
Конвейерная обработка данных сообщение
Обновлено: 15.05.2024
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам
Конвейерная обработка команд
При отсутствии конвейера процессор выполняет программу, по очереди выбирая из памяти и активизируя ее команды.
Процесс обработки команды может быть разбит, например, на следующие шаги (этапы): выборка- чтение команды из памяти, декодирование, формирование адресов и выборка операндов, выполнение заданной в команде операции, запись результата.
Каждый из этих этапов называется микрокомандой. Каждая операция требует для своего выполнения времени, равного такту генератора процессора. Все этапы команды задействуются только один раз и всегда в одном и том же порядке: одна за другой. Это, в частности, означает, что если первая микрокоманда выполнила свою работу и передала результаты второй, то для выполнения текущей команды она больше не понадобится, и, следовательно, может приступить к выполнению следующей команды.
Конвейеризация осуществляет многопоточную параллельную обработку команд, так что в каждый момент одна из команд считывается, другая декодируется и т. д., и всего в обработке одновременно находится пять команд. Таким образом, на выходе конвейера на каждом такте процессора появляется результат обработки одной команды (одна команда в один такт). Первая инструкция может считаться выполненной, когда завершат работу все пять микрокоманд.
Такая технология обработки команд носит название конвейерной обработки. Каждая часть устройства называется ступенью конвейера, а общее число ступеней — длиной линии конвейера.
С ростом числа линий конвейера и увеличением числа ступеней на линии увеличивается пропускная способность процессора при неизменной тактовой частоте. Процессоры с несколькими линиями конвейера получили название суперскалярных. Pentium — первый суперскалярный процессор intel . Здесь две линии, что позволяет ему при одинаковых частотах быть вдвое производительней i 80486, выполняя сразу две инструкции за такт.
Во многих вычислительных системах, наряду с конвейером команд, используются конвейеры данных.
Архитектурные особенности процессоров вычислительных машин: подходы к решению проблемы обработки команд переходов. Определение адреса операндов в памяти. Арифметико-логические устройства. Пропускная способность процессора с помощью конвейеризации.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 12.05.2014 |
| Размер файла | 106,0 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
1. Использование конвейеризации вычислений
2. Архитектурные особенности процессоров вычислительных машин: подходы к решению проблемы обработки команд переходов
3. Методы предсказания переходов
Список использованной литературы
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием "совмещение операций", при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи. архитектурный процессор конвейеризация
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Так обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
1. Использование конвейеризации вычислений
Важным элементом архитектуры, появившимся в i486, является конвейер - специальное устройство, реализующее обработку команд внутри процессора в несколько этапов. Вышеупомянутый конвейер имеет 5-ти ступенчатый конвейер. Соответствующие этапы включают:
- выборку команд из кэш-памяти или оперативной памяти;
- генерацию адреса, в процессе которой определяются адреса операндов в памяти;
- выполнение операции с помощью АЛУ (арифметико-логического устройства);
- запись результатов (адрес определяется конкретной машинной командой).
Каждому этапу соответствует своя схема в составе конвейера. Поэтому, когда после выборки команда поступает в блок декодирования, блок выборки оказывается свободным и может обрабатывать следующую команду. Таким образом, на конвейере могут находиться в разной стадии выполнения 5 команд, в результате чего возрастает скорость обработки отдельной команды.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунке 1 показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и, соответственно, пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.
Рис. 1 Блоки прохождения команды в процессоре
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие - образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд - естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд - разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (табл. 1).
Таблица 1 Суперконвейерные процессоры
Микропроцессоры, имеющие один конвейер называются скалярными, а более одного - суперскалярными. Микропроцессор Pentium имеет два конвейера, и поэтому может выполнять 2 команды за машинный такт.
Конвейеризация - один из первых архитектурных приемов совершенствования процессов радикально отразившийся на производительности.
Конвейеризация вычислений заключается в следующем: каждая последующая команда начинает выполнение сразу же после прохождения 1-ой ступени конвейера предыдущей команды. Конвейерная работа процессора заключается в разбивке каждой команды на несколько ступеней. По очередности тактового импульса каждая команда перемещается на следующую ступень. Выполненная команда покидает процессор, а новая поступает в него.
Максимальное время выполнения самых продолжительных операций - Tmax. Очередная порция данных может поступать в входной регистр с интервалом не меньше Tmax. Если распределить функции выполняемые функциональным блоком между несколькими последовательными независимыми блоками ФБi с учетом того что каждый из них выполняет операции за временной интервал Tmax/n, где n - число блоков, можно получить заметный выигрыш в скорости появления (поступления) результатов на выходной регистр.
Распределение функций между блоками выполняется так, что время на их реализацию у всех блоков одинаковое и составляет Tmax/3. Между функциональными блоками размещаются буферные регистры, предназначенные для хранения результатов операций выполненных блоком ФБi в случае если следующий за ним блок ФБi+1 еще не завершил выполнение операций и не готов к использованию результата работы блока ФБi. При такой организации работы данные на входной регистр конвейера могут поступать втрое чаще (в общем случае в n раз). При этом общая задержка от момента поступления 1-ой единицы данных на входной регистр до момента появления результата в выходном регистре составляет Tmax, последующие результаты появляются в выходном регистре с интервалом Tmax/n. Поскольку на практике не удается достичь одинаковых задержек в работе всех ступеней конвейера, его суммарная производительность снижается и интервал поступления данных на конвейер определяется максимальным временем задержки какой либо из его ступеней. Поэтому на практике буферные регистры, а так же входные и выходные регистры заменяются буферной памятью, которая позволяет в значительной степени скомпенсировать издержки работы разных ступеней. Буферная память способна хранить некоторое множество машинных слов, поступление и выдача которых организована по принципу FIRST IN FIRST OUT.
2. Архитектурные особенности процессоров вычислительных машин: подходы к решению проблемы обработки команд переходов
Наибольшие издержки в работе процессорных конвейеров вызывает обработка команд условного перехода. Для сокращения издержек, а в некоторых случаях и устранения используются различные методы аппаратного характера, среди которых наиболее известны 4 подхода
1) Использование буфера предвыборки
Буфером предвыборки называется блок буферной памяти располагаемый между ступенью выборки команды и основной частью конвейера. В конвейере используется 2 буферных блока, работающих параллельно. Каждая извлеченная из памяти и помещенная в буфер команда анализируется блоком перехода. При обнаружении команды условного перехода блок перехода вычисляет исполнительный адрес точки перехода и параллельно с продолжением последовательной выборки команд в основной буфер блок перехода организует выборку команд в дополнительный буфер начиная с точки условного перехода. После этого блок перехода определяет исход команды условного перехода и в зависимости от результата подключает к оставшейся части конвейера либо основному либо дополнительному буферу. Основные недостатки данного метода связаны с необходимостью дублирования части схем, а главное с тем, что в случае когда команда условного перехода следует одна за другой или располагаются достаточно близко.
2) Организация параллельных потоков
3) Стратегия задерженного перехода
4) Предсказание переходов
Один из наиболее распространенных методов условных переходов. Идея заключается в том, что до момента выполнения команды условного перехода либо сразу после поступления ее на конвейер делается предположение о вероятном исходе команды условного перехода. Последующие команды выбираются/поступают на конвейер в соответствии с этим предположением. При ошибочном предсказании перехода все выполненные к тому моменту ненужные команды отбрасываются и осуществляется повторная загрузка конвейера, начиная с правильной точки программы. Такой вариант эквивалентен простою конвейера и связан с большими издержками. Но в случае правильного предсказания выигрыш так же оказывается очень заметным.
3. Методы предсказания переходов
Модуль предсказания условных переходов (англ. Branch Prediction Unit) -- устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, определяющее направление ветвлений (предсказывающее, будет ли выполнен условный переход) в исполняемой программе. Предсказание ветвлений позволяет осуществлять предварительную выборку инструкций и данных из памяти, а также выполнять инструкции, находящиеся после условного перехода, до того, как он будет выполнен. Предсказатель переходов является неотъемлемой частью всех современных суперскалярных микропроцессоров, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора.
Существует два основных метода предсказания переходов: статический и динамический.
Статические методы предсказания ветвлений являются наиболее простыми. Суть этих методов состоит в том, что различные типы переходов либо выполняются всегда, либо не выполняются никогда. В современных процессорах статические методы используются лишь в том случае, когда невозможно использование динамического предсказания.
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие - образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Модуль предсказания условных переходов (англ. Branch Prediction Unit) -- устройство, входящее в состав микропроцессоров, имеющих конвейерную архитектуру, определяющее направление ветвлений (предсказывающее, будет ли выполнен условный переход) в исполняемой программе. Предсказание ветвлений позволяет осуществлять предварительную выборку инструкций и данных из памяти, а также выполнять инструкции, находящиеся после условного перехода, до того, как он будет выполнен. Предсказатель переходов является неотъемлемой частью всех современных суперскалярных микропроцессоров, так как в большинстве случаев (точность предсказания переходов в современных процессорах превышает 90 %) позволяет оптимально использовать вычислительные ресурсы процессора.

К 2020 году вы не могли не заметить, что миром правят данные. И, как только речь заходит о работе с ощутимыми объёмами, появляется необходимость в сложном многоэтапном конвейере обработки данных.
Сам по себе конвейер обработки данных — это комплект преобразований, которые требуется провести над входными данными. Сложен он, например, потому, что информация всегда поступает на вход конвейера в непроверенном и неструктурированном виде. А потребители хотят видеть её в лёгкой для понимания форме.
В наших приложениях Badoo и Bumble конвейеры принимают информацию из самых разных источников: генерируемых пользователями событий, баз данных и внешних систем. Естественно, без тщательного обслуживания конвейеры становятся хрупкими: выходят из строя, требуют ручного исправления данных или непрерывного наблюдения.
Я поделюсь несколькими простыми правилами, которые помогают нам в работе с преобразованием данных и, надеюсь, помогут и вам.
Правило наименьшего шага
Первое правило сформулировать легко: каждое отдельное взятое преобразование должно быть как можно проще и меньше.
Допустим, данные поступают на машину с POSIX-совместимой операционной системой. Каждая единица данных — это JSON-объект, и эти объекты собираются в большие файлы-пакеты, содержащие по одному JSON-объекту на строку. Пускай каждый такой пакет весит около 10 Гб.
Над пакетом надо произвести три преобразования:
Проверить ключи и значения каждого объекта.
Применить к каждому объекту первую трансформацию (скажем, изменить схему объекта).
Применить вторую трансформацию (внести новые данные).
Совершенно естественно всё это делать с помощью единственного скрипта на Python:
Блок-схема такого конвейера не выглядит сложной:
Проверка объектов в transform.py занимает около 10% времени, первое преобразование — 70%, на остальное уходит 20% времени.
Теперь представим, что ваш стартап вырос и вам уже приходится обрабатывать сотни, а то и тысячи пакетов. И тут вы обнаружили, что в финальный этап логики обработки данных (занимающий 20% времени) закралась ошибка, — и вам нужно всё выполнить заново.
В такой ситуации рекомендуется собирать конвейеры из как можно более мелких этапов:
Блок-схема превращается в симпатичный паровозик:
конкретные преобразования проще понять;
каждый этап можно протестировать отдельно;
промежуточные результаты отлично кешируются;
систему легко дополнить механизмами обработки ошибок;
преобразования можно использовать и в других конвейерах.
Правило атомарности
К правилу наименьшего шага прилагается второе — правило атомарности. Оно звучит так: каждый шаг-преобразование либо должен случиться, либо нет. Никаких промежуточных состояний данных быть не должно.
Давайте вернёмся к первому примеру. Есть входные данные, над которыми мы проводим преобразование:
Что будет, если в процессе работы скрипт упадёт? Выходной файл будет повреждён. Или, что ещё хуже, данные окажутся преобразованы лишь частично, а следующие этапы конвейера об этом не узнают. Тогда на выходе вы получите лишь частичные данные. Это плохо.
В идеале данные должны быть в одном из двух состояний: готовые к преобразованию или уже преобразованные. Это называется атомарностью: данные либо переходят в следующее правильное состояние, либо нет:
Если какие-то этапы конвейера расположены в транзакционной базе данных, то атомарность легко достигается использованием транзакций. Если вы можете использовать такую базу данных, то не пренебрегайте этой возможностью.
В POSIX-совместимых файловых системах всегда есть атомарные операции (скажем, mv или ln), с помощью которых можно имитировать транзакции:
В этом примере испорченные промежуточные данные окажутся в файле *.tmp, который можно изучить позднее при проведении отладки или просто удалить.
Обратите внимание, как хорошо это правило сочетается с правилом наименьшего шага, ведь маленькие этапы гораздо легче сделать атомарными.
Правило идемпотентности
В императивном программировании подпрограмма с побочными эффектами является идемпотентной, если состояние системы не меняется после одного или нескольких вызовов.
Википедия
Наше третье правило более тонкое: применение преобразования к одним и тем же данным один или несколько раз должно давать одинаковый результат.
Повторюсь: если вы дважды прогоните пакет через какой-то этап, результаты должны быть одинаковы. Если прогоните десять раз, результаты тоже не должны различаться. Давайте скорректируем наш пример, чтобы проиллюстрировать эту идею:
На входе у нас /input/batch.json, а на выходе — /output/batch.json. И вне зависимости от того, сколько раз мы применим преобразование, мы должны получить одни и те же данные:
Так что если только transform.py не зависит от каких-то неявных входных данных, этап transform.py является идемпотентным (своего рода перезапускаемым).
Обратите внимание, что неявные входные данные могут проявиться самым неожиданным образом. Если вы слышали про детерминированную компиляцию, то главные подозреваемые вам известны: временные метки, пути в файловой системе и другие разновидности скрытого глобального состояния.
Чем важна идемпотентность? В первую очередь это свойство упрощает обслуживание конвейера. Оно позволяет легко перезагружать подмножества данных после изменений в transform.py или входных данных в /input/batch.json. Информация будет идти по тем же маршрутам, попадёт в те же таблицы базы данных, окажется в тех же файлах и т. д.
Но помните, что некоторые этапы в конвейерах по определению не могут быть идемпотентными. Например, очистка внешнего буфера. Однако, конечно же, подобные процедуры всё равно должны оставаться маленькими™ и атомарными™.
Правило избыточности
Четвёртое правило: насколько возможно откладывайте удаление промежуточных данных. Зачастую это подразумевает использование дешёвого, медленного, но ёмкого хранилища для входных данных:
Сохраняйте сырые (input/batch.json) и промежуточные (/tmp/batch-1.json, /tmp/batch-2.json, /tmp/batch-3.json) данные как можно дольше — по меньшей мере до завершения цикла работы конвейера.
Вы скажете мне спасибо, когда аналитики решат поменять алгоритм вычисления какой-то метрики в transform3.py и вам придётся исправлять данные за несколько месяцев.
Другими словами: избыточность избыточных данных — ваш лучший избыточный друг.
Заключение
Давайте подведём итоги:
разбивайте конвейер на изолированные маленькие этапы;
стремитесь делать этапы атомарными и идемпотентными;
сохраняйте избыточность данных (в разумных пределах).
Так обрабатываем данные и мы в Badoo и Bumble: они приходят через сотни тщательно подготовленных этапов преобразований, 99% из которых атомарные, небольшие и идемпотентные. Мы можем позволить себе изрядную избыточность, поэтому держим данные в больших холодном и горячем хранилищах, а между отдельными ключевыми преобразованиями имеем и сверхгорячий промежуточный кеш.
Оглядываясь назад, могу сказать, что эти правила выглядят очевидными. Возможно, вы даже интуитивно уже следуете им. Но понимание лежащих в их основе причин помогает видеть границы применимости этих правил и выходить за них при необходимости.
Разработчики архитектуры компьютеров издавна прибегали к методам проектирования, известным под общим названием “совмещение операций”, при котором аппаратура компьютера в любой момент времени выполняет одновременно более одной базовой операции. Этот общий метод включает в себя два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, эти термины отражают два совершенно различных подхода. При параллелизме совмещение операций достигается путем воспроизведения в нескольких копиях аппаратной структуры. Высокая производительность достигается за счет одновременной работы всех элементов структур, осуществляющих решение различных частей задачи.
Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Для выполнения каждой ступени выделяется отдельный блок аппаратуры. Так, обработку любой машинной команды можно разделить на несколько этапов (несколько ступеней), организовав передачу данных от одного этапа к следующему. При этом конвейерную обработку можно использовать для совмещения этапов выполнения разных команд. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд.
Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах.
Простейшая организация конвейера
Выполнение типичной команды можно разделить на следующие этапы:
• выборка команды – IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
• декодирование команды/выборка операндов из регистров – ID;
• выполнение операции/вычисление эффективного адреса памяти – EX;
• обращение к памяти – MEM;
• запоминание результата – WB.
Чтобы конвейеризовать выполнение программы, мы можем просто разбить выполнение команд на указанные выше этапы, отведя для выполнения каждого этапа один такт синхронизации, и начинать в каждом такте выполнение новой команды. Естественно, для хранения промежуточных результатов каждого этапа необходимо использовать регистровые станции. Хотя общее время выполнения одной команды в таком конвейере будет составлять пять тактов, в каждом такте аппаратура будет выполнять в совмещенном режиме пять различных команд.
Чаще всего для представления работы конвейера используются временные диаграммы (таблица), на которых обычно изображаются выполняемые команды, номера тактов и этапы выполнения команд.
Диаграмма работы простейшего конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. В действительности она даже несколько увеличивает время выполнения каждой команды из-за накладных расходов, связанных с управлением регистровыми станциями. Однако увеличение пропускной способности означает, что программа будет выполняться быстрее по сравнению с простой неконвейерной схемой.
Тот факт, что время выполнения каждой команды в конвейере не уменьшается, накладывает некоторые ограничения на практическую длину конвейера. Кроме ограничений, связанных с задержкой конвейера, имеются также ограничения, возникающие в результате несбалансированности задержки на каждой его ступени и из-за накладных расходов на конвейеризацию. Частота синхронизации не может быть выше, а, следовательно, такт синхронизации не может быть меньше, чем время, необходимое для работы наиболее медленной ступени конвейера. Накладные расходы на организацию конвейера возникают из-за задержки сигналов в конвейерных регистрах (защелках) и из-за перекосов сигналов синхронизации. Конвейерные регистры к длительности такта добавляют время установки и задержку распространения сигналов.
В качестве примера рассмотрим неконвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно (рис. 12).
Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. Тогда среднее время выполнения команды в неконвейерной машине будет равно 260 нс. Если же используется конвейерная организация, длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т.е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере. Таким образом, ускорение, полученное в результате конвейеризации, будет равно:
Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых команд и операндов соответствует максимальной производительности конвейера. Если произойдет задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Такие задержки могут возникать в результате возникновения конфликтных ситуаций.
При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Существует три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по ресурсам, когда аппаратные средства не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением.
Рис. 12. Эффект конвейеризации при выполнении трех команд – четырехкратное ускорение
2. Конфликты по данным, возникающие в случае, когда выполнение одной команды зависит от результата выполнения предыдущей команды.
3. Конфликты по управлению, которые возникают при конвейеризации команд переходов и других команд, которые изменяют значение счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения команд. Обычно в простейших конвейерах, если приостанавливается какая-либо команда, то все следующие за ней команды также приостанавливаются. Команды, предшествующие приостановленной, могут продолжать выполняться, но во время приостановки не выбирается ни одна новая команда.
Статьи к прочтению:
Системная шина персонального компьютераAGP
Похожие статьи:
При обсуждении способов параллельной обработки информации было отмечено, что одним из способов как раз и является способ конвейерной обработки. Различают…
Существующие в настоящее время алгоритмы прикладных задач, системное программное обеспечение и аппаратные средства преимущественно ориентированы на…
Принцип конвейерной обработки информации нашел широкое применение в вычислительной технике. В первую очередь это относится к конвейеру команд. Практически все современные ЭВМ используют этот принцип. Вместе с тем во многих вычислительных системах наряду с конвейером команд используется и конвейер данных. Сочетание этих двух конвейеров дает возможность достигнуть очень высокой производительности систем на определенных классах задач, особенно если при этом используется несколько конвейерных процессоров, способных работать одновременно и независимо друг от друга. Именно так и построены самые высокопроизводительные системы.
Магистральные системы относятся к классу МКОД - системы с множественным потоком команд и одиночным потоком данных. Принцип магистральной обработки основан на разделении вычислительного процесса на несколько подпроцессов, каждый из которых выполняется на отдельном устройстве, причем последовательные подпроцессы могут выполняться на своих устройствах подобно тому, как это имеет место на промышленных конвейерных линиях. Этот принцип может применяться на различных иерархических уровнях вычислительного процесса, начиная с уровня логического вентиля.
В качестве основных уровней реализации магистрального принципа можно выделить уровень устройств выполнения элементарных операций над битами данных, уровень арифмегико-логических устройств и уровень управляющих устройств, которым сопоставляются арифметико-магистральвая, командно-магистральная и макромагистральвая обработка соответственно. Схемы процессов трех указанных видов магистральной обработки приведены на рис. 35.
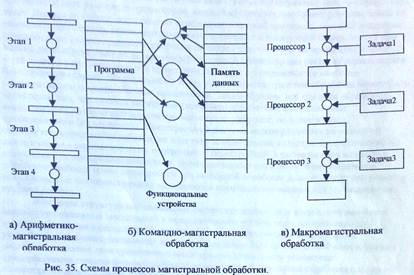
На рис. 35а показана схема четырехэтапной арифметика-магистральной обработки, когда каждая команда выполняется последовательно на четырех устройствах, а последовательность четырех соседних команд заполняет арифметическую магистраль системы так, что одновременно на последнем четвертом устройстве выполняется завершающий четвертый этап первой команды, на третьем устройстве - третий этап второй команды, на втором устройстве - второй этап третьей команды и на первом устройстве -начальный, первый этап четвертой команды. После завершения выполнения устройствами своих этапов обработки первая команда оказывается выполненной и выводится из магистрали, вторая, третья и четвертая команды поступают на очередные четвертый, третий и второй этапы соответственно, а в первое устройство поступает очередная пятая команда для начала выполнения на первом этапе и так далее. Арифметико-магистральная обработка реализована в системах STAR 100 и ASC, в первой из которых используется четырехэтапная магистраль для сложения и шестиэтапная магистраль для умножения, а во второй -магистраль - из восьми этапов общего назначения.
Векторная структура магистральных систем характерна наличием одной или более многофункциональных магистралей в исполнительном устройстве и соответствующих средств управления в процессоре. В случае магистрали статической конфигурации устройство управления оказывается достаточно простым При динамической конфигурации управление сложнее, но и существенно выше производительность вследствие одновременного существования нескольких конфигураций. Векторная обработка сопряжена с некоторыми недостатками, главными из которых являются усложнение векторных операций по сравнению со скалярными и существенный разрыв между алгоритмами скалярной и векторной обработки. Для подготовки векторной операции требуется определенное время, необходимы вспомогательные средства управления конфигурацией магистрали и подготовкой операндов, а для оптимизации машинного кода требуются более развитая система команд и более эффективные компиляторы.
Конвейерные ВС в архитектурном плане занимают промежуточное место среди средств обработки информации, базирующихся на модели вычислителя, и средств, основанных на модели коллектива вычислителей Имеется тенденция к неуклонному совершенствованию архитектуры конвейерных ВС в направлении к коллективу вычислителей Высокий уровень быстродействия достигнут в конвейерных ВС за счет мультиконвейерности (параллельной работы нескольких конвейеров) и конвейеризации на микроуровне (на уровне фаз выполнения арифметических операций, что обеспечивает одновременное выполнение нескольких фаз операций, но над различными операндами). Возможности по наращиванию эффективности конвейерных ВС ограничены:
1) число конвейерных процессоров в системе определяется алгоритмическими возможностями решаемых задач, надежностью управляющего устройства и технико-экономическими ограничениями; это число существенно меньше 10;
2) число модулей в одном конвейерном процессоре не может быть произвольно большим, что следует, например, из алгоритмов решения сложных задач и неабсолютной надежности электронных компонентов; это число порядка 10;
3) число секций в любом модуле (при реализации конвейерного способа обработки информации на микроуровне) ограничивается алгоритмами выполнения арифметических операций и имеет порядок 10.
Ясно, что главные ограничения в наращивании производительности конвейерных ВС следуют из трудностей распараллеливания заданий (сложных задач) и из потенциально низкой надежности: выход из строя управляющего устройства или любого модуля конвейера приводит к отказу системы в целом или в наилучшем случае к сильному сужению круга решаемых задач.
Читайте также: