
Инфологические модели данных реферат
Обновлено: 02.07.2024
Инфологическая модель реляционной БД – это структурная схема объектов БД – её таблиц и логических связей между таблицами.
Слово "инфологическая" происходит от лат. "informatio" - разъяснение, сведения и греч. "logikě" - логика, т.е. инфологическая модель означает информационную модель данных, между которыми установлены логические связи. Массивы данных обычно сводятся в таблицы, а таблицы – в базы данных (БД).
Слово "реляционная" происходит от relation (англ.) – отношение, в математических моделях данных отношения изображают в виде таблиц, поэтому БД, состоящая из двумерных таблиц, называется реляционной. Реляционная БД (РБД)состоит из нескольких таблиц, содержащих массивы данных, между таблицами установлены логические связи, которые и объединяют их в единую базу данных.
Отношение БД (таблица) состоит из полей (другое название - атрибутов), т.е. столбцов таблицы, и записей (или кортежей), т.е. строк таблицы. Шапка таблицы с названиями полей называется схемой отношения. Связь между таблицами устанавливаются по ключевым атрибутам, которые в Access могут быть трёх типов: простой ключ, составной ключ и внешний ключ.
Простой ключ или ключевой атрибут (в русифицированной версии Access – первичный ключ или ключевое поле) должен однозначно идентифицировать (определять) любую запись в таблице БД. Например, поле Фамилия не может быть первичным ключом, т.к. в кортежах БД могут быть люди с одной фамилией, поле Корпус может означать и корпус прибора, и воинское подразделение и т.п., поэтому в качестве первичного выбирают уникальные атрибуты – Табельный номер, шифр изделия, Код дисциплины и т.п.
Составной ключ –это первичный ключ, состоящий из нескольких
атрибутов, например, по отдельности атрибуты Фамилия и Дата рождения не могут однозначно определить любую запись таблицы, а составной атрибут Фамилия+Дата рождения является уникальным (единственным), так как маловероятно, что в таблице могут иметься две записи с совпадающими значениями этих полей.
Внешний ключ –это атрибут, который служит для связи с другими таблицами и имеется во всех таблицах, между которыми устанавливается связи.Обычнотаблица БД имеет один ключевой атрибут (простой или составной) и один или несколько вторичных. Внешним ключом для подчинённой таблицы является первичный ключ. Для задания связи эти поля таблицы должны иметь одинаковые имена или хотя бы одинаковые форматы данных.
Одна таблица в БД является основной, родительской, а связанные с ней таблицы – подчинёнными, дочерними, которые, в свою очередь являются основными для своих подчинённых таблиц и т.д. На рис. 1 изображена структура реляционной БД "Факультет", содержащая таблицы Деканат, Кафедры, Преподаватели, Дисциплины, Группы и Студенты .
Рисунок 1 Инфологическая модель реляционной БД "Деканат"
Между таблицами БД может быть три вида связей:
· связь "один к одному" , 1:1, например, между деканатом и факультетом, т.к. у факультета – один деканат, и у деканата – один факультет,
· связь "один ко многим", 1:N, например, между кафедрой и преподавателями, т.к. у кафедры много преподавателей, а у каждого преподавателя – одна кафедра и
· связь"многие ко многим", N:M, например, между преподавателями
и дисциплинами, т.к. один преподаватель читает несколько дисциплин, и одна дисциплина может читаться несколькими преподавателями.
Связи "один к одному" и "один ко многим" легко устанавливаются в Access, а связь "многие ко многим" напрямую не может быть реализована, но фактически она представляет собой две связи типа "один ко многим", поэтому для неё создаётся третья таблица, ключ которой состоит из двух полей, общих для двух таблиц со связью N:M. Таким образом, связь N:M заменяется на ещё одну таблицу, которая связывается с обеими таблицами двумя связями 1:N. В таблице связи, кроме ключевых атрибутов могут быть и другие описательные поля.
Например, связь N:M между таблицами-объектами ГРУППА и ДИСЦИПЛИНА реализуется с помощью третьей таблицы с именем ГРУП-ДИСЦ, которые связаны с исходными таблицами связями 1:N (рис. 2).
Рисунок 2 Замена связи N:M на таблицу с двумя связями 1:N
Таким образом, реализация связи "многие ко многим" добавляет в БД ещё один объект – таблицу связи.
Логическая модель реляционной БД – это инфологическая БД, в которой каждая её таблица представлена своей схемой – шапкой таблицы и показаны ключевые атрибуты, между которыми установлены логические связи между таблицами.
Обеспечения надежности системы управления данными. Походы к выбору состава и структуры предметной области. Исследования информационной среды для моделирования. Цель инфологического моделирования – обеспечение естественных способов сбора информации.
| Рубрика | Программирование, компьютеры и кибернетика |
| Вид | курсовая работа |
| Язык | русский |
| Дата добавления | 27.02.2009 |
| Размер файла | 212,0 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
ГЛАВА 1. АНАЛИЗ ПРЕДМЕТНОЙ ОБЛАСТИ
1.1 Описание предметной области
1.2 Инфологическое моделирование
ГЛАВА 2. ИНФОЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
2.2 Связи между сущностями
ВВЕДЕНИЕ
Процесс проектирования БД на основе принципов нормализации представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели.
Инфологическое проектирование прежде всего связано с попыткой представления семантики предметной области в модели БД.
Цель нашего проекта - инфологическое моделирование информационной системы выборов.
В настоящее время практически во всех сферах человеческой деятельности используются базы данных. Данная инфологическая модель базы данных может применяться в различных организациях. Для обеспечения надежности системы управления данными необходимо выполнить следующие основные требования:
- целостность и непротиворечивость данных,
- достоверность данных,
- простота управления данными,
- безопасность доступа к данным.
Предметной областью называется фрагмент реальности, который описывается или моделируется с помощью БД и ее приложений. В предметной области выделяются информационные объекты - идентифицируемые объекты реального мира, процессы, системы, понятия и т.д., сведения о которых хранятся в БД.
ГЛАВА 1. АНАЛИЗ ПРЕДМЕТНОЙ ОБЛАСТИ
Процесс проектирования БД на основе принципов нормализации представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. В общем случае можно выделить следующие этапы проектирования:
1. Системный анализ и словесное описание информационных объектов предметной области.
2. Проектирование инфологической модели предметной области - частично формализованное описание объектов предметной области в терминах некоторой семантической модели, например, в терминах ER-модели.
3. Даталогическое или логическое проектирование БД, то есть описание БД в терминах принятой даталогической модели данных.
4. Физическое проектирование БД, то есть выбор эффективного размещения БД на внешних носителях для обеспечения наиболее эффективной работы приложения.
Если мы учтем, что между вторым и третьим этапами необходимо принять решение, с использованием какой стандартной СУБД будет реализовываться наш проект, то условно процесс проектирования можно представить последовательностью выполнения пяти соответствующих этапов (см. рис. 1).
Рис. 1. Этапы проектирования БД
С точки зрения проектирования БД в рамках системного анализа, необходимо осуществить первый этап, то есть провести подробное словесное описание объектов предметной области и реальных связей, которые присутствуют между описываемыми объектами. Желательно, чтобы данное описание позволяло корректно определить все взаимосвязи между объектами предметной области.
В общем случае существуют два похода к выбору состава и структуры предметной области:
Предметный подход - когда информационные потребности будущих пользователей БД жестко не фиксируются. Они могут быть многоаспектными и весьма динамичными. Мы не может точно выделить минимальный набор объектов предметной области, которые необходимо описывать. В описание предметной области в этом случае включаются такие объекты и взаимосвязи, которые наиболее характерны и наиболее существенны для нее. БД, конструируемая при этом, называется предметной, то есть она может быть использована при решении множества разнообразных, заранее не определенных задач. Конструирование предметной БД в некотором смысле кажется гораздо более заманчивым, однако трудность всеобщего охвата предметной области с невозможностью конкретизации потребностей пользователей может привести к избыточно сложной схеме БД, которая для конкретных задач будет неэффективной.
Чаще всего на практике рекомендуется использовать некоторый компромиссный вариант, который, с одной стороны, ориентирован на конкретные задачи или функциональные потребности пользователей, а с другой стороны, учитывает возможность наращивания новых приложений.
Системный анализ должен заканчиваться подробным описанием информации об объектах предметной области, которая требуется для решения конкретных задач и которая должна храниться в БД, формулировкой конкретных задач, которые будут решаться с использованием данной БД с кратким описанием алгоритмов их решения, описанием выходных документов, которые должны генерироваться в системе, описанием входных документов, которые служат основанием для заполнения данными БД.
1.2 Инфологическое моделирование
Процесс, в ходе которого решается, какой вид будет у вновь создаваемой базы данных, называется проектированием базы данных (database design). Работа по проектированию базы данных включает выбор:
- таблиц, которые будут входить в базу данных,
- столбцов, принадлежащих каждой таблице,
- взаимосвязей между таблицами и столбцами.
На практике проектирование базы данных требует хорошего понимания моделируемой предметной области, а также знаний в области моделирования зависимостей и нормализации. Проектирование базы данных обычно является итеративным процессом, в ходе которого шаг за шагом достигается требуемый результат, а иногда и пересматривается несколько шагов, переделывая предыдущую работу с учетом появившихся новых потребностей. Вот примерная последовательность шагов выполняемая в процессе проектирования базы данных.
1. Исследования информационной среды для моделирования.
Откуда поступает информация и в каком виде?
Как она будет вводиться в систему и кто этим будет заниматься?
Как часто она изменяется?
Какие параметры системы будут наиболее критическими с точки зрения времени реакции на запрос и надежности?
Изучение всех бумажных материалов, а также информационных файлов и форм, которые используются в организации для хранения и обработки данных.
Уточнение, в каком виде информация должна извлекаться из базы данных -- в форме отчетов, заказов, статистической информации.
Кому она будет предназначаться.
2. Создание списка объектов (вещей, которые будут предметом базы данных) вместе с их свойствами и атрибутами. Объекты, скорее всего, должны быть собраны в таблицы (каждая строка таблицы будет описывать один объект, например организацию, счет или платежное поручение), свойства объектов будут представлены столбцами таблицы (например, адрес компании, стоимость дистрибутива).
3. В ходе работы обязательно должен создаваться макет таблиц и связей между ними, называемый структурой данных (data structure), или диаграммой зависимостей между объектами (E-R diagram).
4. Предварительно разобравшись с объектами и их атрибутами, надо убедится, что каждый объект имеет атрибут (или группу атрибутов), по которому однозначно можно идентифицировать любую строку в будущей таблице. Этот идентификатор обычно называется первичным ключом. Если такового нет, то для получения искусственного ключа следует создать дополнительный столбец.
5. Затем должны быть рассмотрены зависимости между объектами.
Имеются ли зависимости типа один-ко-многим (один заказчик может иметь множество выписанных счетов, но каждый счет может быть выписан только на одного заказчика) или многие-ко-многим?
Есть ли возможности для объединения связанных таблиц? Для этого служат внешние ключи (foreign key), столбцы в связанных таблицах с совпадающими значениями первичных ключей.
6. Анализ структуры базы данных с точки зрения правил нормализации для поиска логических ошибок. Исправление всех отклонений от нормальных форм или обоснование решения отказаться от выполнения ряда правил нормализации в интересах простоты освоения или производительности. Документирование причины таких решений.
7. Непосредственному создание структуры базы данных и помещению в нее некоторых прототипов данных. Обязательное экспериментирование с запросами, изучение полученных результатов. Выполнение рядов тестов на производительность, чтобы проверить разные технические решения.
8. Оцените базы данных с точки зрения того, удовлетворяют ли заказчика полученные результаты.
Данная СУБД была выбрана по следующим причинам:
- простота средств реализации,
- легкость освоения инструментарием разработчика (VBA),
- наглядность визуализации информации.
Связи между таблицами можно разбить на четыре базовых реляционных типа с отношениями:
- один-к-одному;
- один-ко-многим;
- многие-к-одному;
- многие-ко-многим.
Структура организации таблиц позволяет создание первичных и внешних ключей. Имеется возможность изменения типа внутренних объединений для связанных таблиц.
Цель инфологического моделирования - обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка). Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Сущность - любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе.
Сущность имеет имя, уникальное в пределах модели. При этом имя сущности - это имя типа, а не конкретного экземпляра.
Сущность может быть расщеплена на два или более взаимоисключающих подтипов, каждый из которых включает общие атрибуты и/или связи. Эти общие атрибуты и/или связи явно определяются один раз на более высоком уровне. В подтипах могут определяться собственные атрибуты и/или связи. В принципе выделение подтипов может продолжаться на более низких уровнях, но в большинстве случаев оказывается достаточно двух-трех уровней.
Атрибут - поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей. Атрибуты используются для определения того, какая информация должна быть собрана о сущности.
Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность.
Ключ - минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся.
Связь - ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных - это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Между двумя сущностям, например, А и В возможны четыре вида связей.
Первый тип - связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В:
Второй тип - связь ОДИН-КО-МНОГИМ (1:М): одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В.
Так как между двумя сущностями возможны связи в обоих направлениях, то существует еще два типа связи МНОГИЕ-К-ОДНОМУ (М:1) и МНОГИЕ-КО-МНОГИМ (М:N).
ГЛАВА 2. ИНФОЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д. Наиболее популярной из них оказалась модель "сущность-связь" или называемая ещё ER-моделью (от англ. Entity-Relationship, т.е. сущность-связь).
Система управления базой данных (СУБД) — важнейший компонент информационной системы. СУБД предоставляет возможность контролировать описание своих данных, работу с ними и организацию коллективного пользования этой информацией. СУБД так же существенно увеличивает возможности и облегчает ведение больших объёмов хранящейся в многочисленных таблицах информации. Основные функции СУБД: Чтобы вызвать… Читать ещё >
Инфологическая модель данных ( реферат , курсовая , диплом , контрольная )
Инфологическая модель базы данныхструктурная схема объектов БД, а в частности ее таблицы и логические связи между ними. Связанные между собой таблицы, нужны для создания запросов и форм, а также для нахождения нужной информации из подходящих полей связанных таблиц.
Между таблицами БД может быть 3 вида связей:
Построим инфологическую модель данного книжного магазина (см рисунок 1).
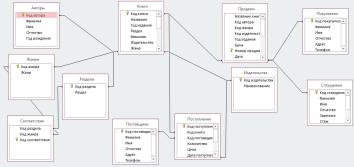
Рисунок 1. Инфологическая модель данных.
Чтобы вызвать окно Схема данных, необходимо выполнить одноименную команду меню Сервис или нажать соответствующую кнопку инструментальной панели. Добавить таблицу в окно Схема данных можно, вызвав правой кнопкой мыши контекстное меню и выбрав пункт Добавить таблицу или выполнив команду Связь — Добавить таблицу, а также используя соответствующую кнопку инструментальной панели.
Проведя связи между таблицы, мы четко определили данные предметной области и получили более полное отображение.
2. Практическая часть
Реализация баз данных в MS Access
Система управления базой данных (СУБД) — важнейший компонент информационной системы. СУБД предоставляет возможность контролировать описание своих данных, работу с ними и организацию коллективного пользования этой информацией. СУБД так же существенно увеличивает возможности и облегчает ведение больших объёмов хранящейся в многочисленных таблицах информации. Основные функции СУБД:
- * управление данными во внешней памяти (на дисках);
- * управление данными в оперативной памяти;
- * журнализация изменений и восстановление БД после сбоев;
- * поддержание языков БД (язык определения данных).
Наиболее популярной на сегодняшний СУБД для персональных компьютеров является MS Access. Она представляет собой систему обслуживания реляционных баз данных с графической оболочкой. Данные в таких базах оформляются в виде одной или нескольких таблиц, состоящих из однотипных записей.

ГОСТ
Инфологическое моделирование выполняется с целью обеспечения самых естественных для человека способов представления и сбора информации, которая будет храниться в создаваемой БД. Поэтому инфологическая модель данных">данных строится в соответствии с естественным языком, который не возможно использовать в чистом виде в виду сложности обработки текстов с помощью компьютера и неоднозначности естественного языка.
Основные конструктивные элементы инфологической модели – это сущности, связи между сущностями и их атрибуты (свойства).
Сущностью является любой объект, предмет, идея, событие, явление или факт, информация о котором должна храниться в БД.
В роли сущностей могут выступать изобретения, гроза, женитьба, цвет, вкус, рейсы, самолеты, места, люди и т.п.
Различают понятия экземпляр сущности и тип сущности.
Тип сущности определяет набор однородных идей, событий, предметов или личностей, которые выступают как целое.
Экземпляр сущности определяет конкретную вещь в наборе.
Например, ГОРОД может являться типом сущности, а Кишинев, Одесса – экземпляром сущности.
Атрибут является поименованной характеристикой (свойством) сущности.
Т.е. атрибутом является любая деталь, служащая для выражения состояния, числовой характеристики, классификации, идентификации или уточнения сущности.
Готовые работы на аналогичную тему
Для конкретного типа сущности наименование атрибута должно быть уникальным, но для разного типа сущностей может быть одинаковым.
Например, атрибут ЦВЕТ может определяться для многих сущностей: ДЫМ, АВТОМОБИЛЬ, СОБАКА и т.д.
Атрибуты используют, чтобы определить информацию, которая должна быть собрана о сущности.
Примеры атрибутов для сущности СОБАКА – ПОРОДА, ЦВЕТ, ВОЗРАСТ, КЛИЧКА и т.д.
Имеет место также разница между экземпляром и типом. У типа атрибута ПОРОДА есть много значений или экземпляров (Овчарка, Колли, Дог, Пекинес и т.д.), но каждый экземпляр сущности имеет лишь одно значение атрибута.
Кардинальная разница между атрибутами и типами сущностей отсутствует. Атрибут является атрибутом лишь в связи с типом сущности. В другом понимании атрибут может быть самостоятельной сущностью.
Ключ является минимальным набором атрибутов, значения которых однозначно определяют необходимый экземпляр сущности.
Минимальный набор означает, что при удалении из набора любого атрибута невозможно по тем атрибутам, которые остались, идентифицировать сущность.
Связь ассоциирует две или больше сущности.
Абсолютного различия между связями и типами сущностей не существует. Один и тот же факт можно совершенно правдиво рассматривать или как связь, или как сущность.
Если бы база данных предназначалась лишь для хранения отдельных данных, которые не связаны между собой, то структура такой базы была бы слишком простой.
Но одним из основных требований к организации базы данных является обеспечение возможности нахождения одних сущностей по значениям других, а для этого необходимо установление между ними определенных связей. В практической деятельности базы данных зачастую содержат более сотен или даже тысяч сущностей, поэтому теоретически между ними можно установить больше миллиона связей. Наличием такого большого количества связей и определяется сложность инфологических моделей.
Составить инфологическую модель базы данных (БД), необходимой для предоставления информации программе расчета предельно-допустимых сбросов (ПДС) сточных вод предприятий в прибрежную зону моря.
Эта программа производит расчет максимально-допустимых концентраций загрязняющих веществ в выпусках сточной воды
Предприятие, для которого производится расчет ПДС может иметь несколько выпусков. Каждый выпуск характеризуется своими техническими параметрами, которые учитываются в расчетах. Каждый выпуск имеет свой набор загрязняющих веществ. Для каждого выпуска существует свой контрольный створ (точка на море, отстоящая от места выпуска на 50-500 м, в которой производится замер концентраций загрязняющих веществ). Несколько выпусков могут иметь один и тот же контрольный створ, но не наоборот.
Расчет производится для каждого выпуска в отдельности в два этапа. Первый - это расчет для каждого загрязняющего вещества индивидуального ПДС (без учета других веществ) по специальной методике* . Для этого расчета требуются следующие данные: фоновая концентрация вещества в контрольном створе, концентрация вещества в сточных водах выпуска, диаметр выпускного отверстия, минимальная скорость морского течения в месте выпуска, расход сточных вод, угол истечения стоков относительно поверхности моря, расстояние от выпуска до поверхности моря, до берега и до ближайшей границы водопользования (т. е. до контрольного створа), коэффициент неконсервативности (КНК) вещества, предельно допустимая концентрация (ПДК) вещества в контрольном створе.
Второй этап - расчет ПДС для каждого вещества на основе индивидуального ПДС с учетом других веществ, находящихся в одной группе с одинаковым лимитирующим фактором вредности (ЛФВ) или в одной группе с одинаковым классом опасности. Распределение веществ по группам ЛФВ и классам опасности происходит в зависимости от типа водопользования предприятия, для которого считается ПДС.
Проектируемая БД должна содержать информацию по всем предприятиям, для которых производился расчет ПДС. Значения фоновых концентраций, концентраций в стоках и ПДК веществ должны быть закреплены за датой.
Таким образом, программе расчета ПДС требуются следующие данные:
· наименование и характеристики всех выпусков, для которых производится расчет ПДС;
· список всех контролируемых веществ для каждого выпуска с концентрациями этих веществ в сточных водах;
· ПДК, фоновая концентрация и КНК веществ в контрольных створах для каждого выпуска;
· таблица соответствий веществ с ЛФВ в зависимости от типа водопользования предприятия, для которого производится расчет.
| Тип сущности | Атрибуты |
| Предприятие | Код, Наименование |
| Выпуск | Код, Наименование, |
| КонтрольныйСтвор | Код, Наименование |
| Вещество | Код, Наименование |
| ТипВодопользования | Код, Наименование |
| ЛФВ | Код, Наименование |
| КлассОпасности | Код, Наименование |
| Тип связи | Типы сущностей | Атрибуты |
| ИмеетВыпуск | Предприятие, Выпуск | — |
| ИмеетТипВодопользования | Предприятие, ТипВодопользования | — |
| ИмеетКонтрольныйСтвор | Выпуск, КонтрольныйСтвор | — |
| КонцентрацияСтока | Выпуск, Вещество | Концентрация, Дата |
| КонцентрацияФона | КонтрольныйСтвор, Вещество | Концентрация, Дата |
| КонцентрацияПД | КонтрольныйСтвор, Вещество | Концентрация, Дата |
| КНК | КонтрольныйСтвор, Вещество | Коэффициент, Дата |
| ГруппыПоЛФВ | ТипВодопользования, Вещество, ЛФВ | — |
| ГруппыПоКлассуОпасности | ТипВодопользования, Вещество, КлассОпасности | — |
| Атрибут | Тип сущности/связи |
| Код | Предприятие |
| Код | Выпуск |
| Код | КонтрольныйСтвор |
| Код | Вещество |
| Код | ТипВодопользования |
| Код | ЛФВ |
| Код | КлассОпасности |
| Дата | КонцентрацияСтока |
| Дата | КонцентрацияФона |
| Дата | КонцентрацияПД |
| Дата | КНК |
Виды связей
ИмеетВыпуск Предприятие Þ Выпуск
ИмеетКонтрольныйСтвор КонтрольныйСтвор Þ Выпуск
КонцентрацияСтока
КонцентрацияФона
КонцентрацияПД
КНК
Ограничения по существованию
| ИмеетВыпуск | Предприятие Þ Выпуск |
 |
* ВНИИВО, “Методика расчета ПДС веществ в водные объекты со сточными водами”, Харьков 1990 г.
Читайте также: