
Каким свойством должны обладать данные для того чтобы сообщение можно было сжать
Обновлено: 30.06.2024
При преобразовании или селекции информации избыточность используют для повышения ее качества. Однако при хранении готовых документов или их передаче, то избыточность можно уменьшить, что дает эффект сжатия (архивация данных) данных.
В зависимости от того, в каком объекте размещены данные подвергаемые сжатию, различают:
уплотнение (архивация) файлов - применяют для уменьшения их размеров при подготовке к передаче по каналам электронных сетей или к транспортировке на внешнем носителе малой емкости, например на гибком диске;
Уплотнение папок используют как средство архивации данных перед длительным хранением, в частности, при резервном копировании.
Уплотнение дисков служит целям повышения эффективности использования их рабочего пространства и, как правило, применяется к дискам, имеющим недостаточную емкость.
Несмотря на изобилие алгоритмов сжатия данных, теоретически есть только три способа уменьшения их избыточности. Это либо изменение содержания данных, либо изменение их структуры, либо и то и другое вместе.Если при сжатии данных происходит изменение их содержания, метод сжатия необратим и при восстановлении данных из сжатого файла не происходит полного восстановления исходной последовательности. Такие методы называют также методами сжатия с регулируемой потерей информации. Они применимы только для тех типов данных, для которых формальная утрата части содержания не приводит к значительному снижению потребительских свойств. В первую очередь, это относится к мультимедийным данным: видеорядам, музыкальным записям, звукозаписям и рисункам. Методы сжатия с потерей информации обычно обеспечивают гораздо более высокую степень сжатия, чем обратимые методы, но их нельзя применять к текстовым документам, базам данных и, тем более, к программному коду. Характерными форматами сжатия с потерей информации являются:JPG для графических данных;MPG для видеоданных;М РЗ для звуковых данных.
Обратимые методы. Если при сжатии данных происходит только изменение их структуры, то метод сжатия обратим. Из результирующего кода можно восстановить исходный массив путем применения обратного метода. Обратимые методы применяют для сжатия любых типов данных. Характерными форматами сжатия без потери информации являются:GIF, TIP,. PCX и др. для графических данных; AVI для видеоданных;
ZIP, .ARJ, .BAR, .LZH, .LH, .CAB и др. для любых типов данных.
24. Программы WinRar, WinZip.
Среди программ-архиваторов наибольшей популярностью пользуются программы WinZip и WinRar. Оба архиватора очень удобные, поэтому лучше всего установить на компьютер сразу два.
WinRar был создан русским программистом, его имя — Евгений Рошал. Поэтому WinRar в основном используется в России и СНГ.
А WinZip — западная программа, ее разработал Фил Кац.
Rar и Zip — это форматы сжатия информации. Принцип их работы почти одинаковый, но есть и некоторые различия. WinZip работает быстрее, чем WinRar, но сжимает данные хуже. Например, файл размером 89 Кб WinRar сжимает до 16 Кб, а WinZip только до 21 Кб. Скорость сжатия при этом почти одинаковая. Разница в сжатии может быть и незначительной и даже одинаковой в некоторых случаях в зависимости от типа файла (текстовый документ, графика, музыка). Но WinRar в большинстве случаев показывает более медленную скорость работы. Поэтому можно сказать, что WinRar целесообразнее использовать для сжатия каких-то небольших файлов, а WinZip — для сжатия больших объемов информации.
Оба архиватора могут разархивировать почти любой формат архива — список этих форматов довольно внушительный. Кроме самой архивации данные программы предоставляют пользователю и другие возможности. К ним относятся создание самораспаковывающихся архивов, многотомных архивов и другое.
Создание многотомного архива пригодится в том случае, если нужно разделить один файл (например большой фильм) на несколько взаимосвязанных архивов. Разархивировать их каждый по отдельности нельзя, нужно собрать весь многотомный архив на одном компьютере и только после этого распаковывать.
WinZip и WinRar являются мультиязычными программами, поэтому освоить их совсем не сложно. Что касается удобства интерфейса, то здесь у данных архиваторов тоже есть некоторые различия.
А чтобы создать архив в WinZip, нужно сначала дать архиву имя, а только потом выбирать файлы для архивации. При этом папка не совпадает с той, где пользователь создает архив, а является последней, откуда архивировали файлы. Поэтому приходится 2 раза выбирать один и тот же путь, чтобы создать архив там, где находятся файлы для архивации.
25. История развития компьютерных вирусов.
Компьютерный вирус - программа, способная присоединяться к другим программам, создавать свои копии и внедрять их в файлы, системные области компьютера и в сети с целью нарушения работы программ, порчи файлов и каталогов, создания всевозможных помех в работе компьютера.
Название "вирус" было взято из биологии, так как процесс захвата компьютера вирусом полностью соответствует процессу захвата вирусом человеческого организма. Человеческий вирус внедряется в клетку, после чего начинает размножаться. Так и компьютерный: попав в программу, вирус действует аналогичным образом. Впервые это определение было дано Фредом Коэном, который сказал, что вирус является программой, способной заражать другие программы путем добавления в них копии самой себя.
Конечно, первые мысли о программах, которые развиваются самостоятельно, приходили в голову к людям давно. Еще в 40-ые года, однако, дальше идей дело не дошло. Доступ к компьютерам был далеко не у всех, поэтому и развитием вирусов не занимались. Однако в восьмидесятые компьютеры стали достоянием общественности, а это привело к массовому росту вирусов. В 1981 году появился первый вирус под названием Elk Cloner. Он выводил на экран известные строчки: It will infiltrate your chips. Yes it's Cloner! Фред Коэн в этом же году занялся исследованием саморазвивающихся программ. Первый вирус для MS-DOS - был изобретен двумя пакистанским программистами, которые владели Brain Computer Services. Этот вирус был загрузочным. При запуске компьютера он попадал в память и заражал его при загрузке. Данный вирус проявлял себя сразу же, поэтому его было легко обнаружить, не допустив, таким образом, заражение других дисков. Никто так и не понял, зачем этим программистам захотелось создать вирус. Однако, скорее всего, создание вируса было маркетинговым ходом, в результате которого им удалось привлечь внимание к своей небольшой компании. Вирусы наших дней благодаря широкому распространению компьютеров постоянно совершенствуются, например: загрузочные заменяют информацию, которая необходима для беспрепятственного запуска системы; бэкборды – позволяют получить доступ к персональным и личным данным пользователя, заражают системы компьютерными вирусами без ведома пользователя, рекламные программы и др.
Доброго времени суток.
Сегодня я хочу коснуться темы сжатия данных без потерь. Несмотря на то, что на хабре уже были статьи, посвященные некоторым алгоритмам, мне захотелось рассказать об этом чуть более подробно.
Я постараюсь давать как математическое описание, так и описание в обычном виде, для того, чтобы каждый мог найти для себя что-то интересное.
В этой статье я коснусь фундаментальных моментов сжатия и основных типов алгоритмов.
Сжатие. Нужно ли оно в наше время?
Разумеется, да. Конечно, все мы понимаем, что сейчас нам доступны и носители информации большого объема, и высокоскоростные каналы передачи данных. Однако, одновременно с этим растут и объемы передаваемой информации. Если несколько лет назад мы смотрели 700-мегабайтные фильмы, умещающиеся на одну болванку, то сегодня фильмы в HD-качестве могут занимать десятки гигабайт.
Конечно, пользы от сжатия всего и вся не так много. Но все же существуют ситуации, в которых сжатие крайне полезно, если не необходимо.
- Пересылка документов по электронной почте (особенно больших объемов документов с использованием мобильных устройств)
- При публикации документов на сайтах, потребность в экономии трафика
- Экономия дискового пространства в тех случаях, когда замена или добавление средств хранения затруднительно. Например, подобное бывает в тех случаях, когда выбить бюджет под капитальные расходы непросто, а дискового пространства не хватает
Конечно, можно придумать еще множество различных ситуаций, в которых сжатие окажется полезным, но нам достаточно и этих нескольких примеров.
Все методы сжатия можно разделить на две большие группы: сжатие с потерями и сжатие без потерь. Сжатие без потерь применяется в тех случаях, когда информацию нужно восстановить с точностью до бита. Такой подход является единственно возможным при сжатии, например, текстовых данных.
В некоторых случаях, однако, не требуется точного восстановления информации и допускается использовать алгоритмы, реализующие сжатие с потерями, которое, в отличие от сжатия без потерь, обычно проще реализуется и обеспечивает более высокую степень архивации.
Универсальные методы сжатия без потерь
В общем случае можно выделить три базовых варианта, на которых строятся алгоритмы сжатия.
Первая группа методов – преобразование потока. Это предполагает описание новых поступающих несжатых данных через уже обработанные. При этом не вычисляется никаких вероятностей, кодирование символов осуществляется только на основе тех данных, которые уже были обработаны, как например в LZ – методах (названных по имени Абрахама Лемпеля и Якоба Зива). В этом случае, второе и дальнейшие вхождения некой подстроки, уже известной кодировщику, заменяются ссылками на ее первое вхождение.
Вторая группа методов – это статистические методы сжатия. В свою очередь, эти методы делятся на адаптивные (или поточные), и блочные.
В первом (адаптивном) варианте, вычисление вероятностей для новых данных происходит по данным, уже обработанным при кодировании. К этим методам относятся адаптивные варианты алгоритмов Хаффмана и Шеннона-Фано.
Во втором (блочном) случае, статистика каждого блока данных высчитывается отдельно, и добавляется к самому сжатому блоку. Сюда можно отнести статические варианты методов Хаффмана, Шеннона-Фано, и арифметического кодирования.
Общие принципы, на которых основано сжатие данных
Все методы сжатия данных основаны на простом логическом принципе. Если представить, что наиболее часто встречающиеся элементы закодированы более короткими кодами, а реже встречающиеся – более длинными, то для хранения всех данных потребуется меньше места, чем если бы все элементы представлялись кодами одинаковой длины.
Точная взаимосвязь между частотами появления элементов, и оптимальными длинами кодов описана в так называемой теореме Шеннона о источнике шифрования(Shannon's source coding theorem), которая определяет предел максимального сжатия без потерь и энтропию Шеннона.
Немного математики

Если вероятность появления элемента si равна p(si), то наиболее выгодно будет представить этот элемент — log2p(si) битами. Если при кодировании удается добиться того, что длина всех элементов будет приведена к log2p(si) битам, то и длина всей кодируемой последовательности будет минимальной для всех возможных методов кодирования. При этом, если распределение вероятностей всех элементов F =
Это значение называют энтропией распределения вероятностей F, или энтропией источника в заданный момент времени.
Однако обычно вероятность появления элемента не может быть независимой, напротив, она находится в зависимости от каких-то факторов. В этом случае, для каждого нового кодируемого элемента si распределение вероятностей F примет некоторое значение Fk, то есть для каждого элемента F= Fk и H= Hk.
Иными словами, можно сказать, что источник находится в состоянии k, которому соответствует некий набор вероятностей pk(si) для всех элементов si.

Поэтому, учитывая эту поправку, можно выразить среднюю длину кодов как
Где Pk — вероятность нахождения источника в состоянии k.
Итак, на данном этапе мы знаем, что сжатие основано на замене часто встречающихся элементов короткими кодами, и наоборот, а так же знаем, как определить среднюю длину кодов. Но что же такое код, кодирование, и как оно происходит?
Кодирование без памяти
Коды без памяти являются простейшими кодами, на основе которых может быть осуществлено сжатие данных. В коде без памяти каждый символ в кодируемом векторе данных заменяется кодовым словом из префиксного множества двоичных последовательностей или слов.
На мой взгляд, не самое понятное определение. Рассмотрим эту тему чуть более подробно.

Пусть задан некоторый алфавит , состоящий из некоторого (конечного) числа букв. Назовем каждую конечную последовательность символов из этого алфавита (A=a1, a2,… ,an) словом, а число n — длиной этого слова.

Пусть задан также другой алфавит. Аналогично, обозначим слово в этом алфавите как B.
Введем еще два обозначения для множества всех непустых слов в алфавите. Пусть — количество непустых слов в первом алфавите, а — во втором.
Пусть также задано отображение F, которое ставит в соответствие каждому слову A из первого алфавита некоторое слово B=F(A) из второго. Тогда слово B будет называться кодом слова A, а переход от исходного слова к его коду будет называться кодированием.
Поскольку слово может состоять и из одной буквы, то мы можем выявить соответствие букв первого алфавита и соответствующих им слов из второго:
a1 B1
a2 B2
…
an Bn
Это соответствие называют схемой, и обозначают ∑.
В этом случае слова B1, B2,…, Bn называют элементарными кодами, а вид кодирования с их помощью — алфавитным кодированием. Конечно, большинство из нас сталкивались с таким видом кодирования, пусть даже и не зная всего того, что я описал выше.
Итак, мы определились с понятиями алфавит, слово, код, и кодирование. Теперь введем понятие префикс.
Итак, мы подошли вплотную к пониманию определения кодов без памяти. Последнее определение, которое нам осталось понять — это префиксное множество. Схема ∑ обладает свойством префикса, если для любых 1≤i, j≤r, i≠j, слово Bi не является префиксом слова Bj.
Проще говоря, префиксное множество – это такое конечное множество, в котором ни один элемент не является префиксом (или началом) любого другого элемента. Простым примером такого множества является, например, обычный алфавит.
Одним из канонических алгоритмов, которые иллюстрируют данный метод, является алгоритм Хаффмана.
Алгоритм Хаффмана
Алгоритм Хаффмана использует частоту появления одинаковых байт во входном блоке данных, и ставит в соответствие часто встречающимся блокам цепочки бит меньшей длины, и наоборот. Этот код является минимально – избыточным кодом. Рассмотрим случай, когда, не зависимо от входного потока, алфавит выходного потока состоит из всего 2 символов – нуля и единицы.
Для лучшей иллюстрации, рассмотрим небольшой пример.
Пусть у нас есть алфавит, состоящий из всего четырех символов — < a1, a2, a3, a4>. Предположим также, что вероятности появления этих символов равны соответственно p1=0.5; p2=0.24; p3=0.15; p4=0.11 (сумма всех вероятностей, очевидно, равна единице).
Итак, построим схему для данного алфавита.
- Объединяем два символа с наименьшими вероятностями (0.11 и 0.15) в псевдосимвол p'.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Объединяем два символа с наименьшей вероятностью (0.24 и 0.26) в псевдосимвол p''.
- Удаляем объединенные символы, и вставляем получившийся псевдосимвол в алфавит.
- Наконец, объединяем оставшиеся два символа, и получаем вершину дерева.
Если сделать иллюстрацию этого процесса, получится примерно следующее:

Как вы видите, при каждом объединении мы присваиваем объединяемым символам коды 0 и 1.
Таким образом, когда дерево построено, мы можем легко получить код для каждого символа. В нашем случае коды будут выглядить так:
Поскольку ни один из данных кодов не является префиксом какого-нибудь другого (то есть, мы получили пресловутое префиксное множество), мы можем однозначно определить каждый код в выходном потоке.
Итак, мы добились того, что самый частый символ кодируется самым коротким кодом, и наоборот.
Если предположить, что изначально для хранения каждого символа использовался один байт, то можно посчитать, насколько нам удалось уменьшить данные.
Пусть на входу у нас была строка из 1000 символов, в которой символ a1 встречался 500 раз, a2 — 240, a3 — 150, и a4 — 110 раз.
Изначально данная строка занимала 8000 бит. После кодирования мы получим строку длинной в ∑pili = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 бит. Итак, нам удалось сжать данные в 4,54 раза, потратив в среднем 1,76 бита на кодирование каждого символа потока.
Напомню, что согласно Шеннону, средняя длина кодов составляет . Подставив в это уравнение наши значения вероятностей, мы получим среднюю длину кодов равную 1.75496602732291, что весьма и весьма близко к полученному нами результату.
Тем не менее, следует учитывать, что помимо самих данных нам необходимо хранить таблицу кодировки, что слегка увеличит итоговый размер закодированных данных. Очевидно, что в разных случаях могут с использоваться разные вариации алгоритма – к примеру, иногда эффективнее использовать заранее заданную таблицу вероятностей, а иногда – необходимо составить ее динамически, путем прохода по сжимаемым данным.
Заключение
Итак, в этой статье я постарался рассказать об общих принципах, по которым происходит сжатие без потерь, а также рассмотрел один из канонических алгоритмов — кодирование по Хаффману.
Если статья придется по вкусу хабросообществу, то я с удовольствием напишу продолжение, так как есть еще множество интересных вещей, касающихся сжатия без потерь; это как классические алгоритмы, так и предварительные преобразования данных (например, преобразование Барроуза-Уилира), ну и, конечно, специфические алгоритмы для сжатия звука, видео и изображений (самая, на мой взгляд, интересная тема).
Сжатие файлов позволяет быстрее передавать, получать и хранить большие файлы. Оно используется повсеместно и наверняка хорошая вам знакомо: самые популярные расширения сжатых файлов — ZIP, JPEG и MP3. В этой статье кратко рассмотрим основные виды сжатия файлов и принципы их работы.
Что такое сжатие?
Сжатие файла — это уменьшение его размера при сохранении исходных данных. В этом случае файл занимает меньше места на устройстве, что также облегчает его хранение и передачу через интернет или другим способом. Важно отметить, что сжатие не безгранично и обычно делится на два основных типа: с потерями и без потерь. Рассмотрим каждый из них по отдельности.
Сжатие с потерями
Такой способ уменьшает размер файла, удаляя ненужные биты информации. Чаще всего встречается в форматах изображений, видео и аудио, где нет необходимости в идеальном представлении исходного медиа. MP3 и JPEG — два популярных примера. Но сжатие с потерями не совсем подходит для файлов, где важна вся информация. Например, в текстовом файле или электронной таблице оно приведёт к искажённому выводу.
MP3 содержит не всю аудиоинформацию из оригинальной записи. Этот формат исключает некоторые звуки, которые люди не слышат. Вы заметите, что они пропали, только на профессиональном оборудовании с очень высоким качеством звука, поэтому для обычного использования удаление этой информации позволит уменьшить размер файла практически без недостатков.
Аналогично файлы JPEG удаляют некритичные части изображений. Например, в изображении с голубым небом сжатие JPEG может изменить все пиксели на один или два оттенка синего вместо десятков.
Чем сильнее вы сжимаете файл, тем заметнее становится снижение качества. Вы, вероятно, замечали такое, слушая некачественную музыку в формате MP3, загруженную на YouTube. Например, сравните музыкальный трек высокого качества с сильно сжатой версией той же песни.
Сжатие с потерями подходит, когда файл содержит больше информации, чем нужно для ваших целей. Например, у вас есть огромный файл с исходным (RAW) изображением. Целесообразно сохранить это качество для печати изображения на большом баннере, но загружать исходный файл в Facebook будет бессмысленно. Картинка содержит множество данных, не заметных при просмотре в социальных сетях. Сжатие картинки в высококачественный JPEG исключает некоторую информацию, но изображение выглядит почти как оригинал.
При сохранении в формате с потерями, вы зачастую можете установить уровень качества. Например, у многих графических редакторов есть ползунок для выбора качества JPEG от 0 до 100. Экономия на уровне 90 или 80 процентов приводит к небольшому уменьшению размера файла с незначительной визуальной разницей. Но сохранение в плохом качестве или повторное сохранение одного и того же файла в формате с потерями ухудшит его.
Посмотрите на этот пример.
Оригинальное изображение, загруженное с Pixabay в формате JPEG. 874 КБ:

Результат сохранения в формате JPEG с 50-процентным качеством. Выглядит не так уж плохо. Вы можете заметить артефакты по краям коробок только при увеличении. 310 КБ:

Исходное изображение, сохранённое в формате JPEG с 10-процентным качеством. Выглядит ужасно. 100 КБ:

Где используется сжатие с потерями
Как мы уже упоминали, сжатие с потерями отлично подходит для большинства медиафайлов. Это крайне важно для таких компаний как Spotify и Netflix, которые постоянно транслируют большие объёмы информации. Максимальное уменьшение размера файла при сохранении качества делает их работу более эффективной.
Сжатие без потерь
Сжатие без потерь позволяет уменьшить размер файла так, чтобы в дальнейшем можно было восстановить первоначальное качество. В отличие от сжатия с потерями, этот способ не удаляет никакую информацию. Рассмотрим простой пример. На картинке ниже стопка из 10 кирпичей: два синих, пять жёлтых и три красных.

Вместо того чтобы показывать все 10 блоков, мы можем удалить все кирпичи одного цвета, кроме одного. Используя цифры, чтобы показать, сколько кирпичей каждого цвета было, мы представляем те же данные используя гораздо меньше кирпичей — три вместо десяти.
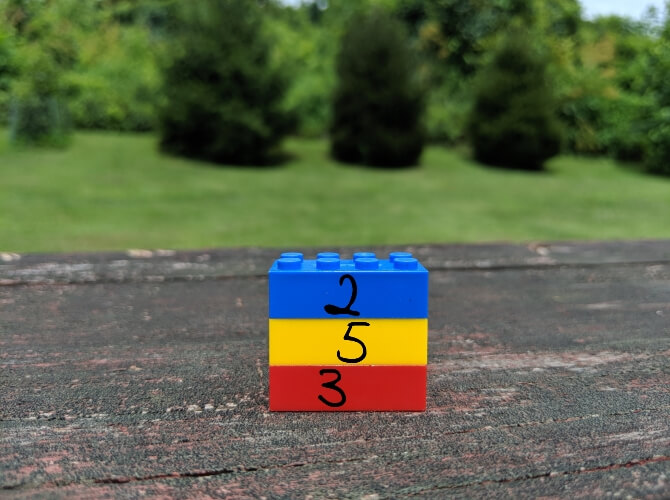
Это простая иллюстрация того, как осуществить сжатие без потерь. Та же информация сохраняется более эффективным способом. Рассмотрим реальный файл: mmmmmuuuuuuuoooooooooooo. Его можно сжать до гораздо более короткой формы: m5u7o12. Это позволяет использовать 7 символов вместо 24 для представления одних и тех же данных.
Где используется сжатие без потерь
ZIP-файлы — популярный пример сжатия без потерь. Хранить информацию в виде ZIP-файлов более эффективно, при этом когда вы распаковываете архив, там присутствует вся оригинальная информация. Это актуально для исполняемых файлов, так как после сжатия с потерями распакованная версия будет повреждена и непригодна для использования.
Другие распространённые форматы без потерь — PNG для изображений и FLAC для аудио. Форматы видео без потерь встречаются редко, потому что они занимают много места.
Сжатие с потерями vs сжатие без потерь
Теперь, когда мы рассмотрели обе формы сжатия файлов, может возникнуть вопрос, когда и какую следует использовать. Здесь всё зависит от того, для чего вы используете файлы.
Скажем, вы только что откопали свою старую коллекцию компакт-дисков и хотите оцифровать её. Когда вы копируете свои компакт-диски, имеет смысл использовать формат FLAC, формат без потерь. Это позволяет получить мастер-копию на компьютере, которая обладает тем же качеством звука, что и оригинальный компакт-диск.
Позже вы, возможно, захотите загрузить музыку на телефон или старый MP3-плеер. Здесь не так важно, чтобы музыка была в идеальном качестве, поэтому вы можете конвертировать файлы FLAC в MP3. Это даст вам аудиофайл, который по-прежнему достаточно хорош для прослушивания, но не занимает много места на мобильном устройстве. Качество MP3, преобразованного из FLAC, будет таким же, как если бы вы создали сжатый MP3 с оригинального CD.
Тип данных, представленных в файле, также может определять, какой вид сжатия подходит больше. В PNG используется сжатие без потерь, поэтому его хорошо использовать для изображений, в которых много однотонного пространства. Например, для скриншотов. Но PNG занимает гораздо больше места, когда картинка состоит из смеси множества цветов, как в случае с фотографиями. В этом случае с точки зрения размера файлов лучше использовать JPEG.
Проблемы во время сжатия файлов
Бесполезно конвертировать формат с потерями в формат без потерь. Это пустая трата пространства. Скажем, у вас есть MP3-файл весом в 3 МБ. Преобразование его в FLAC может привести к увеличению размера до 30 МБ. Но эти 30 МБ содержат только те звуки, которые имел уже сжатый MP3. Качество звука от этого не улучшится, но объём станет больше.
Также стоит иметь в виду, что преобразовывая один формат с потерями в аналогичный, вы получаете дальнейшее снижение качества. Каждый раз, когда вы применяете сжатие с потерями, вы теряете больше деталей. Это становится всё более и более заметно, пока файл по существу не будет разрушен. Помните также, что форматы с потерями удаляют некоторые данные и их невозможно восстановить.
Заключение
Мы рассмотрели как сжатие файлов с потерями, так и без потерь, чтобы увидеть, как они работают. Теперь вы знаете, как можно уменьшить размер файла и как выбрать лучший способ для этого.
Алгоритмы, которые определяют, какие данные выбрасываются в методах с потерями и как лучше хранить избыточные данные при сжатии без потерь, намного сложнее, чем описано здесь. На эту тему можно почитать больше информации здесь, если вам интересно.
Сжатия данных или кодирования источника является процессом компьютер преобразования последовательности битов А последовательности битов короче B может доставить ту же информацию или информацию, соседнее с использованием алгоритма для декомпрессии . Это операция кодирования, которая сокращает размер (передача, хранение) данных за счет сжатия. Это противоположно декомпрессии.
Алгоритм сжатия без потерь возвращается после декомпрессии точно такой же последовательности битов в оригинале. Алгоритмы сжатия без потерь используются для архивов , исполняемых файлов или текста .
Для сжатия данных без потерь в основном используются энтропийное кодирование и алгоритмическое кодирование. Энтропийное кодирование основано на предположениях об источнике. Например, для кодирования Хаффмана мы должны передать таблицу вероятностей символов источника. Другими примерами являются словарные кодировки, такие как LZ77 , LZ78 и LZW . Алгоритмическое кодирование не требует передачи другой информации, кроме результата кодирования (и используемого метода сжатия).
При использовании алгоритма сжатия с потерями битовая последовательность, полученная после распаковки, более или менее соседствует с исходной в соответствии с желаемым качеством. Алгоритмы сжатия с потерями полезны для изображений, звука и видео.
Эти форматы данных , такие как Zip , RAR , GZIP , ADPCM , MP3 и JPEG алгоритмов сжатия данных использования.
Повышение эффективности сжатия на 5% по сравнению с алгоритмами большого тока обычно может умножить на 100 время, необходимое для сжатия.
Теория сжатия данных использует концепции теории информации : энтропию в смысле Шеннона .
Резюме
Типы сжатия
Сжатие без потерь
Сжатие считается без потерь, если исходная информация не теряется. После сжатия остается столько же информации, сколько и раньше, она только переписывается в более сжатой форме (например, сжатие gzip для любого типа данных или формат PNG для типов данных. Синтетические изображения, предназначенные для Интернета ). Сжатие без потерь также называется уплотнением.
Сжатие с потерями

Этот метод основан на простой идее: лишь очень слабое подмножество всех возможных изображений (а именно тех , которые можно было бы получить, например , путем рисования значения каждого пикселя с помощью генератора случайных чисел) имеет уязвимостям и информативный характер. Для глаз. Поэтому мы постараемся кратко кодировать эти изображения. На практике глазу необходимо идентифицировать области, в которых есть корреляции между соседними пикселями, то есть есть смежные области соседних цветов. Программы сжатия пытаются обнаружить эти области и кодировать их как можно компактнее. Например, стандарт JPEG 2000 обычно позволяет кодировать фотографические изображения с разрешением 1 бит на пиксель без видимой потери качества на экране, то есть сжатия с коэффициентом 24 к 1.
Поскольку глаз не обязательно воспринимает все детали изображения, можно уменьшить объем данных, чтобы результат выглядел очень похожим на исходный или даже идентичным человеческому глазу. Задача сжатия с потерями состоит в том, чтобы уменьшить объем данных в файле , сохраняя при этом ощутимое качество и избегая появления артефактов .
Точно так же ухо может использовать только очень небольшое подмножество возможных звуков, которое требует регулярностей, которые сами по себе создают избыточность (точное кодирование шума дыхания не представляет большого интереса). Кодирование, устраняющее эту избыточность и восстанавливающее его по прибытии, остается приемлемым, даже если восстановленный звук не во всех отношениях идентичен исходному звуку.
Мы можем выделить три основных семейства сжатия с потерями:
- прогнозированием, например ADPCM ;
- путем трансформации. Это наиболее эффективные и широко используемые методы. ( JPEG , JPEG 2000 , все стандарты MPEG и т. Д.);
- сжатие на основе фрактальной повторяемости паттернов ( Fractal Compression ).
Форматы MPEG - это форматы сжатия с потерями для видеопоследовательностей. Таким образом, они включают в себя аудиокодеры, такие как известные MP3 или AAC , которые можно использовать независимо друг от друга, и, конечно же, видеокодеры - обычно просто ссылаются на стандарт, от которого они зависят (MPEG-2, MPEG-4), как а также решения для синхронизации аудио- и видеопотоков и их передачи по разным типам сетей.
Сжатие практически без потерь
Существенные методы сжатия без потерь - это подмножество методов сжатия с потерями, которые иногда отличаются от последних. Сжатие без значительных потерь можно рассматривать как промежуточное звено между консервативным сжатием и неконсервативным сжатием в том смысле, что оно сохраняет весь смысл исходных данных, удаляя при этом часть информации .
В области сжатия изображений проводится различие между сжатием без потерь (с идеальным битом или идеальным битом ) и сжатием без значительных потерь (с идеальным или с точным совпадением пикселей ). Сжатое изображение почти без потерь (не путать со сжатым изображением с небольшими потерями) может быть распаковано для получения идентичных пикселей его несжатой версии. С другой стороны, его нельзя распаковать для получения полностью идентичной несжатой версии (метаданные могут быть разными).
Методы сжатия, близкие к потерям
Среди алгоритмов сжатия почти без потерь мы находим большинство алгоритмов сжатия без потерь, специфичных для определенного типа данных. Например, JPEG-LS обеспечивает сжатие растрового изображения Windows практически без потерь, а Monkey's Audio обеспечивает сжатие без потерь звуковых данных в формате PCM : нет потери качества, изображение и музыкальный фрагмент являются в точности оригинальными.
Такие алгоритмы, как кодирование Lempel-Ziv или RLE, состоят из замены цепочек битов, используемых несколько раз в одном и том же файле. В алгоритме кодирования Хаффмана чем чаще используется строка битов, тем короче строка, которая ее заменит.
Алгоритмы, такие как преобразование Барроуза-Уиллера , используются с алгоритмом сжатия. Такие алгоритмы изменяют порядок битов, чтобы повысить эффективность алгоритма сжатия, но без сжатия самих по себе.
Кодирование с повторением
Кодирование RLE
Буквы RLE обозначают кодирование длин серий . Это один из простейших методов сжатия: любая последовательность идентичных битов или символов заменяется парой (количество вхождений; повторяющийся бит или символ).
Пример : AAAAAAAAZZEEEEEER дает 8A2Z6E1R :, что намного короче.
CCITT сжатие
Есть два сжатия, Группа 3 (рекомендация ITU T.4) и Группа 4 (рекомендация ITU T.6), используемых для факсов:
Это теоретически: на практике необходимо передать больше символов, но отправка пустой страницы все же намного быстрее с группой 4, чем с группой 3.
Энтропийное кодирование
Кодирование Хаффмана
Оригинальность Дэвида А. Хаффмана заключается в том, что он обеспечивает объективный процесс агрегирования, позволяющий составлять его код, как только у вас есть статистика использования каждого символа.
Macintosh от Apple , закодированный текст в системе вдохновило Хаффман: 15 наиболее частых букв (на языке) были закодированы на 4 бита, а 16 - й комбинации был код побег , указывающий , что письмо было закодировано в ASCII на следующих 8 бит . Эта система позволяла сжатие текста в среднем примерно на 30% в то время, когда память была чрезвычайно дорогой по сравнению с текущими ценами (если считать в 1000 раз).
Недостаток кодирования Хаффмана заключается в том, что оно должно знать частоту символов, используемых в файле, прежде чем выбирать оптимальные коды. И поэтому он должен прочитать весь файл перед сжатием. Другое следствие заключается в том, что для распаковки необходимо знать коды и, следовательно, таблицу, которая добавляется перед файлом как для передачи, так и для хранения, что снижает степень сжатия, особенно для небольших файлов. Эта проблема устраняется адаптивным кодированием Хаффмана , которое со временем меняет свою таблицу. И поэтому можно начать с базовой таблицы. В принципе, начинается с персонажей с одинаковой вероятностью.
Код Бодо

Код Бодо - это конкретный, простой и представительный пример сжатия. Этот код использует 5- битную базу для кодирования символов, в то время как таблица символов, распределенная по 6 битам, содержит элементы. Последний разделен на два набора элементов, а два символа: буквы инверсии (код 31) и номера инверсии (код 27) позволяют переключаться между двумя наборами. Если бы символы использовались случайным образом, эта система была бы бессмысленной и даже привела бы к избытку данных со средним числом бит на символ. Однако буквы кодируются на первом наборе символов, а числа и специальные символы - на втором. Однако характер используемых персонажей не случаен. Действительно, при написании связного текста цифры отделяются от букв, а знаки препинания встречаются редко. 2 6 знак равно 64 = 64> 2 5 знак равно 32 = 32> ( 1 / 2 ) * 5 + 5 знак равно 7 , 5
Таким образом, мы напишем:
Хотя вряд ли нам придется набирать:
Без сжатия, то есть при каждом кодировании символов из 6 бит , эти символьные строки имеют одинаковый вес для битов. 52 * 6 знак равно 312
Здесь мы замечаем, что с помощью кода Бодо первый текст был сжат лучше, чем второй. Действительно, первая строка была предсказуемой, а вторая - нет.
Таким образом, код Бодо играет на вероятности распределения символов в понятном тексте.
Арифметическое кодирование
Арифметическое кодирование очень похоже на кодирование Хаффмана в том, что оно связывает наиболее вероятные шаблоны с кратчайшими кодами ( энтропией ). В отличие от кодирования Хаффмана, которое лучше всего дает 1-битные коды, арифметическое кодирование может создавать пустые коды. Таким образом, полученная степень сжатия лучше.
Кодирование словаря
Лемпель-Зив 1977 (LZ77)
Сжатие LZ77 заменяет повторяющиеся шаблоны ссылками на их первое появление.
Он дает более низкую степень сжатия, чем другие алгоритмы (PPM, CM), но имеет двойное преимущество: он быстрый и асимметричный (то есть алгоритм распаковки отличается от алгоритма сжатия, который можно использовать для получения мощного алгоритма сжатия и быстрой распаковки. алгоритм).
LZ77, в частности, является основой широко распространенных алгоритмов, таких как Deflate ( ZIP , gzip ) или LZMA ( 7-Zip , xz ).
Лемпель-Зив 1978 и Лемпель-Зив-Велч (LZ78 и LZW)
LZW основан на том же методе, но Уэлч обнаружил, что путем создания начального словаря всех возможных символов сжатие было улучшено, поскольку декомпрессор может воссоздать исходный словарь и, следовательно, не должен передавать его или отправлять первые символы. Он был запатентован UNISYS и поэтому не мог свободно использоваться во всех странах до истечения срока действия патента в 2003 году. Он используется в модемах, но UNISYS обязуется продавать лицензию любому производителю до того, как она будет выпущена. стандарт для модемов.
Сжатие Лемпеля-Зива-Велча называется словарным типом. Он основан на том факте, что шаблоны встречаются чаще, чем другие, и поэтому их можно заменить индексом в словаре. Словарь строится динамически в соответствии с встречающимися шаблонами.
Кодирование контекстного моделирования
Прогнозирование частичного распознавания (PPM)
Прогнозирование частичного распознавания основано на контекстном моделировании для оценки вероятности появления различных символов. Зная содержимое части источника данных (файла, потока…), PPM может угадать остальное с большей или меньшей точностью. PPM может использоваться, например, на входе арифметического кодирования.
Прогнозирование частичного распознавания обычно дает лучшую степень сжатия, чем алгоритмы на основе Лемпеля-Зива, но значительно медленнее.
Взвешивание контекста (CM)
Взвешивание контекста состоит из использования нескольких предикторов (например, PPM) для получения наиболее надежной возможной оценки символа, который должен появиться в источнике данных (файле, потоке и т. Д.). В основном это можно сделать с помощью средневзвешенного значения, но наилучшие результаты достигаются с помощью методов машинного обучения, таких как нейронные сети .
Взвешивание контекстов очень эффективно с точки зрения степени сжатия, но чем медленнее, тем больше контекстов.
В настоящее время наилучшие степени сжатия достигаются алгоритмами, связывающими контекстное взвешивание и арифметическое кодирование, такими как PAQ .
Преобразование Барроуза-Уиллера (BWT)
Это режим реорганизации данных, а не режим сжатия. Он в первую очередь предназначен для облегчения сжатия текста на естественном языке, но его также можно использовать для сжатия любых двоичных данных. Это преобразование, которое является полностью обратимым, сортирует все повороты исходного текста, что имеет тенденцию группировать идентичные символы вместе на выходе, так что простое сжатие, применяемое к выходным данным, часто приводит к очень эффективному сжатию.
Методы сжатия с потерями
Сжатие с потерями применяется только к перцепционным данным (аудио, изображения, видео) и зависит от характеристик зрительной системы или слуховой системы человека для своих стратегий уменьшения информации. Поэтому методы индивидуальны для каждой среды. Эти методы не используются по отдельности, а объединяются для создания системы сжатия с высокими характеристиками.
Даунсэмплинг
В изображениях и видео обычно выполняется пространственная субдискретизация компонентов цветности . Поскольку зрительная система человека более чувствительна к изменениям яркости, чем цвета, удаление важной части информации о цвете практически незаметно.
Количественная оценка
Количественная оценка - самый важный шаг в сокращении информации. Именно на квантовании играют, когда хотят достичь целевой скорости, обычно с использованием модели искажения скорости .
Во время кодирования посредством преобразования (например, вейвлетов или DCT ) квантование применяется к коэффициентам в преобразованном пространстве, снижая их точность .
Степень сжатия
Степень сжатия связана с соотношением между размером сжатого файла и размером исходного файла . Степень сжатия обычно выражается в процентах. Коэффициент 50% означает, что размер сжатого файла составляет половину . Формула для расчета этого показателя: τ б B в В б B в
τ знак равно 1 - ( б / в )
Алгоритм, используемый для преобразования в , предназначен для получения результата размером менее . Парадоксально, но иногда это может привести к увеличению размера: в случае сжатия без потерь всегда есть несжимаемые данные, размер сжатого потока которых больше или равен исходному потоку. В B B В
Об этом свидетельствует абсурд :
- Рассмотрим алгоритм сжатия без потерь . ПРОТИВ
- Рассмотрим набор всех потоков size : (с функцией вычисления размера потока). F НЕТ F : ∀ В ∈ F НЕТ , S z ( В ) знак равно НЕТ , Sz (A) = N> S z ( В )
- Поскольку алгоритм работает без потерь, существует взаимное соответствие между исходными потоками и сжатыми потоками . F НЕТ > ПРОТИВ ( F НЕТ ) )>
- Действительно, если бы алгоритм не был биективным, тогда было бы два потока с одним и тем же сжатым потоком . В В ′ B
- При распаковке невозможно узнать, следует ли восстанавливать поток или : для этого потребуется кодировать хотя бы один бит. В В ′
- Следовательно, либо алгоритм либо с потерей данных (например , невозможно восстановить поток ), или оба потока и не имеют один и тот же сжатый образ , так как алгоритм будет производить два различных сжатых потоков , по меньшей мере , один бит. ПРОТИВ В ′ В В ′ B
- Следовательно, алгоритм без потерь могут быть только биекция из червей , то есть сказать , что изображение не имеет два разных фона: . ПРОТИВ F НЕТ > ПРОТИВ ( F НЕТ ) )> ∀ B ∈ ПРОТИВ ( F НЕТ ) , ∃ ! В ∈ F НЕТ / ПРОТИВ ( В ) знак равно B ), \ существует! A \ in F_ / C (A) = B>
- Кроме того ,. ∀ ( В , В ′ ) ∈ F НЕТ 2 , ( В знак равно В ′ ⇒ ПРОТИВ ( В ) знак равно ПРОТИВ ( В ′ ) ) ∧ ( В ≠ В ′ ⇒ ПРОТИВ ( В ) ≠ ПРОТИВ ( В ′ ) ) <\ Displaystyle \ forall (A, A ') \ in F_ ^ , (A = A' \ Rightarrow C (A) = C (A ')) \ земля (A \ neq A' \ Rightarrow C (A) \ neq C (A '))>
- Принимая в качестве единицы размера (байтовые различных значений), общее число различных файлов размера это . 2 8 знак равно 256 = 256> НЕТ карта ( F НЕТ ) знак равно 256 НЕТ (F_ ) = 256 ^ >
- Общее количество файлов размером самое большее равно есть , что соответствует геометрической прогрессии : искомое значение поэтому . ( НЕТ - 1 ) карта ( ПРОТИВ ( F НЕТ ) ) знак равно ∑ я знак равно 1 НЕТ - 1 256 я (C (F_ )) = \ sum _ ^ 256 ^ > ( 256 НЕТ - 1 256 - 1 ) - 1 <\ displaystyle \ left (<\ frac <256 ^ -1>> \ right) -1>
- Мы тривиально наблюдаем, что : следовательно, файлов размера строго меньше, чем файлов размера . ( 256 НЕТ - 1 256 - 1 ) - 1 256 НЕТ <\ displaystyle \ left (<\ frac <256 ^ -1>> \ right) -1 1 ( НЕТ - 1 ) НЕТ
- Однако алгоритм биективен: так . Однако предыдущее неравенство дает , что абсурдно. ПРОТИВ карта ( F НЕТ ) знак равно карта ( ПРОТИВ ( F НЕТ ) ) (F_ ) = \ operatorname (C (F_ ))> карта ( ПРОТИВ ( F НЕТ ) ) карта ( F НЕТ ) (C (F_ ))
Таким образом, независимо от размера используемого потока или характера данных, всегда будет по крайней мере один сжатый поток, больший, чем его исходный, следовательно, несжимаемый поток.
Обратите внимание, что в крайнем случае однобайтового потока рассуждение тривиально (сжатый поток не может иметь нулевую длину в байтах), но не позволяет обобщить демонстрацию на все размеры файлов. характер данных в потоке.
ВНИМАНИЕ: это не верно только для алгоритмов сжатия без потерь . Напротив, используя алгоритм с потерями, можно гарантировать, что любой файл будет сжимаемым, за счет более или менее значительной потери информации во время сжатия / декомпрессии потока. карта ( ПРОТИВ ( F НЕТ ) ) карта ( F НЕТ ) (C (F_ ))
Совместное кодирование канала источника
Базы данных и сжатие
Некоторые базы данных позволяют сжимать данные таблиц и индексов без необходимости распаковывать данные, чтобы использовать их при последовательном чтении (сканировании), как при доступе с помощью поиска (поиска).
Эти принципы можно найти в Oracle и DB2.
В PostgreSQL нет техники сжатия, за исключением хранения LOB (больших объектов, таких как изображение, звук, видео, длинный текст или двоичные файлы электронных документов), которые по умолчанию сжимаются с помощью TOAST (техника хранения негабаритных атрибутов).
Читайте также: