
Последовательный анализ вальда реферат
Обновлено: 30.06.2024
Когда к врачу приходит пациент, врач предварительно, основываясь на интуиции и своем опыте или знаниях о распространенности болезни в популяции, имеет некоторое предположение относительно заболевания это априорная, или дотестовая вероятность. Далее, имея уже результаты клинического анамнеза и лабораторных тестов, он выстраивают картину болезни пациента, и увеличивает или уменьшает вероятность своего предположения – это апостериорная вероятность. В свете новых данных (например, по истечении некоторого времени лечения) апостериорная вероятность может быть пересмотрена.
Подобный алгоритм положен в основу Байесовского классификатора. Данный подход рассчитывает вероятность того, что гипотеза истинна, путем обновления предшествующих мнений о гипотезе, по мере того как новые данные становятся доступными Метод оперирует вероятностью особого типа, известной как условная вероятность. Это вероятность события при условии, что другое событие уже произошло. Например, распространенность сахарного диабета в Европе составляет 6% (вероятность 0,06), но если у конкретного пациента обнаружено повышенное содержание глюкозы в крови, то вероятность обнаружить у него сахарный диабет резко возрастает.
Апостериорная вероятность является фактически условной вероятностью гипотезы, использующей результаты исследования.
Теорема Байеса утверждает, что апостериорная вероятность пропорциональна априорной, умноженной на величину, называемую правдоподобием наблюдаемых результатов (которая описывает правдоподобие наблюдаемых результатов, если гипотеза верна).
Вероятность того, что событие А произойдет, если событие В уже произошло

(79)
Отношение правдоподобия положительного результата теста это шанс положительного результата теста, если пациент имеет заболевание, деленный на шанс положительного результата теста, если он заболевания не имеет.
На формуле Байеса основана диагностическая процедура, которая использует метод последовательного статистического анализа А. Вальда. Рассмотрим суть этого метода. Пусть перед нами стоит задача выбора диагноза А или В.Известна распространенность этих заболеваний, т.е. априорные вероятности Р(А) и Р(В). После обнаружения у пациента признака х1

(80)

где
отношение априорных вероятностей

отношение апостериорных вероятностей при условии обнаружения признака х1

вероятность (отн. частота встречаемости) признака х1 при диагнозе А

вероятность (отн. частота встречаемости) признака х1 при диагнозе В

отношение правдоподобия
Тогда процесс дифференциальной диагностики выражается следующим образом

(81)
Т.е., если полученное выражение больше некоторого порогового значения А, то ставится диагноз А,если меньшенекоторого порогового значения В, то ставится диагноз В.Если ни один из порогов не достигнут, то для диагностики привлекается следующий признак х2 и проверяется неравенство

(82)
Если использована вся имеющаяся в распоряжении информация, и ни один из порогов так и не достигнут, то делается заключение, что информации не достаточно для постановки диагноза.
Пороговые значения устанавливаются по следующим формулам

(83)

(84)
где α – вероятность ошибки первого рода вероятность ложно поставить диагноз В, когда на самом деле верен диагноз А
β – вероятность ошибки второго рода вероятность ошибочно поставить диагноз А, когда на самом деле верен диагноз В
Вероятности ошибок первого и второго рода устанавливаются самим исследователем, исходя из сути решаемой проблемы.
Для удобства вычислений используются не сами отношения шансов, а их десятичные логарифмы, умноженные на число 10, и далее округленные до целых. Полученную величину называют диагностическим коэффициентом

(85)
Пороги также выражаются через логарифмы

(86)

(87)
Тогда алгоритм диагностики имеет следующий вид

(88)
Процесс диагностики значительно ускоряется, если использовать признаки в порядке убывания их информационной ценности. Под дифференциальной информативностью признака понимается степень различия его распределения при дифференцируемых состояниях А и В.
Удобной мерой для оценки информативности является мера Кульбаха

(89)

Если признак имеет диапазоны (например, возраст имеет диапазоны дети, взрослые, пожилые), то информационная ценность всего признака

(90)

Вопрос о минимальной информативности признака еще не нашел своего решения, но некоторые авторы рекомендуют включать в процедуру прогноза признаки с
Рассмотрим пример прогнозирования послеродовых осложнений. С этой целью были сформированы две выборки: основная (п=34) это лица, у которых наблюдались послеродовые осложнения, и контрольная (без осложнений), в которую вошли 32 роженицы. Всего исследовано 20 признаков, которые имели от 2 до 3 диапазонов. Результаты всех расчетов приведены в таблице 84.
Таблица 84. Данные к примеру
| № | Факторы риска  |  | Число случаев |  |  | Р/Р | ДК |  |  |
| Осн.гр.(A) п=34 | Контр. гр.(B) п=32 | ||||||||
| Мед аборты до настоящих родов 12 | есть | 0,206 | 0,094 | 2,196 | 0,19 | 0,22 | |||
| нет | 0,794 | 0,906 | 0,876 | 0,03 | |||||
| Самопроизвольные выкидыш до настоящих родов | есть | 0,265 | 0,125 | 2,118 | 0,23 | 0,28 | |||
| нет | 0,735 | 0,875 | 0,840 | 0,05 | |||||
| Патология шейки матки | есть | 0,147 | 0,125 | 1,176 | 0,01 | 0,01 | |||
| нет | 0,853 | 0,875 | 0,975 | 0,00 | |||||
| Бесплодие в анамнезе | есть | 0,176 | 0,031 | 5,647 | 0,55 | 0,59 | |||
| нет | 0,824 | 0,969 | 0,850 | 0,05 | |||||
| Многоплодная беременность | есть | 0,176 | 0,094 | 1,882 | 0,11 | 0,13 | |||
| нет | 0,824 | 0,906 | 0,909 | 0,02 | |||||
| Токсикозы | в первой половине | 0,618 | 0,500 | 1,235 | 0,05 | 0,35 | |||
| во второй половине | 0,235 | 0,188 | 1,255 | 0,02 | |||||
| нет | 0,147 | 0,313 | 0,471 | 0,27 | |||||
| ОРВИ | 1 триместре | 0,500 | 0,156 | 3,200 | 0,87 | 2,84 | |||
| 2 триместре | 0,059 | 0,063 | 0,941 | 0,00 | |||||
| 3 триместре | 0,294 | 0,125 | 2,353 | 0,31 | |||||
| нет | 0,147 | 0,656 | 0,224 | 1,65 | |||||
| Резус конфликт | есть | 0,088 | 0,031 | 2,824 | 0,13 | 0,14 | |||
| нет | 0,912 | 0,969 | 0,941 | 0,01 | |||||
| Хронические генитальные инфекции | есть | 0,706 | 0,469 | 1,506 | 0,21 | 0,51 | |||
| нет | 0,294 | 0,531 | 0,554 | 0,30 | |||||
| Маловодие | есть | 0,382 | 0,281 | 1,359 | 0,07 | 0,10 | |||
| нет | 0,618 | 0,719 | 0,859 | 0,03 | |||||
| Многоводие | есть | 0,500 | 0,344 | 1,455 | 0,13 | 0,22 | |||
| нет | 0,500 | 0,656 | 0,762 | 0,09 | |||||
| Преждевременные роды | есть | 0,147 | 0,031 | 4,706 | 0,39 | 0,42 | |||
| нет | 0,853 | 0,969 | 0,880 | 0,03 | |||||
| Кесарева сечение | есть | 0,206 | 0,063 | 3,294 | 0,37 | 0,42 | |||
| нет | 0,794 | 0,938 | 0,847 | 0,05 | |||||
| Родостимуляция | есть | 0,147 | 0,063 | 2,353 | 0,16 | 0,17 | |||
| нет | 0,853 | 0,938 | 0,910 | 0,02 | |||||
| Аномальное предлежание | есть | 0,118 | 0,031 | 3,765 | 0,25 | 0,27 | |||
| нет | 0,882 | 0,969 | 0,911 | 0,02 | |||||
| Воды грязные | есть | 0,471 | 0,125 | 3,765 | 1,00 | 1,37 | |||
| нет | 0,529 | 0,875 | 0,605 | 0,38 | |||||
| Отслойка плаценты | есть | 0,176 | 0,063 | 2,824 | 0,26 | 0,29 | |||
| нет | 0,824 | 0,938 | 0,878 | 0,03 | |||||
| Преждевременные излитие околоплодных вод | есть | 0,294 | 0,031 | 9,412 | 1,28 | 1,46 | |||
| нет | 0,706 | 0,969 | 0,729 | 0,18 | |||||
| Низкая плацентация | есть | 0,235 | 0,063 | 3,765 | 0,50 | 0,57 | |||
| нет | 0,765 | 0,938 | 0,816 | 0,08 | |||||
| Сильное шевеление | есть | 0,529 | 0,188 | 2,824 | 0,77 | 1,18 | |||
| нет | 0,471 | 0,813 | 0,579 | 0,41 |
В таблице 85 приведены первые 7 признаков, расположенные по мере убывания их и информационной ценности
Таблица 85. Информационная ценность признаков
| № | |||||||
| xi | ОРВИ | Преждевр. излитие околоплодных вод | Воды грязные | Сильное шевеление | Бесплодие в анамнезе | Низкая плацентация | Хрон. генитальные инфекции |
| | 2,84 | 1,46 | 1,37 | 1,18 | 0,59 | 0,57 | 0,52 |
Из этой таблицы видно, что наиболее значимыми признаками послеродовых осложнений являются перенесенные ОРВИ, преждевременное излитие околоплодных вод, сильное шевеление плода и т.д.
Для реализации алгоритма прогноза в данном исследовании были заданы:
α – вероятность ошибки первого рода = 0,05
β – вероятность ошибки второго рода = 0,1
К вероятности α более жесткие требования, поскольку речь идет о том, что ошибочно не будут спрогнозированы послеродовые осложнения.


Т.к. по литературным данным послеродовые осложнения достигают до 26% (априорная вероятность), то

Осуществим прогноз для пациентки со следующими признаками:
Таблица 86. Алгоритм прогнозирования
| | | | ДК |  |
| ОРВИ | 2,84 | 1 триместр | 5+5=0 | |
| Преждевременные излитие околоплодных вод | 1,40 | нет | 5+51=1 | |
| Воды грязные | 1,32 | есть | 5+51+6=5 | |
| Сильное шевеление | 1,18 | есть | 5+51+6+5=10 | |
| Бесплодие в анамнезе | 0,59 | нет | ||
| … | … | … | … | … |
Уже на четвертом шаге превышается верхний порог и прогнозируются послеродовые осложнения.

М. Физматлит, 1960. - 328 с.
Монография выдающегося математика-статистика посвящена разработанному автором методу последовательной проверки статистических гипотез. Этот метод оказывается весьма эффективным в различных областях науки и техники, например при выборочном контроле массовой продукции, при статистической обработке результатов физических экспериментов, в общей теории связи (при решении задачи обнаружения сигнала в шумах).
Книга рассчитана на специалистов в области математической статистики, физики и различных отраслей техники (радиотехника, машиностроение и др. )
Русский перевод дополнен пятью статьями автора, в которых излагаются некоторые доказательства, отсутствующие в книге, и развивается дальше теория последовательного анализа.
Акулова Т.Г. Лекции по статистике
- формат doc
- размер 772.89 КБ
- добавлен 13 марта 2010 г.
Основные понятия, предмет и методы СТ; Статистическое наблюдение, сводка и группировка; статистические таблицы и графики; абсолютные и относительные величины; средние величины; показатели вариации; выборочный метод; проверка гипотез; статистические методы анализа корреляционных связей; анализ таблиц взаимной спряженности; анализ интенсивности динамики; анализ тенденций развития; статистические индексы.
Бикел П., Доксам К. Математическая статистика. Выпуск 2
- формат djvu
- размер 7.91 МБ
- добавлен 30 ноября 2010 г.
М.: Финансы и статистика, 1983. - 254 с. (Серия - Математико-статистические методы за рубежом). В книге изложены основные методы современной математической статистики. Содержится большое число задач. В вып. 1 рассмотрены линейные модели - регрессионный и дисперсионный анализ, анализ дискретных данных, непараметрические модели, теория решений. Приведены обзор основных понятий теории вероятностей и статистические таблицы. Для преподавателей математ.
Вучков И. Прикладной линейный регрессионный анализ
- формат pdf
- размер 10.32 МБ
- добавлен 25 сентября 2009 г.
М.: Финансы и статистика, 1987. -230 с. 1 Классическая процедура регрессионного анализа. 2 Модификации процедуры регрессионного анализа. 3 Вычислительные проблемы при плохо обусловленной информационной матрице. 4 Регрессионный анализ при неоднородных и корректированных наблюдениях. 5 Регрессионный анализ при ошибках в независимых переменных. 6 Регрессионный анализ при нарушении предположения о нормальном законе распределения наблюдений.
Горяинов В.Б., Павлов И.В., Цветкова Г.М. и др. Математическая статистика
- формат djvu
- размер 4.12 МБ
- добавлен 24 декабря 2009 г.
М.: Изд-во МГТУ им. Н. Э. Баумана, 2001. - 424 с. (Сер. Математика в техническом университете. Вып. XVII ). В. Б. Горяинов, И. В. Павлов, Г. М. Цветкова, О. И. Тескин под ред. В. С. Зарубин, А. П. Крищенко Предлагаемая книга знакомит читателя с основными понятиями математической статистики и некоторыми из ее приложений. Ее отличительной особенностью является взвешенное сочетание математической строгости с прикладной направленностью задач. Каждую.
Кочетыгов. Теория вероятностей и мат. статистика
- формат djvu
- размер 2.73 МБ
- добавлен 03 марта 2010 г.
Учебное пособие. Случайные события. Случайные величины. Системы случайных величин. Функции случайных величин. Характеристические функции случайных величин. Основы мат. статистики. Корреляционный анализ. Регрессионный анализ.
Кремлёв А.Г. Математика. Раздел Статистика
- формат pdf
- размер 6.26 МБ
- добавлен 16 апреля 2010 г.
Учебное пособие. Изд. УрГЮА (Екатеринбург), 2001, 140 с. Изложены теоретические основы математической статистики: анализ вариационных рядов, оценивание числовых характеристик и закона распределения, анализ корреляционной зависимости, линейные и нелинейные модели регрессии, проверка гипотез. Рассматриваются и объясняются в примерах практические методы расчёта статистических характеристик. Каждый раздел содержит систематизированную подборку задач.
Уилкс С. Математическая статистика
- формат djvu
- размер 9.86 МБ
- добавлен 23 июля 2009 г.
М.: Наука, 1967. 632 с. Обширная по материалу книга с удобной навигацией. Предварительные замечания. Функции распределения. Средние значения и моменты случайных величин. Последовательности случайных величин. Характеристические и производящие функции. Некоторые специальные дискретные распределения. Некоторые специальные непрерывные распределения. Теория выборочного метода. Асимптотическая теория выборочного метода для больших выборок. Линейное ста.
Хальд А. Математическая статистика с техническими приложениями
- формат djvu
- размер 13.73 МБ
- добавлен 23 июля 2009 г.
М.: Изд. Иностр. лит. , 1956. Книга является обширным руководством по приложению статистических методов. Основные понятия теории вероятностей. Некоторые основные приложения теории вероятностей. Графическое и табличное изображение наблюдений. Определение и основные свойства эмпирических распределений. Определения и основные свойства теоретических распределений. Нормальное распределение. Асимметричные распределения. Некоторые предельные теоремы и в.
Хейс Д. Причинный анализ в статистических исследованиях
- формат djvu
- размер 2.25 МБ
- добавлен 09 июля 2011 г.
Содержание: Причинность и причинный анализ Причинные диаграммы и анализ потоковых графов Статистические представления Путевой анализ Идентификация и оценка О динамике
Rencher A.C. Methods of multivariate analysis
- формат pdf
- размер 4 МБ
- добавлен 25 сентября 2011 г.
N.-Y., John Wiley & Sons, Inc., 2002. - 732p. Учебник по многомерному статистическому анализу, охватывающий достаточно стандартный набор тем: матричная алгебра, понятие о многомерных данных и простейшие методы их анализа, многомерное нормальное распределение, сравнение средних для векторов, многомерный дисперсионный анализ, сравнение ковариационных матриц, дискриминантный анализ, классификация, многомерная регрессия, каноническая корреляция.
Сущность и содержание структурной схемы агрегирования подмоделей в комплексную нейросетевую модель. Характеристика и особенности принципа Вальда, анализ и возможное управление адекватностью нейросетевой модели диагностики, прогнозирования банкротств.
| Рубрика | Экономика и экономическая теория |
| Вид | статья |
| Язык | русский |
| Дата добавления | 31.05.2018 |
| Размер файла | 1,3 M |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Многоступенчатый метод анализа и управления адекватностью нейросетевой модели прогнозирования банкротств на основе последовательного принципа Вальда
Ключевые слова: нейросеть; модель банкротства; адекватность; последовательный принцип Вальда; агрегирование; каскадное усиление положительного свойства алгоритма; байесова регуляризация нейросетевой модели.
Данная статья посвящена вопросам нейросетевого моделирования риска банкротств корпораций. Предметом исследования является анализ и управление адекватностью нейросетевых логистических моделей банкротств. Нейросети являются универсальными аппроксиматорами и классификаторами [1], способными работать в условиях высокой априорной непараметрической неопределенности в данных, т.е. когда априори нельзя задать вид функции распределения шумов. Тем не менее, как показали исследования авторов статьи [2], существуют для каждого класса задач нейросетевого моделирования предельные уровни зашумленности данных, когда нейросеть теряет устойчивость и начинает аппроксимировать в большей степени шум, чем восстанавливаемые действительные зависимости. Поэтому интерес к вопросам обеспечения качества и адекватности нйросетевых моделей (НСМ) в последнее десятилетие нарастает [3].
До настоящего времени не исследована проблема оценки и управления адекватностью разрабатываемой нейросетевой модели типа многослойного персептрона (Multi Lauer Perseptron (MLP)). Суть проблемы заключается в следующем. вальд нейросетевой банкротство
В классических моделях регрессионного анализа, получаемых с помощью метода наименьших квадратов (МНК) [4], оценка адекватности моделей не представляет трудностей - она сводится к проверке статистических гипотез о выполнении предпосылок МНК. В рассматриваемых условиях обработки данных и построения НСМ эти предпосылки заведомо нарушаются. Здесь и возникает непростая и практически неисследованная проблема оценки адекватности получаемой нелинейной многомерной НСМ, для решения которой авторы разработали оригинальный метод, основанный на принципе последовательного нейросетевого моделирования.
Истоки последовательного принципа организации схемы наблюдений берут начало из работ А. Вальда [5] и С.А. Айвазяна [6]. Изложим в сжатой форме суть этого принципа.
Как известно [6], построение статистического критерия ??(??) = ??(??1, ??2, … , . . D), где
. - наблюдаемое в i-ом опыте значение анализируемого признака (фактора), для проверки гипотезы при условии фиксированного объема выборки N сводится к разбиению области возможных значений критической статистики ??(??)на две: область I правдоподобных (в условиях проверяемой гипотезы Н0) и область II неправдоподобных значений ??(??). При попадании конкретного (экспериментального) значения статистики ??(??1, ??2, … , . ) в область неправдоподобных значений принимается решение об отклонении проверяемой гипотезы Н0 и принятии противоположной гипотезы Н1 = Н?0.
В классической схеме организации наблюдений, заранее не известно, достаточно ли фиксированное количество наблюдений ?? для различия интересующих нас гипотез Н0 и Н1 = Н?0 с заданными характеристиками точности (. ??).
Наряду с классической схемой наблюдения в практике статистических исследований применяются последовательные схемы наблюдений, при которых на каждом из последовательных во времени этапах наблюдения принимается одно из трех решений:
??(??1, … , . ) попадает в область неправдоподобных значений критической статистики . ;
Последовательная схема организации наблюдений является более гибкой и экономичной по числу опытов . необходимых для обеспечения заданного качества (. ??) проверки, статистического критерия . по сравнению с классической схемой наблюдений, где ?? = ?? ? фиксировано. Иногда удается сократить необходимое число опытов в 2-3 и даже в 4 раза [6].
В качестве конкретного примера последовательного критерия приведем широко известный критерий отношения правдоподобия Вальда [5], предназначенный для различия двух простых гипотез вида:
«Н0: выборка извлечена из генеральной совокупности с законом распределения плотности вероятности ?(. ??0);
Критическая статистика этого критерия для последовательности независимых наблюдений ??1, ??2, … , . определяется отношением правдоподобия Вальда:
Области правдоподобных , неправдоподобных , и сомнительных , значений критической статистики Вальда . по (1) (в условиях справедливости гипотезы Н0) задаются приближенно соотношениями:
1. Постановка задачи
Пусть решается задача аппроксимации многомерных данных ?? в нейросетевом базисе:
где . (. ) - восстановленное НСМ значение моделируемой случайной величины Y; . - вектор экзогенных переменных (факторов); ?? - номер наблюдения; ?? - число примеров (кортежей) в данных ??; ??(•) - оператор нейросетевого отображения:
Здесь . ??(1) - пространства вещественных чисел входа размерности ?? и выхода размерности 1; ?? - матрица синаптических весов нейросети [1].
Предполагаем, что читателю известен принцип работы MLP - нейросетей из [1], и сразу перейдем к описанию предлагаемого метода оценки и управления адекватности НСМ
Замечание. Поскольку модели слоев иерархической структуры взаимодействуют между собой, то в этой структуре имеет место агрегирование всех четырех типов, т.е. агрегаты - конфигураторы, агрегаты-операторы, агрегаты-структуры, агрегаты-статистики [8].
3. Описание алгоритма метода
Конкретизируем виды подмоделей по слоям т.е. в направлении преобразования информации (сверху-вниз на Рис. 1) и снабдим их краткими комментариями.
Рис. 1. Структурная схема агрегирования подмоделей в комплексную НСМ
В слое 1 содержатся подмодели 1.1-1.5 предобработки данных. Применяемые в этом агрегате - конфигураторе языки описания:
язык нейросетевых отображений;
вероятностный язык байесовского подхода, т.е. язык субъективных
язык математической статистики.
Подмодели слоя 1 повышают однородность и информативность данных и, следовательно, создают предпосылки для построения в нижестоящем по иерархии слое 2 НСМ хорошего качества. Достигаемый в слое 1 положительный эффект (эмерджентность) основан на основном признаке всех моделей этого слоя: предобработка данных производится не изолированно, а в объединенном пространстве размерности ?? Ч ?? входных и выходных сигналов нейросетей
где ? - логический знак объединения множеств, причем критерии предобработки данных в каждой подмодели слоя 1 подчинены критериям качества обобщения сетью данных для специально введенных вспомогательных нейросетевых субмоделей (НССМ); . . - пространства вещественных чисел размерностей ?? и ?? соответственно.
В слое 2 содержатся нейросетевые подмодели 2.2-2.3 байесовского ансамбля, которые служат для аппроксимации предобработанных данных. Здесь согласно основной парадигме регуляризации из [1, 9] происходит сужение множества искомых решений обратной задачи нахождения синаптических весов ?? нейросети. Применяемые в слое 2 агрегаты - это агрегаты-операторы в виде восстанавливаемых многомерных функций нейросетевых отображений вида (3), (4), и агрегаты-структуры в виде многослойных нейросетей. Достигаемый в слое 2 эмерджентный эффект - это регуляризация вспомогательных НССМ на байесовских ансамблях за счет механизмов их фильтрации по качеству аппроксимации данных и затем усреднения этого качества на НССМ, отфильтрованного ансамбля.
В подмоделях слоя 3 вычисляются выходные характеристики, необходимые для анализа моделируемого объекта или системы и поддержки разработки управленческих решений. Новизна этих моделей обусловлена новизной НСМ из слоя 2. Достигаемый эмерджентный эффект состоит в увеличении объективности достоверности разрабатываемых управленческих решений.
Замечание. Определяемые в слое 3 выходные (финишные) характеристики финансового объекта, помимо своей прикладной функции для принятия управленческих решений, нужны также в слое 4 как неотъемлемая часть алгоритма оценки адекватности всей НСМ.
Наконец, в подмоделях слоя 4 с использованием выходных характеристик моделируемого объекта производится оценка адекватности обобщенной (гибридной НСМ), получаемой по МВММ из [2]. Естественно, методы получения указанных оценок различны для различных прикладных задач. Общий положительный эффект (эмерджентность) для подмодели 4 обусловлен предложенным многоступенчатым методом контроля качества преобразования информации на всех ступеням (слоях) обобщенной НСМ. Другими словами оценка адекватности обобщенной НСМ носит интегральный (финишный) характер, т.е. она вбирает в себя положительные и отрицательные моменты всех предшествующих (сверху вниз на схеме Рис. 1) алгоритмов. Как правило, при этом происходит сглаживание исходных погрешностей данных, поскольку преобразование содержит в слоях 1,2 и 3 операторы усреднения, интегрирования, сокращения длины описания данных, регуляризации, которые уменьшают ошибки моделирования.
Дальнейшая детализация алгоритмов подмоделей уже выходит за границы объемы статьи, ее можно найти в [2] применительно к экономическим системам.
4. Результаты количественных оценок
Ниже приведены фрагменты количественных оценок эмерджентных эффектов, достигаемых в подмоделях слоев 1,2 и 3 многоступенчатого алгоритма оценки адекватности НСМ (Рис. 1). Полное описание результатов расчетов далеко выходят за рамки данной статьи.
Для слоя 1 в подмодели 1.1 производился выбор оптимальной системы экономических показателей (факторов) для построения комплексной НСМ диагностики банкротств. Базовой (стартовой) системой показателей служила публичная бухгалтерская отчетность для строительных организаций из [10]. В распоряжении авторов были данные о финансовом состоянии 136 российских строительных предприятий, причем 68 из них были банкротами , а 68 - стабильно работающие предприятия. На основе этой информации было сформировано 4 системы показателей (СП), которые используются в большинстве известных моделей диагностики банкротств: в пятифакторной модели Альтмана, моделях Недосекина, Зайцевой и Рахимкуловой и другими краткий обзор которых можно найти в [11]. Указанные модели отличаются количеством факторов <. >, в качестве которых используются относительные величины, характеризующие финансовое состояние предприятия.
Значение аргумента ?? в обучающих примерах известны. Если в исходной базе данных . = 1, это означает, что ??(. = 1)=1 при ?? ? 7. А если . = 0, то ??(. = 0)=0 при ?? ? ?7.
где - количество верно идентифицированных предприятий для метагипотезы . ;
- количество ошибок 2-го рода; - количество ошибок 1-го рода, ??1, ??2, ??3 - удельный вес каждого показателя. Веса ??1, ??2, ??3 назначаются согласно правилу Фишберна [11]:
где ?? - количество ранжируемых параметров.
Аномальные наблюдения не участвовали в обучении нейросети , но включались в тестовое множество для оценки качества обучения. Результаты тестирования всех СП приведены в таблице 1.
Соединившись в работах Д. Миддлтона, эти два направления образовали теоретико-техническую дисциплину — теорию статистических решений, которая занимается разработкой методов раскрытия неопределенности пространства апостериорной информации. Критерий А. Вальда — последовательный анализ: минимизируется число испытаний п, достаточное для принятия определенного решения. В этом случае производится… Читать ещё >
Теория выдвижения и проверки статистических гипотез А. Вальда ( реферат , курсовая , диплом , контрольная )
Наибольшее распространение из методов принятия статистических решений получил метод, называемый методом выдвижения и проверки гипотез.
Метод возник для оценки процессов передачи сигналов на расстоянии; базируется на общей теории статистических решающих функций А. Вальда; важным частным случаем теории является байесовский подход к исследованию процессов передачи информации, процессов общения, обучения и др. в организационных системах.
Идея метода заключается в следующем.
Имеется два векторных пространства — пространство априорной информации и пространство апостериорной информации. Первое из них иногда называют просто пространством информации 5,; второе — пространством восприятия 5 В или пространством решения.
В случае детерминированного (достоверного) восприятия точке х е 5/ соответствует только одна точка х" е 5″.
В случае статистического (вероятностного) восприятия каждой точке .г е 5, соответствует в пространстве 5 В распределение (х / х"), которое называется решающей функцией.
Что собой представляет решающая функция, можно пояснить па примере двуальтернативного решения с событиями х, и х и их априорными вероятностями р, И р.
События Х и х в пространстве 5/ могут представлять собой два состояния точки х: хх — отсутствие точки О, х — наличие точки ®.
В пространстве 5И событиям Х и х соответствуют события х < и х'2 иусловные вероятности р (х')/ хх).
Способы восприятия информации приведены на рис. 3.4.
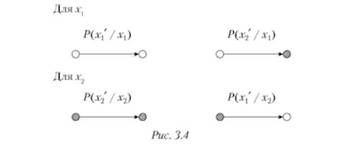
Условные вероятности р (х[/х) и р (х'2/х) характеризуют случаи правильного восприятия:
- — р (х / х <) —отсутствие точки х в пространстве восприятия 5 В в случае отсутствия ее в пространстве информации 5,;
- — р (х'2/х) — обнаружение точки х в пространстве 5 В в случае наличия ее в пространстве 5/.
Для оценки рассмотренных случаев вводится понятие " функция потерь У" .
В случае правильного восприятия, т. е. при />(. /.<) и р (х/х),
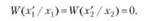
В случае ложной тревоги или пропуска сигнала.
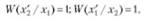
Пользуясь этими оценками потерь, можно ввести понятие условного риска. у
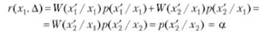
где Д — условный знак, характеризующий возможность отклонения от правильного решения, т. е. условный риск равен вероятности ложной тревоги.
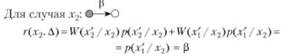
Общий риск (имеют место решения, а и Р):
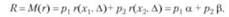
При решении некоторых задач удобнее оперировать не непосредственно с функционалами, а с их отношениями. В частности, с отношением правдоподобия, представляющем собой отношение функционалов правдоподобия условных вероятностей при наличии и при отсутствии сигнала.
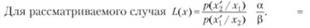
Решение о наличии или отсутствии сигнала принимается путем проверки, превышает ли отношение правдоподобия некоторый порог Ь0, т. е. если.
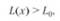
то принимается решение о наличии сигнала. В противном случае принимается решение об отсутствии сигнала.
Рассмотренный случай — это критерий Зигерта — Котельникова, называемый часто критерием идеального наблюдения (минимизируется общий риск).
В теории статистических решений используются также следующие критерии:
- а) критерий Байеса — критерий минимального риска; ищется минимальный риск из нескольких максимальных общих рисков;
- б) критерий минимакса; априорные вероятности неизвестны, и минимизируется значение максимально возможного риска, т. е. ищется ппп Д шах;
- в) критерий Неймана — Пирсона; минимизируется (3 при, а Ь, то принимается решение о наличии сигнала; если же Ьх В. А. Котельникова .
Соединившись в работах Д. Миддлтона, эти два направления образовали теоретико-техническую дисциплину — теорию статистических решений, которая занимается разработкой методов раскрытия неопределенности пространства апостериорной информации.
Читайте также: