
Создание базы данных реферат
Обновлено: 05.07.2024
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТА
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования
КУРСОВАЯ РАБОТА
Выполнила студентка Факультет: ЭСУ Специальность: ЭУТ 505
Номер зачетной книжки: 09-ЭУТк-214
Рассматриваются основные особенности создания, редактирования, хранения и передачи заказчику баз данных в среде Microsoft Office. Для получения оценок сначала рассматриваются особенности реализации баз данных (БД) в приложении MS Excel, а затем в MS Access.
После уточнения формирования исходных данных на конкретном примере, заданном вариантом индивидуального задания, разрабатываются запросы. На основании запросов определяются основные характеристики БД: количество полей, тип данных, точность используемых числовых значений и т. д.
Реализация запросов в MS Excel, в том числе с использованием макросов, позволяет определить основные характеристики таблицы. Затем на конкретных примерах иллюстрируется работа запросов в MS Excel.
Анализ исходной таблицы позволяет заключить о целесообразности ее деления на части с целью уменьшения условной площади (количества ячеек). На рассматриваемом примере показана эффективность деления исходной таблицы на две части.
Проиллюстрированы варианты реализации запросов в MS Access. Основные положения обоснованы и проиллюстрированы.
- фамилии и инициалы владельца
- профиль торгового предприятия
- площадь торгового предприятия
- площадь торговых залов
- сведения о районе расположения (название, фамилия и инициалы главы администрации, телефон)
1. Заполнение и редактирование таблиц базы данных.
2. Вычисление среднего количества продавцов, обслуживающих 10 м 2 площади торгового зала
3. Формирование списка магазинов указанного профиля, площадь торговых залов которого не превышает указанной величины.
4. Вывод количества торговых предприятий, принадлежащих каждому владельцу.
5. Формирование отчета, содержащего следующие данные: название магазина, профиль торгового предприятия с группировкой по районам расположения торговых предприятий
База данных в Excel – это список связанных данных, в котором строки данных являются записями, столбцы – полями. Верхняя строка списка содержит название каждого из столбцов. Ссылка может быть задана либо как диапазон ячеек, либо как имя, соответствующему диапазону списка.

Рисунок 1 - Рабочее окно EXCEL
Для ввода информации в ячейки рабочего листа вначале следует сделать ячейку активной, переместив в нее указатель мыши и щелкнуть один раз правой кнопкой мыши. После этого можно либо просто вводить данные с клавиатуры, либо щелкнуть левой кнопкой мыши в строке формул над рабочим листом и после этого вводить данные.

Рисунок 2 - Заполненная база данных
1.2 Вычисление среднего количества продавцов, обслуживающих 10 м 2 площади торгового зала
Для этого вводим дополнительный столбец, где считаем среднее количество продавцов на 10 м2 площади для каждого магазина. Данные в этом поле получаем по формуле:
=Количество продавцов/(Площадь ТЗ/10)

Рисунок 3. Вычисление среднего количества продавцов
После этого используем статистическую функцию =СРЗНАЧ() для подсчета среднего значения по столбцу:

Рисунок 4. Среднее количество продавцов по всем магазинам.
Для этого используем автофильтр. Он позволяет вывести на рабочий лист все записи, удовлетворяющие определенным требованиям.
Автофильтр создаётся следующим образом: выделяем всю таблицу и выбираем

Рисунок 5 - Создание автофильтра

Для создания списка удовлетворяющего запросу. Например, формирование списка магазинов указанного профиля, площадь торговых залов которого не превышает указанной величины. (см. рис.6)
Рисунок 6 - Формирование списка, удовлетворяющего запросу
Далее выбираем нужное условие. Например, меньше или равно 1100. (см. рис.7)

Рисунок 7 - Задание условия

Рисунок 8 - Готовый список по запросу
1.4 Вывод количества торговых предприятий, принадлежащих каждому владельцу

Рисунок 9 – Настройка группировки данных

Рисунок 10. Количество предприятий, принадлежащих каждому владельцу
1.5 Формирование отчета, содержащего следующие данные: название магазина, профиль торгового предприятия с группировкой по районам расположения торговых предприятий
С помощью автофильтра необходимо выполнить группировку магазинов по районам.
Создать 2 дополнительные мини-таблицы, в которых будут подсчитаны общее число магазинов в каждом районе. Подсчет выполняется по средствам функции

=СУММЕСЛИ (диапазон; критерий; диапазон суммирования). В данном случае за диапазон суммирование берется столбец(по числу станций) единиц.
Рисунок 11 – Подсчет общего количества магазино
Microsoft Access – это система управления базами данных (СУБД), предназначенная для создания и обслуживания баз данных, обеспечения доступа к данным и их обработки.
Базы данных содержат различные объекты, основными из которых являются таблицы. Структура простейшей базы данных соответствует структуре ее двухмерной таблицы, содержащей столбцы и строки. Их аналогами в структуре простейшей базы данных являются поля и записи.

 |
Для создания в будущем запросов необходимо создать 3(три) таблицы, из которых будут запрашиваться данные.
Рисунок 13 - Создание таблицы в режиме конструктора
Создаем справочник магазинов:

Рисунок 13 - создание полей для таблицы № 1 – справочник магазинов
Создаем справочник районов

Рисунок 14 - Создание полей для таблицы № 2 – справочник районов
Создаем таблицу для хранения данных:

Рисунок 15 - Создание полей для таблицы № 3 – Данные
После этого устанавливаем связи между таблицами:

Рисунок 16 - Создание связей между таблицами
Получаем структуру готовой базы данных:

Рисунок 17 – Структура базы данных
Новая таблица не имеет записей, а содержит только наименование столбцов (полей). Для заполнения таблицы данными курсор устанавливает в требуемую ячейку указателем мыши. Переход к следующей ячейке можно выполнять с помощью клавиши , а в предыдущее поле можно попасть с помощью комбинации клавиш . После заполнения последней ячейки и нажатия клавиши курсов переместится в первую ячейку следующей строки, и Access автоматически сохранит только что введенную запись. Таким образом, после заполнения таблицы данными их сохранять не надо; Access все введенные данные сохраняет автоматически. Однако если при работе с таблицами происходит изменение ее структуры (например, менялась ширина столбцов), то Access попросит подтвердить эти изменения. Для увеличения или уменьшения ширины столбцов в таблице (в режиме конструктора) нужно указатель мыши установить в строку заголовка столбцов, на границу между столбцами, и перетащите мышь вправо или влево.

Рисунок 18 – Заполненная таблица № 1 - магазины

Рисунок 19 - Заполненная таблица № 2 – районы

Рисунок 20 - Заполненная таблица № 3 – данные
Это делается с помощью запросов. Основным назначением запросов является отбор данных по критериям поиска. Кроме того, с помощью запросов можно добавлять данные в таблицу, удалять и обновлять их.
Для получения необходимой информации используем построитель выражения

Рисунок 21 – Построитель выражения
В итоге получаем запрос:
SELECT Avg([КолПродавцов]/[Торговая площадь]) AS Выражение1

Рисунок 22 – Результат выполнения запроса

Рисунок 23 – Создание простого запроса

Рисунок 24 - Вывод данных по простому запросу

Рисунок 25 – Получение числа магазинов

Рисунок 26 – Вывод данных по запросу с группировкой
Так же, как и прежде сформируем запрос.

Рисунок 27 - Создание запроса конструктором

Теперь точно так же формируем запрос, но чтобы запрос выглядел в виде красиво оформленной таблицы, необходимо создать отчет.

Рисунок 29 - Порядок создания отчета
Выбираем запрос который мы создали для этого задания по аналогии с предыдущими пунктами. С помощью стрелок перекидываем строки из доступных полей в выбранные и нажимаем далее.
Выбираем вид представления данных – по районам:

 |
Рисунок 30 - Порядок создания отчета
Рисунок 31 - Порядок создания формы

Рисунок 32 - готовая отчет «Список магазинов по районам
2. Н .В .Байдина, Н. Ф. Костянко. СБОРНИК ЗАДАНИЙ к выполнению лабораторных, контрольных и курсовой работ по дисциплине Информатика. Для студентов заочной формы обучения всех специальностей. С.-Пб.: ПГУПС 2005. - 59 c.
В современном мире человеку приходится сталкиваться с огромными массивами однородной информации. Эту информацию необходимо упорядочить каким-либо образом, обработать однотипными методами и в результате получить сводные данные или разыскать в массе конкретную информацию. Этой цели служат базы данных. Используя Microsoft Office Access, который входит в пакет офисных приложений Microsoft Office, мы можете самостоятельно создать базу данных.
Под базой данных принято понимать объективную форму представления и организации совокупности данных (статей, расчетов и так далее), систематизированных таким образом, чтобы эти данные могли быть найдены и обработаны с помощью электронной вычислительной машины.
Создание реляционной базы данных с помощью СУБД начинается с формирования структуры таблиц. При этом определяется состав полей и задается их описание. После определения структуры таблиц создается схема данных, в которой устанавливаются связи между таблицами. Access запоминает и использует эти связи при заполнении таблиц и обработке данных.
При создании базы данных важно задать параметры, в соответствии с которыми Access будет автоматически поддерживать целостность данных. Для этого при определении структуры таблиц должны быть указаны ограничения на допустимые значения данных, а при создании схемы данных на основе нормализованных таблиц должны быть заданы параметры поддержания целостности связей базы данных.
Завершается создание базы данных процедурой загрузки, т.е. заполнением таблиц конкретными данными. Особое значение имеет технология загрузки взаимосвязанных данных. Удобным инструментом загрузки данных во взаимосвязанные таблицы являются формы ввода/вывода, обеспечивающие интерактивный интерфейс для работы с данными базы. Формы позволяют создать экранный аналог документа источника, через который можно вводить данные в несколько взаимосвязанных таблиц.
Для анализа данных или распечатки их определенным образом используется отчет. Отчет – это объект, предназначенный для создания документа на основе данных из таблицы или запроса. Этот документ можно распечатать или включить в документ другого приложения (Word, Excel).
Перед созданием базы данных необходимо ответить на следующие вопросы:
−Каково назначение базы данных и кто будет ею пользоваться?
−Какие таблицы (данные) будет содержать база данных?
−Какие запросы и отчеты могут потребоваться пользователям этой базы данных?
−Какие формы может потребоваться создать?
Отвечая на эти вопросы, можно разработать проект базы данных и создать полезную и удобную в использовании базу данных.
1. Создание базы данных. Таблица в Microsoft Access.
В Microsoft Access поддерживаются три метода создания Базы данных:
1.Создание базы данных с помощью мастера
2.Создание базы данных с помощью шаблона
3.Создание пустой базы данных без помощи мастера
Мы воспользуемся третьим методом, то есть создадим пустую базу данных без помощи мастера. Этот метод удобен, если требуется начать создание базы данных по собственному проекту, в которой можно создать пустую базу данных, а затем добавить в нее таблицы, формы, отчеты и другие объекты — это наиболее гибкий способ, но он требует отдельного определения каждого элемента базы данных.



Строка Создание таблицы в режиме конструктора в рабочем поле окна базы данных или Конструктор в окне Новая таблица определяет выбор основного способа создания новой таблицы, при котором создание таблицы начинается с определения ее структуры в режиме конструирования. В этом режиме пользователь может сам установить параметры всех элементов структуры таблицы.



2. Создание связей между таблицами.
При создании связей в схеме данных используем проект логической структуры базы данных, в котором показаны одно-многозначные связи. Каждая из этих связей устанавливается по ключу связи (простому или составному). Такой ключ в одной из связанных таблиц (главной) должен быть уникальным ключом, а в другой таблице может являться частью уникального ключа или не входить в состав ключа таблицы. Одно-многозначные связи — основные в реляционных базах данных. Одно-однозначные связи используются лишь в случаях, когда приходится распределять большое количество полей, определяемых одним и тем же ключом, по разным таблицам, имеющим разный регламент обслуживания.


3. Создание запросов в Microsoft Access.
Microsoft Access объединяет сведения из разных источников в одной реляционной базе данных. Для поиска и отбора данных, удовлетворяющих определенным условиям создается запрос. С помощью запросов можно просматривать, анализировать и изменять данные из нескольких таблиц, выполнять встроенные или специальные вычисления. Запросы также используются в качестве источника данных для форм и отчетов.Наиболее часто используется запрос на выборку. При его выполнении данные, удовлетворяющие условиям отбора, выбираются из одной или нескольких таблиц и выводятся в определенном порядке.
В Microsoft Access после создания таблиц и организации связей между ними создаются запросы.
Запрос можно создать с помощью мастера или самостоятельно. В этом случае следует в режиме конструктора выбрать таблицы или запросы, содержащие нужные данные и заполнить бланк запроса.

4. Создание форм в Microsoft Access.
Форма — это объект базы данных, который можно использовать для ввода, изменения или отображения данных из таблицы или запроса. Формы могут применяться для управления доступом к данным: с их помощью можно определять, какие поля или строки данных будут отображаться. Например, некоторым пользователям достаточно видеть лишь несколько полей большой таблицы. Если предоставить им форму, содержащую только нужные им поля, это облегчит для них использование базы данных. Для автоматизации часто выполняемых действий в форму можно добавить кнопки и другие функциональные элементы.

5. Создание отчетов в Microsoft Access.
Отчет – это форматированное представление данных, которое выводится на экран, в печать или файл. Они позволяют извлечь из базы нужные сведения и представить их в виде, удобном для восприятия, а также предоставляют широкие возможности для обобщения и анализа данных. При печати таблиц и запросов информация выдается практически в том виде, в котором хранится. Часто возникает необходимость представить данные в виде отчетов, которые имеют традиционный вид и легко читаются. Подробный отчет включает всю информацию из таблицы или запроса, но содержит заголовки и разбит на страницы с указанием верхних и нижних колонтитулов.
В Microsoft Access можно создавать отчеты различными способами:
―Автоотчет: в столбец,
СУБД Access предоставляет необходимые средства для работы с базами данных неискушенному пользователю, позволяя ему легко и просто создавать базы данных, вводить в них информацию, обрабатывать запросы и формировать отчеты. К сожалению, встроенная система помощи недостаточно понятно объясняет начинающему пользователю порядок работы, поэтому возникает необходимость в пособии.
Список использованной литературы:
1. Информатика: Практикум по технологии работы на компьютере. Учебное пособие / Под ред. Н.В.Макаровой. 3-е изд. М.: Финансы и статистика, 2004.
3. Лазарев И.П.. “Microsoft Access для чайников”.. СПб – Питер, 2004. – 256 с.
4. Марченко А. П. Microsoft Access : Краткий курс. – СПб.: Питер, 2005. – 288 с.
Иерархическая модель базы данных. Операции над данными, определенные в иерархической модели. Запуск Access и открытие базы данных. Создание таблиц путем ввода данных, запросов с помощью мастера запросов, таблиц с помощью мастера и в режиме конструктора.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | реферат |
| Язык | русский |
| Дата добавления | 29.03.2011 |
| Размер файла | 1,7 M |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Глава1. Иерархический модель база данных
1.1 Иерархическая модель данных
1.2 Структура иерархического модель данных
1.3 Операции над данными, определенные в иерархической модели
Глава 2. Создать база данных
2.1 Запуск Access и открытие база данных
2.2 Создание таблиц путем ввода данных
2.3 Создание запрос с помощью Мастера запросов
2.4 Создание таблиц с помощью мастера
2.5 Создание таблиц в режиме конструктор
Иерархическая модель данных (МД) была исторически первой структурой БД, видимо, из-за того, что древовидные иерархические структуры широко используются в повседневной человеческой деятельности. Это всевозможные классификаторы, ускоряющие поиск требуемой информации, иерархические функциональные структуры управления. Наиболее известной иерархической СУБД до сих пор остается IMS .
Если структура запроса совпадает со структурой иерархической БД, то такая модель данных обладает самым высоким быстродействием и потому чаще всего применяется в суперЭВМ. В противном случае быстродействие может резко снизиться или данные совсем могут быть не получены. Чтобы избежать последнего неприятного случая, в иерархическую МД вводят еще один тип связи - логическую, о которой поговорим позднее. Иерархические МД, как и сетевые могут быть представлены в виде графов: сегмент отражается в виде узла. В графической диаграмме схемы базы данных вершины графа также используются для интерпретации типов сущностей, а дуги - типов связей между типами сущностей. При реализации каждая вершина графа представляется совокупностью описаний экземпляров сущности соответствующего типа.
Глава 1. Иерархическая модель база данных
1.1 Иерархическая модель данных
Модель данных - некоторая абстракция, которая, будучи приложенной к конкретным данным, позволяется трактовать их уже как информацию, то есть модель - это не только данные, но и связи между ними.
За время развития баз данных выделились основные модели данных: сетевые, иерархические, реляционные.
Иерархия - это разновидность сети, являющаяся совокупностью деревьев (лесом), в которой все связи направлены от отца к сыну.
Основными информационными единицами являются база данных, сегмент и поле. Поле - это минимальная неделимая единица данных, доступная пользователю с помощью СУБД. Сегмент (который в терминологии Data Base Task Group, DBTG называют записью) определяет два понятия - тип сегмента (записи) и экземпляр сегмента (записи).
Тип сегмента - это именованная совокупность типов элементов данных, в него входящих. Экземпляр сегмента образуется из конкретных значений полей или элементов данных, в него входящих. Каждый тип сегмента образует набор однородных записей.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами (родительскому по иерархии экземпляру сегмента может соответствовать множество экземпляров подчиненного сегмента). Схема иерархической базы данных представляет собой совокупность отдельных деревьев, каждое из которых называется физической базой данных. Каждая физическая база данных удовлетворяет иерархическим ограничениям:
- у нее существует один корневой сегмент, у которого нет родителя;
- каждый сегмент может быть связан с произвольным числом подчиненных сегментов;
- каждый подчиненный сегмент может иметь только одного родителя.
В рамках иерархической модели выделяют языковые средства описания данных (Data Definition Language, DDL) и манипулирования данными (Data Manipulation Language, DML).
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом как на новую технологию БД, так и на новую технику.
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева).
Представление связей в иерархической модели
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается (примером такой “внешней” ссылки может быть содержимое поля Каф_Номер в экземпляре типа записи Куратор).
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия
1.2 Структура иерархического модель данных
Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных.
Атрибут (элемент данных) - наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
Запись - именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи - конкретная запись с конкретным значением элементов.
Групповое отношение - иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути.
При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами (диаграмма Бахмана).
Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись. При удалении родительской записи автоматически удаляются все подчиненные.
1.3 Операции над данными, определенные в иерархической модели
ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
УДАЛИТЬ некоторую запись и все подчиненные ей записи.
извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей
извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева)
В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.)
Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название "навигационного".
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Графическим способом представления иерархической структуры является дерево.
Дерево представляет собой иерархию элементов, называемых узлами. Под элементами понимается совокупность атрибутов, описывающих объекты. В модели имеется корневой узел (корень дерева), который находится на самом верхнем уровне и не имеет узлов, стоящих выше него. У одного дерева может быть только один корень. Остальные узлы, называемые порожденными, связаны между собой следующим образом: каждый узел имеет только один исходный, находящийся на более высоком уровне, и любое число (один, два или более, либо ни одного) подчиненных узлов на следующем уровне.
Примером простого иерархического представления может служить административная структура высшего учебного заведения: институт - отделение - факультет - студенческая группа (см. рис. 2.3).
Рис. 1.3 Пример иерархической структуры
Глава 2. Создать база данных
2.1 Запуск Access и открытие база данных
Для того чтобы создать база данных мы используем MS Access.
Для того чтобы запустить Microsoft Office Access необходимо
И у нас откроется диалоговой окно MS Access
2.2 Создание таблиц путем ввода данных
1.Открыть окно новой или существующей базы данных и в нем открыть список таблиц.
2. Выделить в списке таблиц ярлык создание таблиц путем ввода данных и дважды щелкнуть по нему левой кнопкой мыши. Появится пустая таблица со стандартными названиями столбцов: Поле1, Поле2, и.т.д. По умолчанию для создания таблицы предоставляется десять полей.
3. В поля этой таблицы нужно ввести требуемые данные. Тип данных в одном поле (столбце) во всех записях должен быть одинаковым.
4. Можно ввести свои заголовки столбцов, для чего дважды щелкните по заголовку столбца. После этого стандартное название столбца подсвечивается и вы можете вводить свое название.
2.3 Создание запрос с помощью Мастера запросов
Чтобы создать запрос при помощи Мастера запросов необходимо:
2.4 Создание таблиц с помощью мастера
Для того чтобы создать таблиц с помощью мастера таблиц нам необходимо:
2.5 Создание таблиц в режиме конструктор
Теперь мы познакомимся с режимом Конструктора. В режиме Конструктора таблицы создаются путем задания имени полей, их типов и свойств. Чтобы создать таблицу в режиме Конструктора, необходимо:
иерархическая модель база данное access
В иерархической модели данных действуют более жесткие внутренние ограничения на представление связей между сущностями, чем в сетевой модели. Основные внутренние ограничения иерархической модели данных:
1) все типы связей функциональные (1:1, 1:М, М:1);
2) структура связей древовидная.
Результатом действия этих ограничений является ряд особенностей процесса структуризации данных в иерархической модели.
Древовидная структура (дерево) - это связный неориентированный граф, который не содержит циклов (петель) из замкнутых путей. Обычно при работе с деревом выделяют конкретную вершину, которую определяют как корень дерева, и рассматривают ее особо: в нее не заходит ни одно ребро. В этом случае дерево становится ориентированным. Корневое дерево можно определить следующим образом:
1) имеется единственная особая вершина, называемая корнем, в которую не заходит ни одно ребро;
2) во все остальные вершины заходит только одно ребро, а исходит произвольное (0, 1, 2, . n) количество ребер;
3) не имеется циклов.
В программировании используется другое определение дерева, позволяющее при решении задач рассматривать дерево как структуру, состоящую из меньших деревьев (или поддеревьев), т.е. как рекурсивную структуру.
Подобные документы
Создание базы данных в Microsoft Access с помощью мастера шаблонов. Создание таблиц путём ввода данных, с помощью мастера таблиц или таблицы в режиме конструктора таблиц. Создание запросов в Microsoft Access, с помощью мастера или конструктора запросов.
реферат [27,3 K], добавлен 08.09.2010
Компоненты реляционной базы данных Microsoft Access. Создание структуры таблиц и определение связей между ними. Проектирование форм для сводных таблиц и запросов с помощью конструктора окон. Разработка и создание автоотчетов и запросов на выборку данных.
реферат [3,3 M], добавлен 29.01.2011
Разработка структуры таблиц собственной базы данных Access. Последовательность действий при создании структуры таблиц с помощью мастера и конструктора. Создание и редактирование модулей. Создание отчета на основе нескольких таблиц с помощью мастера.
лабораторная работа [25,3 K], добавлен 16.11.2008
Разработка базы данных деканата магистратуры, включающую в себя информация о студентах, форму обучения, экзамены. Создание таблиц и запросов в режиме конструктора, отчета с помощью мастера отчетов. Вывод данных с помощью форм. Вкладки кнопочной формы.
курсовая работа [2,9 M], добавлен 18.07.2014
Интерфейс и начало работы в Microsoft Access. Построение реляционной базы данных и разработка инфологической модели. Разработка формы с помощью мастера форм и запроса в режиме конструктора. Создание таблиц данных. Поиск и замена значений в полях.
методичка [3,9 M], добавлен 21.07.2009
Создание моделей данных, основных таблиц с помощью конструктора таблиц, связей между таблицами, форм для заполнения таблиц, запросов на выборку данных, отчетов для вывода на печать и начальной кнопочной формы. Основные объекты Microsoft Access.
контрольная работа [4,5 M], добавлен 18.03.2012
Понятие и основные функции СУБД "Access". Алгоритм создания базы данных сотрудников: создание таблиц с помощью конструктора, ключевые поля, установление связей между таблицами. Создание форм для поиска и ввода данных. Работа с запросами и отчетами.
В файловых системах одновременная работа нескольких пользователей, связанная с модификацией данных в файле либо вообще не реализовывалась, либо была замедлена. Эти недостатки привели к разработке новых подходов к управлению информации. Этот подход был реализован в рамках новых программных средств и называется системой управления базой данных (СУБД), а сами хранилища информации назывались базами данных и банками данных. Одним из первых этапов создания базы данных – это были большие ЭВМ. Первые СУБД были даны в эксплуатацию фирмой IBM в конце 60-х годов. Эта СУБД была связана с организацией базы данных на больших ЭВМ (360) и ЕС (Единая система). Здесь базы данных хранились во внешней памяти центрального ЭВМ. Пользовательскими задачами были запуск данных в пакетном режиме. Мощные операционные системы параллельно обеспечивали множество задач. Эти системы можно было отнести к системе распределённого доступа, потому что база данных была централизованной. Хранилась на установленной внешней памяти одной из центрального ЭВМ, а доступ к ней поддерживался от многих пользователей и задач.
В дальнейшем в теории базы данных был сделан большой вклад американским математиком Эдвардом Коддом, который являлся создателем теории реляционной базы данных и в то же время появились языки высокого уровня.
Второй этап – это эпоха персональных компьютеров. В это время появились программы, которые назывались СУБД и позволяли хранить значительный объём информации. Они имели удобный интерфейс для заполнения базы данных. Они позволяли автоматизировать множественные функции, которые ранее велись вручную. Первые базы данных на компьютерах были недолговечны, т.е. они не учитывали взаимосвязи реальных объектов и спрос на удобные программы СУБД. Это привело к созданию настольных СУБД. При этом каждый разработчик разрабатывал собственные СУБД , используя стандартные языки программирования и таким образом каждый раз приходилось набранные данные переносить на более новый СУБД. Это было одно из основных недостатков этой эпохи. Яркие представители этой эпохи были: dbase, FoxPro, clipper, Paradox.
Третий этап распределения базы данных. В этом этапе появилось большое количество локальных сетей, все больше информации передаются между компьютерами и встаёт задача о согласовании данных , хранящихся и обрабатываемых в разных местах, но которые логически связаны друг с другом. Решение этой задачи приводит к появлению распределённой базы данных, сохраняющих преимущество всех настольных СУБД, но в тоже время позволяющих организовать параллельную обработку информации. Именно на этом этапе были начаты работы связанные с концепцией объектно ориентированной базы данных (SQL). Для манипулирования данными на этом этапе был использован SQL и технологии по обмену данными между СУБД, к которым можно отнести ODBC (open database connectivity). Именно на этом этапе были представлены MsAccess, MsSQL,ORCL и т.д.
Четвёртый этап- перспективы развития СУБД. Он характерен новой технологией доступа к данным intronet. При этом отпадают необходимости использования специального клиентского программного обеспечения. Для работы с удалённой базой данных используют стандартные браузеры Интернет Explorer и т.д. При этом встроенный в загруженный пользователями html страницы код, написан на языках java, JavaScript отлаживает все действия пользователя и транслируют их в низкоуровневые SQL запросы. Таким образом выполняется клиентская программа. Удобства такого подхода позволило использовать его не только в удалённые базы данных, но и в локальных сетях предприятий.
Основные понятия и определение базы данных
Очень часто упоминается термин банк и база данных и они отличаются. База данных- именованная совокупность данных, отражённых состояний объектов и их отношений в рассмотренной предметной области. Под предметной областью понимают одну или несколько объектов управления информации которых моделируются с помощью базы данных и используются для решения различных функциональных задач. Система управления базы данных совокупность языков и программных средств, предназначенных для создания введения и совместного использования базы данных многими пользователями. СУБД должен обеспечивать независимость данных. Практически одна и та же СУБД может быть использована для введения разных файлов, которые используются для решения различных не связанных между собой задач управления. Все функции СУБД можно объединить в такие группы:
1) Управление данными. Задачами управления данных являются подготовка и контроль данных, внесения данных в базу данных, обеспечение целостности и секретности данных.
2) Доступ к данным. Поиски, селекция данных, преобразование данных в форму удобную для дальнейшего использования.
Этапы проектирования базы данных
Вопрос проектирования базы данных выделяется как отдельное направление работ при разработке информационных систем проектирование базы данных- это итерационный многоэтапный процесс принятия решения в процессе анализа информационной модели предметной области. Здесь должны быть учтены требования к данным со стороны прикладного программирования и пользователя, логичных и функциональных структур данных, выбор программ и аппаратных средств. Этапы проектирования базы данных связаны с многоуровневой организацией данных. Многоуровневый процесс данных состоит в следующем: внешнее, инфологическое, логическое, даталогическое, внутреннее. Существуют и другие уровни представления данных, где используются 3 уровня: внешний, концептуальный, внутренний.
На этом уровне формируется концептуальная модель данных, которая отвечает особенностям и ограничениям выбранного СУБД. Эта модель ориентирована на программистов. Модель логического уровня, которая поддерживает конкретизацию средств СУБД, называется даталогической. Инфологическая и даталогическая модели зависимы между собой. Инфологическая модель может легко трансформироваться в даталогическую. Внутренний уровень связан с физическим размещением данных. От параметров физической модели зависит объём памяти и время реакции системы. Физические параметры базы данных можно изменять с целью повышения эффективности функциональной системы. Изменение физических параметров не предопределяется необходимостью изменения инфологической и даталогической модели. Схема взаимосвязи уровней включает описание данных.
Проектирование баз данных — процесс создания схемы базы данных и определения необходимых ограничений целостности.

Невозможно создать БД без подробного ее описания, также как и невозможно сделать какое-либо сложное изделие без чертежа и подробного описания технологий его изготовления. Другими словами, нужен проект. Проектом принято считать эскиз некоторого устройства, который в дальнейшем будет воплощен в реальность. Процесс проектирования БД представляет собой процесс переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. Конечной целью проектирования является построение конкретной БД. Очевидно, что процесс проектирования сложен и поэтому имеет смысл разделить его на логически завершенные части – этапы.
При проектировании таблиц рекомендуется руководствоваться следующими основными принципами:
- Информация в таблице не должна дублироваться. Не должно быть повторений и между таблицами. Когда определенная информация хранится только в одной таблице, то и изменять ее придется только в одном месте. Это делает работу более эффективной, а также исключает возможность несовпадения информации в разных таблицах. Например, в одной таблице должны содержаться адреса и телефоны клиентов.
- Каждая таблица должна содержать информацию только на одну тему. Сведения на каждую тему обрабатываются намного легче, если они содержатся в независимых друг от друга таблицах. Например, адреса и заказы клиентов лучше хранить в разных таблицах с тем, чтобы при удалении заказа информация о клиенте осталась в базе данных.
- Каждая таблица должна содержать необходимые поля. Каждое поле в таблице должно содержать отдельные сведения по теме таблицы. Например, в таблице с данными о клиенте могут содержаться поля с названием компании, адресом, городом, страной и номером телефона. При разработке полей для каждой таблицы необходимо помнить, что каждое поле должно быть связано с темой таблицы. Не рекомендуется включать в таблицу данные, которые являются результатом выражения. В таблице должна присутствовать вся необходимая информация. Информацию следует разбивать на наименьшие логические единицы (Например, поля "Имя" и "Фамилия", а не общее поле "Имя").

- База данных должна иметь первичный ключ. Это необходимо для того, чтобы СУБД могла связать данные из разных таблиц, например, данные о клиенте и его заказы.
Основные задачи проектирования баз данных:
- Обеспечение хранения в БД всей необходимой информации.
- Обеспечение возможности получения данных по всем необходимым запросам.
- Сокращение избыточности и дублирования данных.
- Обеспечение целостности базы данных.
Основные этапы проектирования баз данных:
Концептуальное (инфологическое) проектирование.
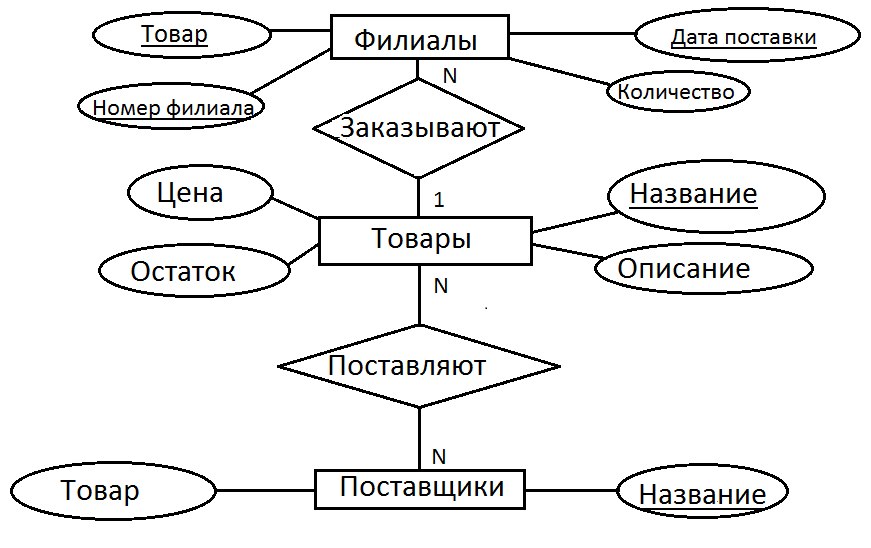
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам.
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений. При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
Логическое (даталогическое) проектирование.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Логическая структура БД должна соответствовать логической модели предметной области и учитывать связь модели данных с поддерживаемой СУБД. Поэтому этап начинается с выбора модели данных, где важно учесть её простоту и наглядность.
Предпочтительнее, когда естественная структура данных совпадает с представляющей её моделью. Так, например, если в данные представлены в виде иерархической структуры, то и модель лучше выбирать иерархическую. Однако на практике такой выбор чаще определяется системой управления БД, а не моделью данных. Поэтому концептуальная модель фактически транслируется в такую модель данных, которая совместима с выбранной системой управления БД.
Здесь тоже находит отражение природа проектирования, которая допускает возможность (или необходимость) вернуться к концептуальной модели для её изменения в случае, если отражённые там взаимосвязи между объектами (или атрибуты объектов) не удастся реализовать средствами выбранной СУБД.
По завершению этапа должны быть сформированы схемы баз данных обоих уровней архитектуры (концептуального и внешнего), созданные на языке определения данных, поддерживаемых выбранной СУБД.
Схемы базы данных формируются с помощью одного из двух разнонаправленных подходов:
- либо с помощью восходящего подхода, когда работа идёт с нижних уровней определения атрибутов, сгруппированных в отношения, представляющие объекты, на основе существующих между атрибутами связей;
- либо с помощью обратного, нисходящего, подхода, применяемого при значительном (до сотен и тысяч) увеличении числа атрибутов.
Физическое проектирование.
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.

На следующем этапе физического проектирования БД логическая структура отображается в виде структуры хранения БД, то есть увязывается с такой физической средой хранения, где данные будут размещены максимально эффективно. Здесь детально расписывается схема данных с указанием всех типов, полей, размеров и ограничений. Помимо разработки индексов и таблиц, производится определение основных запросов.
Построение физической модели сопряжено с решением во многом противоречивых задач:
- задачи минимизации места хранения данных,
- задачи достижения целостности, безопасности и максимальной производительности.
Вторая задача вступает в конфликт с первой, поскольку, например:
- для эффективного функционирования транзакций нужно резервировать дисковое место под временные объекты,
- для увеличения скорости поиска нужно создавать индексы, число которых определяется числом всех возможных комбинаций участвующих в поиске полей,
- для восстановления данных будут создаваться резервные копии базы данных и вестись журнал всех изменений.
Всё это увеличивает размер базы данных, поэтому проектировщик ищет разумный баланс, при котором задачи решаются оптимально путём грамотного размещения данных в пространстве памяти, но не за счёт средств защиты базы дынных, куда входит как защита от несанкционированного доступа, так и защита от сбоев.
Для завершения создания физической модели проводят оценку её эксплуатационных характеристик (скорость поиска, эффективность выполнения запросов и расхода ресурсов, правильность операций). Иногда этот этап, как и этапы реализации базы данных, тестирования и оптимизации, а также сопровождения и эксплуатации, выносят за пределы непосредственного проектирования БД.
Выбор системы управления и программных средств БД.
От выбора системы управления БД зависит практическая реализация информационной системы. Наиболее значимыми критериями в процессе выбора становятся параметры:
- типа модели данных и её соответствие потребностям предметной области,
- запас возможностей в случае расширения информационной системы,
- характеристики производительности выбранной системы,
- эксплуатационная надёжность и удобство СУБД,
- инструментальная оснащённость, ориентированная на персонал администрирования данных,
- стоимость самой СУБД и дополнительного софта.
Ошибки в выборе СУБД практически наверняка впоследствии спровоцируют необходимость корректировать концептуальную и логическую модели.
Читайте также: