
Реферат метод классификации функций
Обновлено: 04.07.2024
Стратегическое планирование (высший уровень) — это попытка взглянуть в долгосрочной перспективе на основополагающие составляющие организации; оценить, какие тенденции наблюдаются в ее окружении; определить, каким вероятнее всего будет поведение конкурентов. Главная задача планирования на этом уровне состоит в том, чтобы определить, как организация будет вести себя в своей рыночной нише. Цели… Читать ещё >
Классификация общих функций управления, их содержание ( реферат , курсовая , диплом , контрольная )
Прогнозирование и планирование
Экономическое прогнозирование— это предвидение хода экономического развития на предстоящий период для конкретной организации.
Планирование— функция управления, определяющая цели деятельности, необходимые для этого средства, а также разрабатывающая методы наиболее эффективные в конкретных условиях.
В широком смысле слова планирование — это деятельность по выработке и принятию управленческого решения. План как система взаимосвязанных решений, направленных на достижение желаемого результата, предусматривает следующее:
- · Цели и задачи. На современном этапе экономического развития осуществляется стратегия рыночной экономики, высшая цель которой — неуклонный подъем материального и культурного уровня жизни народа, создание лучших условий для всестороннего развития личности на основе дальнейшего повышения эффективности всего общественного производства.
- · Пути и средства. Для достижения поставленных целей выбираются методы совокупности взаимосвязанных действий.
- · Ресурсы, необходимые для выполнения поставленных задач. Цели и задачи, поставленные в плане, должны увязываться с материальными, финансовыми и трудовыми ресурсами.
- · Пропорции. Поддержание пропорциональности между отдельными элементами производства — важнейшее условие его эффективности.
- · Организация выполнения плана и контроль. Устанавливается связь плановой работы с конечной целью производства, удовлетворением потребностей общества.
Существует три основных типа планирования.
Стратегическое планирование (высший уровень) — это попытка взглянуть в долгосрочной перспективе на основополагающие составляющие организации; оценить, какие тенденции наблюдаются в ее окружении; определить, каким вероятнее всего будет поведение конкурентов. Главная задача планирования на этом уровне состоит в том, чтобы определить, как организация будет вести себя в своей рыночной нише ["https://referat.bookap.info", 12].
Тактическое планирование (средний уровень) — это определение промежуточных целей на пути достижения стратегических целей и задач. В основе стратегического планирования лежат идеи, которые были рождены при стратегическом планировании.
Оперативное планирование (низший уровень) — это основа основ планирования. В оперативных планах стандарты деятельности, описание работ и т. п. вписываются в такую систему, при которой каждый направляет свои усилия на достижение общих и главных целей организации.
Эффективность планирования зависит от того, какими принципами руководствуются при составлении планов.
коммуникацией, установлением информационных связей между обучаемыми и обучающим.
Накопление человечеством опыта и знаний при освоении природы смеш алось с
Сначала из поколения в поколен ие информация переда валась устно. Это были сведения
о профессиональных навыках, например о приемах охоты, обработки охотничьих трофеев,
способах земледелия и др. Но затем информацию стали фиксировать в виде графических
образов окружающего мира. Так, первые наскальные рисунки, изображающие животных,
растения, людей, появились примерно 20 – 30 тыс. лет назад.
Поиск более с овременных способов фикс ирования информации привел к появлению
письменности. Вначале люди записывали расчеты с покупателями, а затем написали и первое
Одним из направлений решения этой важной задачи стала разработка Единой системы
классификации и кодирования технико-экономической и социальной информации (ЕСКК
ТЭСИ). Координация всех работ по созданию ЕСКК ТЭСИ и разработка основополагающих
нормативно-технических и органи зационно-методических документов была возложена на
Особенно активно работа по созданию ЕСКК ТЭСИ стала проводиться после принятия в 1971
году специального постановления Совета Министров СССР, в котором были определены
учреждения и организации, ответственные за разработку классификаторов.
Основной целью, которая ставилась перед ЕСКК ТЭСИ, являлась стандартизация
информационного обеспечения проц ессов управления хозяйс твом страны на основе
применения средств вычислительной техники и новых информационн ых технологий путем
создания единого языка формализованного описания данных.
ГОСТ 6.01.1-87 Единая система классификации и кодирования технико-экономической
Понимая значение классификаторов ТЭСИ ка к стандартного языка ф ормали зованного описания
данных, Правит ельство РФ приняло 1 ноя бря1999 года специальное Постановление “О
развитии единой сист емы классификации и кодирования технико-экономической и социальной
информации”, в котором определены организации, ответственные за дальнейшее развитие
ЕСКК ТЭСИ, и закреплены общие принципы функционирования единой системы
классификации и кодирования технико- экономической и социальной информации:
– открытость и общедоступность системы кодирования для пользователей в той части, которая
не содержит сведений, составляющих государственную тайну;
– автоматизация процесса обработки технико-экономической и социальной информации;
– обеспечение методического и организационного единства системы кодирования;
– комплексность системы кодирования, предусматривающая наиболее полный охват технико-
экономической и социальной информации, используемой при межотраслевом обмене;
– обязательность применения системы кодирования при формировании государственных
– совместимость системы кодирования и других государственных информационных систем и
ресурсов и их взаимодействие в едином информационном пространстве Российской Федерации
– гармонизация системы кодирования с международными и региональными классификациями и
– классификация и кодирование технико-экономической и социальной информации;
– упорядочение и унификация технико-экономических и социальных показателей;
– обеспечение однозначности и сопоставимости данных, используемых при описании
кодирования технико-экономической и социальной информации объектов ТЭСИ;
– создание условий для автоматизации процессов обработки информации, включая создание
– создание распределенного автоматизированного банка общероссийских классификаторов;
– создание комплекса взаимоувязанных общероссийских классификаторов и общероссийских
– использование в отечественной практике международного и национального зарубежного
опыта работ по классификации и кодированию информации.
ЕСКК ТЭСИ состоит из сов окуп ности общероссийских классификаторов технико-
экономической и социальной информации, средств их вeдeние, нормативных и методических
документов по их разработке, ведению и применению. Объектами классификации и
кодирования в ЕСКК ТЭСИ РФ являются технико-экономические и социальные объекты и их
свойства, используемые в различных областях хозяйственной деятельности.
Классификатор ТЭСИ представляет собой систематизированный свод наименований и
кодов классификационных группировок и (или) объектов классификации.
ПР 50-733-93 Правила п о стандартизации. Основные положения Един ой с истемы
классификации и кодирования техн ико-экономической и социальной информации и
унифицированных систем документации Российской Федерации.
Методы кодирования технико-экономической и социальной информации тесно
взаимосвязаны с методами классификации. Каждому методу классификации соответствует
В процессе кодирования объектам класси фикации и их группировкам по определен ным
Код характеризуется алфавитом, то есть знаками, используемыми для его образования,
основанием кода – числом знаков в алфавите кода и длиной кода.
В классификаторах ТЭСИ используются четыре метода кодирования информации:
Порядковый метод кодирования – это такой метод, при котором кодами служат числа
натурального ряда. В этом случае кодом каждого из объектов классифицируемого
Данный метод кодирования обеспечивает довольно большую долговечность классификатора
при незначительн ой избыточности кода. Этот метод обладает наибольшей простотой,
использует наиболее короткие коды и лучше обеспечивает однозначность определения каждого
объекта классификации. Кроме того, он обеспечивает наиболее простое присвоение кодов
новым объектам, появляющимся в проц ессе ведения классификатора. Каждому новому объекту
Существенным недостатком порядкового метода кодирования является отсутствие в коде
какой-либо конкретной информации о св ойс твах объекта, а также сложность машинной
обработки информации при получении итогов по группе объектов классификации с
одинаковыми признаками. Этот метод кодирования не обеспечивает возможности размещения
вновь появившихся объектов классификации в необходимом месте классификатора, так как
резервные коды располагаются в конце ряда. По этим причи нам порядковый метод
кодирования чаще всего применяется в сочетании с другими методами кодирования.
Серийно-порядковый метод кодирования – э то такой метод, при котором кода ми служат
числа натурального ряда с закреплением отдельных серий этих чисел за объектами
Серийно-порядковый мет од коди рования целесообразно применять для объектов, имеющих два
соподчиненных признака. В каждой серии, кроме кодов имеющихся объектов классификации,
предусматривается определенное количество кодов для резерва. Резерв кодов располагается в
середине или в конце серии. Это является большим преимуществом данного метода по
сравнению с порядковым методом кодирования. Данный метод кодирования обладает всеми
преимуществами и недостатками порядкового метода кодирования.
Последовательный метод кодирования – это такой метод, при котором код объекта
классификации и (или) классификационной группировки образуется с использованием
кодов последовательно расположенных подчиненных группировок, полученных при
В этом случае код нижестоящей группировки образуется путем добавления соответствующего
количества разрядов к коду вышестоящей группировки. Последовательный метод кодирован ия
чаще всего используется при иерархическом методе классификации.
Преимуществами последовательного метода кодирования являются логичность построения
кода и большая емкость. Вместе с тем он обладает всеми недостатками, присущими
иерархическому методу классификации, а также ограниченными возможностями
идентификации объектов. Использование последовательного метода кодирования связано с
определенными трудностями, обусловленными тем, что в результате зависимости значений
последующих разрядов кода от предыдущих применять этот код по частям нельзя,
группировать объекты по различным сочетаниям имеющихся признаков сложно, практически
невозможно вносить новые признаки и производить изменения в коде без коренн ой
перестройки классификатора. Поэтому применят ь последовательный метод кодирования
целесообразно в тех случаях, когда набор признаков классификации и их последовательность

Как сделать реферат? Выбрать актуальную тему, поставить цели и задачи, изучить литературные источники и написать текст. Ничего не забыли? Нужно ещё указать методологию исследования.
Какие бывают методы исследования в реферате? Как их использовать и где описывать? На все эти вопросы ответим в статье. А заодно покажем на примерах, как описать методы в реферате.
Хотите получать полезную информацию из мира образования? Подписывайтесь на наш Telegram-канал. И не забывайте следить за акциями и скидками от компании.
Доверь свою работу кандидату наук!
Узнать стоимость бесплатно
Методы исследования в реферате: определение
Студенты понимают, зачем нужны методы исследования в курсовой и дипломной. Это серьёзные работы, которые требуют серьёзного подхода и научных методик. Но зачем методы в реферате? Ведь это простая работа, которая не предполагает глубокого анализа и изучения.
На самом деле, реферат — пусть и небольшой, но тоже исследовательский проект. А значит, в нём должны использоваться как методы написания самого реферата, так и методы исследования. С последними и познакомимся ближе.
Методы исследования — это способы познания, использование которых помогает лучше раскрыть цели и задачи научно-исследовательской работы. Они включают в себя определённые методики, приёмы и подходы. Все методы, используемые студентом в работе, составляют методологическую базу исследования.
Методы исследования в реферате: классификация
Есть много классификаций исследовательских методов: от общенаучных до узкоспециализированных. Но для реферата достаточно основных методов, которые входят в следующую классификацию:
- теоретические;
- эмпирические;
- количественные;
- качественные.

Для математических рефератов стоит использовать специальные методы
Если вы хотите углубиться в вопрос и использовать узкоспециализированные методологии, вы можете изучить методы исследования в психологии, юриспруденции, лингвистике и других науках и выбрать те, которые помогут лучше изучить выбранную тему.
Кстати! Для наших читателей сейчас действует скидка 10% на любой вид работы.
Существуют не только специализированные методологии, которые используют в исследованиях конкретных наук. Есть также междисциплинарные методы. Их применяют, когда тема располагается на стыке нескольких дисциплин и важно рассмотреть её с разных сторон.
Методы, используемые в реферате: таблицы с примерами
Какие методы можно использовать в реферате? Те, которые лучше раскрывают тему и решают поставленные задачи. Чтобы вы могли познакомиться с основными методами, мы собрали их в удобные таблицы и разбили по видам. Вы узнаете, что это за методы и как их применяют на практике.
Теоретические методы исследования в реферате
Теоретические методы — это методы, которые помогают систематизировать и обобщать исследовательский материал. Они отличаются абстрактным характером.
В астрономии: исследовать планетарные системы через уменьшенные модели.
В генетике: изучить РНК через их увеличенные модели.
Эмпирические методы исследования в реферате
Эмпирические методы — это методологические приёмы, в основе которых практические исследования, которые опираются на чувственный опыт или показатели измерительных приборов.
В биологии: наблюдать за ростом горохового зерна и записывать результаты.
В социологии: наблюдать за определённой группой людей и их жизненными изменениями.
Количественные методы исследования в реферате
Количественные методы — это методологические приёмы, которые помогают анализировать объекты и опираться при этом на конкретные количественные показатели.
| Название | Определение | Пример |
| Статистический анализ | Это метод, который позволяет изучать, сравнивать и сопоставлять данные, выводить общую статистику и делать на их основе практические выводы. | В криминалистике: изучить показатели преступности в конкретном регионе, сравнить с предыдущими и сделать выводы о том, растёт или уменьшается криминальная обстановка. |
| Контент-анализ | Метод, с помощью которого анализируют содержание конкретных текстов и выявляют определённые данные. | В журналистике: оценить, с какой частотой используются иностранные слова в российских СМИ. |
Качественные методы исследования в реферате
Качественные методы — методы, оценивающие качественные показатели и их влияние на конкретные явления или группы людей. Их в основном применяют в маркетинговых и социальных исследованиях.
| Название | Определение | Пример |
| Глубинное интервью | Этот метод более глубокий, чем простые опросы или беседы. Его цель — изучать глубинные убеждения, ценности и мотивации людей. | В маркетинге: исследовать отношение и интерес выбранной аудитории к коучингу. |
| Экспертное интервью | Этот метод позволяет исследовать экспертные мнения по острым вопросам. | В журналистике: изучить журналистские приёмы через экспертные интервью с именитыми журналистами (на основе открытых источников). |
| Фокус-групповое исследование | Помогает изучать объект исследования и получать данные через групповые дискуссии с аудиторией, которая имеет отношение к изучаемой теме. | В педагогике: фокус-групповое исследование преподавательских методик среди учителей начальных школ. |
Как выбрать методы для исследования в реферате
Из всего многообразия методов придётся выбрать несколько подходящих. Это можно сделать несколькими способами:
- Обратить внимание на тему исследования. В ней часто содержатся готовые подсказки.
- Посмотреть, какие методы выбирали для других аналогичных исследований.
- Использовать самые универсальные методы, например, наблюдение и анализ.
- Обратиться к научному руководителю. Он подскажет, как составить методологическую базу, чтобы лучше раскрыть тему, объект и предмет исследования.
Неправильно выбранные методы в реферате могут завести исследователя в тупик и превратить работу в бесполезные буквы.
Где описывают методы исследования в реферате
Выбрали методы исследования в реферате, теперь их необходимо правильно использовать и описать. Где и как это сделать? Не забыть о трёх моментах:
- перечислить выбранные методы во введении в реферат;
- применить в теоретическом и практическом разделах;
- указать в заключительной части, когда будете подводить итоги всего исследования.
Методы в реферате: пример описания
Чтобы правильно описать методы во введении, достаточно всего пару строк. Чтобы вы не растерялись и всё сделали правильно, используйте в качестве примера наши образцы.
Первый пример: методы в реферате
В реферате исследуются методики обучения в начальных классах. Для этого используются следующие методы исследования:
Второй пример: методы в реферате
Для того чтобы раскрыть тему и достичь поставленные цели, в реферате используются следующие методы: анализ литературных источников и ограничений, которые предъявляют к частной собственности, а также метод моделирования ситуаций.
Все примеры описания методов в реферате можно скачать по ссылке в формате Word.
Мы познакомились с основными методами в реферате. Теперь вы с лёгкостью составите свою методологическую базу и приятно удивите научного руководителя. А если нет времени писать реферат самостоятельно, обращайтесь в студенческий сервис. Наши эксперты позаботятся о правильном содержании и оформлении работы.
При изучении Data Science, я решил составить для себя конспект по основным приемам, используемым в анализе данных. В нем отражены названия методов, кратко описана суть и приведен код на Python для быстрого применения. Готовил конспект для себя, но подумал, что кому-то это также может быть полезно, например, перед собеседованием, в соревновании или при запуске нового проекта. Рассчитано на аудиторию, которая в целом знакома со всеми этими методами, но имеет необходимость освежить их в памяти. Статья под катом.
-Наивный байесовский классификатор. Формула расчета вероятности отнесения наблюдения к тому или иному классу:

Например, нужно рассчитать вероятность, что спортивный матч состоится при условии, что погода солнечная. Исходные данные и расчеты приведены в таблице ниже:

Можно посчитать по формуле (3/9) * (9/14) / (5/14) = 60%, или просто из здравого смысла 3/(2+3)=60%. Сильные стороны — легко интерпретировать результат, подходит для больших выборок и мультиклассовой классификации. Слабые стороны — не всегда выполняется предположение о независимости характеристик, характеристики должны составлять полную группу событий.
-Метод ближайших соседей. Классифицирует каждое наблюдение по степени похожести на остальные наблюдения. Алгоритм является непараметрическим (отсутствуют ограничения на данные, например, функция их распределения) и использует ленивое обучение (не применяются заранее обученные модели, все имеющиеся данные используются во время классификации).

Сильные стороны — легко интерпретировать результат, хорошо подходит для задач с малым количеством объясняющих переменных. Слабые стороны — невысокая точность по сравнению с другими методами. Требует значительных вычислительных мощностей при большом количестве объясняющих переменных и больших выборках.
-Метод опорных векторов (SVM). Каждый объект данных представляется как вектор (точка) в p-мерном пространстве. Задача — разделить точки гиперплоскостью. То есть, можно ли найти такую гиперплоскость, чтобы расстояние от неё до ближайшей точки было максимальным. Искомых гиперплоскостей может быть много, поэтому полагают, что максимизация зазора между классами способствует более уверенной классификации.
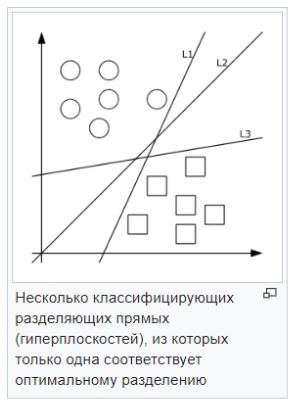
Сильные стороны — Эффективен при большом количестве гиперпараметров. Способен обрабатывать случаи, когда гиперпараметров больше, чем количество наблюдений. Существует возможность гибко настраивать разделяющую функцию. Слабые стороны — в случае, когда наблюдений меньше, чем объясняющих переменных, необходимо применять методы регуляризации, чтобы не переобучить модель. Также этот метод напрямую не дает вероятностных оценок.
-Деревья решений. Разделение данных на подвыборки по определенному условию в виде древовидной структуры. Математически разделение на классы происходит до тех пор, пока не найдутся все условия, определяющие класс максимально точно, т. е. когда в каждом классе отсутствуют представители другого класса. На практике используется ограниченное количество характеристик и слоев, а ветви всегда две.

Сильные стороны — возможно моделировать сложные процессы и легко их интерпретировать. Возможна мультиклассовая классификация. Слабые стороны — легко переобучить модель, если делать много слоев. Выбросы могут повлиять на точность, решение этих проблем — обрезать нижние уровни.
-Случайный лес/Ансамбль деревьев. Это много бустингов и деревьев решений объединенных вместе. Бустинг — случайная выборка из базовой выборки. За счет большого числа таких подвыборок (random patching) и построения на каждой своей модели увеличивается качество финальной модели за счет усреднения. Для оценки качества модели нужно применять oob-оценку.
Сильные стороны: нечувствительность к выбросам, малые требования к предобработке данных, к масштабированию, небольшая чувствительность к гиперпараметрам, разброс модели меньше, а значит она не склонна к переобучению. Так как построение деревьев независимое, то вычисления можно распараллелить. Слабые стороны — потребляет память и время, чтобы считать и хранить много деревьев. Не применять, когда признаков очень много (больше 100 000), в этом случае лучше — регрессии.
-Метод градиентного спуска. Итерационный алгоритм минимизации функции потерь (по умолчанию hinge loss function). Алгоритм также применяется в задачах прогнозирования.

Также есть версия стохастического градиентного спуска, который применяется при больших выборках. Его суть в том что он считает производную не по всей выборке, а по каждому наблюдению (online learning) (или по группе наблюдений mini-batch) и меняет веса. В итоге он приходит в тот же оптимум что и при обычном ГС. Существуют методы применения ГС для МНК, логит, тобит и других методов (доказательства).
Сильные стороны: высокая точность классификации и прогнозирования, подходит для мультиклассовой классификации. Слабые стороны — чувствительность к параметрам модели.
-Градиентный бустинг. Это ансамбли моделей. Строятся регрессии или деревья решений и минимизируется функция потерь, как в градиентном спуске. Используется, когда выборка помещается в память, есть смесь разных признаков.
Сильные стороны: высокая точность классификации и прогнозирования, подходит для мультиклассовой классификации, не чувствителен к выбросам, способен решать задачи ранжирования. Слабые стороны — требователен к ресурсам компьютера.
-Логистическая регрессия/logit. Используется для классификации от 0 до 1, доказывается методом максимального правдоподобия (log likelihood). ММП — это вероятность получить Y при заданных Х и найденных параметрах w.

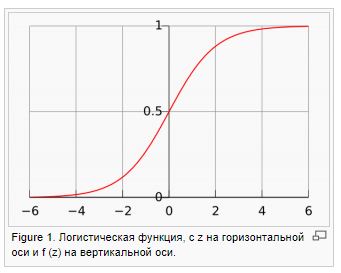
Сильные стороны: хорошо работает, когда гиперпараметры коррелируют с объясняющей переменной. Слабые стороны — подходит для бинарной классификации, слабо работает при эндогенности.
-Probit. Отличается от логит модели тем, что предполагает нормальность распределения гиперпараметров, в то время, как логит модель предполагает логистическое распределение.
-Tobit. Применяется, когда зависимая переменная ограничена и непрерывна.
Если упущен какой-либо важный метод, пожалуйста, напишите об этом в комментариях. Планируется выпуск статей по обучению без учителя, методам предобработки, методам оценки качества модели, интересным терминам и доказательствам. Спасибо за внимание.
При изучении Data Science, я решил составить для себя конспект по основным приемам, используемым в анализе данных. В нем отражены названия методов, кратко описана суть и приведен код на Python для быстрого применения. Готовил конспект для себя, но подумал, что кому-то это также может быть полезно, например, перед собеседованием, в соревновании или при запуске нового проекта. Рассчитано на аудиторию, которая в целом знакома со всеми этими методами, но имеет необходимость освежить их в памяти. Статья под катом.
-Наивный байесовский классификатор. Формула расчета вероятности отнесения наблюдения к тому или иному классу:
Например, нужно рассчитать вероятность, что спортивный матч состоится при условии, что погода солнечная. Исходные данные и расчеты приведены в таблице ниже:
Можно посчитать по формуле (3/9) * (9/14) / (5/14) = 60%, или просто из здравого смысла 3/(2+3)=60%. Сильные стороны — легко интерпретировать результат, подходит для больших выборок и мультиклассовой классификации. Слабые стороны — не всегда выполняется предположение о независимости характеристик, характеристики должны составлять полную группу событий.
-Метод ближайших соседей. Классифицирует каждое наблюдение по степени похожести на остальные наблюдения. Алгоритм является непараметрическим (отсутствуют ограничения на данные, например, функция их распределения) и использует ленивое обучение (не применяются заранее обученные модели, все имеющиеся данные используются во время классификации).
Сильные стороны — легко интерпретировать результат, хорошо подходит для задач с малым количеством объясняющих переменных. Слабые стороны — невысокая точность по сравнению с другими методами. Требует значительных вычислительных мощностей при большом количестве объясняющих переменных и больших выборках.
-Метод опорных векторов (SVM). Каждый объект данных представляется как вектор (точка) в p-мерном пространстве. Задача — разделить точки гиперплоскостью. То есть, можно ли найти такую гиперплоскость, чтобы расстояние от неё до ближайшей точки было максимальным. Искомых гиперплоскостей может быть много, поэтому полагают, что максимизация зазора между классами способствует более уверенной классификации.
Сильные стороны — Эффективен при большом количестве гиперпараметров. Способен обрабатывать случаи, когда гиперпараметров больше, чем количество наблюдений. Существует возможность гибко настраивать разделяющую функцию. Слабые стороны — в случае, когда наблюдений меньше, чем объясняющих переменных, необходимо применять методы регуляризации, чтобы не переобучить модель. Также этот метод напрямую не дает вероятностных оценок.
-Деревья решений. Разделение данных на подвыборки по определенному условию в виде древовидной структуры. Математически разделение на классы происходит до тех пор, пока не найдутся все условия, определяющие класс максимально точно, т. е. когда в каждом классе отсутствуют представители другого класса. На практике используется ограниченное количество характеристик и слоев, а ветви всегда две.
Сильные стороны — возможно моделировать сложные процессы и легко их интерпретировать. Возможна мультиклассовая классификация. Слабые стороны — легко переобучить модель, если делать много слоев. Выбросы могут повлиять на точность, решение этих проблем — обрезать нижние уровни.
-Случайный лес/Ансамбль деревьев. Это много бустингов и деревьев решений объединенных вместе. Бустинг — случайная выборка из базовой выборки. За счет большого числа таких подвыборок (random patching) и построения на каждой своей модели увеличивается качество финальной модели за счет усреднения. Для оценки качества модели нужно применять oob-оценку.
Сильные стороны: нечувствительность к выбросам, малые требования к предобработке данных, к масштабированию, небольшая чувствительность к гиперпараметрам, разброс модели меньше, а значит она не склонна к переобучению. Так как построение деревьев независимое, то вычисления можно распараллелить. Слабые стороны — потребляет память и время, чтобы считать и хранить много деревьев. Не применять, когда признаков очень много (больше 100 000), в этом случае лучше — регрессии.
-Метод градиентного спуска. Итерационный алгоритм минимизации функции потерь (по умолчанию hinge loss function). Алгоритм также применяется в задачах прогнозирования.
Также есть версия стохастического градиентного спуска, который применяется при больших выборках. Его суть в том что он считает производную не по всей выборке, а по каждому наблюдению (online learning) (или по группе наблюдений mini-batch) и меняет веса. В итоге он приходит в тот же оптимум что и при обычном ГС. Существуют методы применения ГС для МНК, логит, тобит и других методов (доказательства).
Сильные стороны: высокая точность классификации и прогнозирования, подходит для мультиклассовой классификации. Слабые стороны — чувствительность к параметрам модели.
-Градиентный бустинг. Это ансамбли моделей. Строятся регрессии или деревья решений и минимизируется функция потерь, как в градиентном спуске. Используется, когда выборка помещается в память, есть смесь разных признаков.
Сильные стороны: высокая точность классификации и прогнозирования, подходит для мультиклассовой классификации, не чувствителен к выбросам, способен решать задачи ранжирования. Слабые стороны — требователен к ресурсам компьютера.
-Логистическая регрессия/logit. Используется для классификации от 0 до 1, доказывается методом максимального правдоподобия (log likelihood). ММП — это вероятность получить Y при заданных Х и найденных параметрах w.
Сильные стороны: хорошо работает, когда гиперпараметры коррелируют с объясняющей переменной. Слабые стороны — подходит для бинарной классификации, слабо работает при эндогенности.
-Probit. Отличается от логит модели тем, что предполагает нормальность распределения гиперпараметров, в то время, как логит модель предполагает логистическое распределение.
-Tobit. Применяется, когда зависимая переменная ограничена и непрерывна.
Если упущен какой-либо важный метод, пожалуйста, напишите об этом в комментариях. Планируется выпуск статей по обучению без учителя, методам предобработки, методам оценки качества модели, интересным терминам и доказательствам. Спасибо за внимание.
Читайте также: