
Дано сообщение скоро сессия построить эффективный код методом шеннона фано
Обновлено: 07.07.2024
К работе прилагается программа, написанная на языке программирования высокого уровня (Turbo Pascal).
Информатика и вычислительная техника – это область науки и техники, которая включает совокупность средств, способов и методов человеческой деятельности, направленных на создание и применение устройств связи, систем сбора, хранения и обработки информации.
Во многих случаях хранимая и передаваемая информация может представлять интерес для лиц, желающих использовать ее в корыстных целях.
Одним из методов защиты является кодирование.
Код – это правило, описывающее отображение одного набора знаков в другой набор знаков (или слов). Кодом также называют и множество образов при этом отображении.
Таким образом, знание методов обработки информации является базовым для инженеров, работа которых связана с вычислительными системами и сетями. Избыточность - дополнительные средства, вводимые в систему для повышения ее надежности и защищенности.
Таким образом, информатика занимается изучением обработки и передачи информации.
В работе отражается применение базовых понятий информатики.
СОДЕРЖАНИЕ ЗАДАНИЯ
Для проведения расчетов разработать программу на языке ПАСКАЛЬ.
а) если символы алфавита встречаются с равными вероятностями;
Сумма всех вероятностей должна быть равой единице, поэтому:
Определить, насколько недогружены символы во втором случае.
1.2. Число символов алфавита = m (номер варианта задания). Вероятности появления символов равны соответственно
Длительности символов τ1 = 1 сек; τ2 = 2 сек;
а) если символы алфавита встречаются с равными вероятностями;
Определить, насколько недогружены символы во втором случае.
ТЕОРЕТИЧЕСКАЯ ЧАСТЬ
КОЛИЧЕСТВЕННАЯ ОЦЕНКА ИНФОРМАЦИИ
Неопределенность, приходящаяся на символ первичного (кодируемого) алфавита, составленного из равновероятных и взаимонезависимых символов,
Для неравновероятных алфавитов энтропия на символ алфавита:
ВЫЧИСЛЕНИЕ СКОРОСТИ ПЕРЕДАЧИ ИНФОРМАЦИИ И ПРОПУСКНОЙ СПОСОБНОСТИ КАНАЛОВ СВЯЗИ
Скорость передачи информации также может быть представлена как

бит/сек,
где тау - время передачи одного двоичного символа.
В случае неравновероятных символов равной длительности:
В случае неравновероятных и взаимонезависимых символов разной длительности:


Смакс = бит/сек
Для двоичного кода:

Смакс бит/сек

бит/сек (15)

бит/сек


бит/сек (16)
Для симметричных бинарных каналов, в которых сигналы передаются при помощи двух качественных признаков и вероятность ложного приема , а вероятность правильного приема , потери учитываются при помощи условной энтропии вида

бит/сек (17)
пропускная способность таких каналов

бит/сек (18)
Для симметричного бинарного канала


бит/сек (19)
Для симметричных дискретных каналов связи с числом качественных признаков m > 2 пропускная способность

бит/сек (20)
,

где = μ - коэффициент сжатия (относительная энтропия). Н и Нмакс берутся относительно одного и того же алфавита.

L можно представить и как

где и - соответственно качественные признаки первичного и вторичного алфавитов. Поэтому для цифры 5 в двоичном коде можно записать

дв. симв.
Однако эту цифру необходимо округлить до ближайшего целого числа (в большую сторону), так как длина кода не может быть выражена дробным числом.
В общем случае, избыточность от округления:

где , k - округленное до ближайшего целого числа значение . Для нашего примера

Избыточность необходима для повышения помехоустойчивости кодов и ее вводят искусственно в виде добавочных символов. Если в коде всего n разрядов и из них несут информационную нагрузку, то характеризуют абсолютную корректирующую избыточность, а величина характеризует относительную корректирующую избыточность.
Если равной вероятности в подгруппах нельзя достичь, то их делят так, чтобы в верхней части (верхней подгруппе) оставались символы, суммарная вероятность которых меньше суммарной вероятности символов в нижней части (нижней подгруппе);
3) первой группе присваивается символ 0, а второй группе - символ 1;
4) каждую из образованных подгрупп делят на две части таким образом, чтобы суммарные вероятности вновь образованных подгрупп были по возможности равны;
5) первым группам каждой из подгрупп вновь присваивается 0, а вторым - 1. Таким образом, мы получаем вторые цифры кода. Затем каждая из четырех групп вновь делится на равные (с точки зрения суммарной вероятности) части до тех пор, пока в каждой из подгрупп не останется по одной букве.
Построенный код называют оптимальным неравномерным кодом (ОНК).
ПРАКТИЧЕСКАЯ ЧАСТЬ
a) Расчеты
1) рассчитывается первоначальные вероятности для неравновероятных символов алфавита.
2) выполняет нормирование указанных вероятностей.
3) рассчитывается энтропия алфавита из равновероятных символов.
4) производится расчет энтропии алфавита с неравновероятными символами и недогруженность в этом случае.
5) с учетом заданных длительностей символов вычисляется скорость передачи и избыточность.
6) строится оптимальный код по методу Шеннона-Фано.

рi = pi /(pi )

рi = 3,6
рi = 1
Hmax = log2 24 = ln 24/ln 2 = 4,5850 бит/символ
H = – (0,0417*log2 0,0417 + 0,0018*log2 0,0018 + 0,020*log2 0,0020 + 0,0022*log2 0,0022 + 0,0024*log2 0,0024 + 0,0026*log2 0,0026 + 0,0029*log2 0,0029 + 0,0033*log2 0,0033 + 0,0037*log2 0,0037 + 0,0042*log2 0,0042 + 0,0048*log2 0,0048 + 0,0055*log2 0,0055 + 0,0064*log2 0,0064 + 0,0076*log2 0,0076 + 0,0091*log2 0,0091 + 0,0111*log2 0,0111 + 0,0139*log2 0,0139 + 0,0179*log2 0,0179 + 0,0238*log2 0,0238 + 0,0333*log2 0,0333 + 0,0500*log2 0,0500 + 0,0833*log2 0,0833 + 0,1667*log2 0,1667 + 0,5000*log2 0,5000) =
Недогруженность символов в данном случае:
N = Нmax – Н = 4,5850 – 2,6409 = 1,9441 бит/символ
Вычисление скорости передачи информации.
С= – (0,0417*log2 0,0417 + 0,0018*log2 0,0018 + 0,020*log2 0,0020 + 0,0022*log2 0,0022 + 0,0024*log2 0,0024 + 0,0026*log2 0,0026 + 0,0029*log2 0,0029 + 0,0033*log2 0,0033 + 0,0037*log2 0,0037 + 0,0042*log2 0,0042 + 0,0048*log2 0,0048 + 0,0055*log2 0,0055 + 0,0064*log2 0,0064 + 0,0076*log2 0,0076 + 0,0091*log2 0,0091 + 0,0111*log2 0,0111 + 0,0139*log2 0,0139 + 0,0179*log2 0,0179 + 0,0238*log2 0,0238 + 0,0333*log2 0,0333 + 0,0500*log2 0,0500 + 0,0833*log2 0,0833 + 0,1667*log2 0,1667 + 0,5000*log2 0,5000) /
(1*0,0417 + 2*0,0018 + 3*0,020 + 4*0,0022 + 5*0,0024 + 6*0,0026 + 7*0,0029 + 8*0,0033 + 9*0,0037 + 10*0,0042 + 11*0,0048 + 12*0,0055 + 13*0,0064 + 14*0,0076 + 15*0,0091 + 16*0,0111 + 17*0,0139 + 18*0,0179 + 19*0,0238 + 20*0,0333 + 21*0,0500 + 22*0,0833 + 23*0,1667 + 24*0,5000) = 0,1244 бит/сек
D = 1 – (Н/Нmax ) = 1 – (2,6409 / 4,5850) = 0,4240
Построение оптимального кода
| 1 | p24=0,5000 | 0,5 | 0 | 0 | ||||||||||
| 2 | p23=0,1667 | 0,5 | 1 | 0,25 | 1 | 0,1666 | 1 | 111 | ||||||
| 3 | p22=0,0833 | 1 | 1 | 0,0833 | 0 | 110 | ||||||||
| 4 | p21=0,0500 | 1 | 0,25 | 0 | 0 | 0,05 | 1 0 | 1000 | ||||||
| 5 | p1=0,0417 | 1 | 0 | 0 | 0,0690 | 1 | 0,0357 | 1 | 10011 | |||||
| 6 | p20=0,0333 | 1 | 0 | 0,1190 | 0 | 1 | 0,0333 | 0 | 10010 | |||||
| 7 | p19=0,0238 | 1 | 0 | 1 | 1 | 0,0428 | 1 | 0,0178 | 1 | 101111 | ||||
| 8 | p18=0,0179 | 1 | 0 | 1 | 1 | 1 | 0,025 | 0 | 0,0138 | 0 | 1011100 | |||
| 9 | p17=0,0139 | 1 | 0 | 1 | 1 | 0 | 0,025 | 1 | 101101 | |||||
| 10 | p16=0,0111 | 1 | 0 | 1 | 0,0666 | 1 | 1 | 0 | 101110 | |||||
| 11 | p15=0,0091 | 1 | 0 | 1 | 0,0642 | 0 | 0 | 1 | 0,0090 | 1 | 1010011 | |||
| 12 | p14=0,0076 | 1 | 0 | 1 | 0 | 0 | 1 | 0,0102 | 0 | 0,0054 | 0 | 10100100 | ||
| 13 | p13=0,0064 | 1 | 0 | 1 | 0 | 0 | 0,0166 | 0 | 0,0064 | 1 | 1010001 | |||
| 14 | p12=0,0055 | 1 | 0 | 1 | 0 | 0 | 0,0166 | 1 | 0,0064 | 1 | 1010011 | |||
| 15 | p11=0,0048 | 1 | 0 | 1 | 0 | 0,0333 | 1 | 1 | 1 | 0,0047 | 1 | 10101111 | ||
| 16 | p10=0,0042 | 1 | 0 | 1 | 0 | 1 | 1 | 0,0088 | 1 | 0 | 0,0032 | 0 | 101011100 | |
| 17 | p9=0,0037 | 1 | 0 | 1 | 0 | 1 | 1 | 0,0078 | 0 | 0,0036 | 1 | 10101101 | ||
| 18 | p8=0,0033 | 1 | 0 | 1 | 0 | 1 | 1 | 0,0078 | 1 | 0,0036 | 0 | 10101110 | ||
| 19 | p7=0,0029 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 10101010 | ||||
| 20 | p6=0,0026 | 1 | 0 | 1 | 0 | 1 | 0,0167 | 0 | 1 | 0,0026 | 1 | 0,0026 | 1 | 101010111 |
| 21 | p5=0,0024 | 1 | 0 | 1 | 0 | 1 | 0,0147 | 0 | 1 | 1 | 0,0024 | 0 | 101010110 | |
| 22 | p4=0,0022 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0,0022 | 0 | 10101000 | |||
| 23 | p3=0,0020 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0,0038 | 1 | 0,0020 | 1 | 101010011 | |
| 24 | p2=0,0018 | 1 | 0 | 1 | 0 | 1 | 0 | 0,0083 | 0 | 1 | 0,0018 | 0 | 101010010 |
| Буква | Вероятность появления буквы | Кодовые слова | Число знаков в кодовом слове | Pi ·li |
| A[1] (p24) | 0,5000 | 0 | 1 | 0,5 |
| A[2] (p23) | 0,1667 | 111 | 3 | 0,50001 |
| A[3] (p22) | 0,0833 | 110 | 3 | 0,2500 |
| A[4] (p21) | 0,0500 | 1000 | 4 | 0,2000 |
| A[5] (p1) | 0,0417 | 10011 | 5 | 0,2083 |
| A[6] (p20) | 0,0333 | 10010 | 5 | 0,1667 |
| A[7] (p19) | 0,0238 | 101111 | 6 | 0,1429 |
| A[8] (p18) | 0,0179 | 1011100 | 7 | 0,1250 |
| A[9] (p17) | 0,0139 | 101101 | 6 | 0,0833 |
| A[10] (p16) | 0,0111 | 101110 | 6 | 0,0667 |
| A[11] (p15) | 0,0091 | 1010011 | 7 | 0,0636 |
| A[12] (p14) | 0,0076 | 10100100 | 8 | 0,0606 |
| A[13] (p13) | 0,0064 | 1010001 | 7 | 0,0449 |
| A[14] (p12) | 0,0055 | 1010011 | 7 | 0,0385 |
| A[15] (p11) | 0,0048 | 10101111 | 8 | 0,0381 |
| A[16] (p10) | 0,0042 | 101011100 | 9 | 0,0375 |
| A[17] (p9) | 0,0037 | 10101101 | 8 | 0,0294 |
| A[18] (p8) | 0,0033 | 10101110 | 8 | 0,0261 |
| A[19] (p7) | 0,0029 | 10101010 | 8 | 0,0234 |
| A[20] (p6) | 0,0026 | 101010111 | 9 | 0,0237 |
| A[21] (p5) | 0,0024 | 101010110 | 9 | 0,0214 |
| A[22] (p4) | 0,0022 | 10101000 | 8 | 0,0173 |
| A[23] (p3) | 0,0020 | 101010011 | 9 | 0,0178 |
| A[24] (p2) | 0,0018 | 101010010 | 9 | 0,0163 |

2 Смотреть ответы Добавь ответ +10 баллов

Ответы 2
Это получатся ошибка,тоесть база данных жёсткого диска устарела просто обнови жёсткий диск.если не получается то это просто док текст.
сложно давай сам окей а я покушаю
Другие вопросы по Информатике

Язык python (возможно, кто знает pascal тоже самое) как составить цикл while, чтобы пользователь вводил в нем в пределах от 10 до 25000. если он введет меньше 10 или больше 25000.
Решить на паскале задано два массива a (8) и b (8), которые упорядкованi по убыванию. определить кiлькicть элементов, что в двух массивах и их значения. вывести выходные массивы, э.
С. написать программу для : пользователь вводит с клавиатуры величину, выраженную в килобайтах. программа переводит ее в биты и мегабайты. в паскале.
Алгоритм метода Шеннона-Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано, и он имеет большое сходство с алгоритмом Хаффмана. Алгоритм основан на частоте повторения. Так, часто встречающийся символ кодируется кодом меньшей длины, а редко встречающийся — кодом большей длины.
В свою очередь, коды, полученные при кодировании, префиксные. Это и позволяет однозначно декодировать любую последовательность кодовых слов. Но все это вступление.
Для работы оба алгоритма должны иметь таблицу частот элементов алфавита.
Таким образом, видно, что алгоритм Хаффмана как бы движется от листьев к корню, а алгоритм Шеннона-Фано, используя деление, движется от корня к листям.
Ну вот, быстро осмыслив информацию, можно написать код алгоритма Шеннона-Фано на паскале. Попросили именно на нем написать. Поэтому приведу листинг вместе с комментариями.
Ну вот собственно и все, о чем я хотел рассказать. Всю информацию можно взять из википедии. На рисунках приведены частоты сверху.
Объектом исследования работы является изучение принципов эффективного кодирования методом Шеннона-Фано.
Цель работы состоит в создании программы эффективного кодирования методом Шеннона-Фано.
К полученным результатам относится приложение, демонстрирующее эффективное кодирование методом Шеннона-Фано.
Содержание
1.Теоретические сведения .………………………………..…………. 6
1.2.Основные сведения о методе кодирования Шеннона-Фано……. 6
1.3.Алгоритм вычисления кодов Шеннона-Фано……………………. 7
1.4.Общие сведения и пример решения задачи………………………..7
2.Требования к программному изделию……………………………….10
4.Результаты и листинг программы……………………. …………….12
Список использованной литературы…………..…….……..………….19
Информатика и вычислительная техника – это область науки и техники, которая включает совокупность средств, способов и методов человеческой деятельности, направленных на создание и применение устройств связи, систем сбора, хранения и обработки информации.
Во многих случаях хранимая и передаваемая информация может представлять интерес для лиц, желающих использовать ее в корыстных целях.
Одним из методов защиты является кодирование.
Код – это правило, описывающее отображение одного набора знаков в другой набор знаков (или слов). Кодом также называют и множество образов при этом отображении.
Таким образом, знание методов обработки информации является базовым для инженеров, работа которых связана с вычислительными системами и сетями. Избыточность - дополнительные средства, вводимые в систему для повышения ее надежности и защищенности.
Таким образом, информатика занимается изучением обработки и передачи информации.
В работе отражается применение базовых понятий информатики.
1.1 Эффективное кодирование
Этот вид кодирования используется для уменьшения объемов информации на носителе - сигнале.
Для кодирования символов исходного алфавита используют двоичные коды переменной длины: чем больше частота символа, тем короче его код. Эффективность кода определяется средним числом двоичных разрядов для кодирования одного символа – lср по формуле
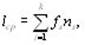
где k – число символов исходного алфавита;
ns – число двоичных разрядов для кодирования символа s;
fs – частота символа s; причем
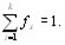

где n – мощность кодируемого алфавита,
fi – частота i-го символа кодируемого алфавита.
1.2 Основные сведения о методе кодирования Шеннона-Фано
1.3 Алгоритм вычисления кодов Шеннона-Фано
Код Шеннона — Фано строится с помощью дерева. Построение этого дерева начинается от корня. Всё множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины. Ветви кодового дерева размечаем символами 1 и 0, как в случае кода Хаффмана.
При построении кода Шеннона — Фано разбиение множества элементов может быть произведено, вообще говоря, несколькими способами. Выбор разбиения на уровне n может ухудшить варианты разбиения на следующем уровне (n + 1) и привести к неоптимальности кода в целом. Другими словами, оптимальное поведение на каждом шаге пути ещё не гарантирует оптимальности всей совокупности действий. Поэтому код Шеннона — Фано не является оптимальным в общем смысле, хотя и дает оптимальные результаты при некоторых распределениях вероятностей. Для одного и того же распределения вероятностей можно построить, вообще говоря, несколько кодов Шеннона — Фано, и все они могут дать различные результаты. Если построить все возможные коды Шеннона — Фано для данного распределения вероятностей, то среди них будут находиться и все коды Хаффмана, то есть оптимальные коды.
1.4 Общие сведения и пример решения задачи
и порядок их размещения не играет роли.
1 шаг: располагаем сообщения в порядке возрастания порядковых номеров.
3 шаг: первой группе в качестве первого символа кодовых слов присваиваем 0, второй группе — 1.
4 шаг: разбиваем каждую из подгрупп еще на две равновероятные подгруппы, затем каждой первой подгруппе в качестве второго символа присваиваем 0, авторой - 1, и записываем их в колонку.
5 шаг: каждую из подгрупп разбиваем на две равновероятные части и первой из них присваиваем 0, а второй-1 и, таким образом, в колонке появляется значение третьего символа.
Среднее число двоичных знаков на букву кода
Lcp=N, то есть код оптимальный.
2.Требования к программному изделию
2.1.Требования к функциональным характеристикам
Разработанная программа пригодна для эффективного кодирования методом Шеннона-Фано.
2.2. Контроль входной и выходной информации.
Описание программы
3.1. Интерфейс пользователя
На рисунке 1 показан внешний вид программы при запуске
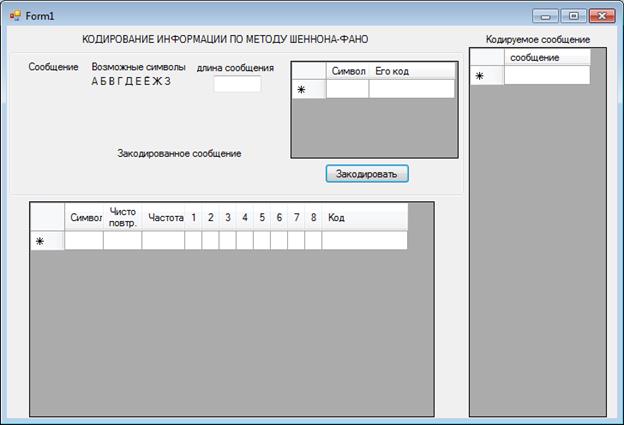
Также в программе находится поле ввода данных для кодирования и поле вывода закодированной информации.
Читайте также: