
Реферат на тему архитектура процессора
Обновлено: 03.07.2024
Понятие архитектуры процессора не имеет единого толкования, поскольку под ним понимаются две различные сущности. С программной позиции она представляет собой совместимость процессора с конкретным набором команд, его способность выполнять определённый набор кодов. То есть это способность программы, которая была собрана для архитектуры семейства x86, функционировать на всех x86-совместимых системах. На ARM системе такая программа работать не будет.
С аппаратной позиции архитектура процессора, называемая иногда микроархитектурой, является набором свойств, характерным для всего семейства процессоров и отражающим базовые особенности его внутренней организации. К примеру, микроархитектура процессоров Intel Pentium имела обозначение Р5, а процессоры Pentium 4 относились к NetBurst. После закрытия Intel микроархитектуры Р5 для производителей AMD разработала архитектуру К7 и К8 для процессоров Athlon, Athlon XP и Athlon 64 соответственно.
CISC
CISC-архитектура (Complex Instruction Set Computer) относится к процессорам с полным набором команд. Она имеет нефиксированную длину команд, отличается кодированием арифметических действий в единой команде и малым количеством регистров, большинство из которых выполняет только выделенную функцию.
CISC реализована во множестве типов микропроцессоров, таких как Pentium, которые выполняют большое количество разноформатных команд (порядка 200-300), применяя более десяти различных способов адресации. Командная система может включать несколько сотен команд различного уровня сложности или формата (от 1 до 15 байт).

Всё это делает возможным реализовывать эффективные алгоритмы для различных задач. В качестве примеров CISC-архитектуры, используемой преимущественно для десктопных версий, можно привести следующие процессоры:
- x86 (IA-32, сокращенное от "Intel Architecture, 32-bit") - ;
- x86_64 (AMD64);
- Motorola MC680x0;
- мейнфреймы zSeries.
В CISC-процессорах каждую из команд возможно заменить на аналогичную ей либо на группу выполняющих такую же функцию команд. Это формирует как достоинства, так и недостатки архитектуры: она обладает высокой производительностью благодаря возможности замены команд, но большей стоимостью в сравнении с RISC, что связано с усложнённой архитектурой, в которой существует множество сложных для раскодирования команд.
RISC-архитектура (Reduced Instruction Set Computer) относится к процессорам с сокращённым набором команд. В ней быстродействие увеличивается посредством упрощения инструкций: за счёт того, что их декодирование становится проще, уменьшается время исполнения. Изначально RISC-процессоры не обладали инструкциями деления и умножения и не могли работать с числами, имеющими плавающую запятую. Их появление связано с тем, что в CISC достаточно много способов адресации и команд использовались крайне редко.
Система команд в RISC состоит из малого числа часто применяемых команд одного формата, которые можно выполнить за единичный такт центрального процессора. Более сложные и редко применяемые команды выполняются на программном уровне. При этом, благодаря значительному увеличению скорости реализации команд, средняя производительность RISC-процессоров выше, чем у CISC.

Благодаря сокращению аппаратных средств, используемых для декодирования и реализации сложных команд, достигается значительное упрощение и снижение стоимости интегральных схем. В то же время возрастает производительность и снижается энергопотребление, что особенно актуально для мобильного сегмента. Эти же достоинства служат причиной использования во многих современных CISC-процессорах, например в последних моделях К7 и Pentium, RISC-ядра. Сложные CISC-команды заранее преобразуются в набор простых RISC-операций, которые оперативно выполняются RISC-ядром.
Характерными примерами RISC-архитектур являются:
- PowerPC;
- DEC Alpha;
- ARC;
- AMD Am29000;
- серия архитектур ARM;
- Atmel AVR;
- Intel i860 и i960;
- BlackFin;
- MIPS;
- PA-RISC;
- Motorola 88000;
- SuperH;
- RISC-V;
- SPARC.
RISC быстрее CISC, и даже при условии выполнения системой RISC четырёх или пяти команд вместо единственной, выполняемой CISC, RISC выигрывает в скорости, поскольку его команды выполняются в разы оперативнее. Однако CISC продолжает использоваться. Это связано с совместимостью: x86_64 продолжает лидировать в десктоп-сегменте, а поскольку старые программы могут функционировать только на x86, то и новые десктоп-системы должны быть x86(_64), чтобы дать возможность старым программам работать на новых устройствах.
Для Open Source это не проблема, ведь пользователь может найти в сети версию программы, подходящую для другой архитектуры. Однако создать версию проприетарной программы для другой архитектуры получится только у владельца исходного кода.
MISC
MISC-архитектура (Minimal Instruction Set Computer) является процессором с минимальным набором команд. Она отличается ещё большей простотой и используется для ещё большего снижения энергопотребления и итоговой стоимости процессора. MISC-архитектура применяется в IoT-сегменте и компьютерах малой стоимости вроде роутеров. Первой вариацией такого процессора стал MuP21.
В основе MISC-процессоров лежит укладка ряда команд в единое большое слово, что позволяет параллельно обрабатывать несколько потоков данных. MISC применяет стековую модель устройства и базовые слова языка Forth. Процессоры этой архитектуры отличаются малым числом наиболее востребованных команд и использованием длинных командных слов, что позволяет получить выполнение ряда непротиворечивых команд за единый цикл работы процессора. Порядок исполнения команд определяется так, чтобы максимально загрузить маршруты, пропускающие потоки данных.
VLIW
VLIW-архитектура (Very Long Instruction Word) относится к микропроцессорам, применяющим очень длинные команды за счёт наличия нескольких вычислительных устройств. В отдельных полях команды присутствуют коды, которые обеспечивают реализацию различных операций. Одна команда в VLIW может исполнить одновременно несколько операций в разных узлах микропроцессора. Формированием таких длинных команд занимается соответствующий компилятор во время трансляции программ, которые написаны на высокоуровневом языке.
VLIW-архитектура, являясь достаточно перспективной для разработки нового поколения высокопроизводительных процессоров, реализована в некоторых современных микропроцессорах:

VLIW схожа с архитектурой CISC, имея собственный аналог спекулятивной реализации команд. Однако спекуляция выполняется не при работе программы, а при компиляции, что делает VLIW-процессоры устойчивыми к уязвимостям Spectre и Meltdown. Компиляторы в этой архитектуре привязаны к определённым процессорам. Так, в следующем поколении наибольшая длина одной команды может из 256 бит превратиться в 512 бит, и тогда придётся выбирать между обратной совместимостью со старым типом процессора и возрастанием производительности посредством компиляции под новый процессор. И в этом случае Open Sourсe даёт возможность получить программу под определённый процессор при помощи перекомпиляции.
Развитием указанных архитектур стали различные гибридные архитектуры. К примеру, современные x86_64 процессоры CISC-совместимы, однако имеют RISC-ядро. В этих CISC-процессорах CISC-инструкции переводятся в набор RISC-команд. Вероятно, в дальнейшем разнообразие гибридных архитектур только возрастёт.
Целью работы является изучение типов архитектур современных процессоров.
Задачами работы являются:
- изучение истории, основных видов архитектур процессоров;
- рассмотрение основных характеристик современных процессоров;
- выделение особенностей современных процессоров.
Содержание
Введение 3
1. История, основные виды архитектур процессоров 5
1.1. История развития современных процессоров 5
1.2. Архитектура фон Неймана 6
1.3. Конвейерная архитектура 6
1.4. Суперскалярная архитектура 7
1.5. Параллельная архитектура 9
2. Основные характеристики современных процессоров 11
3. Особенности современных процессоров 20
Заключение 25
Список литературы 27
Работа содержит 1 файл
Архитектура современных процессоров.docx
Содержание
1. История, основные виды архитектур процессоров 5
1.1. История развития современных процессоров 5
1.2. Архитектура фон Неймана 6
1.3. Конвейерная архитектура 6
1.4. Суперскалярная архитектура 7
1.5. Параллельная архитектура 9
2. Основные характеристики современных процессоров 11
3. Особенности современных процессоров 20
Список литературы 27
Введение
Процессор (или центральный процессор, ЦП) — это транзисторная микросхема, которая является главным вычислительным и управляющим элементом компьютера.
Английское название процессора - CPU (Central Processing Unit).
Процессор представляет собой специально выращенный полупроводниковый кристалл, на котором располагаются транзисторы, соединенные напыленными алюминиевыми проводниками. Кристалл помещается в керамический корпус с контактами.
Конструктивно, процессоры могут выполняться как в виде одной большой монокристальной интегральной микросхемы — чипа, так и в виде нескольких микросхем, блоков электронных плат и устройств.
Чаще всего процессор представлен в виде чипа, расположенного на материнской плате. На самом чипе написана его марка, его тактовая частота (число возможных операций, которые он может выполнить в единицу времени) и изготовитель.
В настоящее время, микропроцессоры и процессоры вмещают в себе миллионы транзисторов и других элементов электронной логики и представляют сложнейшие высокотехнологичные электронные устройства. Персональный компьютер содержит в своем составе довольно много различных процессоров. Они входят в состав систем ввода/вывода контроллеров устройств. Каждое устройство, будь то видеокарта, системная шина или еще что-либо, обслуживается своим собственным процессором или процессорами. Однако, архитектуру и конструктивное исполнение персонального компьютера определяет процессор или процессоры, контролирующие и обслуживающие системную шину и оперативную память, и, что более важно, выполняющие объектный код программ. Такие процессоры принято называть центральными или главными процессорами (Central Point Unit — CPU). На основе архитектуры центральных процессоров строится архитектура материнских плат, и проектируется архитектура и конструкция компьютера.
Основные характеристики центрального процессора
- тип архитектуры или серия (Intel x86, Intel Pentium, Pentium overdrive, RISC…)
- система поддерживаемых команд (standard 86/88, 286, 386, 486, Pentium, MMX) и адресации (real mode, protected mode, virtual mode, EMS, paging).
- разрядность (бит)
- тактовая частота (МГц)
- величина питающего напряжения (Вольт)
Тип архитектуры, как правило, определяется фирмой производителем оборудования. Все крупнейшие фирмы, производящие электронное оборудование для IBM-PC-совместимых компьютеров и выпускающие свои типы центральных процессоров вносят изменения в базовую архитектуру процессоров серии Intel x86 или разрабатывают свою. С типом архитектуры тесно связан набор поддерживаемых команд или инструкций, и их расширений. Эти два параметра, в основном, определяют качественный уровень возможностей персонального компьютера и в большой степени уровень его производительности.
Целью работы является изучение типов архитектур современных процессоров.
Задачами работы являются:
- изучение истории, основных видов архитектур процессоров;
- рассмотрение основных характеристик современных процессоров;
- выделение особенностей современных процессоров.
1. История, основные виды архитектур процессоров
1.1. История развития современных процессоров
Ранние ЦП создавались в виде уникальных составных частей для уникальных, и даже единственных в своём роде, компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и миникомпьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где помимо вычислительного устройства на кристалле расположены дополнительные компоненты (память программ и данных, интерфейсы, порты ввода/вывода, таймеры, и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
1.2. Архитектура фон Неймана
Большинство современных процессоров для персональных компьютеров в общем основаны на той или иной версии циклического процесса последовательной обработки информации, изобретённого Джоном фон Нейманом.
Д. фон Нейман придумал схему постройки компьютера в 1946 году.
Важнейшие этапы этого процесса приведены ниже. В различных архитектурах и для различных команд могут потребоваться дополнительные этапы. Например, для арифметических команд могут потребоваться дополнительные обращения к памяти, во время которых производится считывание операндов и запись результатов. Отличительной особенностью архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и той же памяти.
1.3. Конвейерная архитектура
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
получение и декодирование инструкции (Fetch)
адресация и выборка операнда из ОЗУ (Memory access)
выполнение арифметических операций (Arithmetic Operation)
сохранение результата операции (Store)
После освобождения k-й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в n ступеней займёт n единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
Действительно, при отсутствии конвейера выполнение команды займёт n единиц времени (так как для выполнения команды по прежнему необходимо выполнять выборку, дешифрацию и т. д.), и для исполнения m команд понадобится единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения m команд понадобится всего лишь n + m единиц времени.
Факторы, снижающие эффективность конвейера:
простой конвейера, когда некоторые ступени не используются (напр., адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами);
ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд, out-of-order execution);
очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода.)
1.4. Суперскалярная архитектура
Способность выполнения нескольких машинных инструкций за один такт процессора. Появление этой технологии привело к существенному увеличению производительности.
Complex Instruction Set Computer — вычисления со сложным набором команд. Процессорная архитектура, основанная на усложнённом наборе команд. Типичными представителями CISC является семейство микропроцессоров Intel x86 (хотя уже много лет эти процессоры являются CISC только по внешней системе команд).
Reduced Instruction Set Computer — вычисления с сокращённым набором команд. Архитектура процессоров, построенная на основе сокращённого набора команд. Характеризуется наличием команд фиксированной длины, большого количества регистров, операций типа регистр-регистр, а также отсутствием косвенной адресации. Концепция RISC разработана Джоном Коком (John Cocke) из IBM Research, название придумано Дэвидом Паттерсоном (David Patterson).
Среди первых реализаций этой архитектуры были процессоры MIPS, PowerPC, SPARC, Alpha, PA-RISC. В мобильных устройствах широко используются ARM-процессоры.
Minimum Instruction Set Computer — вычисления с минимальным набором команд. Дальнейшее развитие идей команды Чака Нориса, который полагает, что принцип простоты, изначальный для RISC-процессоров, слишком быстро отошёл на задний план. В пылу борьбы за максимальное быстродействие, RISC догнал и перегнал многие CISC процессоры по сложности. Архитектура MISC строится на стековой вычислительной модели с ограниченным числом команд (примерно 20-30 команд
Содержат несколько процессорных ядер в одном корпусе (на одном или нескольких кристаллах).
Процессоры, предназначенные для работы одной копии операционной системы на нескольких ядрах, представляют собой высокоинтегрированную реализацию мультипроцессорности.
Двухъядерность процессоров включает такие понятия, как наличие логических и физических ядер: например двухъядерный процессор Intel Core Duo состоит из одного физического ядра, которое в свою очередь разделено на два логических. Процессор Intel Core 2 Quad состоит из двух физических ядер, каждое из которых в свою очередь разделено на два логических ядра, что существенно влияет на скорость его работы.
10 сентября 2007 года были выпущены в продажу нативные (в виде одного кристалла) четырёхъядерные процессоры для серверов AMD Opteron, имевшие в процессе разработки кодовое название AMD Opteron Barcelona.[1] 19 ноября 2007 года вышел в продажу четырёхъядерный процессор для домашних компьютеров AMD Phenom.[2] Эти процессоры реализуют новую микроархитектуру K8L (K10).
27 сентября 2006 года Intel продемонстрировала прототип 80-ядерного процессора.[3] Предполагается, что массовое производство подобных процессоров станет возможно не раньше перехода на 32-нанометровый техпроцесс, а это в свою очередь ожидается к 2010 году.
26 октября 2009 года Tilera анонсировала[4] 100-ядерный процессор широкого назначения серии TILE-Gx. Каждое процессорное ядро представляет собой отдельный процессор с кэшем 1, 2 и 3 уровней. Ядра, память и системная шина связаны посредством технологии Mesh Network. Процессоры производятся по 40-нм нормам техпроцесса и работают на тактовой частоте 1,5 ГГц. Выпуск 100-ядерных процессоров назначен на начало 2011 года.
На данный момент массово доступны двух-, четырёх- и шестиядерные процессоры, в частности Intel Core 2 Duo на 65-нм ядре Conroe (позднее на 45-нм ядре Wolfdale) и Athlon 64 X2 на базе микроархитектуры K8. В ноябре 2006 года вышел первый четырёхъядерный процессор Intel Core 2 Quad на ядре Kentsfield, представляющий собой сборку из двух кристаллов Conroe в одном корпусе. Потомком этого процессора стал Intel Core 2 Quad на ядре Yorkfield (45 нм), архитектурно схожем с Kentsfield но имеющем больший объём кэша и рабочие частоты.
К 1-2 кварталу 2009 года обе компании обновили свои линейки четырёхъядерных процессоров. Intel представила семейство Core i7, состоящее из трёх моделей, работающих на разных частотах. Основными изюминками данного процессора является использование трёхканального контроллера памяти (типа DDR-3) и технологии эмулирования восьми ядер (полезно для некоторых специфических задач). Кроме того, благодаря общей оптимизации архитектуры удалось значительно повысить производительность процессора во многих типах задач. Слабой стороной платформы, использующей Core i7, является её чрезмерная стоимость, так как для установки данного процессора необходима дорогая материнская плата на чипсете Intel X58 и трёхканальный набор памяти типа DDR3, также имеющий на данный момент высокую стоимость.
- Для учеников 1-11 классов и дошкольников
- Бесплатные сертификаты учителям и участникам
Муниципальное автономное общеобразовательное учреждение города Калининграда средняя образовательная школа №25 с углубленным изучением отдельных предметов им. И.В. Грачева
Ученик 10Б класса
Содержание Стр.
1 История развития процессоров…………………….………………. 4
2 Алгоритм работы процессора……………………….……………. 10
2.1 Устройство процессора…………………….……………………. 10
2.2 Алгоритм работы процессора. 11
2.3 Прерывание процессора. 12
3 Моделирование работы процессора. 15
Список источников……………. 18
За три десятка лет, прошедших с этого знаменательного дня, процессоры сильно изменились. Современный процессор - это не просто набор транзисторов, а целая система множества важных устройств.
1 История развития процессоров
В настоящее время существуют много фирм по производству процессоров для персональных компьютеров. Это Intel , AMD , Cyrix , VIA , Centaur / IDT , NexGen , и многие другие . Однако наиболее популярными являются Intel и AMD . Развитие процессоров этих ведущих фирм мы и постараемся рассмотреть.
Однако прежде чем углубляться в историю производства процессоров необходимо дать характеристику некоторым техническим терминам характеризующих процессор.
Тактовая частота – это скорость работы процессора, а именно количество операций выполненных на протяжении 1 секунды.
Поколения – поколения процессоров отличаются друг от друга скоростью работы, архитектурой, исполнением и внешним видом. Если просмотреть поколения процессоров фирмы Intel то их было 8 (8088, 286, 386, 486, Pentium , PentiumII , PentiumIII , PentiumIV ).
Модификация –у ведущих и постоянно конкурирующих фирм Intel и AMD есть две модификации процессоров. У Intel это Pentium и Celeron , у AMD это Athlon и Duron . Pentium и Athlon это дорогие процессоры для графических станций или серверов, а Celeron и Duron это процессоры для домашних компьютеров.
Технология производства – под технологией производства в данном случае понимают размер минимальных элементов процессора. Так в 1999 году фирмы перешли на новую, 0,13 – микронную технологию.
КЭШ-память первого уровня – небольшая (несколько десятков килобайт) сверхбыстрая память, предназначенная для хранения промежуточных результатов вычислений.
КЭШ-память второго уровня – эта память более медленная, но она больше от 128 до 512 кбайт.
Центральный процессор (ЦП; также центра́льное процессорное устройство — ЦПУ; англ. centralprocessingunit, CPU, дословно — центральное обрабатывающее устройство, часто просто процессор) — электронный блок либо интегральная схема, исполняющая машинные инструкции (код программ), главная часть аппаратного обеспечения компьютера или программируемого логического контроллера. Иногда называют микропроцессором или просто процессором.
Изначально термин центральное процессорное устройство описывал специализированный класс логических машин, предназначенных для выполнения сложных компьютерных программ. Вследствие довольно точного соответствия этого назначения функциям существовавших в то время компьютерных процессоров он естественным образом был перенесён на сами компьютеры. Начало применения термина и его аббревиатуры по отношению к компьютерным системам было положено в 1960-е годы. Устройство, архитектура и реализация процессоров с тех пор неоднократно менялись, однако их основные исполняемые функции остались теми же, что и прежде.
Главными характеристиками ЦПУ являются: тактовая частота, производительность, энергопотребление, нормы литографического процесса, используемого при производстве (для микропроцессоров), и архитектура.
Ранние ЦП создавались в виде уникальных составных частей для уникальных и даже единственных в своём роде компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и мини-компьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где, помимо вычислительного устройства, на кристалле расположены дополнительные компоненты (память программ и данных, интерфейсы, порты ввода-вывода, таймеры и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
История развития производства процессоров полностью соответствует истории развития технологии производства прочих электронных компонентов и схем.
Первым этапом, затронувшим период с 1940-х по конец 1950-х годов, было создание процессоров с использованием электромеханических реле, ферритовых сердечников (устройств памяти) и вакуумных ламп. Они устанавливались в специальные разъёмы на модулях, собранных в стойки. Большое количество таких стоек, соединённых проводниками, в сумме представляло процессор. Отличительными особенностями были низкая надёжность, низкое быстродействие и большое тепловыделение.
Вторым этапом, с середины 1950-х до середины 1960-х, стало внедрение транзисторов. Транзисторы монтировались уже на близкие к современным по виду платы, устанавливавшиеся в стойки. Как и ранее, в среднем процессор состоял из нескольких таких стоек. Возросло быстродействие, повысилась надёжность, уменьшилось энергопотребление.
Третьим этапом, наступившим в середине 1960-х годов, стало использование микросхем. Первоначально использовались микросхемы низкой степени интеграции, содержавшие простые транзисторные и резисторные сборки, затем, по мере развития технологии, стали использоваться микросхемы, реализующие отдельные элементы цифровой схемотехники (сначала элементарные ключи и логические элементы, затем более сложные элементы — элементарные регистры, счётчики, сумматоры), позднее появились микросхемы, содержащие функциональные блоки процессора — микропрограммное устройство, арифметическо-логическое устройство, регистры, устройства работы с шинами данных и команд.
Четвёртым этапом, в начале 1970-х годов, стало создание, благодаря прорыву в технологии, БИС и СБИС (больших и сверхбольших интегральных схем, соответственно), микропроцессора — микросхемы, на кристалле которой физически были расположены все основные элементы и блоки процессора. Фирма Intel в 1971 году создала первый в мире 4-разрядный микропроцессор 4004, предназначенный для использования в микрокалькуляторах. Постепенно практически все процессоры стали выпускаться в формате микропроцессоров. Исключением долгое время оставались только малосерийные процессоры, аппаратно оптимизированные для решения специальных задач (например, суперкомпьютеры или процессоры для решения ряда военных задач) либо процессоры, к которым предъявлялись особые требования по надёжности, быстродействию или защите от электромагнитных импульсов и ионизирующей радиации. Постепенно, с удешевлением и распространением современных технологий, эти процессоры также начинают изготавливаться в формате микропроцессора.
Переход к микропроцессорам позволил потом создать персональные компьютеры, которые проникли почти в каждый дом.
Первым общедоступным микропроцессором был 4-разрядный Intel 4004, представленный 15 ноября 1971 года корпорацией Intel. Он содержал 2300 транзисторов, работал на тактовой частоте 92,6 кГц и стоил 300 долларов.
Затем последовала его модификация, 80186.
В процессоре 80286 появился защищённый режим с 24-битной адресацией, позволявший использовать до 16 Мб памяти.
Процессор Intel 80386 появился в 1985 году и привнёс улучшенный защищённый режим, 32-битную адресацию, позволившую использовать до 4 Гб оперативной памяти и поддержку механизма виртуальной памяти. Эта линейка процессоров построена на регистровой вычислительной модели.
Параллельно развиваются микропроцессоры, взявшие за основу стековую вычислительную модель.
За годы существования микропроцессоров было разработано множество различных их архитектур. Многие из них (в дополненном и усовершенствованном виде) используются и поныне. Например, Intel x86, развившаяся вначале в 32-битную IA-32, а позже в 64-битную x86-64 (которая у Intel называется EM64T). Процессоры архитектуры x86 вначале использовались только в персональных компьютерах компании IBM (IBM PC), но в настоящее время всё более активно используются во всех областях компьютерной индустрии, от суперкомпьютеров до встраиваемых решений. Также можно перечислить такие архитектуры, как Alpha, POWER, SPARC, PA-RISC, MIPS (RISC-архитектуры) и IA-64 (EPIC-архитектура).
В современных компьютерах процессоры выполнены в виде компактного модуля (размерами около 5×5×0,3 см), вставляющегося в ZIF-сокет (AMD) или на подпружинивающую конструкцию — LGA (Intel). Особенностью разъёма LGA является то, что выводы перенесены с корпуса процессора на сам разъём — socket, находящийся на материнской плате. Большая часть современных процессоров реализована в виде одного полупроводникового кристалла, содержащего миллионы, а с недавнего времени даже миллиарды транзисторов.
2 Алгоритм работы процессора
2.1 Устройство процессора
Основные функциональные компоненты процессора
Ядро: Сердце современного процессора - исполняющий модуль. Pentium имеет два параллельных целочисленных потока, позволяющих читать, интерпретировать, выполнять и отправлять две инструкции одновременно.
Предсказатель ветвлений: Модуль предсказания ветвлений пытается угадать, какая последовательность будет выполняться каждый раз когда программа содержит условный переход, так чтобы устройства предварительной выборки и декодирования получали бы инструкции готовыми предварительно.
Блок плавающей точки. Третий выполняющий модуль внутри Pentium, выполняющий нецелочисленные вычисления
Первичный кэш: Pentium имеет два внутричиповых кэша по 8kb, по одному для данных и инструкций, которые намного быстрее большего внешнего вторичного кэша.
Шинный интерфейс: принимает смесь кода и данных в CPU, разделяет их до готовности к использованию, и вновь соединяет, отправляя наружу.

Рис. 1 Внутреннее строение процессора
Все элементы процессора синхронизируются с использованием частоты часов, которые определяют скорость выполнения операций. Самые первые процессоры работали на частоте 100kHz, сегодня рядовая частота процессора - 2000MHz, иначе говоря, часики тикают 2000 миллионов раз в секунду, а каждый тик влечет за собой выполнение многих действий. Счетчик Команд (PC) - внутренний указатель, содержащий адрес следующей выполняемой команды. Когда приходит время для ее исполнения, Управляющий Модуль помещает инструкцию из памяти в регистр инструкций (IR). В то же самое время Счетчик команд увеличивается, так чтобы указывать на последующую инструкцию, а процессор выполняет инструкцию в IR. Некоторые инструкции управляют самим Управляющим Модулем, так если инструкция гласит 'перейти на адрес 2749', величина 2749 записывается в Счетчик Команд, чтобы процессор выполнял эту инструкцию следующей.
Многие инструкции задействуют Арифметико-логическое Устройство (АЛУ), работающее совместно с Регистрами Общего Назначения - место для временного хранения, которое может загружать и выгружать данные из памяти. Типичной инструкцией АЛУ может служить добавление содержимого ячейки памяти к регистру общего назначения. АЛУ также устанавливает биты Регистра Состояний (Statusregister - SR) при выполнении инструкций для хранения информации о ее результате. Например, SR имеет биты, указывающие на нулевой результат, переполнение, перенос и так далее. Модуль Управления использует информацию в SR для выполнения условных операций, таких как 'перейти по адресу 7410 если выполнение предыдущей инструкции вызвало переполнение'.
Это почти все что касается самого общего рассказа о процессорах - почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным.
2.2 Алгоритм работы процессора
Весь алгоритм работы процессора можно описать в трех строчках
| чтение команды из памяти по адресу, записанному в СК
| увеличение СК на длину прочитанной команды
| выполнение прочитанной команды
Однако для полного представления необходимо определить логические схемы выполнения тех или иных команд, вычисления величин, а это уже функции Арифметико-логического Устройства.
Арифметико-логическое устройство (АЛУ)— блок процессора , который под управлением устройства управления (УУ) служит для выполнения арифметических и логических преобразований (начиная от элементарных ) над данными, называемыми в этом случае операндами . Разрядность операндов обычно называют размером или длиной машинного слова .
2.3 Прерывания процессора
При работе процессорной системы могут возникать особые случаи, когда процессор вынужден прерывать работу текущей программы и переходить к обработке этого особого случая, более срочного и важного. Причинами прерывания текущей программы может быть:
внешний сигнал по шине управления - маскируемых прерываний и немаскируемого прерывания;
аномальная ситуация, сложившаяся при выполнении команды программы и препятствующую ее дальнейшему выполнению;
находящаяся в программе команда прерывания.
Первая из указанных выше причин относится к аппаратным прерываниям, а две другие - к программным прерываниям. Отметим, что аппаратные прерывания непредсказуемы и могут возникать в любые моменты времени.
С помощью аппаратных прерываний осуществляется взаимодействие процессора с устройствами ввода-вывода ( клавиатурой, диском, модемом и т.п.), таймером и внутренними часами, сообщается о возникновении ошибки на шине или в памяти, об аварийном выключении сети и т.п. При возникновении аппаратного прерывания процессор выявляет его источник, сохраняет минимальный контекст текущей программы (включая адрес возврата), и переключается на специальную программу -- обработчик прерывания ( interrupthandler) . Эта программа правильно реагирует на возникшую ситуацию (например, помещает символ с клавиатуры в буфер, считывает сектор с диска и т.п.), что называется 1обслуживанием прерывания . После обслуживания прерывания процессор возвращается к прерванной программе, как будто прерываний не было.
Программные прерывания обычно называются особыми случаями , или исключениями (exception) . Особые случаи возникают, например, при делении на ноль, нарушения при защите по привилегиям, превышении длины сегмента, выходе за границу массива. Как правило, предсказать эти исключения невозможно. Однако встречающаяся в программе 1команда прерывания вполне предсказуема и находится под управлением программиста. Реакция процессора на программное прерывание такое же, как и на аппаратное прерывание, однако его обработка производится 1обработчиком особого случая (exceptionhandler).
Все особые случаи квалифицируются на:
Нарушение (fault) . Особый случай, который процессор может обнаружить до возникновения фактической ошибки (например -- нарушение правил привилегий). После обработки нарушения можно продолжить программу, осуществив повторное выполнение ( рестарт ) виноватой команды. Иногда это исключение называют отказом.
Ловушка (trap) . Особый случай, который возникает после окончания виноватой программы. После обслуживания ловушки процессор продолжает выполнение программы с команды, находящейся после виноватой. Типичный пример -- команда прерывания INT n в процессорах семейства x86 или прерывание при переполнении.
Авария (abort) -- возникает при столь серьезной ошибке, что контекст программы теряется и продолжать ее невозможно. Причину аварии установить нельзя, поэтому рестарт невозможен и ее необходимо прекратить. Иногда авария называется выходом из процесса.
Обработка всех прерывания и особых случаев происходит, в общем, одинаково и состоит из двух основных этапов. На первом этапе процессор выполняет некоторые "рефлексивные" операции, которые одинаковы для всех прерываний и исключений, и которыми программист управлять не может. На втором этапе запускается созданный программистом обработчик прерывания или исключения. Все служебные действия процессор производит автоматически.
3 Моделирование работы процессора
Разгон компьютеров - процесс увеличения тактовой частоты (и напряжения) компонента компьютера сверх штатных режимов с целью увеличения скорости его работы. Повышение частоты может достигать максимального значения, при котором сохраняется стабильность работы системы в необходимом для пользователя режиме. При разгоне повышается тепловыделение, энергопотребление, шум, уменьшается рабочий ресурс.
Конечная цель разгона — повышение производительности оборудования. Побочными эффектами могут быть повышение шума и тепловыделения, нестабильности, особенно при условии несоблюдения правил, подразумевающих усиление охлаждающего оборудования, улучшения питания компонентов, тонкой настройки разгона.
Противоположную цель ставит андерклокинг — снизить частоту работы оборудования (и, иногда, необходимого для неё напряжения) и этим достичь снижения тепловыделения, шума, а иногда и нестабильности. Может быть особенно актуальным для тихих помещений, экономии энергии или заряда батареи.
Могут быть разогнана центральные процессоры, память, видеокарты, матплаты, роутеры и прочее.
Классическим методом разгона может быть задание параметров через интерфейс BIOS оборудования и установку там более высоких значений частот работы компонентов системы, нежели штатные. Другой метод — перепрошивка BIOS'а альтернативной от штатной микропрограммой, имеющей уже другие параметры частот и напряжения по умолчанию. Третий метод — повышение частот через операционную систему с помощью специального разгонного программного обеспечения.
Для тестов стабильности компонентов компьютеров используются программное обеспечение такое как: Prime95, AIDA64, Super PI, LINPACK, SiSoft Sandra, BOINC, Memtest86+, OCCT.
Переход на новые технологии изготовления процессоров, разработка новых алгоритмов их работы является перспективным продвижением данной отрасли. По прогнозам ученых скорость процессоров через 10 лет может достичь 20-ти кратного увеличения по сравнению с современными процессорами.
Автоматизм работы процессора, возможность выполнения длинных последовательных команд без участия человека – одна из основных отличительных особенностей ЭВМ как универсальной машины по обработке информации.
Список источников
Большинство современных процессоров для персональных компьютеров, в общем, основаны на той или иной версии циклического процесса последовательной обработки информации, изобретённого Джоном фон Нейманом. Джон фон Нейман придумал схему постройки компьютера в 1946 году.
Отличительной особенностью архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и той же памяти.
Этапы цикла выполнения:
Процессор выставляет число, хранящееся в регистре счётчика команд, на шину адреса, и отдаёт памяти команду чтения;
Выставленное число является для памяти адресом; память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных, и сообщает о готовности;
Процессор получает число с шины данных, интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её;
Если последняя команда не является командой перехода, процессор увеличивает на единицу (в предположении, что длина каждой команды равна единице) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды;
И далее с начала цикла…
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса процессор считывает последовательность команд, содержащихся в памяти, и исполняет их. Такая последовательность команд называется программой и представляет алгоритм полезной работы процессора. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода — тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды останова или переключение в режим обработки аппаратного прерывания.
Команды центрального процессора являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов называется тактовой частотой.
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
получение и декодирование инструкции (Fetch)
выполнение арифметических операций (Arithmetic Operation)
адресация и выборка операнда из ОЗУ (Memory access)
сохранение результата операции (Store)
Факторы, снижающие эффективность конвейера:
простой конвейера, когда некоторые ступени не используются (напр., адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами);
ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд, out-of-order execution);
очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода.)
Есть так же Суперскалярная архитектура
Способность выполнения нескольких машинных инструкций за один такт процессора. Появление этой технологии привело к существенному увеличению производительности.
Complex Instruction Set Computing — вычисления со сложным набором команд. Процессорная архитектура, основанная на усложнённом наборе команд. Типичными представителями CISC является семейство микропроцессоров Intel x86 (хотя уже много лет эти процессоры являются CISC только по внешней системе команд)
Reduced Instruction Set Computing (technology) — вычисления с сокращённым набором команд. Архитектура процессоров, построенная на основе сокращённого набора команд. Характеризуется наличием команд фиксированной длины, большого количества регистров, операций типа регистр-регистр, а также отсутствием косвенной адресации. Концепция RISC разработана Джоном Коком (John Cocke) из IBM Research, название придумано Дэвидом Паттерсоном (David Patterson).
Самая распространённая реализация этой архитектуры представлена процессорами серии PowerPC, включая G3, G4 и G5. Довольно известная реализация данной архитектуры — процессоры серий MIPS и Alpha.
Содержат несколько процессорных ядер в одном корпусе (на одном или нескольких кристаллах).
На данный момент массово доступны процессоры с двумя и четырех ядрами в частности Intel Core 2 Duo и Intel Core 2 Quad на ядре Kentsfield
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через центральный процессор, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах.
Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
SISD — один поток команд, один поток данных;
SIMD — один поток команд, много потоков данных;
MISD — много потоков команд, один поток данных;
MIMD — много потоков команд, много потоков данных.
Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда
Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысячи ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
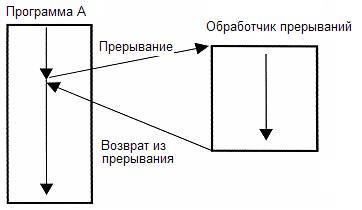
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврате из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того, чтобы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0, а в *nix — системным. Не стоит путать Привелигированный пользователь и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU

MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техника благодаря которой компилятор генерирует код который будет работать в любом месте в памяти. Эта техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Популярная техника SIMD используется для того, что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре, например, как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Это техника Используется для оптимизации кода, генерируемого компилятором, с помощью пересортировки инструкций, увеличивая производительность процессора. Это позволяет использовать конвейер на полную.

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо он может являться узким местом как поступили в MIPS.
В MIPS нет отдельной инструкции загрузки константы в память, но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. В других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны, использование двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы, как MIPS, или которые используют одну систему команд, но имеют разный порядок байт, например ARM.

Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой. Они позволяют исполнять инструкции, которые слишком громоздки для основной части процессора. Как яркий пример, сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386, который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли: контролировали прерывания, исключения и системные вызовы. Часто сопроцессоры имеют собственные инструкции и на системах, где этих инструкций нет, (пример ARM) эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность и маленькую производительность, они часто являются единственным выбором в микроконтроллерах.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций, которые выполняют несколько действий за один псевдотакт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.

Вы, навярняка, слышали о L1, L2, L3 и регистрах. Если коротко, процессор анализирует часть кода, чтобы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например, в программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предусмотрена процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не останутся незаметными просадки в производительности.Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
В современных процессорах часто используется техника теневых регистров. Они позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.

Спросите тогда что такое куча (Heap)? Куча это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть куча. А указатели хранятся в стеке или в регистрах. С помощью инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека, поскольку не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу), чтобы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров, а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета Беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имея лучшую производительность. В других же, таких как AVR, ограничили использование регистров. Для примера: три 16-битных можно трактовать как шесть восьмибитных, где первые 16ть недоступны при некоторых операциях. Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Читайте также: