 1 слово множества Х n путем многократных циклических сдвигов на одну позицию влево и выделения первых n символов сдвинутой последовательности. Введем важное понятие перекрытия пары слов.
Определение. При циклических сдвигах символов на шаг получаются слова вида (х2, …, хn, у1), (х3, …, хn, у1, у2)…( хn, у1,…, уn-2, уn-1), которые называются перекрытиями пары слов х и у.
Покажем, как это осуществляется. Пусть в принятой последовательности символов выбран и зафиксирован некоторый символ. Отсчитав n символов от фиксированного, декодер сопоставляет слово, которое получилось, со словами кодового списка. Если имеет место совпадение с одним из слов кодового списка, то синхронизация установлена. Фиксированный символ и его позиция стартовые.
Если совпадения нет ни с одним из слов списка кода, т. е. попали на слово-перекрытие, то это означает, что стартовая позиция расположена левее фиксированной позиции.
Сдвигаемся влево на одну позицию от фиксированной и повторяем действия предыдущего шага до тех пор, пока не получим на некотором шаге совпадения с одним из кодовых слов. Этот процесс обязательно имеет успешное завершение в правильной стартовой позиции, т. е. синхронизация в среднем устанавливается за число n/2 шагов.
Определение. Блоковым кодом без разделителя (запятой) называется подмножество D є Х n слов длины n в алфавите Х таких, что для любых двух кодовых слов х, у єD все перекрытия для них не являются кодовыми словами.
Мы уже установили, что такой код обеспечивает правильную синхронизацию в длинных цепочках кодовых слов без разделителей между ними. Какие же слова из множества Х n включаются в подмножество D є Х n ? Если мощность множества Х n делится на целые числа, то мощность D может быть одним из таких делителей (теорема Лагранжа о группах) и код при этом называется групповым блоковым кодом без запятой.
Состав символов в словах кода пока остается не установленным, так же, как и количество слов в D. Очевидно, что выбор конкретного подмножества D из Х n имеет много вариантов (сочетаний из Х n по D), из которых только немногие или возможно единственный удовлетворяет всем требованиям к коду без запятой. Нами рассмотрено одно из важных требований о перекрытиях, и это свойство слов кода может быть использовано в качестве фильтра для отсеивания непригодных вариантов при выборе D.
Перейдем к решению вопроса о числе слов в формируемом коде.
Мощность кода без запятой. Будем отыскивать наибольшее из возможных число слов в коде D, которое обозначим символом |D| = Wn(q). Точное значение получить не удается, но оценку сверху для количества слов получить возможно, используя понятие периода слова. Обозначим символом Т k х циклический сдвиг слова длиной n на k шагов, k k х = х и d ≤ n, d | n. Слова максимального периода d = n называются полноцикловыми (основными). Код без запятой включает в свой состав только полноцикловые слова.
Действительно, пусть кодовое слово х = (х1, х2, х3, х1, х2, х3 ) имеет период d
Как вы знаете, признаки и свойства каждого организма определяются прежде всего белками, которые синтезируются в его клетках. Белки выполняют самые разнообразные функции (вспомните какие), обеспечивая тем самым протекание процессов жизнедеятельности. Можно сказать, что именно от этих биополимеров в первую очередь и зависит существование организма. Однако время функционирования белков, как и многих других биомолекул, весьма ограничено. Поэтому синтез белков в организме должен осуществляться непрерывно. Этот процесс протекает во всех клетках одноклеточных и многоклеточных организмов.
Вам также известно, что хранителем наследственной (генетической) информации, т. е. информации о первичной структуре белков, является ДНК. Участок молекулы ДНК, содержащий информацию о первичной структуре одного белка, получил название ген. Кроме того, генами называют участки ДНК, хранящие информацию о строении молекул рРНК и тРНК.
В биосинтезе белков, который осуществляется в рибосомах, ДНК прямого участия не принимает. Передача генетической информации, содержащейся в ДНК, к месту синтеза белка происходит с помощью посредника. Этим посредником является матричная (информационная) РНК (мРНК, иРНК), которая синтезируется на одной из цепей молекулы ДНК по принципу комплементарности.
Генетический код обладает следующими свойствами.
Таблица 23.1. Генетический код , указаны нуклеотиды мРНК (иРНК)
(первый нуклеотид триплета берут из левого вертикального ряда, второй — из горизонтального ряда,
третий — из правого вертикального)
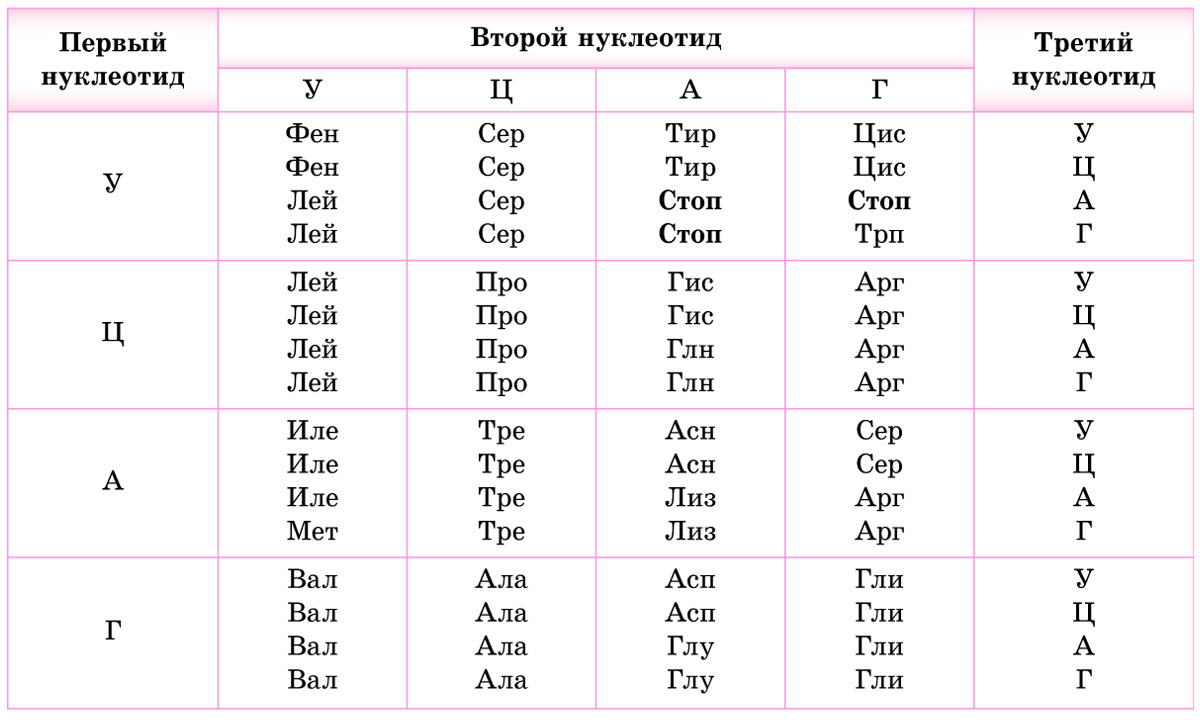
Обратите внимание, что 3 из 64 кодонов (в молекулах мРНК — УАА, УАГ и УГА) не кодируют аминокислоты. Это так называемые стоп-кодоны *или нонсенс-кодоны (от англ. nonsense — бессмыслица)*, они служат сигналом окончания синтеза белка. *Остальные триплеты называются смысловыми.*
* Генетический код расшифровали американские биохимики Р. Холли, Х. Г. Корана и М. Ниренберг в середине прошлого века. Работа стартовала в 1961 г. В бесклеточные системы, содержащие все необходимые компоненты для синтеза белка (рибосомы, аминокислоты, тРНК и др.), ученые сначала вводили искусственно синтезированные мРНК, состоящие только из одного типа нуклеотидов. Было выяснено, что в присутствии, например, полицитидиловой мРНК (ЦЦЦЦЦЦ. ) синтезируется полипептид, состоящий только из остатков аминокислоты пролина, в присутствии полиуридиловой (УУУУУУ. ) — из фенилаланина. Стало понятно, что кодону ЦЦЦ соответствует пролин, а триплет УУУ кодирует фенилаланин. К 1965 г., благодаря использованию искусственно синтезированных молекул мРНК с известными повторяющимися последовательностями нуклеотидов, удалось расшифровать все остальные триплеты. В 1968 г. это открытие было удостоено Нобелевской премии.*
2. Код однозначен — каждый триплет кодирует только одну аминокислоту.
3. Как уже отмечалось, число триплетов превышает количество кодируемых аминокислот. Поэтому генетический код является избыточным (вырожденным) — одна и та же аминокислота может кодироваться разными триплетами. Например, в мРНК цистеин (Цис) может быть закодирован триплетом УГУ или УГЦ, треонин (Тре) — АЦУ, АЦЦ, АЦА или АЦГ. Некоторые аминокислоты, например лейцин (Лей), кодируются шестью различными триплетами, в то же время метионину (Мет) и триптофану (Трп) соответствует только по одному кодону (проверьте по таблице генетического кода).
4. Код не перекрывается — один и тот же нуклеотид не может одновременно входить в состав двух соседних триплетов.
5. Код непрерывен. В полинуклеотидной цепи нуклеотиды располагаются непрерывно и соседние триплеты ничем не отделены друг от друга. Это значит, что фактически деление на триплеты условно — все зависит от того, с какого именно нуклеотида начинается их считывание. Поэтому в клетках считывание информации, содержащейся в генах, всегда начинается со строго определенного нуклеотида.
Если в составе гена происходит изменение количества нуклеотидов (их выпадение или вставка) на число, не кратное трем, наблюдается так называемый сдвиг рамки считывания (рис. 23.1). Это прив одит к существенному изменению последовательности аминокислот в белке, который кодируется измененным геном. В некоторых случаях сдвиг рамки считывания приводит к возникновению стоп-кодонов, из-за чего синтез белка обрывается.
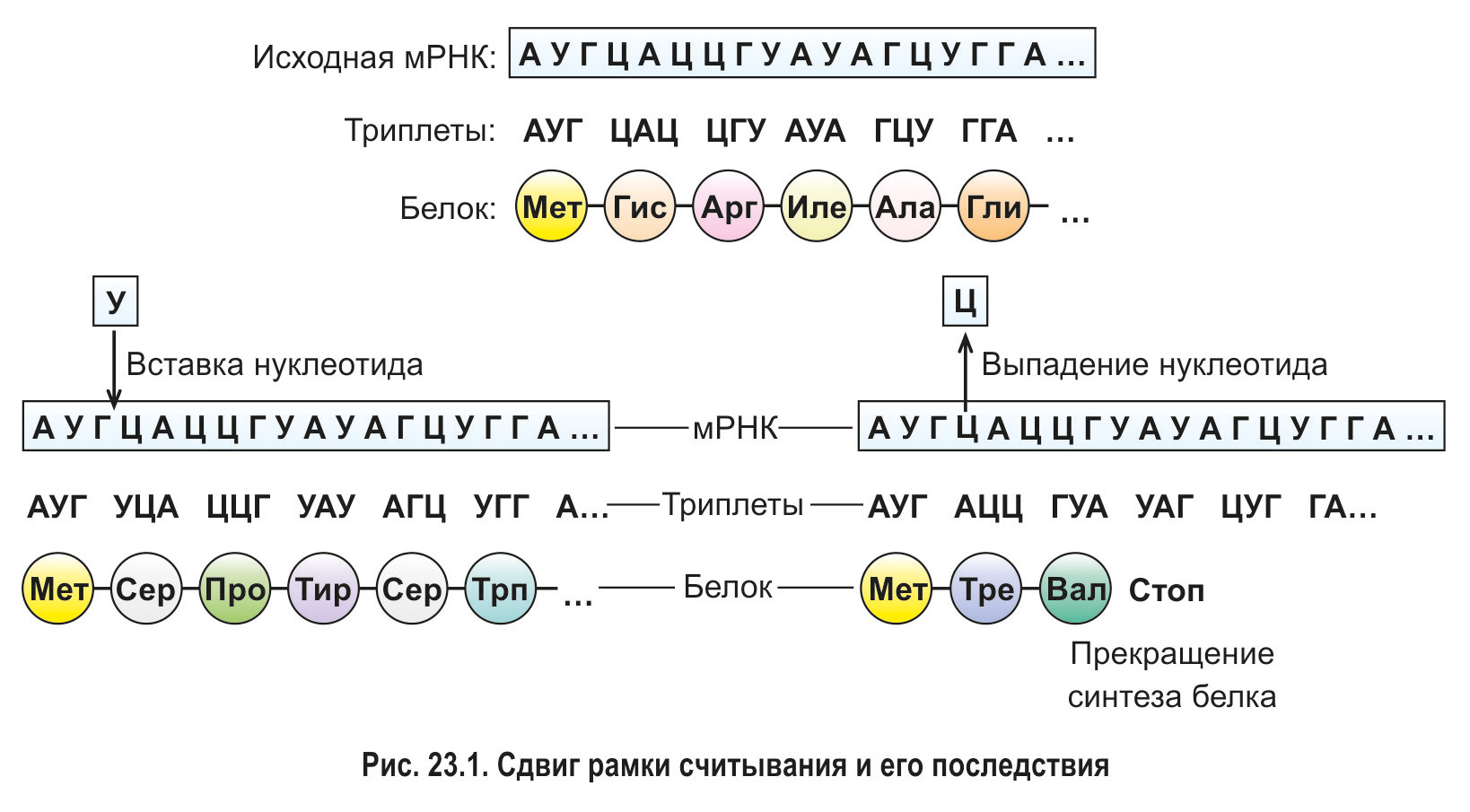
*Суть происходящего при сдвиге рамки считывания можно понять на следующем примере. Прочитайте предложение, составленное из трехбуквенных слов (аналогично триплетам):
ЖИЛ БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ.
В этом предложении заключен определенный смысл, понять который можно и без знаков препинания. Выпадение одной буквы аналогично выпадению одного нуклеотида. Оно приводит к изменению порядка считывания и потере смысла:
ЖЛБ ЫЛК ОТТ ИХБ ЫЛС ЕРМ ИЛМ НЕТ ОТК ОТ — выпадение второй буквы.
То же самое произошло бы и после вставки лишней буквы. В случае замены одной буквы либо при изменении их количества на три смысл предложения меняется не столь значительно. Например:
ЖИВ БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — замена третьей буквы;
БЫЛ КОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — выпадение первых трех букв.
Однако смысл предложения (в нашей аналогии — первичная структура белка) во многом зависит от положения измененных букв (нуклеотидов). Так, смысл может существенно исказиться:
ЖИЛ БОТ ТИХ БЫЛ СЕР МИЛ МНЕ ТОТ КОТ — выпадение пятой, шестой и седьмой букв.
Аналогичная ситуация наблюдается и с белками. В зависимости от расположения замененной (утраченной, добавленной) аминокислоты молекула белка может сохранить пространственную конфигурацию и функции, частично изменить их или же полностью утратить свои исходные характеристики.*
Как уже отмечалось, правильное считывание генетической информации обеспечивается только тогда, когда оно начинается со строго определенной позиции. У эукариот стартовым кодоном молекулы мРНК является триплет АУГ. Именно с него и начинается считывание.
6. Код универсален — у всех живых организмов одним и тем же триплетам соответствуют одни и те же аминокислоты. Иными словами, у всех организмов генетический код расшифровывается одинаково (за редким исключением). Это свидетельствует о единстве происхождения живых организмов.
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам

Описание презентации по отдельным слайдам:
Генетический код Биология. 10 класс

Наследственная информация записана в молекулах НК в виде последовательности нуклеотидов. Определенные участки молекулы ДНК и РНК (у вирусов и фагов) содержат информацию о первичной структуре одного белка и называются генами. 1 ген = 1 молекула белка Поэтому наследственную информацию, которую содержат ДНК называют генетической.

Для краткости каждый нуклеотид обозначается русской или латинской заглавной буквой, с которой начинается название азотистого основания, входящего в его состав: -А (A) — аденин, -Г (G) — гуанин, -Ц (C) — цитозин, в ДНК Т (T) — тимин, в РНК У (U) — урацил.

Расшифровка кода генетического, т. е. нахождение соответствия между кодонами и аминокислотами, осуществлена американскими биохимиками М. У. Ниренбергом, С. Очоа и др. в 1961-65.


Свойства генетического кода

Одна аминокислота закодирована тремя нуклеотидами (один кодон или триплет). Пример: АК триптофан закодирована в РНК УГГ, в ДНК - АЦЦ. АЦТ АГЦ ГАТ Триплет, кодон ген АК1 АК2 АК3 белок Триплетность

Имеется 64 кодона: 61 кодон кодирует 20 (21) аминокислот, три кодона являются знаками препинания: кодоны-терминаторы УАА, УАГ, УГА (в РНК). А Т Ц Г 43

Избыточность кода Каждая АК шифруется более, чем одним кодоном (от двух до шести). Аргинину соответствуют триплеты: ГЦА, ГЦТ, ГЦЦ. Случайная замена третьего нуклеотида не отразится на структуре синтезируемого белка.

Специфичность Каждый кодон шифрует только одну АК эритроциты - двояковогнутые диски, содержат гемоглобин. Норма: 6-е место – глу Патология – вал Гемоглобин - белок 1 молекула = 4 полимера 1 полимер = 574 АК При изменении молекулы белка изменяется свойство гемоглобина, возникает наследственное заболевание: серповидно-клеточная анемия.

Внутри генов знаков препинания нет Жил был пёс тих был сер мил мне тот пёс Илб ылп ёст ихб ылс ерм илм нет отп ёс

Универсальность Генетический код един для всех живущих на Земле существ У бактерий и грибов, пшеницы и хлопка, рыб и червей, лягушки и человека…

РЕШЕНИЕ ЗАДАЧ ПО МОЛЕКУЛЯРНОЙ БИОЛОГИИ

Задача 1. К имеющейся цепи триплетов азотистых оснований ДНК достройте: - - недостающую цепь, - к полученному фрагменту цепь иРНК, - определите последовательность АК ААТ – ТТА – ААЦ – АГА – ГГА – ТТЦ – ГЦА – АЦГ – ГГА – ААА

Решение ДНК1: ААТ–ТТА–ААЦ–АГА–ГГА–ТТЦ–ГЦА–АЦГ–ГГА–ААА ДНК2: ТТА–ААТ–ТТГ–ТЦТ–ЦЦТ–ААГ–ЦГТ–ТГЦ–ЦЦТ-ТТТ иРНК: ААУ–УУА–ААЦ–АГА–ГГА–УУЦ–ГЦА–АЦГ–ГГА–ААА АК: асн– лей– асн– арг– гли– фен– ала– тре– гли– лиз

Задача 2. Фрагмент молекулы миоглобина имеет следующие АК: вал-ала-глу-тир-сер-глн. Определите один из возможных вариантов строения молекулы ДНК, кодирующей эту последовательность АК.

Решение Один из возможных вариантов молекулы ДНК следующий: ЦАА ЦГА ЦТТ АТА АГА ГТТ

ЗАДАЧА 3. Участок одной цепи ДНК имеет следующую последовательность нуклеотидов: ГГААЦАЦТАГТТААААТАЦГТ… Какова последовательность АК в белке, соответствующем этой генетической информации? ЗАДАЧА 4. Участок одной нити ДНК имеет такую структуру: Укажите структуру соответствующей молекулы белка, синтезированного при участии комплементарной цепи. Как изменится первичная структура фрагмента белка, если выпадет второй от начала нуклеотид? ЗАДАЧА 5. Напишите один из возможных вариантов последовательности нуклеотидов в обеих цепях фрагмента молекулы ДНК, если кодируемый белок имеет следующую первичную структуру: ала-тре-лиз-асн-сер-глн-глу-асп…

Домашнее задание С. 110-111, записи в тетради (прочитать, проработать) Решить задачи: 1. К имеющемуся фрагменту молекулы ДНК достройте вторую цепь, а затем напишите последовательность аминокислот, закодированных триплетами на основе данных второй цепи, предполагая, что каждый триплет кодирует лишь одну аминокислоту. ГАГ – ГГА – ТАТ – ТТГ – ТТТ – ГГТ – АТЦ – ЦЦТ – ЦАЦ – ГАЦ – ЦГА 2. К имеющейся последовательности аминокислот постройте фрагмент молекулы информационной РНК, которая могла бы кодировать данные аминокислоты, предполагая, что каждая аминокислота закодирована лишь одним триплетом азотистых оснований. три – фен – про – мет – лей – лиз – иле – глу – глн – гли – арг – асп – асн
Читайте также: